高级java每日一道面试题-2024年10月24日-JVM篇-说一下JVM有哪些垃圾回收器?
如果有遗漏,评论区告诉我进行补充
面试官: 说一下JVM有哪些垃圾回收器?
我回答:
1. Serial收集器
- 特点:Serial收集器是最古老、最稳定的收集器,它使用单个线程进行垃圾收集工作。在进行垃圾回收时,它会暂停所有用户线程,即Stop The World(STW)。
- 单线程工作,适合单核 CPU。
- 在年轻代(Young Generation)中使用,称为 Serial。
- 在老年代(Old Generation)中使用,称为 Serial Old。
- 收集速度快,但会暂停整个应用。
- 适合小型应用或测试环境。
- 应用场景:适用于单CPU环境或内存较小、对停顿时间要求不高的应用。
- 回收算法:
- 在新生代,它采用复制算法,将新生代划分为一个 Eden 区和两个 Survivor 区,默认比例是 8:1:1。在垃圾回收时,将 Eden 区和其中一个 Survivor 区中存活的对象复制到另一个 Survivor 区。
- 在老年代,它采用标记 - 整理算法,对存活对象进行标记后,将其移动到一端,清除另一端的垃圾。
2. ParNew收集器
- 特点:ParNew收集器是Serial收集器的多线程版本,也被称为“并行年轻代收集器”。它可以与CMS收集器配合使用,以实现更短的停顿时间。
- 多线程工作,适合多核 CPU。
- 在年轻代中使用,称为 ParNew 或者 Parallel。
- 专注于吞吐量优化。
- 使用复制算法(Copy)或标记-压缩算法(Mark-Compact)。
- 适合需要高吞吐量的应用。
- 应用场景:适用于多CPU环境,特别是需要缩短年轻代垃圾回收停顿时间的应用。
- 回收算法:
- 在新生代采用复制算法,其内存区域划分和 Serial 回收器相同,也是 Eden 区和两个 Survivor 区。
3. Parallel收集器(Parallel Scavenge)
- 特点:Parallel收集器是一种多线程并行的垃圾收集器,它关注点是吞吐量(运行用户代码时间与CPU总消耗时间的比值)。它同样适用于新生代和老年代的回收。
- 应用场景:适用于对吞吐量有较高要求的应用,如后台计算任务等。
- 回收算法:
- 在新生代采用复制算法,通过参数调整可以控制新生代的大小、Survivor 区比例等内存分配策略,以优化吞吐量。
4. CMS(Concurrent Mark-Sweep)收集器
- 特点:CMS收集器是一种以获取最短回收停顿时间为目标的收集器。它是第一款并发收集器,可以实现垃圾收集线程与用户线程同时工作。但需要注意的是,CMS收集器对CPU资源敏感,且无法处理浮动垃圾,还可能产生大量空间碎片。
- 并发标记和清扫,减少暂停时间。
- 专注于降低停顿时间。
- 使用标记-清除算法(Mark-Sweep)。
- 可能会产生碎片。
- 适合对响应时间敏感的应用。
- 应用场景:适用于对停顿时间有严格要求的应用,如Web服务等。
5. G1(Garbage-First)收集器
- 特点:G1收集器是一种面向服务端应用的垃圾收集器,它逐步取代了CMS收集器。G1收集器具有更可控的停顿时间和高效的并发能力。它将堆内存划分为多个大小相等的独立区域(Region),并根据对象的存活周期和垃圾回收的优先级来选择要回收的区域。
- 设计目标是在控制 GC 停顿时间的同时获得高吞吐量。
- 使用分区(Region)的概念,将堆划分为多个小块。
- 并发执行,适合大堆(Large Heap)。
- 自适应调整策略,自动选择最优的收集时机。
- 适合对停顿时间和吞吐量都有较高要求的应用。
- 应用场景:适用于对停顿时间和吞吐量都有较高要求的大型应用。
- 回收过程及算法:
- 初始标记(Initial Mark):需要暂停所有用户线程,标记从 GC Roots 能直接关联到的对象,时间很短。
- 并发标记(Concurrent Mark):与用户线程并发执行,对堆中对象进行可达性分析,标记存活对象。
- 最终标记(Final Mark):需要暂停所有用户线程,处理并发标记阶段遗留的少量的 SATB(Snapshot - At - The - Beginning)记录。
- 筛选回收(Live Data Counting and Evacuation):对各个区域的回收价值和成本进行排序,根据设定的停顿时间,选择部分区域进行回收,回收过程中采用复制算法,将存活对象复制到新的区域。
6. ZGC Collector(Z Garbage Collector)
- 特点:
- 专注于极低的 GC 停顿时间。
- 使用并行与并发技术。
