mysql数据量分库分表
一、分库分表参考阈值
分库分表是解决大规模数据和高并发访问问题的常用策略。虽然没有绝对的阈值来决定何时进行分库分表,但以下是一些参考阈值和考虑因素,可以帮助你做出决策:
1.1 数据量阈值
- 单表数据行数:当单表的数据行数达到千万级别(例如,1000万行)时,就应该开始考虑分表。对于一些高性能要求的应用,甚至在百万级别(100万行)时就需要考虑。
- 表的大小:如果表的大小达到了几十GB(例如,50GB),这可能是考虑分表或分库的信号。对于一些特定的硬件配置,10GB 的表大小就可能需要考虑分表。
- 数据库总大小:当整个数据库的大小接近或超过 1TB 时,分库可能是一个好的选择。
- 单表字段数量:单表字段数量在30-50个左右时,查询性能较好。超过50个字段时,可能会导致查询性能下降。
1.2 性能阈值
- 查询延迟:如果常见的查询操作或报表生成的响应时间不再满足业务需求,可能需要考虑分库分表。
- 写入延迟:当写入操作(包括插入、更新、删除)的延迟显著增加时,分表或分库可能有助于提高性能。
- 锁争用:高并发环境下,如果频繁出现锁争用问题,导致事务等待时间过长,分表可以减少锁的粒度。
1.3 系统架构阈值
- 硬件资源限制:当数据库服务器的 CPU、内存或磁盘 I/O 成为瓶颈时,分库可以帮助分散负载。
- 并发用户数:如果系统的并发用户数或并发请求量显著增加,导致数据库压力过大,分库分表可以提高并发处理能力。
- 数据访问模式:如果数据访问模式呈现明显的热点数据和冷数据分布,分表可以将热点数据和冷数据分离,优化性能。
1.4 业务发展阈值
- 业务模块增长:随着业务模块的增加,如果原有的数据库架构无法有效支持新的业务需求,分库可以按业务模块进行数据隔离。
- 数据增长速度:如果数据的增长速度远超预期,导致数据库维护和管理成本急剧上升,提前规划分库分表是明智的选择。
- 多地域部署需求:为了提高跨地域用户的访问速度和数据的可用性,根据地理位置进行分库可以减少跨地域访问延迟。
二、分库分表的策略
分库分表是解决大规模数据和高并发访问问题的有效手段,尤其是在互联网应用中。合理的分库分表策略能够提高系统的可扩展性和性能。以下是一些常见的分库分表策略:
1. 垂直分库
- 策略描述:按业务模块将数据分布到不同的数据库中,每个数据库负责存储特定业务模块的数据。
- 适用场景:适用于业务模块之间耦合度低,数据交互不频繁的场景。
2. 水平分库
- 策略描述:将同一业务模块的数据按某种规则分散存储到多个数据库中,每个数据库存储一部分数据。
- 适用场景:适用于单一业务模块数据量巨大,单库无法承载的场景。
3. 垂直分表
- 策略描述:将一个数据表按功能拆分成多个表,每个表只存储部分字段。
- 适用场景:适用于单表字段过多,部分字段查询频率远高于其他字段的场景。
4. 水平分表
- 策略描述:将一个数据表的数据按某种规则分散存储到多个表中,每个表存储一部分数据。
- 适用场景:适用于单表数据量巨大,单表查询、写入性能下降的场景。
三、分库分表可能存在的问题
分库分表虽然是解决大规模数据和高并发访问问题的有效策略,但它也带来了一系列复杂的技术挑战。以下是分库分表可能存在的主要问题:
3.1. 数据一致性问题
- 跨库事务难以保证
- 分布式事务的复杂性增加
- 数据同步和复制延迟可能导致数据不一致
在分布式系统中,数据一致性问题是一个核心挑战。为了解决这个问题,业界提出了多种解决方案,每种方案都有其适用场景和权衡。以下是一些主要的数据一致性解决方案:
3.1.1. 强一致性(Strong Consistency)
- 描述:系统在更新数据后,任何后续的访问都将返回最新的值。这确保了所有节点在任何时间点都是一致的。
- 实现方式:使用分布式锁、两阶段提交(2PC)等协议来确保操作的原子性和一致性。
- 适用场景:对数据一致性要求极高的场景,如金融交易。
3.1.2. 弱一致性(Weak Consistency)
- 描述:系统不保证立即看到更新的结果,但最终所有的访问将返回最新的值。
- 实现方式:允许数据在不同节点上暂时不一致,依靠后续的同步过程来达到一致性。
- 适用场景:对实时性要求不高的应用,如社交网络的时间线更新。
3.1.3. 最终一致性(Eventual Consistency)
- 描述:是弱一致性的一种特例,保证只要没有新的更新,系统最终会达到一致状态。
- 实现方式:通过后台的同步和复制过程来逐渐达到全局一致性。
- 适用场景:大规模分布式系统,如云存储服务。
3.1.4. 顺序一致性(Sequential Consistency)
- 描述:系统中的所有操作都是顺序一致的,即操作的结果反映了所有操作的顺序。
- 实现方式:通过分布式锁或时间戳来保证操作的全局顺序。
- 适用场景:需要保证操作顺序的分布式队列和日志系统。
3.1.5. 因果一致性(Causal Consistency)
- 描述:如果操作A在操作B之前发生,那么系统保证任何节点上看到的B都在A之后。
- 实现方式:通过维护操作之间的因果关系(如向量时钟)来实现。
- 适用场景:分布式协作应用,如在线文档编辑。
3.1.6. 读己之所写(Read-your-writes Consistency)
- 描述:保证用户总是能读到自己写入的数据。
- 实现方式:通过客户端缓存或会话一致性来保证。
- 适用场景:个人化服务,如用户配置信息的存储。
3.1.7. CRDTs(Conflict-free Replicated Data Types)
- 描述:一种特殊的数据结构,能够在没有中心协调器的情况下,在分布式系统中达到强一致性。
- 实现方式:通过数学上的合并操作来解决数据冲突,保证最终一致性。
- 适用场景:分布式计数器、集合等数据结构的同步。
3.1.8. 分区容忍(Partition Tolerance)
- 描述:在网络分区发生时,系统仍然能够保持一定程度的可用性和一致性。
- 实现方式:通过多副本、故障转移和数据同步策略来实现。
- 适用场景:高可用性要求的分布式系统。
选择合适的一致性模型和解决方案需要根据具体的应用场景、性能要求和系统复杂度来综合考虑。在设计系统时,通常需要在一致性、可用性和分区容忍性之间做出权衡(CAP定理)。
3.2. 跨库跨表查询复杂性
- 联合查询性能下降
- 需要额外的查询拆分和结果合并逻辑
- 分页、排序等操作变得复杂
3.3. 分布式ID生成
- 需要全局唯一ID生成策略
- 自增ID在分布式环境中难以维护
在分库分表的背景下,分布式ID生成变得尤为重要,因为我们需要确保跨多个数据库和表的全局唯一性。以下是在这种场景下适用的分布式ID生成解决方案:
Snowflake算法(改进版)
- 原理:基于Twitter的Snowflake算法,生成64位的长整型ID。
- 组成:
- 1位符号位
- 41位时间戳(毫秒级)
- 10位工作机器ID(5位数据中心ID + 5位机器ID)
- 12位序列号
- 优点:
- 高性能,每秒可生成数百万个ID
- ID有序,便于数据库索引
- 不依赖外部系统
- 缺点:
- 依赖系统时钟,时钟回拨可能导致ID重复
- 适用:大规模分布式系统,需要高性能ID生成的场景
号段模式(Segment)
- 原理:预先从数据库中批量获取一段ID范围,应用程序在内存中分配。
- 实现:
- 使用一个专门的表存储各个业务线的当前最大ID
- 应用程序批量获取一段ID范围,如1001-2000
- 在内存中顺序分配这些ID
- 优点:
- 减少数据库访问,提高性能
- ID连续性好,便于分库分表的扩展
- 缺点:
- 需要额外的ID管理表
- 服务重启可能导致ID段浪费
- 适用:对ID连续性有要求的分库分表场景
Redis生成
- 原理:利用Redis的INCR或INCRBY命令原子性递增生成ID。
- 实现:
- 为每个分片设置一个Redis key
- 使用INCRBY命令批量获取ID
