构建负责任的人工智能:数据伦理与隐私保护

构建负责任的人工智能:数据伦理与隐私保护
目录
- 🌟 数据伦理的重要性
- 📊 公平性评估:实现无偏差的模型
- 🔒 数据去标识化:保护用户隐私的必要手段
- 🔍 透明性与问责:建立可信的数据处理流程
1. 🌟 数据伦理的重要性
在当今数字化快速发展的时代,数据伦理成为构建负责任人工智能的重要基石。随着机器学习和人工智能的广泛应用,如何在技术创新与用户隐私之间找到平衡显得尤为重要。数据伦理不仅仅是对数据的合法使用,更是对社会责任的承担。无论是企业、开发者还是研究者,都应当意识到自己的数据使用行为对个体和社会的潜在影响。
一个良好的数据伦理框架应当包括对数据采集、存储、处理和分享的全面考量。首先,企业在进行数据采集时,需确保所获取的数据是经过用户同意的,用户应当清楚其数据将如何被使用。其次,数据的存储和处理过程应保证数据的安全性,防止未授权的访问和数据泄露。最后,数据的分享应以透明和负责的方式进行,确保数据不会被滥用。
建立数据伦理不仅是法律的要求,更是赢得用户信任的基础。透明的数据使用政策和负责任的行为能够增强用户的信任感,使他们愿意共享数据,从而推动科技的进步与发展。总之,数据伦理是构建负责任人工智能的核心要素,值得各方共同关注与努力。
2. 📊 公平性评估:实现无偏差的模型
公平性评估是机器学习模型开发中的重要环节,它确保模型在做出决策时不会对某一群体产生偏见。随着AI技术的普及,如何让模型公平公正地对待不同群体,成为了一个亟待解决的问题。实现这一目标需要采用多种公平性指标来监测模型输出,以评估其对不同群体的影响。
公平性指标的选择
常用的公平性指标包括但不限于以下几种:
- 均等机会(Equal Opportunity):评估不同群体在预测正例时的真实阳性率。
- 均衡预测率(Equal Predictive Value):关注模型在不同群体中的预测准确率。
- 群体平等(Group Fairness):确保不同群体在模型决策中享有相似的结果分布。
代码示例
以下是一个简单的Python代码示例,使用Fairlearn库进行模型公平性评估:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from fairlearn.metrics import demographic_parity_difference# 生成示例数据
data = pd.DataFrame({'feature1': [1, 2, 3, 4, 5, 6, 7, 8],'feature2': [0, 1, 0, 1, 0, 1, 0, 1],'label': [0, 0, 1, 1, 0, 1, 1, 0]
})# 特征和标签划分
X = data[['feature1', 'feature2']]
y = data['label']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型
model = LogisticRegression()
model.fit(X_train, y_train)# 进行预测
y_pred = model.predict(X_test)# 计算公平性指标
dp_diff = demographic_parity_difference(y_true=y_test, y_pred=y_pred, sensitive_features=X_test['feature2'])
print(f"Demographic Parity Difference: {dp_diff}")
在上述代码中,使用Fairlearn库计算人口统计差异。这个简单示例展示了如何通过公平性指标来评估模型的偏见程度。开发者应不断优化模型,减少偏见,确保其在不同群体间公平对待。
3. 🔒 数据去标识化:保护用户隐私的必要手段
随着数据隐私保护法规的日益严格,数据去标识化成为了保护用户隐私的重要技术手段。去标识化指的是通过技术手段消除数据中的个人身份信息,从而降低数据被滥用的风险。这一过程不仅提高了用户对数据使用的信任度,同时也满足了法律法规的要求。
去标识化的技术方法
去标识化的方法主要包括以下几种:
- 数据掩码(Data Masking):通过隐藏或替换敏感信息,使数据无法被直接识别。
- 数据聚合(Data Aggregation):将数据汇总至一定的层级,以避免对单个用户的直接识别。
- 差分隐私(Differential Privacy):在数据中添加噪声,从而保护个体数据隐私的同时,保留整体数据的有效性。
代码示例
以下是一个使用Python进行数据去标识化的示例:
import pandas as pd
import numpy as np# 生成示例数据
data = pd.DataFrame({'user_id': [1, 2, 3, 4, 5],'age': [25, 30, 35, 40, 45],'salary': [50000, 60000, 70000, 80000, 90000]
})# 数据去标识化
data['user_id'] = data['user_id'].apply(lambda x: f'user_{x}') # 替换用户ID
data['age'] = data['age'].apply(lambda x: np.random.randint(20, 50)) # 随机化年龄
data['salary'] = data['salary'].apply(lambda x: x * np.random.uniform(0.8, 1.2)) # 添加噪声print(data)
在这个示例中,用户ID被替换为通用格式,年龄和薪水也被随机化,达到了去标识化的目的。去标识化的实施可以在保护用户隐私的同时,确保数据在分析和研究中的有效性。
4. 🔍 透明性与问责:建立可信的数据处理流程
透明性与问责制是建立负责任人工智能的另一重要方面。确保用户了解其数据如何被收集、处理和使用,不仅能够提高用户的信任度,还能促进企业和机构在数据使用中的自律。
透明性的重要性
透明性意味着在数据处理的每个环节,用户都能够清晰地了解到数据的用途、来源及其处理方式。企业应当公开其数据政策,并在数据采集和使用过程中保持开放的沟通。透明的数据处理流程有助于增强用户对企业的信任,从而促进数据的合法使用。
建立问责机制
问责机制确保在数据处理过程中,任何一方都需对其行为负责。企业应建立内部审核机制,定期检查数据使用的合规性和安全性。此外,用户应有权了解其数据使用情况,并在需要时能够撤回同意。
代码示例
以下是一个示例代码,展示如何记录数据处理日志,以确保透明性和问责制:
import logging# 设置日志配置
logging.basicConfig(filename='data_processing.log', level=logging.INFO, format='%(asctime)s - %(message)s')def log_data_processing(action):"""记录数据处理操作"""logging.info(f"Data processing action: {action}")# 记录数据采集操作
log_data_processing("Data collected from users.")# 记录数据处理操作
log_data_processing("Data anonymized and aggregated.")# 记录数据分享操作
log_data_processing("Data shared with research partners.")
在这个示例中,通过记录数据处理的每个步骤,确保了透明性和问责制。这样的日志记录不仅能够帮助企业追踪数据使用情况,还能为用户提供信心,确保数据在处理中的安全性和合规性。
相关文章:
构建负责任的人工智能:数据伦理与隐私保护
构建负责任的人工智能:数据伦理与隐私保护 目录 🌟 数据伦理的重要性📊 公平性评估:实现无偏差的模型🔒 数据去标识化:保护用户隐私的必要手段🔍 透明性与问责:建立可信的数据处理…...