- 适合非常大的堆(数 TB)。
- 适用于需要极高响应时间的应用。
- 从 Java 11 开始引入。
7. Shenandoah Collector
- 特点:
- 类似于 ZGC,专注于极低的 GC 停顿时间。
- 使用并行与并发技术。
- 适合需要极高响应时间的应用。
- 从 Java 9 开始作为实验性功能,Java 12 作为正式功能引入。
8. Parallel Old Collector
- 特点:
- 与 Parallel Collector 配合使用。
- 在老年代中使用,称为 Parallel Old。
- 适用于需要高吞吐量的应用。
- 回收算法:
- 采用标记 - 整理算法进行老年代垃圾回收。
9. Serial Old Collector
-
特点:
- 与 Serial Collector 配合使用。
- 在老年代中使用,称为 Serial Old。
- 适用于小型应用或测试环境。
-
适用场景
- 主要用于 Client 模式下的老年代垃圾回收,或者在 Server 模式下与 Parallel Scavenge 回收器搭配使用,用于处理 CMS 回收器产生的垃圾碎片等情况。
-
回收算法
- 采用标记 - 整理算法进行老年代垃圾回收。
10. Concurrent Mark Sweep Collector (CMS)
- 特点:
- 已经在 Java 9 中被标记为废弃,并在 Java 14 中被移除。
- 曾经用于降低停顿时间,但在现代 JVM 中已经被 G1 等更先进的收集器取代。
- 回收过程及算法:
- 初始标记(Initial Mark):需要暂停所有用户线程,标记从 GC Roots 能直接关联到的对象,速度很快。
- 并发标记(Concurrent Mark):可以与用户线程并发执行,从初始标记的对象开始,遍历整个老年代,标记所有存活的对象。
- 重新标记(Remark):需要暂停所有用户线程,修正并发标记期间因用户线程继续运行而导致标记变动的那部分对象的标记记录,这个阶段的停顿时间比初始标记长,但远比并发标记短。
- 并发清除(Concurrent Sweep):与用户线程并发执行,清除未被标记的垃圾对象。
- 整体采用标记 - 清除算法,在并发清除阶段会产生一定的内存碎片。
垃圾回收算法简介
为了更好地理解垃圾回收器的工作原理,以下是几种常见的垃圾回收算法的简要介绍:
- 标记-清除算法:该算法分为标记和清除两个阶段。在标记阶段,垃圾回收器会从GC Roots开始遍历所有可达的对象,并标记它们为活动对象。在清除阶段,垃圾回收器会遍历整个堆,回收所有未被标记的对象的内存。但这种方法可能会产生大量不连续的内存碎片。
- 标记-整理算法:该算法是标记-清除算法的改进版本。它在标记和清除的基础上增加了整理阶段,将所有活动对象向一端移动,从而消除内存碎片。但这种方法可能会增加额外的开销。
- 复制算法:该算法通常用于新生代垃圾回收。它将内存分为Eden空间和两个Survivor空间。在垃圾回收时,将还存活的对象复制到另一个Survivor空间或老年代中,然后清空当前使用的空间。这种方法可以减少内存碎片的产生,但可能会浪费一定的空间。
总结
选择合适的垃圾回收器需要根据应用程序的具体需求和运行环境进行权衡。以下是一些选择垃圾回收器时需要考虑的因素:
- 内存大小:对于大内存应用,G1和CMS可能是更好的选择。
- 吞吐量:如果对吞吐量有较高要求,Parallel GC是较好的选择。
- 停顿时间:对于对响应时间要求较高的应用,CMS和G1可能更合适。
- CPU资源:并行和并发垃圾收集器会占用额外的CPU资源来进行垃圾回收工作。如果应用程序本身已经对CPU资源有较高的需求,那么需要谨慎选择垃圾收集器,以避免对应用程序性能造成过大影响。
- 垃圾产生速度:如果应用程序产生垃圾的速度非常快,那么需要选择能够高效处理大量垃圾的收集器,如G1或Parallel GC。
- JVM版本:不同版本的JVM可能支持不同的垃圾收集器,且同一收集器在不同版本中的表现也可能有所不同。因此,在选择垃圾收集器时,还需要考虑JVM的版本兼容性。
垃圾收集器的调优是一个复杂的过程,需要根据具体的应用场景和性能目标进行调整。以下是一些常见的调优策略:
- 设置合适的堆内存大小:堆内存设置过大或过小都会影响垃圾收集器的性能。过大可能导致垃圾回收时间过长,过小则可能频繁触发垃圾回收。因此,需要根据应用程序的内存需求来设置合适的堆内存大小。
JVM的垃圾回收器有多种类型,每种类型都有其特定的应用场景和优势。在选择垃圾回收器时,需要根据应用的特点和需求进行权衡和选择。同时,了解垃圾回收算法的基本原理也有助于更好地理解垃圾回收器的工作原理和优化策略。
相关文章:

