Java全栈经典面试题剖析5】JavaSE高级 -- 集合
目录
面试题3.18 Java中有多少种数据结构,分别是什么?
面试题3.19 List、Set和Map的区别?
面试题3.20 List遍历方式有多少种
面试题3.21 Arraylist,Vector和Linkedlist 的区别
面试题3.22 Collection和Collections的区别
面试题3.23 Comparable接口用法 或者 comparable和comparator接口的用途? 列出他们的区别? 另一种问法,想实现些比较或排序,或统计元素的个数,要用到比较器。
面试题3.24 Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用==还是equals()? 它们有何区别?
面试题3.25 Map怎么遍历? 怎么遍历一个map?写一下
面试题3.26 怎么获取Map所有的key,所有的value
面试题3.27 HashMap与Hashtable的区别
面试题3.28 HashMap HashSet的底层实现
面试题3.18 Java中有多少种数据结构,分别是什么?
【技术难度: 3 出现频率:3 】
栈:元素是先进后出,后进先出。
队列:元素存储是排列有序的,一定保证先进的先出,后进的后出。
数组:静态数组,指定类型,固定长度,元素存储地址是连续的。
向量:动态数组,可以存储任何类型元素,动态长度,元素存储地址是连续的。
树:元素以树形结构存储,只有一个根节点。
List:是列表,有下标值,存储元素可以重复,遍历元素是有序的。
Set:是散列集(或称哈希集),无下标值,存储元素不可重复,遍历元素是无序的。
Map:是以键值对存储,一个key一个value,key不可以重复,value可以重复。
面试题3.19 List、Set和Map的区别?
【技术难度: 2 出现频率:2 】
1.List和Set是Collection的子接口,map不是;
2.List的底层是数组或链表实现,Set的底层是map,而map的底层是哈希表或红黑树。
3.List和Set以单个元素的方式存储数据,但map是键值对的方式;
4.List是有序可重复的,Set是无序不可重复的;map中hashMap无序,LinkedHashMap有序,TreeMap排序,而且key不重复,value可重复;
5.List和Set可直接使用itertator来进行遍历,map需要先获取keySet或entrySet,通过它们来遍历。
面试题3.20 List遍历方式有多少种
【技术难度: 2 出现频率:2 】
1.下标遍历;
2.Iterator遍历;
通过hasNext()方法检查序列中是否还有更多元素,以及通过next()方法获取序列中的下一个元素。
// 使用while循环遍历List集合 while (iterator.hasNext()) { // 获取下一个元素 String element = iterator.next(); // 打印元素 System.out.println(element); } 3.foreach遍历(最快)。List类的forEach() + Lambda表达式。
public class Main { public static void main(String[] args) { List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David"); // 使用forEach() + Lambda表达式遍历List names.forEach(name -> System.out.println(name)); }
}面试题3.21 Arraylist,Vector和Linkedlist 的区别
【技术难度: 2 出现频率:2 】
它们都是List接口的实现类。
ArrayList:
1.底层是数组,查询快增删慢,线程不安全,效率高;
2.数组初始长度10,存满扩容,扩到原数组1.5倍。
Vector:
1.与ArrayList类似,底层是数组,查询快增删慢,线程安全,效率更低(synchronized);
LinkedList:
1.底层是链表,查询慢增删快,线程不安全,效率高;
2.链表无扩容机制,理论上可以无限扩容,就是直接修改节点之间关联。
面试题3.22 Collection和Collections的区别
【技术难度: 2 出现频率:2 】
1.Collection是集合类的上级接口,继承于他的接口主要有Set和List;
2.Collections是针对集合的一个工具类,提供一系列静态方法实现对各种集合的搜索(二分查找)、排序、线程安全化等操作。
面试题3.23 Comparable接口用法 或者 comparable和comparator接口的用途? 列出他们的区别? 另一种问法,想实现些比较或排序,或统计元素的个数,要用到比较器。
【技术难度: 2 出现频率: 1 】
第一层:
这两个接口一般用来实现集合内排序,Comparator相对于Comparable更加灵活,耦合度更低,Comparable不但用于排序还可用与比较本类两个对象的大小。
第二层:
Comparable接口和他的compareTo()方法
Comparator接口和它的compare()方法
Comparable接口里面有个compareTo()接口方法,当一个类的对象需要比较的时候,该类需要实现Comparable接口和他的compareTo()方法,当调用集合排序方法时,就会调用该类对象的compareTo()方法来实现对象的比较。
Comparator接口是一个比较器接口,一般定义一个匿名类实现该接口和它的compare()方法,并创建对象,传入集合排序方法中。
第三层:
Comparable接口:
public class Person implements Comparable<Person> { private String name; private int age; // 构造函数、getter和setter方法省略 @Override public int compareTo(Person other) { return Integer.compare(this.age, other.age); // 按年龄排序 } public static void main(String[] args) { List<Person> people = new ArrayList<>(); // 添加Person对象到列表中 people.add(new Person("Alice", 30)); people.add(new Person("Bob", 25)); people.add(new Person("Charlie", 35)); Collections.sort(people); // 按年龄排序 // 输出排序后的列表 for (Person person : people) { System.out.println(person.getName() + " " + person.getAge()); } }
}Comparator接口:
public class Person { private String name; private int age; // 构造函数、getter和setter方法省略
} class AgeComparator implements Comparator<Person> { @Override public int compare(Person p1, Person p2) { return Integer.compare(p1.getAge(), p2.getAge()); // 按年龄排序 }
} public class Main { public static void main(String[] args) { List<Person> people = new ArrayList<>(); // 添加Person对象到列表中 people.add(new Person("Alice", 30)); people.add(new Person("Bob", 25)); people.add(new Person("Charlie", 35)); Collections.sort(people, new AgeComparator()); // 按年龄排序,使用Comparator // 输出排序后的列表 for (Person person : people) { System.out.println(person.getName() + " " + person.getAge()); } }
}面试题3.24 Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用==还是equals()? 它们有何区别?
【技术难度: 2 出现频率: 2 】
1.Set里的元素是不能重复的;因为无论是HashSet还是TreeSet,其底层数据结构都不允许元素重复。
2.元素重复与否是使用equals()方法进行判断的;
3.==比较两个对象是比较对象的内存地址,equals()默认是使用==判断2个对象的内存地址是否相等,重写以后按照自定义规则比较2个对象。
面试题3.25 Map怎么遍历? 怎么遍历一个map?写一下
【技术难度: 2 出现频率:2 】
1.先调用map.keySet()方法获取所有的key,再通过这些key获取对应的value;
Map<String,Integer> map = new HashMap<>();
for(String key :map.keySet()){System.out.println(key + " - " + map.get(key));
}2.先调用map.entrySet()方法获取所有的entry键值对对象,再从每个entry中取出key和value。
Map<String,Integer> map = new HashMap<>();
for (Map.Entry<String,Integer> entry :map.entrySet()) {System.out.println(entry.getKey() + " - " + entry.getValue());
}面试题3.26 怎么获取Map所有的key,所有的value
【技术难度: 2 出现频率:2 】
1.Map调用keySet()方法获取所有的key值,是一个Set集合。
2.Map调用values()方法获取所有的value值,是一个Collection集合。
3.调用map.entrySet()方法获取所有的entry键值对对象,getKey() 和 getValue()。
面试题3.27 HashMap与Hashtable的区别
【技术难度:2 出现频率:2 】
1. 继承的父类不同。HashMap:继承自AbstractMap类,实现了Map接口。Hashtable:继承自Dictionary类,同样实现了Map接口。
2. HashMap不是线程安全的,Hashtable是安全的 (通过synchronized同步方法来实现,低效);
3. HashMap的key和value都允许null值,Hashtable的key和value都不允许null值(如果存入null会抛出nullpointerException);
4. HashMap数组初始长度16,扩容原数组的2倍,Hashtable数组初始长度11,扩容原数组的2倍 + 1。
5.计算hash值的方法
- HashMap:为了提高计算效率,HashMap将哈希表的大小固定为2的幂,并对key的hashCode()返回值进行二次hash(对哈希表的大小进行取模运算),以获得更好的散列效果。
- Hashtable:直接使用key的hashCode()返回值对哈希表的大小进行取模运算来计算hash值。