微信小程序live-pusher和video同时使用,video播放声音时时大时小
一、遇到的问题 微信小程序live-pusher和video同时使用,video播放声音时有时无时大时小 二、排查流程 业务是模拟面试,每道题一个推流live-pusher和一个面试题video,一次面试有多道面试题,页面就一个live-pusher和一个video,切换面试题时给live-pusher和video重新赋值u…...

MySQL 分库分表实战
在当今互联网时代,数据量的增长呈爆炸式趋势,传统的单库单表架构已经难以满足大规模数据存储和高并发访问的需求。MySQL 分库分表技术应运而生,它可以有效地提高数据库的性能、扩展性和可用性。本文将详细介绍 MySQL 分库分表的实战经验。 一…...

MySQL—CRUD—进阶—(二) (ಥ_ಥ)
文本目录: ❄️一、新增: ❄️二、查询: 1、聚合查询: 1)、聚合函数: 2)、GROUP BY子句: 3)、HAVING 子句: 2、联合查询: 1)、内连接…...

时序分解 | TTNRBO-VMD改进牛顿-拉夫逊算法优化变分模态分解
时序分解 | TTNRBO-VMD改进牛顿-拉夫逊算法优化变分模态分解 目录 时序分解 | TTNRBO-VMD改进牛顿-拉夫逊算法优化变分模态分解效果一览基本介绍程序设计参考资料 效果一览 基本介绍 (创新独家)TTNRBO-VMD改进牛顿-拉夫逊优化算优化变分模态分解TTNRBO–VMD 优化VMD分解层数K和…...