高级java每日一道面试题-2024年10月24日-JVM篇-说一下JVM有哪些垃圾回收器?
如果有遗漏,评论区告诉我进行补充 面试官: 说一下JVM有哪些垃圾回收器? 我回答: 1. Serial收集器 特点:Serial收集器是最古老、最稳定的收集器,它使用单个线程进行垃圾收集工作。在进行垃圾回收时,它会暂停所有用户线程,即St…...

Java-内部类
个人主页 学习内部类(Inner Class)是Java编程中一项重要且强大的特性,它允许你在一个类的内部定义另一个类。内部类提供了一种将逻辑上相关的类组织在一起的方式,增加了代码的封装性和可读性。接下来带领大家进入內部类的学习。 …...

flutter集成极光推送
一、简述 极光推送,英文简称 JPush,免费的第三方消息推送服务,官方也推出众多平台的SDK以及插件。 参考链接 名称地址客户端集成插件客户端集成插件 - 极光文档 二、操作步骤 2.1 添加插件 flutter项目中集成官方提供的 极光推送flutte…...

D. Skipping 【 Codeforces Round 980 (Div. 2)】
D. Skipping 思路: 注意到最佳策略是先往右跳转到某处,然后按顺序从右往左把没有遇到过的题目全部提交。 将从 i i i跳转到 b [ i ] b[i] b[i]视为通过边权(代价)为 a [ i ] a[i] a[i]的路径,而向左的路径边权都是 0 0 0;目的是找到到从出发…...

【golang】学习文档整理
Binding | Echo 传值时注意零值和传空的区别 需要validate require 和 设置指针配合使用 保证不同值的返回不同 不能客户端传0值被判断为空 测试时要空值零值去测试字段是否正确返回 返回错误是否符合预期...

动态规划-子序列问题——1218.最长定差子序列
1.题目解析 题目来源:1218.最长定差子序列——力扣 测试用例 2.算法原理 1.状态表示 本题可以看作是寻找一个等差序列,并且公差给出,这里并不是普通的使用一个dp表,而是将arr与dp表同时存储于一个哈希表,arr[i]映射dp…...

双子塔楼宇可视化系统:提升建筑管理与运营效率
利用图扑可视化技术对双子塔楼宇的各项功能进行实时监控和管理。通过数据分析优化资源配置,提高能源效率,增强楼宇安全性,实现智能化运营。...
32位的ARMlinux的4字节变量原子访问问题
在32位的ARM Linux内核中,4字节整型变量通常被认为是原子操作。 这主要是因为: 对齐要求:在ARM架构中,4字节整型变量通常是按4字节对齐存储的,这样可以确保在读取和写入时,CPU能够以单个指令完成操作。 …...

