使用AMD GPU和LangChain构建问答聊天机器人
Question-answering Chatbot with LangChain on an AMD GPU — ROCm Blogs

作者:Phillip Dang 2024年3月11日
LangChain是一个旨在利用语言模型强大功能来构建前沿应用程序的框架。通过将语言模型连接到各种上下文资源并基于给定的上下文提供推理能力,LangChain创建了能够智能推理和响应的上下文感知应用程序。在这篇博客中,我们演示了如何使用LangChain和Hugging Face来创建一个简单的问答聊天机器人。我们还展示了如何使用检索增强生成(RAG)技术来增强我们的大型语言模型(LLM)知识,然后允许我们的机器人根据指定文档中的信息来回答查询。
前提条件
要运行本文中的内容,你需要以下条件:
-
AMD GPUs: AMD Instinct GPU.
-
Linux: see the supported Linux distributions.
-
ROCm 6.0+
-
PyTorch
-
或者,你可以启动一个包含以上设置的 Docker 容器,将
/YOUR/FOLDER替换成你选择的目录,它将挂载到 Docker 根目录。下面是一个使用 ROCm 6.2 和 PyTorch 2.3 的示例:docker run -it --group-add=video --ipc=host --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --device /dev/kfd --device=/dev/dri -v /YOUR/FOLDER:/root rocm/pytorch:rocm6.2_ubuntu22.04_py3.10_pytorch_release_2.3.0
为了检查你的硬件并确保系统识别你的 GPU,请运行:
! rocm-smi --showproductname
你的输出应该如下所示:
================= ROCm System Management Interface ================ ========================= Product Info ============================ GPU[0] : Card series: Instinct MI210 GPU[0] : Card model: 0x0c34 GPU[0] : Card vendor: Advanced Micro Devices, Inc. [AMD/ATI] GPU[0] : Card SKU: D67301 =================================================================== ===================== End of ROCm SMI Log =========================
接下来,确保 PyTorch 检测到你的 GPU:
import torch
print(f"number of GPUs: {torch.cuda.device_count()}")
print([torch.cuda.get_device_name(i) for i in range(torch.cuda.device_count())])
你的输出应该如下所示:
number of GPUs: 1 ['AMD Radeon Graphics']
库
要构建一个能够与文档聊天的聊天机器人,你将需要以下三个工具:
-
LangChain
-
一个语言模型
-
使用 Facebook AI 相似性搜索 (FAISS) 的 RAG
LangChain
LangChain 作为一个框架,用于创建由语言模型驱动的应用程序。它允许应用程序:
-
通过将语言模型与上下文资源(如提示、示例或相关内容)链接来*拥抱上下文性*,以丰富其响应。
-
依靠语言模型根据给定的上下文逻辑地推导答案,并决定采取适当的行动来*进行推理*。
要安装 LangChain,请运行 pip install langchain langchain-community。
语言模型
在本博客中,我们使用Google Flan-T5-large作为我们的底层语言模型。
要安装我们的语言模型并与文档聊天,请运行以下代码:`pip install transformers sentence-transformers`。
带有 FAISS 的 RAG
尽管大规模语言模型(LLM)在各种领域都很智能,但它们的知识仅限于在训练完成时可供其使用的公共信息。如果我们希望模型考虑私有信息或训练后的数据,我们必须自己添加这些额外的信息。这个添加过程叫做RAG,而用于高效检索相关信息的工具是FAISS。
FAISS是一个用于高效相似性搜索和密集向量聚类的库。它广泛用于近邻搜索、相似性匹配以及在大型数据集中的其他相关操作。它帮助我们高效存储新的信息,并根据我们的查询检索最相关的信息块。
要安装FAISS,请运行`pip install faiss-cpu`。
Q&A 聊天机器人
首先,设置您的语言模型。您需要拥有一个Hugging Face API Token。
import os
from langchain import HuggingFaceHub, LLMChain
from langchain.prompts import PromptTemplateos.environ["HUGGINGFACEHUB_API_TOKEN"] = "your Huggingface API Token here"llm = HuggingFaceHub(repo_id="google/flan-t5-large",model_kwargs={'temperature':0.5,'max_length': 512})
一旦您有了您的模型,您可以通过 LangChain 的 LLMChain 来将各组件组合在一起。LLMChain 使用 PromptTemplate 来结构化用户输入,然后将这些输入发送给您的语言模型进行处理。这使得 LLMChain 成为生成连贯语言的有价值工具。
template = """Question: {question}
Answer: Let's think step by step."""prompt = PromptTemplate(template=template, input_variables=["question"])
llm_chain = LLMChain(prompt=prompt, llm=llm)
现在是有趣的部分——让我们向聊天机器人问几个问题:
输入:
question = "What is the capital of Ecuador?" llm_chain.run(question)
输出:
'Quito is the capital city of Ecuador. Quito is located in the north of the country. The answer: Quito.'
输入:
question = "What is GTA? " llm_chain.run(question)
输出:
'GTA is an abbreviation for Grand Theft Auto. GTA is a video game series. The answer: video game series.'
输入:
question = "What are some key advantages of LoRA for LLM?" llm_chain.run(question)
输出:
'LoRA is a centralized repository for all LLM degree work. The LLM degree program at the University of Michigan was the first to use LoRA for their degree program. The University of Michigan School of Law is the first law school in the United States to use LoRA for their degree program.'
最后一个问题的答案是错误的。这可能是因为模型的训练数据中没有包含关于 LoRA 的信息。在下一部分中,我们将通过应用 RAG 技术来解决这个问题。
Q&A 聊天机器人使用 RAG 技术
根据前一节的内容,模型错误地回答了我们关于LoRA技术的问题——这可能是因为在模型训练时没有包含该信息。要解决这个问题,你可以使用RAG技术将信息包含到你的模型中。
RAG工作分为两个阶段:
-
检索阶段:给定一个查询(例如,一个临床问题),模型在大型数据库中搜索相关文档或片段。
-
生成阶段:模型使用检索到的信息生成响应,确保输出基于输入数据,在我们的例子中将是一个PDF。
要看到这点的实际效果,你需要创建两个函数,一个用于处理我们的输入数据(关于LoRA的PDF论文),另一个用于构建我们的知识数据库。
from langchain.vectorstores import FAISS from langchain.text_splitter import CharacterTextSplitter from langchain.embeddings import HuggingFaceEmbeddingsdef process_text(text):# 使用LangChain的CharacterTextSplitter将文本分割成片段text_splitter = CharacterTextSplitter(separator="\n", chunk_size=256, chunk_overlap=64, length_function=len)chunks = text_splitter.split_text(text)# 将文本片段转换为嵌入以形成知识库embeddings = HuggingFaceEmbeddings(model_name='sentence-transformers/all-mpnet-base-v2')knowledgeBase = FAISS.from_texts(chunks, embeddings)return knowledgeBase
import PyPDF2 import requests from io import BytesIO# 阅读PDF论文 pdf_url = "https://arxiv.org/pdf/2106.09685.pdf" response = requests.get(pdf_url) pdf_file = BytesIO(response.content) pdf_reader = PyPDF2.PdfReader(pdf_file)def get_vectorstore():# 从pdf_reader构建向量存储text = ""# 变量text将存储pdf文本for page in pdf_reader.pages:text += page.extract_text()# 创建知识库对象db = process_text(text)return dbdb = get_vectorstore()
现在,通过加载LangChain的Q&A链,搜索知识数据库中最相关的信息,并查看聊天机器人是否能提供更准确的答案来将所有内容结合在一起:
from langchain.chains.question_answering import load_qa_chain # 加载Q&A链 chain = load_qa_chain(llm, chain_type="stuff", prompt=)query = "what are some key advantages of LoRA for LLM?" # 搜索数据库中相关的信息 docs = db.similarity_search(query=query)# 运行我们的链 chain.run(input_documents=docs, question=query)
输出:
'LORA makes training more efficient and lowers the hardware barrier to entry by up to 3 times when using adaptive optimizers since we do not need to calculate the gradients or cantly fewer GPUs and avoid I/O bottlenecks. Another benefit is that we can switch between tasks while deployed at a much lower cost by only swapping the LoRA weights as opposed to all the'
在为我们的模型提供了额外的信息后,更新的答案显然更加相关,通过`input_documents=docs`参数可以实现这一点。
我们建议测试不同的LLM作为基础模型,并尝试用于不同用例的各种LLMChain。我们还鼓励实验不同的处理方法,并细分输入文档以提高相似性搜索的相关性。
相关文章:
使用AMD GPU和LangChain构建问答聊天机器人
Question-answering Chatbot with LangChain on an AMD GPU — ROCm Blogs 作者:Phillip Dang 2024年3月11日 LangChain是一个旨在利用语言模型强大功能来构建前沿应用程序的框架。通过将语言模型连接到各种上下文资源并基于给定的上下文提供推理能力,L…...

