Python——脚本实现datax全量同步mysql到hive
文章目录
- 前言
- 一、展示脚本
- 二、使用准备
- 1、安装python环境
- 2、安装EPEL
- 3、安装脚本执行需要的第三方模块
- 三、脚本使用方法
- 1、配置脚本
- 2、创建.py文件
- 3、执行脚本
- 4、测试生成json文件是否可用
前言
在我们构建离线数仓时或者迁移数据时,通常选用sqoop和datax等工具进行操作,sqoop和datax各有优点,datax优点也很明显,基于内存,所以速度上很快,那么在进行全量同步时编写json文件是一项很繁琐的事,是否可以编写脚本来把繁琐事来简单化,接下来我将分享这样一个mysql全量同步到hive自动生成json文件的python脚本。
一、展示脚本
# coding=utf-8
import json
import getopt
import os
import sys
import pymysql# MySQL 相关配置,需根据实际情况作出修改
mysql_host = "XXXXXX"
mysql_port = "XXXX"
mysql_user = "XXX"
mysql_passwd = "XXXXXX"# HDFS NameNode 相关配置,需根据实际情况作出修改
hdfs_nn_host = "XXXXXX"
hdfs_nn_port = "XXXX"# 生成配置文件的目标路径,可根据实际情况作出修改
output_path = "/XXX/XXX/XXX"def get_connection():return pymysql.connect(host=mysql_host, port=int(mysql_port), user=mysql_user, password=mysql_passwd)def get_mysql_meta(database, table):connection = get_connection()cursor = connection.cursor()sql = "SELECT COLUMN_NAME,DATA_TYPE from information_schema.COLUMNS WHERE TABLE_SCHEMA=%s AND TABLE_NAME=%s ORDER BY ORDINAL_POSITION"cursor.execute(sql, [database, table])fetchall = cursor.fetchall()cursor.close()connection.close()return fetchalldef get_mysql_columns(database, table):return list(map(lambda x: x[0], get_mysql_meta(database, table)))def get_hive_columns(database, table):def type_mapping(mysql_type):mappings = {"bigint": "bigint","int": "bigint","smallint": "bigint","tinyint": "bigint","decimal": "string","double": "double","float": "float","binary": "string","char": "string","varchar": "string","datetime": "string","time": "string","timestamp": "string","date": "string","text": "string"}return mappings[mysql_type]meta = get_mysql_meta(database, table)return list(map(lambda x: {"name": x[0], "type": type_mapping(x[1].lower())}, meta))def generate_json(source_database, source_table):job = {"job": {"setting": {"speed": {"channel": 3},"errorLimit": {"record": 0,"percentage": 0.02}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": mysql_user,"password": mysql_passwd,"column": get_mysql_columns(source_database, source_table),"splitPk": "","connection": [{"table": [source_table],"jdbcUrl": ["jdbc:mysql://" + mysql_host + ":" + mysql_port + "/" + source_database]}]}},"writer": {"name": "hdfswriter","parameter": {"defaultFS": "hdfs://" + hdfs_nn_host + ":" + hdfs_nn_port,"fileType": "text","path": "${targetdir}","fileName": source_table,"column": get_hive_columns(source_database, source_table),"writeMode": "append","fieldDelimiter": "\t","compress": "gzip"}}}]}}if not os.path.exists(output_path):os.makedirs(output_path)with open(os.path.join(output_path, ".".join([source_database, source_table, "json"])), "w") as f:json.dump(job, f)def main(args):source_database = ""source_table = ""options, arguments = getopt.getopt(args, '-d:-t:', ['sourcedb=', 'sourcetbl='])for opt_name, opt_value in options:if opt_name in ('-d', '--sourcedb'):source_database = opt_valueif opt_name in ('-t', '--sourcetbl'):source_table = opt_valuegenerate_json(source_database, source_table)if __name__ == '__main__':main(sys.argv[1:])
二、使用准备
1、安装python环境
这里我安装的是python3环境
sudo yum install -y python3
2、安装EPEL
EPEL(Extra Packages for Enterprise Linux)是一个由 Fedora Special Interest Group 维护的软件仓库,提供了大量在官方 RHEL 或 CentOS 软件仓库中没有的软件包。当你在 CentOS 或 RHEL 系统上需要安装一些不在官方软件仓库中的软件时,通常会先安装epel - release
sudo yum install -y epel-release
3、安装脚本执行需要的第三方模块
pip3 install pymysql
pip3 install cryptography
这里可能由于斑纹问题cryptography安装不上去更新一下pip和setuptools
pip3 install --upgrade pip
pip3 install --upgrade setuptools
重新安装cryptography
pip3 install cryptography
三、脚本使用方法
1、配置脚本
首先根据自己服务器修改脚本相关配置
2、创建.py文件
vim /xxx/xxx/xxx/gen_import_config.py
3、执行脚本
python3 /脚本路径/gen_import_config.py -d 数据库名 -t 表名
4、测试生成json文件是否可用
datax.py -p"-Dtargetdir=/表在hdfs存放路径" /生成的json文件路径
执行时首先要确保targetdir目标地址在hdfs上存在,如果没有需要创建后再次执行
相关文章:

Python——脚本实现datax全量同步mysql到hive
文章目录 前言一、展示脚本二、使用准备1、安装python环境2、安装EPEL3、安装脚本执行需要的第三方模块 三、脚本使用方法1、配置脚本2、创建.py文件3、执行脚本4、测试生成json文件是否可用 前言 在我们构建离线数仓时或者迁移数据时,通常选用sqoop和datax等工具进…...

Python爬虫教程:从入门到精通
Python爬虫教程:从入门到精通 前言 在信息爆炸的时代,数据是最宝贵的资源之一。Python作为一种简洁而强大的编程语言,因其丰富的库和框架,成为了数据爬取的首选工具。本文将带您深入了解Python爬虫的基本概念、实用技巧以及应用…...

pytorh学习笔记——cifar10(四)用VGG训练
1、新建train.py,执行脚本训练模型: import os import timeimport torch import torch.nn as nn import torchvisionfrom vggNet import VGGbase, VGGNet from load_cifar import train_loader, test_loader import warnings import tensorboardX# 忽略…...

CRLF、UTF-8这些编辑器右下角的选项的意思
经常使用编辑器的小伙伴应该经常能看到右下角会有这么两个选项,下图是VScode中的示例,那么这两个到底是啥作用呢? 目录 字符编码ASCII 字符集GBK 字符集Unicode 字符集UTF-8 编码 换行 字符编码 此部分参考博文 在计算机中,所有…...

【C++干货篇】——类和对象的魅力(四)
【C干货篇】——类和对象的魅力(四) 1.取地址运算符的重载 1.1const 成员函数 将const修饰的成员函数称之为const成员函数,const修饰成员函数放到成员函数参数列表的后面。const实际修饰该成员函数隐含的this指针(this指向的对…...

基于java的诊所管理系统源码,SaaS门诊信息系统,二次开发的不二选择
门诊管理系统源码,诊所系统源码,saas服务模式 医疗信息化的新时代已经到来,诊所管理系统作为诊所管理和运营的核心工具,不仅提升了医疗服务的质量和效率,也为患者提供了更加便捷和舒适的就医体验,同时还推动…...

O2OA如何实现文件跨服务器的备份
O2OA可以外接存储服务器,但是一个存储服务器上怕磁盘损坏等问题导致文件丢失,所以需要实现文件跨服务器备份。 整体过程: 1、SSH免密登录配置 2、增加一个同步推送文件的.sh文件 3、编辑crontab 增加定时任务执行上一步的.sh文件 一、配…...
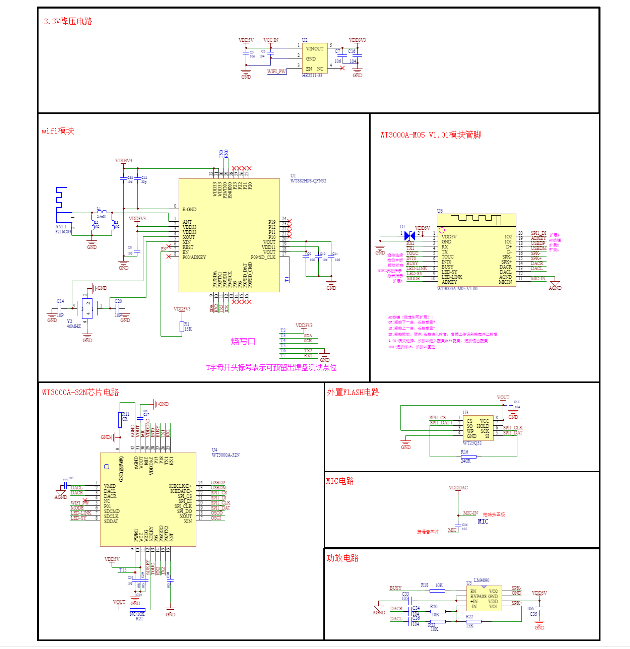
语音提示器-WT3000A离在线TTS方案-打破语种限制/AI对话多功能支持
前言: TTS(Text To Speech )技术作为智能语音领域的重要组成部分,能够将文本信息转化为逼真的语音输出,为各类硬件设备提供便捷的语音提示服务。本方案正是基于唯创知音的离在线TTS(离线本地音乐播放与在线…...

