Ollama: 使用Langchain的OllamaFunctions
1. 引言
Function call Langchain的Ollama 的实验性包装器OllamaFunctions,提供与 OpenAI Functions 相同的 API。因为网络的原因,OpenAI Functions不一定能访问,但如果能通过Ollama部署的本地模型实现相关的函数调用,还是有很好的实践意义。使用不同的模型可能能够得到不同的结果
2.Function Call
Function Call,或者叫函数调用、工具调用,是大语言模型中比较重要的一项能力,对于扩展大语言模型的能力,或者构建AI Agent,至关重要。
Function Call的简单原理如下:
- 按照特定规范(这个一般是LLM在训练阶段构造数据的格式),定义函数,一般会包含函数名、函数描述,参数、参数描述、参数类型,必填参数,一般是json格式
- 将函数定义绑定的大模型上,这一步主要是让LLM感知到工具的存在,好在query来到时选取合适的工具
- 跟常规使用一样进行chat调用
- 检查响应中是否用tool、function之类的部分,如果有,则说明触发了函数调用,并且进行了参数解析
- 根据json中定义的函数名,找到Python中的函数代码,并使用大模型解析的参数进行调用,到这一步,一般已经拿到结果了
- 通常还会再增加一步,就是拿Python中调用函数的结果,和之前的历史记录,继续调用一次大模型,这样能让最终返回结果更自然
下面这张图简单描述了大语言模型函数调用的流程:
3. Ollama模型及相关API_KEY的准备
3.1 安装Ollama
Ollama中下载大语言模型,在本试验中,将使用Ollama部署本地模型Qwen2:7b,通过ollama pull qwen2:7b即可下载,在本机运行这个模型推荐16G内存/显存,如果内存或显存不够,可以下载qwen2:7b版本,但Function Call效果可能会下降【测试表明,如果没有足够的显示,模型响应速度会很慢】。
3.2 申请相关的API_KEY
申请高德API,天气查询使用的是高德API。通过网站 https://console.amap.com/dev/key/app
申请Tavily API Key,这是一个为LLM优化的搜索API,免费用户每月有1000次调用额度,地址https://tavily.com/,点击右上角的Try it out. 通过网站:官网:Tavily
3.3 安装引用相关的包
安装langchain, langchain-core, langchain-experimental
from langchain_experimental.llms.ollama_functions import OllamaFunctionsmodel = OllamaFunctions(model='qwen:14b', base_url='http://192.2.22.55:11434', format='json')
# 定义相关API_Key
amap_api_key = '2b6437dfc4fa7f2af564eb2569a6116f' # https://console.amap.com/dev/key/app
tavily_api_key = '此处填写Tavily API Key' #官网:Tavily tavily.com
4. 绑定工具
4.1 定义工具
此处定义了2个工具,一个是网络搜索,一个是天气查询,其中天气查询要发送2次网络请求,首先根据城市名称拿到对应的行政区划码adcode,然后再使用adcode查询天气
# 自定义网络搜索工具
def search_web(query, k=5, max_retry=3):import osfrom langchain_community.retrievers import TavilySearchAPIRetrieveros.environ["TAVILY_API_KEY"] = tavily_api_keyretriever = TavilySearchAPIRetriever(k=5)documents = retriever.invoke(query)# return [{'title': doc.metadata['title'], 'abstract': doc.page_content, 'href': doc.metadata['source'], 'score': doc.metadata['score']} for doc in# documents]content = '\n\n'.join([doc.page_content for doc in documents])prompt = f"""请将下面这段内容(<<<content>>><<</content>>>包裹的部分)进行总结:<<<content>>>{content}<<</content>>>"""print('prompt:')print(prompt)return model.invoke(prompt).content# 自定义天气查询工具
def get_current_weather(city):import requestsfrom datetime import datetimeurl = f'https://restapi.amap.com/v3/config/district?keywords={city}&key={amap_api_key}'resp = requests.get(url)# print('行政区划:')# print(resp.json())adcode = resp.json()['districts'][0]['adcode']# adcode = '110000'url = f'https://restapi.amap.com/v3/weather/weatherInfo?city={adcode}&key={amap_api_key}&extensions=base'resp = requests.get(url)"""样例数据{'province': '北京','city': '北京市','adcode': '110000','weather': '晴','temperature': '26','winddirection': '西北','windpower': '4','humidity': '20','reporttime': '2024-05-26 13:38:38','temperature_float': '26.0','humidity_float': '20.0'}"""# print('天气:')# print(resp.json())weather_json = resp.json()['lives'][0]return f"{weather_json['city']}{datetime.strptime(weather_json['reporttime'], '%Y-%m-%d %H:%M:%S').strftime('%m月%d日')}{weather_json['weather']},气温{weather_json['temperature']}摄氏度,{weather_json['winddirection']}风{weather_json['windpower']}级"# 工具映射列表
fn_map = {'get_current_weather': get_current_weather,'search_web': search_web
}4.2 绑定工具
使用下面的语句,将自定义的函数,绑定到大语言模型上
llm_with_tool = model.bind_tools(tools=[{"name": "get_current_weather","description": "根据城市名获取天气","parameters": {"type": "object","properties": {"city": {"type": "string","description": "城市名,例如北京"}},"required": ["city"]}},{"name": "search_web","description": "搜索互联网","parameters": {"type": "object","properties": {"query": {"type": "string","description": "要搜素的内容"}},"required": ["query"]}},],#function_call={"name": "get_current_weather"}
)
5. 使用工具
5.1 天气查询
# 基于大模型获取调用工具及相关参数
import json
ai_msg = llm_with_tool.invoke("北京今天的天气怎么样")
kwargs = json.loads(ai_msg.additional_kwargs['function_call']['arguments'])
print(kwargs)# 调用自定义函数,获得返回结果
res = fn_map[ai_msg.additional_kwargs['function_call']['name']](**kwargs)
print(res)
5.2 网络搜索
输入比较新的内容后,大语言模型会自动判断使用网络搜索工具
# 基于大模型获取调用工具及相关参数
ai_msg = llm_with_tool.invoke("庆余年2好看吗")
kwargs = json.loads(ai_msg.additional_kwargs['function_call']['arguments'])
print(kwargs)# 调用自定义函数,获得返回结果【API获取问题未试验】
#res = fn_map[ai_msg.additional_kwargs['function_call']['name']](**kwargs)#
#print(res)
6. 结构化数据分析
在此处使用函数调用做的一件有用的事情是以结构化格式从给定输入中提取属性:
# 结构化信息提取
from langchain_core.prompts import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field# 结构化的返回信息,基于该模型生成JSON
class Person(BaseModel):name: str = Field(description="The person's name", required=True)height: float = Field(description="The person's height", required=True)hair_color: str = Field(description="The person's hair color")# Prompt template
prompt = PromptTemplate.from_template("""Alex is 5 feet tall. Claudia is 1 feet taller than Alex and jumps higher than him. Claudia is a brunette and Alex is blonde.Human: {question}AI: """)# Chain
llm = OllamaFunctions(model='qwen:14b', base_url='http://192.2.22.55:11434', format='json',temperature=0)
structured_llm = llm.with_structured_output(Person)
chain01 = prompt | structured_llm
alex = chain01.invoke("Describe Alex")
print(alex)
- 注意对于英文理解,这里不推荐使用qwen14b,推荐使用llama3等模型
参考资料:
https://blog.csdn.net/engchina/article/details/138006370
https://zhuanlan.zhihu.com/p/701616275
相关文章:

Ollama: 使用Langchain的OllamaFunctions
1. 引言 Function call Langchain的Ollama 的实验性包装器OllamaFunctions,提供与 OpenAI Functions 相同的 API。因为网络的原因,OpenAI Functions不一定能访问,但如果能通过Ollama部署的本地模型实现相关的函数调用,还是有很好…...

java质数的判断 C语言指针变量的使用
1. public static void main(String[] args) {Scanner scnew Scanner(System.in);System.out.println("请输入一个值");int num sc.nextInt();boolean flagtrue;for (int i2;i<num;i){if (num%i0){flagfalse;break;}}if (flag){System.out.println(num"是一…...

TensorFlow面试整理-TensorFlow 数据处理
在 TensorFlow 中,数据处理是构建和训练深度学习模型的重要环节。高效地管理、预处理和增强数据可以显著提高模型的训练效率和性能。TensorFlow 提供了强大的 tf.data API 来帮助处理各种数据集。下面是 TensorFlow 数据处理的详细介绍: 1. tf.data.Dataset API tf.data API …...

vue路由的基本使用
vue路由的基本使用 vue-router简介一、路由配置和使用1、安装2、创建路由实例2、在组件中引用路由 router-view ,如APP根组件中直接引用:3、最后还需要把路由挂载到APP实例中,在main.js中注册路由: 二、路由重定向与别名三、声明式导航1、传统…...

