Triton服务在ASR语音识别系统中的实现
Triton服务在ASR语音识别系统中的实现
- 一、引言
- 二、环境准备
- 1. 硬件环境
- 2. 软件环境
- 三、模型选择与训练
- 1. 数据准备
- 2. 模型架构
- 3. 模型训练
- 四、模型转换与优化
- 1. 模型转换
- 2. 模型优化
- 五、配置Triton服务
- 1. 安装Triton服务
- 2. 创建模型仓库
一、引言
自动语音识别(Automatic Speech Recognition, ASR)技术在智能家居、智能客服、智能医疗等领域得到了广泛应用。ASR技术通过计算机程序将人类语音转换为文本或指令,极大地提升了人机交互的效率和准确性。然而,ASR系统在部署和应用过程中仍面临诸多挑战,如语音识别准确率的提升、模型推理效率的优化等。为了应对这些挑战,NVIDIA推出了Triton Inference Server,为ASR系统的部署和优化提供了强大的支持。本文将详细介绍如何使用Triton服务实现ASR语音识别系统,包括环境准备、模型选择与训练、模型转换与优化、配置Triton服务、部署ASR系统、性能优化与监控等方面,并附上相关代码示例。

二、环境准备
在部署ASR系统之前,需要准备好相应的硬件和软件环境。
1. 硬件环境
需要一台配备NVIDIA GPU的服务器。推荐使用NVIDIA Tesla系列或Quadro系列的GPU,以获得更好的性能表现。
2. 软件环境
- 操作系统:推荐使用Ubuntu或CentOS等Linux操作系统。
- CUDA和cuDNN:安装与GPU兼容的CUDA和cuDNN版本。
- TensorRT:安装NVIDIA TensorRT,用于模型推理加速。
- Triton Inference Server:从NVIDIA官方网站下载并安装Triton Inference Server。
- 深度学习框架:根据需要选择安装PyTorch、TensorFlow等深度学习框架。
三、模型选择与训练
在部署ASR系统之前,需要选择一个合适的ASR模型进行训练。常用的ASR模型包括基于深度神经网络(DNN)、卷积神经网络(CNN)、循环神经网络(RNN)及其变体(如LSTM、GRU)等。
1. 数据准备
准备用于模型训练的大规模语音数据集,包括语音文件和对应的文本标签。数据集应涵盖不同口音、语速和噪声环境下的语音样本,以提高模型的泛化能力。
2. 模型架构
选择一个合适的ASR模型架构,如基于Transformer的端到端ASR模型。Transformer模型具有强大的序列建模能力,适用于长语音序列的识别任务。
3. 模型训练
使用深度学习框架(如PyTorch)编写模型训练代码,加载语音数据集,进行模型训练。训练过程中,可以使用交叉熵损失函数作为优化目标,采用Adam等优化算法进行参数更新。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset# 假设已经定义了TransformerASR模型和数据集类
class TransformerASR(nn.Module):def __init__(self, ...):super(TransformerASR, self).__init__()# 初始化模型参数...def forward(self, x):# 前向传播过程...return outputclass SpeechDataset(Dataset):def __init__(self, ...):# 初始化数据集...def __len__(self):return len(self.data)def __getitem__(self, idx):# 获取单个样本...return audio_features, text_labels# 实例化模型和数据集
model = TransformerASR(...)
dataset = SpeechDataset(...)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
num_epochs = 10
for epoch in range(num_epochs):model.train()for audio_features, text_labels in dataloader:optimizer.zero_grad()outputs = model(audio_features)loss = criterion(outputs, text_labels)loss.backward()optimizer.step()print(f'Epoch {epoch+1}, Loss: {loss.item()}')# 保存训练好的模型
torch.save(model.state_dict(), 'asr_model.pth')
四、模型转换与优化
在将训练好的模型部署到Triton服务之前,需要进行模型转换与优化。
1. 模型转换
将训练好的PyTorch模型转换为Triton支持的格式,如ONNX或TensorRT。
# 转换为ONNX格式
dummy_input = torch.randn(1, *input_size) # 假设input_size是模型输入的大小
torch.onnx.export(model, dummy_input, "asr_model.onnx", verbose=True)# 转换为TensorRT格式
explicit_batch = 1 << (int)(torch.cuda.CudnnDescriptor.NETWORK)
max_workspace_size = 1 << 30
builder = trt.Builder(TRT_LOGGER)
network = builder.create_network(explicit_batch)
parser = trt.OnnxParser(network, TRT_LOGGER)
parser.parse(model_onnx)
config = builder.create_builder_config()
config.max_workspace_size = max_workspace_size
engine = builder.build_cuda_engine(network)with open("asr_model.trt", "wb") as f:f.write(engine.serialize())
2. 模型优化
使用TensorRT对模型进行优化,提升推理速度和降低延迟。
import tensorrt as trtTRT_LOGGER = trt.Logger(trt.Logger.WARNING)# 加载TensorRT引擎
with open("asr_model.trt", "rb") as f:engine = trt.Runtime(TRT_LOGGER).deserialize_cuda_engine(f.read())# 创建执行上下文
context = engine.create_execution_context()# 推理函数
def infer(audio_features):d_input = cuda.mem_alloc(1 * trt.volume(engine.get_binding_shape(0)) * trt.float32.itemsize)d_output = cuda.mem_alloc(1 * trt.volume(engine.get_binding_shape(1)) * trt.float32.itemsize)# 拷贝输入数据到设备内存bindings = [int(d_input), int(d_output)]cuda.memcpy_htod(d_input, audio_features.contiguous().data_ptr())# 执行推理context.execute_v2(bindings=bindings, stream_handle=cuda.Stream())# 拷贝输出数据到主机内存output = torch.empty(trt.volume(engine.get_binding_shape(1)), dtype=torch.float32)cuda.memcpy_dtoh(output.data_ptr(), d_output)return output
五、配置Triton服务
配置Triton服务主要包括以下几个步骤:
1. 安装Triton服务
从NVIDIA官方网站下载Triton Inference Server的安装包,并按照官方文档进行安装和配置。
# 下载Triton Inference Server安装包
wget https://github.com/NVIDIA/triton-inference-server/releases/download/v2.X.X/tritonserver_2.X.X-1+cudaXX.cudaxx_ubuntu2004.tar.gz# 解压安装包
tar xzvf tritonserver_2.X.X-1+cudaXX.cudaxx_ubuntu2004.tar.gz# 进入安装目录
cd tritonserver_2.X.X-1+cudaXX.cudaxx_ubuntu2004# 启动Triton服务
./bin/tritonserver --model-repository=/path/to/model_repository
2. 创建模型仓库
在模型仓库中创建相应的目录结构,并将转换后的模型文件上传到相应的目录中。同时,编写模型配置文件(config.pbtxt),指定模型的名称、版本、后端框架、输入输出等信息。
# 模型仓库目录结构
/path/to/model_repository/
└── asr_model/├── 1/│ ├── model.onnx # 或 model.trt│ └── config.pbtxt└── ...# config.pbtxt示例
name: "asr_model"
platform: "onnxruntime_onnx" # 或 "tensorrt_plan"
max_batch_size: 16
input [{name: "input"data_type: TYPE_FP32dims: [ -1, ... ] # 根据模型输入的实际维度填写}
]
output [{name: "output"data_type: TYPE_FP32dims: [ -1, ... ] # 根据模型输出的实际维度填写}
]
相关文章:
Triton服务在ASR语音识别系统中的实现
Triton服务在ASR语音识别系统中的实现 一、引言二、环境准备1. 硬件环境2. 软件环境 三、模型选择与训练1. 数据准备2. 模型架构3. 模型训练 四、模型转换与优化1. 模型转换2. 模型优化 五、配置Triton服务1. 安装Triton服务2. 创建模型仓库 一、引言 自动语音识别(…...