面试题3.28 HashMap HashSet的底层实现
【技术难度: 2 出现频率:3 】
底层数据结构:
HashSet底层就是HashMap。HashMap底层是哈希表数据结构,jdk1.8开始,哈希表等于数组加链表加红黑树(二叉树的一种),数组的初始长度16,加载因子0.75,扩容到原数组的2倍。当单向链表的节点个数大于8并且数组长度大于64时,链表转红黑树,当节点的个数小于6,红黑树转回链表。
插入函数:
调用map.put()方法时,会调用key的hashCode()方法计算哈希值,这个哈希值会经过再次计算得出最终哈希值,然后根据这个哈希值计算数组的存储下标,此时会有两种情况:
1.如果数组存储下标对应的空间没有值,key和value直接存入;Jdk1.8后在链表末尾插入。
2.如果数组存储下标对应的空间有值(单向链表或红黑树),就继续调用key的equals()方法和其中每个节点的key比较,若返回true,后面的value覆盖前面的value,若直到最后一个都是返回false,key和value存入。
------------------------END-------------------------
才疏学浅,谬误难免,欢迎各位批评指正。
相关文章:
Java全栈经典面试题剖析5】JavaSE高级 -- 集合
目录 面试题3.18 Java中有多少种数据结构,分别是什么? 面试题3.19 List、Set和Map的区别? 面试题3.20 List遍历方式有多少种 面试题3.21 Arraylist,Vector和Linkedlist 的区别 面试题3.22 Collection和Collections的区别 面试…...