用哪种建站程序做谷歌SEO更容易?
做网站很容易,但做一个能带来流量和订单的网站就没那么简单了。尤其是在谷歌SEO优化方面,不同的建站程序对SEO的支持程度也不同。在这方面,WordPress和Shopify无疑是最佳选择。 WordPress作为一个内容管理系统(CMS)&am…...
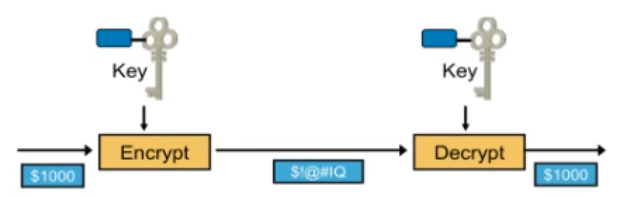
IPsec简单介绍
VPN相关介绍 VPN:虚拟私有网络 例如:像这种不加密的 PPTPL2TP ------- 一般用在windows server 服务端(但是大多数企业不用这个) 假如总公司内部的PC1要去访问分公司内部的PC2(一般用在公司服务器有内网的服务&#…...
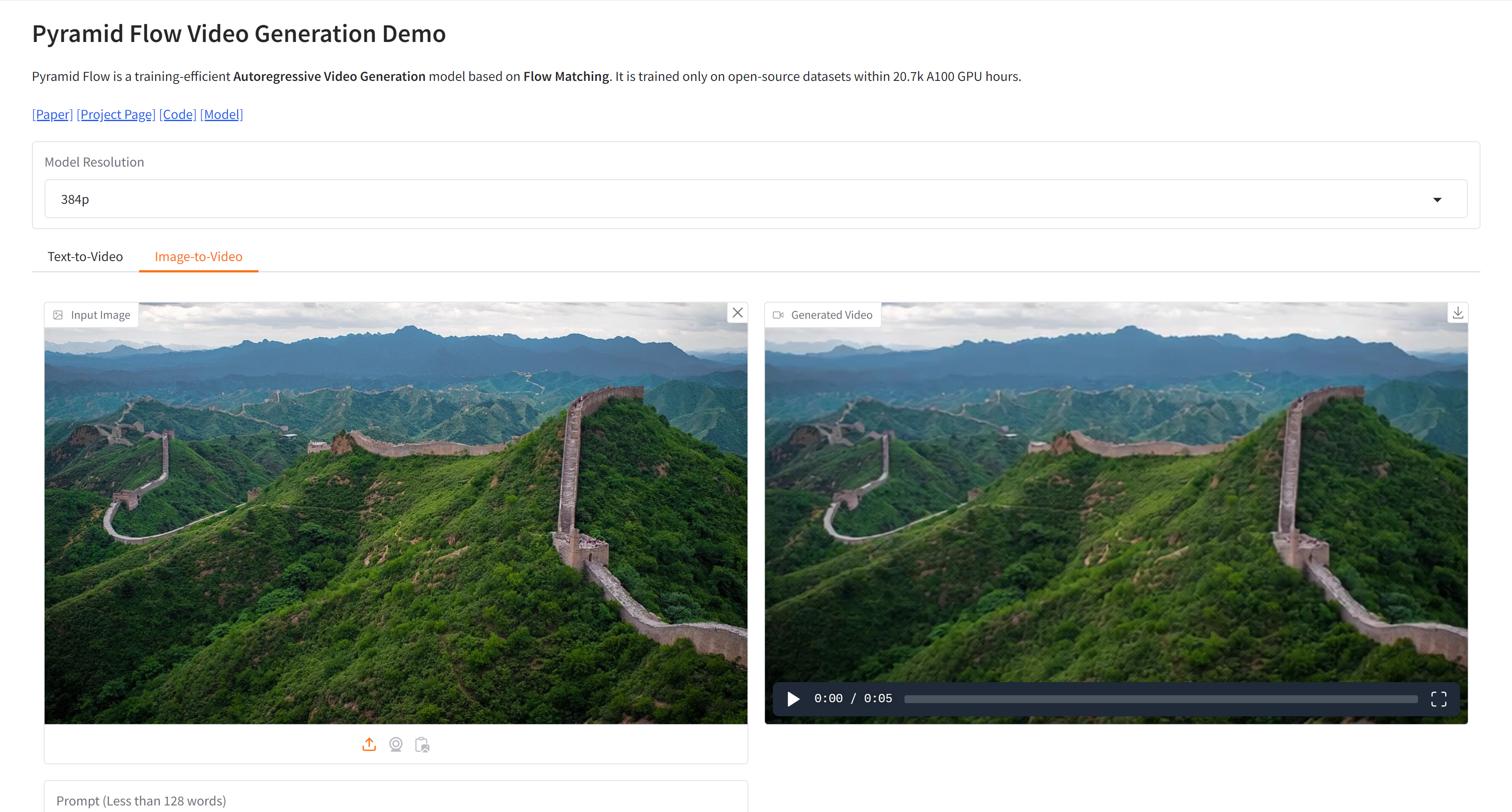
颠覆级AI:10秒生成超清视频
颠覆级AI:10秒生成超清视频 Pyramid-Flow 是一款开源 AI 视频生成神器💻,只需文字或图片即可极速生成高清视频🎥!高效、高清、资源需求低,适合创作广告、教学视频等多种用途🚀,快来…...