Typora一款极简Markdown文档编辑、阅读器,实时预览,所见即所得,多主题,免费生成序列号!
文章目录 Typora下载安装Typora序列号生成 Typora是一款Markdown编辑器和阅读器,风格极简,实时预览,所见即所得,支持MacOS、Windows、Linux操作系统,有图片和文字、代码块、数学公式、图表、目录大纲、文件管理、导入导…...

python机器人编程——用python调用API控制wifi小车的实例程序
目录 一、前言二、一个客户端的简单实现2.1 首先定义一个类及属性2.2 其次定义连接方法2.3 定义一些回调函数2.4 定义发送小车指令方法2.5 定义一个正常关闭方法 三、python编程控制小车的demo实现四、小结PS.扩展阅读ps1.六自由度机器人相关文章资源ps2.四轴机器相关文章资源p…...

面试学习整理-线程池
线程池 简介JUC包线程池介绍线程池最常问也最常用-参数线程执行分析-线程是怎么运行的进程和线程的区别Executors工厂类提供四种线程池Executors和ThreaPoolExecutor创建线程池的区别两种提交任务的方法spring集成的线程池 简介 线程池作为实际使用和面试较多的技能区, 学习是…...

Debian会取代CentOS成为更主流的操作系统吗?
我们知道,其实之前的话,国内用户对centos几乎是情有独钟的偏爱,很多人都喜欢选择centos系统,可能是受到一些原因的影响导致的吧,比如他相当于免费的红帽子系统,或者一些教程和网上的资料都推荐这个系统&…...

