气候服务平台ClimateSERV2.0简介(python)
1 简介
ClimateSERV 2.0允许开发从业者、科学家/研究人员和政府决策者可视化和下载历史降雨数据、植被状况数据以及 180 天的降雨和温度预报,以增进对农业和水资源供应相关问题的理解并做出改进的决策。
这些数据可以通过 Web 应用程序直接访问,也可以使用 Python 应用程序中的 ClimateSERVpy 通过应用程序 API 进行访问。
可以通过以下方式安装 ClimateSERVpy包:
pip install climateserv
conda install -c servir climateserv
环境要求:
- Python 3.9.5 或更高版本 (建议使用 3.9.5)
- PostgreSQL (版本 13)
- THREDDS (版本 4.6.14)
- Linux 服务器
具体安装需要使用两个环境:一个用于数据库,另一个用于应用程序。
2 在conda 环境中设置数据库
- 创建环境
mkdir -p /cserv2/python_environments/conda/anaconda3/envs/
conda create --prefix=/cserv2/python_environments/conda/anaconda3/envs/psqlenv python=3.9.5
conda create --name psqlenv python=3.9.5
- 进入环境
conda activate psqlenv
- 通过 Conda 安装 PostgreSQL
conda install -y -c conda-forge postgresql
- 创建基本数据库
cd /cserv2
mkdir db
cd dbinitdb -D local_climateserv
- 启动 Postgres 的服务器模式/实例
pg_ctl -D local_climateserv -l logfile start
- 创建非超级用户(更安全)
createuser --encrypted --pwprompt csadmin
- 使用此用户,在 Base Database 中创建内部数据库
createdb --owner=csadmin cs2_db
conda deactivate
- 创建数据库连接文件
将以下内容粘贴到下面的文件:
/cserv2/django_app/ClimateSERV2/climateserv2/data.json
{"NAME": "cs2_db","USER": "csadmin","PASSWORD": "PASSWORD_YOU_SET_FOR_THIS_USER","HOST": "127.0.0.1","SECRET_KEY": "Your_super_secret_key_for_django""DEBUG": "False"
}
对于 SECRET_KEY 必须是一个较大的随机值,并且必须保密。
对于 DEBUG,在 development 中,将其设置为 “True”,对于生产环境,将其设置为 “False”。
3 在conda 环境中设置应用程序
安装 conda 后,运行以下命令来创建 python 环境并激活:
conda create --prefix=/cserv2/python_environments/conda/anaconda3/envs/climateserv2 python=3.9.5
conda activate ClimateSERV2
cd 到项目目录,然后运行以下两个安装命令:
pip install -r requirements.txt
conda install --file conda_requirements.txt
完成后,再添加一个全局 lib 来代理消息队列:
sudo apt-get install rabbitmq-server
sudo systemctl enable rabbitmq-server
sudo service rabbitmq-server start
现在可以创建一个服务和配置文件来启动 celery,这是任务队列,专注于实时处理。
需要创建两个文件,一个位于 /etc/systemd/system/celery.service,另一个位于 /etc/conf.d/celery
在 celery.service 中,需要以下内容(可能需要调整路径):
[Unit]
Description=Celery Service
After=rabbitmq-server.service network.target
Requires=rabbitmq-server.service
RuntimeDirectory=celery [Service]
Type=forking
User=www-data
Group=www-data
EnvironmentFile=/etc/conf.d/celery
WorkingDirectory=/cserv2/django_app/ClimateSERV2
ExecStart=/bin/bash -c '${CELERY_BIN} -A $CELERY_APP multi start $CELERYD_NODES \--pidfile=${CELERYD_PID_FILE} --logfile=${CELERYD_LOG_FILE} \--loglevel="${CELERYD_LOG_LEVEL}" $CELERYD_OPTS'
ExecStop=/bin/sh -c '${CELERY_BIN} multi stopwait $CELERYD_NODES \--pidfile=${CELERYD_PID_FILE} --logfile=${CELERYD_LOG_FILE} \--loglevel="${CELERYD_LOG_LEVEL}"'
ExecReload=/bin/sh -c '${CELERY_BIN} -A $CELERY_APP multi restart $CELERYD_NODES \--pidfile=${CELERYD_PID_FILE} --logfile=${CELERYD_LOG_FILE} \--loglevel="${CELERYD_LOG_LEVEL}" $CELERYD_OPTS'
Restart=always[Install]
WantedBy=multi-user.target
在 /etc/conf.d/celery 中,可以粘贴:
CELERYD_NODES="w1 w2 w3"
DJANGO_SETTINGS_MODULE="climateserv2.settings"# Absolute or relative path to the 'celery' command:
CELERY_BIN="/cserv2/python_environments/conda/anaconda3/envs/climateserv2/bin/celery"# App instance to use
CELERY_APP="climateserv2"
CELERYD_MULTI="multi"# Extra command-line arguments to the worker
CELERYD_OPTS="--time-limit=300 --concurrency=8"
CELERYD_PID_FILE="/var/run/celery/%n.pid"
CELERYD_LOG_FILE="/var/log/celery/%n%I.log"
Celery 使用一个临时目录,该目录需要在重启时自动创建。创建 /usr/lib/tmpfiles.d 并将以下内容粘贴到其中:
D /var/run/celery 0777 root root - -
手动创建此目录,以及其他几个目录:
sudo mkdir /var/run/celery
sudo chmod 777 /var/run/celery -Rsudo mkdir /opt/celery
sudo chmod 777 /opt/celerysudo mkdir /var/log/celery
sudo chmod 777 /var/log/celery -R
可以启用并启动 celery:
sudo chmod 644 /etc/systemd/system/celery.service
sudo systemctl daemon-reload
sudo systemctl enable celery
sudo service celery restart
开始应用程序设置:
python manage.py migrate
这将负责设置数据库。
运行前,需要创建一个超级用户:
python manage.py createsuperuser
启动应用程序:
python manage.py runserver
4 其他
web端还提供不同参数的统计计算以及不同数据的图层可视化:


