nnMamba用于糖尿病视网膜病变检测测试
1.代码修改
源码是针对3D单通道图像的,只需要简单改写为2D就行,修改nnMamba4cls.py代码如下:
# -*- coding: utf-8 -*-
# 作者: Mr Cun
# 文件名: nnMamba4cls.py
# 创建时间: 2024-10-25
# 文件描述:修改nnmamba,使其适应3通道2分类DR分类任务import torch
import torch.nn as nn
import torch.nn.functional as F
from mamba_ssm import Mambadef conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):"""3x3 convolution with padding."""return nn.Conv2d(in_planes,out_planes,kernel_size=3,stride=stride,padding=dilation,groups=groups,bias=False,dilation=dilation,)def conv1x1(in_planes, out_planes, stride=1):"""1x1 convolution."""return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)class BasicBlock(nn.Module):expansion = 1def __init__(self, inplanes, planes, stride=1, downsample=None):super(BasicBlock, self).__init__()# Both self.conv1 and self.downsample layers downsample the input when stride != 1self.conv1 = conv3x3(inplanes, planes, stride)self.bn1 = nn.BatchNorm2d(planes)self.relu = nn.ReLU(inplace=True)self.conv2 = conv3x3(planes, planes)self.bn2 = nn.BatchNorm2d(planes)self.downsample = downsampleself.stride = stridedef forward(self, x):identity = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return outdef make_res_layer(inplanes, planes, blocks, stride=1):downsample = nn.Sequential(conv1x1(inplanes, planes, stride),nn.BatchNorm2d(planes),)layers = []layers.append(BasicBlock(inplanes, planes, stride, downsample))for _ in range(1, blocks):layers.append(BasicBlock(planes, planes))return nn.Sequential(*layers)class MambaLayer(nn.Module):def __init__(self, dim, d_state=8, d_conv=4, expand=2):super().__init__()self.dim = dimself.nin = conv1x1(dim, dim)self.nin2 = conv1x1(dim, dim)self.norm2 = nn.BatchNorm2d(dim) # LayerNormself.relu2 = nn.ReLU(inplace=True)self.relu3 = nn.ReLU(inplace=True)self.norm = nn.BatchNorm2d(dim) # LayerNormself.relu = nn.ReLU(inplace=True)self.mamba = Mamba(d_model=dim, # Model dimension d_modeld_state=d_state, # SSM state expansion factord_conv=d_conv, # Local convolution widthexpand=expand # Block expansion factor)def forward(self, x):B, C = x.shape[:2]x = self.nin(x)x = self.norm(x)x = self.relu(x)act_x = xassert C == self.dimn_tokens = x.shape[2:].numel()img_dims = x.shape[2:]x_flat = x.reshape(B, C, n_tokens).transpose(-1, -2)x_mamba = self.mamba(x_flat)out = x_mamba.transpose(-1, -2).reshape(B, C, *img_dims)# act_x = self.relu3(x)out += act_xout = self.nin2(out)out = self.norm2(out)out = self.relu2(out)return outclass MambaSeq(nn.Module):def __init__(self, dim, d_state=16, d_conv=4, expand=2):super().__init__()self.dim = dimself.relu = nn.ReLU(inplace=True)self.mamba = Mamba(d_model=dim, # Model dimension d_modeld_state=d_state, # SSM state expansion factord_conv=d_conv, # Local convolution widthexpand=expand # Block expansion factor)def forward(self, x):B, C = x.shape[:2]x = self.relu(x)assert C == self.dimn_tokens = x.shape[2:].numel()img_dims = x.shape[2:]x_flat = x.reshape(B, C, n_tokens).transpose(-1, -2)x_mamba = self.mamba(x_flat)out = x_mamba.transpose(-1, -2).reshape(B, C, *img_dims)return outclass DoubleConv(nn.Module):def __init__(self, in_ch, out_ch, stride=1, kernel_size=3):super(DoubleConv, self).__init__()self.conv = nn.Sequential(nn.Conv2d(in_ch, out_ch, kernel_size=kernel_size, stride=stride, padding=int(kernel_size / 2)),nn.BatchNorm2d(out_ch),nn.ReLU(inplace=True),nn.Conv2d(out_ch, out_ch, 3, padding=1, dilation=1),nn.BatchNorm2d(out_ch),nn.ReLU(inplace=True),)def forward(self, input):return self.conv(input)class SingleConv(nn.Module):def __init__(self, in_ch, out_ch):super(SingleConv, self).