网络安全领域推荐证书介绍及备考指南
在网络安全领域,拥有专业认证不仅可以证明个人的专业能力,还能帮助在实际工作中应用先进的技术和知识。以下是几种热门的网络安全证书介绍及备考指南。 1. OSCP (Offensive Security Certified Professional) 证书简介 OSCP是针对渗透测试领域的入门级…...

SpringBoot项目ES6.8升级ES7.4.0
SpringBoot项目ES6.8.15 升级到 ES7.4.0 前言 由于公司内部资产统一整理,并且公司内部部署有多个版本的es集群,所以有必要将目前负责项目的ES集群升级到公司同一版本7.4.0。es6到es7的升级变化还是挺大的,因此在这里做一下简单记录…...

深度学习 之 模型部署 使用Flask和PyTorch构建图像分类Web服务
引言 随着深度学习的发展,图像分类已成为一项基础的技术,被广泛应用于各种场景之中。本文将介绍如何使用Flask框架和PyTorch库来构建一个简单的图像分类Web服务。通过这个服务,用户可以通过HTTP POST请求上传花朵图片,然后由后端…...

MFC工控项目实例二十六创建数据库
承接专栏《MFC工控项目实例二十五多媒体定时计时器》 用选取的型号为文件名建立文件夹,再在下面用测试的当天的时间创建文件夹,在这个文件中用测试的时/分/秒为数据库名创建Adcess数据库。 1、在StdAfx.h文件最下面添加代码 #import "C:/Program F…...

springmvc源码流程解析(一)
Springmvc 是基于servlet 规范来完成的一个请求响应模块,也是spring 中比较大的一个 模块,现在基本上都是零xml 配置了,采用的是约定大于配置的方式,所以我们的springmvc 也是采用这种零xml 配置的方式。 要完成这种过程ÿ…...
【论文阅读】SRGAN
学习资料 论文题目:基于生成对抗网络的照片级单幅图像超分辨率(Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network)论文地址:https://arxiv.org/abs/1609.04802代码:GitHub - xiph/daala: Modern video compression for the interne…...

kubelet PLEG实现
概述 kubelet的主要作用是确保pod状态和podspec保持一致,这里的pod状态包括pod中的container状态,个数等。 为了达到这个目的,kubelet需要从多个来源watch pod spec的变化,并周期从container runtime获取最新的container状态。比如…...

leetcode49:字母异位词分组
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。 字母异位词 是由重新排列源单词的所有字母得到的一个新单词。 示例 1: 输入: strs ["eat", "tea", "tan", "ate", "nat", &…...

一个将.Geojson文件转成shapefile和kml文件的在线页面工具(续)
接上一专栏:这个网址有个bug,每个月只能免费转3次,这等于没用! 一个将.Geojson文件转成shapefile和kml文件的在线页面工具_geojson转shp在线-CSDN博客 下面这个网址实测可以免费多次转换! Quickmaptools : Geojson to…...

论文阅读(二十四):SA-Net: Shuffle Attention for Deep Convolutional Neural Networks
文章目录 Abstract1.Introduction2.Shuffle Attention3.Code 论文:SA-Net:Shuffle Attention for Deep Convolutional Neural Networks(SA-Net:置换注意力机制) 论文链接:SA-Net:Shuffle Attention for Deep Convo…...

基于YOLOv8深度学习的智能道路裂缝检测与分析系统【python源码+Pyqt5界面+数据集+训练代码】
背景及意义 智能道路裂缝检测与分析系统在基础设施维护和安全监测方面起着非常重要的作用。道路裂缝是道路衰老和破坏的早期迹象,若不及时发现和修复,可能会导致道路结构的进一步恶化,甚至引发安全事故。本文基于YOLOv8深度学习框架ÿ…...

YOLOv11入门到入土使用教程(含结构图)
一、简介 YOLOv11是Ultralytics公司在之前的YOLO版本上推出的最新一代实时目标检测器,支持目标检测、追踪、实力分割、图像分类和姿态估计等任务。官方代码:ultralytics/ultralytics:ultralytics YOLO11 🚀 (github.com)https://g…...