参考:https://github.com/SERVIR/ClimateSERV2
相关文章:
气候服务平台ClimateSERV2.0简介(python)
1 简介 ClimateSERV 2.0允许开发从业者、科学家/研究人员和政府决策者可视化和下载历史降雨数据、植被状况数据以及 180 天的降雨和温度预报,以增进对农业和水资源供应相关问题的理解并做出改进的决策。 这些数据可以通过 Web 应用程序直接访问,也可以…...

Docker | centos7上对docker进行安装和配置
安装docker docker配置条件安装地址安装步骤2. 卸载旧版本3. yum 安装gcc相关4. 安装需要的软件包5. 设置stable镜像仓库6. 更新yum软件包索引7. 安装docker引擎8. 启动测试9. 测试补充:设置国内docker仓库镜像 10. 卸载 centos7安装docker https://docs.docker.com…...

React--》掌握Valtio让状态管理变得轻松优雅
Valtio采用了代理模式,使状态管理变得更加直观和易于使用,同时能够与React等框架无缝集成,本文将深入探讨Valtio的核心概念、使用场景以及其在提升应用性能中的重要作用,帮助你掌握这一强大工具,从而提升开发效率和用户…...

python爬虫百度图片
直接给代码,可直接用,个人需要修改的地方有两处: self.directory 这是本地存储地址,修改为自己电脑的地址,另外,**{}**不要删spider.json_count 10 这是下载的图像组数,一组有30张图像&#x…...
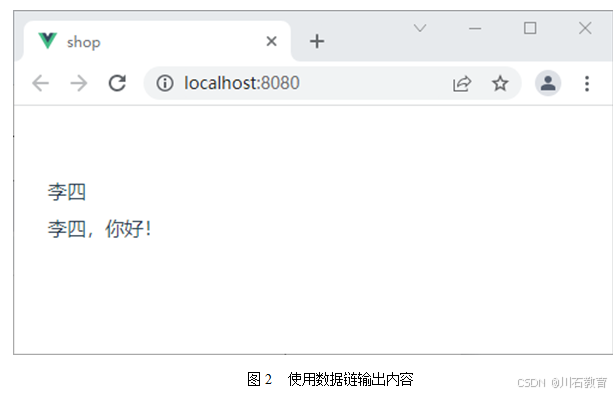
前端开发:Vue中数据绑定原理
Vue 中最大的一个特征就是数据的双向绑定,而这种双向绑定的形式,一方面表现在元数据与衍生数据之间的响应,另一方面表现在元数据与视图之间的响应,而这些响应的实现方式,依赖的是数据链,因此,要…...

CTF-RE 从0到N: TEA
TEA TEA(Tiny Encryption Algorithm,轻量加密算法) 是一种简单、快速的对称加密算法。它是一个分组加密算法,通常用于加密 64 位的数据块,并使用 128 位的密钥。TEA 是一种“费斯妥结构”(Feistel structu…...

python 使用PIL获取图片长宽
在Python中,你可以使用Pillow库(PIL的一个分支和替代品)来获取图片的长和宽。Pillow提供了丰富的图像处理功能,包括获取图像的基本属性,如尺寸。 以下是一个简单的示例,展示了如何使用Pillow库来获取图片的…...
【Nas】X-DOC:搞机之PVE部署All In One(黑群晖NAS 软路由OpenWrt Docker Win10远程桌面)
【Nas】X-DOC:搞机之PVE部署All In One(黑群晖NAS & 软路由OpenWrt & Docker & Win10远程桌面) 1、原硬件配置清单:2、改AIO后增加配置清单:3、虚拟化平台PVE:4、搭建的关键服务: 1…...

linux 驱动源码分析的理解。
首先 , 是linux 驱动,我看网上的老师,在分析源码时 , 不会 所有的函数都分析,而是分析一些比较重要的函数,一些厉害的人,在分析源码时…...

