科大讯飞:成本降低 60%,性能提升 10 倍,从 ES Loki 到 Apache Doris 可观测性存储底座升级
导读:科大讯飞星际日志中心经历了从 Elasticsearch 到 Loki,再到 Apache Doris 的可观测性存储分析底座升级,支持可观测三大支柱 Log Trace Metrics 的存储与分析,有效解决 Elasticsearch 成本高、Loki 查询慢的问题。Doris 能够在降低成本的同时提高查询效率,实现了查询性能提升 10 倍、存储空间缩减至 Elasticsearch 1/6。此外,Doris 提供的半结构化数据类型 VARIANT 能高效存储可扩展的 JSON 数据,具备很高的灵活性,且其性能媲美普通宽表。
作者|科大讯飞软件研发工程师,曲庆伟
指标、日志、链路是服务可观测性的三大支柱。 在保障服务稳定性方面,指标主要用于发现故障和问题,而日志和链路分析则侧重于定位和分析问题。其中,日志实际上在这三大维度中充当了重要桥梁。
讯飞星迹作为科大讯飞推出的一款全领域场景的可观测产品,旨在满足基础设施、应用及业务上的监测需求,提供一体化的解决方案。以实际场景为例,当服务上线后,需要对中间件和操作系统的 CPU 、内存等资源进行监控,这些指标能够实时反映系统的健康状态。当问题出现后,可以通过日志数据分析其来源,再利用日志链路分析迅速定位问题的位置。
为更好的处理及管理日志数据,讯飞星迹推出了星迹日志中心,经过多个版本迭代后, 现已基于 Apache Doris 升级为可观测存储分析底座,实现查询性能提升 10 倍,存储空间缩减至原来 1/6。目前,在集团内多个 BG BU 的项目上稳定运行,帮助业务降本增效,同时通过业务指标分析和用户画像与行为分析助力业务增长。
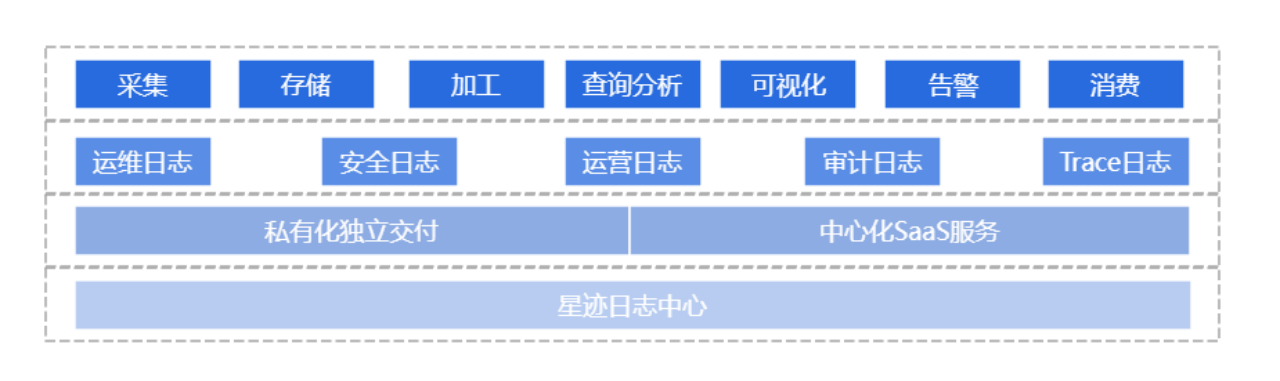
星迹可观测日志中心建设目标
科大讯飞对星迹可观测日志中心建设目标可以总结为三点:写的多、查的快、易于使用。
写的多:
-
高吞吐、低延迟:日志数据增长迅猛,每天可产生 10 ~ 100 TB 数据、日志条数可达几十亿~几百亿条。同时,日志写入并发量也在持续提升,可达到 50 万 TPS,对日志平台的写入吞吐要求极高。
-
低成本存储:日志数据总量庞大且保存时间较长,需实现高压缩率的存储方案,支持冷热存储和数据归档,避免占用过多存储资源。
查的快:
- 秒级查询响应:即使面对海量数据,也需要提供稳定高性能的查询能力,以应对故障排查等对响应速度有较高要求的使用场景,分钟级的数据延迟往往无法满足业务要求。
易于使用:
-
运维简单:要求架构极简易用,支持快速部署、扩容及运维,并能够与其他子系统串联打通,支持多云场景。
-
使用简单:支持工程师熟悉的接口和语言比如 SQL,以及可视化的、便捷的管理界面。
可观测性存储底座架构演进
01 ELK
早期讯飞基于 Elasticsearch 搭建了如图所示的日志处理及分析架构。具体来说,日志采集器将数据上报到 Kafka,接着通过 Logstash 进行 ETL 处理,处理后的数据存储到 Elasticsearch 中,由 Elasticsearch 提供数据的查询及分析服务。
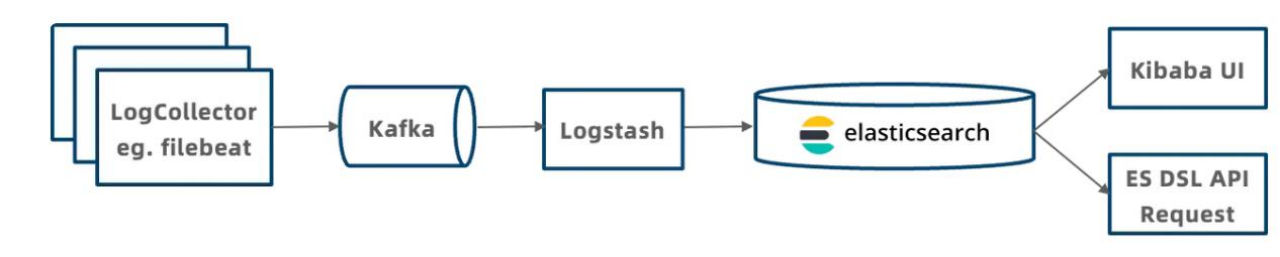
存在的问题:
-
资源占用高:无论是写入还是查询,CPU 占用率普遍较高。这主要是由于高吞吐量写入时,分词操作和 Segment 合并会导致显著的 CPU 消耗。
-
存储成本高:受限于 Elasticsearch 的压缩率,海量日志数据存储成本相对较高。
-
稳定性差:在进行跨天查询或处理大数据量时,系统经常出现 OOM(内存溢出)问题,且故障恢复时间较长。此外,index 加载耗时较长,可能导致写入被拒绝。
02 Loki + Cassandra
第二代架构采用了基于 Grafana Loki 的轻量化架构,通过在各应用物理机上部署采集器来实现日志数据的收集。日志数据通过 Kafka 进入 Logstash 进行 ETL 处理,最终存储到 Loki 中。Loki 的后端存储选用 Cassandra ,其采用 ZSTD 算法压缩,相较于 Elasticsearch,存储成本节约了 5 倍。具体而言,单条日志 300KB,每分钟处理 1.8 万次,经过压缩后,1 天的日志数据仅需 1.4 TB 的存储空间。
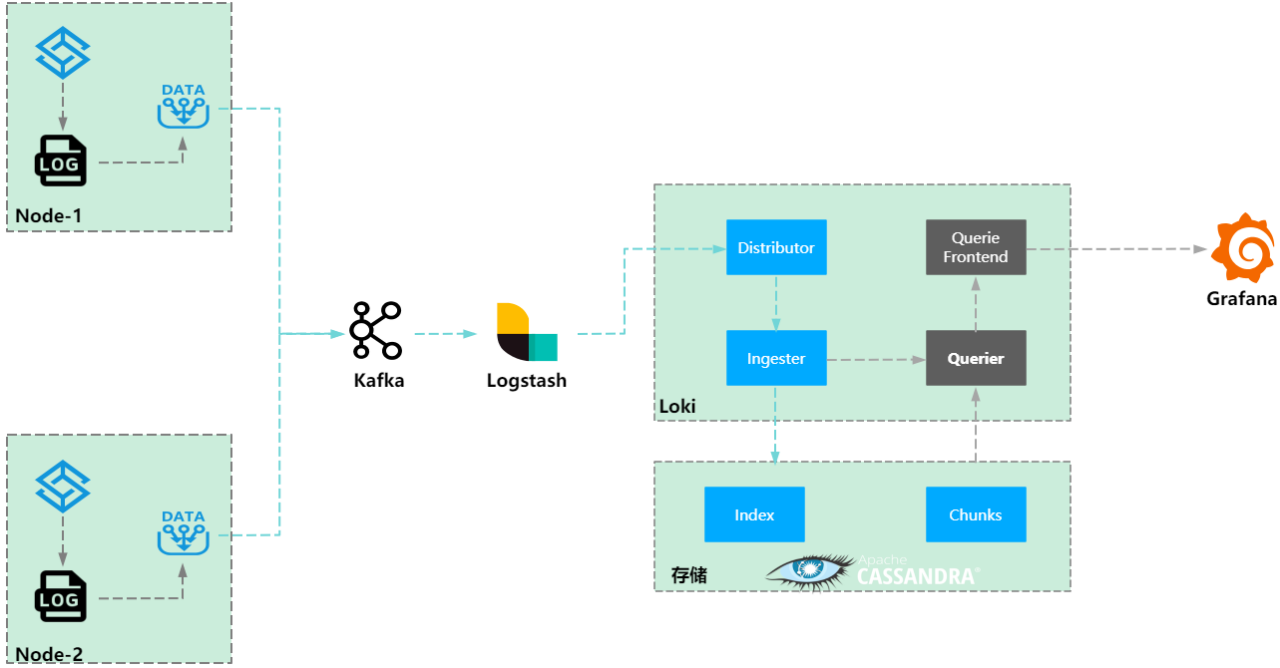
存在的问题:
-
CPU 使用率高、查询分析效率低:Loki 的架构与 Prometheus 原理相似。当以标签进行数据查询时,系统先根据 index 定位到 chunk,然后加载 chunk 中的数据,解压后逐条暴力搜索。这种处理方式显然会导致较高的 CPU 使用率,并且经常出现 OOM(内存溢出)问题,查询和分析的效率也并不理想。
