MusePose模型部署指南
一、模型介绍
MusePose是一个基于扩散和姿势引导的虚拟人视频生成框架。
主要贡献可以概括如下:
- 发布的模型能够根据给定的姿势序列,生成参考图中人物的舞蹈视频,生成的结果质量超越了同一主题中几乎所有当前开源的模型。
- 发布该
pose align算法,以便用户可以将任意舞蹈视频与任意参考图像对齐,这显著提高了推理性能并增强了模型的可用性。 - 修复了几个重要的错误,并在 Moore-AnimateAnyone的代码基础上做了一些改进。
二、部署流程
1. 环境要求
- Python 3.10 或更高版本
- 推荐:CUDA 11.7 或更高版本
2. 克隆并安装依赖项
git clone https://github.com/TMElyralab/MusePose.git
pip install -r requirements.txt
3. 下载mim软件包
pip install --no-cache-dir -U openmim
mim install mmengine
mim install "mmcv>=2.0.1"
mim install "mmdet>=3.1.0"
mim install "mmpose>=1.1.0"
4.下载权重
git lfs install
git clone https://www.modelscope.cn/jackle/ComfyUI-MusePose-models.git

pretrained_weights 最后,这些权重应按如下方式组织:
./pretrained_weights/
|-- MusePose
| |-- denoising_unet.pth
| |-- motion_module.pth
| |-- pose_guider.pth
| └── reference_unet.pth
|-- dwpose
| |-- dw-ll_ucoco_384.pth
| └── yolox_l_8x8_300e_coco.pth
|-- sd-image-variations-diffusers
| └── unet
| |-- config.json
| └── diffusion_pytorch_model.bin
|-- image_encoder
| |-- config.json
| └── pytorch_model.bin
└── sd-vae-ft-mse|-- config.json└── diffusion_pytorch_model.bin
三、推理
1. 准备
在文件夹中准备参考图片和舞蹈视频 ./assets,并按照示例进行组织:
./assets/
|-- images
| └── ref.png
└── videos└── dance.mp4
2. 姿势对齐
获取参考图的对齐 dwpose:
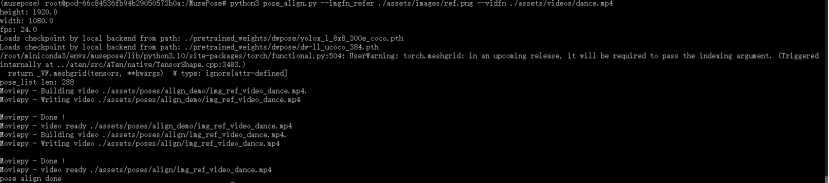
python pose_align.py --imgfn_refer ./assets/images/ref.png --vidfn ./assets/videos/dance.mp4
此后,您可以在其中看到姿势对齐结果 ./assets/poses,其中 ./assets/poses/align/img_ref_video_dance.mp4 是对齐的 dwpose,而 ./assets/poses/align_demo/img_ref_video_dance.mp4 用于调试。
3. 推断 MusePose
将参考图的路径和对齐的 dwpose 添加到测试配置文件中,./configs/test_stage_2.yaml 例如:
test_cases:"./assets/images/ref.png":- "./assets/poses/align/img_ref_video_dance.mp4"
然后,只需运行
python test_stage_2.py --config ./configs/test_stage_2.yaml
./configs/test_stage_2.yaml 是推理配置文件的路径。
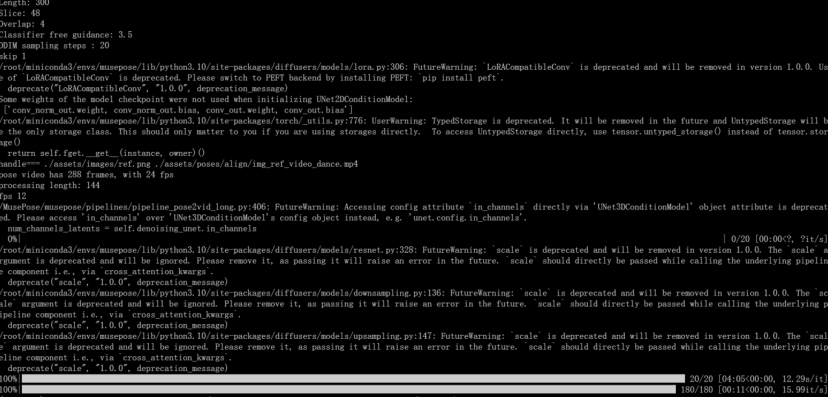
最后,你可以在 ./output/文件夹下查看
4. 降低 VRAM 成本
如果要降低 VRAM 成本,可以设置推理的宽度和高度。例如,
python test_stage_2.py --config ./configs/test_stage_2.yaml -W 512 -H 512
它将首先生成 512 x 512 的视频,然后将其调整回姿势视频的原始大小。
目前在 512 x 512 x 48 上运行需要 16GB VRAM,在 768 x 768 x 48 上运行需要 28GB VRAM。但需要注意的是,推理分辨率会影响最终结果(尤其是人脸区域)。
5. 面部美容
如果要增强脸部区域以获得更好的脸部一致性,可以使用FaceFusion。您可以使用该 face-swap 功能将参考图中的脸部交换到生成的视频中。
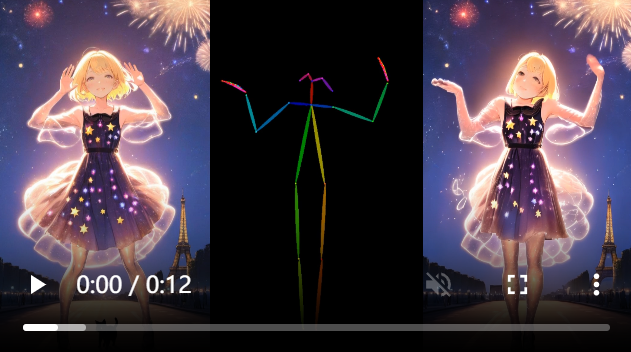
四、界面演示
相关文章:
MusePose模型部署指南
一、模型介绍 MusePose是一个基于扩散和姿势引导的虚拟人视频生成框架。 主要贡献可以概括如下: 发布的模型能够根据给定的姿势序列,生成参考图中人物的舞蹈视频,生成的结果质量超越了同一主题中几乎所有当前开源的模型。发布该 pose alig…...