鸿蒙-任务栏右击退出 或 UIAbility窗口关闭,怎么弹框拦截
onPrepareToTerminate 需要配置权限 ohos.permission.PREPARE_APP_TERMINATE 参考链接:文档中心import { emitter } from kit.BasicServicesKit; import { common } from kit.AbilityKit; import { TipsDialog } from kit.ArkUI;// entryAbility.ets 在你的uiabilit…...

【C++进阶篇】——STL的简介
【C进阶篇】——STL的简介 1.什么是STL STL(standard template libaray-标准模板库):是C标准库的重要组成部分,不仅是一个可复用的组件库,而且是一个包罗数据结构与算法的软件框架。 2.STL的版本 原始版本 Alexander Stepanov、Meng Lee 在…...

信息安全工程师(70)网络攻击陷阱技术与应用
前言 网络攻击陷阱技术是一种主动的防御方法,作为网络安全的重要策略和技术手段,有利于网络安全管理者获得信息优势。 一、网络攻击陷阱技术原理 网络攻击陷阱技术可以消耗攻击者所拥有的资源,加重攻击者的工作量,迷惑攻击者&…...
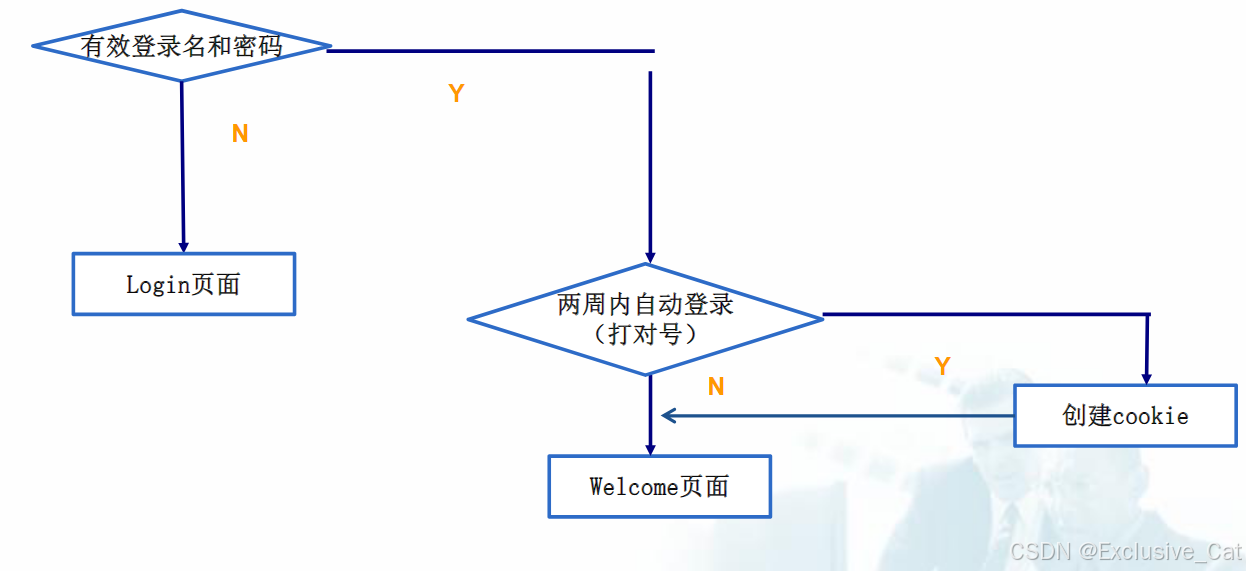
Web保存状态的手段(Session的使用)
一,JSP中的page指令 1. <% page language“java” session“true”%> session:此页面是否使用session,默认值为true 二,使用Session完善之前的登录程序 1. 如何禁止直接输入URL地址进入登录功能的欢迎界面? …...

第五十四章 安全元素的详细信息 - DerivedKeyToken 详情
文章目录 第五十四章 安全元素的详细信息 - <DerivedKeyToken> 详情详情消息中的位置 第五十四章 安全元素的详细信息 - 详情 <DerivedKeyToken> 的目的是携带发送者和接收者可以独立使用的信息来生成相同的对称密钥。这些方可以使用该对称密钥对 SOAP 消息的相关…...

kafka 的高可用机制是什么?
大家好,我是锋哥。今天分享关于【kafka 的高可用机制是什么?】面试题?希望对大家有帮助; kafka 的高可用机制是什么? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 Apache Kafka 是一个分布式消息系统&am…...