- 优点:
- 高性能,支持高并发
- 实现简单
- 缺点:
- 依赖Redis的可用性
- ID不保证连续
- 适用:高并发、对ID连续性要求不高的场景
数据库多主模式
- 原理:多个数据库实例各自生成自增ID,通过初始值和步长保证全局唯一。
- 实现:
- 如两个数据库实例,一个初始值为1,步长为2;另一个初始值为2,步长为2
- 优点:
- 实现简单,利用数据库自增特性
- 保证ID的连续性
- 缺点:
- 扩展性受限,增加数据库实例需要调整步长
- 依赖数据库性能
- 适用:中小规模系统,分库数量相对固定的场景
UUID变种
- 原理:基于标准UUID,但进行了优化以适应分库分表场景。
- 实现:
- 使用时间戳替换UUID的前几位
- 加入机器标识
- 压缩UUID长度(如使用Base64编码)
- 优点:
- 全局唯一性好
- 不依赖外部系统
- 缺点:
- 相比纯数字ID,字符串ID在索引和存储上可能效率较低
- 适用:对ID格式没有特殊要求,但需要确保全局唯一性的场景
分布式缓存+数据库
- 原理:结合分布式缓存和数据库的优点。
- 实现:
- 使用分布式缓存(如Redis)存储当前最大ID
- 定期将最大ID同步到数据库
- 应用程序从缓存中获取ID段
- 优点:
- 高性能
- 数据库作为备份,提高可靠性
- 缺点:
- 实现相对复杂
- 需要管理缓存和数据库的一致性
- 适用:大规模、高并发的分布式系统
Leaf(美团点评开源方案)
- 原理:提供号段模式和Snowflake算法两种模式。
- 实现:
- 号段模式:类似于上述的号段模式
- Snowflake模式:改进的Snowflake算法,解决了时钟回拨问题
Leaf是美团点评开源的分布式ID生成系统,它提供了两种模式:Leaf-Segment和Leaf-Snowflake。在Leaf-Snowflake模式中,特别针对Snowflake> 算法中的时钟回拨问题提出了解决方案。
Leaf 如何解决时钟回拨问题
Snowflake算法依赖于系统时钟来保证生成的ID的唯一性和顺序性。如果系统时钟发生回拨,就有可能生成重复的ID,这在分布式系统中是不可接受的。Leaf通过以下方式来解决时钟回拨问题:
- 时钟回拨检测
- Leaf在生成ID时会检测系统时钟是否发生了回拨。具体来说,它会记录上一次生成ID时的时间戳,每次生成ID前都会检查当前时间戳是否小于上次记录的时> - 间戳。如果发现当前时间戳小于上次记录的时间戳,即检测到时钟回拨。
- 等待时钟恢复
- 一旦检测到时钟回拨,Leaf的处理策略是等待直到系统时钟“追上”上次记录的时间戳。在这个等待期间,Leaf会拒绝生成新的ID,以避免ID冲突或重复。> - 这种策略的优点是简单直接,能够有效避免因时钟回拨导致的ID重复问题。但缺点是在等待期间无法生成ID,影响服务的可用性。
- 使用NTP服务校准时间
- 为了减少时钟回拨的发生概率,Leaf推荐使用网络时间协议(NTP)服务来校准系统时钟。通过定期同步NTP服务器的时间,可以确保系统时钟的准确性和一> - 致性,从而减少时钟回拨的风险。
- 记录和报警
- Leaf还建议在检测到时钟回拨时进行日志记录和报警,以便及时发现并处理时钟回拨问题。这有助于运维人员迅速响应,采取措施校准系统时钟,恢复ID生> - 成服务的正常运行。
- 总的来说,Leaf通过时钟回拨检测、等待时钟恢复、使用NTP服务校准时间以及记录和报警等措施来解决Snowflake算法中的时钟回拨问题。这些措施旨在> - 确保即使在时钟回拨的情况下,也能保证生成的ID的全局唯一性和顺序性,从而保障分布式系统的稳定运行。
- 优点:
- 高性能
- 双模式支持不同场景
- 解决了常见的分布式ID问题
- 缺点:
- 需要额外部署和维护Leaf服务
- 适用:大型分布式系统,需要统一ID生成服务的场景
在选择分布式ID生成方案时,需要考虑系统的规模、性能需求、ID的格式要求(如是否需要连续、是否包含业务信息)以及系统的扩展性。通常,Snowflake算法和号段模式是比较常用且适合大多数分库分表场景的解决方案。
3.4. 数据迁移和扩容困难
- 历史数据的迁移和重新分布复杂
- 在线扩容(增加新的分片)需要复杂的数据重平衡过程
3.5. 数据库中间件的选择和维护
- 需要引入额外的中间件来管理分片路由
- 中间件本身可能成为性能瓶颈或单点故障
在分库分表的背景下,数据库中间件扮演着至关重要的角色,它帮助管理和抽象分布式数据库环境的复杂性,提供数据路由、分片、读写分离、负载均衡等> 功能。选择合适的数据库中间件对于确保系统的高性能、高可用性和可扩展性至关重要。以下是几种常见数据库中间件的选择、区别和适用场景:
1. ShardingSphere
- 描述:ShardingSphere是一个开源的分布式数据库解决方案,提供了数据分片、读写分离、分布式事务等功能。
- 优点:支持多种数据库,灵活的配置和强大的功能,适用于复杂的分布式场景。
- 适用场景:适用于需要高度定制化分片策略和读写分离的复杂应用场景。
2. MyCAT
- 描述:MyCAT是基于Java的开源数据库中间件,支持数据库的高可用、负载均衡、分片等。
- 优点:配置简单,社区活跃,有丰富的实践案例。
- 适用场景:适用于MySQL数据库的分库分表,特别是对于追求简单易用的中小型项目。
3. ProxySQL
- 描述:ProxySQL是一个高性能的MySQL代理,支持读写分离、查询缓存、自动故障转移等。
- 优点:高性能,支持复杂的查询路由和负载均衡策略。
- 适用场景:适用于需要高性能读写分离和负载均衡的MySQL应用。
4. Vitess
- 描述:Vitess是针对MySQL设计的数据库集群系统,支持水平扩展和分片。
- 优点:支持大规模分布式环境,由Google开发和维护,稳定性和可扩展性强。
- 适用场景:适用于大规模的Web应用和云原生环境,特别是需要水平扩展的场景。
5. Cobar
- 描述:Cobar是阿里巴巴开源的一个MySQL数据库分库分表的中间件。
- 优点:支持SQL路由、读写分离、负载均衡等。
- 适用场景:适用于阿里巴巴生态内的应用,以及需要简单分库分表功能的场景。
中间件选择的考虑因素
- 性能需求:不同中间件在性能优化、查询路由、负载均衡等方面有所不同,需要根据应用的性能需求进行选择。
- 功能支持:根据应用对分片策略、读写分离、分布式事务等功能的需求,选择提供相应支持的中间件。
- 技术栈兼容性:考虑中间件与现有技术栈的兼容性,包括编程语言、数据库类型等。
- 社区和支持:活跃的社区和良好的文档支持可以在遇到问题时提供帮助。
总之,选择数据库中间件时,需要综合考虑应用的具体需求、中间件的性能特点、功能支持以及未来的扩展性。正确的选择可以帮助应用更好地实现分库分表,提升系统的整体性能和可用性。
3.6. 事务管理
- 分布式事务的实现和管理变得复杂
- 可能需要引入分布式事务协调器(如 XA、TCC 等)
3.6.1. 分布式事务
分布式事务是指跨多个计算机系统或数据库的事务,它们需要保证事务的ACID属性(原子性、一致性、隔离性、持久性),即使在分布式环境中也是如此。由于分布式系统的复杂性,实现分布式事务比在单个数据库系统中实现事务要困难得多。以下是处理分布式事务的一些主要解决方案:
1. 两阶段提交(2PC)
- 描述:两阶段提交是分布式事务的经典解决方案,它将事务提交过程分为两个阶段:准备阶段和提交阶段。
- 优点:能够保证分布式事务的原子性。
- 缺点:性能开销大,存在单点故障问题,第一阶段锁定资源导致系统并发能力下降。
2. 三阶段提交(3PC)
- 设计理念:3PC是两阶段提交(2PC)的改进版,增加了一个预提交阶段,目的是减少在事务处理过程中占用系统资源的时间,提高系统的并发能力。
- 阶段:
- CanCommit:协调者询问参与者是否可以执行事务提交操作。
