施磊C++ | 项目实战 | 手写移植SGI STL二级空间配置器内存池 项目源码
手写移植SGI STL二级空间配置器内存池 项目源码
笔者建议配合这两篇博客进行学习
侯捷 | C++ | 内存管理 | 学习笔记(二):第二章节 std::allocator-CSDN博客
施磊C++ | 项目实战 | SGI STL二级空间配置器源码剖析-CSDN博客
文章目录
- 手写移植SGI STL二级空间配置器内存池 项目源码
- 1.大致框架
- 2.allocate函数
- 3.refill函数
- 4._S_chunk_alloc函数
- 5.malloc_alloc::allocate函数
- 6.deallocate函数
- 7.reallocate
- 8.完整版myallocator.h
- 9.pch.h和pch.cpp
- 10.测试
考虑的问题:多线程安全
空间配置器是容器使用的,而容器产生的对象是很有可能在多个线程中去操作的
1.大致框架
1.四个函数定义
2.重要的类型变量
3.两个辅助函数
4.静态成员函数初始化
#pragma once
#include<mutex>
//移植SGI STL二级空间配置器内存池 源码template<typename T>
class myallocator
{
public://开辟内存 __n是开辟的大小(多少字节)T* allocate(size_t __n);//释放内存 __n是释放的大小void deallocate(void* __p, size_t __n);//内存扩容或缩容void* reallocate(void* __P, size_t __old_sz, size_t __new_sz);//对象构造 定位new实现void construct(T *__p,const T&val){new (__p) T(val);}//对象析构void destroy(T* __p){__p->~T();}
private://自由链表是从8字节开始,以8字节为对齐方式,扩充到128字节//obj数组的第一个链表挂着的是8字节,第二个是16字节,一次类推到128字节enum { _ALIGN = 8 };//内存池最大的chunk块的大小enum { _MAX_BYTES = 128 };//自由链表的数量 16 = 128 / 8enum { _NFREELISTS = 16 };// 每一个内存chunk块(结点)的头信息union _Obj {union _Obj* _M_free_list_link;//保存下一个结点的地址char _M_client_data[1]; };// 组织所有自由链表的数组,数组的每一个元素的类型是_Obj*,全部初始化为 0/*多线程环境下防止线程自己拷贝一个副本,会加一个volatile关键字,使得在数据段或者堆上的数据改变了每个线程都可以立马看到,防止多个线程看到的数据版本不一致*/static _Obj* volatile _S_free_list[_NFREELISTS];//s_free_list存储自由链表数组的地址,这是个数组名,大小就是上面的16//内存池基于freelist实现,需要考虑线程安全,主要做互斥操作 换成C++11的锁static std::mutex mtx;//已分配的内存chunk块的使用情况 初始化全为0//start~~end 分配给程序之后剩下的空闲内存起始和终止地址 heapsize 堆的大小,记录的是已经分配的内存大小 除以16算出来的就是追加量static char* _S_start_free;static char* _S_end_free;static size_t _S_heap_size;/*将 __bytes 上调至最邻近的 8 的倍数 _ALIGN==81-8 全都映射(对齐)到89-16 全都映射(对齐)到16*/static size_t _S_round_up(size_t __bytes){return (((__bytes)+(size_t)_ALIGN - 1) & ~((size_t)_ALIGN - 1));}/*返回 __bytes 大小的chunk块位于 free-list 中的编号作用就是,如果申请的字节在1-8之间,就挂到内存块大小为8的那个链表下面如果申请的字节在9-16之间,就挂到内存块大小为16的那个链表下面*/static size_t _S_freelist_index(size_t __bytes) {return (((__bytes)+(size_t)_ALIGN - 1) / (size_t)_ALIGN - 1);}//把分配好的chunk进行连接的static void* _S_refill(size_t __n);//主要负责分配自由链表,chunk块的static char* _S_chunk_alloc(size_t __size,int& __nobjs);
};//静态成员变量初始化
template <typename T>
char* myallocator<T>::_S_start_free = nullptr;
template <typename T>
char* myallocator<T>::_S_end_free = nullptr;
template <typename T>
size_t myallocator<T>::_S_heap_size = 0;template <typename T>
//这里的typename告诉编译器这里是一个类型定义
typename myallocator<T>::_Obj* volatile myallocator<T>::_S_free_list[_NFREELISTS]=
{nullptr,nullptr, nullptr, nullptr, nullptr, nullptr, nullptr, nullptr, nullptr, nullptr, nullptr, nullptr, nullptr, nullptr, nullptr, nullptr};template <typename T>
std::mutex myallocator<T>::mtx;2.allocate函数
//开辟内存 __n是开辟的大小(多少字节)
T* allocate(size_t __n)
{//要传入的是字节数,而容器调用传进来的1,2,3这些数字是个数不是字节数,还要乘以T的大小才行__n = __n * sizeof(T);void* __ret = 0;//大于128字节,直接mallocif (__n > (size_t)_MAX_BYTES) {__ret = malloc_alloc::allocate(__n);}//小于128字节else {_Obj* volatile* __my_free_list= _S_free_list + _S_freelist_index(__n);//线程安全std::lock_guard<std::mutex> guard(mtx);_Obj* __result = *__my_free_list;//内存池有chunk块就去相应大小的链表下面拿,没有的话就看如何进行分配了if (__result == 0)//没有相应大小chunk块,下面解释如何分配__ret = _S_refill(_S_round_up(__n));else {//有相应大小chunk块,就从内存池里面拿出相应的块分配给程序*__my_free_list = __result->_M_free_list_link;__ret = __result;}}//返回我们从内存池申请的chunk块return (T*)__ret;
}
注意点:
1.vector容器传入的__n是对象个数,还要乘以对象类型T的大小才是我们要开辟的字节数
2.最后指针要强转
3.把线程安全换成c++11的互斥锁
3.refill函数
//把分配好的chunk进行连接的
static void* _S_refill(size_t __n)
{int __nobjs = 20;//chunk_alloc主要负责内存开辟char* __chunk = _S_chunk_alloc(__n, __nobjs);_Obj* volatile* __my_free_list;_Obj* __result;_Obj* __current_obj;_Obj* __next_obj;int __i;if (1 == __nobjs) return(__chunk);__my_free_list = _S_free_list + _S_freelist_index(__n);/* Build free list in chunk *///result和chunk都指向chunk_alloc分配的内存的首地址 chunk指针用来遍历chunk块,result指针指向开头的地方做一个保存__result = (_Obj*)__chunk;//把头指针的位置指向下一chunk块,因为当前的情形是已经要把当前自由链表头指针的位置分配出去了,而头指针的后面才是剩下的空闲的chunk块,再次分配是分配空闲的,分配出去的就没关系了*__my_free_list = __next_obj = (_Obj*)(__chunk + __n);for (__i = 1; ; __i++) {__current_obj = __next_obj;//这行描述的就是遍历过程 先转成char*,这样每次加减都是以字节为单位,chunk指针每一次加8字节到下一个chunk块(不一定是8,这里只是说明,具体多少要看内存块的大小,反正就是到下一个chunk内存块了)__next_obj = (_Obj*)((char*)__next_obj + __n);if (__nobjs - 1 == __i) {__current_obj->_M_free_list_link = 0;break;}else {__current_obj->_M_free_list_link = __next_obj;}}//返回第一个空闲的chunk结点给容器使用return(__result);
}
4._S_chunk_alloc函数
