es kibana .logstash离线集群安装
es离线集群安装
下载对应的版本一般看你客户端引用的是什么版本我这里下载的是7.6.2
官方下载地址:https://www.elastic.co/cn/downloads/elasticsearch
源码安装-环境准备:在etc/hosts文件添加3台主机
node-001 192.168.1.81
node-002 192.168.1.82
node-003 192.168.1.83
将上传的包放到一个目录底下我是放在 /data/elk
解压包 tar -zxvf elasticsearch-7.6.2-linux-x86_64.tar.gz
系统设置
设置内核参数
#Elasticsearch mmapfs默认使用目录来存储其索引。默认的操作系统对mmap计数的限制可能太低,这可能会导致内存不足异常。
vi /etc/sysctl.conf
vm.max_map_count=262144sysctl -p #执行命令sysctl -p生效当前用户每个进程最大同时打开文件数
#查看硬限制
ulimit -Hn
ulimit -Sn
#通常情况下如果值是4096启动ES时会报如下错误
#max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]修改配置文件
vi /etc/security/limits.conf
* hard nofile 65537
* soft nofile 65536sysctl -p
修改es的配置文件
节点1
vi config/elasticsearch.yml
cluster.name: elk # 集群名称
node.name: node-001 # 节点名称
path.data: /opt/elk/data # 自定义数据目录
path.logs: /opt/elk/logs # 自定义logs文件目录
network.host: 0.0.0.0 # 配置那些ip可以访问
http.port: 9200 # 配置端口
discovery.seed_hosts: ["192.168.1.81:9300", "192.168.1.82:9300","192.168.1.83:9300"] # 这是配置集群访问端口的,也可以配置为node-001......之类的只要配置了hosts就行,他会自动拼接ip:9300
cluster.initial_master_nodes: ["node-001", "node-002","node-003"] # 配置节点信息。我上边节点名称用了node-001...这边就配置node-001...
节点2:######## node-002cluster.name: elk # 集群名称
node.name: node-002 # 节点名称
path.data: /opt/elk/data # 自定义数据目录
path.logs: /opt/elk/logs # 自定义logs文件目录
network.host: 0.0.0.0 # 配置那些ip可以访问
http.port: 9200 # 配置端口
discovery.seed_hosts: ["192.168.1.81:9300", "192.168.1.82:9300","192.168.1.83:9300"] # 这是配置集群访问端口的,也可以配置为node-001......之类的只要配置了hosts就行,他会自动拼接ip:9300
cluster.initial_master_nodes: ["node-001", "node-002","node-003"] # 配置节点信息。我上边节点名称用了node-001..
节点3:cluster.name: elk # 集群名称
node.name: node-003 # 节点名称
path.data: /opt/elk/data # 自定义数据目录
path.logs: /opt/elk/logs # 自定义logs文件目录
network.host: 0.0.0.0 # 配置那些ip可以访问
http.port: 9200 # 配置端口
discovery.seed_hosts: ["192.168.1.81:9300", "192.168.1.82:9300","192.168.1.83:9300"] # 这是配置集群访问端口的,也可以配置为node-001......之类的只要配置了hosts就行,他会自动拼接ip:9300
cluster.initial_master_nodes: ["node-001", "node-002","node-003"] # 配置节点信息。我上边节点名称用了node-001...这边就配置node-001...创建ES需要的用户
root权限是直接启动不了ES的,所以需要创建启动的用户
用户名是elsearch 密码是elsearch
useradd elsearch && echo "elsearch" | passwd --stdin "elsearch" # 创建一个普通用户
chown -R elsearch:elsearch /data/elk/ # 给es源码换一下所属组和主
启动es集群 启动3台机器的es
./bin/elasticsearch -d # 后台运行启动(第一次启动可以先不加-d前台运行看下有没有问题和报错
注意
7点多以后es需要jdk11版本如果是jdk1.8会报错这里是使用了es自带的jdk删除elasticsearch-env文件里面的
# now set the path to java
if [ ! -z "$JAVA_HOME" ]; thenJAVA="$JAVA_HOME/bin/java"JAVA_TYPE="JAVA_HOME"
elseif [ "$(uname -s)" = "Darwin" ]; then# macOS has a different structureJAVA="$ES_HOME/jdk.app/Contents/Home/bin/java"elseJAVA="$ES_HOME/jdk/bin/java"fiJAVA_TYPE="bundled jdk"
