逐行讲解transformers中model.generate()源码
目录
- 简介
- 输入程序
- model.generate()
- 输入参数
- 1. 创建生成参数对象 generation_config
- 2. 初始化部分输入参数
- 3. 定义模型输入
- 4. 定义其他模型参数
- 5. 准备 input_ids
- 6. 准备 max_length
- 7. 确定生成模式
- 8. 准备 logits 处理器
- 9. 准备 stopping 处理器
- 10. 执行生成
- self._sample
- 1. 先拿出一些变量
- 2. 根据要求初始化一些变量
- 3. 再设置一些变量
- 4. 正式进行生成
- 备注
简介
本文将使用几个输入案例,详细解读transformers库中
使用环境参考:transformers=4.41.1 torch=2.0.1+cu117
输入程序
本文使用Qwen2.5-1.5B-Instruct模型进行实验,下面程序为输入的一个样例,.generate()中的参数为实验中debug使用的,作为参考这里就不删掉了。
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model ontomodel = AutoModelForCausalLM.from_pretrained("Qwen2.5-1.5B-Instruct",torch_dtype=torch.bfloat16,device_map="cuda"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen2.5-1.5B-Instruct")
tokenizer.padding_side = "left"
text1 = [{"role": "system", "content": "你是一个人工智能助手"},{"role": "user", "content": '介绍一下你自己'}
]
text1 = tokenizer.apply_chat_template(text1,tokenize=False,add_generation_prompt=True
)
text2 = [{"role": "system", "content": "你是一个人工智能助手"},{"role": "user", "content": '写一个谜语'}
]
text2 = tokenizer.apply_chat_template(text2,tokenize=False,add_generation_prompt=True
)
model_inputs = tokenizer([text1, text2], truncation=True, padding=True, return_tensors="pt").to(device)generated_ids = model.generate(# model_inputs.input_ids,# temperature=0.1,# top_k=10,# top_p=0.7,# penalty_alpha=1.3,max_new_tokens=64,# return_dict_in_generate=True,# output_scores=True,# output_logits=True,no_repeat_ngram_size=2,# num_beam_groups=3,# num_beams=6,do_sample=True,# diversity_penalty=0.5,**model_inputs,
)
generated_ids1 = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]response = tokenizer.batch_decode(generated_ids1, skip_special_tokens=True)
print(response)model.generate()
输入参数
进入.generate()中最先涉及的就是输入参数的问题,以下是函数的定义。
def generate(self,inputs: Optional[torch.Tensor] = None,generation_config: Optional[GenerationConfig] = None,logits_processor: Optional[LogitsProcessorList] = None,stopping_criteria: Optional[StoppingCriteriaList] = None,prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor], List[int]]] = None,synced_gpus: Optional[bool] = None,assistant_model: Optional["PreTrainedModel"] = None,streamer: Optional["BaseStreamer"] = None,negative_prompt_ids: Optional[torch.Tensor] = None,negative_prompt_attention_mask: Optional[torch.Tensor] = None,**kwargs,) -> Union[GenerateOutput, torch.LongTensor]:
在代码中可以看到在函数入口显式的定义了很多参数。他们的具体含义如下
inputs:tensor 形式的 token_id,通常先准备文本形式的提示词和输入,使用tokenizer转化为对应 id,这里维度通常为 [batch_size, seq_len]generation_config:一个用 GenerationConfig 类创建的对象,存储着模型生成的超参数,可以提前创建该对象并传入 .generate()logits_processor:高级功能,logits_processor 可以在每个 step 的输出概率计算完成后,对分数进行进一步的干预,改变输出的概率分布,从而影响生成的结果,例如最常见的,重复惩罚,就是使用 logits_processor 完成的。(不懂的话可以看后面如何具体实现的)stopping_criteria:高级功能,允许用户通过 stopping_criteria 自定义生成停止条件(不懂的话可以看后面如何具体实现的)prefix_allowed_tokens_fn:synced_gpus:- DeepSpeed ZeRO Stage-3 多GPU时使用(ZeRO-3包括优化器状态+梯度+权重并行优化,而推理阶段只使用权重并行),此时需要将 synced_gpus 设置成 Ture。.
- 否则,如果一个 GPU 在另一个 GPU 之前完成生成,整个系统就会挂起,因为其余 GPU 尚未从最先完成的 GPU 接收到权重分片。
- transformers>=4.28 在生成时检测到多个 GPU 会自动设置 synced_gpus=True,transformers<4.28 需要手动设置,本文代码环境transformers=4.41.1
assistant_model:高级功能,辅助生成模型,另一个词表完全相同的小模型,有些token使用辅助模型生成更快streamer:流式输出控制器,现在的大模型平台都是一个字一个字显示出来的,这就是流式输出,否则的话会等所有生成完成再显示出来。这个可以自定义流式输出的方式negative_prompt_ids:负面提示,一些前沿研究会用到,不用管negative_prompt_attention_mask:负面提示的 attention_mask**kwargs- 以上输入都太高大上了,只有 inputs 会每次传入,其他的对于常规输出根本用不到(其实 inputs 也可以不用输入,通过
tokenizer()得到model_inputs后,使用**model_inputs方式也可以传入) - 回想一下别人的代码,会看到这里经常传入
temperature=0.7,top_k=20,max_new_tokens=512等参数,都是通过**kwargs传入进来的 - 其实传入的这些都是输入参数
generation_config的属性(可以进入对应类中看一下有哪些属性,from transformers.generation.configuration_utils import GenerationConfig),你可以创建该对象并覆盖某些参数,也可以通过参数形式在调用.generate()时传进来 - 在后面会将传入的这些参数覆盖掉
generation_config中对应的属性
- 以上输入都太高大上了,只有 inputs 会每次传入,其他的对于常规输出根本用不到(其实 inputs 也可以不用输入,通过
1. 创建生成参数对象 generation_config
刚说完**kwargs,正式代码的第一部分就是整合输入的这些参数,如果输入 kwargs 中存在某些字段,则进行替换。
-
先别着急,第一行先验证模型是否与
.generate()兼容,运行了如下代码self._validate_model_class()进入对应函数看到如下代码第一个函数,其实就看第一行 if 判断的结果,.can_generate()放到了下面第二个函数(其实不在一个文件中,以下博文使用同样方式),里面主要判断当前模型有没有重写生成函数,如果重写了就不能执行默认的
.generate()了,即执行了一堆东西弹出异常,下面一堆主要用来提出是哪一种异常,方便调试修改def _validate_model_class(self):"""Confirms that the model class is compatible with generation. If not, raises an exception that points to theright class to use."""# 验证能不能用.generate()生成,应该很少不可以的吧if not self.can_generate():generate_compatible_mappings = [MODEL_FOR_CAUSAL_LM_MAPPING,MODEL_FOR_CAUSAL_IMAGE_MODELING_MAPPING,MODEL_FOR_VISION_2_SEQ_MAPPING,MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING,MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING,]generate_compatible_classes = set()for model_mapping in generate_compatible_mappings:supported_models = model_mapping.get(type(self.config), default=None)if supported_models is not None:generate_compatible_classes.add(supported_models.__name__)exception_message = (f"The current model class ({self.__class__.__name__}) is not compatible with `.generate()`, as ""it doesn't have a language model head.")if generate_compatible_classes:exception_message += f" Please use one of the following classes instead: {generate_compatible_classes}"raise TypeError(exception_message)def can_generate(cls) -> bool:"""Returns whether this model can generate sequences with `.generate()`.Returns:`bool`: Whether this model can generate sequences with `.generate()`."""# Detects whether `prepare_inputs_for_generation` has been overwritten, which is a requirement for generation.# Alternativelly, the model can also have a custom `generate` function.if "GenerationMixin" in str(cls.prepare_inputs_for_generation) and "GenerationMixin" in str(cls.generate):return Falsereturn True -
如果输入了 tokenizer,将其从 kwargs 中取出,这个后面会用于生成停止的判定条件
tokenizer = kwargs.pop("tokenizer", None) -
进入正题,将输入的生成参数覆盖掉默认生成参数,这里只从
**kwargs中取出默认生成参数中有的 key,其余没有的 key 放回 model_kwargs 中generation_config, model_kwargs = self._prepare_generation_config(generation_config, **kwargs)具体实现为如下代码,每一行的具体功能标了注释
里面有几处判断 is_torchdynamo_compiling(),这里说明一下- is_torchdynamo_compiling():判断当前代码是否使用了 TorchDynamo 优化
- TorchDynamo 是一种为 PyTorch 设计的即时(JIT)编译器,通过在运行时拦截 Python 代码、优化它,并编译成高效的机器代码来解决这一问题
def _prepare_generation_config(self, generation_config: Optional[GenerationConfig], **kwargs: Dict) -> Tuple[GenerationConfig, Dict]:# 如果 model.generate() 没有传入 generation_config,就是用 model 自身创建的默认 generation_configif generation_config is None:# 首先声明,这是一个即将弃用的策略# 第一行 is_torchdynamo_compiling() 判断是否用了 TorchDynamo 计算图,只有在使用 TorchDynamo 时它才会设置为 True \# 参考 https://pytorch.org/docs/stable/_modules/torch/compiler.html#is_dynamo_compiling# 以前用户会在模型创建时指定生成参数,与现在的通用推理方式不同,为了适配这种遗留问题,做了三个判断检测是否是这种情况# 注意:这里的 self 是 model 本身,即 Qwen2ForCausalLM 类# 1. generation_config 是从 model config 里创建的,在那里面会设置 _from_model_config=True# 2. generation config 自创建以来没有修改过,即在创建模型时创建的 generation config,这里用哈希值判断有没有修改# 3. 用户必须在 model config 中设置生成参数,这里创建了一个默认参数字典,只要 model config 中有一个参数值与默认值不同就返回 Trueif (not is_torchdynamo_compiling()and self.generation_config._from_model_configand self.generation_config._original_object_hash == hash(self.generation_config)and self.config._has_non_default_generation_parameters()):new_generation_config = GenerationConfig.from_model_config(self.config)if new_generation_config != self.generation_config:warnings.warn("You have modified the pretrained model configuration to control generation. This is a"" deprecated strategy to control generation and will be removed soon, in a future version."" Please use and modify the model generation configuration (see"" https://huggingface.co/docs/transformers/generation_strategies#default-text-generation-configuration )")self.generation_config = new_generation_configgeneration_config = self.generation_config# 如果使用了计算图,则必须传入 generation_config 参数设置,因为 torch.compile 无法使用 copy.deepcopy()if is_torchdynamo_compiling():# 这里检测使用 **kwargs 传入了那些参数,然后弹出异常用于提示model_kwargs = kwargsgenerate_attributes_in_kwargs = [key for key, value in kwargs.items() if getattr(generation_config, key, None) != value]if len(generate_attributes_in_kwargs) > 0:raise ValueError("`torch.compile` exception: all generation configuration attributes must be passed within a "f"`generation_config` instance passed to `generate` (found: {generate_attributes_in_kwargs}).")else:# 深拷贝出来一份(目前还没找到为什么要深拷贝,这里拷贝完进行替换了,上一级函数也替换了,有网友知道可以说一下)generation_config = copy.deepcopy(generation_config)# 这里的 .update() 不是 dict 默认的,是自己实现的,它将 generation_config 里面存在的属性进行替换,不存在的 return 给 model_kwargsmodel_kwargs = generation_config.update(**kwargs)return generation_config, model_kwargs -
这里验证剩余的输入参数,如果 key 输入错误也会在这里被发现
self._validate_model_kwargs(model_kwargs.copy())这里审核了很多东西,防止各种可能的错误,并弹出对应异常来提示
def _validate_model_kwargs(self, model_kwargs: Dict[str, Any]):# 如果模型不支持cache类,但是传入的past_key_values却是cache类,就弹出异常if isinstance(model_kwargs.get("past_key_values", None), Cache) and not self._supports_cache_class:raise ValueError(f"{self.__class__.__name__} does not support an instance of `Cache` as `past_key_values`. Please ""check the model documentation for supported cache formats.")# 如果是encoder-decoder模型,移除不需要的属性if self.config.is_encoder_decoder:for key in ["decoder_input_ids"]:model_kwargs.pop(key, None)unused_model_args = []# 取出模型输入需要用到的所有参数model_args = set(inspect.signature(self.prepare_inputs_for_generation).parameters)if "kwargs" in model_args or "model_kwargs" in model_args:model_args |= set(inspect.signature(self.forward).parameters)# Encoder-Decoder 模型还需要一些额外的编码器参数if self.config.is_encoder_decoder:base_model = getattr(self, self.base_model_prefix, None)# allow encoder kwargsencoder = getattr(self, "encoder", None)# `MusicgenForConditionalGeneration` has `text_encoder` and `audio_encoder`.# Also, it has `base_model_prefix = "encoder_decoder"` but there is no `self.encoder_decoder`# TODO: A better way to handle this.if encoder is None and base_model is not None:encoder = getattr(base_model, "encoder", None)if encoder is not None:encoder_model_args = set(inspect.signature(encoder.forward).parameters)model_args |= encoder_model_args# allow decoder kwargsdecoder = getattr(self, "decoder", None)if decoder is None and base_model is not None:decoder = getattr(base_model, "decoder", None)if decoder is not None:decoder_model_args = set(inspect.signature(decoder.forward).parameters)model_args |= {f"decoder_{x}" for x in decoder_model_args}# allow assistant_encoder_outputs to be passed if we're doing assisted generatingif "assistant_encoder_outputs" in model_kwargs:model_args |= {"assistant_encoder_outputs"}# 如果传入了不需要用到的参数,就弹出异常for key, value in model_kwargs.items():if value is not None and key not in model_args:unused_model_args.append(key)if unused_model_args:raise ValueError(f"The following `model_kwargs` are not used by the model: {unused_model_args} (note: typos in the"" generate arguments will also show up in this list)")