2024“源鲁杯“高校网络安全技能大赛-Misc-WP
Round 1 hide_png 题目给了一张图片,flag就在图片上,不过不太明显,写个python脚本处理一下 from PIL import Image # 打开图像并转换为RGB模式 img Image.open("./attachments.png").convert("RGB") # 获取图像…...

CSS行块标签的显示方式
块级元素 标签:h1-h6,p,div,ul,ol,li,dd,dt 特点: (1)如果块级元素不设置默认宽度,那么该元素的宽度等于其父元素的宽度。 (2)所有的块级元素独占一行显示. (3ÿ…...

Go 语言中的 for range 循环教程
在 Go 语言中,for range 循环是一个方便的语法结构,用于遍历数组、切片、映射和字符串。本教程将通过示例代码来帮助理解如何在 Go 中使用 for range 循环。 package mainimport "fmt"func main() {// 遍历切片并计算和nums : []int{2, 3, 4}…...

青训营 X 豆包MarsCode 技术训练营--小M的比赛胜场计算
问题描述 小M参加了一场n个人的比赛,比赛规则是所有选手两两对决。每个人有一个能力值,对应着他们的序号。参赛者同时被分为黄色或蓝色两种颜色。比赛胜负的规则如下: 当比赛双方颜色不同时,能力值大的选手获胜; 当比…...

海王3纯源码
海王3是一款热门的捕鱼类游戏,其纯源码为开发者提供了一个完整的游戏开发基础。该源码包括客户端和服务端的完整架构,支持多人在线竞技模式和丰富的游戏玩法。服务端采用C语言编写,并使用MySQL数据库来存储玩家数据,确保数据处理的…...

【ShuQiHere】Linux 系统中的硬盘管理详解:命令与技巧
【ShuQiHere】 💽 在 Linux 系统中,硬盘管理不仅仅是存储数据的操作,更涉及系统性能、数据安全和稳定性的优化。无论你是系统管理员、开发者还是 Linux 爱好者,掌握硬盘管理的基础操作都非常有用。本文将从硬盘健康检查、分区管理…...

数据结构之堆和二叉树的简介
1.树 1.1 树的概念与结构 如图所示,树是⼀种非线性的数据结构,它是由 n (n>0) 个有限结点组成⼀个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。 …...

微信小程序上传图片添加水印
微信小程序使用wx.chooseMedia拍摄或从手机相册中选择图片并添加水印, 代码如下: // WXML代码:<canvas canvas-id"watermarkCanvas" style"width: {{canvasWidth}}px; height: {{canvasHeight}}px;"></canvas&…...

xshell5找不到匹配的host key算法
xshell5找不到匹配的host key算法,是因为电脑客户端不支持服务器的算法,因此需要再服务器增加算法。 下面以Ubuntu系统为例,修改下面的文件 sudo vim /etc/ssh/sshd_config 增加下面算法 KexAlgorithms diffie-hellman-group-exchange-…...

Linux中安装Tomcat
文章目录 一、Tomcat介绍1.1、Tomcat是什么1.2、Tomcat的工作原理1.3、Tomcat适用的场景1.4、Tomcat与Nginx、Apache比较1.4.1、优势1.4.2、劣势1.4.3、定位功能 1.5、Tomcat 的主要组件1.6、Tomcat 的主要配置文件 二、Tomcat安装2.1、查看可用的JDK2.2、安装OpenJDK 112.3、配…...

RV1126音视频学习(二)-----VI模块
文章目录 前言2.RV1126的视频输入vi模块2.1什么是VI模块2.3RV1126VI模块主要APIRK_MPI_SYS_Init()RK_MPI_VI_SetChnAttrRK_MPI_VI_EnableChnRK_S32 RK_MPI_VI_DisableChnRK_MPI_VI_StartStreamRK_MPI_SYS_GetMediaBufferRK_MPI_MB_GetPtrRK_MPI_MB_GetSizeRK_MPI_MB_ReleaseBuf…...