fi
安装kibana
官网下载linux版本:https://www.elastic.co/cn/downloads/kibana
跟es对应的版本这里是7.6.2 上传到/data/elk
修改配置文件
vi config/kibana.yml
#配置端口号
server.port: 5601
#配置网络访问地址
server.host: "0.0.0.0"
#配置es链接地址(es集群,可以用逗号分隔)
elasticsearch.hosts: ["http://10.0.0.81:9200","http://10.0.0.82:9200","http://10.0.0.83:9200"]
#配置中文语言界面
i18n.locale: "zh-CN"赋权 chown -R elsearch:elsearch /data/elk/
su elsearch
4 执行以下命令创建manage_script.sh管理脚本
echo '#!/bin/bash
KIBANA_HOME="/data/elk/kibana-7.6.2-linux-x86_64" # Kibana安装目录
KIBANA_BIN="$KIBANA_HOME/bin/kibana" # Kibana 可执行文件路径
PID_FILE="$KIBANA_HOME/kibana.pid"
LOG_FILE_PATH="$KIBANA_HOME/logs"start_kibana() {if [ -f "$PID_FILE" ]; thenecho "Kibana is already running."elseecho "Starting Kibana..."mkdir -p ${LOG_FILE_PATH}nohup $KIBANA_BIN > "${LOG_FILE_PATH}/kibana.log" 2>&1 &echo $! > $PID_FILEecho "Kibana started."fi
}stop_kibana() {if [ -f "$PID_FILE" ]; thenPID=$(cat $PID_FILE)echo "Stopping Kibana..."kill $PIDrm $PID_FILEecho "Kibana stopped."elseecho "Kibana is not running."fi
}status_kibana() {if [ -f "$PID_FILE" ]; thenPID=$(cat $PID_FILE)if ps -p $PID > /dev/null 2>&1; thenecho "Kibana is running. PID: $PID"elseecho "Kibana is not running, but pid file exists."fielseecho "Kibana is not running."fi
}case "$1" instart)start_kibana;;stop)stop_kibana;;status)status_kibana;;*)echo "Usage: $0 {start|stop|status}"exit 1
esac' > /data/elk/kibana-7.6.2-linux-x86_64/bin/manage_script.sh
chmod +x /data/elk/kibana-7.6.2-linux-x86_64/bin/manage_script.sh启动kibana
bin/manage_script.sh start
停止kibana
bin/manage_script.sh stop
查看kibana的状态
bin/manage_script.sh status
启动报错
Illegal character in scheme name at index 0: 10.0.0.81:9200,10.0.0.82:9200,10.0.0.83:9200
这是因为elasticsearch.hosts: ["http://10.0.0.81:9200","http://10.0.0.82:9200","http://10.0.0.83:9200"]配置错了logstash 安装
下载logstash版本 7.2.1
下载推荐到elastic中文社区,里面有elastic系列里所有的开源产品下载链接,地址如下:
https://elasticsearch.cn/download/
解压 安装包:
tar zxvf logstash-7.6.2.tar.gz
赋权 chown -R elsearch:elsearch /data/elk/
su elsearch
配置kafka es
新建 myconf.conf
配置文件 编辑如下
input {kafka {bootstrap_servers => "x.x.x.x:9092,x.x.x.x:9092,x.x.x.x:9092"group_id => "kafka_logstash"topics => "eoplog"consumer_threads => 5auto_commit_interval_ms => "1500"auto_offset_reset => "earliest"codec => "json"type => "eoplog"client_id => "kafka_logstash"}
}
output {elasticsearch{#es的地址hosts => ["x.x.113.15:9200"] index => "eopstat-%{+YYYY.MM.dd}"user => "elastic"
password => "elastic"}
# stdout { codec => rubydebug }
}置文件启动命令如下:
nohup bin/logstash -f myconf.conf &问题:
生成的es发现索引时间不对这个应该跟系统时间有关
“_index” : “stat-2024.10.18”,