2. 初始化部分输入参数
-
最先验证一下是否用了 DeepSpeed ZeRO Stage-3 多GPU,具体说明在输入参数
synced_gpus里,如果没用 DeepSpeed 或单卡的话不用管,此时synced_gpus=Falseif synced_gpus is None:if is_deepspeed_zero3_enabled() and dist.get_world_size() > 1:synced_gpus = Trueelse:synced_gpus = False -
接下来,初始化 logits 处理器和停止条件(具体说明看输入参数)。以 logits_processor 为例,这是一个 LogitsProcessorList: List 对象,也就是一个继承的list的类,可以往里面放很多单个的处理器,LogitsProcessorList 复写了__call__函数,调用的时候会循环执行自己的单处理器,从而实现 logits 的修改。stopping_criteria 是同样原理。
logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList() stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList() -
检测一些 attention_mask 的事情,主要判断需不需要,以及传没传入,如果没传入后续会自己创建
# inspect.signature(self.forward).parameters.keys() 获取 self.forward 的所有输入参数,这里判断模型是否需要 attention_mask 参数 accepts_attention_mask = "attention_mask" in set(inspect.signature(self.forward).parameters.keys()) # 这里如果通过判断模型有没有 encoder 决定是否需要 attention_mask,与 accepts_attention_mask 为双保险判断 requires_attention_mask = "encoder_outputs" not in model_kwargs # 检测输入 kwargs 中是否传入了 attention_mask kwargs_has_attention_mask = model_kwargs.get("attention_mask", None) is not None
3. 定义模型输入
首先需要拓展一下,从这里初次判断模型的种类,是 encoder-decoder 类型还是 decoder-only 类型,两者有很多不同,例如输入 id 的 key 名称
-
里面验证了几点
- 若传入了 inputs,就不要在 kwargs 中再次定义 input_ids
- 若 inputs 为 None,且 model_kwargs 不包含 input_ids 或 input_ids 也为 None,则创建一个 [batch_sie, 1] 大小的tensor,里面的值都为 bos_token_id
inputs_tensor, model_input_name, model_kwargs = self._prepare_model_inputs(inputs, generation_config.bos_token_id, model_kwargs )输入有三种方式,
inputs(model.generate()的输入参数)、input_ids(放在kwargs中的输入id)、inputs_embeds(通常在encoder-decoder 模型中使用,可以传入编码器输出的embedding),这个部分就是来回确认是否传错def _prepare_model_inputs(self,inputs: Optional[torch.Tensor] = None,bos_token_id: Optional[torch.Tensor] = None,model_kwargs: Optional[Dict[str, torch.Tensor]] = None, ) -> Tuple[torch.Tensor, Optional[str], Dict[str, torch.Tensor]]:"""This function extracts the model-specific `inputs` for generation."""# 1.有一些 encoder-decoder 模型的输入有不同的名称,这里首先确认名称if (self.config.is_encoder_decoderand hasattr(self, "encoder")and self.encoder.main_input_name != self.main_input_name):input_name = self.encoder.main_input_nameelse:input_name = self.main_input_name# 从 model_kwargs 中去掉 input_name: None 的键值对model_kwargs = {k: v for k, v in model_kwargs.items() if v is not None or k != input_name}# 2.这里确保 model.generate() 输入参数中的 inputs 和 kwargs 中的 input_name 只输入一个inputs_kwarg = model_kwargs.pop(input_name, None)if inputs_kwarg is not None and inputs is not None:raise ValueError(f"`inputs`: {inputs}` were passed alongside {input_name} which is not allowed. "f"Make sure to either pass {inputs} or {input_name}=...")elif inputs_kwarg is not None:inputs = inputs_kwarg# 3.如果 input_name != inputs_embeds, 这里确保 input_name 和 inputs_embeds 只输入一个if input_name == "input_ids" and "inputs_embeds" in model_kwargs:# 如果是 decoder-only 模型,先看看模型 .forward() 函数的参数中,是否包含 inputs_embeds,如果不包含就弹出异常if not self.config.is_encoder_decoder:has_inputs_embeds_forwarding = "inputs_embeds" in set(inspect.signature(self.prepare_inputs_for_generation).parameters.keys())if not has_inputs_embeds_forwarding:raise ValueError(f"You passed `inputs_embeds` to `.generate()`, but the model class {self.__class__.__name__} ""doesn't have its forwarding implemented. See the GPT2 implementation for an example ""(https://github.com/huggingface/transformers/pull/21405), and feel free to open a PR with it!")# In this case, `input_ids` is moved to the `model_kwargs`, so a few automations (like the creation of# the attention mask) can rely on the actual model input.model_kwargs["input_ids"] = self._maybe_initialize_input_ids_for_generation(inputs, bos_token_id, model_kwargs=model_kwargs)else:if inputs is not None:raise ValueError("You passed `inputs_embeds` and `input_ids` to `.generate()`. Please pick one.")inputs, input_name = model_kwargs["inputs_embeds"], "inputs_embeds"# 4. 如果 `inputs` 还是 None,尝试用 BOS token 创建 `input_ids`inputs = self._maybe_initialize_input_ids_for_generation(inputs, bos_token_id, model_kwargs)return inputs, input_name, model_kwargs -
一些小操作,取 batch_size 和设备类型
# 取第一个维度 batch_size 大小 batch_size = inputs_tensor.shape[0] # device 类型 device = inputs_tensor.device -
处理 bos_token_id、eos_token_id、pad_token_id、decoder_start_token_id,将其转化为 tensor torch.long 类型
self._prepare_special_tokens(generation_config, kwargs_has_attention_mask, device=device)这里面的具体操作,就是各种安全确认
def _prepare_special_tokens(self,generation_config: GenerationConfig,kwargs_has_attention_mask: Optional[bool] = None,device: Optional[Union[torch.device, str]] = None, ):# 将 token 数字转化成 tensordef _tensor_or_none(token, device=None):if device is None:device = self.deviceif token is None or isinstance(token, torch.Tensor):return tokenreturn torch.tensor(token, device=device, dtype=torch.long)# encoder-decoder 模型在输出时需要 decoder_start_token_id,如果没传入就用 bos_token_idif self.config.is_encoder_decoder:generation_config.decoder_start_token_id = self._get_decoder_start_token_id(generation_config.decoder_start_token_id, generation_config.bos_token_id)# 将这些特殊 id 转化成 tensor 形式bos_token_id = _tensor_or_none(generation_config.bos_token_id, device=device)eos_token_id = _tensor_or_none(generation_config.eos_token_id, device=device)pad_token_id = _tensor_or_none(generation_config.pad_token_id, device=device)decoder_start_token_id = _tensor_or_none(generation_config.decoder_start_token_id, device=device)# 这里讲 eos_token_id 弄成至少一维的格式,用于后面统一方式取数if eos_token_id is not None and eos_token_id.ndim == 0:eos_token_id = eos_token_id.unsqueeze(0)# 如果没设置 pad_token_id,就用 eos_token_id 填充if pad_token_id is None and eos_token_id is not None:# attention mask 和 pad_token_id 如果都不设置就会弹出警告,可能有未知的异常发生if kwargs_has_attention_mask is not None and not kwargs_has_attention_mask:logger.warning("The attention mask and the pad token id were not set. As a consequence, you may observe ""unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.")pad_token_id = eos_token_id[0]logger.warning(f"Setting `pad_token_id` to `eos_token_id`:{pad_token_id} for open-end generation.")# 一些安全检查if self.config.is_encoder_decoder and decoder_start_token_id is None:raise ValueError("`decoder_start_token_id` or `bos_token_id` has to be defined for encoder-decoder generation.")if eos_token_id is not None and (torch.is_floating_point(eos_token_id) or (eos_token_id < 0).any()):logger.warning(f"`eos_token_id` should consist of positive integers, but is {eos_token_id}. Your generation will not ""stop until the maximum length is reached. Depending on other flags, it may even crash.")# 将处理好的特殊 token 传回去generation_config.bos_token_id = bos_token_idgeneration_config.eos_token_id = eos_token_idgeneration_config.pad_token_id = pad_token_idgeneration_config.decoder_start_token_id = decoder_start_token_id -
检测 tokenizer 是否 padding 左对齐
tokenizer 默认对其方式是右对齐,需设置 tokenizer.padding_side = “left”,decoder-only 在批次生成时必须左对齐,具体理论这里不具体讲解
if not self.config.is_encoder_decoder and not is_torchdynamo_compiling():# 检查是否批次大于1,且每个样本最后一个元素是否为 pad_token_id,如果有则认为当前是右对齐,弹出警告if (generation_config.pad_token_id is not Noneand batch_size > 1and len(inputs_tensor.shape) == 2and torch.sum(inputs_tensor[:, -1] == generation_config.pad_token_id) > 0):logger.warning("A decoder-only architecture is being used, but right-padding was detected! For correct ""generation results, please set `padding_side='left'` when initializing the tokenizer.")
4. 定义其他模型参数
- 首先又是模型种类区分,如果是 encoder-decoder 类型并传入了编码器的 embedding 表示,则自动认为这是输入缓存(关于kv cache的原理这里不展开),否则设置接收 generation_config.use_cache(默认是True)
if not self.config.is_encoder_decoder and model_input_name == "inputs_embeds":model_kwargs["use_cache"] = True else:model_kwargs["use_cache"] = generation_config.use_cache - attention_mask的检查,如果没传入就默认创建
# 如果没有传入 attention_mask,则使用各种方式生成 attention_mask if not kwargs_has_attention_mask and requires_attention_mask and accepts_attention_mask:model_kwargs["attention_mask"] = self._prepare_attention_mask_for_generation(inputs_tensor, generation_config.pad_token_id, generation_config.eos_token_id)# 如果是 encoder-decoder 模型,将 encoder_outputs 放到 model_kwargs 中 if self.config.is_encoder_decoder and "encoder_outputs" not in model_kwargs:model_kwargs = self._prepare_encoder_decoder_kwargs_for_generation(inputs_tensor, model_kwargs, model_input_name, generation_config)
5. 准备 input_ids
- 先准备 input_ids,如果是 encoder_decoder 模型,传入了 decoder_input_ids 就直接用,如果没传入就用 decoder_start_token_id 创建一个(这里就不展开了)。如果是 decoder-only 模型,直接取 input_ids
if self.config.is_encoder_decoder:input_ids, model_kwargs = self._prepare_decoder_input_ids_for_generation(batch_size=batch_size,model_input_name=model_input_name,model_kwargs=model_kwargs,decoder_start_token_id=generation_config.decoder_start_token_id,device=inputs_tensor.device,) else:# 之前 _prepare_model_inputs 函数中处理了 model_input_name# if input_name == "input_ids" and "inputs_embeds" in model_kwargs:# inputs, input_name = model_kwargs["inputs_embeds"], "inputs_embeds"# 这种情况下 model_input_name=="inputs_embeds",所以这里再次尝试取出 input_idsinput_ids = inputs_tensor if model_input_name == "input_ids" else model_kwargs.pop("input_ids") - 这里顺便定义了一下流失输出
# 流式输出时使用,即一个字一个字的显示 if streamer is not None:streamer.put(input_ids.cpu())
6. 准备 max_length
-