python中如何获取对象信息
目录 一、获取对象类型 二、使用isinstance()函数 三、使用dir()函数 四、使用对象的__dict__属性(适用于大多数自定义对象) 五、使用文档字符串(__doc__属性)获取对象的文档信息 一、获取对象类型 使用type()函数ÿ…...
逐行讲解transformers中model.generate()源码
目录 简介输入程序model.generate()输入参数1. 创建生成参数对象 generation_config2. 初始化部分输入参数3. 定义模型输入4. 定义其他模型参数5. 准备 input_ids6. 准备 max_length7. 确定生成模式8. 准备 logits 处理器9. 准备 stopping 处理器10. 执行生成 self._sample1. 先…...

小白对时序数据库的理解
一、什么是时序数据库? 时序数据库(Time Series Database,TSDB)是一种专门用于存储、处理和分析时间序列数据的数据库管理系统。时间序列数据是按时间顺序记录的数据,通常由各种设备和传感器生成,例如智慧…...
打开游戏提示丢失(或找不到)XINPUT1_3.DLL的多种解决办法
xinput1_3.dll是一个动态链接库(DLL)文件,它在Windows操作系统中扮演着重要的角色。该文件作为系统库文件,通常存放于C:\Windows\System32目录下(对于32位系统)或C:\Windows\SysWOW64目录下(对于…...

netty的网络IO模型
参考: 聊聊Netty那些事儿之从内核角度看IO模型...

电子木鱼小游戏小程序源码系统 带完整的安装代码包以及搭建部署教程
系统概述 在快节奏的生活中,人们越来越注重内心的平静与放松。电子木鱼小游戏小程序正是基于这一需求而诞生的,它将传统的木鱼文化与现代科技相结合,为用户提供了一个简单、方便、有趣的冥想与放松工具。通过敲击屏幕上的虚拟木鱼࿰…...