「C/C++」C++17 之 std::string_view 轻量级字符串视图
✨博客主页何曾参静谧的博客📌文章专栏「C/C」C/C程序设计📚全部专栏「VS」Visual Studio「C/C」C/C程序设计「UG/NX」BlockUI集合「Win」Windows程序设计「DSA」数据结构与算法「UG/NX」NX二次开发「QT」QT5程序设计「File」数据文件格式「PK」Parasoli…...
Linux内核-内核模块内核参数
作者介绍:简历上没有一个精通的运维工程师。希望大家多多关注作者,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。 我们的Linux进阶部分,到目前为止,已经讲过:硬件,日常运维,基础软…...
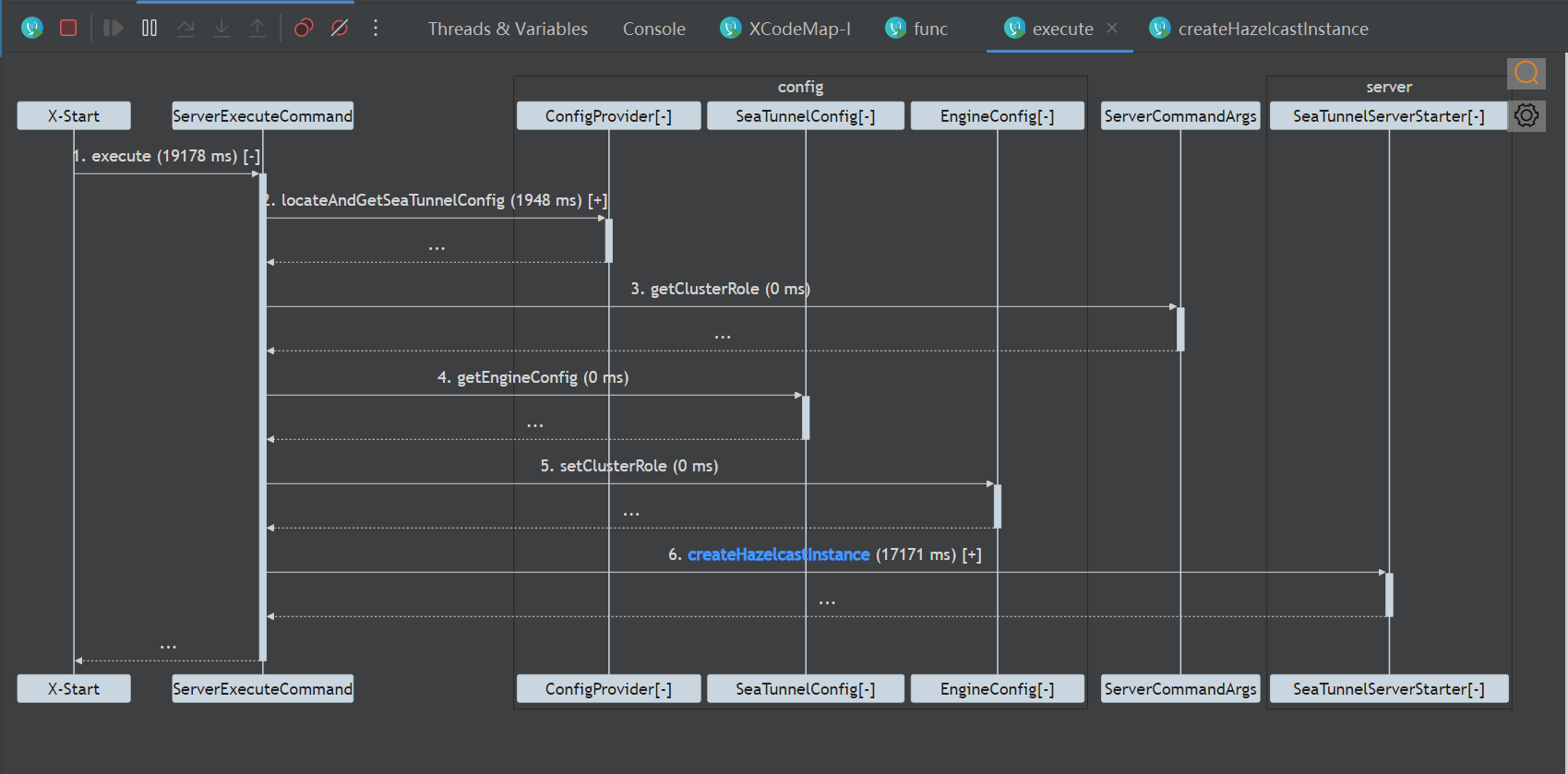
中电信翼康工程师:我在 Apache SeaTunnel 社区的贡献之旅
贡献者Github ID:luckyLJY 文章整理:曾辉 Apache SeaTunnel 作为一款强大的数据同步和转换工具,凭借其部署易用性、容错机制、数据源支持、性能优势、功能丰富性以及活跃的社区支持,成为了数据工程师们不可或缺的利器。 因其具有的…...