又一次升级:字节在用大模型在做推荐啦!
原文链接 字节前几天2024年9年19日公开发布的论文《HLLM:通过分层大型语言模型增强基于物品和用户模型的序列推荐效果》。 文字、图片、音频、视频这四大类信息载体,在生产端都已被AI生成赋能助力,再往前一步,一定需要一个更强势…...
无线领夹麦克风怎么挑选,麦克风行业常见踩坑点,避雷不专业产品
随着短视频和直播行业的迅速发展,近年来无线领夹麦克风热度持续高涨,作为一款小巧实用的音频设备,它受到很多视频创作者以及直播达人的喜爱。但如今无线领夹麦克风品类繁杂,大家选购时容易迷失方向,要知道并不是所有…...

OJ-1017中文分词模拟器
示例0 输入: ilovechina i,ilove,lo,love,ch,china,lovechina 输出: ilove,china 示例1 输入: ilovechina i,love,china,ch,na,ve,lo,this,is,the,word 输出: i,love,china 说明: 示例2 输入: iat i,love,…...

Unity 关于UGUI动静分离面试题详解
前言 近期有同学面试,被问到这样一道面试题: ”说说UGUI的动静分离是怎么一回事?” 关于这个优化有一些误区,容易让开发者陷入一个极端。我们先分析关于UGUI 合批优化的问题,最后给这个面试题一个参考回答。 对惹,…...

HarmonyNext保存Base64文件到Download下
本文介绍如何保存Base64的文件到Download下 参考文档地址: 保存用户文件-Harmony Next 用到的是DOWNLOAD模式保存文件 用户在使用save接口时,可以将pickerMode配置为DOWNLOAD模式,该模式下会拉起授权接口,用户确认后会在公共路径…...