支付域——交易系统设计
摘要 交易是业务流转的基础,其中交易系统和订单系统的设计至关重要。交易系统需确保安全、高效与稳定。在设计时,要考虑支付方式的多样性及兼容性,保障资金流转的准确与安全。同时,应具备良好的风险控制机制,防范欺诈等风险。订单系统则负责记录和管理交易的全过程。需清…...

IBus 和 Fcitx 框架下的rime输入法引擎
Rime 输入法引擎 Rime(中州韵输入法引擎):这是一个跨平台的输入法引擎,支持多种输入法方案,如拼音、五笔、注音等。Rime本身不提供前端界面,它需要与输入法框架(如IBus或Fcitx)结合…...
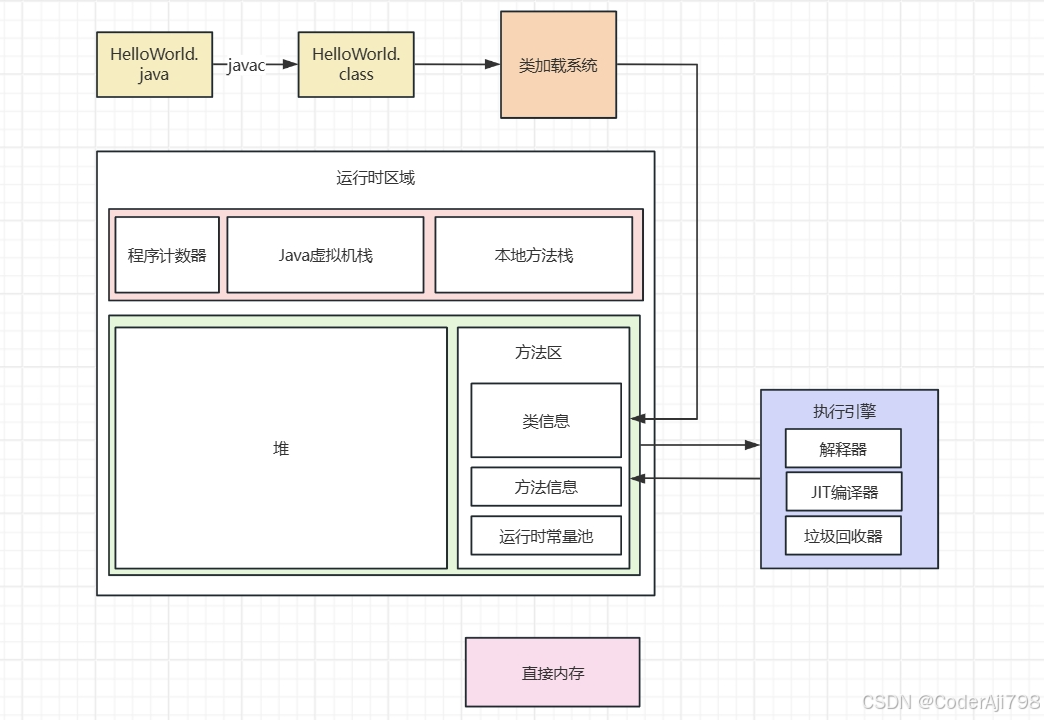
Java基础-JVM
JVM构成部分 类加载系统 类加载子系统的作用是将磁盘中的.class文件加载到内存当中。工作过程如下: 加载:通过类全路径名获取二进制字节流;将这个二进制字节流代表的数存储构转化为方法区运行时数据结构;在内存生成一个代表该类的…...

集成学习:投票法、提升法、袋装法
集成学习:投票法、提升法、袋装法 目录 🗳️ 投票法 (Voting)🚀 提升法 (Boosting)🛍️ 袋装法 (Bagging) 1. 🗳️ 投票法 (Voting) 投票法是一种强大的集成学习策略,它通过将多个模型的预测结果进行组合…...