- PreCommit:如果所有参与者同意提交事务,协调者会让参与者准备提交。
- DoCommit:一旦所有参与者准备就绪,协调者指示参与者提交事务。
- 优点:相比2PC,3PC在某些情况下可以减少阻塞和锁定资源的时间,提高系统的可用性。
- 缺点:仍然存在单点故障问题(协调者故障),实现复杂,网络通信开销大。
3. TCC(Try-Confirm-Cancel)
- 设计理念:TCC是一种基于补偿操作的分布式事务处理机制。它不是在尝试达到强一致性,而是通过业务操作的补偿(撤销)来保证系统的最终一致> 性。
- 阶段:
- Try:预留必要的业务资源。
- Confirm:确认执行业务操作,只有Try阶段成功后才执行。
- Cancel:如果业务操作失败或部分参与者Try失败,执行补偿操作以撤销Try阶段预留的资源。
- 优点:更加灵活,适用于长事务和复杂业务逻辑,可以有效减少锁定资源的时间,提高系统的可用性和并发能力。
- 缺点:需要为每个业务操作定义相应的补偿逻辑,增加了业务实现的复杂度。
4. Saga
- 描述:Saga通过一系列本地事务和补偿事务来保证整个业务流程的最终一致性。
- 优点:适用于长事务处理,提高了系统的可用性和响应速度。
- 缺点:需要为每个步骤定义补偿操作,逻辑可能变得复杂。
5. 分布式事务中间件
- 描述:使用分布式事务中间件,如Seata、Atomikos等,来管理分布式事务的生命周期。
- 优点:提供了一套相对完整的分布式事务解决方案,简化了开发工作。
- 缺点:引入外部依赖,可能会对系统性能产生影响。
6. 基于消息队列的最终一致性
- 描述:通过消息队列实现服务间的异步通信,结合事件驱动的方式来保证数据的最终一致性。
- 优点:系统解耦,提高了系统的伸缩性和可用性。
- 缺点:只能保证最终一致性,无法保证强一致性。
7. BASE理论
- 描述:基于BASE理论(Basically Available, Soft state, Eventually > consistent),通过放宽对一致性的要求,采用最终一致性来提高系统的可用性和伸缩性。
- 优点:提高了系统的可用性和伸缩性。
- 缺点:无法保证强一致性,需要业务能够接受最终一致性的前提。
8. CRDTs(Conflict-free Replicated Data Types)
- 描述:通过使用特殊的数据类型来保证分布式系统中数据的最终一致性,无需额外的同步机制。
- 优点:适用于无中心化的分布式系统,简化了数据同步的复杂性。
- 缺点:适用范围有限,需要根据具体的数据类型设计CRDTs。
3.7. 数据库运维复杂度增加
- 备份和恢复操作变得更加复杂
- 数据库版本升级需要考虑多个实例
3.8. 数据热点问题
- 不均衡的数据分布可能导致某些分片成为热点
- 需要动态负载均衡策略
在分库分表的背景下,数据热点问题是一个常见且重要的挑战。数据热点指的是在分布式系统中,某些特定的数据分片或节点承受了不成比例的高负载,而> 其他分片或节点相对空闲的情况。这种不均衡可能导致系统性能下降、响应时间增加,甚至造成部分服务不可用。以下是关于数据热点问题的详细分析和解> 决方案:
数据热点问题的原因
不均衡的分片策略:如果分片键的选择不当,可能导致数据分布不均匀。
访问模式倾斜:某些数据被频繁访问,而其他数据访问较少。
临时热点:由于特定事件或活动导致的短期内某些数据访问量激增。
固定热点:系统设计导致的某些数据持续高频访问,如配置表、字典表等。
解决方案
优化分片策略
- 使用复合分片键:结合多个字段作为分片键,提高数据分布的均匀性。
- 动态调整分片策略:根据数据访问模式动态调整分片规则。
引入缓存层
- 使用分布式缓存:如Redis,缓存热点数据,减轻数据库压力。
- 多级缓存:结合本地缓存和分布式缓存,进一步提高访问速度。
读写分离
- 将读操作分散到多个从库,减轻主库压力。
- 使用读写分离中间件,如ProxySQL或MyCat,智能分发读写请求。
数据冗余
- 对热点数据进行适度冗余,分散到多个分片或节点。
- 使用异步复制保持冗余数据的一致性。
动态负载均衡
- 实时监控数据访问模式,动态调整负载分配。
- 使用智能路由算法,将请求分发到负载较轻的节点。
分库分表细化
- 对热点表进行更细粒度的分库分表,进一步分散负载。
应用层优化
- 批量处理:合并多个小请求为大请求,减少数据库交互次数。
- 异步处理:将非实时需求的操作异步化,平滑峰值负载。
预热和预加载
- 对可预见的热点数据进行预热,如活动开始前预加载相关数据到缓存。
使用NoSQL数据库
- 对于特定类型的热点数据,考虑使用更适合的NoSQL解决方案,如MongoDB或Cassandra。
数据分级存储
- 根据数据的访问频率和重要性,将数据分级存储在不同性能的存储介质中。
智能分片算法
- 开发或采用能够自适应数据访问模式的智能分片算法。
监控和告警
- 实施全面的监控系统,及时发现和响应热点问题。
- 设置合理的告警阈值,在问题恶化前采取行动。
实施建议
- 分析数据访问模式:在实施解决方案前,深入分析数据访问模式,识别热点的类型和原因。
- 综合应用多种策略:通常需要结合多种策略来有效解决热点问题。
- 持续优化:数据热点是一个动态问题,需要持续监控和优化。
- 考虑业务特性:根据具体业务特性选择合适的解决方案,没有一刀切的方法。
通过合理应用这些策略,可以有效缓解分库分表环境中的数据热点问题,提高系统的整体性能和可用性。>
3.9. 跨分片的数据聚合和统计
- 全局的聚合操作(如 COUNT、SUM 等)变得复杂
- 可能需要额外的数据汇总服务
3.10. 应用程序改造
- 现有应用可能需要大规模重构以适应分库分表架构
- ORM 框架可能需要特殊配置或自定义扩展
3.11. 数据库特性的限制
- 某些数据库特性(如外键约束)在分布式环境中难以实现
- 可能需要在应用层实现一些原本由数据库提供的功能
3.12. 数据一致性和完整性约束
- 跨库的外键关系难以维护
- 唯一性约束在全局范围内难以保证
3.13. 性能监控和问题诊断
- 需要更复杂的监控系统来跟踪多个数据库实例
- 问题定位和性能优化变得更加困难
3.14. 数据安全和权限管理
- 需要在多个数据库实例上统一管理用户权限
- 数据加密和敏感信息保护变得更加复杂
3.15. 跨分片的数据操作
- 批量操作(如批量插入、更新)需要特殊处理
- 跨分片的数据移动(如用户数据迁移)变得复杂
3.16. 测试难度增加
- 需要模拟分布式环境进行测试
- 全面的集成测试和性能测试变得更加复杂
3.17. 数据库选型限制
- 不是所有数据库都能很好地支持分库分表
- 可能需要更换或升级数据库系统
3.18. 成本增加
- 硬件成本可能增加(需要更多的服务器)
- 运维和开发成本增加
3.19. 学习曲线
- 团队需要学习新的技术和最佳实践
- 可能需要引入专门的数据库架构师
3.20. 与云服务的集成
- 在云环境中实施分库分表可能面临额外的挑战
- 需要考虑云服务提供商的特定限制和功能
3.21. 性能和容量规划
- 性能测试:在实施分库分表前后进行全面的性能测试,确保系统能够满足性能要求。
- 容量规划:根据业务增长预测进行容量规划,确保系统的可扩展性。
这些问题突显了分库分表策略的复杂性。在实施分库分表之前,需要仔细评估其必要性,并制定详细的实施计划来应对这些挑战。同时,也要考虑其他可能的替代方案,如使用NoSQL数据库、缓存策略等,以确定最适合特定业务需求的解决方案。
四、注意事项
- 分库分表会增加系统的复杂度,需要提前规划设计。
- 在实施分库分表之前,应该先尝试其他优化手段,如索引优化、SQL 调优、硬件升级等。
- 分库分表的设计应该基于详细的业务分析和数据访问模式分析,避免过度设计。
总之,分库分表的决策应该综合考虑数据量、性能、系统架构和业务发展等多个因素。在实施之前,进行充分的规划和测试是非常重要的。
相关文章:

mysql数据量分库分表
一、分库分表参考阈值 分库分表是解决大规模数据和高并发访问问题的常用策略。虽然没有绝对的阈值来决定何时进行分库分表,但以下是一些参考阈值和考虑因素,可以帮助你做出决策: 1.1 数据量阈值 单表数据行数:当单表的数据行数…...

Vite创建Vue3项目以及Vue3相关基础知识
1.创建Vue3项目 1.运行创建项目命令 # 使用 npm npm create vitelatest2、填写项目名称 3、选择前端框架 4、选择语法类型 5、按提示运行代码 不出意外的话,运行之后应该会出现 下边这个页面 6.延伸学习:对比webpack和vite(这个是面试必考…...

Elasticsearch封装公共索引增删改查
什么是索引? 定义:索引是 Elasticsearch 中用于存储数据的逻辑命名空间。它由多个文档组成,每个文档是一个 JSON 格式的结构化数据对应关系:在关系数据库中,索引类似于表;而在 Elasticsearch 中࿰…...
详解)
Python异常检测:Isolation Forest与局部异常因子(LOF)详解
这里写目录标题 Python异常检测:Isolation Forest与局部异常因子(LOF)详解引言一、异常检测的基本原理1.1 什么是异常检测?1.2 异常检测的应用场景 二、Isolation Forest2.1 Isolation Forest的原理2.1.1 算法步骤 2.2 Python实现…...
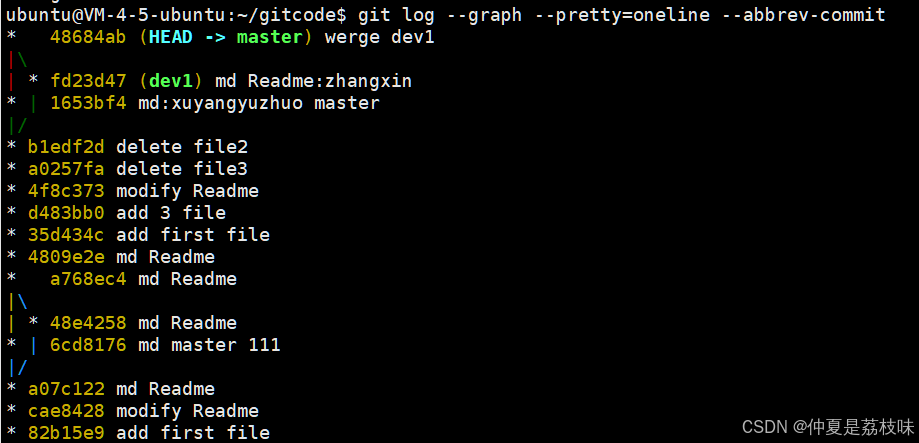
Git的原理和使用(二)
1. git的版本回退 之前我们也提到过,Git 能够管理⽂件的历史版本,这也是版本控制器重要的能⼒。如果有⼀天你发现 之前前的⼯作做的出现了很⼤的问题,需要在某个特定的历史版本重新开始,这个时候,就需要版本 回退的功能…...

docker 发布镜像
如果要推广自己的软件,势必要自己制作 image 文件。 1 制作自己的 Docker 容器 基于 centos 镜像构建自己的 centos 镜像,可以在 centos 镜像基础上,安装相关的软件,之后进行构建新的镜像。 1.1 dockerfile 文件编写 首先&…...