先能取的取出来,这里解释一下变量
- max_length: 包括输入和输出所有 token 的最大长度
- max_new_tokens: 除输入之外,新生成 token 的最大长度
input_ids_length = input_ids.shape[-1] # 查看是否设置了最大长度和最小长度,这里区分 "max_length" 和 "max_new_tokens" has_default_max_length = kwargs.get("max_length") is None and generation_config.max_length is not None has_default_min_length = kwargs.get("min_length") is None and generation_config.min_length is not None -
然后正式处理这个长度,多种检查保证不会出错
generation_config = self._prepare_generated_length(generation_config=generation_config,has_default_max_length=has_default_max_length,has_default_min_length=has_default_min_length,model_input_name=model_input_name,inputs_tensor=inputs_tensor,input_ids_length=input_ids_length, )def _prepare_generated_length(self,generation_config,has_default_max_length,has_default_min_length,model_input_name,input_ids_length,inputs_tensor, ):# max_length 和 max_new_tokens 只传入一个就行,都传则 max_new_tokens 优先,并弹出警告,min 同理if generation_config.max_new_tokens is not None:if not has_default_max_length and generation_config.max_length is not None:logger.warning(f"Both `max_new_tokens` (={generation_config.max_new_tokens}) and `max_length`(="f"{generation_config.max_length}) seem to have been set. `max_new_tokens` will take precedence. ""Please refer to the documentation for more information. ""(https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)")# max_new_tokens 优先的方式就是用 max_new_tokens + input_ids_length 重新赋值 max_lengthgeneration_config.max_length = generation_config.max_new_tokens + input_ids_length# 到这步如果 model_input_name == "inputs_embeds" 说明同时传入了 `inputs_embeds` 和 `input_ids`# 此时将 max_length 扣除掉 inputs_tensor 的长度elif (model_input_name == "inputs_embeds"and input_ids_length != inputs_tensor.shape[1]and not self.config.is_encoder_decoder):generation_config.max_length -= inputs_tensor.shape[1]# 最小长度相同的做法if generation_config.min_new_tokens is not None:if not has_default_min_length:logger.warning(f"Both `min_new_tokens` (={generation_config.min_new_tokens}) and `min_length`(="f"{generation_config.min_length}) seem to have been set. `min_new_tokens` will take precedence. ""Please refer to the documentation for more information. ""(https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)")generation_config.min_length = generation_config.min_new_tokens + input_ids_lengthelif (model_input_name == "inputs_embeds"and input_ids_length != inputs_tensor.shape[1]and not self.config.is_encoder_decoder):generation_config.min_length = max(generation_config.min_length - inputs_tensor.shape[1], 0)return generation_config -
在这里顺便处理一下 cache 相关
# 不支持同时传递“cache_implementation”(生成时使用的缓存类)和“past_key_values”(缓存对象) if generation_config.cache_implementation is not None and model_kwargs.get("past_key_values") is not None:raise ValueError("Passing both `cache_implementation` (used to initialize certain caches) and `past_key_values` (a ""Cache object) is unsupported. Please use only one of the two.") # 当前版本 transformers NEED_SETUP_CACHE_CLASSES_MAPPING 只有 {"static": StaticCache} elif generation_config.cache_implementation in NEED_SETUP_CACHE_CLASSES_MAPPING:# 这里的 self 是模型类,例如 Qwen2ForCausalLM# 检查模型是否支持 cache_implementation,若不支持则弹出警告if not self._supports_cache_class:raise ValueError("This model does not support the `cache_implementation` argument. Please check the following ""issue: https://github.com/huggingface/transformers/issues/28981.")if generation_config.cache_implementation == "static":# 检查模型是否支持 cache_implementation='static',若不支持则弹出警告if not self._supports_static_cache:raise ValueError("This model does not support `cache_implementation='static'`. Please check the following ""issue: https://github.com/huggingface/transformers/issues/28981")# 如果是 "static",就用这种方式创建一个 Cache 对象model_kwargs["past_key_values"] = self._get_static_cache(batch_size, generation_config.max_length) -
最后又检查了长度相关,反反复复
self._validate_generated_length(generation_config, input_ids_length, has_default_max_length)def _validate_generated_length(self, generation_config, input_ids_length, has_default_max_length):"""Performs validation related to the resulting generated length"""# 1. max_new_tokens 和 max_length 都没设置会弹出警告提醒if has_default_max_length and generation_config.max_new_tokens is None and generation_config.max_length == 20:# 这里的 20 是默认 max_lengthwarnings.warn(f"Using the model-agnostic default `max_length` (={generation_config.max_length}) to control the ""generation length. We recommend setting `max_new_tokens` to control the maximum length of the ""generation.",UserWarning,)# 输入长度直接超过 max_length 弹出异常if input_ids_length >= generation_config.max_length:input_ids_string = "decoder_input_ids" if self.config.is_encoder_decoder else "input_ids"raise ValueError(f"Input length of {input_ids_string} is {input_ids_length}, but `max_length` is set to"f" {generation_config.max_length}. This can lead to unexpected behavior. You should consider"" increasing `max_length` or, better yet, setting `max_new_tokens`.")# 2. 最小长度也是同理,这里做一些提醒信息min_length_error_suffix = (" Generation will stop at the defined maximum length. You should decrease the minimum length and/or ""increase the maximum length.")if has_default_max_length:min_length_error_suffix += (f" Note that `max_length` is set to {generation_config.max_length}, its default value.")# 如果单独设置了 min_length 且 min_length > max_length,当然要弹出异常if generation_config.min_length is not None and generation_config.min_length > generation_config.max_length:warnings.warn(f"Unfeasible length constraints: `min_length` ({generation_config.min_length}) is larger than"f" the maximum possible length ({generation_config.max_length})." + min_length_error_suffix,UserWarning,)# 如果设置了 min_new_tokens,就重新计算 min_length,若大于 max_length 就弹出警告if generation_config.min_new_tokens is not None:min_length = generation_config.min_new_tokens + input_ids_lengthif min_length > generation_config.max_length:warnings.warn(f"Unfeasible length constraints: `min_new_tokens` ({generation_config.min_new_tokens}), when "f"added to the prompt length ({input_ids_length}), is larger than"f" the maximum possible length ({generation_config.max_length})." + min_length_error_suffix,UserWarning,)
7. 确定生成模式
-
先直接确定生成模式,通过一堆条件判断当前属于那种生成模式,各种生成模式的解释单独放到后面的博客中。
generation_mode = generation_config.get_generation_mode(assistant_model)def get_generation_mode(self, assistant_model: Optional["PreTrainedModel"] = None) -> GenerationMode:"""Returns the generation mode triggered by the [`GenerationConfig`] instance.Arg:assistant_model (`PreTrainedModel`, *optional*):The assistant model to be used for assisted generation. If set, the generation mode will beassisted generation.Returns:`GenerationMode`: The generation mode triggered by the instance."""# TODO joao: find out a way of not depending on external fields (e.g. `assistant_model`), then make this a# property and part of the `__repr__`if self.constraints is not None or self.force_words_ids is not None:generation_mode = GenerationMode.CONSTRAINED_BEAM_SEARCHelif self.num_beams == 1:if self.do_sample is False:if (self.top_k is not Noneand self.top_k > 1and self.penalty_alpha is not Noneand self.penalty_alpha > 0):generation_mode = GenerationMode.CONTRASTIVE_SEARCHelse:generation_mode = GenerationMode.GREEDY_SEARCHelse:generation_mode = GenerationMode.SAMPLEelse:if self.num_beam_groups > 1:generation_mode = GenerationMode.GROUP_BEAM_SEARCHelif self.do_sample is True:generation_mode = GenerationMode.BEAM_SAMPLEelse:generation_mode = GenerationMode.BEAM_SEARCH# Assisted generation may extend some generation modesif assistant_model is not None or self.prompt_lookup_num_tokens is not None:if generation_mode in ("greedy_search", "sample"):generation_mode = GenerationMode.ASSISTED_GENERATIONelse:raise ValueError("You've set `assistant_model`, which triggers assisted generate. Currently, assisted generate ""is only supported with Greedy Search and Sample.")return generation_mode -
其他操作,比如流式输出不支持束搜索,输入和模型要放到相同的设备上
if streamer is not None and (generation_config.num_beams > 1):raise ValueError("`streamer` cannot be used with beam search (yet!). Make sure that `num_beams` is set to 1.")if self.device.type != input_ids.device.type:warnings.warn("You are calling .generate() with the `input_ids` being on a device type different"f" than your model's device. `input_ids` is on {input_ids.device.type}, whereas the model"f" is on {self.device.type}. You may experience unexpected behaviors or slower generation."" Please make sure that you have put `input_ids` to the"f" correct device by calling for example input_ids = input_ids.to('{self.device.type}') before"" running `.generate()`.",UserWarning,)
8. 准备 logits 处理器
根据生成参数的不同,将对应的 logits_processor 放到类 LogitsProcessorList 中,LogitsProcessorList 是一个 list 类型的类,在调用的时候会顺序执行里面的每一个子对象。
比如重复惩罚系数不是默认值,就加入重复惩罚类RepetitionPenaltyLogitsProcessor;
最小序列长度不是默认值,就设置最小长度类MinLengthLogitsProcessor
prepared_logits_processor = self._get_logits_processor(generation_config=generation_config,input_ids_seq_length=input_ids_length,encoder_input_ids=inputs_tensor,prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,logits_processor=logits_processor,device=inputs_tensor.device,model_kwargs=model_kwargs,negative_prompt_ids=negative_prompt_ids,negative_prompt_attention_mask=negative_prompt_attention_mask,
)
9. 准备 stopping 处理器
与上面类似的操作,将对应的处理器放到类 StoppingCriteriaList 中,它也是一个list类型的类,在调用的时候会顺序执行里面的每一个子对象。
比如最大长度停止的处理器 MaxLengthCriteria;
eos_token_id停止的处理器 EosTokenCriteria
prepared_stopping_criteria = self._get_stopping_criteria(generation_config=generation_config, stopping_criteria=stopping_criteria, tokenizer=tokenizer, **kwargs
)
10. 执行生成
这里就根据第 7 步创建的生成模式执行不同函数,本文仅以 SAMPLE模式为例。
-
首先加载
logits warper,这里和之前加载的logits processor是类似的,区别在于:logits warper里面是采样时才需要运行的处理器logits processor是通用的处理器,每种生成模式都需要用到的
prepared_logits_warper = (self._get_logits_warper(generation_config) if generation_config.do_sample else None ) -
为了生成结果的多样性,生成参数中的
