Scrapy框架原理与使用流程
一.Scrapy框架特点
- 框架(Framework)是一种软件设计方法,它提供了一套预先定义的组件和约定,帮助开发者快速构建应用程序。框架通常包括一组库、工具和约定,它们共同工作以简化开发过程。
- scrapy框架是python写的 为了爬取网站数据 提取结构化数据的爬虫框架
- 相当于人家已经给我们写好了功能,提供好了方法,我们直接拿过来用就可以完成对应v
- 特点:
1.异步处理提高爬取效率
(1)异步处理的基本原理
异步处理允许程序在等待某些操作完成时继续执行其他任务,从而避免了CPU资源的浪费,这种非阻塞的工作模式显著提高了数据处理的效率和吞吐量。
(2)异步处理在爬虫中的应用
在网络爬虫中应用异步处理,可以同时处理多个请求,减少了等待服务器响应的时间,通过并发爬取,大幅提高了数据抓取的速度和效率。
(3)异步处理的优势与挑战
异步处理通过提高资源利用率和响应速度来提升爬取效率,但同时也带来了编程模型的复杂性,需要合理管理并发任务和资源,以避免潜在的性能瓶颈和错误。
2.中间件系统扩展功能
(1)下载器中间件功能
下载器中间件通过自定义扩展,实现对下载过程的深度定制,如添加请求头信息、处理响应数据等,极大增强了Scrapy框架的灵活性和功能性。
(2)爬虫中间件作用
爬虫中间件在引擎与爬虫间架起桥梁,允许用户插入自定义代码来操作请求和响应,从而实现对爬虫流程的精细控制,提升数据处理的能力和效率。
(3)中间件系统的功能拓展
通过中间件系统,Scrapy能够实现包括网络通讯处理、下载加速、异步框架支持等功能,这些功能拓展了Scrapy的应用范围,满足了更多样化的爬虫开发需求。
3.数据管道处理存储数据
(1)定义Item类
在数据管道处理的第一步中,我们定义一个继承自`scrapy.Item`的类,这个类通过使用`scrapy.Field()`定义字段,来存储我们需要爬取的数据。
(2)编写Pipeline类
接下来,我们创建一个Pipeline类,实现`open_spider`和`process_item`两个关键方法,用于在爬虫开始时初始化资源,并在每个item被爬取后进行处理,如写入文件或数据库。
(3)数据处理与存储
在`process_item`方法中,我们可以编写逻辑来具体处理每一个item,例如将其写入文件或存入数据库。根据这个方法是否返回item对象,决定item是否继续传递到下一个Pipeline。
4.内置选择器提取数据
(1)XPath选择器提取数据
XPath选择器通过XPath表达式定位网页元素,能够精确地从复杂的HTML结构中提取出所需的数据,如使用特定路径表达式提取具有特定属性的元素文本。
(2)CSS选择器提取数据
CSS选择器利用简洁的语法通过元素的类名、ID或属性等来定位网页中的特定元素,使得数据提取过程更为直接和高效,适用于快速提取样式定义的元素内容。
(3)正则表达式匹配数据
正则表达式提供强大的字符串匹配能力,通过定义特定的模式来匹配和提取字符串中的复杂数据,是处理非结构化文本数据时不可或缺的工具,尤其适用于从文本中提取符合特定格式的信息。
5.支持分布式爬虫任务
(1)Redis作为共享队列
在Scrapy分布式爬虫中,Redis充当核心的共享队列和数据存储角色,允许不同爬虫实例通过它共享待爬取的URL和已抓取的数据,实现信息同步。
(2)调度器的角色
调度器在Scrapy框架中负责管理和分配待爬取的URLs。在分布式设置下,通过Redis实现的调度器确保多个爬虫实例能高效地获取并处理URLs。
(3)并行下载与数据处理
Scrapy分布式爬虫利用各自的下载器进行并行下载,以及多个Spider实例同时运行来处理网页,提高了下载效率和数据处理速度,Item Pipeline则负责后续的数据存储或处理工作。
二.Scrapy使用流程
1.开发步骤
(1)项目创建 创建项目:scrapy startproject xxx(项目名字,不区分大小写)!!!(在终端输入open in Explore)
(2)明确目标 (编写items.py):明确你想要抓取的目标,其实就是先确定一下你要爬取什么字段的数据
(3)制作爬虫 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
(4)存储内容 存储内容 (pipelines.py):设计管道存储爬取内容取网页
实际中不必要按照顺序去遵守 自己写代码想咋写就咋写 实现功能为主
2.项目文件解释
spiders 爬虫目录
items 设置数据存储的模板
middlewares 中间件文件
pipelines 管道文件 数据持久化
settings 配置文件
3.项目创建与使用
创建项目 scrapy startproject xxx(项目名)
进入项目 cd xxx(项目名)。
创建爬虫 scrapy genspider 爬虫名 要爬取网站的域名
运行爬虫 scrapy crawl 爬虫名
4.爬虫文件
- 创建爬虫文件默认生成一个类,里面三个属性一个方法
