Redis|延迟双删策略的优点和缺点是什么?
延迟双删策略是什么?
延迟双删策略是一种保证缓存与数据库数据一致性的方法,特别适用于高并发场景下的缓存更新。其核心思想是:在更新数据库时,不仅删除一次缓存,还在短时间后再进行一次延迟删除,以避免并发问题导致的数据不一致。
延迟双删策略的步骤
- 第一次删除缓存:在更新数据库之前,先删除对应的缓存,确保缓存中不会存在旧数据。
- 更新数据库:执行数据库更新操作。
- 延迟一段时间后,再次删除缓存:为了防止在数据库更新后立即有并发请求读到了旧缓存数据,延迟一定时间(比如 1 秒)后,再次删除缓存,确保缓存中不存在陈旧的数据。
为什么需要延迟再删一次缓存?
在高并发的场景下,延迟双删策略可以有效避免以下两种常见的问题:
- 更新数据库后立即有请求查询:当某个线程刚更新完数据库,在其还未重新更新缓存前,有其他线程同时查询到了旧缓存数据。这种情况会导致数据库中的新数据还没被缓存,查询到的却是旧数据。
- 脏数据回填缓存:由于并发请求的存在,数据库更新后有可能缓存还没被删除或者重建,导致旧缓存被重新写入。
延迟双删策略的优点
- 提高数据一致性:通过延迟删除可以减少缓存中的陈旧数据,避免因并发请求导致的缓存数据与数据库数据不一致的问题。
- 减少缓存更新压力:相比于每次数据库更新都立即更新缓存,延迟双删避免了频繁的缓存更新请求,降低了缓存服务器的压力。
- 简单易实现:不需要对现有的缓存系统做太大的修改,只需在更新逻辑中加入两次删除操作,成本较低。
延迟双删策略的缺点
- 延迟时间的难以确定:延迟多久再删除缓存是一个难点。如果延迟时间太短,可能仍然会出现并发问题;如果延迟时间太长,则可能增加缓存中的陈旧数据存在的时间,影响数据一致性。
- 并发高时可能出现不一致:即使有延迟双删,极端高并发场景下(如延迟期间有大量请求访问),仍然可能出现数据不一致的情况。比如在延迟时间内,有大量读请求仍然会命中旧缓存。
- 多次缓存删除带来额外开销:延迟删除缓存意味着每次数据库更新后都要进行两次缓存删除操作,虽然可以保证数据一致性,但也可能带来额外的性能开销,特别是在高并发场景下,缓存的删除和重建会增加负载。
延迟双删策略适用场景
延迟双删策略适合于那些需要在高并发环境下保证缓存与数据库一致性的场景,特别是在更新操作频繁的系统中,比如电商、社交平台等需要对大量缓存数据进行频繁更新的应用场景。
示例
假设我们有一个电商系统,当用户下单时,库存数据需要更新。延迟双删的实现大致如下:
// 更新库存的伪代码
public void updateInventory(String productId, int newInventory) {// 第一次删除缓存cache.delete(productId);// 更新数据库中的库存信息database.updateInventory(productId, newInventory);// 延迟一段时间再删除缓存try {Thread.sleep(1000); // 延迟1秒} catch (InterruptedException e) {e.printStackTrace();}// 再次删除缓存,确保数据一致性cache.delete(productId);
}
基础总结一下但是任然有问题:
延迟双删策略通过在数据库更新前和更新后延迟一段时间再次删除缓存,有效避免了在并发情况下缓存和数据库数据不一致的问题。虽然它能提高一致性,但需要合理设计延迟时间,并且在极高并发的场景下仍需考虑其他优化策略。