投了15亿美元,芯片创新公司Ampere为何成了Oracle真爱?
【科技明说 | 科技热点关注】 一个数据库软件公司却想要操控一家芯片厂商,这样的想法不错。也真大胆。 目前,全球数据库巨头甲骨文Oracle已经持有Ampere Computing LLC 29%的股份,并有可能通过未来的投资选择权获得对这家芯片制造…...

vue 报告标题时间来自 elementUI的 el-date-picker 有开始时间和结束时间
要在Vue中使用 Element UI 的 el-date-picker 来选择开始时间和结束时间,并将其展示在报告中,以下是详细的实现步骤。 实现思路: 使用 Element UI 的 el-date-picker 组件,让用户选择时间范围(开始时间和结束时间&am…...
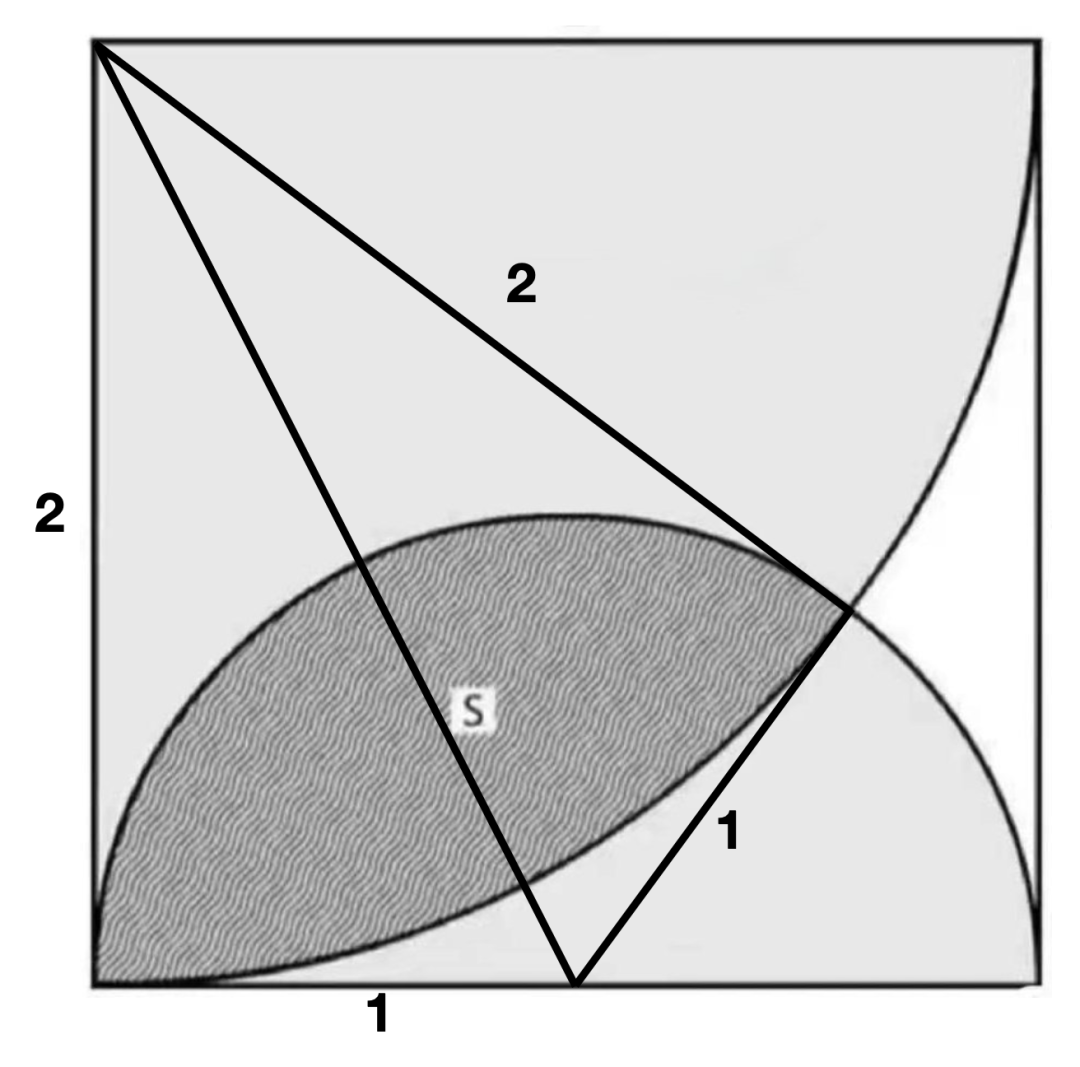
简单几何问题的通解
来,这道题怎么做?边长为2的正方形内,2个扇形的交集面积是多少?这道题一定要画辅助线,因为要用到两个扇形的交点,如果不画辅助线,这个交点相关的4个子图一个都无法求出面积,只能求出子…...