generation_config.num_return_sequences可以控制一条输入要有几个输出,如果不止一个输出,就需要将这个批次的数据赋值出来几份,同步进行生成。input_ids, model_kwargs = self._expand_inputs_for_generation(input_ids=input_ids,expand_size=generation_config.num_return_sequences,is_encoder_decoder=self.config.is_encoder_decoder,**model_kwargs, )def _expand_inputs_for_generation(expand_size: int = 1,is_encoder_decoder: bool = False,input_ids: Optional[torch.LongTensor] = None,**model_kwargs, ) -> Tuple[torch.LongTensor, Dict[str, Any]]:def _expand_dict_for_generation(dict_to_expand):for key in dict_to_expand:if (key != "cache_position"and dict_to_expand[key] is not Noneand isinstance(dict_to_expand[key], torch.Tensor)):dict_to_expand[key] = dict_to_expand[key].repeat_interleave(expand_size, dim=0)return dict_to_expand# 将 input_ids 复制出来几份if input_ids is not None:input_ids = input_ids.repeat_interleave(expand_size, dim=0)# 将 model_kwargs 中的 attention mask 也复制出来几份model_kwargs = _expand_dict_for_generation(model_kwargs)# 如果是 encoder-decoder 模型,则将 encoder_outputs 也复制出来几份if is_encoder_decoder:if model_kwargs.get("encoder_outputs") is None:raise ValueError("If `is_encoder_decoder` is True, make sure that `encoder_outputs` is defined.")model_kwargs["encoder_outputs"] = _expand_dict_for_generation(model_kwargs["encoder_outputs"])return input_ids, model_kwargs -
接下来就进入正式的生成和采样了
result = self._sample(input_ids,logits_processor=prepared_logits_processor,logits_warper=prepared_logits_warper,stopping_criteria=prepared_stopping_criteria,generation_config=generation_config,synced_gpus=synced_gpus,streamer=streamer,**model_kwargs, )
self._sample
输入参数就不说了,都是之前处理过的传进来
1. 先拿出一些变量
pad_token_id = generation_config.pad_token_id # pad 值
output_attentions = generation_config.output_attentions # 是否输出 attentions
output_hidden_states = generation_config.output_hidden_states # 是否输出 hidden states
output_scores = generation_config.output_scores # 是否输出 scores
output_logits = generation_config.output_logits # 是否输出 logits
return_dict_in_generate = generation_config.return_dict_in_generate # 是否返回 dict
has_eos_stopping_criteria = any(hasattr(criteria, "eos_token_id") for criteria in stopping_criteria) # 检测有没有 eos 停止条件
do_sample = generation_config.do_sample # 是否使用采样
# 如果设置 do_sample,要求 logits_warper 必须是特定的数据类型
if do_sample is True and not isinstance(logits_warper, LogitsProcessorList):raise ValueError("`do_sample` is set to `True`, `logits_warper` must be a `LogitsProcessorList` instance (it is "f"{logits_warper}).")
2. 根据要求初始化一些变量
如果想输出下面中间变量值,必须设置 return_dict_in_generate=True,然后想输出哪个就指定哪个为True
# 这里先将对应值初始化为元组类型
scores = () if (return_dict_in_generate and output_scores) else None
raw_logits = () if (return_dict_in_generate and output_logits) else None
decoder_attentions = () if (return_dict_in_generate and output_attentions) else None
cross_attentions = () if (return_dict_in_generate and output_attentions) else None
decoder_hidden_states = () if (return_dict_in_generate and output_hidden_states) else None# 如果是 encoder-decoder 模型,从 model_kwargs 里取出 encoder 的 attentions 和 hidden states
if return_dict_in_generate and self.config.is_encoder_decoder:encoder_attentions = model_kwargs["encoder_outputs"].get("attentions") if output_attentions else Noneencoder_hidden_states = (model_kwargs["encoder_outputs"].get("hidden_states") if output_hidden_states else None)
3. 再设置一些变量
记录有哪些序列完成生成了,以及计算一下缓存或者输入序列的长度是多少,确定生成第一个字符的位置编码索引。
batch_size = input_ids.shape[0]
# 是否 batch 内所有序列都生成完成的判断标志位
this_peer_finished = False
# 创建一个跟踪每个序列是否完成生成的变量
unfinished_sequences = torch.ones(batch_size, dtype=torch.long, device=input_ids.device)
# 初始化位置序号,如果用了 cache,就从 cache 里取,没有就根据 input_ids 长度创建
# prefilling 阶段确定输入的长度
model_kwargs = self._get_initial_cache_position(input_ids, model_kwargs)def _get_initial_cache_position(self, input_ids, model_kwargs):if not model_kwargs.get("use_cache", True):model_kwargs["cache_position"] = Nonereturn model_kwargspast_length = 0# 如果输入了 past_key_values ,则根据 past_key_values 确定缓存序列的长度if "past_key_values" in model_kwargs:if isinstance(model_kwargs["past_key_values"], Cache):past_length = model_kwargs["past_key_values"].get_seq_length()else:past_length = model_kwargs["past_key_values"][0][0].shape[2]# 如果输入 inputs_embeds 则根据这个确定if "inputs_embeds" in model_kwargs:cur_len = model_kwargs["inputs_embeds"].shape[1]else:# 都没有就根据 input_ids 确定cur_len = input_ids.shape[-1]# 创建输入序列的位置索引model_kwargs["cache_position"] = torch.arange(past_length, cur_len, device=input_ids.device)return model_kwargs
4. 正式进行生成
首先进入一个循环来生成,知道所有序列都生成完成。这个函数可以只关注this_peer_finished变量,如果都完成会变成True,从而退出循环。
while self._has_unfinished_sequences(this_peer_finished, synced_gpus, device=input_ids.device):
然后开始准备模型的输入,这里的prepare_inputs_for_generation函数是模型内部的,本文是在 qwen2\modeling_qwen2.py中。
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)def prepare_inputs_for_generation(self, input_ids, past_key_values=None, attention_mask=None, inputs_embeds=None, **kwargs
):# 忽略被 kv cache 覆盖的 tokenif past_key_values is not None:if isinstance(past_key_values, Cache):cache_length = past_key_values.get_seq_length()past_length = past_key_values.seen_tokensmax_cache_length = past_key_values.get_max_length()else:cache_length = past_length = past_key_values[0][0].shape[2]max_cache_length = None# 特殊情况,如果 atten mask 的长度小于 input_ids,就将没有 mask 的地方一起输入进去,常见于 encoder-decoder 模型生成第一个字符的时候if attention_mask is not None and attention_mask.shape[1] > input_ids.shape[1]:input_ids = input_ids[:, -(attention_mask.shape[1] - past_length) :]# 在每次新生成token的时候都会触发,input_ids 只存储最新的一个token,配合 kv cache 快速生成# 这里每次进来的 input_ids 是全部已有的 token(输入+输出),截取最新的一个放到了 model_inputs 中,不影响外层的 input_ids 值elif past_length < input_ids.shape[1]:input_ids = input_ids[:, past_length:]# 如果超出了 kv cache 的最大长度,就丢掉最远的部分if (max_cache_length is not Noneand attention_mask is not Noneand cache_length + input_ids.shape[1] > max_cache_length):attention_mask = attention_mask[:, -max_cache_length:]position_ids = kwargs.get("position_ids", None)# 如果输入了 attention mask 但没有输入 position ids,则根据 atten mask 创建if attention_mask is not None and position_ids is None:# 动态创建position_ids以进行批量生成# .cumsum(-1) 沿着 atten mask 最后一个维度进行累加求和,生成0,1,2,3...# 如果 atten mask 前几个是0,则生成是 -1,-1,-1,0,1,2,3...position_ids = attention_mask.long().cumsum(-1) - 1# 将 atten mask 等于0的地方填充为1(原来为-1),用于处理padding部分的位置编码# 由于是左填充,所以都是最左边的位置编码为1position_ids.masked_fill_(attention_mask == 0, 1)# 每次生成 position_ids 也只取最新的一个if past_key_values:position_ids = position_ids[:, -input_ids.shape[1] :]# inputs_embeds 只在生成第一个 token 时使用if inputs_embeds is not None and past_key_values is None:model_inputs = {"inputs_embeds": inputs_embeds}else:model_inputs = {"input_ids": input_ids}# 都输入给 model_inputs 返回model_inputs.update({"position_ids": position_ids,"past_key_values": past_key_values,"use_cache": kwargs.get("use_cache"),"attention_mask": attention_mask,})return model_inputs
然后运行模型,生成下一个 token,生成之后取出最新生成的token,经过 logits_processor和logits_warper采样。
# 进入模型内部生成下一个token
outputs = self(**model_inputs,return_dict=True,output_attentions=output_attentions,output_hidden_states=output_hidden_states,
)if synced_gpus and this_peer_finished:continue # don't waste resources running the code we don't need# 取出最后一个token,.logits维度为(batch_size, seq_len, vocab_size)
next_token_logits = outputs.logits[:, -1, :]# 经过前面的处理器进行分数调整
next_token_scores = logits_processor(input_ids, next_token_logits)
if do_sample:next_token_scores = logits_warper(input_ids, next_token_scores)
如果需要输出某些变量,这里进行处理,将最新结果存储进去
if return_dict_in_generate:if output_scores:scores += (next_token_scores,)if output_logits:raw_logits += (next_token_logits,)if output_attentions:decoder_attentions += ((outputs.decoder_attentions,) if self.config.is_encoder_decoder else (outputs.attentions,))if self.config.is_encoder_decoder:cross_attentions += (outputs.cross_attentions,)if output_hidden_states:decoder_hidden_states += ((outputs.decoder_hidden_states,)if self.config.is_encoder_decoderelse (outputs.hidden_states,))
如果进行采样,先将原始得分概率化,然后从候选 token 中,按给定概率随机采样一个 token;
如果贪婪搜索,则直接选取原始得分最大的那个 token。
if do_sample:probs = nn.functional.softmax(next_token_scores, dim=-1)next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
else:next_tokens = torch.argmax(next_token_scores, dim=-1)
再更新一些变量
# 如果生成完成了,就将新生成的 token 替换成 pad_token_id,提醒后面这个已经生成完成
if has_eos_stopping_criteria:next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)# update generated ids, model inputs, and length for next step
# 输入的 input_ids 和 model_kwargs 都要更新
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
# 流式输出将最新生成的 token 输出到 streamer
if streamer is not None:streamer.put(next_tokens.cpu())model_kwargs = self._update_model_kwargs_for_generation(outputs,model_kwargs,is_encoder_decoder=self.config.is_encoder_decoder,
)
最后判断有没有生成完毕,stopping_criteria是之前加载的结束生成的处理器,这里返回的数量是序列,对应每个序列是否生成完毕,例如[True, False],取反之后跟 unfinished_sequences 与操作,得到最终每个序列是否生成完毕。
this_peer_finished 只在所有序列都生成完毕才为 True
unfinished_sequences = unfinished_sequences & ~stopping_criteria(input_ids, scores)
this_peer_finished = unfinished_sequences.max() == 0
最后,先结束流失输出,在处理需要返回的一些中间变量,返回的结果使用类似GenerateDecoderOnlyOutput的类,它继承了ModelOutput(一个模型输出结果的基类),除了取数时可以用索引、切片或字符串(类似字典的 key),其他时候与python 的字典无异。
if streamer is not None:streamer.end()if return_dict_in_generate:if self.config.is_encoder_decoder:return GenerateEncoderDecoderOutput(sequences=input_ids,scores=scores,logits=raw_logits,encoder_attentions=encoder_attentions,encoder_hidden_states=encoder_hidden_states,decoder_attentions=decoder_attentions,cross_attentions=cross_attentions,decoder_hidden_states=decoder_hidden_states,past_key_values=model_kwargs.get("past_key_values"),)else:return GenerateDecoderOnlyOutput(sequences=input_ids,scores=scores,logits=raw_logits,attentions=decoder_attentions,hidden_states=decoder_hidden_states,past_key_values=model_kwargs.get("past_key_values"),)
else:return input_ids
到这里就全部结束啦!!!
备注
本篇文章是拆解 transformers 源码逐行解析的,由于博文太长难免有错误或者遗漏(博文创作周期很长,很可能某部分当时懒得写了)。如有不对也请指出,我及时改正,谢谢。
相关文章:
逐行讲解transformers中model.generate()源码
目录 简介输入程序model.generate()输入参数1. 创建生成参数对象 generation_config2. 初始化部分输入参数3. 定义模型输入4. 定义其他模型参数5. 准备 input_ids6. 准备 max_length7. 确定生成模式8. 准备 logits 处理器9. 准备 stopping 处理器10. 执行生成 self._sample1. 先…...