069_基于springboot的OA管理系统
目录 系统展示 开发背景 代码实现 项目案例 获取源码 博主介绍:CodeMentor毕业设计领航者、全网关注者30W群落,InfoQ特邀专栏作家、技术博客领航者、InfoQ新星培育计划导师、Web开发领域杰出贡献者,博客领航之星、开发者头条/腾讯云/AW…...
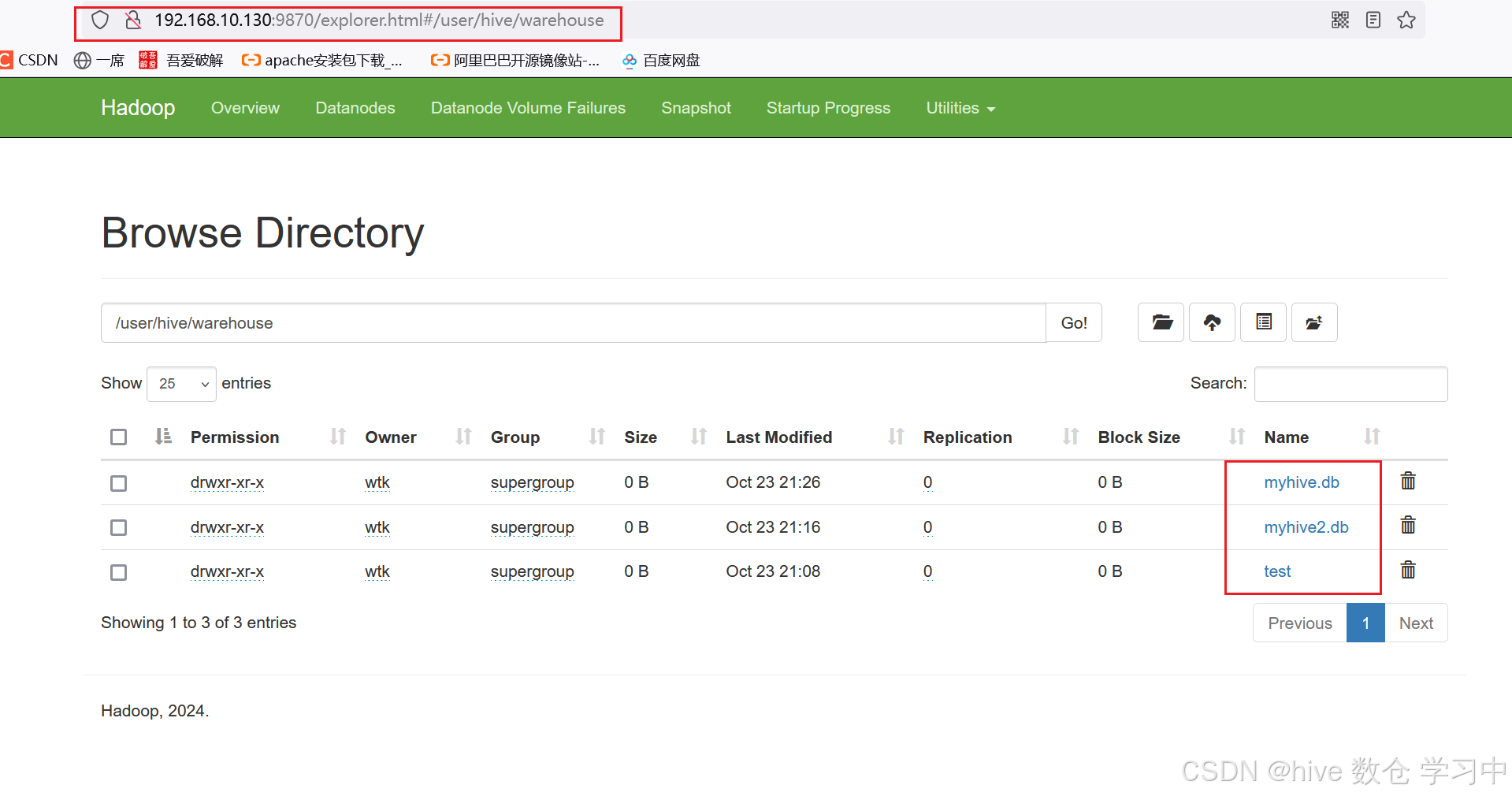
hive数据库,表操作
1.创建; create database if not exists myhive; use myhive; 2.查看: 查看数据库详细信息:desc database myhive; 默认数据库的存放路径是 HDFS 的: /user/hive/warehouse 内 补充:创建数据库并指定 hdfs 存储位置:create database myhive2 location /myhive2 3.…...