《西安科技大学学报》
《西安科技大学学报》主要刊载安全科学与工程、矿业工程、建筑与土木工程、地质与环境工程、测绘工程、材料科学与工程、化学与化工、机械工程、电气工程及自动化、通信与信息工程、计算机科学与工程、矿业经济管理等专业领域内具有创新性的学术论文和科研成果。 来稿必须符合以…...

redis详细教程(2.List教程)
List是一种可以存储多个有序字符串的数据类型,其中的元素按照顺序排列(可以重复出现),可以通过数字索引来访问列表中的元素,索引可以从左到右或者从右到左。 Redis 列表可以通过两种方式实现:压缩列表&…...

电子电气架构 --- 电气系统工程
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消耗你的人和事,多看一眼都是你的不对。非必要不费力证明自己,无利益不试图说服别人,是精神上的节…...

15-4连续子串和的整除问题
问题描述 小M是一个五年级的小学生,今天他学习了整除的知识,想通过一些练习来巩固自己的理解。他写下了一个长度为 n 的正整数序列 a_0, a_1, ..., a_{n-1},然后想知道有多少个连续子序列的和能够被一个给定的正整数 b 整除。你能帮小M解决这…...

Spring源码:Bean创建、Bean获取
Bean是怎么被创建,如何获取Bean,基于Spring 5.3.24版本,Spring Boot 可用 2.7.6 结论: 创建:非懒加载的单实例bean在容器创建的时候创建,通过beanFactory的doGetBean方法,利用反射进行创建&…...

MetaArena推出《Final Glory》:引领Web3游戏技术新风向
随着区块链技术的日益成熟,Web3游戏成为了游戏产业探索的新方向,将去中心化经济与虚拟世界结合在一起,形成了一个全新的生态体系。然而,尽管Web3游戏展示了令人兴奋的可能性,但其背后的技术障碍依旧严峻,特…...

玩转Shodan:深度挖掘特定漏洞与脆弱资产的实战技巧
内容预览 ≧∀≦ゞ Shodan进阶使用之发现并解锁隐藏的脆弱资产声明导语VNC未授权访问查询被黑的网站查询思科未授权设备查询MongoDB未授权访问搜索后台管理页面结语 Shodan进阶使用之发现并解锁隐藏的脆弱资产 声明 笔记内容参考了B站UP主泷羽sec的学习视频,如有侵…...

Java程序设计:spring boot(8)——API ⽂档构建⼯具 - Swagger2
目录 1 环境整合配置 2 Swagger2 常⽤注解说明 2.1 Api 2.2 ApiOperation 2.3 ApiImplicitParams 2.4 ApiResponses 2.5 ApiModel 3 用户模块注解配置 3.1 Controller 使用注解 3.2 JavaBean 使用注解 4 Swagger2 接⼝⽂档访问 由于 Spring Boot 能够快速开发、便捷…...