小白对时序数据库的理解
一、什么是时序数据库? 时序数据库(Time Series Database,TSDB)是一种专门用于存储、处理和分析时间序列数据的数据库管理系统。时间序列数据是按时间顺序记录的数据,通常由各种设备和传感器生成,例如智慧…...
打开游戏提示丢失(或找不到)XINPUT1_3.DLL的多种解决办法
xinput1_3.dll是一个动态链接库(DLL)文件,它在Windows操作系统中扮演着重要的角色。该文件作为系统库文件,通常存放于C:\Windows\System32目录下(对于32位系统)或C:\Windows\SysWOW64目录下(对于…...

netty的网络IO模型
参考: 聊聊Netty那些事儿之从内核角度看IO模型...

电子木鱼小游戏小程序源码系统 带完整的安装代码包以及搭建部署教程
系统概述 在快节奏的生活中,人们越来越注重内心的平静与放松。电子木鱼小游戏小程序正是基于这一需求而诞生的,它将传统的木鱼文化与现代科技相结合,为用户提供了一个简单、方便、有趣的冥想与放松工具。通过敲击屏幕上的虚拟木鱼࿰…...

支付域——交易系统设计
摘要 交易是业务流转的基础,其中交易系统和订单系统的设计至关重要。交易系统需确保安全、高效与稳定。在设计时,要考虑支付方式的多样性及兼容性,保障资金流转的准确与安全。同时,应具备良好的风险控制机制,防范欺诈等风险。订单系统则负责记录和管理交易的全过程。需清…...