2024年808数据结构答案
1.已知带头结点单链表,H为头指针。设计一个算法,查找到链表的第m个结点(不包含头结点),并将元 素值为X的结点插入到该结点后,形成一个新的链表。 // 定义单链表节点结构 typedef struct Node {int data;struct Node* next; } Nod…...

Amazon Linux 2023 安装 Docker
Amazon Linux 2023 安装 Docker 1. 简介 在公司需要将代码部属到 Amazon Linux 2023 系统上时,去 Docker 官方文档里面看也没有针对该系统的部属文档。虽然有通用的 Linux 部属方案但不能应用包管理工具。 首先执行yum、dnf、apt,执行yum和dnf都有正确…...

接口测试(八)jmeter——参数化(CSV Data Set Config)
一、CSV Data Set Config 需求:批量注册5个用户,从CSV文件导入用户数据 1. 【线程组】–>【添加】–>【配置元件】–>【CSV Data Set Config】 2. 【CSV数据文件设置】设置如下 3. 设置线程数为5 4. 运行后查看响应结果...

GGD证明推导学习
GGD证明推导学习 这篇文章,建议先看相关的论文。这篇是我读证明的感悟,因此,不会论文的主体内容 首先,给出命题: DGI的sumary向量是一个常数 给定一个图: G { X ∈ R N D , A ∈ R N N } \mathcal{G…...

Flink难点和高频考点:Flink的反压产生原因、排查思路、优化措施和监控方法
目录 反压定义 反压影响 WebUI监控 Metrics指标 backPressureTimeMsPerSecond idleTimeMsPerSecond busyTimeMsPerSecond 反压可视化 资源优化 算子优化 数据倾斜优化 复杂算子优化 背压机制 反压预防 性能调优 内置工具 第三方工具 反压定义 在探讨Flink的性…...

Swarm - Agent 编排工具
文章目录 一、关于 Swarm(实验性、教育性)为什么选择蜂群文档 二、安装使用安装基本用法其它示例 三、Running Swarmclient.run()ArgumentsResponse字段 四、AgentFields Agent指令函数切换和更新上下文变量函数模式 流媒体评估工具 一、关于 Swarm&…...

使用Python中的jieba库进行简单情感分析
在自然语言处理(NLP)领域,情感分析是一项重要的任务,它可以帮助我们理解文本背后的情感倾向。本文将通过一个简单的例子来介绍如何使用Python的jieba库对中文文本进行基本的情感分析。 1. 环境准备 首先,确保已经安装…...

`pip` 下载速度慢
pip 下载速度慢(例如只有 50KB/s)可能由多个因素导致,以下是一些常见原因和解决方法: 1. 使用国内镜像源 国内访问 PyPI 服务器可能会较慢,您可以通过配置国内镜像源来提升下载速度。以下是一些常用的国内镜像源&…...

【WRF数据准备】基于GEE下载静态地理数据-叶面积指数LAI及绿色植被率Fpar
【WRF数据准备】基于GEE下载静态地理数据 准备:WRF所需静态地理数据(Static geographical data)数据范围说明基于GEE下载叶面积指数及绿色植被率GEE数据集介绍数据下载:LAI(叶面积指数)和Fpar(绿色植被率)数据处理:基于Python处理为单波段LAI数据参考GEE的介绍可参见另…...