//主要负责分配自由链表,chunk块的static char* _S_chunk_alloc(size_t __size,int& __nobjs){char* __result;size_t __total_bytes = __size * __nobjs;size_t __bytes_left = _S_end_free - _S_start_free;if (__bytes_left >= __total_bytes) {__result = _S_start_free;_S_start_free += __total_bytes;return(__result);}else if (__bytes_left >= __size) {__nobjs = (int)(__bytes_left / __size);__total_bytes = __size * __nobjs;__result = _S_start_free;_S_start_free += __total_bytes;return(__result);}else {size_t __bytes_to_get =2 * __total_bytes + _S_round_up(_S_heap_size >> 4);// Try to make use of the left-over piece.if (__bytes_left > 0) {_Obj* volatile* __my_free_list =_S_free_list + _S_freelist_index(__bytes_left);((_Obj*)_S_start_free)->_M_free_list_link = *__my_free_list;*__my_free_list = (_Obj*)_S_start_free;}_S_start_free = (char*)malloc(__bytes_to_get);if (nullptr == _S_start_free) {size_t __i;_Obj* volatile* __my_free_list;_Obj* __p;// Try to make do with what we have. That can't// hurt. We do not try smaller requests, since that tends// to result in disaster on multi-process machines.for (__i = __size;__i <= (size_t)_MAX_BYTES;__i += (size_t)_ALIGN) {__my_free_list = _S_free_list + _S_freelist_index(__i);__p = *__my_free_list;if (0 != __p) {*__my_free_list = __p->_M_free_list_link;_S_start_free = (char*)__p;_S_end_free = _S_start_free + __i;return(_S_chunk_alloc(__size, __nobjs));// Any leftover piece will eventually make it to the// right free list.}}_S_end_free = 0; // In case of exception._S_start_free = (char*)malloc_alloc::allocate(__bytes_to_get);// This should either throw an// exception or remedy the situation. Thus we assume it// succeeded.}_S_heap_size += __bytes_to_get;_S_end_free = _S_start_free + __bytes_to_get;return(_S_chunk_alloc(__size, __nobjs));}}
5.malloc_alloc::allocate函数
最后一行typedef __malloc_alloc_template<0> malloc_alloc;
这个类就是malloc_alloc
//封装了malloc和free函数,可以设置OOM释放内存的回调函数
template <int __inst>
class __malloc_alloc_template {private:static void* _S_oom_malloc(size_t);static void* _S_oom_realloc(void*, size_t);static void (*__malloc_alloc_oom_handler)();public:static void* allocate(size_t __n){void* __result = malloc(__n);if (0 == __result) __result = _S_oom_malloc(__n);return __result;}static void deallocate(void* __p, size_t /* __n */){free(__p);}static void* reallocate(void* __p, size_t /* old_sz */, size_t __new_sz){void* __result = realloc(__p, __new_sz);if (0 == __result) __result = _S_oom_realloc(__p, __new_sz);return __result;}static void (*__set_malloc_handler(void (*__f)()))(){void (*__old)() = __malloc_alloc_oom_handler;__malloc_alloc_oom_handler = __f;return(__old);}};template <int __inst>
void (*__malloc_alloc_template<__inst>::__malloc_alloc_oom_handler)() = 0;template <int __inst>
void*
__malloc_alloc_template<__inst>::_S_oom_malloc(size_t __n)
{void (*__my_malloc_handler)();void* __result;for (;;) {__my_malloc_handler = __malloc_alloc_oom_handler;if (0 == __my_malloc_handler) { throw std::bad_alloc(); }(*__my_malloc_handler)();__result = malloc(__n);if (__result) return(__result);}
}template <int __inst>
void* __malloc_alloc_template<__inst>::_S_oom_realloc(void* __p, size_t __n)
{void (*__my_malloc_handler)();void* __result;for (;;) {__my_malloc_handler = __malloc_alloc_oom_handler;if (0 == __my_malloc_handler) { throw std::bad_alloc(); }(*__my_malloc_handler)();__result = realloc(__p, __n);if (__result) return(__result);}
}typedef __malloc_alloc_template<0> malloc_alloc;
6.deallocate函数
//释放内存 __n是释放的大小
void deallocate(void* __p, size_t __n)
{//回收的过大 直接用freeif (__n > (size_t)_MAX_BYTES)malloc_alloc::deallocate(__p, __n);else {//定位到要回收的chunk块的地址_Obj* volatile* __my_free_list= _S_free_list + _S_freelist_index(__n);_Obj* __q = (_Obj*)__p;std::lock_guard<std::mutex> guard(mtx);//这里就是链表的头插法//要归还的块是要插入的块,要插入到头结点和头结点的next域指的节点(这个节点是第一个空闲块),而我们归还的这个块就接到头结点的next域,然后要回收的块再接着原来的第一个空闲块,成为新的第一个空闲块,就类比一下链表的头插法就行__q->_M_free_list_link = *__my_free_list;*__my_free_list = __q;// lock is released here 出作用域锁释放}
}
7.reallocate
//内存扩容或缩容
void* reallocate(void* __p, size_t __old_sz, size_t __new_sz)
{void* __result;size_t __copy_sz;//如果旧的和新的全都比128字节大,那说明这就不是从我内存池里面出去的,那就直接调用c的realloc函数if (__old_sz > (size_t)_MAX_BYTES && __new_sz > (size_t)_MAX_BYTES) {return(realloc(__p, __new_sz));}//如果新的和旧的对齐以后一样,那就不用扩容,直接返回 比如一个12,扩容到15,但是这两个的round_up都是16 那就没必要扩容了if (_S_round_up(__old_sz) == _S_round_up(__new_sz)) return(__p);//分配一块新的大小的内存空间__result = allocate(__new_sz);//比较大小,就选个比较小的__copy_sz = __new_sz > __old_sz ? __old_sz : __new_sz;//把内容copy到新开辟的内存空间memcpy(__result, __p, __copy_sz);//把旧的内存空间给释放掉deallocate(__p, __old_sz);//最后把新的内存地址返回return(__result);