IBus 和 Fcitx 框架下的rime输入法引擎
Rime 输入法引擎 Rime(中州韵输入法引擎):这是一个跨平台的输入法引擎,支持多种输入法方案,如拼音、五笔、注音等。Rime本身不提供前端界面,它需要与输入法框架(如IBus或Fcitx)结合…...
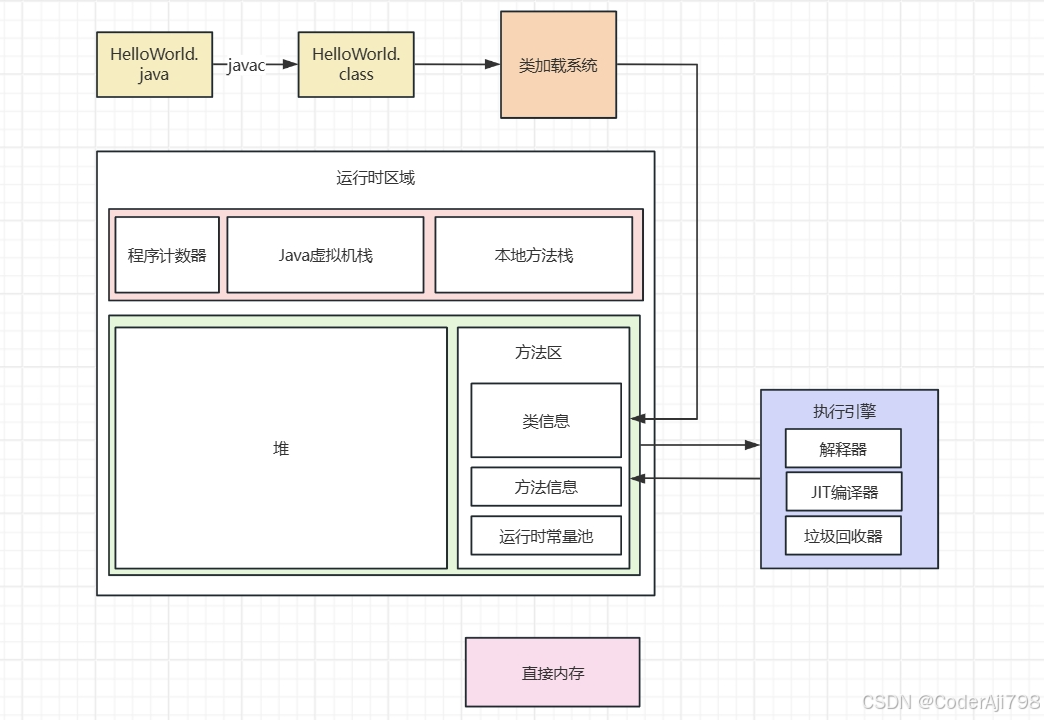
Java基础-JVM
JVM构成部分 类加载系统 类加载子系统的作用是将磁盘中的.class文件加载到内存当中。工作过程如下: 加载:通过类全路径名获取二进制字节流;将这个二进制字节流代表的数存储构转化为方法区运行时数据结构;在内存生成一个代表该类的…...