(1)三个属性
name = "" :这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字 `allow_domains = []` 是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略 `start_urls = [] :爬取的URL列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
(2)一个方法
`parse(self, response)` :解析的方法,每个初始URL完成下载后将被调用,调用的时候传入请求url的Response对象来作为唯一参数,主要作用如下: 1. 负责解析返回的网页数据(response.body),提取结构化数据(生成item) 2. 生成需要下一页的URL请求。
5.配置Settings设置
(1)修改settings.py文件
`settings.py`位于Scrapy项目的根目录,是项目配置的核心。通过修改该文件,可以调整日志级别、用户代理等关键设置,以适应不同的爬虫需求。
(2)常见设置项
Scrapy中的常见设置项包括LOG_LEVEL用于调整日志输出级别,ROBOTSTXT_OBEY决定是否遵守robots协议,以及USER_AGENT用于设置爬虫的用户代理字符串,帮助爬虫更好地伪装身份。
(3)日志等级
严重错误 critical
一般错误 error
警告 warning
一般信息 info
调试信息 debug
默认的日志等级是debug LOG_LEVEL = 'ERROR' 修改日志的输出
6.Scrapy框架组成部分!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
(1)调度器
作用: 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
(2)引擎
作用:负责与其他部分的交流通讯
(3)下载器
作用:负责下载引擎发送的所有Requests请求,并将其获取到的Responses交还给引擎,由引擎交给Spider来处理
(4)爬虫
作用:它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入调度器
(5)管道
作用: 它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
7.Scrapy的运作流程
(1)8.. ``引擎``询问`Spider`, 需要爬取的网站是谁?
(2). `Spider`:告诉`引擎`目标url是谁。并且给到`引擎`
(3). `引擎`:Hi!`调度器`,我这有request请求你帮我排序入队一下。
(4). `调度器`:好的,对这个请求做对应的处理,比如排序入队,。
(5). `调度器`:排序入队完了以后把处理好的request给`引擎`
(6). `引擎`:找到 `下载器 `,你按照`下载中间件`的设置帮我下载一下这个request请求
(7). `下载器`:好的!把下载好的东西发给 ` 引擎`。(如果这个request下载失败了。然后`引擎`告诉`调度器`,这个request下载失败了,你记录一下,我们待会儿再下载)
(8). `引擎`:把下载好的内容给到 ` Spider`(注意!这儿responses默认是交给`def parse()`这个函数处理的)
(9). `Spider`:处理完毕有两个结果,一:我需要跟进的URL,二:需要保存的Item数据 如果为结果一就重复第2到最后的步骤,如果为结果二, ` Spider`把item数据发给 ` 引擎`,由 ` 引擎`给 ` 管道`进行持久化存储 重复这个步骤 直到爬虫运行完毕 注意:只有当`调度器`没有request需要处理时,整个程序才会停止。(对于下载失败的URL,Scrapy也会重新下载。)
8.数据管道处理存储数据
(1)定义Item类
`scrapy.Item`,这个类通过使用`scrapy.Field()`定义字段,来存储我们需要爬取的数据。我们需要存几个字段的数据就定义几个字段的值, 字段名= scrapy.Field()
(2).爬虫使用
from ..items import item类名 变量名 =类名() # 实例化 变量名[字段名]=字段值 yield item # 通过yield 把数据发给管道
(3).编写Pipeline类
`process_item`这个方法里面写数据保存的代码。如文件保存到本地的代码,里面的return可以把数据传给下一个管道,管道可以定义多个,不同的管道做不同的数据保存操作,如一个管道存MySQL一个管道写代码把数据存本地,也可以一个管道即存MySQL又存本地
(4). 配置文件解开注释
配置文件解开管道的注释 其中key的值是管道类名的路径,值是权重值,权重值越小 优先级越高,范围是0-1000会按照权重大小依次执行,先到第一个权重高的管道 执行 process_item方法 保存到本地 如果没有return出去 没有返回 那么就会阻塞在当前管道