-
创建标签的数量受限: 当标签基数较少时,查询速度尚可。而当标签数量过多或搜索条件复杂时,无法对基数较大的值进行查询加速,而日志场景中的字段基数通常较高。例如,在查询每个链路的 trace ID 时,每条 trace ID 数据几乎都是唯一的,这种高基数的数据不适合使用标签来处理。
03 基于 Apache Doris 的可观测性存储底座
进一步的,为解决上述架构存储的问题,讯飞引入了 Apache Doris。使用 Apache Doris 替换了 Loki 服务。采集后的数据依旧流转至 Kafka 中,消费到日志服务加工处理,按时间和数据大小攒批,设置攒批时长为 3 分钟、数据大小为 200M,满足任一条件则触发数据发送,处理完的数据通过 Stream Load 写入到 Doris 集群中。
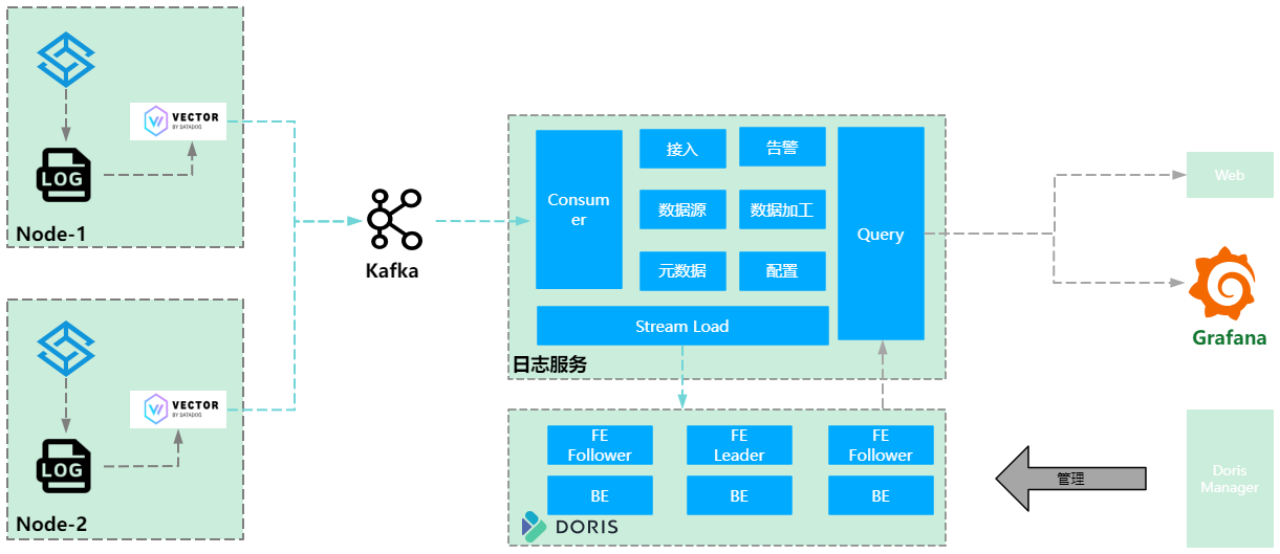
Apache Doris 引入后,可以满足文章最初提出的 3 个建设目标:
-
写的多: 可支撑日均 600 亿条、10TB 的写入流量。与 Elasticsearch 相比,存储成本不及其 1/6,相同的数据 Elasticsearch 存储需要 1T,而依赖于 Doris 的列式存储和 ZSTD 压缩,仅需要 170 G。
-
查的快: 查询效率提升至少 10 倍,特别是在聚合分析、短语模糊匹配及 TOPN 命中前缀索引等场景下,性能提升效果显著。Doris 即使在没有命中索引的情况下,也可以在分钟内返回结果。与 Elasticsearch 频繁出现的 OOM 相比,效率提升尤为突出。
-
易于使用: Doris manager 可便捷管理所有 Doris 集群。科大讯飞在交付私有化项目时,通常需要管理至少数十套集群,而 Doris Manager 使这一过程变得便捷轻松。此外,系统还提供 Grafana 和自研的 Web 查询界面,方便用户进行日志检索和分析。
新架构的应用及优化经验
01 Log Trace Metric 选择合适的数据模型
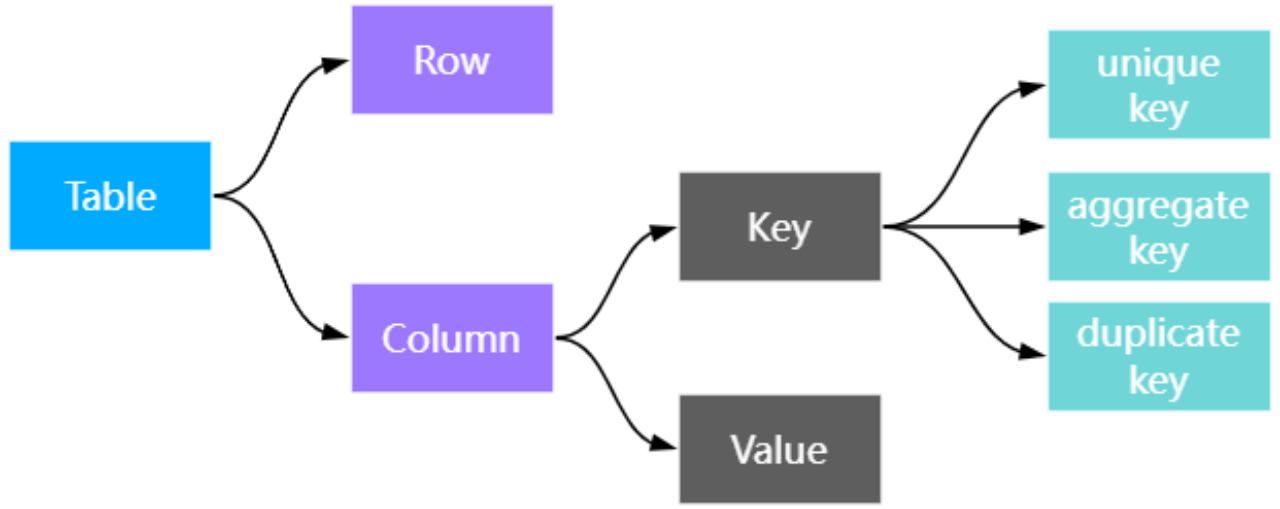
Doris 数据模型分为主键模型、明细模型和聚合模型,这三个模型在可观测日志中心都有不同程度的应用。
主键模型: 主要应用于调用链数据 Trace、配置数据的处理。主键模型能够保证 Key(主键)的唯一性,当用户更新一条数据时,新写入的数据会覆盖具有相同 Key(主键)的旧数据。
CREATE TABLE config (app_code varchar(50) NOT NULL COMMENT '业务唯一编码',app_name varchar(50) NOT NULL ,table_name varchar(200) NOT NULL COMMENT '数据表名',create_time datetime NOT NULL COMMENT '创建时间',update_time datetime NOT NULL COMMENT '更新时间'
)
ENGINE = OLAP
UNIQUE KEY(app_code)
DISTRIBUTED BY HASH(app_code) BUCKETS AUTO
PROPERTIES ("enable_unique_key_merge_on_write" = "true","light_schema_change" = "true"
);
**明细模型:**主要用于日志数据 Log 的处理。数据将按照导入文件中的内容进行存储,且不进行任何聚合,即使 Key 列完全相同的数据也会被保留。在建表语句中指定的 Duplicate Key 仅用于指明数据存储时按哪些列进行排序,以适应业务不断产生的数据。一旦数据产生,就不会再发生变化。
CREATE TABLE log_record
(`log_date` DATETIMEV2(3) COMMENT "日志打印时间",`source` VARCHAR(100) COMMENT "日志来源",`level` VARCHAR(10) COMMENT "日志级别",`host_name` VARCHAR(100) COMMENT "主机名",`msg` STRING COMMENT "日志内容",INDEX idx_msg (`msg`) USING INVERTED
)
ENGINE = OLAP
DUPLICATE KEY(`log_date`)
PARTITION BY RANGE (`log_date`)
(
)