集成学习:投票法、提升法、袋装法
集成学习:投票法、提升法、袋装法 目录 🗳️ 投票法 (Voting)🚀 提升法 (Boosting)🛍️ 袋装法 (Bagging) 1. 🗳️ 投票法 (Voting) 投票法是一种强大的集成学习策略,它通过将多个模型的预测结果进行组合…...

波浪理论、江恩理论、价值投资的结合
结合波浪理论、江恩理论和价值投资,需要理解这三种方法的核心原理和应用方式。下面详细解析如何将它们融合在一起,形成一个更全面的投资策略: 1. 基本概述 波浪理论:由艾略特提出,通过分析市场波动的五个上升浪和三个…...
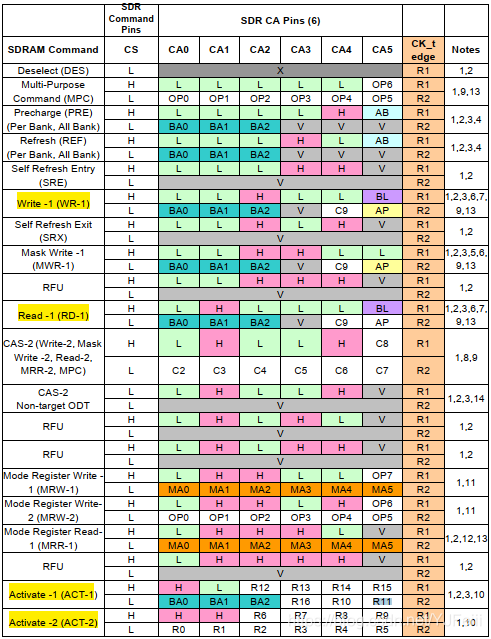
LRDDR4芯片学习(三)——命令和时序
ddr command: activate commandrefresh commandprecharge commandwrite/read commandburst write/read commandMRR/MRW command 一、Activate命令 在读写命令之前,必须要发送Activate命令,由ACTIVATE-1、ACTIVATE-2命令组成。ACTIVATE命令中包含了BA[…...

