yjs机器学习数据操作01——数据的获取、可视化
数据的获取
1.库与模块:
import sklearnfrom sklearn import datasets2.数据集获取的API及解释
对于sklearn的数据获取,主要分为两大部分,分别是“小数据集的获取——load_xxx”和“大数据集的获取fetch_xxx”
a.datasets.load_xxx():
load_xxx:这些数据集通常加载到内存中,适合快速实验和模型验证
常见的有
load_iris():加载经典的鸢尾花(Iris)数据集。load_digits():加载手写数字数据集。load_wine():加载葡萄酒分类数据集。load_breast_cancer():加载乳腺癌分类数据集。load_diabetes():加载糖尿病回归数据集。load_linnerud():加载 Linnerud 数据集(多输出回归)。
b.datasets.fetch_xxx()
fetch_xxx:从网络下载数据集,适用于较大规模的真实世界数据集常见的有:
fetch_20newsgroups():加载20类新闻组数据集,用于文本分类任务。fetch_olivetti_faces():加载 Olivetti 人脸数据集,用于图像处理任务。fetch_lfw_people():加载 LFW(Labelled Faces in the Wild)人脸识别数据集。fetch_lfw_pairs():加载 LFW 人脸对数据集,用于人脸匹配。fetch_covtype():加载 Covertype 数据集,用于分类问题。fetch_rcv1():加载 RCV1(Reuters Corpus Volume I)数据集
3.数据集的属性
import sklearn
from sklearn import datasets
data=datasets.load_iris()"""1.数据集的具体数据/本质上也是特征值:"""
data["data"] """2.数据集的特征名:"""
data.feature_names"""3.数据集的目标名称/标签名称"""
data.target_names"""4.数据集的目标值/标签值"""
data.target"""5.数据集的总体描述"""
data.DESCR
数据的可视化
1.库与模块:
import seaborn as sns
#seaborn是对matplotlib的更高级api的封装
2.可视化的API及解释——lmplot
sns.lmplot(x= , y= , data= ,hue= , fit_reg=True/False....)参数说明:
x/y=... : 是指定画图时的x坐标是啥,y是啥,这里不是将其命名,而是指出以什么参数为x、y轴 ;一般是某一个“属性”,即特征
························································································································
data= :这里指定数据,并且数据一定要是DataFrame结构
这里就涉及到将load_或者fetch获得的数据结构进行变化:
Data_load=pd.DataFrame(data["data"],columns=data.feature_names)··························································································································
hue= :这里是指按照什么进行分类,
data【“data”】获取的数据一般是这样的:
一般我们把它再加一列,就是将每个样本的目标值,即标签加入进去
Data_load["target"]=data.target
所以这里的hue一般这样写:
hue=Data_load.target或者["target"]
··························································································································
fit_reg=T/F:是否进行线性拟合
整体代码:
# 将数据用seaborn库进行可视化 data_1=pd.DataFrame(data=dataSet1["data"],columns=dataSet1.feature_names) data_1["target"]=dataSet1.target print(data_1) print(data_1.columns[0]) sns.lmplot(x=data_1.columns[0], y=data_1.columns[1], data=data_1, hue="target") plt.xlabel("cols1") plt.ylabel("cols2") plt.title("鸢尾花") plt.show()结果:
注意图的相关显示的属性,如x坐标名称,y坐标名称,图的题目等是同matplotlib那个一样,都是 “plt.xxx”
最后的展示也是“plt.show()”



整体代码:
import matplotlib.pyplot as plt import pandas as pd import sklearn import seaborn as sns from sklearn import datasets import numpy as np plt.rcParams['font.family'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = FalsedataSet1 = datasets.load_iris() print("鸢尾花数据集如下:") print(dataSet1) print("鸢尾花的属性:") print("特征数据数组:") print(dataSet1["data"]) print("标签值:") print(dataSet1.target) print("标签名:") print(dataSet1.target_names) print("特征名:") print(dataSet1.feature_names) print("数据描述:") print(dataSet1.DESCR)# 将数据用seaborn库进行可视化 data_1=pd.DataFrame(data=dataSet1["data"],columns=dataSet1.feature_names) data_1["target"]=dataSet1.target print(data_1) print(data_1.columns[0]) sns.lmplot(x=data_1.columns[0], y=data_1.columns[1], data=data_1, hue="target") plt.xlabel("cols1") plt.ylabel("cols2") plt.title("鸢尾花") plt.show()结果:(截取部分片段)