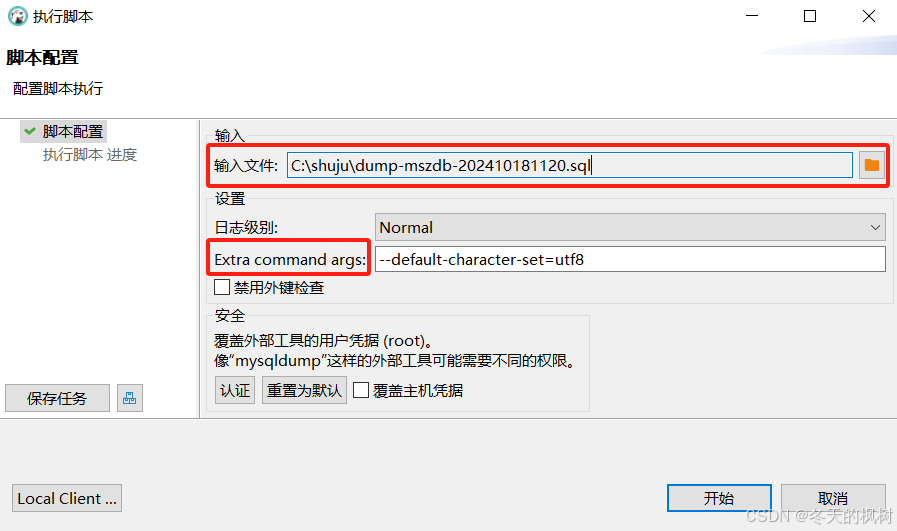
DBeaver导出数据表结构和数据,导入到另一个环境数据库进行数据更新
在工作中,我们会进行不同环境之间数据库的数据更新,这里使用DBeaver导出新的数据表结构和数据,并执行脚本,覆盖另一个环境的数据库中对应数据表,完成数据表的更新。 一、导出 右键点击选中想要导出的数据表࿰…...
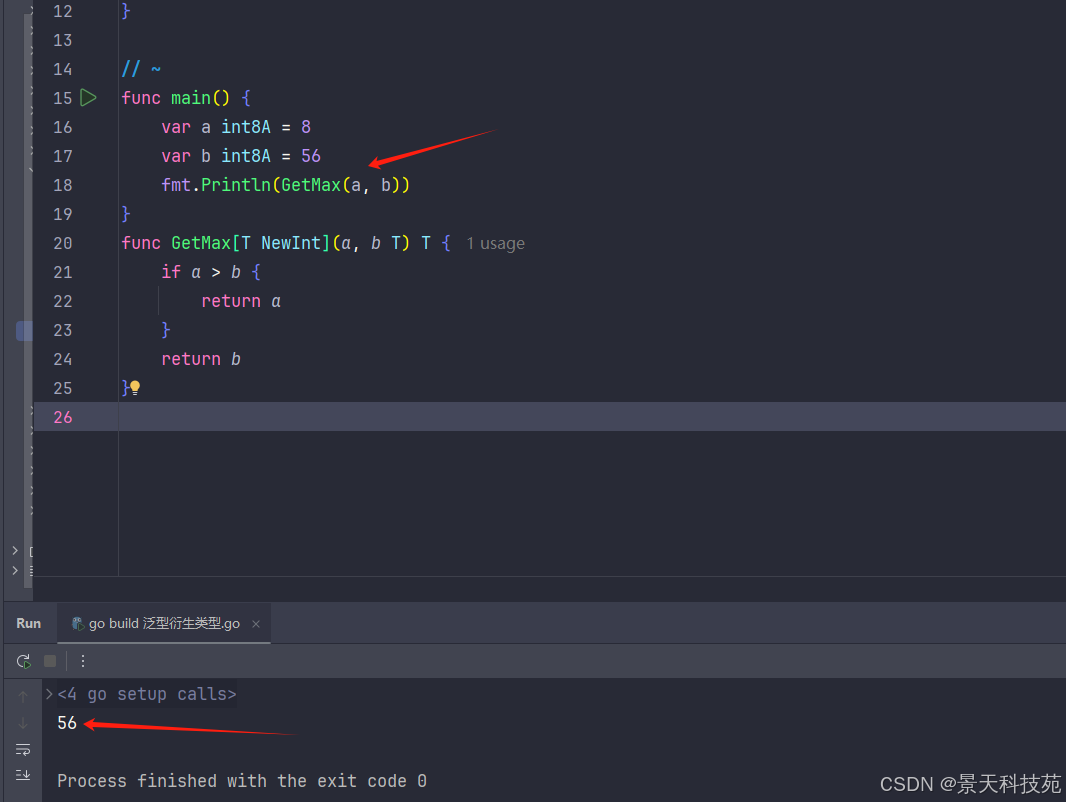
【Golang】合理运用泛型,简化开发流程
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...
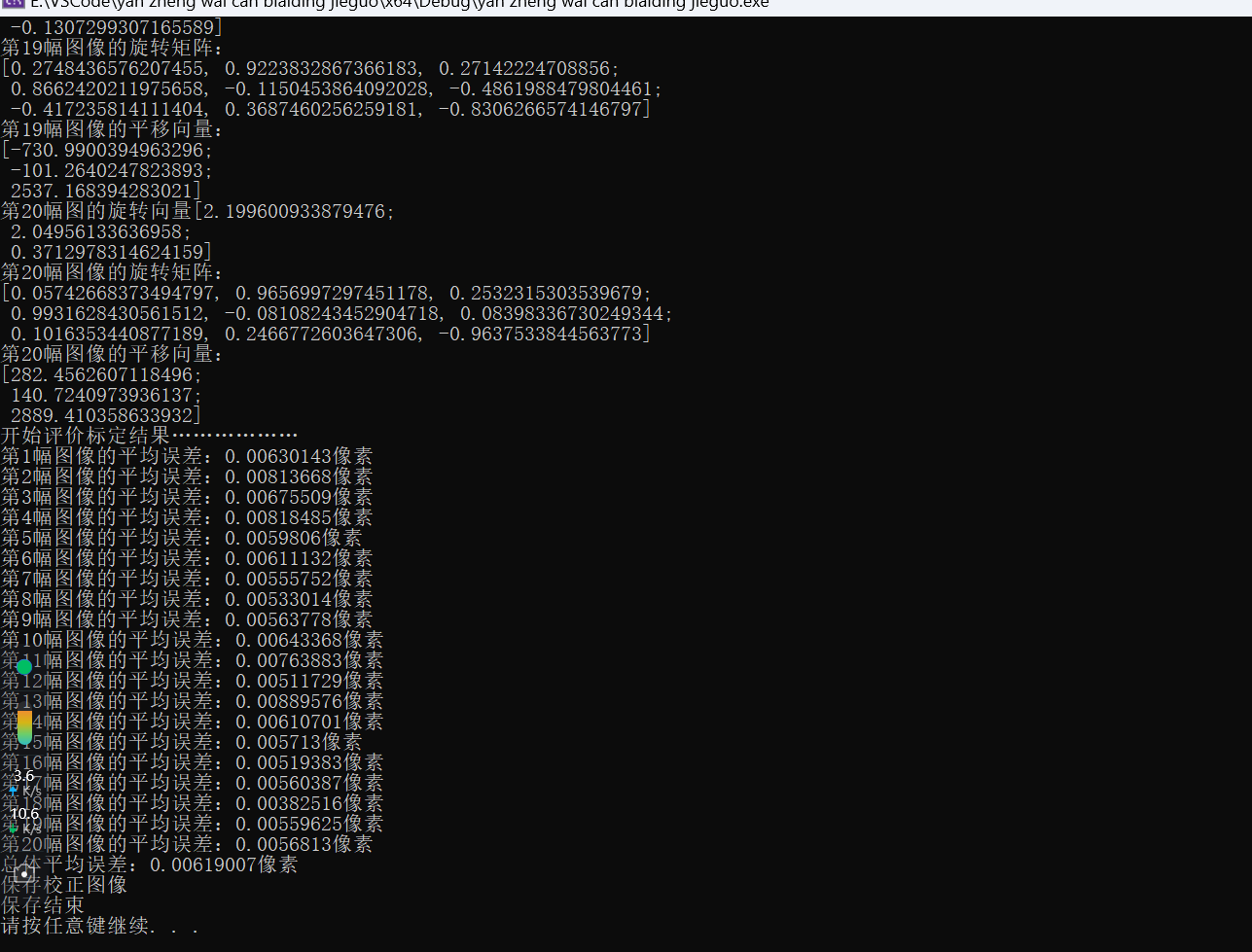
OpenCV单目相机内参标定C++
基于OpenCV 实现单目相机内参标定: a.使用OpenCV库实现内参标定过程。通过角点检测、亚像素角点定位、角点存储与三维坐标生成和摄像机标定分别获取左右相机的内参。 b.具体地,使用库函数检测两组图像(左右相机拍摄图像)中棋盘格…...