使用HAL库的STM32工程,实现DMA传输USART发送接收数据
以串口3为例,初始化部分为STM32CubeMX生成代码 串口初始化 UART_HandleTypeDef huart3; DMA_HandleTypeDef hdma_usart3_rx; DMA_HandleTypeDef hdma_usart3_tx;/* USART3 init function */ void MX_USART3_UART_Init(void) {/* USER CODE BEGIN USART3_Init 0 */…...

常用排序算法总结
内容目录 1. 选择类排序 1.1 直接选择排序1.2 堆排序 2. 交换类排序 2.1 冒泡排序2.2 快速排序 3. 插入类排序 3.1 直接插入排序3.2 希尔排序 4. 其它排序 4.1 归并排序4.2 基数排序/桶排序 排序 1. 选择类排序 选择类排序的特征是每次从待排序集合中选择出一个最大值或者最…...

[项目详解][boost搜索引擎#2] 建立index | 安装分词工具cppjieba | 实现倒排索引
目录 编写建立索引的模块 Index 1. 设计节点 2.基本结构 3.(难点) 构建索引 1. 构建正排索引(BuildForwardIndex) 2.❗构建倒排索引 3.1 cppjieba分词工具的安装和使用 3.2 引入cppjieba到项目中 倒排索引代码 本篇文章,我们将继续项…...

R语言编程
一、R语言在机器学习中的优势 R语言是一种广泛用于统计分析和数据可视化的编程语言,在机器学习领域也有诸多优势。 丰富的包:R拥有大量专门用于机器学习的包。例如,caret包是一个功能强大的机器学习工具包,它提供了统一的接口来训练和评估多种机器学习模型,如线性回归、决…...

Mysql主主互备配置
在现有运行的mysql环境下,修改相关配置项,完成主主互备模式的部署。 下面的配置说明中设置的mysql互备对应服务器IP为: 192.168.1.6 192.168.1.7 先检查UUID 在mysql的数据目录下,检查主备mysql的uuid(如下的server-…...
)
如何预防数据打架?数据仓库如何保持指标数据一致性开发指南(持续更新)
大数据开发人员最经常遇到尴尬和麻烦的事是,指标开发好了,以为万事大吉了。被业务和运营发现这个指标在不同地方数据打架,显示不同的数值。为了保证指标数据一致性,要从整个开发流程做好。 目录 一、数据仓库架构规划 二、数据抽取与转换 三、数据存储管理 四、指标管…...

我谈Canny算子
在Canny算子的论文中,提出了好的边缘检测算子应满足三点:①检测错误率低——尽可能多地查找出图像中的实际边缘,边缘的误检率(将边缘识别为非边缘)低,且避免噪声产生虚假边缘(将非边缘识别为边缘…...

算法的学习笔记—平衡二叉树(牛客JZ79)
😀前言 在数据结构中,二叉树是一种重要的树形结构。平衡二叉树是一种特殊的二叉树,其特性是任何节点的左右子树高度差的绝对值不超过1。本文将介绍如何判断一棵给定的二叉树是否为平衡二叉树,重点关注算法的时间复杂度和空间复杂度…...

SSM学习day01 JS基础语法
一、JS基础语法 跟java有点像,但是不用注明数据类型 使用var去声明变量 特点1:var关键字声明变量,是为全局变量,作用域很大。在一个代码块中定义的变量,在其他代码块里也能使用 特点2:可以重复定义&#…...

kubeadm快速自动化部署k8s集群
目录 一、准备环境 二、安装docker--三台机器都操作 三、使用kubeadm部署Kubernetes 在所有节点安装kubeadm和kubelet、kubectl 配置启动kubelet(所有主机) master节点初始化 Mater重新完成初始化 执行Master初始化后的提示配置 配置使用网络插件 创建flannel网络 …...