【Python】if选择判断结构详解:逻辑分支与条件判断
目录 🍔 if选择判断结构作用 1.1 if选择判断结构的基本语法 1.2 if选择结构案例 1.3 if...else...结构 1.4 if...elif...else多条件判断结构 1.5 if嵌套结构 🍔 综合案例:石头剪刀布 2.1 需求分析 2.2 代码实现 2.3 随机出拳 &…...

如何快速解密RPG Maker加密文件:终极解密工具使用指南
如何快速解密RPG Maker加密文件:终极解密工具使用指南 【免费下载链接】RPGMakerDecrypter Tool for decrypting and extracting RPG Maker XP, VX and VX Ace encrypted archives and MV and MZ encrypted files. 项目地址: https://gitcode.com/gh_mirrors/rp/R…...

MUMmer4:基因组比对领域的终极解决方案
MUMmer4:基因组比对领域的终极解决方案 【免费下载链接】mummer Mummer alignment tool 项目地址: https://gitcode.com/gh_mirrors/mu/mummer 在基因组学研究领域,高效、准确的序列比对工具是解开生命密码的关键钥匙。MUMmer4作为一款开源的快速…...

Godot开发者的宝藏:awesome-godot资源库使用指南与实战技巧
1. 项目概述:一个游戏开发者的“藏宝图”如果你正在用Godot引擎做游戏,或者对这个开源、轻量又强大的工具感兴趣,那你大概率听说过或者正在寻找一个叫“awesome-godot”的仓库。这可不是一个普通的代码项目,它更像是一份由全球God…...

新手避坑指南:用Virtuoso和Calibre做DRC/LVS检查时,IO Pad和电源连接的那些坑
数字后端验证实战:Virtuoso与Calibre中的DRC/LVS避坑指南 第一次用Virtuoso和Calibre做DRC/LVS检查的新手工程师,往往会在IO Pad和电源连接上栽跟头。这些看似基础的问题,轻则导致验证失败,重则影响芯片功能。本文将结合SIMC 0.18…...

基于LM567的反射式红外检测电路在智能车信标检测中的实战应用与优化
1. LM567红外检测电路基础解析 第一次接触LM567芯片是在五年前的智能车竞赛备赛期间,当时为了解决传统红外检测易受环境光干扰的问题,我们团队尝试了各种方案。这款看似普通的8脚芯片,却让我们成功实现了在强光环境下稳定工作的红外检测系统。…...

Stata 数据处理实战:时间序列数据的日期转换与聚合
1. 时间序列数据处理的常见痛点 刚接触时间序列分析的朋友们,经常会遇到这样的困扰:从Excel导入的数据明明是日期格式,到了Stata里却变成了看不懂的字符;想按周汇总销售数据,却发现系统根本不认识"2023-W15"…...

构建可靠AI智能体:从提示词工程到结构化内容生成的实战指南
1. 项目概述与核心思路最近在折腾AI应用开发,特别是想搞一个能稳定输出、逻辑清晰、还能带点“人味儿”的文本生成工具。市面上现成的方案要么太“机械”,要么定制化程度不够,总感觉差点意思。后来,我在一个开发者社区里看到了一个…...

开源游戏串流革命:Sunshine如何重新定义家庭游戏共享体验
开源游戏串流革命:Sunshine如何重新定义家庭游戏共享体验 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 在游戏设备日益多样化的今天,你是否曾想过将高性能…...

MemOS:为AI智能体构建统一记忆操作系统,提升长期对话与RAG性能
1. 项目概述:MemOS,为AI智能体装上“记忆大脑” 如果你正在开发基于大语言模型的AI智能体,或者在使用RAG(检索增强生成)技术,那么你一定遇到过这个核心痛点: 对话上下文太短,智能体…...
)
从DICOM到NIfTI:3D Slicer中医学图像坐标转换的完整避坑指南(附Python代码片段)
从DICOM到NIfTI:3D Slicer中医学图像坐标转换的完整避坑指南(附Python代码片段) 医学影像处理中,数据格式和坐标系的差异常常成为工程师和研究员们的"隐形杀手"。想象一下,你花了三天三夜训练的深度学习模型…...