基于MATLAB(DCT DWT)
第三章 图像数字水印的方案 3.1 图像数字水印的技术方案 在数据库中存储在国际互联网上传输的水印图像一般会被压缩,有时达到很高的压缩比。因此,数字水印算法所面临的第一个考验就是压缩。JPEG和EZW(Embedded Zero-Tree Wavelet࿰…...
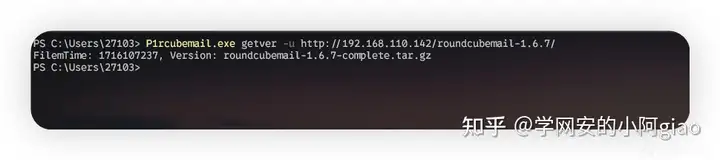
渗透基础-rcube_webmail版本探测
简介 本文介绍了开源产品RoundCube webmail邮件系统的版本探测思路,并用go语言实现工具化、自动化探测。 正文 0x01 探测思路研究 探测系统版本,最理想的方法就是系统主页html代码中有特定的字符串,比如特定版本对应的hash在主页的html代…...
linux下编译鸿蒙版boost库
我在上一篇文章中介绍了curl和openssl的编译方式(linux下编译鸿蒙版curl、openssl-CSDN博客),这篇再介绍一下boost库的编译。 未经许可,请勿转载! 一.环境准备 1.鸿蒙NDK 下载安装方式可以参考上篇文章,…...

滚雪球学Redis[6.3讲]:Redis分布式锁的实战指南:从基础到Redlock算法
全文目录: 🎉前言🚦Redis分布式锁的概念与应用场景🍃1.1 什么是分布式锁?🍂1.2 应用场景 ⚙️使用Redis实现分布式锁🌼2.1 基本思路🌻2.2 示例代码🥀2.3 代码解析 &#…...
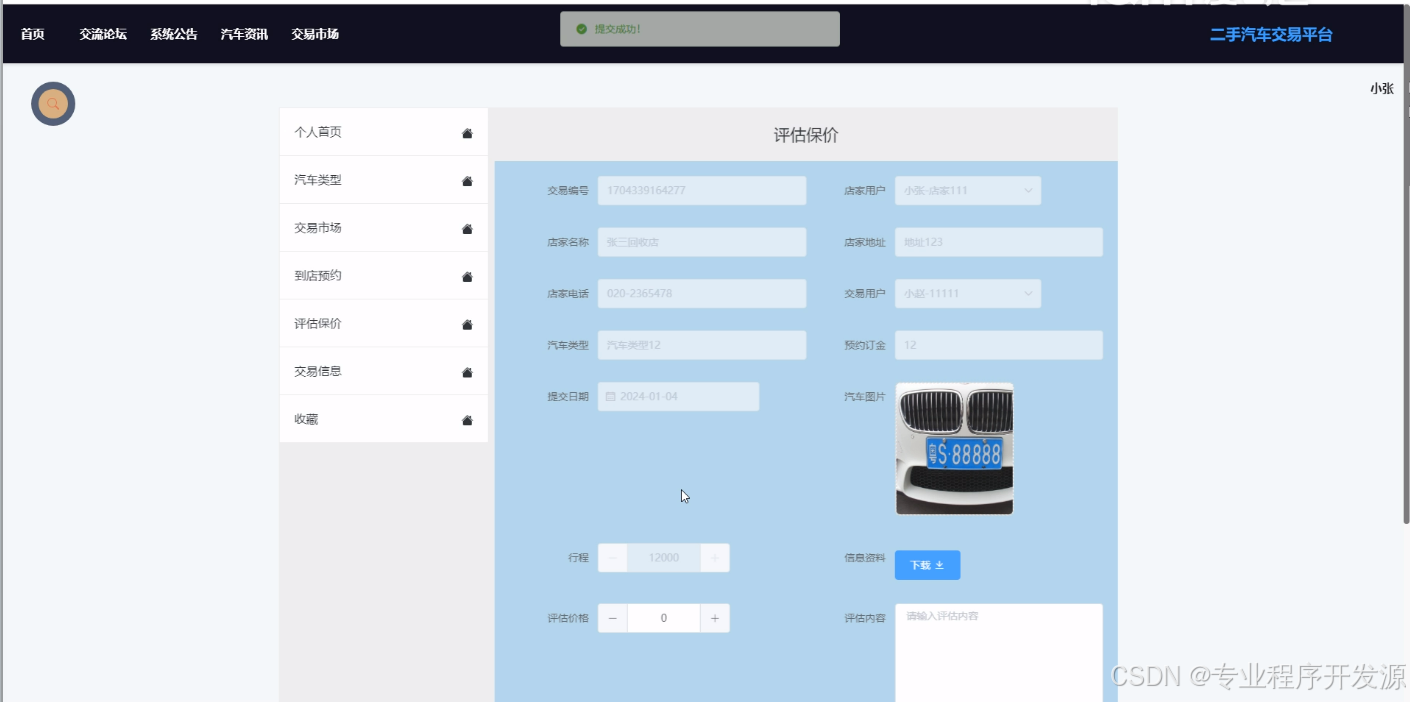
springboot二手汽车交易平台-计算机毕业设计源码82053
目录 1 绪论 1.1研究背景 1.2研究意义 1.3国内外研究现状 2 二手汽车交易平台系统分析 2.1 可行性分析 2.2 系统流程分析 2.3 功能需求分析 2.4 性能需求分析 3 二手汽车交易平台概要设计 3.1 系统体系结构设计 3.2总体功设计 3.3子模块设计设计 3.4 数据库设计 …...

typescript 中的类型推断
在 TypeScript 中,类型推断(Type Inference)是一种编译器自动确定变量或表达式类型的能力。这大大减少了需要显式声明类型的代码量,使得代码更加简洁和易读。TypeScript 的类型推断机制非常强大,可以在很多情况下自动推…...