【趣学C语言和数据结构100例】
【趣学C语言和数据结构100例】 问题描述 61.假定采用带头结点的单链表保存单词,当两个单词有相同的后缀时,可共享相同的后缀存储空间,例如,loading 和 being 的存储映像如下图所示,设 strl 和 str2 分别指向两个单词所在单链表的头结点,链表结点结构为 data next。请设计…...
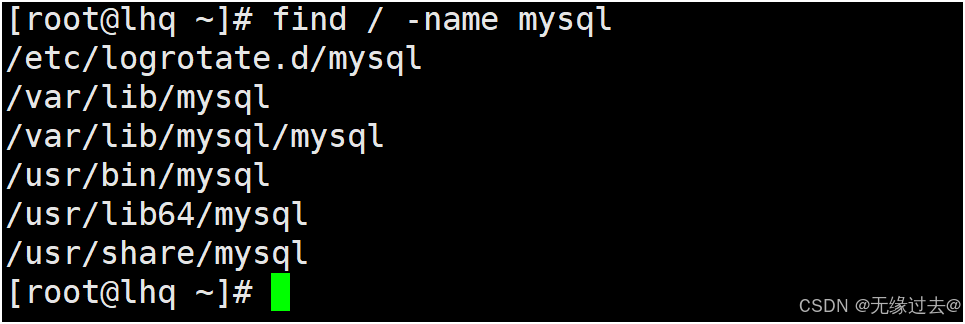
linux卸载数据库(最为完整的卸载方式)
1.首先检查是否安装了MySQL组件 我们可以看到有五个与mysql相关的组件 2.卸载前关闭MySQL服务 systemctl stop mysqld systemctl status mysqld 3.收集MySQL对应的文件夹信息 whereis mysql 4.卸载删除MySQL各类组件 #例如 rpm -ev --nodeps mysql-community-libs-5.7.…...
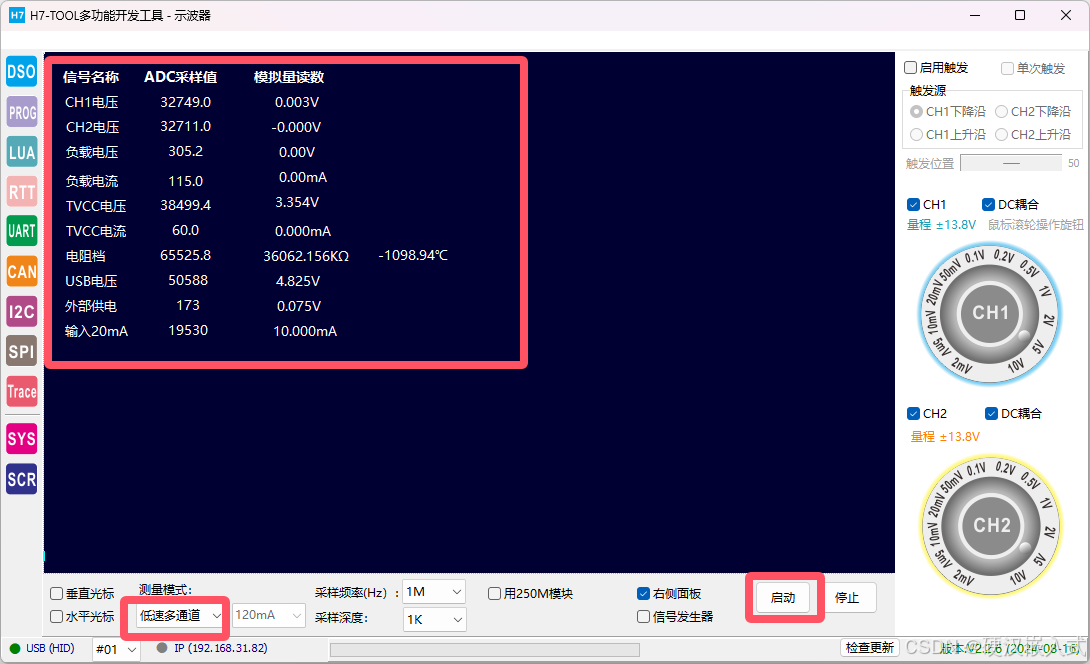
H7-TOOL的LUA小程序教程第15期:电压,电流,NTC热敏电阻以及4-20mA输入(2024-10-21,已经发布)
LUA脚本的好处是用户可以根据自己注册的一批API(当前TOOL已经提供了几百个函数供大家使用),实现各种小程序,不再限制Flash里面已经下载的程序,就跟手机安装APP差不多,所以在H7-TOOL里面被广泛使用ÿ…...

使用梧桐数据库进行销售趋势分析和预测
在当今竞争激烈的商业环境中,企业需要深入了解销售数据,以便做出明智的决策。销售趋势分析和预测是帮助企业把握市场动态、优化库存管理、制定营销策略的重要工具。本文将介绍如何使用SQL来创建销售数据库的表结构,插入示例数据,并…...
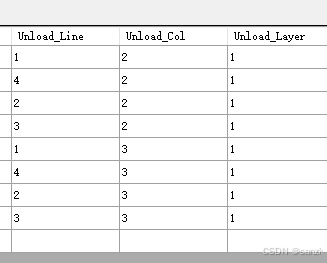
SQLITE排序
最终实现的效果:先查询第一层2列开始的1、4、2、3排,再查询第三列、四列...,然后第二层... 入库 排序优先级:层>列>排(1>2,4>3) 最终排的优先级 1>4>2>3 ORDER BY rack.rackLayer,rack.rackColumn, CASE rack.rackRowW…...

python的文件操作
文件操作 1.打开文件 2.读取文件内容 3.写入文件内容 4.关闭文件 要打开文件,可以使用open()函数并指定文件路径和模式。 file open("example.txt", "r") # 打开了一个名为"example.txt"的文件,并将其赋值给变量file。第…...

群晖通过 Docker 安装 MySQL
1. 打开 Docker 应用,并在注册表搜索 MySQL 2. 下载 MySQL 镜像,并选择版本 3. 在 Docker 文件夹中创建 MySQL,并创建子文件夹 4. 设置权限 5. 选择 MySQL 映像运行,创建容器 6. 配置 MySQL 容器 6.1 使用高权限执行容器 6.2 启…...

同程旅行面经
前言 一面 2024-10-11 实习项目架构,技术栈是怎么样的,自己实现了哪些功能?(文件上传,更新记录记忆,动态表格)写了多少行代码?(2~3k)项目有上线了吗&#x…...
)
【贪心算法】(第八篇)
目录 分发饼⼲(easy) 题目解析 讲解算法原理 编写代码 最优除法(medium) 题目解析 讲解算法原理 编写代码 分发饼⼲(easy) 题目解析 1.题目链接:. - 力扣(LeetCode…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

浅谈不同二分算法的查找情况
二分算法原理比较简单,但是实际的算法模板却有很多,这一切都源于二分查找问题中的复杂情况和二分算法的边界处理,以下是博主对一些二分算法查找的情况分析。 需要说明的是,以下二分算法都是基于有序序列为升序有序的情况…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

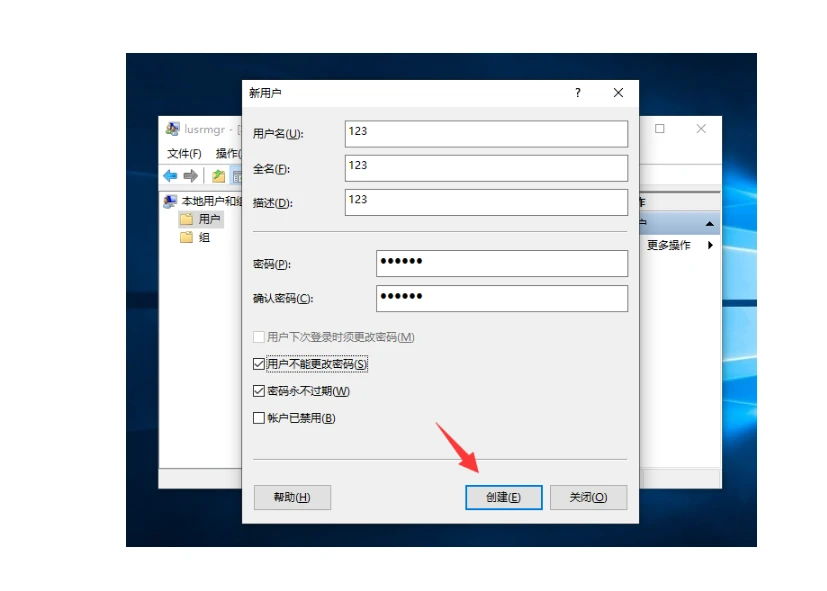
MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...
AI语音助手的Python实现
引言 语音助手(如小爱同学、Siri)通过语音识别、自然语言处理(NLP)和语音合成技术,为用户提供直观、高效的交互体验。随着人工智能的普及,Python开发者可以利用开源库和AI模型,快速构建自定义语音助手。本文由浅入深,详细介绍如何使用Python开发AI语音助手,涵盖基础功…...

nnUNet V2修改网络——暴力替换网络为UNet++
更换前,要用nnUNet V2跑通所用数据集,证明nnUNet V2、数据集、运行环境等没有问题 阅读nnU-Net V2 的 U-Net结构,初步了解要修改的网络,知己知彼,修改起来才能游刃有余。 U-Net存在两个局限,一是网络的最佳深度因应用场景而异,这取决于任务的难度和可用于训练的标注数…...