你可以使用以下命令检查当前时间和时间同步状态
timedatectl
设置正确的时区
sudo timedatectl set-timezone Asia/Shanghai
手动设置系统时间
禁用自动时间同步
sudo timedatectl set-ntp false
sudo timedatectl set-time ‘2024-10-18 10:02:00’
可选:重新启用自动时间同步
sudo timedatectl set-ntp true
相关文章:
es kibana .logstash离线集群安装
es离线集群安装 下载对应的版本一般看你客户端引用的是什么版本我这里下载的是7.6.2 官方下载地址:https://www.elastic.co/cn/downloads/elasticsearch 源码安装-环境准备:在etc/hosts文件添加3台主机 node-001 192.168.1.81 node-002 19…...

Java项目-基于springboot框架的基于协同过滤算法商品推荐系统项目实战(附源码+文档)
作者:计算机学长阿伟 开发技术:SpringBoot、SSM、Vue、MySQL、ElementUI等,“文末源码”。 开发运行环境 开发语言:Java数据库:MySQL技术:SpringBoot、Vue、Mybaits Plus、ELementUI工具:IDEA/…...

JAVA使用easyExcel导出数据到EXCEl,导出数据不全问题解决
JAVA使用easyExcel导出数据到EXCEl,导出数据不全问题解决 问题描述解决思路一解决思路二温馨提示 问题描述 JAVA使用easyExcel导出数据到EXCEl,导出数据不全问题。 导出的excel部分列有数据,好几列没有数据 解决思路一 从网上百度查询,大多数的解决思路…...
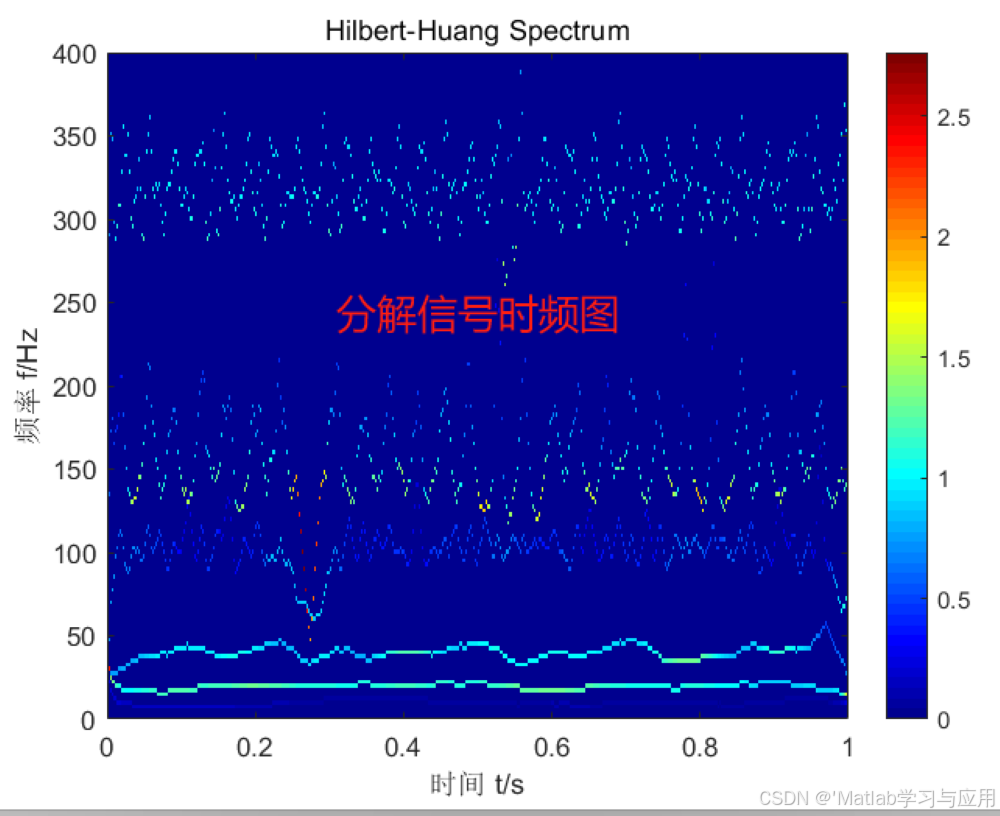
2-130 基于经验模态分解(EMD)的信号分解
基于经验模态分解(EMD)的信号分解。通过仿真信号构造待分解信号,经过分解后得到信号希尔伯特时频图,可视化展示不同分解信号频率段。程序已调通,可直接运行。 下载源程序请点链接:2-130 基于经验模态分解&…...
- vue3)
openlayers 测量功能实现(测距测面)- vue3
一、配置openlayer环境 借鉴:Vue 3 OpenLayers 的简单使用_vue3 openlayers-CSDN博客 二、代码如下(测距、测面和清除) measurs.js: import {ref} from vue; import Draw from ol/interaction/Draw import VectorSource from ol/source/…...
)
各种语言的序列化与反序列化(C/C++ c# Python Javascript Java)
序列化是指将程序中的对象转换为字节序列的过程,使得对象的状态可以在网络上传输或存储到文件中。反序列化则是将字节序列恢复为程序中的对象的过程。这两个过程是数据持久化和远程通信中的关键步骤。 1. C 序列化与反序列化 在 C 中,标准库没有提供内…...