波浪理论、江恩理论、价值投资的结合
结合波浪理论、江恩理论和价值投资,需要理解这三种方法的核心原理和应用方式。下面详细解析如何将它们融合在一起,形成一个更全面的投资策略: 1. 基本概述 波浪理论:由艾略特提出,通过分析市场波动的五个上升浪和三个…...
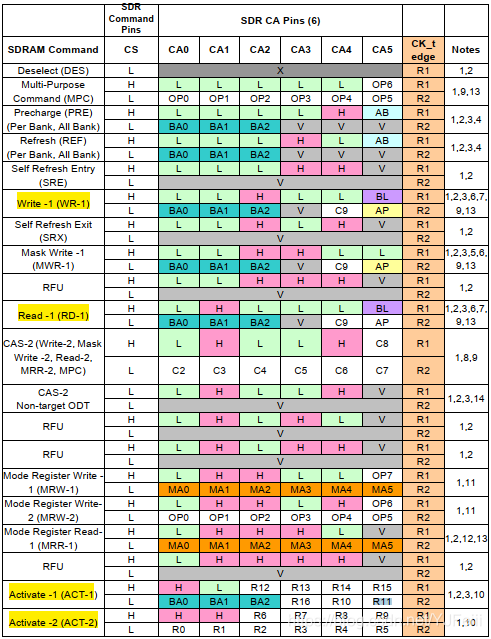
LRDDR4芯片学习(三)——命令和时序
ddr command: activate commandrefresh commandprecharge commandwrite/read commandburst write/read commandMRR/MRW command 一、Activate命令 在读写命令之前,必须要发送Activate命令,由ACTIVATE-1、ACTIVATE-2命令组成。ACTIVATE命令中包含了BA[…...