数据结构分类
数据结构(data structure)是计算机存储、组织数据的方式,是带有结构特性的数据元素的集合。是相互之间存在一种或多种特定关系的数据元素的集合,即带“结构”的数据元素的集合。这种“结构”指的是数据元素之间存在的关系,分为逻辑结构和存储…...

【STM32】 TCP/IP通信协议--LwIP介绍
LwIP(Lightweight IP)是一个轻量级的TCP/IP协议栈,专为嵌入式系统设计,以较小的资源消耗实现完整的网络功能。本文将详细介绍LwIP的基本概念、特点、与TCP/IP的区别以及如何在STM32上使用LwIP实现TCP/IP通信。 1. LwIP的定义和设…...

一些面试题整理
第一章、基础 以下是对上述10道面试题的参考答案: 一、Java语言及性能调优 答案: 线程安全问题是指多个线程同时访问共享资源时可能出现的数据不一致或错误的情况。例如,多个线程同时对一个共享变量进行写操作,如果没有适当的同…...

端口号和ip地址一样吗?区别是什么
在网络通信的世界里,端口号和IP地址是两个不可或缺的概念,它们各自扮演着独特的角色,共同维系着数据在网络中的有序传输。然而,对于许多初学者而言,这两者往往容易被混淆,认为它们是同一事物的不同表述。那…...

深入探讨全流量回溯分析与网络性能监控系统
AnaTraf 网络性能监控系统NPM | 全流量回溯分析 | 网络故障排除工具 随着数据量的急剧增加,传统的网络监控手段面临诸多挑战。在此背景下,全流量回溯分析和网络性能监控系统成为了保障网络正常运作的重要工具。本文将围绕这两个关键词,探讨它…...

python机器人编程——一种3D骨架动画逆解算法的启示(上)
目录 一、前言二、fabrik 算法三、python实现结论PS.扩展阅读ps1.六自由度机器人相关文章资源ps2.四轴机器相关文章资源ps3.移动小车相关文章资源ps3.wifi小车控制相关文章资源 一、前言 我们用blender等3D动画软件时,会用到骨骼的动画,通过逆向IK动力学…...

Flutter开发者必备面试问题与答案02
Flutter开发者必备面试问题与答案02 视频 https://youtu.be/XYSxTb0iA9I https://www.bilibili.com/video/BV1Zk2dYyEBr/ 前言 原文 Flutter 完整面试问题及答案02 本文是 flutter 面试问题的第二讲,高频问答 10 题。 正文 11. PageRoute 是什么? …...

拥抱真实:深度思考之路,行动力的源泉
在纷繁复杂的现代社会,人们往往被表象迷惑,忙碌于各种事务之中,却很少停下来进行深度思考。这种忙碌往往是表面的、无效的,因为它缺乏对自我和目标的深刻理解与追求。提升行动力,避免假勤奋,关键在于深度思…...

【Python爬虫实战】深入理解Python异步编程:从协程基础到高效爬虫实现
#1024程序员节|征文# 🌈个人主页:易辰君-CSDN博客 🔥 系列专栏:https://blog.csdn.net/2401_86688088/category_12797772.html 目录 前言 一、异步 (一)核心概念 (二)…...

OpenCV图像处理方法:腐蚀操作
腐蚀操作 前提 图像数据为二值的(黑/白) 作用 去掉图片中字上的毛刺 显示图片 读取一个图像文件,并在一个窗口中显示它。用户可以查看这个图像,直到按下任意键,然后程序会关闭显示图像的窗口 # cv2是OpenCV库的P…...

PG数据库之流复制详解
一、流复制的定义 PostgreSQL流复制(Streaming Replication)是一种数据复制技术,它允许实时传输数据更改,从而在主服务器和一个或多个备用服务器之间保持数据同步。流复制是PostgreSQL数据库管理系统(DBMS)…...

Python酷库之旅-第三方库Pandas(174)
目录 一、用法精讲 801、pandas.Categorical类 801-1、语法 801-2、参数 801-3、功能 801-4、返回值 801-5、说明 801-6、用法 801-6-1、数据准备 801-6-2、代码示例 801-6-3、结果输出 802、pandas.Categorical.from_codes方法 802-1、语法 802-2、参数 802-3、…...