相关文章:

yjs机器学习数据操作01——数据的获取、可视化
数据的获取 1.库与模块: import sklearnfrom sklearn import datasets 2.数据集获取的API及解释 对于sklearn的数据获取,主要分为两大部分,分别是“小数据集的获取——load_xxx”和“大数据集的获取fetch_xxx” a.datasets.load_xxx(): …...
w~自动驾驶合集9
我自己的原文哦~ https://blog.51cto.com/whaosoft/12320882 #自动驾驶数据集全面调研 自动驾驶技术在硬件和深度学习方法的最新进展中迅速发展,并展现出令人期待的性能。高质量的数据集对于开发可靠的自动驾驶算法至关重要。先前的数据集调研试图回顾这些数据集&…...

232. 用栈实现队列 【复习链表】-用自定义链表实现栈 用栈实现队列
232. 用栈实现队列 已解答 简单 相关标签 相关企业 请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty): 实现 MyQueue 类: void push(int x) 将元素 x 推到队列的末尾int pop() 从队…...
)
G-Set(增长集合,Grow-Only Set)
一、概念 G-Set(增长集合,Grow-Only Set)是一种冲突自由复制数据类型(Conflict-Free Replicated Data Type, CRDT),用于在分布式系统中同步和合并数据,而不需要中央协调器。G-Set 支持两种操作…...

《Vue.js 组件开发秘籍:从基础到高级》
Vue.js 组件开发是构建 Vue 应用程序的核心方法之一。以下是对 Vue.js 组件开发的介绍: 一、什么是 Vue.js 组件? 在 Vue.js 中,组件是可复用的 Vue 实例,它们封装了特定的功能和用户界面。每个组件都有自己独立的模板、逻辑和样…...
【Next.js 项目实战系列】03-查看 Issue
原文链接 CSDN 的排版/样式可能有问题,去我的博客查看原文系列吧,觉得有用的话,给我的库点个star,关注一下吧 上一篇【Next.js 项目实战系列】02-创建 Issue 查看 Issue 展示 Issue 本节代码链接 首先使用 prisma 获取所有…...

Android Settings 设置项修改
Settings 设置项 在 Android 系统上,WRITE_SETTINGS 这个权限从 API 1 就已经开始有了。 通过在 app 中设置权限 android.permission.WRITE_SETTINGS 允许 app 读/写 系统设置。 在官方文档的描述中,还有一段注意事项: Note: If the app targets API level 23 or higher,…...

Windows远程桌面到Ubuntu
在Ubuntu系统中,默认情况下root账户是被禁用的,为了安全起见,建议不要直接使用root账户登录图形界面。但是,如果出于特定的管理或维护需求,您可以按照以下步骤启用和使用root账户登录图形界面: 启用root账户…...
)
解释 RESTful API,以及如何使用它构建 web 应用程序(AI)
RESTful API(Representational State Transfer)是一种基于HTTP协议的软件架构风格,用于构建可扩展、可维护和可重用的网络服务。 RESTful API的特点包括: 1. 基于资源:每个API都代表一个或多个资源,这些资…...

NestJs:处理身份验证和授权
使用 Nest.js 开发项目时,处理身份验证和授权是常见的需求,可以采用以下架构和实现方式。 架构 用户认证模块 (Auth Module): 服务 (Service): 处理用户登录逻辑,生成 JWT(JSON Web Token),以及验证 token…...
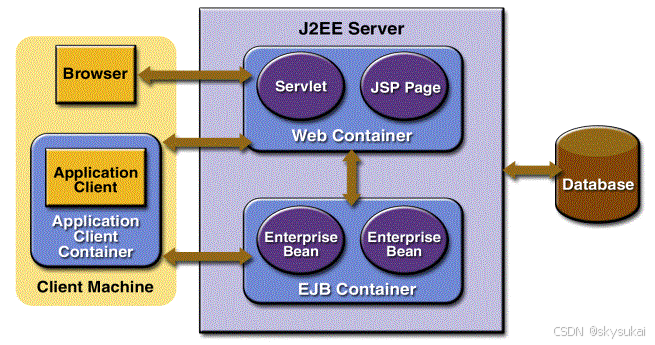
Java EE规范
1、简介 Java EE的全称是Java Platform, Enterprise Edition。早期Java EE也被称为J2EE,即Java 2 Platform Enterprise Edition的缩写。从J2EE1.5以后,就改名成为Java EE。一般来说,企业级应用具备这些特征:1、数据量特别大&…...