## Scrapy的运作流程
#
# 代码写好,程序开始运行...
#
# 1. ``引擎``:Hi!`Spider`, 你要处理哪一个网站?
#
# 2. `Spider`:老大要我处理xxxx.com。
#
# 3. `引擎`:你把第一个需要处理的URL给我吧。
# 4. `Spider`:给你,第一个URL是xxxxxxx.com。
#
# 5. `引擎`:Hi!`调度器`,我这有request请求你帮我排序入队一下。
# 6. `调度器`:好的,正在处理你等一下。
#
# 7. `引擎`:Hi!`调度器`,把你处理好的request请求给我。
# 8. `调度器`:给你,这是我处理好的request
#
# 9. `引擎`:Hi!下载器,你按照老大的`下载中间件`的设置帮我下载一下这个request请求
#
# 10. `下载器`:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后`引擎`告诉`调度器`,这个request下载失败了,你记录一下,我们待会儿再下载)
#
# 11. `引擎`:Hi!`Spider`,这是下载好的东西,并且已经按照老大的`下载中间件`处理过了,你自己处理一下(注意!这儿responses默认是交给`def parse()`这个函数处理的)
#
# 12. `Spider`:(处理完毕数据之后对于需要跟进的URL),Hi!`引擎`,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
#
# 13. `引擎`:Hi !`管道` 我这儿有个item你帮我处理一下!`调度器`!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
#
# 14. `管道``调度器`:好的,现在就做!
#
# ***注意:只有当`调度器`没有request需要处理时,整个程序才会停止。(对于下载失败的URL,Scrapy也会重新下载。)***9.scrapy 常见报错
报错1: AttributeError: 'AsyncioSelectorReactor' object has no attribute '_handleSignals '
原因:Twisted版本23会有不兼容的情况
解决:卸载Twisted 安装Twisted21或者22就行 可以换成 22.10.0版本
pip uninstall Twisted pip install Twisted==22.10.0
报错2:ImagesPipeline 接收不到数据 其他管道能接收
原因:缺少环境 ImagesPipeline 依赖 pillow
解决:pip install pillow
报错3: TypeError: ExecutionEngine.crawl() got an unexpected keyword argument ‘spider‘
原因:运行分布式出现这个问题 是scrapy-redis比较老 用了新版本scrapy以后不兼容
解决:安装老版本的scrapy 经测试 2.9.0和之前的适配
selenium常见报错
报错1:ValueError:Tineout valve connect was object object at 0x00002354CDD7F80>,but it must be an int,float op None,
原因:selenium与urllib3不兼容
解决:卸载urllib3 安装老版本 比如1.26.2就可以解决 pip uninstall urllib3 再 pip install urllib3==1.26.2
报错2:ModuleNotFoundError: No module named 'urllib3.packages.six.moves'
原因:这个报错通常出现在环境为 selenium3.141+urllib1.26+python3.12的电脑上 因为python3.12太新了不能用selenium3.141
解决:方法1:selenium更新到4 urllib更新到最新 就可以解决了
方法2:selenium降低到3.3.1就行 pip uninstall selenium再 pip install selenium==3.3.1
注意:只是例举出了环境方面的报错 其他使用途中的报错大概率是代码编写问题 后续可能更新常见代码报错问题(存在最后报错相同 代码不同的情况 只能编写 报错原因和解决思路 )
相关文章:
Scrapy框架原理与使用流程
一.Scrapy框架特点 框架(Framework)是一种软件设计方法,它提供了一套预先定义的组件和约定,帮助开发者快速构建应用程序。框架通常包括一组库、工具和约定,它们共同工作以简化开发过程。scrapy框架是python写的 为了爬…...