}
8.完整版myallocator.h
#pragma once
#include<mutex>
#include<iostream>
//移植SGI STL二级空间配置器内存池 源码//封装了malloc和free函数,可以设置OOM释放内存的回调函数
template <int __inst>
class __malloc_alloc_template {private:static void* _S_oom_malloc(size_t);static void* _S_oom_realloc(void*, size_t);static void (*__malloc_alloc_oom_handler)();public:static void* allocate(size_t __n){void* __result = malloc(__n);if (0 == __result) __result = _S_oom_malloc(__n);return __result;}static void deallocate(void* __p, size_t /* __n */){free(__p);}static void* reallocate(void* __p, size_t /* old_sz */, size_t __new_sz){void* __result = realloc(__p, __new_sz);if (0 == __result) __result = _S_oom_realloc(__p, __new_sz);return __result;}static void (*__set_malloc_handler(void (*__f)()))(){void (*__old)() = __malloc_alloc_oom_handler;__malloc_alloc_oom_handler = __f;return(__old);}};template <int __inst>
void (*__malloc_alloc_template<__inst>::__malloc_alloc_oom_handler)() = 0;template <int __inst>
void*
__malloc_alloc_template<__inst>::_S_oom_malloc(size_t __n)
{void (*__my_malloc_handler)();void* __result;for (;;) {__my_malloc_handler = __malloc_alloc_oom_handler;if (0 == __my_malloc_handler) { throw std::bad_alloc(); }(*__my_malloc_handler)();__result = malloc(__n);if (__result) return(__result);}
}template <int __inst>
void* __malloc_alloc_template<__inst>::_S_oom_realloc(void* __p, size_t __n)
{void (*__my_malloc_handler)();void* __result;for (;;) {__my_malloc_handler = __malloc_alloc_oom_handler;if (0 == __my_malloc_handler) { throw std::bad_alloc(); }(*__my_malloc_handler)();__result = realloc(__p, __n);if (__result) return(__result);}
}typedef __malloc_alloc_template<0> malloc_alloc;template<typename T>
class myallocator
{
public://vector容器里面要用的东西,不写就会报错using value_type = T;//模仿写vector的allocator的构造和拷贝构造 不写也会报错的constexpr myallocator() noexcept{ // construct default allocator (do nothing)}constexpr myallocator(const myallocator&) noexcept = default;template<class _Other>constexpr myallocator(const myallocator<_Other>&) noexcept{ // construct from a related allocator (do nothing)}//开辟内存 __n是开辟的大小(多少字节)T* allocate(size_t __n){//要传入的是字节数,而容器调用传进来的1,2,3这些数字是个数不是字节数,还要乘以T的大小才行__n = __n * sizeof(T);void* __ret = 0;//大于128字节,直接mallocif (__n > (size_t)_MAX_BYTES) {__ret = malloc_alloc::allocate(__n);}//小于128字节else {_Obj* volatile* __my_free_list= _S_free_list + _S_freelist_index(__n);//线程安全std::lock_guard<std::mutex> guard(mtx);_Obj* __result = *__my_free_list;//内存池有chunk块就去相应大小的链表下面拿,没有的话就看如何进行分配了if (__result == 0)//没有相应大小chunk块,下面解释如何分配__ret = _S_refill(_S_round_up(__n));else {//有相应大小chunk块,就从内存池里面拿出相应的块分配给程序*__my_free_list = __result->_M_free_list_link;__ret = __result;}}//返回我们从内存池申请的chunk块return (T*)__ret;}//释放内存 __n是释放的大小void deallocate(void* __p, size_t __n){//回收的过大 直接用freeif (__n > (size_t)_MAX_BYTES)malloc_alloc::deallocate(__p, __n);else {//定位到要回收的chunk块的地址_Obj* volatile* __my_free_list= _S_free_list + _S_freelist_index(__n);_Obj* __q = (_Obj*)__p;std::lock_guard<std::mutex> guard(mtx);//这里就是链表的头插法//要归还的块是要插入的块,要插入到头结点和头结点的next域指的节点(这个节点是第一个空闲块),而我们归还的这个块就接到头结点的next域,然后要回收的块再接着原来的第一个空闲块,成为新的第一个空闲块,就类比一下链表的头插法就行__q->_M_free_list_link = *__my_free_list;*__my_free_list = __q;// lock is released here 出作用域锁释放}}//内存扩容或缩容void* reallocate(void* __p, size_t __old_sz, size_t __new_sz){void* __result;size_t __copy_sz;//如果旧的和新的全都比128字节大,那说明这就不是从我内存池里面出去的,那就直接调用c的realloc函数if (__old_sz > (size_t)_MAX_BYTES && __new_sz > (size_t)_MAX_BYTES) {return(realloc(__p, __new_sz));}//如果新的和旧的对齐以后一样,那就不用扩容,直接返回 比如一个12,扩容到15,但是这两个的round_up都是16 那就没必要扩容了if (_S_round_up(__old_sz) == _S_round_up(__new_sz)) return(__p);//分配一块新的大小的内存空间__result = allocate(__new_sz);//比较大小,就选个比较小的__copy_sz = __new_sz > __old_sz ? __old_sz : __new_sz;//把内容copy到新开辟的内存空间memcpy(__result, __p, __copy_sz);//把旧的内存空间给释放掉deallocate(__p, __old_sz);//最后把新的内存地址返回return(__result);}//对象构造 定位new实现void construct(T *__p,const T&val){new (__p) T(val);}//对象析构void destroy(T* __p){__p->~T();}
