GGD证明推导学习
GGD证明推导学习
这篇文章,建议先看相关的论文。这篇是我读证明的感悟,因此,不会论文的主体内容
首先,给出命题:
DGI的sumary向量是一个常数
给定一个图: G = { X ∈ R N × D , A ∈ R N × N } \mathcal{G}=\{\mathbf{X}\in\mathbb{R}^{N\times D},\mathbf{A}\in\mathbb{R}^{N\times N}\} G={X∈RN×D,A∈RN×N},以及一个GNN编码器 g g g,我们将其嵌入表示为: H = σ ( g ( G ) ) \mathbf{H}=\sigma(g(\mathcal{G})) H=σ(g(G)), σ \sigma σ是非线性激活函数。通过对summary向量s进行激活函数操作,我们可以得到:ReLU,Prelu,LReLU的值为0.5,sigmoid的值为0.62。及:我们可以得到:
$$s=\mathcal{E}I \tag{1}$$注:这个是有详细的理论证明的,但是不是我阅读的主要部分。详细证明见论文的A.1
GGD与DGI的联系
既然我们知道dgi的summary向量s为1了,那我们就可以简化整个dgi的流程:
简化DGI
假如设置 s = ϵ I = I \mathbf{s}=\mathbf{\epsilon}\mathbf{I}=\mathbf{I} s=ϵI=I,定义区分器为 D ( ⋅ ) \mathcal{D}(\cdot) D(⋅),我们就可以重写dgi为:
$$\begin{aligned} \mathcal{L}_{DGI}& =\frac1{2N}(\sum_{i=1}^N\log\mathcal{D}(\mathbf{h}_i,\mathbf{s})+\log(1-\mathcal{D}(\tilde{\mathbf{h}}_i,\mathbf{s}))), \\ &=\frac1{2N}(\sum_{i=1}^N\log(\mathbf{h}_i\cdot\mathbf{s})+\log(1-\tilde{\mathbf{h}_i}\cdot\mathbf{s}))), \\ &=\frac1{2N}(\sum_{i=1}^N\log(sum(\mathbf{h}_i))+\log(1-sum(\tilde{\mathbf{h}}_i))), \end{aligned} \tag{2}$$其中,区分器是: D ( h i , s ) = σ s i g ( h i ⋅ W ⋅ s ) \mathcal{D}(\mathbf{h}_i,\mathbf{s})=\sigma_{sig}(\mathbf{h}_i\cdot\mathbf{W}\cdot\mathbf{s}) D(hi,s)=σsig(hi⋅W⋅s)(这个在代码中,是nn.bilinear(如果代码看到这个,公式就是左侧的区分器)
我们定义 y ^ i = a g g ( h i ) \hat{y}_{i}=agg(\mathbf{h}_{i}) y^i=agg(hi),那么,整个公式可以简化为:
$$\mathcal{L}_{BCE}=-\frac{1}{2N}(\sum_{i=1}^{2N}y_{i}\log\hat{y}_{i}+(1-y_{i})\log(1-\hat{y}_{i})\tag{3}$$DGI中的引理:定义 { H g } g = 1 ∣ H ∣ \{\mathbf{H}^{g}\}_{g=1}^{|\mathbf{H}|} {Hg}g=1∣H∣是一系列从图形中提取到的一系列节点的嵌入, p ( H ) p(\mathbf{H}) p(H), ∣ H ∣ \left|\mathbf{H}\right| ∣H∣是有限数量的元素。 p ( H g ) = p ( H g ′ ) p(\mathbf{H}^{g})=p(\mathbf{H}^{g\prime}) p(Hg)=p(Hg′)。 R R R是readout函数,其将 H g H^g Hg作为输入,summary向量作为输出, s g \mathbf{s}^{g} sg. s g \mathbf{s}^{g} sg遵循边缘分布 p ( s ) p(\mathbf{s}) p(s)。我们可以得到:联合分布 p ( H , s ) p(\mathbf{H},\mathbf{s}) p(H,s)与边缘分布 p ( H ) p ( s ) ˉ p(\mathbf{H})\bar{p(\mathbf{s})} p(H)p(s)ˉ之间最佳分类器错误率的上界是: E r ∗ = 1 2 ∑ g = 1 ∣ H ∣ p ( s g ) 2 Er^{*}=\frac{1}{2}\sum_{g=1}^{|\mathbf{H}|}p(\mathbf{s}^{g})^{2} Er∗=21∑g=1∣H∣p(sg)2
有公式1我们可以得到s是一个常量summary vector E I \mathcal{E}I EI, E \mathcal{E} E是一个常量。我们可以假设 E \mathcal{E} E独立于 p ( H ) p(H) p(H)(实际上,在本文先前的证明中,我们已经证明 E \mathcal{E} E是常数。其肯定独立于 p ( H ) p(H) p(H))。这样,我们就可以退出lemma2:
lemma2 我们假设s是一个summary vector E I \mathcal{E}I EI, E \mathcal{E} E独立于 p ( H ) p(H) p(H),我们可以得到最优分类器的错误率是: E r ∗ = 1 2 Er^{*}=\frac{1}{2} Er∗=21
其实,很容易理解:现在 E \mathcal{E} E独立于 p ( H ) p(H) p(H),那自然而然, p ( s ) p(\mathbf{s}) p(s)独立于 p ( H ) p(\mathbf{H}) p(H)。这样,预测正确和预测错误都应该为1/2
Theorem 2:给定最佳summary vector s ∗ s^* s∗,其为联合分布和边缘分布的最佳分类器。 s ∗ = a r q m a x s M I ( H ; s ) \mathbf{s}^{*} = arqmax_{\mathbf{s}}MI(\mathbf{H};\mathbf{s}) s∗=arqmaxsMI(H;s)
根据理论2,DGI生成最小化分类器D的分类误差可以被使用于最大化MI在输入和readout函数之间的损失。然而,在上述假设下,错误率是一个常数,最小化分类误差是不切实际的。除此之外,由于s是一个常数vector,因此: M I ( H ; s ) = 0 MI(\mathbf{H};\mathbf{s})=0 MI(H;s)=0
这样,DGI的推理是有问题的。区分器的作用不是最大化 M I ( H ; s ) MI(\mathbf{H};\mathbf{s}) MI(H;s),而是:最大化正嵌入和恒定只要s的相似性和最小化负嵌入和s的相似性。这相当于最大化正嵌入和府前路分布之间的JS偏差。我们给出一个定理来证明这一点:
Theorem 3:假设s是一个常数向量,s独立于 p ( H ) p(H) p(H),给定图 G \mathcal{G} G和扰乱图 G ^ \hat{\mathcal{G}} G^. g θ ( ⋅ ) g_{\theta}(\cdot) gθ(⋅)是GNN编码器。我们考虑正样本嵌入 g θ ( G ) g_{\theta}(\mathcal{G}) gθ(G)为 P p o s h P_{pos}^{\mathbf{h}} Pposh, g θ ( G ~ ) a s P n e g h g_{\theta}(\tilde{\mathcal{G}}) as P_{neg}^{\mathbf{h}} gθ(G~)asPnegh,优化DGI实质上是优化 P p o s h ^ 和 P n e g h ^ P_{pos}^{\mathbf{\hat{h}}} 和 P_{neg}^{\mathbf{\hat{h}}} Pposh^和Pnegh^JS散度,其中 h ^ \hat{h} h^是现行变换后的向量。
证明:首先,我们对DGI进行变换
$$\begin{aligned} \text{L}& =\mathbb{E}_{\mathbf{h}\sim P_{pos}^{\mathbf{h}}}log\mathcal{D}(\mathbf{h},\mathbf{s})+\mathbb{E}_{\mathbf{h}\sim P_{neg}^{\mathbf{h}}}log(1-\mathcal{D}(\mathbf{h},\mathbf{s})), \\ &=\mathbb{E}_{\mathbf{h}\sim P_{pos}^{\mathbf{h}}}log(\mathbf{h}\cdot\mathbf{W}\cdot\mathbf{s})+\mathbb{E}_{\mathbf{h}\sim P_{neg}^{\mathbf{h}}}log(1-\mathbf{h}\cdot\mathbf{W}\cdot\mathbf{s}), \\ &=\mathbb{E}_{\mathbf{h}\sim P_{\infty}^{\mathbf{h}}}log(\mathbf{h}\cdot\mathbf{W}\cdot\epsilon)+\mathbb{E}_{\mathbf{h}\sim P_{\infty}^{\mathbf{h}}}log(1-\mathbf{h}\cdot\mathbf{W}\cdot\epsilon), \end{aligned}$$h是节点嵌入,W是可学习的权重。在这里,我们将 h ⋅ W \mathbf{h}\cdot\mathbf{W} h⋅W视为 h ^ \hat{h} h^。正样本采样为 P h ^ p o s P^{\hat{\mathbf{h}}_{pos}} Ph^pos,负样本采样为: p h ^ p o s p^{\hat{\mathbf{h}}_{pos}} ph^pos。这样,公式就可以重写为:
$$\mathcal{L}=\mathbb{E}_{\hat{\mathbf{h}}\sim P_{pos}^{\hat{\mathbf{h}}}}log(sum(\epsilon\hat{\mathbf{h}}))+\mathbb{E}_{\hat{\mathbf{h}}\sim P_{neg}^{\hat{\mathbf{h}}}}log(1-sum(\epsilon\hat{\mathbf{h}})),\\=\mathbb{E}_{\hat{\mathbf{h}}\sim P_{pos}^{\hat{\mathbf{h}}}}log(\epsilon\cdot agg(\hat{\mathbf{h}}))+\mathbb{E}_{\hat{\mathbf{h}}\sim P_{neg}^{\hat{\mathbf{h}}}}log(1-\epsilon\cdot agg(\hat{\mathbf{h}})),$$a g g ( ⋅ ) agg(\cdot) agg(⋅)是sum函数
Theorem 3的详细证明:
(理论推导受到了gan的启发)
$$\begin{aligned}\mathcal{L}&=\mathbb{E}_{\mathbf{h}\thicksim P_{pos}}log(agg(\mathbf{h}))+\mathbb{E}_{\mathbf{h}\thicksim P_{neg}}log(1-agg(\mathbf{h})),\\&=\int_\mathbf{h}P_{pos}(\mathbf{h})log(agg(\mathbf{h}))d\mathbf{h}+\int_\mathbf{h}P_{neg}(\mathbf{h})log(1-agg(\mathbf{h}))d\mathbf{h},\end{aligned}$$agg是aggregation函数。 P p o s P_{pos} Ppos是正样本的分布, P n e g P_{neg} Pneg是负样本的分布。优化损失函数,我们可以得到 a g g ( h ) agg(h) agg(h)的最优解为: P p o s ( h ) P p o s ( h ) + P n e g ( h ) \frac{P_{pos}(\mathbf{h})}{P_{pos}(\mathbf{h})+P_{neg}(\mathbf{h})} Ppos(h)+Pneg(h)Ppos(h)。这是因为 a l o g ( x ) + b l o g ( 1 − x ) alog(x)+blog(1-x) alog(x)+blog(1−x)在 x = a a + b x=\frac a{a+b} x=a+ba处得到最优解。通过取代 a g g ( h ) agg(\mathbf{h}) agg(h)为: P p o s ( h ) P p o s ( h ) + P n e g ( h ) \frac{P_{pos}(\mathbf{h})}{P_{pos}(\mathbf{h})+P_{neg}(\mathbf{h})} Ppos(h)+Pneg(h)Ppos(h),上述公式可以转换为:
$$\mathcal{L}=\mathbb{E}_{\mathbf{h}\thicksim P_{pos}}log(\frac{P_{pos}(\mathbf{h})}{P_{pos}(\mathbf{h})+P_{neg}(\mathbf{h})})+\mathbb{E}_{\mathbf{h}\thicksim P_{neg}}log(1-\frac{P_{pos}(\mathbf{h})}{P_{pos}(\mathbf{h})+P_{neg}(\mathbf{h})}),\\=\mathbb{E}_{\mathbf{h}\thicksim P_{pos}}log(\frac{P_{pos}(\mathbf{h})}{P_{pos}(\mathbf{h})+P_{neg}(\mathbf{h})})+\mathbb{E}_{\mathbf{h}\thicksim P_{neg}}log(\frac{P_{neg}(\mathbf{h})}{P_{pos}(\mathbf{h})+P_{neg}(\mathbf{h})}).$$我们发现,其和JS散度很相似:
$$JS(P_1\parallel P_2)=\frac12\mathbb{E}_{\mathbf{h}\thicksim P_1}log(\frac{\frac{P_1}{P_1+P_2}}2)+\frac12\mathbb{E}_{\mathbf{h}\thicksim P_2}log(\frac{\frac{P_2}{P_1+P_2}}2).$$这样,我们可以重写公式为:
$$\begin{aligned}\mathcal{L}&=\mathbb{E}_{\mathbf{h}\sim P_{pos}}log(\frac{\frac{P_{pos}(\mathbf{h})}{P_{pos}(\mathbf{h})+P_{neg}(\mathbf{h})}}2)+\mathbb{E}_{\mathbf{h}\sim P_{neg}}log(\frac{\frac{P_{neg}(\mathbf{h})}{P_{pos}(\mathbf{h})+P_{neg}(\mathbf{h})}}2)-2log2,\\&=2JS(P_{pos}\parallel P_{neg})-2log2,\end{aligned}$$因此,最优化L相当于优化JS散度 J S ( P p o s ∥ P n e g ) JS(P_{pos}\parallel P_{neg}) JS(Ppos∥Pneg)
相关文章:

GGD证明推导学习
GGD证明推导学习 这篇文章,建议先看相关的论文。这篇是我读证明的感悟,因此,不会论文的主体内容 首先,给出命题: DGI的sumary向量是一个常数 给定一个图: G { X ∈ R N D , A ∈ R N N } \mathcal{G…...

Flink难点和高频考点:Flink的反压产生原因、排查思路、优化措施和监控方法
目录 反压定义 反压影响 WebUI监控 Metrics指标 backPressureTimeMsPerSecond idleTimeMsPerSecond busyTimeMsPerSecond 反压可视化 资源优化 算子优化 数据倾斜优化 复杂算子优化 背压机制 反压预防 性能调优 内置工具 第三方工具 反压定义 在探讨Flink的性…...

Swarm - Agent 编排工具
文章目录 一、关于 Swarm(实验性、教育性)为什么选择蜂群文档 二、安装使用安装基本用法其它示例 三、Running Swarmclient.run()ArgumentsResponse字段 四、AgentFields Agent指令函数切换和更新上下文变量函数模式 流媒体评估工具 一、关于 Swarm&…...

使用Python中的jieba库进行简单情感分析
在自然语言处理(NLP)领域,情感分析是一项重要的任务,它可以帮助我们理解文本背后的情感倾向。本文将通过一个简单的例子来介绍如何使用Python的jieba库对中文文本进行基本的情感分析。 1. 环境准备 首先,确保已经安装…...

`pip` 下载速度慢
pip 下载速度慢(例如只有 50KB/s)可能由多个因素导致,以下是一些常见原因和解决方法: 1. 使用国内镜像源 国内访问 PyPI 服务器可能会较慢,您可以通过配置国内镜像源来提升下载速度。以下是一些常用的国内镜像源&…...

【WRF数据准备】基于GEE下载静态地理数据-叶面积指数LAI及绿色植被率Fpar
【WRF数据准备】基于GEE下载静态地理数据 准备:WRF所需静态地理数据(Static geographical data)数据范围说明基于GEE下载叶面积指数及绿色植被率GEE数据集介绍数据下载:LAI(叶面积指数)和Fpar(绿色植被率)数据处理:基于Python处理为单波段LAI数据参考GEE的介绍可参见另…...

网管平台(进阶篇):网管软件的配置方式
正确选择网管软件配置方式对于确保网络运行的高效性、稳定性和安全性至关重要,因为它直接影响到网络管理的灵活性、监控的深度以及故障响应的速度,从而保障整体网络环境的顺畅运行和业务连续性。下面我们就分别介绍一下。 一、集中式网络管理配置 在集…...