【C语言】字符型在计算机中的存储方式
ASCII对照表:https://www.jyshare.com/front-end/6318/ ASCII(American Standard Code for Information Interchange,美国信息互换标准代码,ASCII)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语和其他西…...

python:ADB通过包名打开应用
一、依赖库 os 二、命令 1.这是查看设备中所有应用包名的最简单方法。只需在命令行中输入以下命令: adb shell pm list packages 2.打印启动的程序包名 adb shell am monitor回车,然后启动你想要获取包名的那个应用,即可获得 3.查看正在运…...

机器翻译技术:AI 如何跨越语言障碍
大家好,我是Shelly,一个专注于输出AI工具和科技前沿内容的AI应用教练,体验过300款以上的AI应用工具。关注科技及大模型领域对社会的影响10年。关注我一起驾驭AI工具,拥抱AI时代的到来。 AI工具集1:大厂AI工具【共23款…...
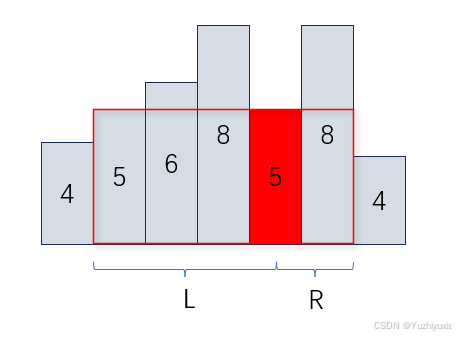
单调栈应用介绍
单调栈应用介绍 定义应用场景实现模板具体示例下一个最大元素I问题描述问题分析代码实现柱状图中最大的矩形问题描述问题分析代码实现接雨水问题描述问题分析代码实现最大宽度坡问题描述问题分析代码实现132模式问题描述问题分析代码实现定义 栈(Stack)是另一种操作受限的线性…...

部署前后端分离若依项目--CentOS7Docker版
一、准备 centos7虚拟机或服务器一台 若依前后端分离项目:可在下面拉取 RuoYi-Vue: 🎉 基于SpringBoot,Spring Security,JWT,Vue & Element 的前后端分离权限管理系统,同时提供了 Vue3 的版本 二、环…...
PH47代码框架功能速查
1. PH47框架逻辑层全局引用对象 全局引用 功能简介 快速访问 bus 数据总线系统功能实现,如对总线数据项读写操作等 数据总线bus drv 驱动层功能实现,如飞控板相关的各种硬件传感器设备进行操作等 驱动层drv mcu 对mcu的片内接口及设备进行操作…...
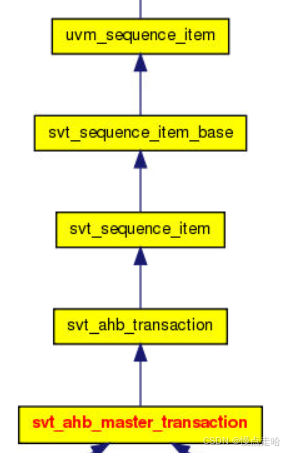
UVM寄存器模型:uvm_reg_adapter
文章目录 一、什么是uvm_reg_adapter1、what2、Example2.1、代码详解 二、如何使用uvm_reg_adapter三、为什么要引入uvm_reg_adapter 一、什么是uvm_reg_adapter 1、what uvm_reg_adapter继承于uvm_object,定义了用于在 uvm_reg_bus_op 和特定总线事务之间进行转换…...