private://自由链表是从8字节开始,以8字节为对齐方式,扩充到128字节//obj数组的第一个链表挂着的是8字节,第二个是16字节,一次类推到128字节enum { _ALIGN = 8 };//内存池最大的chunk块的大小enum { _MAX_BYTES = 128 };//自由链表的数量 16 = 128 / 8enum { _NFREELISTS = 16 };// 每一个内存chunk块(结点)的头信息union _Obj {union _Obj* _M_free_list_link;//保存下一个结点的地址char _M_client_data[1]; };// 组织所有自由链表的数组,数组的每一个元素的类型是_Obj*,全部初始化为 0/*多线程环境下防止线程自己拷贝一个副本,会加一个volatile关键字,使得在数据段或者堆上的数据改变了每个线程都可以立马看到,防止多个线程看到的数据版本不一致*/static _Obj* volatile _S_free_list[_NFREELISTS];//s_free_list存储自由链表数组的地址,这是个数组名,大小就是上面的16//内存池基于freelist实现,需要考虑线程安全,主要做互斥操作static std::mutex mtx;//已分配的内存chunk块的使用情况 初始化全为0//start~~end 分配给程序之后剩下的空闲内存起始和终止地址 heapsize 堆的大小,记录的是已经分配的内存大小 除以16算出来的就是追加量static char* _S_start_free;static char* _S_end_free;static size_t _S_heap_size;/*将 __bytes 上调至最邻近的 8 的倍数 _ALIGN==81-8 全都映射(对齐)到89-16 全都映射(对齐)到16*/static size_t _S_round_up(size_t __bytes){return (((__bytes)+(size_t)_ALIGN - 1) & ~((size_t)_ALIGN - 1));}/*返回 __bytes 大小的chunk块位于 free-list 中的编号作用就是,如果申请的字节在1-8之间,就挂到内存块大小为8的那个链表下面如果申请的字节在9-16之间,就挂到内存块大小为16的那个链表下面*/static size_t _S_freelist_index(size_t __bytes) {return (((__bytes)+(size_t)_ALIGN - 1) / (size_t)_ALIGN - 1);}//把分配好的chunk进行连接的static void* _S_refill(size_t __n){int __nobjs = 20;//chunk_alloc主要负责内存开辟char* __chunk = _S_chunk_alloc(__n, __nobjs);_Obj* volatile* __my_free_list;_Obj* __result;_Obj* __current_obj;_Obj* __next_obj;int __i;if (1 == __nobjs) return(__chunk);__my_free_list = _S_free_list + _S_freelist_index(__n);/* Build free list in chunk *///result和chunk都指向chunk_alloc分配的内存的首地址 chunk指针用来遍历chunk块,result指针指向开头的地方做一个保存__result = (_Obj*)__chunk;//把头指针的位置指向下一chunk块,因为当前的情形是已经要把当前自由链表头指针的位置分配出去了,而头指针的后面才是剩下的空闲的chunk块,再次分配是分配空闲的,分配出去的就没关系了*__my_free_list = __next_obj = (_Obj*)(__chunk + __n);for (__i = 1; ; __i++) {__current_obj = __next_obj;//这行描述的就是遍历过程 先转成char*,这样每次加减都是以字节为单位,chunk指针每一次加8字节到下一个chunk块(不一定是8,这里只是说明,具体多少要看内存块的大小,反正就是到下一个chunk内存块了)__next_obj = (_Obj*)((char*)__next_obj + __n);if (__nobjs - 1 == __i) {__current_obj->_M_free_list_link = 0;break;}else {__current_obj->_M_free_list_link = __next_obj;}}//返回第一个空闲的chunk结点给容器使用return(__result);}//主要负责分配自由链表,chunk块的static char* _S_chunk_alloc(size_t __size,int& __nobjs){char* __result;size_t __total_bytes = __size * __nobjs;size_t __bytes_left = _S_end_free - _S_start_free;if (__bytes_left >= __total_bytes) {__result = _S_start_free;_S_start_free += __total_bytes;return(__result);}else if (__bytes_left >= __size) {__nobjs = (int)(__bytes_left / __size);__total_bytes = __size * __nobjs;__result = _S_start_free;_S_start_free += __total_bytes;return(__result);}else {size_t __bytes_to_get =2 * __total_bytes + _S_round_up(_S_heap_size >> 4);// Try to make use of the left-over piece.if (__bytes_left > 0) {_Obj* volatile* __my_free_list =_S_free_list + _S_freelist_index(__bytes_left);((_Obj*)_S_start_free)->_M_free_list_link = *__my_free_list;*__my_free_list = (_Obj*)_S_start_free;}_S_start_free = (char*)malloc(__bytes_to_get);if (nullptr == _S_start_free) {size_t __i;_Obj* volatile* __my_free_list;_Obj* __p;// Try to make do with what we have. That can't// hurt. We do not try smaller requests, since that tends// to result in disaster on multi-process machines.for (__i = __size;__i <= (size_t)_MAX_BYTES;__i += (size_t)_ALIGN) {__my_free_list = _S_free_list + _S_freelist_index(__i);__p = *__my_free_list;if (0 != __p) {*__my_free_list = __p->_M_free_list_link;_S_start_free = (char*)__p;_S_end_free = _S_start_free + __i;return(_S_chunk_alloc(__size, __nobjs));// Any leftover piece will eventually make it to the// right free list.}}_S_end_free = 0; // In case of exception._S_start_free = (char*)malloc_alloc::allocate(__bytes_to_get);// This should either throw an// exception or remedy the situation. Thus we assume it// succeeded.}_S_heap_size += __bytes_to_get;_S_end_free = _S_start_free + __bytes_to_get;return(_S_chunk_alloc(__size, __nobjs));}}};//静态成员变量初始化
template <typename T>
char* myallocator<T>::_S_start_free = nullptr;
template <typename T>
char* myallocator<T>::_S_end_free = nullptr;
template <typename T>
size_t myallocator<T>::_S_heap_size = 0;template <typename T>
//这里的typename告诉编译器这里是一个类型定义
typename myallocator<T>::_Obj* volatile myallocator<T>::_S_free_list[_NFREELISTS]=
{nullptr,nullptr, nullptr, nullptr, nullptr, nullptr, nullptr, nullptr, nullptr, nullptr, nullptr, nullptr, nullptr, nullptr, nullptr, nullptr};template <typename T>
std::mutex myallocator<T>::mtx;9.pch.h和pch.cpp
//.h
#pragma once
#ifndef PCH_H
#define PCH_H#endif
//.cpp
#include"pch.h"
10.测试
#include <iostream>
#include<vector>
#include"pch.h"
#include"myallocator.h"using namespace std;int main()
{vector<int, myallocator<int>> v;for (int i = 0; i < 100; i++)v.push_back(rand() % 1000);for (int val : v)cout << val << " ";cout << endl;return 0;
}
总结:
通过源码移植可以更加清楚内存池整个分配内存和释放的过程。
侯捷老师内存管理第二章和施磊老师的课程讲清楚了原理和流程。
施磊老师的手写移植内存池是进行实践。
相关文章:

施磊C++ | 项目实战 | 手写移植SGI STL二级空间配置器内存池 项目源码
手写移植SGI STL二级空间配置器内存池 项目源码 笔者建议配合这两篇博客进行学习 侯捷 | C | 内存管理 | 学习笔记(二):第二章节 std::allocator-CSDN博客 施磊C | 项目实战 | SGI STL二级空间配置器源码剖析-CSDN博客 文章目录 手写移植SGI STL二级空…...

C++ | Leetcode C++题解之第507题完美数
题目: 题解: class Solution { public:bool checkPerfectNumber(int num) {if (num 1) {return false;}int sum 1;for (int d 2; d * d < num; d) {if (num % d 0) {sum d;if (d * d < num) {sum num / d;}}}return sum num;} };...
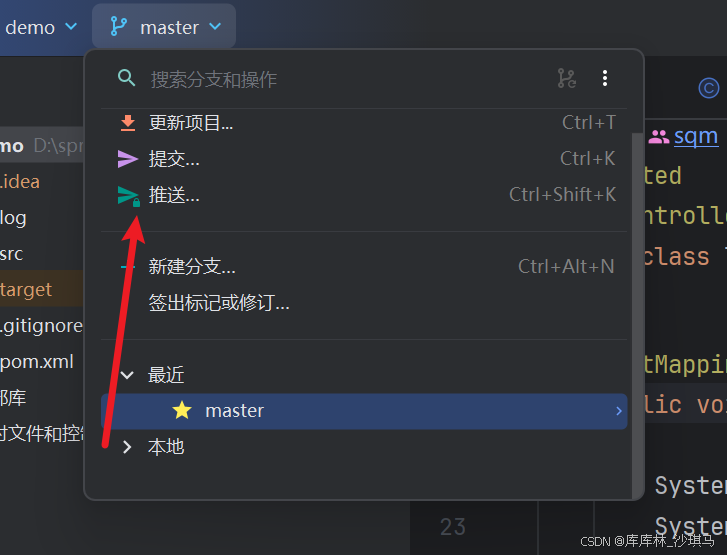
Git快速上手
概述 Git 是一个免费且开源的分布式版本控制系统,被广泛用于软件开发中的代码版本控制。通过使用 Git,开发者可以高效地追踪文件的变化历史,并支持多人协作开发。本教程将带你快速了解 Git 的基本概念和操作,帮助你开始使用 Git …...