__init__()self.conv = nn.Sequential(nn.Conv2d(in_ch, out_ch, 3, padding=1), nn.BatchNorm2d(out_ch), nn.ReLU(inplace=True))def forward(self, input):return self.conv(input)class nnMambaEncoder(nn.Module):def __init__(self, in_ch=3, channels=32, blocks=3, number_classes=2):super(nnMambaEncoder, self).__init__()self.in_conv = DoubleConv(in_ch, channels, stride=2, kernel_size=3)self.mamba_layer_stem = MambaLayer(dim=channels, # Model dimension d_modeld_state=8, # SSM state expansion factord_conv=4, # Local convolution widthexpand=2 # Block expansion factor)self.layer1 = make_res_layer(channels, channels * 2, blocks, stride=2)self.layer2 = make_res_layer(channels * 2, channels * 4, blocks, stride=2)self.layer3 = make_res_layer(channels * 4, channels * 8, blocks, stride=2)self.pooling = nn.AdaptiveAvgPool2d((1, 1))self.mamba_seq = MambaSeq(dim=channels*2, # Model dimension d_modeld_state=8, # SSM state expansion factord_conv=2, # Local convolution widthexpand=2 # Block expansion factor)self.mlp = nn.Sequential(nn.Linear(channels*14, channels), nn.ReLU(), nn.Dropout(0.5), nn.Linear(channels, number_classes))def forward(self, x):c1 = self.in_conv(x)c1_s = self.mamba_layer_stem(c1) + c1c2 = self.layer1(c1_s)c3 = self.layer2(c2)c4 = self.layer3(c3)pooled_c2_s = self.pooling(c2)pooled_c3_s = self.pooling(c3)pooled_c4_s = self.pooling(c4)h_feature = torch.cat((pooled_c2_s.reshape(c1.shape[0], c1.shape[1]*2, 1), pooled_c3_s.reshape(c1.shape[0], c1.shape[1]*2, 2), pooled_c4_s.reshape(c1.shape[0], c1.shape[1]*2, 4)), dim=2)h_feature_att = self.mamba_seq(h_feature) + h_featureh_feature = h_feature_att.reshape(c1.shape[0], -1)return self.mlp(h_feature)if __name__ == "__main__":model = nnMambaEncoder().cuda()input = torch.zeros((8, 3, 224,224)).cuda()output = model(input)print(output.shape)2.增加训练代码和数据集代码
- dr_dataset.py
# -*- coding: utf-8 -*-
# 作者: Mr.Cun
# 文件名: dr_dataset.py
# 创建时间: 2024-10-25
# 文件描述:视网膜数据处理import torch
import numpy as np
import os
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
from torchvision import transforms, datasetsroot_path = '/home/aic/deep_learning_data/retino_data'
batch_size = 64 # 根据自己电脑量力而行
class_labels = {0: 'Diabetic Retinopathy', 1: 'No Diabetic Retinopathy'}
# 设置随机种子
torch.manual_seed(42)
np.random.seed(42)class RetinaDataset:def __init__(self, root_path, batch_size,class_labels):self.root_path = root_pathself.batch_size = batch_sizeself.class_labels = class_labelsself.transform = self._set_transforms()self.train_dataset = self._load_dataset('train')self.val_dataset = self._load_dataset('valid')self.test_dataset = self._load_dataset('test')self.train_loader = DataLoader(self.train_dataset, batch_size=self.batch_size, shuffle=True)self.valid_loader = DataLoader(self.val_dataset, batch_size=self.batch_size, shuffle=False)self.test_loader = DataLoader(self.test_dataset, batch_size=self.batch_size, shuffle=False)def _set_transforms(self):return transforms.Compose([transforms.Resize((224, 224)),transforms.RandomHorizontalFlip(p=0.5),transforms.RandomVerticalFlip(p=0.5),transforms.RandomRotation(30),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),])def _load_dataset(self, split):root = os.path.join(self.root_path, split)return datasets.ImageFolder(root=root, transform=self.transform)def visualize_samples(self, loader):figure = plt.figure(figsize=(12, 12))cols, rows = 4, 4for i in range(1, cols * rows + 1):sample_idx = np.random.randint(len(loader.dataset))img, label = loader.dataset[sample_idx]figure.add_subplot(rows, cols, i)plt.title(self.class_labels[label])plt.axis("off")img_np = img.numpy().transpose((1, 2, 0))img_valid_range = np.clip(img_np, 0, 1)plt.imshow(img_valid_range)plt.show()if __name__ == '__main__':processor = RetinaDataset(root_path, batch_size,class_labels)processor.visualize_samples(processor.train_loader)
- train.py