【趣学C语言和数据结构100例】
【趣学C语言和数据结构100例】 问题描述 61.假定采用带头结点的单链表保存单词,当两个单词有相同的后缀时,可共享相同的后缀存储空间,例如,loading 和 being 的存储映像如下图所示,设 strl 和 str2 分别指向两个单词所在单链表的头结点,链表结点结构为 data next。请设计…...
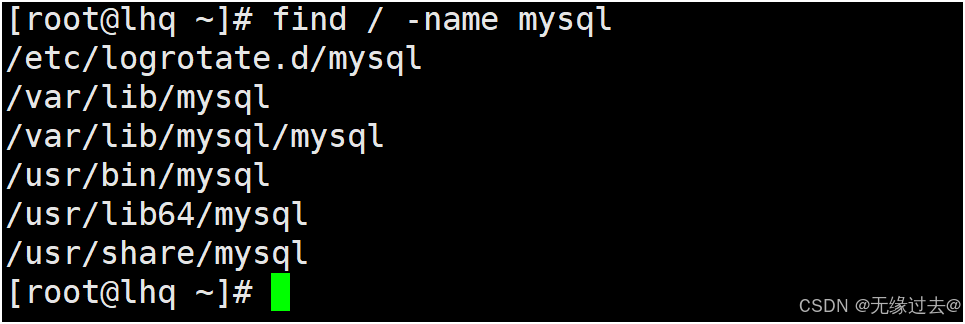
linux卸载数据库(最为完整的卸载方式)
1.首先检查是否安装了MySQL组件 我们可以看到有五个与mysql相关的组件 2.卸载前关闭MySQL服务 systemctl stop mysqld systemctl status mysqld 3.收集MySQL对应的文件夹信息 whereis mysql 4.卸载删除MySQL各类组件 #例如 rpm -ev --nodeps mysql-community-libs-5.7.…...
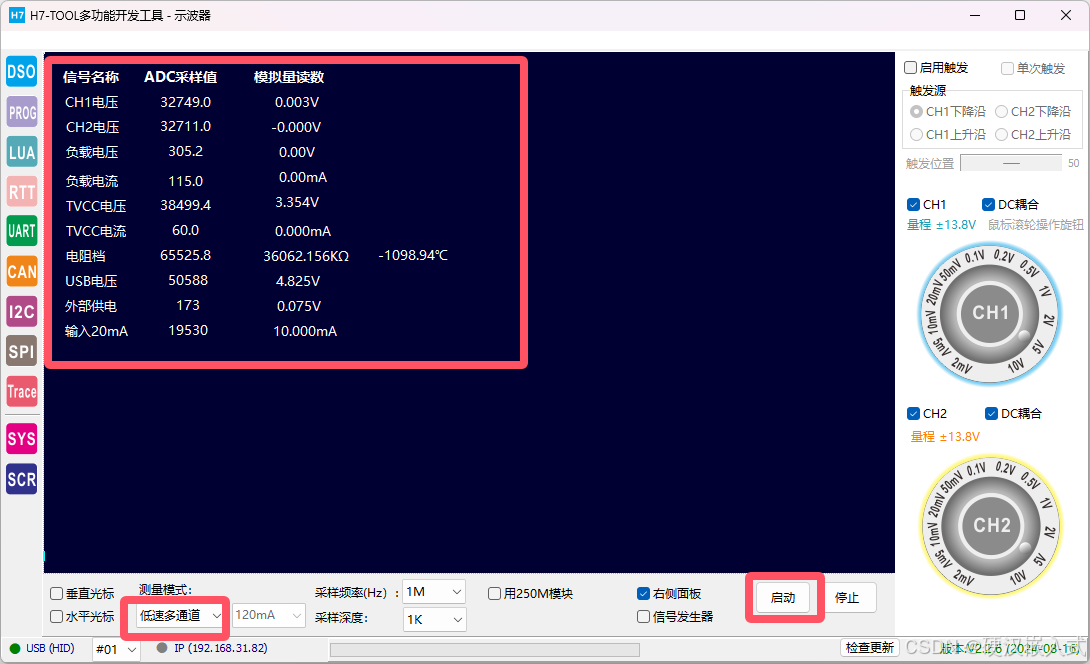
H7-TOOL的LUA小程序教程第15期:电压,电流,NTC热敏电阻以及4-20mA输入(2024-10-21,已经发布)
LUA脚本的好处是用户可以根据自己注册的一批API(当前TOOL已经提供了几百个函数供大家使用),实现各种小程序,不再限制Flash里面已经下载的程序,就跟手机安装APP差不多,所以在H7-TOOL里面被广泛使用ÿ…...

使用梧桐数据库进行销售趋势分析和预测
在当今竞争激烈的商业环境中,企业需要深入了解销售数据,以便做出明智的决策。销售趋势分析和预测是帮助企业把握市场动态、优化库存管理、制定营销策略的重要工具。本文将介绍如何使用SQL来创建销售数据库的表结构,插入示例数据,并…...
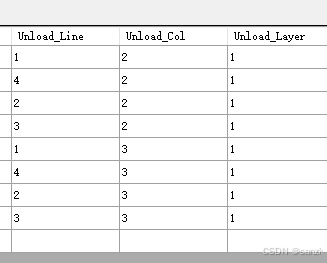
SQLITE排序
最终实现的效果:先查询第一层2列开始的1、4、2、3排,再查询第三列、四列...,然后第二层... 入库 排序优先级:层>列>排(1>2,4>3) 最终排的优先级 1>4>2>3 ORDER BY rack.rackLayer,rack.rackColumn, CASE rack.rackRowW…...

python的文件操作
文件操作 1.打开文件 2.读取文件内容 3.写入文件内容 4.关闭文件 要打开文件,可以使用open()函数并指定文件路径和模式。 file open("example.txt", "r") # 打开了一个名为"example.txt"的文件,并将其赋值给变量file。第…...