RHCE笔记
第二章:时间服务器 东八区:UTC8CST(北京时间) 应用层的时间协议:NTP(网络时间协议):udp/端口:123 Chrony软件:由chronyd(客户端)和chronyc(服务…...

Android 设置控件为圆形
Android的圆形控件 对于所有的View有效 在开发的过程中,肯定需要实现一个圆形的控件,而且不是绘制一个圆形,那么怎么弄呢,在Android5.0后,有一个类ViewOutlineProvider,可以实现这个功能,应该是…...

qt/c++中成员函数返回成员变量并且可以赋值
#创作灵感 最近在做仪表项目,由于客户提供的仪表故障指示灯只有10个固定位置,而故障指示灯却有80多个。为了解决这个问题,进过我的设计,项目中需要返回类的成员变量。并且还可以赋值给它。于是就产生了下面的代码。 class Foo { …...

【网络安全】IDOR与JWT令牌破解相结合,实现编辑、查看和删除数万帐户
未经许可,不得转载。 文章目录 前言漏洞1漏洞2修复建议在今年4月17日,笔者发过一篇关于 JWT 的文章,未学习过或稍有遗忘的朋友可以点击跳转:【网络安全 | 密码学】JWT基础知识及攻击方式详析 现分享一篇与 JWT 有关的漏洞挖掘案例。 前言 我在某公共漏洞奖励计划的应用程…...

docker安装与镜像打包
文章目录 前言一、docker安装1.1、下载docker安装包1.2、解压1.3、移动1.4、docker注册成系统服务1.5、添加文件权限1.6、设置开机启动1.7、启动docker1.8、测试是否启动 二、镜像加载2.1、镜像准备2.2、加载镜像2.3、查看已加载镜像2.4、进入镜像 三、打包镜像3.1、创建 Docke…...

“新物种”即将上线,极氪MIX是近几年最“好玩”的新车?
像极氪MIX这样有创意的新能源车 除了概念车外,市面上真的很少能看到类似的量产车 别致可爱的造型、新颖的对开门设计、百变的空间布局 同时兼顾了MPV大空间以及SUV的操控乐趣和通过性 妥妥的“新物种” A级车车长D级车轴距,配合隐藏式双B柱电动对开…...

【Flutter】路由与导航:复杂导航与深度链接
在开发大型 Flutter 应用时,复杂的导航管理是不可避免的。除了基本的页面跳转与返回操作外,很多应用会用到 嵌套路由、页面分组、TabBar 和 Drawer 的结合使用等复杂导航场景,甚至支持 深度链接 和 动态路由。本文将深入探讨这些高级导航技巧…...

07 实战:视频捕获
代码如下: import tkinter as tk # 导入tkinter库,用于创建图形用户界面 from tkinter import ttk, filedialog, messagebox # 导入tkinter的额外部件、文件对话框和消息框 import cv2 # 导入OpenCV库,用于图像处理 import numpy as np # 导入NumPy库,用于数值计算 from P…...