解决JAVA使用@JsonProperty序列化出现字段重复问题(大写开头的字段重复序列化)
文章目录 引言I 解决方案方案1:使用JsonAutoDetect注解方案2:手动编写get方法,JsonProperty注解加到方法上。方案3:首字母改成小写的II 知识扩展:对象默认是怎样被序列化?引言 需求: JSON序列化时,使用@JsonProperty注解,将字段名序列化为首字母大写,兼容前端和第三方…...

分布式理论基础
文章目录 1、理论基础2、CAP定理1_一致性2_可用性3_分区容错性4_总结 3、BASE理论1_Basically Available(基本可用)2_Soft State(软状态)3_Eventually Consistent(最终一致性)4_总结 1、理论基础 在计算机…...
⚡)
2026电赛电源题通关指南:从Buck-Boost到宿舍断电(附双闭环保命源码)⚡
版权声明: 本文首发于CSDN,未经授权禁止搬运,否则祝你的电解电容全部反接爆炸! 📢 前言: 在全国大学生电子设计竞赛的四大经典方向(控制、电源、仪器仪表、通信)中,**“电…...

日常常见轻微刮花,居家随手就能修
手机屏幕刮花是很多人都会遇到的烦恼,尤其是没有贴钢化膜的手机,日常放置在口袋、背包里,很容易被钥匙、硬币、纸巾碎屑等硬物划出细小划痕。这些划痕虽然不影响正常使用,但看着十分碍眼,不少人会想着换屏幕࿰…...

Python异步爬虫框架lightclaw:轻量级高性能Web数据采集实战
1. 项目概述:一个轻量级、高性能的Web爬虫框架最近在做一个需要大规模采集公开网页数据的项目,市面上成熟的爬虫框架很多,像Scrapy、Playwright这些,功能强大但有时候也显得“笨重”。尤其是在处理海量、高并发的简单页面抓取时&a…...

EDEM-Fluent-CFD风道耦合:多物理场协同仿真实战指南
1. 从零开始理解EDEM-Fluent-CFD风道耦合 第一次接触气固两相流仿真时,我被各种专业术语搞得晕头转向。直到在风机设计项目中踩了三次坑,才真正理解EDEM-Fluent-CFD耦合的价值。简单来说,这就像给风道系统做"数字CT"——用EDEM模拟…...

程序员的职业规划:到底是走技术路线还是管理路线
程序员职业规划:技术与管理的岔路口在软件测试行业深耕多年,你或许早已习惯在代码的迷宫中寻找漏洞,在数据的海洋里甄别异常。但当职业生涯的列车行至中途,一个现实的问题总会悄然浮现:是继续在技术的山峰上攀登&#…...

Photoshop AVIF插件:专业图像工作者的下一代格式解决方案
Photoshop AVIF插件:专业图像工作者的下一代格式解决方案 【免费下载链接】avif-format An AV1 Image (AVIF) file format plug-in for Adobe Photoshop 项目地址: https://gitcode.com/gh_mirrors/avi/avif-format 在当今数字图像处理领域,AVIF格…...

第26课:OpenClaw|日志审计与问题诊断
文章目录26.1 OpenClaw的日志体系与日志级别日志的“两个表面”日志级别的分层逻辑WebSocket日志的三级样式Cache-Trace日志:穿透Agent上下文的黑盒26.2 工作目录中的.jsonl日志文件分析三类关键日志文件读取日志的三种方式三类日志的关联追踪法26.3 结构化日志的收…...

SDN与OpenFlow架构解析及路由实现
1. SDN与OpenFlow架构解析在传统网络架构中,控制平面与数据平面紧密耦合,每个网络设备都需要独立维护路由表和转发决策。这种分布式架构虽然具有高可靠性,但也带来了管理复杂、配置繁琐、创新缓慢等问题。软件定义网络(SDN&#x…...

基于本地LLM与Whisper的沉浸式语音编程环境搭建指南
1. 项目概述:当语音输入遇上沉浸式编程 最近在GitHub上看到一个挺有意思的项目,叫 voice-typing-vibe-coding 。光看名字,你可能会觉得这又是一个语音转代码的工具,但实际体验下来,我发现它的核心远不止“打字”那么…...

32G显存消费级显卡也能搞定!LoRA+VLLM生产级部署,AI专属模型全流程实战教程
本文详细介绍了如何使用LoRA微调和vLLM推理部署,在32G消费级显卡上完成AI模型从训练到上线的全流程。内容涵盖完整代码、逐行解释以及生产级部署方案,包括数据预处理、模型加载、LoRA配置、训练参数设置、模型合并和vLLM部署等关键步骤。通过显存优化策略…...