宝塔如何部署Django项目(前后端分离篇)
一、环境安装 1、安装相关软件 点击软件商店,安装下面软件 一、宝塔部署前端 1、打包Vue项目 打开Vue3项目,输入下面打包命令,对Vue项目进行打包, npm run build 2、部署前端 点击宝塔的网站,在PHP项目里点击添加…...

JavaScript解析JSON对象及JSON字符串
1、问题概述? JavaScript解析JSON对象是常用功能之一。 此处我们要明确JSON对象和JSON字符串的区别?否则会给我们的解析带来困扰。 主要实现如下功能: 1、JavaScript解析JSON字符串和JSON对象? 2、JavaScript解析JSON数组? 3、JavaSc…...

Elasticsearch 构建实时数据可视化应用
Elasticsearch 构建实时数据可视化应用 Elasticsearch 构建实时数据可视化应用一、构建实时数据可视化应用的基本原则1. 数据采集2. 数据处理和清洗3. 数据存储和索引4. 数据可视化展示二、实时数据可视化应用数据存储和检索功能基于Elasticsearch构建实时数据搜索和过滤功能El…...

NVR批量管理软件/平台EasyNVR多个NVR同时管理:H.265与H.264编码优势和差异深度剖析
在数字化安防领域,视频监控系统正逐步成为各行各业不可或缺的一部分。随着技术的不断进步,传统的视频监控系统已经难以满足日益复杂和多变的监控需求。下面我们谈及NVR批量管理软件/平台EasyNVR平台H.265与H.264编码优势及差异。 一、EasyNVR视频汇聚平台…...