前端页面使用google地图api实现导航功能,开发国外网站免费简单好用
开发国外软件的时候,想使用goole map实现导航等功能,可以使用google的api来做,官方文档地址:https://developers.google.com/maps/documentation/urls/get-started?hlzh-cn ,比如: 支持的请求的操作&…...
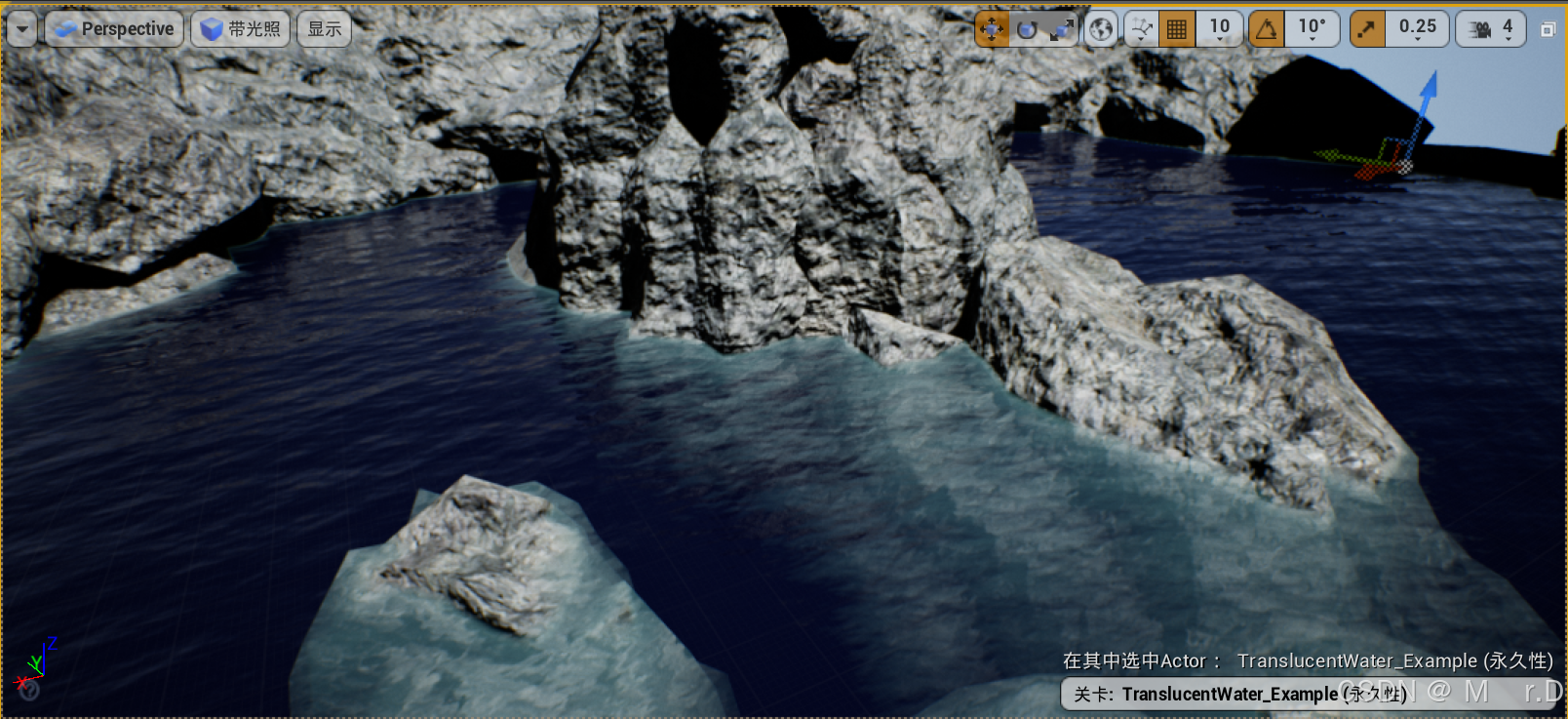
UE4 材质学习笔记12(水体反射和折射)
一.水体反射和折射 首先就是要断开所有连接到根节点的线,因为水有很多不同的节点成分,当所有其他节点都在用时 要分辨出其中一个是何效果是很难的。 虚幻有五种不同的方法可以创建反射,虚幻中的大多数场景使用多种这些方法 它们会同时运作。…...