openpnp - 在顶部相机/底部相机高级校正完成后,需要设置裁剪所有无效像素
文章目录 openpnp - 在顶部相机/底部相机高级校正完成后,需要设置裁剪所有无效像素概述笔记设置后的顶部相机效果设置后的底部相机效果 备注END openpnp - 在顶部相机/底部相机高级校正完成后,需要设置裁剪所有无效像素 概述 用自己编译的基于openpnp-…...

Vue+TypeScript+SpringBoot的WebSocket基础教学
成品图: 对WebSocket的理解(在使用之前建议先了解Tcp,三次握手,四次挥手 ): 首先页面与WebSocket建立连接、向WebSocket发送信息、后端WebSocket向所有连接上WebSoket的客户端发送当前信息。 推荐浏览网站…...
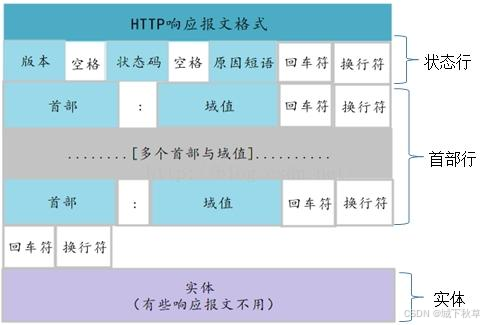
大话网络协议:HTTPS协议和HTTP协议有何不同?为什么HTTPS更安全
大家现在访问网络,浏览网页,注意一下的话,网址前面基本上都是一个 https:// 的前缀,这里就是说明这个网址所采用的协议是 https 协议。那么具体应该怎么理解 https 呢? 本文我们就力争能清楚地解释明白这个我们目前应该最广的协议。 理解HTTP协议 要解释 https 协议,当…...
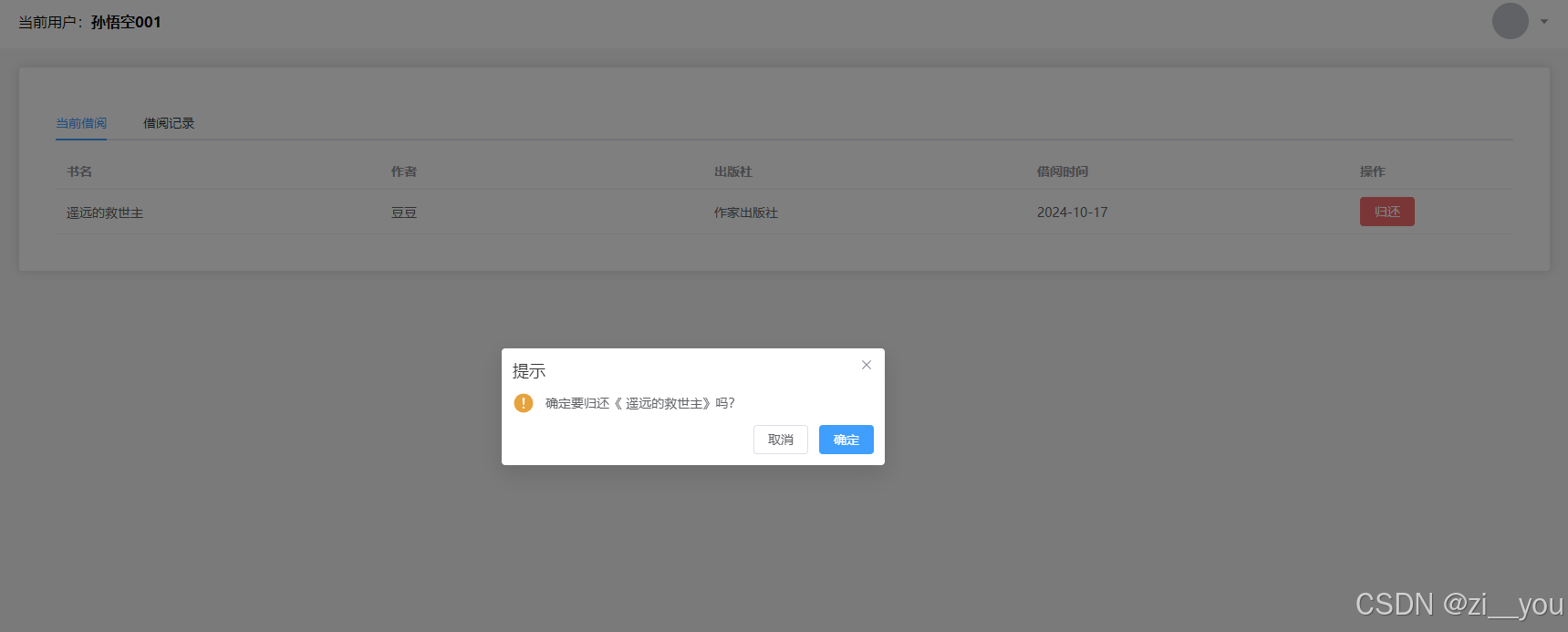
13图书归还-云图书管理系统(Vue3+Spring Boot+element plus)
目录 1 接口地址2 后台代码RecordControllerBookController 3 view/books/BookRecordsVue中前端框架搭建4 api/record.js文件写查询用户借阅记录的接口代码5 api/book.js中写归还图书、查询当前借阅图书接口代码6 BookRecordsVue中导入接口函数,并调用7 运行效果 1 …...