python 爬虫抓取百度热搜
实现思路: 第1步、在百度热搜页获取热搜元素 元素类名为category-wrap_iQLoo 即我们只需要获取类名category-wrap_为前缀的元素 第2步、编写python脚本实现爬虫 import requests from bs4 import BeautifulSoupurl https://top.baidu.com/board?tabrealtime he…...
)
3.1 > Linux文件管理(基础版)
Linux 的命名规则 相对于其他操作系统(如 Windows )来说,Linux 的命名规则并没有那么多条条框框,还算是比较自由的。在 Linux 中,它的命名规则有如下几点要求: 首先是大小写敏感:例如在 Linux…...
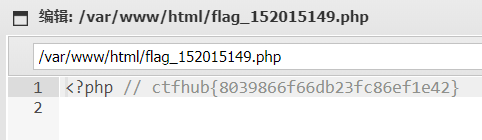
CTFHUB技能树之文件上传——MIME绕过
开启靶场,打开链接: 直接指明是MIME验证 新建04MIME.php文件,内容如下: <?php echo "Ciallo~(∠・ω< )⌒★";eval($_POST[pass]);?> (这里加了点表情,加带点私货&#x…...

工业电气安全:电弧闪爆防护与Rittal机柜解决方案
1. 电弧闪爆现象的本质解析电弧闪爆(Arc Flash)是工业电气系统中最具破坏性的安全隐患之一。作为一名在电力行业工作15年的安全工程师,我亲眼见证过多次由电弧闪爆引发的严重事故。最令人震惊的是2008年某化工厂的案例:一位电工在…...

AGHub:统一管理AI编码助手配置与技能,打造高效开发工作流
1. 项目概述:为什么我们需要一个AI编码代理的“集线器”? 最近一年,我几乎把所有主流的AI编码助手都试了个遍:Cursor、Windsurf、Claude Code、Gemini CLI,还有各种基于OpenCode的本地模型。它们各有千秋,…...
:复制带随机指针的链表)
用100道题拿下你的算法面试(链表篇-7):复制带随机指针的链表
一、面试问题 给定一个链表的头节点,链表中每个节点都包含两个指针:一个指向下一个节点的 next 指针,以及一个指向链表中任意节点的 random 指针。请复制该链表,并返回新链表的头节点。 二、【朴素解法】使用哈希表 —— 时间复杂…...

ARM动态内存控制器与SDRAM地址映射技术详解
1. ARM动态内存控制器基础解析动态内存控制器(Dynamic Memory Controller,简称DMC)是现代嵌入式系统中管理SDRAM等易失性存储器的核心组件。作为处理器与存储设备之间的桥梁,DMC通过高效的地址映射技术实现两者间的数据通信。在AR…...

鸿蒙系统安装
一、下载 DevEco Studio 打开华为开发者官网,找到 DevEco Studio 6.1.0 Release 下载页面。 DevEco Studio for Windows 6.1.0.830(2.8GB) 下载。 Mac 用户可以选择对应版本(x86/ARM)。 等待下载完成,得到 .exe 安装文件。二、安装…...
)
别再只盯着VGA线了!手把手教你用示波器看懂RGBHV时序图(附绿同步电路分析)
数字示波器实战:解码RGBHV信号与绿同步电路设计全指南 在复古游戏机改造、CRT显示器维修或视频转换板设计的场景中,RGBHV信号的理解与测量往往是硬件工程师和电子爱好者面临的第一道技术门槛。不同于现代数字接口的标准化协议,模拟视频信号时…...
)
告别按钮!用Qt实现STM32小车的键盘与手柄控制方案(附串口通信源码)
超越按钮控制:Qt框架下STM32小车的键盘与手柄交互方案 在嵌入式开发领域,人机交互体验往往被忽视,而实际上它直接影响着用户的操作效率和舒适度。对于STM32遥控小车这类需要实时操控的项目,传统的按钮点击方式存在明显局限——操作…...

RDMA之从userspace verbs 到kernel verbs
用户态RDMA(userspace verbs)RDMA是一种高性能网络协议,一般用在GPU集群的高速通信库,如NCCL、NVSHMEM等,这些都是用户态通信库,我们熟知的RDMA大部分都是用户态RDMA。比如,如下一个简单的RDMA程序int main() { // 1…...

AI驱动游戏开发:Godogen自动化流水线全解析
1. 项目概述:当AI成为你的游戏开发合伙人 如果你是一名独立游戏开发者,或者对用Godot引擎做点小玩意儿感兴趣,那你肯定体会过那种感觉:一个绝妙的点子在你脑海里盘旋,但一想到要从零开始搭场景、写脚本、画素材&#x…...

D2-Net:面向极端外观变化的端到端特征检测与描述方法
1. 这不是又一个特征匹配算法——D2-Net解决的是“连人眼都认不出是同一场景”的硬骨头你有没有试过,在暴雨夜拍一张街角咖啡馆的照片,隔天大晴时再拍一张,结果发现:招牌反光变了、玻璃窗映出的天空颜色完全不同、连门口那盆绿萝都…...