C/C++(六)多态
本文将介绍C的另一个基于继承的重要且复杂的机制,多态。 一、多态的概念 多态,就是多种形态,通俗来说就是不同的对象去完成某个行为,会产生不同的状态。 多态严格意义上分为静态多态与动态多态,我们平常说的多态一般…...
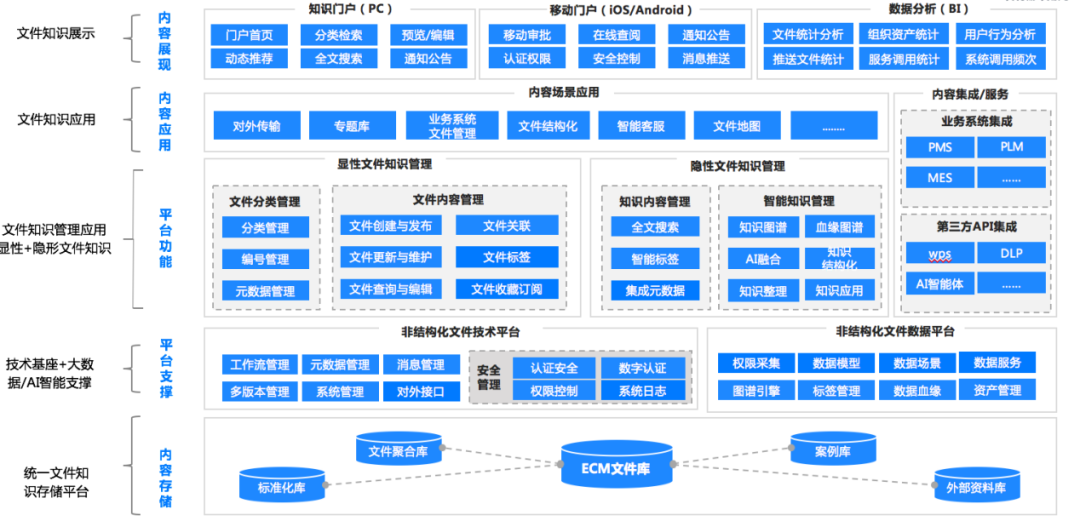
汽车及零配件企业海量文件数据如何管
汽车行业特点 汽车行业是工业企业皇冠上的一颗明珠,在国民经济中占据着举足轻重的地位。汽车行业具备技术密集、创新速度快、供应链复杂等特点,具体体现为: 技术密集:汽车行业是技术密集型行业,覆盖机械、电子、软件、…...

【AI学习】Mamba学习(十二):深入理解S4模型
#1024程序员节|征文# HiPPO的学习暂告一段落,按照“HiPPO->S4->Mamba 演化历程”,接着学习S4。 S4对应的论文:《Efficiently Modeling Long Sequences with Structured State Spaces》 文章链接:https://ar5iv…...

linux入门之必掌握知识点
#1024程序员节|征文# Linux基础 top命令详解 top命令是用来查看进程系统资源使用情况的工具,它可以动态的现实。 top命令执行后,按大写M可以按内存使用情况进行排序,大写P可以按CPU使用情况进行排序,大写H可以显示线…...

【Web.路由]——路由原理
这篇文章,我们来讲一讲什么是路由。 路由是 将用户请求地址映射为一个请求委托的过程,负责匹配传入的Http请求,然后将这些请求发送到应用的可执行终结点。 这里需要注意一个内容,发送到应用的可执行终结点。 路由的分类&#x…...

Spring Boot技术在中小企业设备管理中的应用
2相关技术 2.1 MYSQL数据库 MySQL是一个真正的多用户、多线程SQL数据库服务器。 是基于SQL的客户/服务器模式的关系数据库管理系统,它的有点有有功能强大、使用简单、管理方便、安全可靠性高、运行速度快、多线程、跨平台性、完全网络化、稳定性等,非常…...
)
Lua表(Table)
软考鸭微信小程序 过软考,来软考鸭! 提供软考免费软考讲解视频、题库、软考试题、软考模考、软考查分、软考咨询等服务 Lua中的表(table)是一种核心数据结构,它既是数组也是字典,能够存储多种类型的数据,包括数字、字符…...

51单片机应用开发(进阶)---外部中断(按键+数码管显示0-F)
实现目标 1、巩固数码管、外部中断知识 2、具体实现:按键K4(INT1)每按一次,数码管从0依次递增显示至F,再按则循环显示。 一、共阳数码管 1.1 共阳数码管结构 1.2 共阳数码管码表 共阳不带小数点0-F段码为ÿ…...

怎么区分主谓宾I love you与主系表I am fine? 去掉宾语看句子完整性 主系表结构则侧重于描述主语的状态、特征或性质
主谓宾与主系表是英语句子结构中的两种基本类型,它们在关注点、动词分类以及句子完整性方面有所区别。具体分析如下: 关注点 主谓宾I love you:主谓宾结构主要关注动作和影响对象之间的关系[1]。这种结构强调的是动态和行为,通常描…...

私域流量运营的误区
私域流量运营是近年来营销领域的重要趋势,但在实际操作中,很多企业和个人容易陷入一些误区。以下是几个常见的私域流量运营误区及其解决方法: 1. 只关注流量,不重视内容 误区:许多运营者认为,只要吸引到足…...