群晖通过 Docker 安装 MySQL
1. 打开 Docker 应用,并在注册表搜索 MySQL 2. 下载 MySQL 镜像,并选择版本 3. 在 Docker 文件夹中创建 MySQL,并创建子文件夹 4. 设置权限 5. 选择 MySQL 映像运行,创建容器 6. 配置 MySQL 容器 6.1 使用高权限执行容器 6.2 启…...
)
在AutoDL上搞定nuScenes数据集:从解压到mmdetection3d初始化(含避坑指南)
在AutoDL云端高效部署nuScenes数据集:全流程解析与实战避坑指南 nuScenes作为自动驾驶领域最具挑战性的3D感知数据集之一,包含1000个复杂城市场景的多模态数据。但对于刚接触云端GPU服务器的研究者来说,从数据解压到环境配置的每一步都可能遇…...

SillyTavern角色卡片系统全解析:从技术原理到实战应用
SillyTavern角色卡片系统全解析:从技术原理到实战应用 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 技术原理:PNG元数据驱动的角色存储机制 SillyTavern角色卡片…...
)
C# WebSocket实战:5分钟搞定实时聊天应用(附完整源码)
C# WebSocket实战:5分钟构建高可靠实时聊天系统 实时通信已成为现代应用的核心需求之一。想象一下,当用户发送消息时,对方能立即看到;当股票价格波动时,交易界面实时更新;当多人协作编辑文档时,…...
)
别再手动复制粘贴了!用CubeMX一键生成FreeRTOS工程(STM32F4 HAL库实战)
告别繁琐配置:STM32CubeMXFreeRTOS全自动工程生成指南 在嵌入式开发领域,时间就是竞争力。传统FreeRTOS移植需要手动复制文件、配置路径、修改中断向量表,稍有不慎就会陷入头文件缺失、链接错误的泥潭。现在,STM32CubeMX的图形化…...
)
从51到STM32:手把手教你用STM32CubeMX和PWM驱动智能小车电机(附代码避坑)
从51到STM32:智能小车电机控制的进阶实战指南 十年前用51单片机做智能小车时,PWM配置需要手动计算定时器重装载值,而今天在STM32CubeMX里勾选几下就能生成精准的PWM信号——这就像从手动挡升级到了自动驾驶。作为过来人,我完整记…...

OpenClaw+Qwen3.5-4B-Claude:个人知识库自动化更新方案
OpenClawQwen3.5-4B-Claude:个人知识库自动化更新方案 1. 为什么需要自动化知识管理 作为一个每天需要处理大量技术资料的研究者,我发现自己陷入了一个困境:收藏的文章越来越多,但真正消化吸收的内容却越来越少。上周整理笔记时…...

MogFace-large保姆级部署:Ubuntu/CentOS系统GPU驱动适配指南
MogFace-large保姆级部署:Ubuntu/CentOS系统GPU驱动适配指南 1. 前言:为什么选择MogFace-large 如果你正在寻找一个强大的人脸检测解决方案,MogFace-large绝对值得你的关注。这个模型在Wider Face榜单的六项评测中已经霸榜超过一年…...

03-CAPL 常用函数大全
专栏:《CAPL 脚本编写实战指南》第 3 篇 作者:一线汽车电子测试工程师 适合人群:已掌握 CAPL 基础的测试人员、想系统学习 CAPL 函数的工程师开篇:为什么要学 CAPL 函数? 这是我刚学 CAPL 时的真实经历。 当时的情况&a…...

3个魔法时刻:如何让Switch手柄在PC上获得新生
3个魔法时刻:如何让Switch手柄在PC上获得新生 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.com/gh_mirro…...

Agent能为中小企业降本增效吗?深度拆解AI Agent在企业智能自动化的落地路径
在2026年这一关键的时间节点上,AI Agent能否为中小企业实现实质性的降本增效,已经从一个理论命题转变为大规模的实践成果。随着大模型技术的深度演进,AI Agent不再仅仅是简单的对话机器人,而是进化为具备自主规划、决策与执行能力…...