DISTRIBUTED BY RANDOM BUCKETS 50
PROPERTIES ("compaction_policy" = "time_series","dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "DAY","dynamic_partition.create_history_partition" = "true","dynamic_partition.start" = "-30","dynamic_partition.end" = "7","dynamic_partition.prefix" = "p","compression"="zstd"
);
聚合模型: 主要用于告警指标 Metrics 的聚合。根据 Key 列聚合数据,通过提前聚合大幅提升性能,极大降低聚合查询时所需扫描的数据量和查询的计算量,适合有固定模式的报表类查询场景。
CREATE TABLE alarm_agg
(`id` LARGEINT,`first_trigger_time` DATETIME MIN COMMENT "第一次触发时间",`level` TINYINT MAX COMMENT "告警级别",`msg` STRING REPALCE COMMENT "告警内容",`num` INT SUM COMMENT "总数量"
)
AGGREGATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10;
当相同的 ID 进入时,将根据聚合函数进行处理。例如,对于触发时间,将提取最小值作为第一次触发时间。此外,还会对某些级别和内容进行替换,并对数量进行求和。这一过程可以提前对原始数据进行聚合,从而方便后续查询。通过这种方式,后续查询时能够扫描更少的数据。
-
数据聚合发生的时段分为三个:
- 每一批次数据导入的 ETL 阶段。每一批次导入的数据内部进行聚合,聚合后写入 Doris 集群。
- BE 进行数据 Compaction 阶段。BE 会对已导入的不同批次的数据进行进一步的聚合。
- 数据查询阶段。对于查询涉及到的数据,进行对应的聚合。
-
聚合模型的局限性
- 对
count(*)查询不友好, Doris 必须扫描所有的 AGGREGATE KEY 列,并且聚合后,才能得到语意正确的结果。 当聚合列非常多时,count(*)查询需要扫描大量的数据。
- 对
02 可扩展 JSON 数据使用半结构化数据类型 VARIANT
{"source":"PC","time":1722562556534,"userId":"d3079d82","properties": {"duration":8979,"mark":"标识","title":"标题","url":"/statistic/analysis"}
}
上述示例展示了一个典型的行为分析日志,其中 properties 是 JSON 格式的可扩展字段,存储了运行时长、标题和 URL 等子字段。然而,不同业务线在 properties 字段中的具体数据可能有所差异。例如,某业务线可能仅依据其标识来记录数据,如果该业务线涉及启动参数或启动状态,字段数量可能会减少,仅包含用户信息,如用户 ID。根据不同的事件类型,整个 properties 字段的内容也会有所不同。因此,在日志场景中,经常需要存储一些动态字段,如 Kubernetes 下的标签以及采集指标数据的标签等。
2-1 基于导入手动指定 json_path 静态 Schema 方案:
对于 properties 这种可扩展的 JSON 字段,最初在使用 Doris 导入时,手动配置 json_path 参数以映射到表的字段。为提供用户体验,我们还在页面上添加了可视化配置映射功能。该方案的优缺点都很明显。
- 优点:能够确保存储和查询的效率,所有字段都映射到 Doris 表中的普通列。相较于 JSON 文本数据,列式存储在存储和查询方面的优势非常明显。
- 缺点:不够灵活,无法动态扩展字段。每次修改都需手动调整表结构和映射关系,上下游系统需协同处理,这一过程繁琐且低效,容易出错。
2-2 基于 Doris Variant 动态 Schema 方案:
后来,我们将 Apache Doris 升级到了 2.1 版本,该版本提供了 VARIANT 数据类型,支持嵌套的不固定 Schema。VARIANT 数据类型可以存储任何合法的 JSON,可自动从 JSON 中抽取字段并推断其类型,并将这些字段存储为 VARIANT 列的子列。
使用 VARIANT 类型的表结构和查询语句如下所示:
CREATE TABLE log_variant (time BIGINT,source STRING,userId STRING,properties VARIANT