推荐系统中的AB测试
在现代互联网平台中,推荐系统起着至关重要的作用,无论是视频平台、社交网络还是电商网站,推荐系统都能够帮助用户找到最感兴趣的内容。为了不断优化推荐效果,AB测试(A/B Testing)作为评估新算法或功能改进的…...
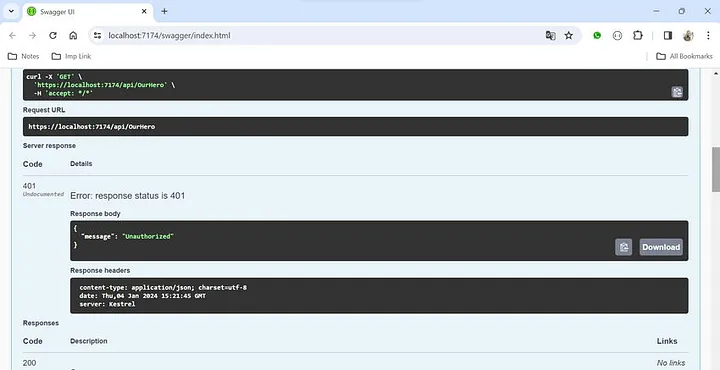
.NET 8 Web API 中的身份验证和授权
本次介绍分为3篇文章: 1:.Net 8 Web API CRUD 操作.Net 8 Web API CRUD 操作-CSDN博客 2:在 .Net 8 API 中实现 Entity Framework 的 Code First 方法https://blog.csdn.net/hefeng_aspnet/article/details/143229912 3:.NET …...

Vue弹窗用也可以直接调用Js方法了
问题描述 在前端开发中,弹窗开发是一个不可避免的场景。然而,按照正常的逻辑,通过在template模板中先引用组件,然后通过v-if指令控制显隐,进而达到弹窗的效果。然而,这种方法却有一个严重的缺陷࿰…...

【c语言测试】
1. C语言中,逻辑“真”等价于( ) 题目分析: “逻辑真”在C语言中通常指的是非零数。 A. 大于零的数B. 大于零的整数C. 非零的数 (正确答案)D. 非零的整数 正确答案:C 2. 若定义了数组 int a[3][4];,则对…...

一种将树莓派打造为游戏机的方法——Lakka
什么是Lakka? Lakka是一款Linux发行版,轻量级的,可将小型计算机转变为一台复古游戏机。 图1-Lakka官网,见参考链接[1] Lakka是RetroArch和libretro生态系统下的官方操作系统,前者RetroArch是模拟器、游戏引擎和媒体播…...

如何在 MySQL 中创建一个完整的数据库备份?
在MySQL数据库中创建一个完整的数据库备份通常不是通过编程语言直接实现的,而是借助MySQL提供的命令行工具mysqldump来完成。 作为Java开发者,我们可以编写脚本来调用这些工具,从而实现自动化备份。 下面我们将详细介绍如何使用Java来调度m…...

京准电钟HR-901GB双GPS北斗卫星时钟服务器
京准电钟HR-901GB双GPS北斗卫星时钟服务器 京准电钟HR-901GB双GPS北斗卫星时钟服务器 作为国家电力系统最重要的设备之一,卫星时间同步装置随着电力行业的发展不断有了新的要求,从单纯的具备时间数据输出能力,发展到装置状态信息上送、对用时设备的对时质量进行监测,确保站点内…...

uniapp使用websocket
后端java websoket中的 onOpen 中。依赖注入为null 引用:https://blog.csdn.net/qq_63431773/article/details/132389555 https://blog.csdn.net/weixin_43961117/article/details/123989515 https://cloud.tencent.com/developer/article/2107954 https://blog.c…...

基于Pycharm和Django模型技术的数据迁移
1.配置数据库 在trip_server/settings.py中修改配置: 其格式可访问官网:Settings | Django documentation | Django 1.1 配置数据库 文件地址:trip_server/settings.py 配置前需要创建(NaviCat)个人数据库 "…...

乐尚代驾-----Day10(订单三)
hi UU 们!!!我又来跟辛辣!感谢你们的观看,话不多说!~ 司机到达代驾终点,代驾结束了。结束代驾之后, – 获取额外费用(高速费、停车费等) – 计算订单实际里程…...

105. 聚光源SpotLight
入门部分给大家介绍过平行光DirectionalLight、点光源PointLight、环境光AmbientLight,下面给大家介绍一个新的光源对象,也就是聚光源SpotLight。 创建聚光源SpotLight 聚光源可以认为是一个沿着特定方会逐渐发散的光源,照射范围在三维空间中构成一个圆…...