4.1.3 网站通信技术
文章目录 1. 网站通信方式2. URL - 统一资源定位符定义格式演示 3. 发送请求的4种形式在地址栏中输入URL访问超链接href属性指定URLform表单在action中指定URL通过AJAX请求后端数据 4. 两种不同返回的请求发送URL,后端处理完响应页面发送AJAX请求,后端处…...

Java-图书管理系统
我的个人主页 欢迎来到我的Java图书管理系统,接下来让我们一同探索如何书写图书管理系统吧! 1管理端和用户端 2建立相关的三个包(book、operation、user) 3建立程序入口Main类 4程序运行 1.首先图书馆管理系统分为管理员端和…...

python如何通过json以及pickle读写保存数据
记录信息 比如说我写了这样一段程序,记录了爱吃的食物: food_list []while True:c input("输入1添加新的食物,输入2查询已添加的食物,输入exit退出:")if c "1":new_food input("输入你…...

【SPIE出版,EI检索稳定】2024年人机交互与虚拟现实国际会议(HCIVR 2024,11月15-17日)
2024年人机交互与虚拟现实国际会议(HCIVR 2024) 2024 International Conference on Human-Computer Interaction and Virtual Reality 官方信息 会议官网:www.hcivr.org 2024 International Conference on Human-Computer Interaction and …...

Linux vim编辑器
前言: 首先我们来了解一下什么是编辑器,通常我们在widow系统下例如C/C我们进行写代码时,我们通过vs2022等等编译器进行,这里的编译器是一种IDE(集成开发环境),集成开发环境是将代码编辑器、编译…...
GitGitHub实操图文详解教程(01)—Git的起源)
(最新版)GitGitHub实操图文详解教程(01)—Git的起源
版权声明 本文原创作者:谷哥的小弟作者博客地址:http://blog.csdn.net/lfdfhl 在现代软件开发过程中,版本控制工具已经成为代码管理与团队协作的重要基础设施。随着软件项目规模不断扩大以及多人协作需求日益复杂,开发团队不仅需…...

AI与人类共创:从替代焦虑到协作闭环
GPT-Image 2 与人类创造力的共生:从“替代焦虑”到“协作闭环”(2026 研究视角与可落地实践)当 GPT-Image 2 这样的多模态生成/理解模型进入创作流程后,“竞争还是协作”立刻变成一个绕不开的讨论。直觉上,大家会把它理…...

CircuitPython FancyLED库:专业级可寻址LED色彩动画开发指南
1. 项目概述:为什么需要FancyLED?在嵌入式开发,尤其是物联网和交互式装置项目中,可寻址LED(如NeoPixel、DotStar)已经成为构建动态视觉反馈的核心组件。无论是制作一个会呼吸的氛围灯,还是一个能…...

Playnite完整指南:高效统一你的跨平台游戏库管理体验
Playnite完整指南:高效统一你的跨平台游戏库管理体验 【免费下载链接】Playnite Video game library manager with support for wide range of 3rd party libraries and game emulation support, providing one unified interface for your games. 项目地址: http…...

从真空袋到回流焊:一份给硬件创业团队的元器件储存与使用避坑指南
从真空袋到回流焊:硬件创业团队的元器件储存与使用避坑指南 当你拆开一包全新的芯片,是否曾想过这些看似坚固的小方块其实对环境湿度极其敏感?对于资源有限的硬件创业团队来说,正确处理MSL(湿度敏感等级)元…...

终极英雄联盟换肤工具:R3nzSkin国服特供版完整使用教程
终极英雄联盟换肤工具:R3nzSkin国服特供版完整使用教程 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 想要在英雄联盟国服免费体验所有皮肤…...

Pinia Colada:革命性Vue数据获取层的完整入门指南
Pinia Colada:革命性Vue数据获取层的完整入门指南 【免费下载链接】pinia-colada 🍹 The smart data fetching layer for Vue 项目地址: https://gitcode.com/gh_mirrors/pi/pinia-colada Pinia Colada是Vue生态系统中一款革命性的数据获取层解决…...

借助 Taotoken 多模型聚合能力为开源项目构建智能问答机器人
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 借助 Taotoken 多模型聚合能力为开源项目构建智能问答机器人 为开源项目添加一个智能问答助手,能显著提升社区体验&…...

AI编程助手Composer插件:无缝管理PHP依赖,提升结对编程效率
1. 项目概述:一个为AI编程助手量身定制的Composer工具如果你和我一样,日常重度依赖像Aider这样的AI编程助手来提升开发效率,那你一定遇到过这样的场景:你正和AI助手热火朝天地讨论一个功能实现,它为你生成了一段完美的…...

杰理之主机插拔U盘,从机较高概率出现无声情况【篇】
switch节点初始丢数据时后续节点状态错误导致时间戳异常问题(对应rx无声)...