# -*- coding: utf-8 -*-
# 作者: Mr Cun
# 文件名: train.py
# 创建时间: 2024-10-25
# 文件描述:模型训练
import json
import os
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
from timm.utils import accuracy, AverageMeter, ModelEma
from sklearn.metrics import classification_report
from timm.data.mixup import Mixup
from nnMamba4cls import *
from torchvision import datasets
torch.backends.cudnn.benchmark = False
import warnings
from dr_dataset import RetinaDatasetwarnings.filterwarnings("ignore")
os.environ['CUDA_VISIBLE_DEVICES']="0"# 设置随机因子
def seed_everything(seed=42):os.environ['PYHTONHASHSEED'] = str(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.backends.cudnn.deterministic = True# 设置全局参数
model_lr = 3e-4
BATCH_SIZE = 64
EPOCHS = 300
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
use_amp = False # 是否使用混合精度
use_dp = False # 是否开启dp方式的多卡训练
classes = 2
resume = None
CLIP_GRAD = 5.0
Best_ACC = 0 # 记录最高得分
use_ema = False
use_mixup = False
model_ema_decay = 0.9998
start_epoch = 1
seed = 1
seed_everything(seed)# 数据预处理
transform = transforms.Compose([transforms.RandomRotation(10),transforms.GaussianBlur(kernel_size=(5, 5), sigma=(0.1, 3.0)),transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5),transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.41593555, 0.22245076, 0.075719066],std=[0.23819199, 0.13202211, 0.05282707])])
transform_test = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.41593555, 0.22245076, 0.075719066],std=[0.23819199, 0.13202211, 0.05282707])
])mixup_fn = Mixup(mixup_alpha=0.8, cutmix_alpha=1.0, cutmix_minmax=None,prob=0.1, switch_prob=0.5, mode='batch',label_smoothing=0.1, num_classes=classes)# 加载数据集
root_path = '/home/aic/deep_learning_data/retino_data'
train_path = os.path.join(root_path, 'train')
valid_path = os.path.join(root_path, 'valid')
test_path = os.path.join(root_path, 'test')
dataset_train = datasets.ImageFolder(train_path, transform=transform)
dataset_test = datasets.ImageFolder(test_path, transform=transform_test)
class_labels = {0: 'Diabetic Retinopathy', 1: 'No Diabetic Retinopathy'}
# 导入数据
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, num_workers=8, shuffle=True,drop_last=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)# 设置loss
# 实例化模型并且移动到GPU
# criterion_train = SoftTargetCrossEntropy() #mixup_fn
criterion_train = torch.nn.CrossEntropyLoss()
criterion_val = torch.nn.CrossEntropyLoss()# 设置模型
# 设置模型
model_ft = nnMambaEncoder()print(model_ft)if resume:model = torch.load(resume)print(model['state_dict'].keys())model_ft.load_state_dict(model['state_dict'])Best_ACC = model['Best_ACC']start_epoch = model['epoch'] + 1
model_ft.to(DEVICE)
print(model_ft)# 选择简单暴力的Adam优化器,学习率调低
optimizer = optim.AdamW(model_ft.parameters(), lr=model_lr)
cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-6)# 设置混合精度,EMA
if use_amp:scaler = torch.cuda.amp.GradScaler()
if torch.cuda.device_count() > 1 and use_dp:print("Let's use", torch.cuda.device_count(), "GPUs!")model_ft = torch.nn.DataParallel(model_ft)
if use_ema:model_ema = ModelEma(model_ft,decay=model_ema_decay,device=DEVICE,resume=resume)
else:model_ema = None# 定义训练过程
def train(model, device, train_loader, optimizer, epoch, model_ema):model.train()loss_meter = AverageMeter()acc1_meter = AverageMeter()total_num = len(train_loader.dataset)print(total_num, len(train_loader))for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True)if use_mixup:samples, targets = mixup_fn(data, target)else:samples, targets = data, targetoutput = model(samples)optimizer.zero_grad()if use_amp:with torch.cuda.amp.autocast():loss = torch.nan_to_num(criterion_train(output, targets))scaler.scale(loss).backward()torch.nn.utils.clip_grad_norm_(model.parameters(), CLIP_GRAD)# Unscales