总结OpenGL和pyrender安装和使用过程中的坑
目录 报错一:AttributeError: NoneType object has no attribute glGetError 报错二:ImportError: (Unable to load OpenGL library, OSMesa: cannot open shared object file: No such file or directory, OSMesa, None) 报错三:raise ImportError("Unable to load…...
)
温湿传感器(学习笔记下)
接着我们温湿传感器上半部分的学习,现在我们学习接下来的部分,编写GXHTC3驱动程序,也就是给gxhtc3.c文件添加代码,我们要判断gxhtc3芯片是否存在和正常,就要先读取gxhtc3的ID号,根据gxhtc3的数据手册,读取命…...
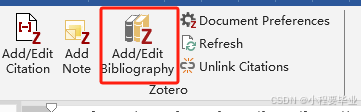
期刊论文写作之word模板
一、zotero参考文献使用 下载zotero软件,请搜索相关帖子或者小破站即可; 把pdf拖到zotero软件里面,直接拉进去; 下面建立一个word演示: 1.导入pdf点击红框部分,根据期刊要求选择参考文献样式࿰…...

雷池社区版OPEN API使用教程
OPEN API使用教程 新版本接口支持API Token鉴权 接口文档官方没有提供,有需要可以自行爬取,爬了几个,其实也很方便 使用条件 需要使用默认的 admin 用户登录才可见此功能版本需要 > 6.6.0 使用方法 1.在系统管理创建API TOKEN 2.发…...