【Linux网络】基于TCP的全连接队列与文件、套接字、内核之间的关系
W...Y的主页 😊 代码仓库管理💕 前言:之前我们已经学习了TCP传输协议,而无论是TCP还是UDP都是使用socket套接字进行网络传输的,而TCP的socket是比UDP复杂的,当时我们学习TCPsocket编程时使用listen函数进行…...
)
IDE(集成开发环境)
IDE(集成开发环境)是软件开发过程中不可或缺的工具,它集成了代码编写功能、分析功能、编译器、调试器等开发工具,旨在提高开发效率。不同的IDE支持不同的语言和框架,下面是一些通用的IDE使用技巧和插件推荐,…...
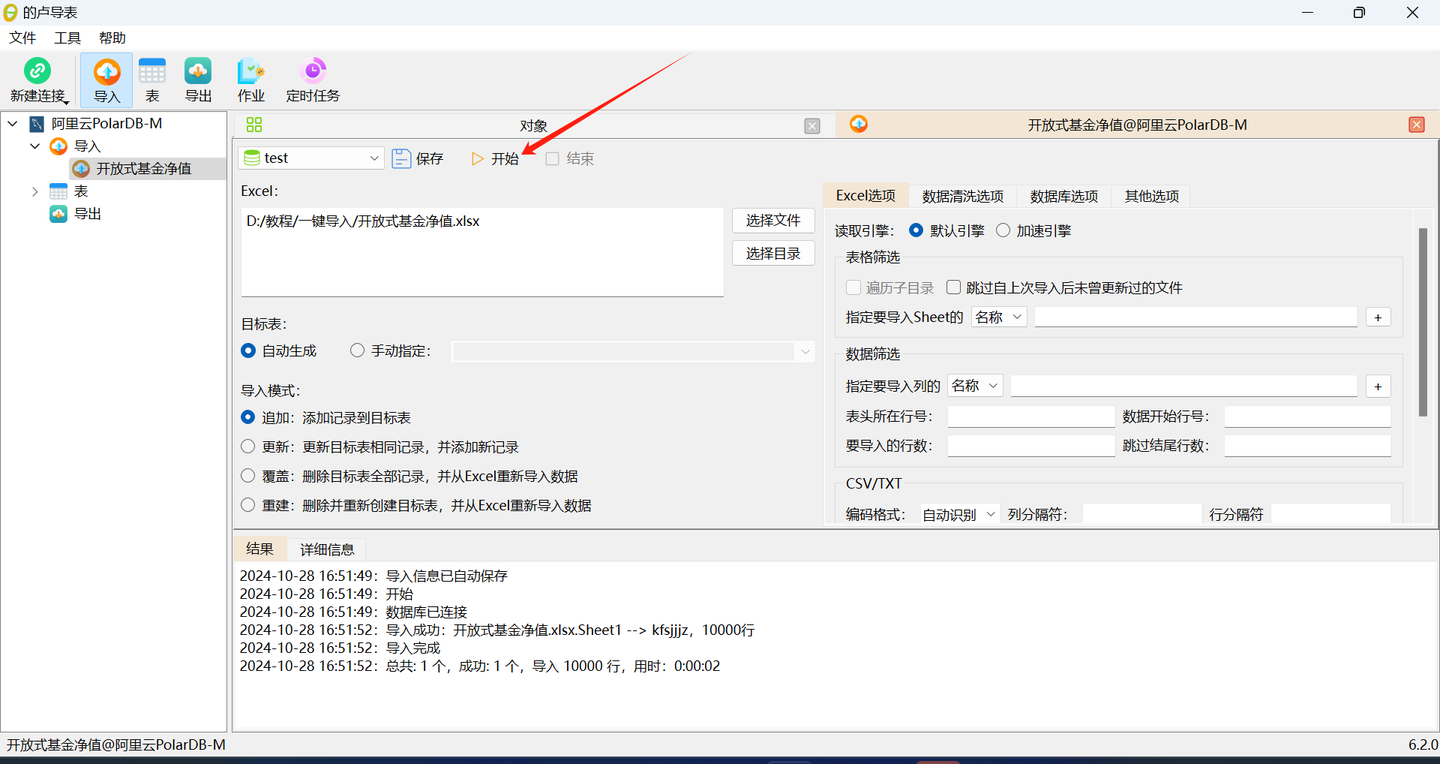
一键导入Excel到阿里云PolarDB-MySQL版
今天,我将分享如何一键导入Excel到阿里云PolarDB-MySQL版数据库。 准备数据 这里,我们准备了一张excel表格如下: 连接到阿里云PolarDB 打开的卢导表,点击新建连接-选择阿里云PolarDB-MySQL版。如果你还没有这个工具,…...