)
SELECT * FROM log_variant
WHERE time BETWEEN t1 AND t2AND source = 'PC'AND properties['duration'] > 100000;
拆分成子列并采用列式存储的方式,使得 VARIANT 具备良好的存储和分析性能。在进行聚合/过滤/排序等查询时,只需读取 VARIANT 子列数据(比如 properties['duration']) 即可,不会产生额外的数据读取和解析的开销(比如mark, title, url 等字段)。这种方案的性能与静态列相当,而相较于 JSON 字符串,性能提升存在数量级的差异。
在使用 VARIANT 类型的过程中,也遇到一些局限性并已找到解决方法。
-
早期版本 VARIANT 不能应用在聚合模型中, 升级到 2.1.3 以上的版本可以解决。
-
当 VARIANT 与 Group Commit 一起使用时,会出现过早反压影响写入性能的问题,升级到 2.1.5 以上的版本可以解决。
-
在 VARIANT 列上创建索引时,会对所有子列同时创建索引。如果子列数量过多,可能导致索引数量过多,从而影响写入性能。此外,同一 VARIANT 列的分词属性是一致的。例如,如果某列包含十个字段,并使用中文分词,那么这十个字段都将应用相同的中文分词规则。
-
日期、Decimal 等非标准 JSON 类型,会被默认推断成字符串类型,应尽可能从 VARIANT 中提取出来,用静态类型性能更好。
综合来看,建议需要 VARIANT 的用户使用最新的 2.1.x 版本,目前最新版本为 2.1.6。针对问题 3 和 4,社区已经开发了 VARIANT 内部 Schema 允许用户自定义的功能,预计将在后续版本中正式发布。
03 建表分区分桶优化
Doris 支持以表进行逻辑分区,一个 Table 下面有多个 Partition,每个 Partition 下有多个 Tablet。
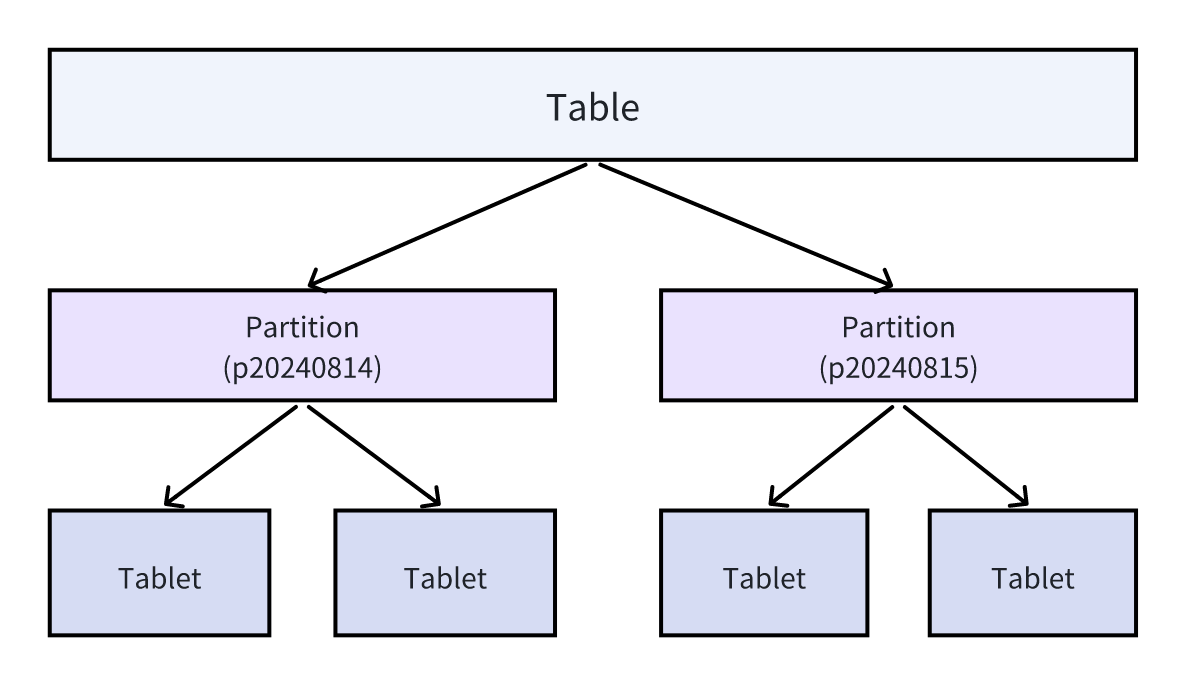
如上图所示,Partition 是按照时间进行分区的,假设今天是 8 月 15 日,那么今天写入的数据将写入到右边分区中。该分区的意义在于,将总体数据量进一步拆分,查询时只查符合条件的分区,以此来提升查询的效率。
Tablet 分桶一般有 Hash 和 Random 这两种方式:
Hash: 数据写入时将指定 Key 进行 Hash 计算,以确定该分配到哪个 Tablet。这种方法的优势在于,当根据 ID 进行 Hash 时,查询时可以精准地定位到相应的 Tablet。具体来说,先根据时间进行过滤,筛选到特定的数据位置,由于数据是基于 Hash 进行分桶的,这样可以轻松地命中相应的 Tablet。
Random: 在数据写入时,系统会随机选择一个 Tablet,并结合 Single Tablet Load 实现将整个 Batch 数据写入同一个 Tablet 的单个文件。这种方式不仅增加了 IO 批处理的规模、提高了写入的性能,还使得时间相近的数据能够存储在一起,从而优化了存储效率。
分桶数一般设置为磁盘数量的三倍,以确保每个 Tablet 的大小保持在 1-10GB 范围内。
CREATE TABLE log_record (log_date DATETIMEV2(3), level VARCHAR(10),host VARCHAR(100),message string,INDEX idx_host (host) USING INVERTED),INDEX idx_message (message) USING INVERTED PROPERTIES("parser" = "chinese", "support_phrase" = "true")
)
ENGINE = OLAP
DUPLICATE KEY(log_date)
PARTITION BY RANGE (log_date)()
DISTRIBUTED BY RANDOM BUCKETS 50
PROPERTIES ("compaction_policy" = "time_series","compression"="zstd“,"dynamic_partition.enable" = "true", "dynamic_partition.time_unit" = "DAY", "dynamic_partition.create_history_partition" = "true", "dynamic_partition.start" = "-30", "dynamic_partition.end" = “3", "dynamic_partition.prefix" = "p"