LSTM(Long Short-Term Memory,长短期记忆网络)在高端局效果如何
lstm 杂乱数据分析 LSTM(Long Short-Term Memory,长短期记忆网络)在高端局,即复杂的机器学习和深度学习应用中,展现出了其独特的优势和广泛的应用价值。以下是对LSTM在高端局中的详细解析: 一、LSTM的优势…...
模组操作宝典:4种关机重启技巧,让你的设备运行无忧
今天我说的是关于关机重启技巧。 给4G模组VBAT断电关机,模组关机前未能及时退出当前基站,会有什么影响呢? 基站会误以为设备还在线,下次开机仍会拿着上次驻网信息去连基站。基站一看,上次链接还在——认为你是非法设…...
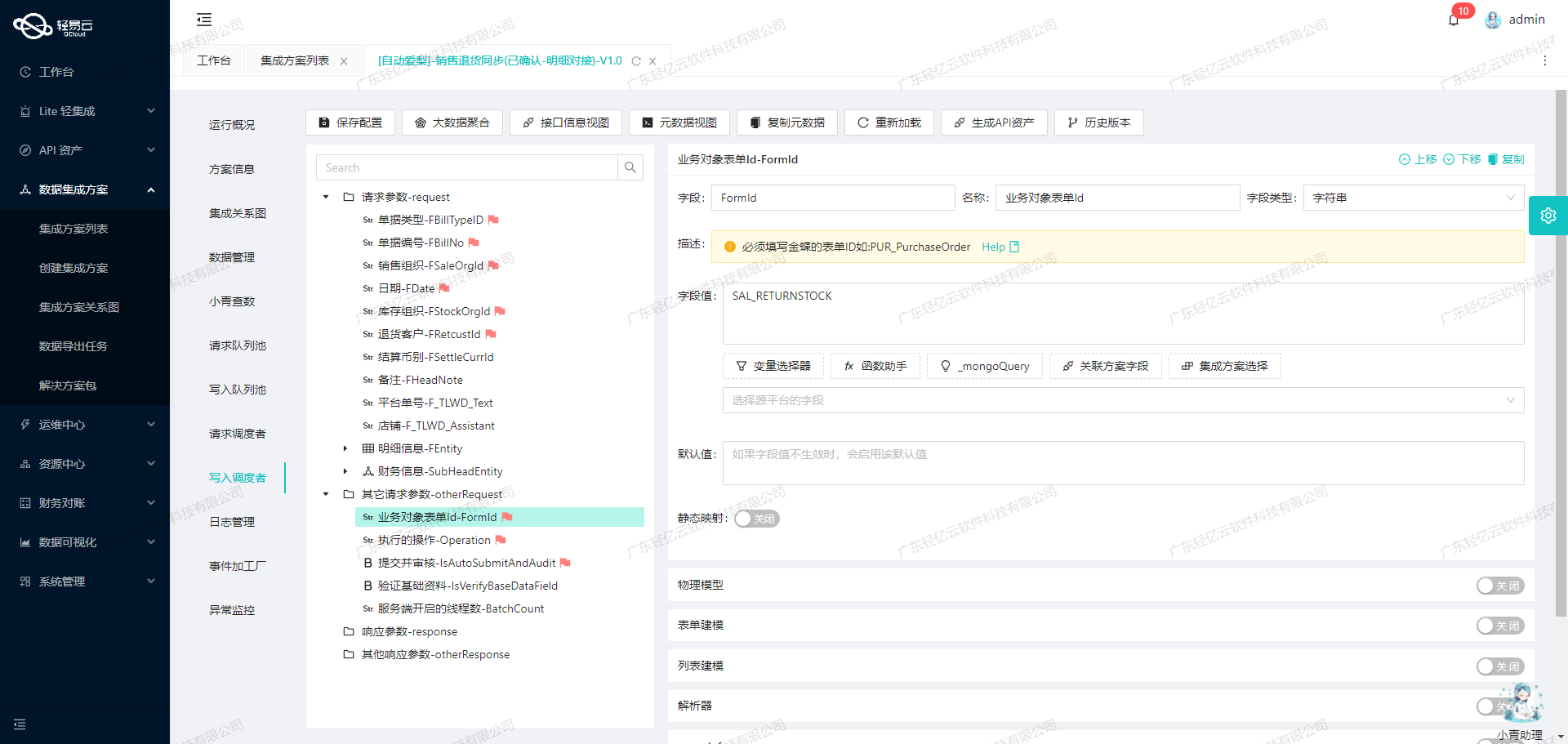
利用API接口实现旺店通和金蝶系统的无缝数据对接
旺店通销售出库对接金蝶销售订单(线下)的技术实现 在企业日常运营中,数据的高效流转和准确对接是确保业务顺畅运行的关键。本文将聚焦于一个具体案例:如何通过轻易云数据集成平台,实现旺店通企业奇门的数据无缝对接到金蝶云星空系统。我们将…...
)
热题100(hash)
热题100(Hash) 三道题目 1.两数之和(√) 49.字母异位词分组(题解) 128.最长连续序列(题解) 思路 第1题简单hash映射,O(n) 第49题,关键点在于Hashmap的形式,‘HashMap<Stri…...

Ubuntu下Mysql修改默认存储路径
首先声明,亲身经验,自己实践,网上百度了好几个帖子,全是坑,都TMD的不行,修改各种配置文件,就是服务起不来,有以下几种配置文件需要修改 第一个文件/etc/mysql/my.cnf 这个文件是存…...

LVGL移植教程(超详细)——基于GD32F303X系列MCU
版本:LVGL Kernel V8.3.0,运行压力测试Demo Stress首先放一张最终Stress Demo 运行图: 一、准备 1. GD32 Keil工程 准备任意一个屏幕可以正常显示的GD32工程: 2. LVGL源码 最新版现在已经是V9.2了,这里我选择了…...

《计算机原理与系统结构》学习系列——处理器(中)
系列文章目录 目录 流水线数据通路与控制概述5个流水级指令周期与流水级 流水线性能流水线时钟周期的长度T和数量cycles流水线性能 流水线数据通路流水线寄存器流水线分析图形化流水线流水线控制 流水线数据通路与控制 概述 5个流水级 指令周期与流水级 单周期实现中&#x…...