【ESP32S3】VSCode 开发环境搭建
ESP32S3 有多种开发方式,主流的有 Eclipse 和 VSCode 两种。本文来介绍一下基于 VSCode 的开发环境搭建。 VSCode 环境需要依赖于 ESP-IDF 插件,因此需要在 VSCode 插件市场中搜索并安装 ESP-IDF 插件: 安装完成后侧边栏会多出一个 ESP-IDF …...

Python自动化Excel数据抓取:OpenClaw技能实战指南
1. 项目概述:从Excel表格到智能数据抓取如果你每天的工作都离不开Excel,并且经常需要从各种网页、文档甚至PDF里手动复制粘贴数据,然后费劲地整理到表格里,那你一定对“Excel大师”这个称号既向往又头疼。我们总希望Excel能更“聪…...

视觉显著目标的自适应分割与动态网格生成算法研究
ArticleObjectiveMethodComments视觉显著目标的自适应分割背景是基于视觉注意模型和最大熵分割算法,针对复杂背景下的显著目标分割问题。目的是提出一种自适应显著目标分割方法,以便快速准确地从场景图像中检测出显著目标。试验用的方法是通过颜色、强度…...

嵌入式开发革命:LuatOS云编译实战指南与效率提升
1. 项目概述:为什么我们需要云编译?作为一名在嵌入式领域摸爬滚打了十多年的老鸟,我太懂那种“买板一时爽,环境火葬场”的痛了。尤其是这几年,合宙、乐鑫、兆易这些厂商的产品线越来越丰富,Air780E、ESP32-…...

PaperDebugger:用代码调试思维提升学术论文可复现性的工具实践
1. 项目概述:一个为学术论文“排雷”的智能调试器如果你和我一样,常年混迹在学术圈或者技术研发一线,肯定对下面这个场景深恶痛绝:好不容易读完一篇几十页的论文,满心欢喜地准备复现其中的算法或实验,结果发…...

Topit:macOS窗口置顶的终极解决方案,开源高效的多任务开发利器
Topit:macOS窗口置顶的终极解决方案,开源高效的多任务开发利器 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit Topit是一款专为macOS系统…...

基于树莓派与电子墨水屏的慢速电影播放器制作全攻略
1. 项目概述:当电影遇见电子墨水如果你和我一样,对电子墨水(eInk)屏幕那种独特的、像印刷品一样的显示效果着迷,同时又是个喜欢折腾树莓派(Raspberry Pi)的玩家,那么这个项目绝对能让…...

Smart-10 多模光时域反射仪:铁路高速光纤故障首选
铁路、高速公路通信光纤线路长、环境复杂,精准检测与故障定位是运维关键。Smart-10 多模光时域反射仪集成 OTDR、光功率计、红光源等功能,为交通行业光纤运维提供高效、可靠的解决方案。Smart-10 多模光时域反射仪是一款一体化光纤综合测试仪,…...

信捷PLC XD/XL系列C语言功能块实战:从指针定义到数据调用,我的高效编程习惯分享
信捷PLC XD/XL系列C语言功能块实战:从指针定义到数据调用,我的高效编程习惯分享 在工业自动化领域,PLC编程的效率直接影响到设备调试周期和产线维护成本。作为一名长期使用信捷PLC XD/XL系列的工程师,我发现其C语言功能块的灵活运…...

如何快速掌握BepInEx:从游戏玩家到插件开发者的完整指南
如何快速掌握BepInEx:从游戏玩家到插件开发者的完整指南 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx是一款强大的Unity游戏插件框架,为游戏模组…...
可穿戴智能服饰制作:NeoPixel灯带与Circuit Playground的集成实践
1. 项目概述:当可穿戴电子遇上创意服饰如果你和我一样,既着迷于微控制器上跑起的第一行代码,又无法抗拒布料、针线和那些闪闪发光的小玩意儿,那么这个项目就是为你准备的。将NeoPixel灯带和Circuit Playground微控制器“缝”进一件…...