);
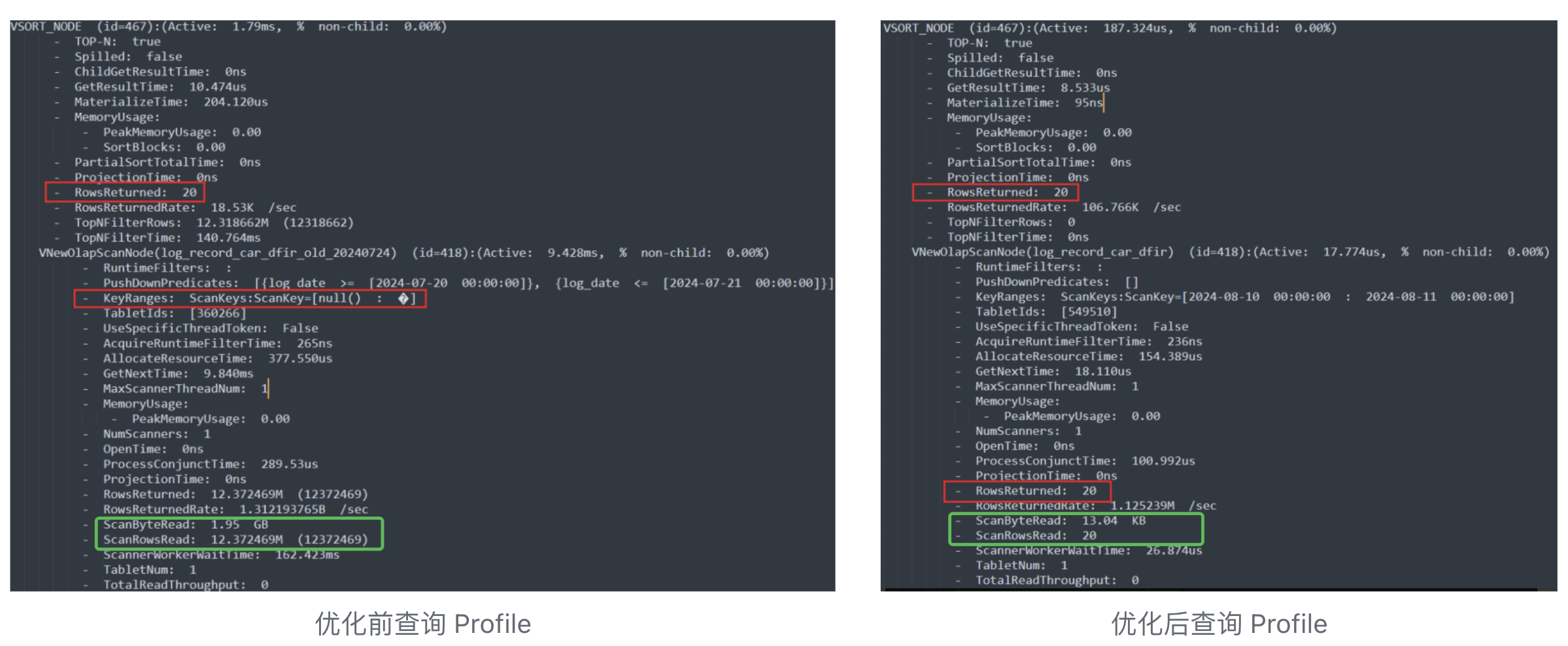
分区分桶优化前后的效果对比非常明显。 例如,下面的根据时间查询前 20 条数据。
SELECT * FROM log_record
WHERE log_date >= '2024-08-10 00:00:00.000' AND log_date <= '2024-08-11 00:00:00.000'
ORDER BY log_date DESC LIMIT 0, 20
优化前(左)虽然成功返回了 20 条数据,但其扫描的行数和数据量(ScanRowsRead, ScanBytesRead)远大于优化后(右)。优化后的查询以时间为分区,并以时间作为前缀索引,该方式适用于分页场景下,能够更好的提高查询的性能,如红色圈注处,只需在每个节点扫描前 20 行数据,即可完成查询。
04 写入优化
-
FE 参数优化:尽量让每个节点的 Tablet 均匀
enable_round_robin_create_tablet = truetablet_rebalancer_type = partition
-
BE 参数优化:增加写入 Buffer Size 的大小,
write_buffer_size = 1073741824 -
Stream Load 参数优化:设置单 Tablet 写入,
load_to_single_tablet=true
我们会在写入前攒批,压力分摊到写入模块:
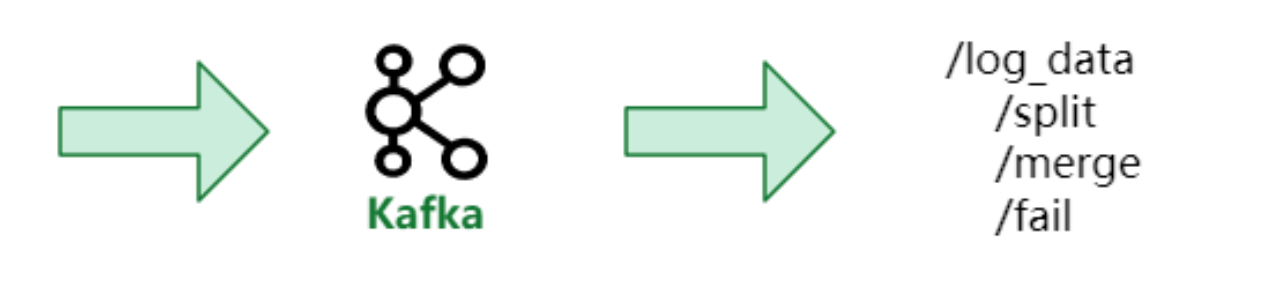
写入前攒批与 Group Commit 原理相似(为什么不使用 Group Commit?最初在使用时, Group Commit 还未发布),将 Kafka 消费的数据进行本地存储,也就是说相当于在写入 Doris 之前,数据已经被处理完成。通过这样的方式将写入压力分摊至写入模块,可有效减轻 BE 的压力。
此外,Doris 提供了两种 compaction 策略:size_based 及 time_series,其中 time_series 适用于时序场景。
时序数据指每批导入的数据具有时间上的顺序性。由于数据写入到 Tablet 中是有序的,因此在合并时,我们可以直接对 Segment 文件进行合并。然而,在实际应用场景需要注意,可能会出现新的数据插入到原本有序的数据中。比如,第一次写入 10-12 点数据,第二次写入 13-14 点数据,第三次又写入 8-9 点数据。在这种情况下,我们通常会默认采用基于 size 的 Compaction 策略。
优化完成后,在三节点集群测试下,每分钟可写入 600 万条数据,数据流量约 4.5G。整个过程中,磁盘 IO 均值不超过 9%,BE 内存占用均值为 4G,CPU 占用均值 9%。相对于其他系统,Doris 在写入优化方面是非常优秀的,写入吞吐高延迟低,而且资源占用率低。
收益总结
可观测性存储分析底座从 ELK 到 Loki 再到 Apache Doris 的架构升级,带来了多个方面的提升,总结起来还是最初提到的 3 个点:写的多,查的快,易于使用,具体表现在:
-
写的多: 可支撑日均 10TB,600 亿条日志的写入流量。与 Elasticsearch 相比,存储成本不到其 1/6。
-
查的快: 查询效率提升至少 10 倍,特别是在聚合分析、短语模糊匹配及 TOPN 命中前缀索引等场景下,性能提升效果显著。
-
易于使用: Doris Manager 使得管理多个集群变得简单,同时提供 Grafana 和自研的 Web 查询界面,方便用户进行日志检索和分析。
未来展望
未来,还将在 Doris 的基础上进行以下规划:
-
基于讯飞星火大模型的 AIOps:持续探索智能运维的最佳实践,包括日志异常监测、故障预测和故障诊断等。
-
用户行为分析:目前采用手动创建物化视图,未来探索如何利用 Doris 的物化视图能力实现自动物化。
-
存算分离:计划基于 3.0 版本的存算分离,实现中心化的读写分离以及租户的物理隔离。
相关文章:
科大讯飞:成本降低 60%,性能提升 10 倍,从 ES Loki 到 Apache Doris 可观测性存储底座升级
导读:科大讯飞星际日志中心经历了从 Elasticsearch 到 Loki,再到 Apache Doris 的可观测性存储分析底座升级,支持可观测三大支柱 Log Trace Metrics 的存储与分析,有效解决 Elasticsearch 成本高、Loki 查询慢的问题。Doris 能够在…...