gradients and calls# or skips optimizer.step()scaler.step(optimizer)# Updates the scale for next iterationscaler.update()else:loss = criterion_train(output, targets)loss.backward()# torch.nn.utils.clip_grad_norm_(models.parameters(), CLIP_GRAD)optimizer.step()if model_ema is not None:model_ema.update(model)torch.cuda.synchronize()lr = optimizer.state_dict()['param_groups'][0]['lr']loss_meter.update(loss.item(), target.size(0))# acc1, acc5 = accuracy(output, target)acc1 = accuracy(output, target)[0]loss_meter.update(loss.item(), target.size(0))acc1_meter.update(acc1.item(), target.size(0))if (batch_idx + 1) % 10 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tLR:{:.9f}'.format(epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),100. * (batch_idx + 1) / len(train_loader), loss.item(), lr))ave_loss = loss_meter.avgacc = acc1_meter.avgprint('epoch:{}\tloss:{:.2f}\tacc:{:.2f}'.format(epoch, ave_loss, acc))return ave_loss, acc# 验证过程
@torch.no_grad()
def val(model, device, test_loader):global Best_ACCmodel.eval()loss_meter = AverageMeter()acc1_meter = AverageMeter()# acc5_meter = AverageMeter()total_num = len(test_loader.dataset)print(total_num, len(test_loader))val_list = []pred_list = []for data, target in test_loader:for t in target:val_list.append(t.data.item())data, target = data.to(device,non_blocking=True), target.to(device,non_blocking=True)output = model(data)loss = criterion_val(output, target)_, pred = torch.max(output.data, 1)for p in pred:pred_list.append(p.data.item())acc1 = accuracy(output, target)[0]loss_meter.update(loss.item(), target.size(0))acc1_meter.update(acc1.item(), target.size(0))acc = acc1_meter.avgprint('\nVal set: Average loss: {:.4f}\tAcc1:{:.3f}%\t'.format(loss_meter.avg, acc,))if acc > Best_ACC:if isinstance(model, torch.nn.DataParallel):torch.save(model.module, file_dir + '/' + 'best.pth')else:torch.save(model, file_dir + '/' + 'best.pth')Best_ACC = accif isinstance(model, torch.nn.DataParallel):state = {'epoch': epoch,'state_dict': model.module.state_dict(),'Best_ACC':Best_ACC}if use_ema:state['state_dict_ema']=model.module.state_dict()torch.save(state, file_dir + "/" + 'model_' + str(epoch) + '_' + str(round(acc, 3)) + '.pth')else:state = {'epoch': epoch,'state_dict': model.state_dict(),'Best_ACC': Best_ACC}if use_ema:state['state_dict_ema']=model.state_dict()torch.save(state, file_dir + "/" + 'model_' + str(epoch) + '_' + str(round(acc, 3)) + '.pth')return val_list, pred_list, loss_meter.avg, acc# 绘制训练和验证的损失和准确率曲线
def plot_training_curves(file_dir,epoch_list,train_loss_list,val_loss_list,train_acc_list,val_acc_list):fig = plt.figure(1)plt.plot(epoch_list, train_loss_list, 'r-', label=u'Train Loss')# 显示图例plt.plot(epoch_list, val_loss_list, 'b-', label=u'Val Loss')plt.legend(["Train Loss", "Val Loss"], loc="upper right")plt.xlabel(u'epoch')plt.ylabel(u'loss')plt.title('Model Loss ')plt.savefig(file_dir + "/loss.png")plt.close(1)fig2 = plt.figure(2)plt.plot(epoch_list, train_acc_list, 'r-', label=u'Train Acc')plt.plot(epoch_list, val_acc_list, 'b-', label=u'Val Acc')plt.legend(["Train Acc", "Val Acc"], loc="lower right")plt.title("Model Acc")plt.ylabel("acc")plt.xlabel("epoch")plt.savefig(file_dir + "/acc.png")plt.close(2)if __name__ == '__main__':# 创建保存模型的文件夹file_dir = 'checkpoints/EfficientVMamba/'if os.path.exists(file_dir):print('true')os.makedirs(file_dir, exist_ok=True)else:os.makedirs(file_dir)# 训练与验证is_set_lr = Falselog_dir = {}train_loss_list, val_loss_list, train_acc_list, val_acc_list, epoch_list = [], [], [], [], []if resume and os.path.isfile(file_dir+"result.json"):with open(file_dir+'result.json', 'r', encoding='utf-8') as file:logs = json.load(file)train_acc_list = logs['train_acc']train_loss_list = logs['train_loss']val_acc_list = logs['val_acc']val_loss_list = logs['val_loss']epoch_list = logs['epoch_list']for epoch in range(start_epoch, EPOCHS + 1):epoch_list.append(epoch)log_dir['epoch_list'] = epoch_listtrain_loss, train_acc = train(model_ft,DEVICE,train_loader,optimizer,epoch,model_ema)train_loss_list.append(train_loss)train_acc_list.append(train_acc)log_dir['train_acc'] = train_acc_listlog_dir['train_loss'] = train_loss_listif use_ema:val_list, pred_list, val_loss, val_acc = val(model_ema.ema, DEVICE, test_loader)else:val_list, pred_list, val_loss, val_acc = val(model_ft, DEVICE, test_loader)val_loss_list.append(val_loss)val_acc_list.append(val_acc)log_dir['val_acc'] = val_acc_listlog_dir['val_loss'] = val_loss_listlog_dir['best_acc'] = Best_ACCwith open(file_dir + '/result.json', 'w', encoding='utf-8') as file:file.write(json.dumps(log_dir))print(classification_report(val_list, pred_list, target_names=dataset_train.class_to_idx))if epoch < 600:cosine_schedule.step()else:if not is_set_lr:for param_group in optimizer.param_groups:param_group["lr"] = 1e-6is_set_lr = True# 绘制训练和验证的损失和准确率曲线plot_training_curves(file_dir,epoch_list,train_loss_list,val_loss_list,train_acc_list,val_acc_list)
3.效果
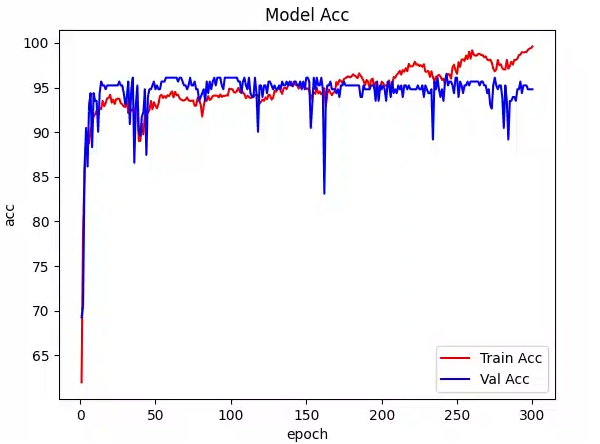
对比之前的几种mamba,针对糖尿病视网膜病变数据集,采用同样的训练参数:300 Epochs,32 Batch Size。
| 序号 | 模型 | 验证集最高准确率 | 显存占用 | 训练时间 |
|---|---|---|---|---|
| 1 | Vision Mamba | 94% | 约12GB | 约3小时 |
| 2 | VMamba | 98.12% | 约24GB | 约2小时 |
| 3 | EfficientVMamba | 95.23% | 约20GB | 约2小时 |
| 4 | MedMamba | 92.3% | 约20GB | 约2小时 |
| 5 | MambaVision | 95.4% | 约20GB | 约2小时 |
| 6 | nnMamba | 96.53% | 约6GB | 约30分钟 |
4.修改代码试试看
这里我只是在增加了一层Residual Block提取,验证集最好的ACC是96.53%
class nnMambaEncoder(nn.Module):def __init__(self, in_ch=3, channels=32, blocks=3, number_classes=2):super(nnMambaEncoder, self).__init__()self.in_conv = DoubleConv(in_ch, channels, stride=2, kernel_size=3)self.mamba_layer_stem = MambaLayer(dim=channels, # Model dimension d_modeld_state=8, # SSM state expansion factord_conv=4, # Local convolution widthexpand=2 # Block expansion factor)self.layer1 = make_res_layer(channels, channels * 2, blocks, stride=2)self.layer2 = make_res_layer(channels * 2, channels * 4, blocks, stride=2)self.layer3 = make_res_layer(channels * 4, channels * 8, blocks, stride=2)self.layer4 = make_res_layer(channels * 8, channels * 16, blocks, stride=2)self.pooling = nn.AdaptiveAvgPool2d((1, 1))self.mamba_seq = MambaSeq(dim=channels*2, # Model dimension d_modeld_state=8, # SSM state expansion factord_conv=2, # Local convolution widthexpand=2 # Block expansion factor)self.mlp = nn.Sequential(nn.Linear(channels*30, channels), nn.ReLU(), nn.Dropout(0.5), nn.Linear(channels, number_classes))def forward(self, x):c1 = self.in_conv(x)c1_s = self.mamba_layer_stem(c1) + c1c2 = self.layer1(c1_s)c3 = self.layer2(c2)c4 = self.layer3(c3)c5 = self.layer4(c4)pooled_c2_s = self.pooling(c2)pooled_c3_s = self.pooling(c3)pooled_c4_s = self.pooling(c4)pooled_c5_s = self.pooling(c5)h_feature = torch.cat((pooled_c2_s.reshape(c1.shape[0], c1.shape[1]*2, 1),pooled_c3_s.reshape(c1.shape[0], c1.shape[1]*2, 2),pooled_c4_s.reshape(c1.shape[0], c1.shape[1]*2, 4),pooled_c5_s.reshape(c1.shape[0], c1.shape[1]*2, 8)), dim=2)h_feature_att = self.mamba_seq(h_feature) + h_feature # B 64 15h_feature = h_feature_att.reshape(c1.shape[0], -1) # B 960return self.mlp(h_feature)
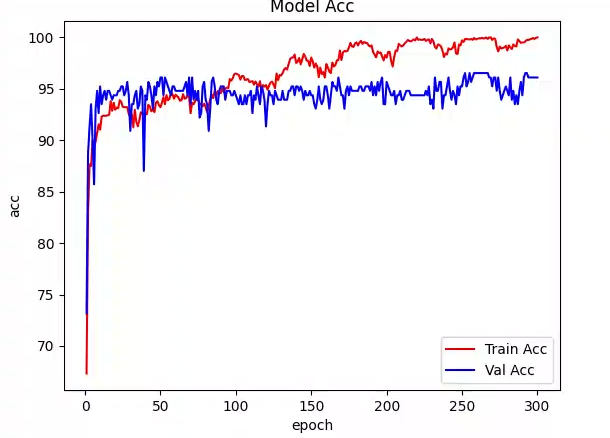
如果继续优化层的设置,应该会有更好的提升,这里就不继续做了
相关文章:
nnMamba用于糖尿病视网膜病变检测测试
1.代码修改 源码是针对3D单通道图像的,只需要简单改写为2D就行,修改nnMamba4cls.py代码如下: # -*- coding: utf-8 -*- # 作者: Mr Cun # 文件名: nnMamba4cls.py # 创建时间: 2024-10-25 # 文件描述:修改nnmamba,使…...