延迟双删策略无法完全做到强一致性!
延迟双删策略虽然能在一定程度上提高缓存与数据库的一致性,但它确实无法做到完全一致性,特别是在极高并发的情况下。下面是对这一点的详细分析:
为什么延迟双删策略不能做到彻底的一致性?
-
延迟时间难以完美把控:
- 延迟时间的设定是策略的核心,但它往往很难确定。设定的时间过短,可能无法覆盖到并发操作的峰值,从而导致旧缓存数据被读取。设定时间过长,则会影响系统性能和实时性。对于不同业务场景和流量模式,理想的延迟时间往往是动态变化的,这使得延迟双删的应用更具挑战性。
-
高并发场景下的并发写入问题:
- 在极高并发的场景下,即使使用延迟双删策略,仍可能出现多个线程同时操作缓存和数据库的情况。举个例子:
- 线程 A 在删除缓存后,开始更新数据库;
- 线程 B 在 A 更新数据库之前,查询到了缓存并回填了旧缓存数据;
- 线程 A 的延迟删除动作也无法及时清理掉线程 B 填充的旧缓存。 这种情况下,会导致缓存中的数据仍然是旧的,从而发生不一致。
- 在极高并发的场景下,即使使用延迟双删策略,仍可能出现多个线程同时操作缓存和数据库的情况。举个例子:
-
脏读问题:
- 在延迟删除的这段时间内,如果有并发的读取请求,可能会读到数据库更新后的旧缓存。这在某些实时性要求高的应用中是不可接受的,比如金融系统或订单处理系统,必须保证读到的数据是最新的。
-
网络延迟和异常情况:
- 网络延迟、系统抖动等不确定因素也会影响延迟双删的效果。在分布式系统中,延迟双删依赖于多个系统的协作(如缓存、数据库、应用服务),如果某个环节出现异常,如缓存删除失败、网络延迟较大等,都可能导致数据不一致。
一致性问题的进一步讨论
严格来说,延迟双删策略提供的一致性保证是最终一致性,即在一段时间内,缓存和数据库的数据可能会出现不一致的情况,但在系统恢复到稳定状态时,缓存和数据库的数据最终会一致。
- 强一致性(Strict Consistency)是指系统中每次读操作都能够获得最近的写操作的结果,要求每次数据读取都是最新的。这种一致性在延迟双删策略中是无法保证的。
- 最终一致性(Eventual Consistency)则意味着经过一段时间后,系统的数据会变得一致,但在某些瞬间,数据可能不一致。延迟双删策略通常保证的是这一类一致性。
替代或补充的优化策略
对于高并发场景或者对一致性要求特别严格的系统,延迟双删策略可能不够,因此需要引入其他优化策略:
-
分布式锁:
- 在缓存更新时使用分布式锁(如 Redis 的
SETNX加锁机制)确保只有一个线程能够更新缓存和数据库,避免并发写操作导致的缓存与数据库不一致。
- 在缓存更新时使用分布式锁(如 Redis 的
-
消息队列:
- 使用消息队列进行缓存更新操作,将数据库更新后的缓存操作通过消息队列异步处理,从而保证顺序性和一致性。
-
强制缓存更新:
- 对于实时性要求较高的系统,可以强制要求在每次读写操作时更新缓存,保证缓存和数据库的数据是一致的,代价是性能损失更大。
-
写通过策略(Write-through Cache):
- 直接在写入数据库时同步更新缓存,这样保证写入数据库的数据也一定进入缓存中,避免了缓存中存在旧数据的问题,但这增加了写操作的延迟。
-
读写分离:
- 可以通过数据库主从架构实现读写分离,将读取操作主要从缓存或者从库执行,减少对主库的压力,同时让主库专注于写操作并及时更新缓存。
强一致性的总结:
延迟双删策略虽然能在大部分场景下解决缓存与数据库不一致的问题,但它并不能保证强一致性,尤其是在高并发场景下或对一致性要求较高的系统中。其一致性保证更多的是最终一致性。如果业务系统对一致性要求较高,建议引入分布式锁、消息队列等其他优化策略来进一步提升一致性。
问题是为啥要延迟1s呢?不延迟可以吗?
延迟双删策略的核心目的是避免并发情况下缓存和数据库之间的短暂不一致问题。虽然延迟并不能阻止线程 B 并发操作,但它可以帮助我们在一个较短的时间窗口内修正数据的不一致性。我们来详细拆解一下这个问题:
问题核心:延迟 1 秒的目的
延迟的 1 秒钟确实是为了让数据库的更新有足够的时间被完全写入并提交,从而避免因为数据库更新延迟而导致的“脏数据”问题。具体来说,延迟 1 秒的主要目的是:
-
避免线程 A 更新数据库后立即读取脏数据:如果线程 A 在删除缓存和更新数据库后,马上读取数据库,可能会因为数据库还没有完全更新而读到旧数据。此时,如果缓存再次填充旧数据,会导致缓存不一致。延迟 1 秒的目的就是为了给数据库的更新操作留出足够的时间,让数据更新在数据库中被真正写入完成。
-
缓解线程 B 的并发读取问题:虽然延迟无法直接阻止线程 B 的并发操作,但如果线程 B 恰好在数据库还未更新完成时读取了旧数据并将其重新写入缓存,延迟后的第二次删除操作可以确保最终缓存中不会保留这些旧数据。因此,延迟 1 秒相当于一个最终修正手段,确保在并发场景下,旧数据不再保留太长时间。
并发情况下脏数据的问题
如果没有延迟,存在以下风险:
-
线程 A 更新数据库时可能存在延迟:数据库操作通常是有耗时的,尤其是在高并发场景下。如果线程 A 在数据库更新后立即读取缓存,可能读到的还是旧数据。如果没有延迟,线程 A 可能会直接填充缓存为旧数据。
-
线程 B 并发读取旧数据:在缓存删除和数据库更新之间的时间窗口内,线程 B 可能会读取旧的数据库数据,并将其重新写入缓存。如果没有延迟进行第二次缓存删除,旧数据将会长期存在于缓存中,导致缓存与数据库之间的数据不一致。
延迟并不是给线程 B 留的时间,而是给数据库写入时间
所以,延迟 1 秒的核心并不是为了让线程 B 等待,而是为了给数据库足够的时间完成更新,并确保缓存中不会保留因为并发读取而填充的旧数据。线程 A 的延迟删除缓存实际上是为了确保即便有线程 B 并发写入了旧数据,最终这些旧数据也会被删除,从而达到数据的一致性。
脏数据与缓存更新关系
如果线程 A 不进行延迟删除,那么在高并发的情况下:
- 数据库更新的速度可能跟不上线程 A 的缓存操作速度,导致线程 A 或其他线程读取到未更新的数据(脏数据)。
- 当并发请求(线程 B)读取旧数据时,这些旧数据会被重新写入缓存,导致缓存的数据和数据库中的数据不同步。
通过延迟删除缓存,可以确保线程 A 在更新数据库后,数据库中的数据有足够的时间更新完成,避免脏数据进入缓存。并且,即便有其他线程在缓存删除后的短时间内写入旧数据,延迟的第二次删除操作也能及时清除这些旧数据。
延迟1 秒的总结
延迟 1 秒的目的是为了给数据库更新操作预留时间,确保数据库在并发场景下能正确地完成更新,防止线程 A 或线程 B 在数据库还没更新完毕的情况下读取到旧数据。延迟删除缓存不是直接解决并发问题的手段,而是通过最终一致性的方式来确保缓存中不会长时间保留旧数据,减少缓存与数据库不一致的时间窗口。
如果并发场景特别复杂或者延迟时间难以估计,还可以引入其他手段(如分布式锁)来更加精细地控制缓存和数据库的同步问题。
相关文章:

Redis|延迟双删策略的优点和缺点是什么?
延迟双删策略是什么? 延迟双删策略是一种保证缓存与数据库数据一致性的方法,特别适用于高并发场景下的缓存更新。其核心思想是:在更新数据库时,不仅删除一次缓存,还在短时间后再进行一次延迟删除,以避免并…...

【计算机网络 - 基础问题】每日 3 题(五十二)
✍个人博客:https://blog.csdn.net/Newin2020?typeblog 📣专栏地址:http://t.csdnimg.cn/fYaBd 📚专栏简介:在这个专栏中,我将会分享 C 面试中常见的面试题给大家~ ❤️如果有收获的话,欢迎点赞…...

LogStash架构分析
一、什么是LogStash LogStash 是一个类似实时流水线的开源数据传输引擎,它像一个两头连接不同数据源的数据传输管道,将数据实时地从一个数据源传输到另一个数据源中。在数据传输的过程中,LogStash 还可以对数据进行清洗、加工和整理…...

2024最新最全【大模型学习路线规划】零基础入门到精通!,大模型学习干货分享,总结的太详细了
第一阶段:基础理论入门 目标:了解大模型的基本概念和背景。 内容: 人工智能演进与大模型兴起。 大模型定义及通用人工智能定义。 GPT模型的发展历程。 第二阶段:核心技术解析 目标:深入学习大模型的关键技术和工…...

QT界面开发:图形化设计、资源文件添加
设计界面介绍 此时我们创建项目时就可以选择添加UI选项了。 添加完之后,我们可以看到,文件中多出了一个存放界面文件的目录,下面有个.ui的界面文件。甚至pro的项目文件中也会添加一项内容。 我们点击界面文件中的.ui文件,我们可以…...
科大讯飞:成本降低 60%,性能提升 10 倍,从 ES Loki 到 Apache Doris 可观测性存储底座升级
导读:科大讯飞星际日志中心经历了从 Elasticsearch 到 Loki,再到 Apache Doris 的可观测性存储分析底座升级,支持可观测三大支柱 Log Trace Metrics 的存储与分析,有效解决 Elasticsearch 成本高、Loki 查询慢的问题。Doris 能够在…...

ISO26262在汽车领域的意义
ISO 26262在汽车领域的意义非常重大,主要体现在以下几个方面: 一、提高汽车功能安全性 统一标准:ISO 26262是汽车电子系统的功能安全标准,为汽车制造商、供应商和相关行业提供了统一的框架和指南,确保汽车电子系统和软…...

11. 事件机制
① 事件模式必须基于 PSR-14 去实现。 ② Hyperf 的事件管理器默认由 hyperf/event 实现,该组件亦可用于其它框架或应用,只需通过 Composer 将该组件引入即可,默认已安装。 composer require hyperf/event一、概念 事件模式是一种非常适用于解耦的机制,分别存在以下 3 种角…...

MySQL 本地社区版安装(不登录) mysql官网链接
一、官网下载 官方地址 https://www.mysql.com/downloads/ 打开后先选择downloads 拉到最后选择 MySQL 社区版 然后继续选择社区版 在这此可以选择新版 选择 archives 可以选择其他版本下载 这里选择下面第一个就可以了 直接选择下载 下载后是安装包 直接双击安装 二…...

Redis Search系列 - 第三讲 拼写检查
拼写检查 - Spellchecking & Dict Spellchecking为拼写错误的搜索词提供建议。例如,术语“reids”可能是“redis”的拼写错误版本。 从v1.4开始,Redis Search可以为拼写错误的查询术语(term)生成替代的方案。拼写错误的术语是…...

Golang | Leetcode Golang题解之第492题构造矩形
题目: 题解: func constructRectangle(area int) []int {w : int(math.Sqrt(float64(area)))for area%w > 0 {w--}return []int{area / w, w} }...

Axure重要元件三——中继器函数
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢! 课程主题:中继器函数 主要内容:Item、Reperter、TargetItem 1、中继器的函数:Item\Reperter\TargetItem Item item:获取…...