网管平台(进阶篇):网管软件的配置方式
正确选择网管软件配置方式对于确保网络运行的高效性、稳定性和安全性至关重要,因为它直接影响到网络管理的灵活性、监控的深度以及故障响应的速度,从而保障整体网络环境的顺畅运行和业务连续性。下面我们就分别介绍一下。 一、集中式网络管理配置 在集…...

推荐系统中的AB测试
在现代互联网平台中,推荐系统起着至关重要的作用,无论是视频平台、社交网络还是电商网站,推荐系统都能够帮助用户找到最感兴趣的内容。为了不断优化推荐效果,AB测试(A/B Testing)作为评估新算法或功能改进的…...
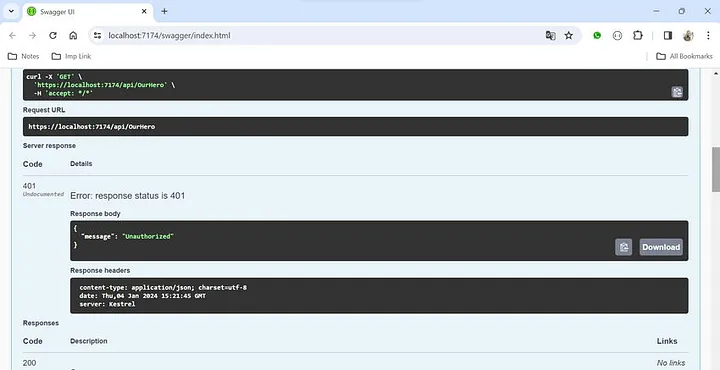
.NET 8 Web API 中的身份验证和授权
本次介绍分为3篇文章: 1:.Net 8 Web API CRUD 操作.Net 8 Web API CRUD 操作-CSDN博客 2:在 .Net 8 API 中实现 Entity Framework 的 Code First 方法https://blog.csdn.net/hefeng_aspnet/article/details/143229912 3:.NET …...

Vue弹窗用也可以直接调用Js方法了
问题描述 在前端开发中,弹窗开发是一个不可避免的场景。然而,按照正常的逻辑,通过在template模板中先引用组件,然后通过v-if指令控制显隐,进而达到弹窗的效果。然而,这种方法却有一个严重的缺陷࿰…...

【c语言测试】
1. C语言中,逻辑“真”等价于( ) 题目分析: “逻辑真”在C语言中通常指的是非零数。 A. 大于零的数B. 大于零的整数C. 非零的数 (正确答案)D. 非零的整数 正确答案:C 2. 若定义了数组 int a[3][4];,则对…...

一种将树莓派打造为游戏机的方法——Lakka
什么是Lakka? Lakka是一款Linux发行版,轻量级的,可将小型计算机转变为一台复古游戏机。 图1-Lakka官网,见参考链接[1] Lakka是RetroArch和libretro生态系统下的官方操作系统,前者RetroArch是模拟器、游戏引擎和媒体播…...

如何在 MySQL 中创建一个完整的数据库备份?
在MySQL数据库中创建一个完整的数据库备份通常不是通过编程语言直接实现的,而是借助MySQL提供的命令行工具mysqldump来完成。 作为Java开发者,我们可以编写脚本来调用这些工具,从而实现自动化备份。 下面我们将详细介绍如何使用Java来调度m…...

京准电钟HR-901GB双GPS北斗卫星时钟服务器
京准电钟HR-901GB双GPS北斗卫星时钟服务器 京准电钟HR-901GB双GPS北斗卫星时钟服务器 作为国家电力系统最重要的设备之一,卫星时间同步装置随着电力行业的发展不断有了新的要求,从单纯的具备时间数据输出能力,发展到装置状态信息上送、对用时设备的对时质量进行监测,确保站点内…...

uniapp使用websocket
后端java websoket中的 onOpen 中。依赖注入为null 引用:https://blog.csdn.net/qq_63431773/article/details/132389555 https://blog.csdn.net/weixin_43961117/article/details/123989515 https://cloud.tencent.com/developer/article/2107954 https://blog.c…...

基于Pycharm和Django模型技术的数据迁移
1.配置数据库 在trip_server/settings.py中修改配置: 其格式可访问官网:Settings | Django documentation | Django 1.1 配置数据库 文件地址:trip_server/settings.py 配置前需要创建(NaviCat)个人数据库 "…...