【Spring MVC】创建项目和建立请求连接
我的主页:2的n次方_ 1. MVC MVC 是 Model View Controller 的缩写,它是软件⼯程中的⼀种软件架构设计模式,它把软件系统分为模型、视图和控制器三个基本部分。 View (视图): 指在应⽤程序中专⻔⽤来与浏览器进⾏交互&…...

台达A2伺服
驱动器: L 外接脉冲 U 在L的基础上增加DI E ethercat总线 F 台达 M CANopen总线 电机: ECMA-C A 0604 SS...

ReactOS系统中搜索给定长度的空间地址区间中的二叉树
搜索给定长度的空间地址区间 //搜索给定长度的空间地址区间 MmFindGap MmFindGapTopDown PVOID NTAPI MmFindGap(PMADDRESS_SPACE AddressSpace,ULONG_PTR Length,ULONG_PTR Granularity,BOOLEAN TopDown );PMADDRESS_SPACE AddressSpace,//该进程用户空间 ULONG_PTR Length,…...

Postgresql中和时间相关的字段类型及其适用场景
PostgreSQL 提供了多种数据类型来表示时间和日期,适用于不同的场景和需求。以下是常用的时间类型及其适用场景: 1. TIMESTAMP WITH TIME ZONE (TIMESTAMPTZ) 用途: 表示一个包含时区信息的日期和时间。 使用场景: 适合存储需要考虑时区变化的全球化应用…...