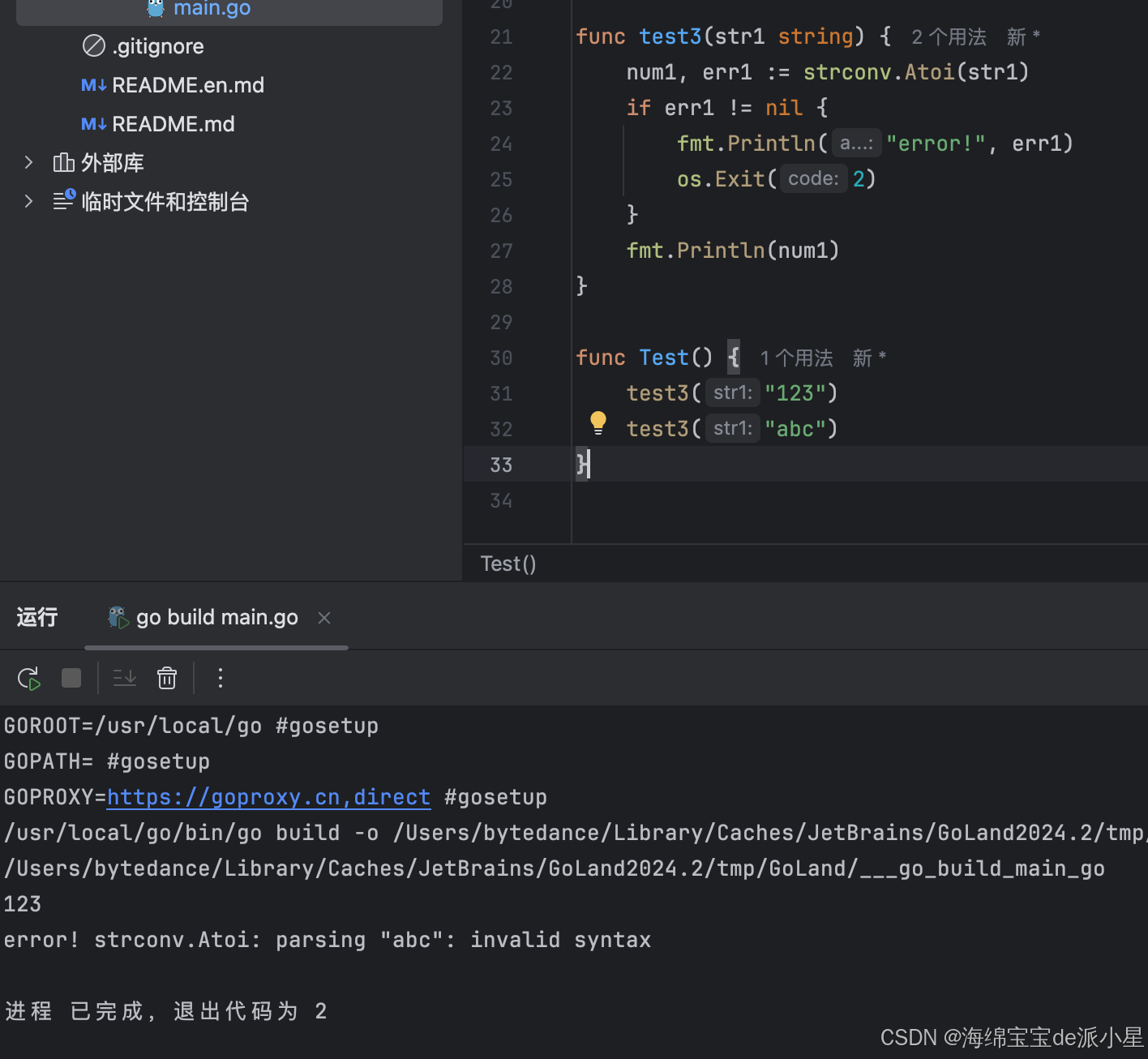
Go:error处理机制和函数
文章目录 error处理机制函数函数作为参数匿名函数匿名函数和闭包闭包运用闭包与工厂模式 error处理机制 本篇总结的是Go中对于错误的处理机制 Go 语言的函数经常使用两个返回值来表示执行是否成功:返回某个值以及 true 表示成功;返回零值(或…...
智能指针(3)
目录 可能问题五: 问题分析: 答案格式: shared_ptr的模拟实现 部分1:引用计数的设计(分考点1) 代码实现: 部分2:作为类所必须的部分(分考点2) 代码实现: 部分3:拷贝构造函数…...
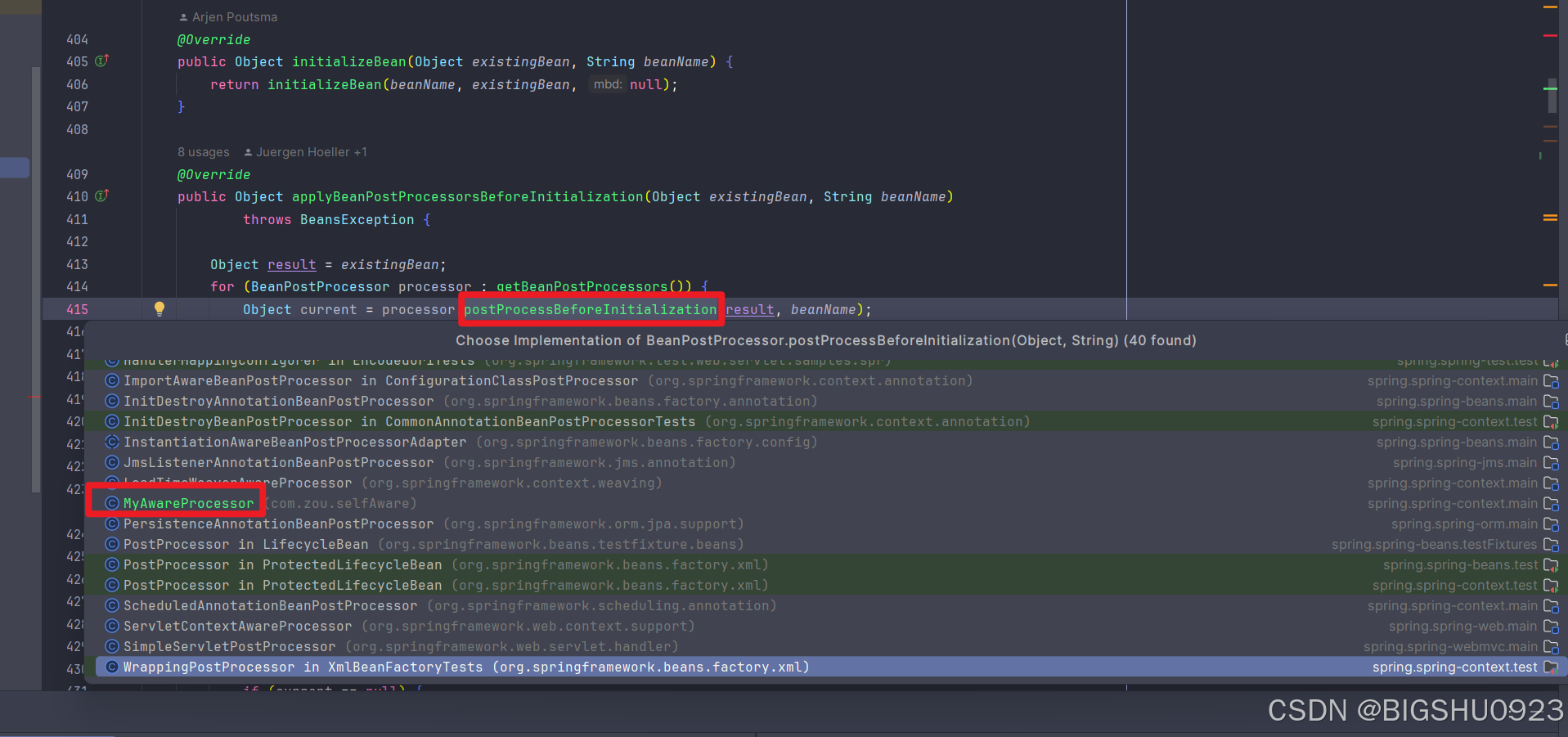
spring源码拓展点3之addBeanPostProcesser
概述 在refresh方法中的prepareBeanFactory方法中,有一个拓展点:addBeanPostProcessor。即通过注入Aware对象从而将容器中的某些值设置到某个bean中。 beanFactory.addBeanPostProcessor(new ApplicationContextAwareProcessor(this));aware接口调用 …...
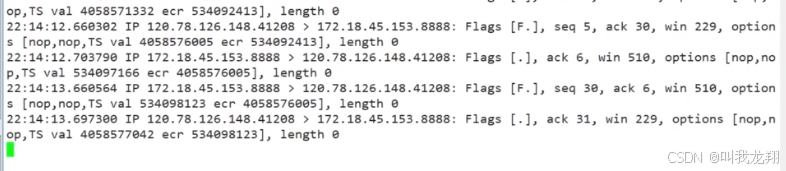
【计网】理解TCP全连接队列与tcpdump抓包
希望是火,失望是烟, 生活就是一边点火,一边冒烟。 理解TCP全连接队列与tcpdump抓包 1 TCP 全连接队列1.1 重谈listen函数1.2 初步理解全连接队列1.3 深入理解全连接队列 2 tcpdump抓包 1 TCP 全连接队列 1.1 重谈listen函数 这里我们使用…...