系统接口权限拦截器,获取用户信息存储
UserInfo 类 这是一个表示用户信息的 Java 类,使用了 Lombok 注解来简化代码编写。 import lombok.Data; import lombok.EqualsAndHashCode; import lombok.ToString;import java.io.Serializable; import java.util.List;Data ToString EqualsAndHashCode public…...

Chromium HTML5 新的 Input 类型color 对应c++
一、Input 类型: color color 类型用在input字段主要用于选取颜色,如下所示: <!DOCTYPE html> <html> <head> <meta charset"utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body&…...

AGENTS.md:为AI编码助手定制的项目说明书,提升人机协作效率
1. 项目概述:为什么你的项目需要一个“AI专属说明书”?如果你最近在尝试用GitHub Copilot、Cursor或者Claude Code来辅助开发,大概率遇到过这样的场景:你满怀期待地给AI下达一个指令,比如“帮我给这个React组件添加一个…...

Display Driver Uninstaller:Windows显卡驱动终极清理方案
Display Driver Uninstaller:Windows显卡驱动终极清理方案 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-uninstal…...

物联网隐私工程:从数据生命周期到安全设计实践
1. 物联网隐私困境:一个被误解的工程问题每次和同行聊起物联网项目,大家最头疼的往往是协议选型、功耗优化或者成本控制。至于隐私?那通常是产品经理或者法务部门在项目后期才想起来要填的“合规表格”。我自己在早期做智能家居网关时也犯过同…...

别再被Excel文件‘炸’了!手把手教你用ZipSecureFile.setMinInflateRatio解决Apache POI的Zip Bomb报错
深度解析Apache POI的Zip Bomb防护机制与安全实践 当Java开发者使用Apache POI处理用户上传的Excel文件时,可能会突然遭遇"Zip bomb detected!"的报错。这个看似简单的错误背后,实际上涉及文件安全检测、内存防护和系统稳定性等多重考量。本文…...

nlpcda高级配置:如何自定义词典和扩展同义词表
nlpcda高级配置:如何自定义词典和扩展同义词表 【免费下载链接】nlpcda 一键中文数据增强包 ; NLP数据增强、bert数据增强、EDA:pip install nlpcda 项目地址: https://gitcode.com/gh_mirrors/nl/nlpcda nlpcda是一款强大的中文数据增…...

10个必备的Solidity安全技巧:Secureum-mind_map实践经验分享
10个必备的Solidity安全技巧:Secureum-mind_map实践经验分享 【免费下载链接】secureum-mind_map Central Repository for the Epoch 0 coursework and quizzes. Contains all the content, cross-referenced and linked. 项目地址: https://gitcode.com/gh_mirr…...

开发者知识管理工具CodingIT:架构设计与应用实践
1. 项目概述:一个面向开发者的“一站式”知识管理工具最近在整理个人技术笔记和项目文档时,我发现自己陷入了典型的“信息碎片化”困境:代码片段散落在Gist、笔记软件、本地文件甚至聊天记录里;项目文档要么是简陋的README&#x…...

dotfiles工程化:用Git与符号链接打造可移植的开发环境
1. 项目概述:dotfiles 是什么,以及为什么你需要它如果你在终端里敲命令的时间超过了你用鼠标点来点去的时间,那你大概率已经听说过dotfiles了。简单来说,dotfiles就是你系统里那些以点(.)开头的配置文件&am…...

3个步骤掌握APK Installer:在Windows上直接安装Android应用的终极指南
3个步骤掌握APK Installer:在Windows上直接安装Android应用的终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否厌倦了在Windows电脑上使用笨重…...
:新手也能快速上手,高效搞定会议纪要)
腾讯会议AI助手使用教程(附避坑指南):新手也能快速上手,高效搞定会议纪要
【前言】最近腾讯会议AI助手彻底火了,身边不少程序员、职场人都在使用,都说“再也不用熬夜整理会议纪要了”。但很多新手第一次使用,会遇到“不知道怎么开启”“转写准确率低”“不会导出总结”等问题。今天就给大家带来一份详细的腾讯会议AI…...