ISO26262在汽车领域的意义
ISO 26262在汽车领域的意义非常重大,主要体现在以下几个方面: 一、提高汽车功能安全性 统一标准:ISO 26262是汽车电子系统的功能安全标准,为汽车制造商、供应商和相关行业提供了统一的框架和指南,确保汽车电子系统和软…...

11. 事件机制
① 事件模式必须基于 PSR-14 去实现。 ② Hyperf 的事件管理器默认由 hyperf/event 实现,该组件亦可用于其它框架或应用,只需通过 Composer 将该组件引入即可,默认已安装。 composer require hyperf/event一、概念 事件模式是一种非常适用于解耦的机制,分别存在以下 3 种角…...

MySQL 本地社区版安装(不登录) mysql官网链接
一、官网下载 官方地址 https://www.mysql.com/downloads/ 打开后先选择downloads 拉到最后选择 MySQL 社区版 然后继续选择社区版 在这此可以选择新版 选择 archives 可以选择其他版本下载 这里选择下面第一个就可以了 直接选择下载 下载后是安装包 直接双击安装 二…...

Redis Search系列 - 第三讲 拼写检查
拼写检查 - Spellchecking & Dict Spellchecking为拼写错误的搜索词提供建议。例如,术语“reids”可能是“redis”的拼写错误版本。 从v1.4开始,Redis Search可以为拼写错误的查询术语(term)生成替代的方案。拼写错误的术语是…...