MySQL8.0.40编译安装
近期MySQL发布了8.0.40版本,与之前的版本相比,部分依赖包发生了变化,因此重新编译一版,也便于大家参考。 1. 下载源码 选择对应的版本、选择源码、操作系统 如果没有登录或者没有MySQL官网账号,可以选择只下载 2. 进…...

JavaScript 第23章:WebSocket 与实时通讯
在JavaScript中使用WebSocket进行实时通信是一个非常实用且强大的功能。下面我们将详细介绍WebSocket协议的基础知识、如何使用WebSocket对象以及如何构建一个简单的实时通信应用。 WebSocket 协议 WebSocket是一个在单个TCP连接上进行全双工通信的协议。WebSocket使得数据可…...

简单汇编教程10 数组
目录 实践:相加连续的数 数组是在内存中连续的一串变量。我这样说,可能你已经想到的大致的定义了: NUMBERS DW 34, 45, 56, 67, 75, 89 现在我们就定义了一个Number数组,里面存放的连续的六个数字:34, 45, 56, …...

Jsoup在Java中:解析京东网站数据
对于电商网站如京东来说,其页面上的数据包含了丰富的商业洞察。对于开发者而言,能够从这些网站中提取有价值的信息,进行分析和应用,无疑是一项重要的技能。本文将介绍如何使用Java中的Jsoup库来解析京东网站的数据。 Jsoup简介 …...
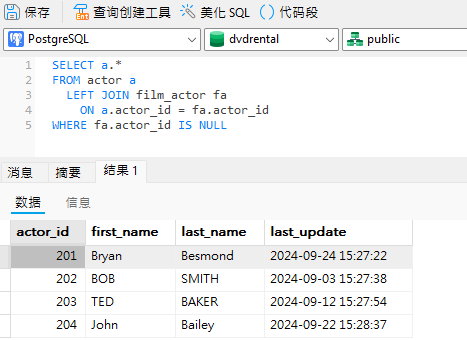
SQL 干货 | SQL 反连接
最强大的 SQL 功能之一是 JOIN 操作,它提供了一种优雅而简单的方法,将一个表中的每一条记录与另一个表中的每一条记录结合起来。不过,有时我们可能想从一个表中找到另一个表中没有的值。正如我们将在今天的博客文章中看到的,通过包…...
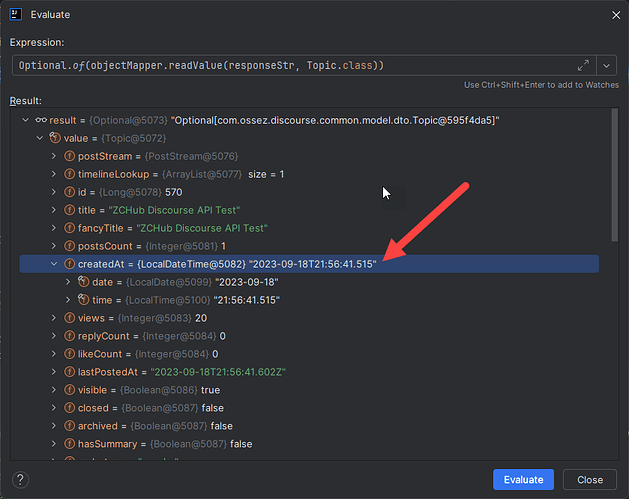
JSON 反对序列化 public final class LocalDateTime 日期格式错误
错误日志为: java.lang.RuntimeException: com.fasterxml.jackson.databind.exc.InvalidDefinitionException: Cannot construct instance of java.time.LocalDateTime (no Creators, like default construct, exist): no String-argument constructor/factory meth…...

Java 集合
1. 集合框架概述 集合框架(Collection Framework) 是 Java 中为处理一组对象而设计的一套标准化 API,它包括一组通用的接口、实现类和算法。这些接口和类为各种数据结构和操作方法提供了统一的实现方式,使得开发者可以轻松地对数…...