Oracle有哪些版本
目录 Oracle 1(1979年) Oracle 2(1983年) Oracle 7(1992年) Oracle 8i(1999年) Oracle 9i(2001年) Oracle 10g(2004年) Oracle 11g(2007年) Oracle 12c(2013年) Oracle 18c(2018年) Oracle 19c(2019年) Oracle 21c(2023年) Oracle 23ai(202…...

HiveWE:现代化魔兽争霸III地图编辑器完全指南
HiveWE:现代化魔兽争霸III地图编辑器完全指南 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版地图编辑器缓慢的加载速度和复杂的操作而烦恼吗?HiveWE作为一款专…...

Java 资源释放与堆外内存管理机制演进分析
在 Java 虚拟机(JVM)的内存管理模型中,垃圾收集器(GC)仅负责回收 JVM 堆内存(Heap Memory)中不可达对象所占用的空间。然而,Java 程序在运行过程中必然会涉及到不受 GC 直接控制的外…...
)
手把手教你用PyTorch 0.4.1复现D-LinkNet道路分割(附完整代码与数据集)
从零复现D-LinkNet道路分割:PyTorch 0.4.1实战指南 当你在GitHub上发现一个两年前的热门道路分割项目D-LinkNet,却发现它依赖PyTorch 0.4.1和CUDA 8.0这种"古董级"环境时,是否感到无从下手?本文将带你穿越时空…...
:92%开发者踩过的5类语音延迟/断连/语义失准陷阱)
ElevenLabs IVR语音制作避坑手册(2024最新版):92%开发者踩过的5类语音延迟/断连/语义失准陷阱
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs IVR语音制作避坑手册导论 在构建高可用、高自然度的智能语音应答(IVR)系统时,ElevenLabs 以其超拟真语音合成能力成为热门选择。然而,其 API …...

手把手教你用UE5 C++复刻《只狼》式动态攀爬:不止于ALS V4的拓展思路
UE5 C实现《只狼》式动态攀爬系统:从ALS V4到次世代交互设计 在动作游戏开发领域,玩家与环境的交互质量往往决定了游戏体验的上限。当《只狼:影逝二度》以其行云流水般的攀爬系统重新定义动作游戏标准时,许多开发者开始思考&#…...

Origin 9 绘图避坑指南:7个高频问题解决,让你的科研图表一次成型
Origin 9 科研绘图实战:7个高频问题深度解析与优化方案 科研绘图是数据可视化的重要环节,而Origin 9作为经典的科学绘图软件,其功能强大但操作细节繁多。许多用户在初次接触或日常使用中常会遇到各种棘手问题,导致绘图效率低下、图…...

FPGA阵列信号处理矩阵算子高性能实现【附代码】
✨ 长期致力于自动驾驶、阵列信号处理、矩阵特征值分解、Jacobi旋转、三角矩阵求逆、序列排序、序列部分排序研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1&…...

Godot行为树框架实战:构建模块化、可复用的游戏AI系统
1. 项目概述:为你的Godot游戏注入灵魂的AI框架 在游戏开发中,给NPC(非玩家角色)赋予“灵魂”一直是个既迷人又头疼的挑战。你肯定不想让敌人像木桩一样站着,或者只会沿着固定路线来回踱步,对吧?…...

别盲目学AI!先搞懂人工智能的3大核心分支,选对方向少走3年弯路
文章目录前言第一大分支:大模型与生成式AI——AI行业的"水电煤"什么是大模型与生成式AI?大模型技术在2026年的发展现状大模型方向的主要岗位和薪资大模型方向的学习路线第二大分支:智能体与多智能体系统——2026年AI行业最大的风口…...

氢燃料电池混合动力能量管理与动力控制【附仿真】
✨ 长期致力于氢燃料电池、能量管理、等效氢耗、变换器、协同控制、永磁同步电机、滑模自抗扰研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)等效氢耗…...