Ollama及其Open-WebUI部署更新
目录 1 安装ollama 2 安装Open-WebUI 2.1 不使用容器安装open-webui 2.2 使用Docker安装open-webui 2.3 基于docker升级open-webui 1 安装ollama curl -fsSL https://ollama.com/install.sh | sh启动、关闭ollama systemctl start ollama systemctl stop ollama sys…...

手写 | 设计模式
这里写目录标题 观察者 vs 发布订阅 观察者 vs 发布订阅 参考代码 观察者模式,一对多,两个角色:观察者observer和被观察者/主题Subject。 Subject维护一个数组,记录有哪些Observer;通过调自身的noticefy方法…...

基于深度学习的地形分类与变化检测
基于深度学习的地形分类与变化检测是遥感领域的一个关键应用,利用深度学习技术从卫星、无人机等地球观测平台获取的遥感数据中自动分析地表特征,并识别地形的变化。这一技术被广泛应用于城市规划、环境监测、灾害预警、土地利用变化分析等领域。 1. 地形…...

进程、线程、协程
文章目录 前言一、易混概念1.1 同步vs异步1.2 并发vs并行 二、进程(Process)2.1进程概念2.2 进程三个基本状态2.3多进程方式编程 三、线程(Thread)3.1 线程的引入3.2 线程概念3.3 多线程编程3.4 GIL对多线程的影响3.5 GIL是否意味…...
——元件基础(完整版))
嵌入式工程师成长之路(1)——元件基础(完整版)
系列文章目录 1.元件基础 2.电路设计 3.PCB设计 4.元件焊接 5.板子调试 6.程序设计 7.算法学习 8.编写exe 9.检测标准 10.项目举例 11.职业规划 文章目录 前言一、认识元件①、认识元件②、认识封装二、电阻1.上拉电阻与下拉电阻①、定义②、应用③、阻值选择④、因上下拉电…...

在Ubuntu 20.04 上安装 CoppeliaSim
在 Ubuntu 20.04 上安装 CoppeliaSim Edu V4.6.0 rev18 的步骤如下: 1. 下载安装文件: 首先,确保您已经下载了 CoppeliaSim_Edu_V4_6_0_rev18_Ubuntu20_04.tar.xz 文件。您可以从 Coppelia Robotics 的官方网站下载。 2. 解压缩文件: 打开终端&#…...
)
pulseaudio的相关操作(二)
这篇文章主要介绍pulseaudio playback的相关API,pulseaudio playback的具体实例可以参考[2]。如果用pulseaudio实现playback,简单地说就是创建一个playback stream,然后指定这个stream的sink,再定期的向这个stream中写数据。 mai…...

Selenium自动化测试工具
一 .Selenium简介 是一个用于Web应用程序测试的工具 Selenium的核心功能之一是测试软件在不同浏览器和操作系统上的兼容性,确保软件功能与用户需求的一致性,提升用户体验。 自动化脚本生成与执行 Selenium支持自动录制用户操作并生成多种编程语言的测…...
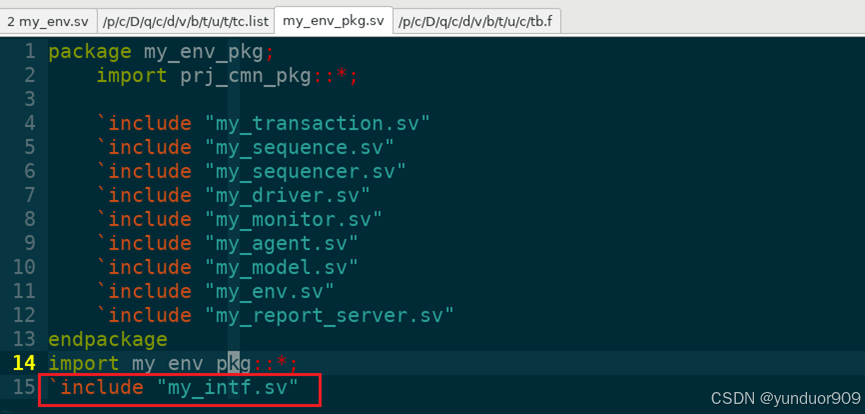
优化UVM环境(九)-将interface文件放在env pkg外面
书接上回: 优化UVM环境(八)-整理project_common_pkg文件 My_env_pkg.sv里不能包含interface,需要将my_intf.sv文件放在pkg之外...