爬虫日常实战
爬取美团新闻信息,此处采用两种方法实现: 注意点:因为此处的数据都是动态数据,所以一定要考虑好向下滑动数据包会更新的情况,不然就只能读取当前页即第一页数据,方法一通过更新ajax数据包网址页数…...

Stata 数据处理实战:时间序列数据的日期转换与聚合
1. 时间序列数据处理的常见痛点 刚接触时间序列分析的朋友们,经常会遇到这样的困扰:从Excel导入的数据明明是日期格式,到了Stata里却变成了看不懂的字符;想按周汇总销售数据,却发现系统根本不认识"2023-W15"…...

基于ASR与NLP的法庭音频智能分析系统:架构、微调与法律场景实践
1. 项目概述:当法庭记录“开口说话” 在司法与法律科技领域,数据正以前所未有的方式重塑工作流程。传统的法庭记录,无论是书记员手写的笔录,还是后来普及的录音录像,其核心价值在于“记录”本身——它们是静态的、被动…...

Windows键盘记录器:为什么需要、它是什么、以及如何正确使用
Windows键盘记录器:为什么需要、它是什么、以及如何正确使用 【免费下载链接】keylogger Keylogger for Windows. 项目地址: https://gitcode.com/gh_mirrors/keylogg/keylogger 在当今数字化时代,键盘记录器作为系统监控和用户行为分析工具&…...

ReRAM与PCM存内计算:突破冯·诺依曼瓶颈,赋能边缘AI与类脑计算
1. 从冯诺依曼瓶颈到存内计算:一场芯片架构的范式转移最近几年,但凡关注芯片和人工智能领域的朋友,肯定对“存内计算”这个词不陌生。它听起来像是一个技术术语,但背后直指一个困扰了我们半个多世纪的计算机根本性难题:…...

02数据模型与单词仓库-鸿蒙PC端Electron开发
欢迎加入开源鸿蒙PC社区 https://harmonypc.csdn.net/ 源码仓库 https://atomgit.com/qq_33247427/englishProject.git 效果截图 第2篇:数据模型与单词仓库 系列教程导航 篇号 标题 状态 01 环境搭建与项目创建 ✅ 已完成 02 数据模型与单词仓库 本篇 …...

RAG:嵌入模型评估与选型
在RAG系统中,嵌入模型是检索质量的关键组件,它决定了系统能否真正“理解”用户意图并从海量知识中精准召回相关信息,其语义匹配精度直接决定了整个RAG的性能上限。 一、嵌入模型评估指标 1.1 公开基准 MTEB v2 是目前全球公认最权威的大规…...

Factool:大语言模型事实核查工具包的设计原理与工程实践
1. 项目概述:当AI学会“查证”,我们该如何信任它?最近在折腾大语言模型(LLM)应用落地的朋友,估计都绕不开一个头疼的问题:幻觉(Hallucination)。你让模型写一篇行业报告&…...

搞懂这6个人工智能核心概念,再也不会被行业黑话难住
文章目录前言一、大模型(LLM):读遍天下书的超级学霸1. 到底什么是大模型?2. 大模型的“超能力”与“致命缺陷”二、微调(Fine-tuning):给学霸补专业课1. 微调到底在调什么?2. 2026年…...

JPlag代码抄袭检测:你的学术诚信守护神
JPlag代码抄袭检测:你的学术诚信守护神 【免费下载链接】JPlag State-of-the-Art Source Code Plagiarism & Collusion Detection. Check for plagiarism in a set of programs. 项目地址: https://gitcode.com/gh_mirrors/jp/JPlag 你是否曾为学生的代码…...

017、GPS原理与定位基础
飞控算法从入门到精通 017 | GPS原理与定位基础 一、一次深夜炸机的教训 去年在郊外调试一架四轴,飞控是自研的Pixhawk变体,GPS模块用的u-blox M8N。起飞后悬停正常,切到Loiter模式后飞机开始缓慢漂移,大约30秒后突然朝东北方向加速,我切回Stabilize已经来不及——眼睁…...