VirtualBox虚拟机桥接模式固定ip详解
VirtualBox虚拟机桥接模式固定ip详解 VirtualBox 桥接设置Ubuntu 24.04使用固定IP问题记录 VirtualBox 桥接设置 为什么设置桥接模式?桥接模式可以实现物理机和虚拟机互相通信,虚拟机也可以访问互联网(推荐万金油),物…...

面试问题基础记录24/10/24
面试问题基础记录24/10/24 问题一:LoRA是用在节省资源的场景下,那么LoRA具体是节省了内存带宽还是显存呢?问题二:假如用pytorch完成一个分类任务,那么具体的流程是怎么样的?问题三:详细介绍一下…...

中国区 Microsoft365主页链接请您参考:
Microsoft365主页链接请您参考: Redirecting PPAC链接请您参考: Power Platform admin center 关于Power Automate开启工单是在 https://portal.partner.microsoftonline.cn/Support/SupportOverview.aspx进行提交的。 对应所需对应管理员可以分配以下…...

3大核心模块+5步实战指南:Betaflight飞控固件深度解析与配置方案
3大核心模块5步实战指南:Betaflight飞控固件深度解析与配置方案 【免费下载链接】betaflight Open Source Flight Controller Firmware 项目地址: https://gitcode.com/gh_mirrors/be/betaflight Betaflight作为开源飞控固件的标杆,为多旋翼和固定…...

从样式覆盖到版本升级:全面解析Antd表格固定列对齐问题的解决路径
1. 问题复现:当Antd表格固定列开始"跳舞" 第一次遇到Antd表格固定列错位问题时,我正喝着咖啡调试一个后台管理系统。突然发现表格右侧的固定列像被施了魔法——表头和内容列完全错开,活像跳着蹩脚的探戈。这种问题在Antd 3.x版本中…...

第57篇:Vibe Coding时代:LangGraph + 代码所有者规则实战,解决 Agent 修改核心模块无人负责的问题
第57篇:Vibe Coding时代:LangGraph + 代码所有者规则实战,解决 Agent 修改核心模块无人负责的问题 一、问题场景:Agent 修改了核心文件,但没有找到该找谁审 在团队项目中,不同模块通常有不同负责人: auth 模块:安全团队 payment 模块:支付团队 database 模块:平台团…...

技术演讲的恐惧症:从实验室到舞台的艰难跨越
一、实验室里的从容,舞台上的慌乱对于软件测试从业者而言,实验室是我们的“舒适区”。在堆满服务器、屏幕上跳动着代码与测试用例的空间里,我们能精准定位一行代码的bug,能设计出覆盖所有场景的测试方案,能在复杂的系统…...

详解 Deepsec:Vercel 开源 AI 代码安全防护工具的技术架构与实现原理
摘要在 AI 大模型深度融入软件开发全链路的今天,代码安全防护正面临 “复杂逻辑漏洞难发现、传统工具误报率高、源码隐私保护难” 三重核心挑战。Vercel 开源的 Deepsec 作为一款Agent 驱动的本地化 AI 安全防护工具,跳出传统 SAST(静态应用安…...

5分钟彻底解决Windows软件DLL缺失问题:VisualCppRedist AIO完整修复方案
5分钟彻底解决Windows软件DLL缺失问题:VisualCppRedist AIO完整修复方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过新安装的软…...
)
别再手动拷贝DLL了!用批处理一键搞定NX二次开发EXE的环境变量配置(VS2015+NX12)
NX二次开发环境配置革命:批处理脚本全自动解决方案 引言 对于NX二次开发工程师来说,最令人头疼的莫过于每次编译后的EXE文件无法直接运行的问题。传统解决方案要么需要手动拷贝DLL文件,要么必须将EXE放置到特定目录下,这些方法不仅…...

从荧光灯到充电器:剖析MJE13001高压小功率三极管的实战选型与参数验证
1. MJE13001三极管的前世今生 第一次见到MJE13001这颗三极管是在修理一台老式荧光灯电子镇流器时。当时电路板上那颗黑乎乎的小元件已经烧得发黄,但依稀能看到"13001"的标识。拆下来用万用表测量发现CE结已经击穿,换上新的MJE13001后…...
)
告别手搓测试平台:用Synopsys SVT APB VIP快速搭建你的SoC验证环境(附完整配置流程)
告别手搓测试平台:用Synopsys SVT APB VIP快速搭建你的SoC验证环境(附完整配置流程) 在SoC验证领域,APB总线作为AMBA协议家族中最基础的外设连接标准,几乎出现在每一个现代芯片设计中。然而,许多验证工程师…...

Shinkai Node:无代码AI智能体平台架构解析与实战部署
1. 项目概述:Shinkai Node,一个无需代码的AI智能体构建平台 最近在折腾AI智能体(AI Agent)的时候,发现了一个挺有意思的开源项目—— Shinkai Node 。它来自dcSpark团队,核心目标非常明确: …...