Anno 1800 Mod Loader终极指南:如何轻松解锁《纪元1800》无限模组潜力
Anno 1800 Mod Loader终极指南:如何轻松解锁《纪元1800》无限模组潜力 【免费下载链接】anno1800-mod-loader The one and only mod loader for Anno 1800, supports loading of unpacked RDA files, XML merging and Python mods. 项目地址: https://gitcode.com…...

收藏!小白也能入行:AI训练师是什么?值不值?怎么学?
AI冲击重复性岗位,但AI训练师需求激增347%。本文解读AI训练师(非程序员)的工作内容(数据标注、Prompt设计等)、市场数据(薪资60k、缺口百万)、适合人群(内容创作者、白领、应届生&am…...

Elasticsearch管理利器:es-client全方位指南与实战技巧
Elasticsearch管理利器:es-client全方位指南与实战技巧 【免费下载链接】es-client elasticsearch客户端,issue请前往码云:https://gitee.com/qiaoshengda/es-client 项目地址: https://gitcode.com/gh_mirrors/es/es-client 你是否曾…...

ZimaOS Blue:本地优先AI代理运行时,打造私有化智能助手
1. 项目概述:ZimaOS Blue,一个为“大胆构建者”准备的本地优先AI代理运行时 如果你和我一样,对当前AI应用生态里那些动辄需要联网、依赖特定云服务、数据隐私存疑的“智能助手”感到厌倦,同时又渴望一个能真正运行在自己设备上、…...

如何通过HWInfo插件实现精准硬件监控与风扇控制:完整配置指南
如何通过HWInfo插件实现精准硬件监控与风扇控制:完整配置指南 【免费下载链接】FanControl.HWInfo FanControl plugin to import HWInfo sensors. 项目地址: https://gitcode.com/gh_mirrors/fa/FanControl.HWInfo 想要让电脑散热系统更智能、更安静吗&#…...

2026 年行业真相:履职规范背后的管理秘密
现场冲突:安全与进度的激烈碰撞在工程建设领域,安全与进度的冲突一直是个老大难问题。就拿上海中心的建设来说,如此庞大复杂的项目,施工过程中安全管理难度极大。在某些施工阶段,为了赶进度,部分施工人员可…...

GraphQL在后端开发中的应用与优势
在现代后端开发领域,GraphQL作为一种新兴的API查询语言,正迅速改变着开发者构建和交互数据的方式。与传统的RESTful API相比,GraphQL提供了一种更灵活、高效的数据获取机制,使前端能够精准地请求所需数据,避免了过度获…...

为个人AI助手项目集成多模型API实现成本与性能平衡
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为个人AI助手项目集成多模型API实现成本与性能平衡 构建个人AI助手是许多独立开发者热衷的项目。在开发过程中,一个常见…...

Anno 1800模组加载器:企业级XML智能合并与高性能游戏扩展架构实现指南
Anno 1800模组加载器:企业级XML智能合并与高性能游戏扩展架构实现指南 【免费下载链接】anno1800-mod-loader The one and only mod loader for Anno 1800, supports loading of unpacked RDA files, XML merging and Python mods. 项目地址: https://gitcode.com…...

Android开发终极指南:Sunflower项目中ViewModel数据共享的最佳实践
Android开发终极指南:Sunflower项目中ViewModel数据共享的最佳实践 【免费下载链接】sunflower A gardening app illustrating Android development best practices with migrating a View-based app to Jetpack Compose. 项目地址: https://gitcode.com/gh_mirro…...