深入解析 OceanBase 数据库中的局部索引和全局索引
深入解析 OceanBase 数据库中的局部索引和全局索引 引言 在分布式数据库中,索引的设计对于优化查询性能至关重要。OceanBase 作为一款高性能的分布式关系数据库,支持局部索引和全局索引两种索引类型。理解这两种索引的特点和适用场景,对于数…...

光纤链路故障排查:从指示灯误导到光功率测量的工程实践
1. 项目概述:一个关于“指示灯谎言”的工程教训在电子工程和测试测量领域,我们习惯于依赖设备上的指示灯——那些绿色、红色或琥珀色的小灯——来快速判断系统状态。它们是我们与复杂硬件对话的直观语言。然而,今天我想分享一个十多年前的真实…...

3步解锁百度网盘满速下载:告别限速困扰的完整方案
3步解锁百度网盘满速下载:告别限速困扰的完整方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘的非会员下载速度而烦恼吗?面对100KB/…...

嵌入式软件在医疗设备开发中的关键技术与实践
1. 嵌入式软件如何重塑现代医疗设备开发作为一名在医疗电子行业摸爬滚打十余年的嵌入式系统工程师,我亲眼见证了嵌入式技术如何彻底改变医疗设备的形态与功能。2008年参与第一台便携式心电监护仪开发时,设备体积还像个手提箱,如今同样功能的设…...

Bonsai工具库:函数式编程与代码设计模式实战解析
1. 项目概述:当代码遇见禅意最近在GitHub上闲逛,发现一个挺有意思的项目,叫sauravpanda/bonsai。光看名字,你可能以为这是个园艺或者艺术相关的仓库,但实际上,它是一个非常精巧的编程工具库。这个项目名“B…...

【ElevenLabs商业增长实战手册】:20年AI语音赛道老兵亲授从0到月营收$2M的7个关键跃迁节点
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs商业增长的核心范式迁移 传统AI语音服务商长期依赖“API调用量时长计费”模型,而ElevenLabs正系统性重构价值交付逻辑——从卖计算资源转向卖情感可信度与品牌声纹资产。这一迁移…...

基于RAG的本地知识库聊天机器人:anything-llm部署与实战指南
1. 项目概述:一个能“消化”任何文件的本地知识库聊天机器人最近在折腾本地大模型应用的朋友,可能都绕不开一个痛点:如何让大模型“读懂”并“记住”我自己的文档?无论是PDF报告、Word文档、网页文章,还是代码片段&…...

3步完成微信聊天记录永久备份:开源工具WeChatExporter终极指南
3步完成微信聊天记录永久备份:开源工具WeChatExporter终极指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter WeChatExporter是一款专为Mac用户设计的开源工…...

Windows系统mfc140.dll文件丢失无法启动程序解决
在使用电脑系统时经常会出现丢失找不到某些文件的情况,由于很多常用软件都是采用 Microsoft Visual Studio 编写的,所以这类软件的运行需要依赖微软Visual C运行库,比如像 QQ、迅雷、Adobe 软件等等,如果没有安装VC运行库或者安装…...

LynxPrompt Action:GitHub Actions 实现 AI 配置中心化与自动化管理
1. 项目概述:为什么我们需要一个AI配置的“中央仓库”? 如果你和我一样,日常开发中同时用着Cursor、Claude Code、GitHub Copilot,甚至还在尝试Windsurf和Aider,那你一定遇到过这个头疼的问题:每个工具的配…...
)
Midjourney油彩风格进阶必修课:用--no shadow, --iw 2.0, --style raw构建可控厚涂质感(附Gaussian噪声注入对照表)
更多请点击: https://intelliparadigm.com 第一章:Midjourney油彩风格的美学本质与技术定位 油彩风格(Oil Painting Style)在 Midjourney 中并非简单滤镜叠加,而是通过语义引导、纹理建模与隐空间解耦共同作用形成的高…...