储能蓝海:技术革新与成本骤降引爆市场
在当今全球能源转型的大背景下,储能项目的前景无疑呈现出前所未有的乐观态势。其快速增长的装机规模、持续的技术创新与成本降低、政策的强力支持以及市场的迫切需求,共同绘制了一幅充满机遇与挑战的壮丽画卷。 快速增长的装机规模:储能市场的…...

java抽象类和接口
前言: 在 Java 编程中,抽象类和接口是面向对象编程(OOP)中的重要概念。它们都是用来定义抽象类型的机制,来帮助程序员构建更加灵活、可维护和可扩展的软件系统。 但是随着软件系统规模的不断扩大和复杂度的增加&…...

法治在沃刷积分-刷文章浏览数
最近有一个任务,需要通过浏览文章来获取积分,一个个手点文章太麻烦,专业的事情还得专业的来。 法1:模拟发包 抓包发现,是通过接口来使积分增长,那直接模拟发包即可。 至于info_id的获取,可以通…...

【深度学习实验七】 自动梯度计算
目录 一、利用预定义算子重新实现前馈神经网络 (1)使用pytorch的预定义算子来重新实现二分类任务 (2)完善Runner类 (3) 模型训练 (4)性能评价 二、增加一个3个神经元的隐藏层,再次实现二分类,并与1做对比 三、自定义隐藏层层数和每个隐藏层中的神经元个数,尝…...

JAVA毕业设计192—基于Java+Springboot+vue的个人博客管理系统(源代码+数据库+万字论文+开题+任务书)
毕设所有选题: https://blog.csdn.net/2303_76227485/article/details/131104075 基于JavaSpringbootvue的个人博客管理系统(源代码数据库万字论文开题任务书)192 一、系统介绍 本项目前后端分离,分为用户、管理员两种角色,角色菜单可自行…...

must be ‘pom‘ but is ‘jar‘解决思路
这个错误信息表明在 Maven 的 pom.xml 文件中,定义的父 POM 的 packaging 类型设置不正确。具体来说,它应该是 pom 类型,但当前设置为 jar。这个问题通常会导致构建失败。以下是解决这个问题的步骤。 解决步骤 检查父 POM 的 packaging 类型…...

STM32启动文件浅析
目录 STM32启动文件简介启动文件中的一些指令 启动文件代码详解栈空间的开辟堆空间的开辟中断向量表定义(简称:向量表)复位程序对于weak的理解对于_main函数的分析 中断服务程序用户堆栈初始化 系统启动流程 STM32启动文件简介 STM32启动文件…...

h5页面与小程序页面互相跳转
小程序跳转h5页面 一个home页 /pages/home/home 一个含有点击事件的元素:<button type"primary" bind:tap"toWebView">点击跳转h5页面</button>toWebView(){ wx.navigateTo({ url: /pages/webview/webview }) } 一个webView页 /pa…...
:React 合成事件系统)
探索 JavaScript 事件机制(四):React 合成事件系统
前言 在前端开发中,事件处理是不可或缺的一部分。在众多的前端框架中,React 凭借其高效和灵活性受到众多开发者的喜爱。React 的事件处理系统,即“合成事件系统”,是其性能优化的一大亮点。 本文将带你深入浅出地探索 React 的合…...

openlayers 封装加载本地geojson数据 - vue3
Geojson数据是矢量数据,主要是点、线、面数据集合 Geojson数据获取:DataV.GeoAtlas地理小工具系列 实现代码如下: import {ref,toRaw} from vue; import { Vector as VectorLayer } from ol/layer.js; import { Vector as VectorSource } fr…...

手机号码携号转网查询接口-在线手机号码携号转网查询-手机号码携号转网查询API
接口简介:通过手机号精准查询该号码转网前及转网后所归属运营商 可查询号码是否为虚拟手机号 可查询到号码归属地信息 高准确率,实时查询运营商数据库 多用于营销场景,如运营商业务办理、客户信息查询、携号转网、电话营销等 接口地址&#x…...

yolo目标检测和姿态识别和目标追踪
要检测摄像头画面中有多少人,人一排排坐着,像教室那样。由于摄像头高度和角度的原因,有的人会被遮挡。 yolo v5 首先需要下载yolo v5官方代码,可以克隆或下载主分支的代码,或者下载release中发布的。 简单说一下环境…...