linux 隐藏文件
在Linux中,隐藏文件以点(.)开头的文件或文件夹被认为是隐藏文件。隐藏文件通常用于存储系统配置文件或敏感文件。 以下是几种不同的方法来隐藏文件或文件夹: 方法1:在文件或文件夹名字前面加上点(.&#…...
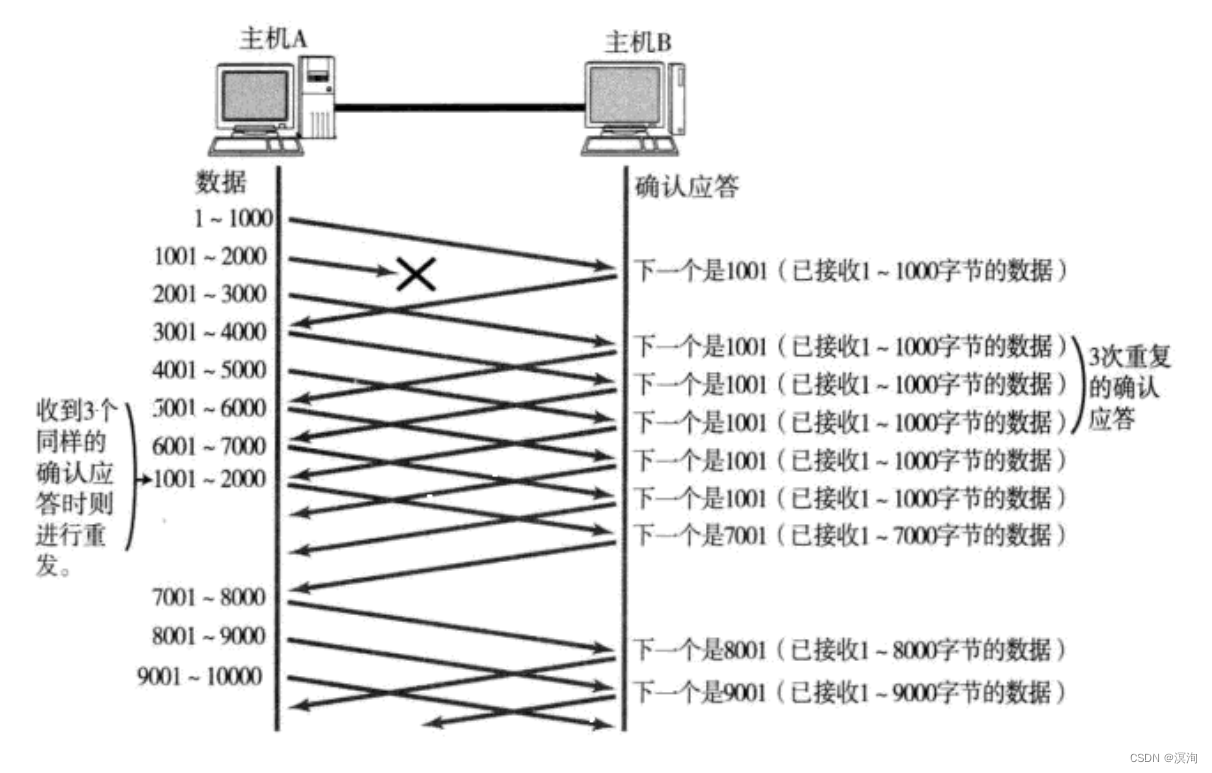
【网络协议栈】Tcp协议(上)结构的解析 和 Tcp中的滑动窗口(32位确认序号、32位序号、4位首部长度、6位标记位、16为窗口大小、16位紧急指针)
绪论 “没有那么多天赋异禀,优秀的人总是努力翻山越岭。”本章主要讲到了再五层网络协议从上到下的第二层传输层中使用非常广泛的Tcp协议他的协议字段结构,通过这些字段去认识其Tcp协议运行的原理底层逻辑和基础。后面将会再写一篇Tcp到底是通过什么调…...

QuickSnap:Blender三维建模效率革命,快速对齐插件让精准建模变得简单
QuickSnap:Blender三维建模效率革命,快速对齐插件让精准建模变得简单 【免费下载链接】quicksnap Blender addon to quickly snap objects/vertices/points to object origins/vertices/points 项目地址: https://gitcode.com/gh_mirrors/qu/quicksnap…...

Ubuntu14.04下用USRP B100实现多模式无线传输:从PSK到QAM的实战配置
Ubuntu 14.04环境下USRP B100多模式无线传输实战指南 在软件定义无线电(SDR)领域,USRP设备配合GNU Radio软件平台已经成为研究和开发无线通信系统的黄金标准组合。本文将带您深入探索如何在Ubuntu 14.04系统中配置USRP B100硬件,实现从基础PSK到复杂QAM等…...

vLLM-v0.17.1部署实战教程:3步启用OpenAI兼容API服务
vLLM-v0.17.1部署实战教程:3步启用OpenAI兼容API服务 1. vLLM框架简介 vLLM是一个专为大型语言模型(LLM)设计的高性能推理和服务库,以其出色的速度和易用性著称。这个项目最初由加州大学伯克利分校的天空计算实验室开发,现在已经发展成为一…...

GHelper:华硕笔记本轻量级替代方案与性能优化指南
GHelper:华硕笔记本轻量级替代方案与性能优化指南 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar, …...

Kazumi WebDAV同步功能详解:实现跨设备番剧数据互通的无缝体验
Kazumi WebDAV同步功能详解:实现跨设备番剧数据互通的无缝体验 【免费下载链接】Kazumi 基于自定义规则的番剧采集APP,支持流媒体在线观看,支持弹幕,支持实时超分辨率。 项目地址: https://gitcode.com/gh_mirrors/ka/Kazumi …...

告别兼容性问题:手把手教你用canvas和base64转换TIFF图片
前端工程师必备:TIFF图片处理全攻略与实战解决方案 在当今数字内容爆炸式增长的时代,图片处理已成为前端开发中不可或缺的一环。作为专业开发者,我们经常需要面对各种图片格式的兼容性问题,其中TIFF(Tagged Image Fil…...

uniapp集成腾讯地图:从marker点聚合到轨迹回放的跨端实战与性能调优
1. uniapp集成腾讯地图SDK的核心步骤 第一次在uniapp里用腾讯地图SDK时,我踩了个大坑——直接在H5端跑代码发现地图出不来。后来才明白,腾讯地图在H5端需要单独配置安全域名。具体操作是在腾讯地图开放平台申请key时,必须把H5的域名加入白名单…...
——从艾里斑到系统分辨率:衍射极限的实战解析)
Zemax光学设计(三)——从艾里斑到系统分辨率:衍射极限的实战解析
1. 艾里斑:光学的终极像素 当你用手机拍夜景时,为什么远处的路灯总变成模糊的光团?这背后隐藏着光学系统的基本限制——艾里斑。我在设计微型内窥镜镜头时,曾花了三周时间优化像差,最终却发现图像清晰度卡在一个无法突…...

Discord社群运营神器:用AI自动回复提升活跃度的完整指南
Discord社群运营神器:用AI自动回复提升活跃度的完整指南 在数字社交时代,Discord已经从一个游戏语音工具成长为全球最受欢迎的社群平台之一。无论是Web3项目、开源社区还是兴趣小组,Discord都成为了连接成员的核心枢纽。但作为社群运营者&…...

影墨·今颜模型API接口开发与调用全指南
影墨今颜模型API接口开发与调用全指南 你是不是已经成功部署了影墨今颜模型,看着它能在本地生成惊艳的图片,心里正盘算着怎么把它变成一个能对外服务的“产品”?比如,让公司的设计团队直接调用,或者集成到自己的应用里…...