Golang | Leetcode Golang题解之第492题构造矩形
题目: 题解: func constructRectangle(area int) []int {w : int(math.Sqrt(float64(area)))for area%w > 0 {w--}return []int{area / w, w} }...

Axure重要元件三——中继器函数
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢! 课程主题:中继器函数 主要内容:Item、Reperter、TargetItem 1、中继器的函数:Item\Reperter\TargetItem Item item:获取…...

MySQL8.0.40编译安装
近期MySQL发布了8.0.40版本,与之前的版本相比,部分依赖包发生了变化,因此重新编译一版,也便于大家参考。 1. 下载源码 选择对应的版本、选择源码、操作系统 如果没有登录或者没有MySQL官网账号,可以选择只下载 2. 进…...

JavaScript 第23章:WebSocket 与实时通讯
在JavaScript中使用WebSocket进行实时通信是一个非常实用且强大的功能。下面我们将详细介绍WebSocket协议的基础知识、如何使用WebSocket对象以及如何构建一个简单的实时通信应用。 WebSocket 协议 WebSocket是一个在单个TCP连接上进行全双工通信的协议。WebSocket使得数据可…...

简单汇编教程10 数组
目录 实践:相加连续的数 数组是在内存中连续的一串变量。我这样说,可能你已经想到的大致的定义了: NUMBERS DW 34, 45, 56, 67, 75, 89 现在我们就定义了一个Number数组,里面存放的连续的六个数字:34, 45, 56, …...

Jsoup在Java中:解析京东网站数据
对于电商网站如京东来说,其页面上的数据包含了丰富的商业洞察。对于开发者而言,能够从这些网站中提取有价值的信息,进行分析和应用,无疑是一项重要的技能。本文将介绍如何使用Java中的Jsoup库来解析京东网站的数据。 Jsoup简介 …...
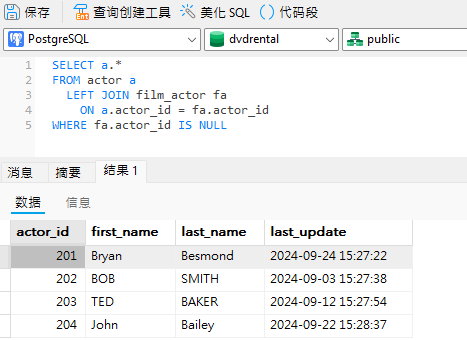
SQL 干货 | SQL 反连接
最强大的 SQL 功能之一是 JOIN 操作,它提供了一种优雅而简单的方法,将一个表中的每一条记录与另一个表中的每一条记录结合起来。不过,有时我们可能想从一个表中找到另一个表中没有的值。正如我们将在今天的博客文章中看到的,通过包…...
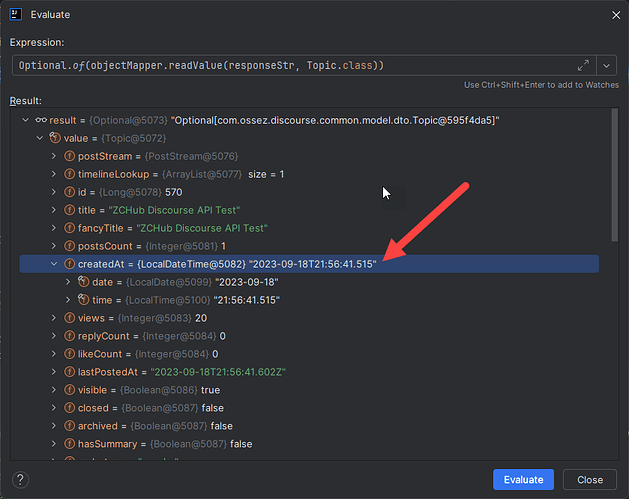
JSON 反对序列化 public final class LocalDateTime 日期格式错误
错误日志为: java.lang.RuntimeException: com.fasterxml.jackson.databind.exc.InvalidDefinitionException: Cannot construct instance of java.time.LocalDateTime (no Creators, like default construct, exist): no String-argument constructor/factory meth…...