Docker搭建开源Web云桌面操作系统Puter和DaedalOS
文章目录 Puter 操作系统说明基于 Docker 启动 Puter 操作系统拉取镜像运行容器基于 Docker-Compose 启动 Puter操作系统创建目录编写docker-compose.yml运行在本地直接运行puter操作系统puter界面截图puter个人使用总结构建自己的Puter镜像daedalos基于web的操作系统说明技术特…...

FAQ-为什么交换机发给服务器的日志显示的时间少8小时
问题描述 配置交换机向日志服务器发送日志,在交换机上面查看日志显示的时间比日志服务器显示的时间快8个小时 解决方案 根据公司全球化整改的要求,syslog默认发送的是UTC时间。 当前设备上配置了时区UTC8,因此,设备上显示的本地…...

[表达式]真假计算
题目描述 有一棵树,不一定是二叉树。 所有叶子节点都是 True 或者 False。 对于从上往下奇数层的非叶子节点是 and,偶数层非叶子节点为 or。 树上每个节点的值是所有孩子节点的值进行该节点的运算操作。 判断一棵树能否砍掉,最快的方法就是从…...

从零构建开源任务管理中枢:TaskWing部署、插件化与自动化实战
1. 项目概述:从零到一,打造你的个人任务管理中枢如果你和我一样,每天被各种待办事项、项目进度、临时想法和会议记录搞得焦头烂额,那么你肯定不止一次地想过:有没有一个工具,能真正“懂”我,能把…...

Cloudflare + PlanetScale:在边缘运行全栈应用,数据库也不例外
全栈开发者面对的一道老难题 Cloudflare Workers 解决了计算层的全球分发问题——你的代码跑在 Cloudflare 遍布全球的 300 多个数据中心里,离用户近,启动快,不需要管理任何服务器。 但数据不一样。 数据库天然是"有状态的"&#x…...

AI代理工具化新范式:基于MCP协议的模块化连接器实践
1. 项目概述:一个面向AI代理的模块化连接器最近在折腾AI应用开发,特别是围绕AI Agent(智能体)的生态构建时,发现一个挺普遍的问题:如何让这些Agent高效、安全地连接和使用外部工具与服务?无论是…...
)
别再写面条代码了!用C语言状态机重构你的单片机项目(附51单片机HSM可移植框架)
从面条代码到优雅架构:用HSM状态机重构嵌入式系统的实战指南 当你面对一个智能家居设备的嵌入式项目,代码里充斥着数百行的if-else嵌套和switch-case分支,每次添加新功能都像是在一碗已经坨掉的面条上再浇一勺酱料——这样的开发体验…...

写论文软件哪个好?2026 实测:真文献 + 实证图表 + 全流程,虎贲等考 AI 才是毕业论文通关王
每到毕业季,“写论文软件哪个好” 就成为本硕生最纠结的问题。市面上工具看似繁多,却大多藏着隐患:通用 AI 编造文献、无实证支撑;小众工具功能碎片化、格式混乱;传统软件效率低、无智能辅助…… 选错软件,…...

QMC-Decoder深度解析:解锁QQ音乐加密音频的高效实战指南
QMC-Decoder深度解析:解锁QQ音乐加密音频的高效实战指南 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 在数字音乐版权保护日益严格的今天,你是否曾…...
)
集合进阶(Collection)
一、集合概述和分类1.1 集合的分类如下图所示:一类是单列集合元素是一个一个的,另一类是双列集合元素是一对一对的。 主要学习Collection单列集合。Collection是单列集合的根接口,也称之为顶层接口,Collection接口下面又有两个子接…...

HsMod终极指南:55项功能全面优化炉石传说游戏体验的完整方案
HsMod终极指南:55项功能全面优化炉石传说游戏体验的完整方案 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx框架开发的炉石传说模改插件,为…...

从Kaggle竞赛到实战:基于XGBoost的Otto多分类产品识别系统构建
1. 从Kaggle竞赛到真实业务场景的跨越 第一次接触Otto数据集是在2015年的Kaggle竞赛上,当时只觉得这是个典型的多分类问题。直到去年为某跨境电商平台搭建商品自动分类系统时,我才真正理解这个案例的实战价值——90%的参赛者只关注模型精度,而…...

CANN/ge 图引擎资源释放
aclgrphBuildFinalize 【免费下载链接】ge GE(Graph Engine)是面向昇腾的图编译器和执行器,提供了计算图优化、多流并行、内存复用和模型下沉等技术手段,加速模型执行效率,减少模型内存占用。 GE 提供对 PyTorch、Tens…...