App无辜躺枪?手把手教你搞定腾讯手机管家误报导致的应用商店下架
当合规应用遭遇误报下架:开发者系统性应对指南运动健康类应用被标记为金融诈骗软件?社交工具因"病毒风险"被各大商店紧急下架?这类看似荒谬的误报事件,正在成为中小开发团队的"无妄之灾"。某知名运动App开发团…...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...

机器学习与深度学习在地球物理勘探中的应用:基于电阻率数据预测极化率模型
1. 项目概述与核心价值在花岗岩这类地质条件复杂的地区搞勘探,最头疼的就是地下情况“看不清”。传统的电阻率(ERT)和激发极化(IP)联合反演,就像用一把刻度模糊的尺子去量一块表面坑洼不平的石头——面对高…...

配置OpenClaw Agent使用Taotoken作为后端模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 配置OpenClaw Agent使用Taotoken作为后端模型提供商 基础教程类,指导希望使用OpenClaw等Agent工具的开发者,…...

DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏
DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PS手柄连接Windows电脑后无法识别而烦恼吗?🎮…...

特定任务需求场景下的过约束并联机构构型设计与控制方法【附代码】
✨ 长期致力于曲面加工、构型综合、运动学和动力学建模、性能评价、多目标优化、滑模控制、鲁棒控制、视觉传感技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (…...

告别枯燥理论!用Unity脚本生命周期与预制体玩转一个“会变身的敌人”
用Unity打造会变身的敌人:脚本生命周期与预制体的实战应用在游戏开发中,敌人AI的行为设计往往是新手开发者最感兴趣也最容易感到困惑的部分。Unity的脚本生命周期和预制体系统为这类需求提供了强大支持,但教科书式的讲解常常让学习者陷入枯燥…...
,锁定雾浓度≤0.38的7个关键阈值参数)
【云雾效果商业级交付标准】:基于Adobe Sensei图像雾度分析报告(N=1,247张MJ生成图),锁定雾浓度≤0.38的7个关键阈值参数
更多请点击: https://intelliparadigm.com 第一章:云雾效果商业级交付标准的定义与行业意义 云雾效果在现代数字体验中已超越视觉装饰范畴,成为空间感知建模、沉浸式交互与品牌情绪传达的核心媒介。商业级交付标准并非仅关注“是否可见雾气”…...

DeepSeek模型微调全链路解析:从数据准备、LoRA配置到推理部署的7大关键步骤
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型微调全链路概览 DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)凭借其开源特性、高性能推理能力与丰富的领域适配性,已成为工业界与学术界微调…...

基于LSTM自编码器的家用电器功耗异常检测系统构建指南
1. 项目概述:从能耗洞察到智能干预我们每天都在和各种家用电器打交道,从清晨唤醒你的咖啡机,到深夜还在默默工作的路由器。你有没有想过,这些看似微不足道的设备,其背后隐藏的能耗模式,其实大有文章&#x…...