中航资本:“女人的茅台”重挫!超7700亿元英伟达概念业绩爆发
今天早盘首要指数强势震动,申万一级工作指数跌多涨少,通讯指数涨逾1%居首。概念方面,存储器、动保、重组等概念板块涨幅居前。存储概念大涨首要仍是AI方向又有好消息,市值逾越7700亿元的英伟达概念龙头SK海力士发布效果超预期财报…...

day7:软件包管理
一,软件包概述 软件包概述 软件包用于安装,升级,卸载一个软件 软件包类型 二进制包 源码经过了编译(而且成功了)后产生的包,二进制包是linux下默认的安装包 编译好的文件,直接使用ÿ…...

探索Konko AI:快速集成大语言模型的最佳实践
探索Konko AI:快速集成大语言模型的最佳实践 引言 随着大语言模型(LLM)的普及,如何快速方便地集成这些模型成为众多开发者关注的焦点。Konko AI 提供了一个全面管理的 API,使开发者能够选择合适的开源或专有大语言模…...

网络地址和本地网络地址
本地网络地址(Local Network Address,简称 LNA)是指在一个子网内用于标识特定主机的部分。在 IPv4 地址中,一个完整的 IP 地址由两部分组成:网络地址部分(Network Address)和本地网络地址部分&a…...

【closerAI ComfyUI】AI绘画界新技术RF Inversion图像编辑和风格迁移!能跟ipadapter争高低吗?
AI绘画界新技术RF Inversion图像编辑和风格迁移!能跟ipadapter争高低吗? 在人工智能绘画领域,技术的创新永不止步。closerAI ComfyUI最近推出了一项名为RF Inversion的新技术,它能够进行图像编辑和风格迁移,为艺术家和…...

【Spring篇】Spring的Aop详解
🧸安清h:个人主页 🎥个人专栏:【计算机网络】【Mybatis篇】【Spring篇】 🚦作者简介:一个有趣爱睡觉的intp,期待和更多人分享自己所学知识的真诚大学生。 目录 🎯初始Sprig AOP及…...

Spring与其他框架的比较
Spring 框架因其丰富的功能和灵活性,在 Java 领域内得到了广泛应用。然而,在不同的应用场景下,开发者可能会选择其他框架。下面将 Spring 框架与其他一些常见的 Java 框架进行比较,以便更好地理解它们各自的优缺点和适用场景。 1…...