Java 集合
1. 集合框架概述 集合框架(Collection Framework) 是 Java 中为处理一组对象而设计的一套标准化 API,它包括一组通用的接口、实现类和算法。这些接口和类为各种数据结构和操作方法提供了统一的实现方式,使得开发者可以轻松地对数…...

爬虫日常实战
爬取美团新闻信息,此处采用两种方法实现: 注意点:因为此处的数据都是动态数据,所以一定要考虑好向下滑动数据包会更新的情况,不然就只能读取当前页即第一页数据,方法一通过更新ajax数据包网址页数…...

复写零--双指针
一:题目描述 题目链接:. - 力扣(LeetCode) 二:算法原理分析 三:代码编写 void duplicateZeros3(vector<int>& arr) {int dest -1, cur 0, n arr.size();//1.找到要复写的最后一个数字while …...

跟着小土堆学习pytorch(二)——TensorBoard和Transform
文章目录 一、TensorBoard1.1 add_scalar()1.1,1 报错:TypeError: MessageToJson() got an unexpected keyword argument including_default_value_fields1.1.2 图像重叠1.1.3 代码展示 1.2 add_image()1.2.1 代码 二、transform2.1 介绍——对图片进行一些变化2.2 …...

自由学习记录(10)
Sprite Packer ~Mode & 图集 packer Project Setting经常是金屋藏娇 创建的项目如果不是2d项目,则默认disable打包 编辑模式就是你没点运行看游戏效果,在狼狈敲码创对象写逻辑的那个状态, 运行模式从点了|>之后,就一直…...

Redis提供了专门的命令来实现自增操作
Redis中的自增操作并不是直接通过CAS(Compare and Set)操作实现的。Redis提供了专门的命令来实现自增操作,这些命令能够确保操作的原子性,而不需要显式地使用CAS机制。 Redis中的自增操作 Redis中的自增操作主要依赖于以下几个命…...

uniapp修改input中placeholder样式
Uniapp官方提供了两种修改的属性方法,但经过测试,只有 placeholder-class 属性能够生效 <input placeholder"请输入手机验证码" placeholder-class"input-placeholder"/><!-- css --> <style lang"scss" s…...

模型微调加速:OpenClaw对接nanobot的LoRA训练
模型微调加速:OpenClaw对接nanobot的LoRA训练 1. 为什么选择OpenClawnanobot进行模型微调 去年我在尝试用Qwen3-4B模型处理专业领域任务时,发现直接使用基础模型的效果总差强人意。模型要么对专业术语理解不到位,要么生成的回答缺乏领域特性…...

Qwen3-0.6B-FP8逻辑推理能力实测:解决经典谜题与数学问题
Qwen3-0.6B-FP8逻辑推理能力实测:解决经典谜题与数学问题 最近在尝试一些轻量级的AI模型,发现Qwen3-0.6B-FP8这个小家伙挺有意思。它体积不大,但官方宣称在逻辑推理方面有不错的表现。这让我很好奇,一个只有6亿参数的模型&#x…...

别再折腾无障碍服务了!用Android蓝牙HID实现投屏反控的保姆级避坑指南
蓝牙HID协议在Android投屏反控中的深度实践 如果你正在开发一款类似Scrcpy的Android投屏工具,肯定遇到过这样的困境:无障碍服务(AccessibilityService)的授权流程繁琐且容易被厂商拦截,反射调用InputManagerService又需要系统级权限。这时候&…...

S32K144 LPUART中断接收丢字节?手把手教你用模拟空闲中断搞定Modbus RTU
S32K144 LPUART通信优化:模拟空闲中断实现Modbus RTU稳定传输 工业控制系统中,RS485总线上的Modbus RTU通信对时序和稳定性有着严苛要求。当使用NXP S32K144这类汽车级MCU时,开发者常会遇到一个典型问题:LPUART模块在连续接收多字…...

技术赋能B端拓客:号码核验行业的革新与实践,氪迹科技法人号码核验系统,阶梯式价格
2026年,随着B端市场竞争的持续加剧,“精准获客、降本增效”已从行业口号转变为企业生存发展的核心诉求,号码核验作为B端拓客全流程的前置关键环节,其服务质量直接决定了拓客效率、人力效能与投入回报比,成为影响企业拓…...

AI专著写作指南:深度剖析热门工具,助你专著创作一步到位
撰写学术专著的挑战与AI解决方案 撰写学术专著是一项严峻的挑战,它不仅考验着研究者的学术能力,还对心理承受能力提出了很高的要求。与论文写作常常可以依赖团队的支持不同,专著的创作更多的是独立作战。从选题到框架设计,再到细…...

Remotely远程控制会话录制:完整监控与分析指南
Remotely远程控制会话录制:完整监控与分析指南 【免费下载链接】Remotely A remote control and remote scripting solution, built with .NET 7, Blazor, and SignalR. 项目地址: https://gitcode.com/gh_mirrors/re/Remotely Remotely是一款基于.NET、Blaz…...
)
MySQL误删数据别慌!手把手教你用binlog2sql从ROW格式日志恢复(附常见报错解决方案)
MySQL数据恢复实战:从误删到完美还原的完整指南 凌晨三点,当大多数人都沉浸在梦乡时,数据库管理员小李却被一阵急促的电话铃声惊醒。生产环境的核心用户表被误操作清空,数百万条用户数据瞬间消失。这种场景对于任何DBA来说都是噩梦…...

3个核心维度解析iOS数据取证:iLEAPP从入门到精通
3个核心维度解析iOS数据取证:iLEAPP从入门到精通 【免费下载链接】iLEAPP iOS Logs, Events, And Plist Parser 项目地址: https://gitcode.com/gh_mirrors/il/iLEAPP 一、核心价值:iOS数据解析的全能工具 iLEAPP(iOS Logs, Events, …...

从投稿到接收:我的IEEE SPL完整时间线复盘与经验总结
从投稿到接收:我的IEEE SPL完整时间线复盘与经验总结 去年夏天,当我收到IEEE Signal Processing Letters(SPL)的录用邮件时,实验室的咖啡机正发出熟悉的咕噜声。那一刻,我意识到这杯咖啡比往常更香——不是…...