AI智能体扩展实战:基于MCP协议构建AlterLab工具箱服务器
1. 项目概述:一个为AI智能体打造的“工具箱”服务器最近在折腾AI智能体(Agent)的开发,发现一个挺有意思的项目:RapierCraft/alterlab-mcp-server。简单来说,这是一个实现了模型上下文协议(Model…...

RedBox容器编排工具:在Docker与K8s间的轻量级生产实践
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫Jamailar/RedBox。乍一看这个名字,你可能会联想到一个红色的盒子,或者某种特定的工具。实际上,它确实是一个“盒子”,一个用于构建、管理和部署容器化应用的…...

Sprout OS:为创意工作者打造的Linux开源操作系统部署与优化指南
1. 项目概述:一个为创意工作者量身定制的操作系统如果你是一名设计师、视频剪辑师、音乐制作人或者任何需要高性能计算和稳定创作环境的创意专业人士,那么你肯定对“创作环境”这四个字又爱又恨。爱的是,它是你挥洒才华的舞台;恨的…...

SK海力士晶圆代工战略:特色工艺如何重塑半导体产业格局
1. 韩国半导体雄心:从存储巨头到晶圆代工的野望最近几年,全球半导体产业的新闻头条几乎被台积电、英特尔和三星的千亿美元级投资计划所占据。然而,在2021年5月,一则来自韩国的消息,虽然声量相对较小,却揭示…...
实战:Spring AI 集成向量数据库实现知识问答)
检索增强生成(RAG)实战:Spring AI 集成向量数据库实现知识问答
系列导读 你现在看到的是《Spring AI 企业级集成与场景实践:从零搭建智能应用》的第 4/10 篇,当前这篇会重点解决:从零搭建一个可工作的 RAG 系统,解决 LLM 知识陈旧和幻觉问题。 上一篇回顾:第 3 篇《对话记忆与上下文管理:Spring AI 实现多轮会话与持久化存储》主要聚…...

3大实战场景:PX4无人机视觉定位从零部署到工业级应用
3大实战场景:PX4无人机视觉定位从零部署到工业级应用 【免费下载链接】PX4-Autopilot PX4 Autopilot Software 项目地址: https://gitcode.com/gh_mirrors/px/PX4-Autopilot PX4-Autopilot作为开源无人机飞控的标杆,其视觉定位能力正在重塑自主飞…...

Multi-Agent 落地常见问题:数据质量、模型适配与业务对齐解决方案
Multi-Agent 落地常见问题:数据质量、模型适配与业务对齐解决方案 引言 痛点引入:从「演示天堂」到「生产地狱」的Multi-Agent鸿沟 2023年11月OpenAI DevDay发布的GPT-4o Assistants API、LangChain团队迭代的LangGraph 1.0、Microsoft Research推出的AutoGen Studio 2.0,…...

从测试驱动到需求驱动:芯片验证范式的深度迁移与实践
1. 从“测试驱动”到“需求驱动”:一次验证范式的深度迁移干了十几年芯片验证,从早期的定向测试到后来的约束随机验证,再到覆盖率驱动验证,我亲眼看着这个领域的复杂度像坐火箭一样往上窜。现在一个SoC项目,动辄几亿门…...
)
WinForm弹窗进阶:手把手教你封装一个通用的MessageBoxHelper工具类(.NET Framework/C#)
WinForm弹窗进阶:打造高复用性的MessageBoxHelper工具类 在WinForm开发中,MessageBox.Show()就像空气一样无处不在——从简单的操作确认到复杂的错误处理,这个基础组件承担了太多交互职责。但当你第20次写下MessageBox.Show("操作成功&q…...

从CAD建模到游戏角色动画:深入浅出聊聊B样条曲线在工业与娱乐中的实战应用
从CAD建模到游戏角色动画:B样条曲线的跨领域实战解析 在工业设计与数字娱乐的交汇处,B样条曲线(B-spline Curves)正悄然重塑着两个行业的创作范式。当汽车设计师在Alias中推敲车身曲面时,游戏动画师正在Blender里调整…...