论当前的云计算
随着技术的不断进步和数字化转型的加速,云计算已经成为当今信息技术领域的重要支柱。本文将探讨当前云计算的发展现状、市场趋势、技术革新以及面临的挑战与机遇。 云计算的发展现状 云计算,作为一种通过网络提供可伸缩的、按需分配的计算资源服务模式&a…...

从零到一:在STM32F103上构建FatFs文件系统并驱动W25Q64 Flash
1. 硬件准备与环境搭建 在开始构建FatFs文件系统之前,我们需要先准备好硬件环境。我手头用的是STM32F103C8T6最小系统板,搭配一块W25Q64 Flash芯片。这块Flash芯片容量为8MB,通过SPI接口通信,正好适合用来做文件存储介质。 首先得…...

游戏平台硬件开发:定制化与长期稳定的挑战
1. 游戏平台硬件开发的特殊挑战在游戏平台开发领域,硬件选型往往面临着一个两难选择:是采用现成的通用组件(Off The Shelf Components),还是投入高昂成本进行完全定制化开发?过去十年间,我参与过…...

NovelForge:AI长篇小说创作引擎,结构化写作与知识图谱实战
1. 项目概述:一个为长篇创作而生的AI写作伙伴如果你和我一样,是一个对长篇故事创作充满热情,但又时常被海量设定、角色关系、情节推进和前后一致性搞得焦头烂额的作者,那么NovelForge的出现,可能正是我们一直在等待的“…...

实测:2026 年国内直连 AI 一站式平台,聊天 / 绘画 / 论文 / 视频全搞定,不用翻墙不花冤枉钱
最近 AI 圈真的太卷了。ChatGPT 5.4、Gemini 3.1、Claude Code 轮番上新,多模态、长文本、代码 Auto Mode 一个比一个强。但普通用户想用明白,真的太折腾。先说说我踩过的三大坑,句句大实话网络糟心到崩溃官网打不开、地区不可用、加载转圈、…...

microeco:微生物组学分析工具的终极指南,让数据分析变得简单快速
microeco:微生物组学分析工具的终极指南,让数据分析变得简单快速 【免费下载链接】microeco An R package for downstream data analysis of microbiome omics data 项目地址: https://gitcode.com/gh_mirrors/mi/microeco 面对海量的微生物组学数…...
)
别再折腾源码编译了!Ubuntu 20.04下用apt-get一键安装Asterisk PBX(附SIP账号配置详解)
别再折腾源码编译了!Ubuntu 20.04下用apt-get一键安装Asterisk PBX(附SIP账号配置详解) 如果你正在寻找一种快速搭建企业级电话系统的方法,那么Asterisk PBX绝对值得考虑。作为开源PBX领域的标杆,Asterisk提供了完整的…...

寄生电感容易被忽略,却是电路不稳定的隐形元凶
调试电路板的时候,最让人抓狂的并不是那些明面上能查到文档的参数问题。示波器一抓波形,明明电源电压已经稳定,负载也没动,可偏偏就是有那种挥之不去的毛刺,幅度不大,频率不低,排查了半天才发现…...
)
告别手动刷新!用PowerShell脚本实现Windows下校园网自动重连(含任务计划设置)
告别手动刷新!用PowerShell脚本实现Windows下校园网自动重连(含任务计划设置) 每次开机都要手动登录校园网?网络突然断开还得重新输入账号密码?这些繁琐操作已经成为过去式。本文将手把手教你用PowerShell打造全自动校…...

前端实战:用HTML/CSS/JS打造交互式生日蛋糕网页应用
1. 项目概述:一个用代码烘焙的生日惊喜最近给朋友准备生日礼物,不想再走寻常路,琢磨着送点特别的。作为一个整天和代码打交道的人,我决定用最熟悉的工具——HTML、CSS和JavaScript——亲手“烘焙”一个数字生日蛋糕。这个项目“Re…...

从零到一:深入拆解 I/O 多路复用的前世今生与实战选型
1. 从单线程阻塞到多路复用:I/O模型的进化史 第一次写网络程序时,你可能遇到过这样的场景:服务器在accept()一个客户端连接后,整个程序就像被冻住一样,直到这个客户端发送数据才能继续运行。这就是最原始的阻塞I/O模型…...