MobileNetv2网络详解
背景:
MobileNet v1中DW卷积在训练完之后部分卷积核会废掉,大部分参数为“0”
MobileNet v2网络是由Google团队在2018年提出的,相比于MobileNet v1网络,准确率更高,模型更小
网络亮点:
Inverted Residuals(倒残差结构)
Linear Bottlenecks
倒残差结构:
Residual Block:
ResNet网络中提出了一种残差结构

1.输入特征矩阵采用1*1的卷积核来对特征矩阵做压缩,减少输入特征矩阵的channel
2.采用3*3的卷积核做卷积处理
3.采用1*1的卷积扩充channel
形成两头大,中间小的瓶颈结构
Inverted Residual Block:

1.采用1*1的卷积核升维,让channel变得更深
2.通过卷积核大小为3*3的DW卷积操作进行卷积
3.通过1*1的卷积进行降维
结构图:

过程:
1.通过大小为1*1的卷积,激活函数为ReLU6
2.通过DW卷积,卷积核大小为3*3,激活函数为ReLU6
3.通过卷积核大小为1*1的卷积处理,使用线性激活

1.h*w*k的输入,经过1*1卷积核、ReLU6(t为扩展因子,1*1卷积核的个数为tk),输出h*w*(tk)
2.第二层输入等于第一层输出,使用DW卷积,卷积核大小为3*3,步距为s(给定),输出的特征矩阵深度和输入特征矩阵的深度相同(MobileNet v1中提到过DW卷积),由于步距为s,输出特征矩阵的高宽缩减为和
3.第三层的1*1卷积为降维操作,所采用的卷积核个数为
ReLU6激活函数:

ReLU激活函数的改进版,诸如此类的改进函数还有很多,类似Leakey ReLU等
在普通的ReLU激活函数中,当输入值小于零,默认全置零;当输入值大于零,不对值进行处理
在ReLU6激活函数中,当输入值小于零,默认全置零;在(0,6)区间,不会改变输入值;当输入值大于“6”,将输入值全部置为“6”
作用:
①避免网络出现激活值过大的情况,稳定训练过程
②适合量化
③保留非线性特征
④提高训练速度
对比:
原始的残差结构是先降维再升维,而倒残差结构是先升维再降维
在普通残差结构中使用的ReLU激活函数,而倒残差结构采用的是ReLU6激活函数
shortcut:
在倒残差结构中,并不是每一个倒残差结构都有shortcut(捷径)分支,在论文中提到当stride=1时有捷径分支,stride=2时没有捷径分支
分析得知上述表达有误:当stride=1且输入特征矩阵与输出特征矩阵shape相同时,才有shortcut连接;若不满足都没有shortcut
倒残差结构的作用:
1. 高效的特征提取:结合深度卷积和逐点卷积,能够有效提取特征,同时减少计算复杂度。
2. 减少梯度消失问题:通过直接将输入特征传递到输出,减轻了深层网络中的梯度消失问题,有助于更快收敛。
3. 灵活的通道扩展:通过设置 expand_ratio,可以灵活调整特征维度,增强模型的表达能力,同时避免不必要的计算。
4. 内存和计算效率:尽管在某些情况下会增加参数量,但整体上,倒残差结构通常能保持相对较低的内存和计算需求,适合在移动设备上运行。
5. 增强非线性变换:通过激活函数,倒残差结构能够引入非线性,使得模型可以学习更复杂的特征关系。
6. 适应性强:能够根据不同任务的需求,调整网络的复杂性和参数设置,适应多种应用场景。
Linear Bottlenecks:
对于倒残差结构的最后一个1*1卷积层,使用线性激活函数而不是ReLU激活函数
线性激活函数使用原因:

在原论文中,作者做了相关实验。输入是二维的矩阵,channel为1,分别采用不同维度的Matrix(矩阵)对其进行变换,变换到一个更高的维度;再使用ReLU激活函数得到输出值;再使用
矩阵的逆矩阵
,将输出矩阵还原为2D特征矩阵
当Matrix 维度为2和3时,通过观察下图可以发现,二维三维的特征矩阵丢失了很多信息

但随着Matrix 的维度不断加深,丢失的信息越来越少

总结:
ReLU激活函数会对低维特征信息造成大量损失,而对于高维特征造成的损失小
倒残差结构为“两边细,中间粗”,在中间时为一个低维特征向量,需要使用线性函数替换ReLU激活函数,避免信息损失
网络结构:

t:扩展因子
c:输出特征矩阵的深度,channel
n:bottleneck(论文中的倒残差结构)重复的次数
s:步距,只代表每一个block(每一个block由一系列bottleneck组成)的第一层bottleneck的步距,其他的步距都为1
![]()
当stride=1时:输入特征矩阵的深度为64,输出特征矩阵的深度为96;若有捷径分支,捷径分支的输出的特征矩阵分支深度为64,但是通过主分支的一系列操作,所输出的深度为96,很明显深度时不同的,无法使用加法操作,也就无法使用shortcut
对于上述提到的block的第一层一定是没有shortcut的,但对于第二层,stride=1(表中的s只针对第一层,其他层的stride=1),输入特征矩阵深度等于上一层输出特征矩阵的深度,为96;输出特征矩阵深度为96,因此在bottleneck第二层输出特征矩阵的shape和输入特征矩阵的shape相同,此时可以使用shortcut分支
在网络的最后一层为一个卷积层,就是一个全连接层,k为分类的个数
性能分析:
图像分类:

准确率,模型参数都有一系列的提升,基本上达到了实时的效果
目标检测:

将MobileNet与SSD联合使用,将SSD中的一些卷积换为DW卷积和PW卷积,相比原始的模型有一些提升,但对比MNet v1却差了一些
总结:
基本实现了在移动设备或嵌入式设备上跑深度学习模型,也将研究和日常生活紧密结合
相关文章:
MobileNetv2网络详解
背景: MobileNet v1中DW卷积在训练完之后部分卷积核会废掉,大部分参数为“0” MobileNet v2网络是由Google团队在2018年提出的,相比于MobileNet v1网络,准确率更高,模型更小 网络亮点: Inverted Residu…...

惊了!大模型连这样的验证码都能读懂_java_识别验证码
最近在看视觉大模型的能力,然后用了某网站的一个验证码试了试,竟然连这样的验证码都能认识,这个有点夸张,尤其是这个9和6颠倒的都能理解,现在的能力已经这么牛了么 具体就是用了通义最新的qwen vl模型spring ai alibab…...
【小白学机器学习26】 极大似然估计,K2检验,logit逻辑回归(对数回归)(未完成----)
目录 1 先从一个例题出来,预期值和现实值的差异怎么评价? 1.1 这样一个问题 1.2 我们的一般分析 1.3 用到的关键点1 1.4 但是差距多远,算是远呢? 2 极大似然估计 2.1 极大似然估计的目的 2.1.1 极大似然估计要解决什么问题…...

【日常记录-Java】SLF4J扫描实现框架的过程
1. 简介 SLF4J(Simple Logging Facade for Java)作为一种简单的门面或抽象,服务于其他各种日志框架,例如JUL、log4j、logback等,核心作用有两项: 提供日志接口;提供获取具体日志对象的方法; 2. 扫描过程 …...

uni-app 获取 android 手机 IMEI码
1、需求来源 最近项目上需要获取手机的IMEI码,并且在更换手机号登录后,需要提示重新更新IMEI码。 2、需求拆分 2.1 获取 IMEI 码 查阅 uni-app 官网发现在android 10 已经无法获取imei码,所以对于这个需求拆分成两种情况。 第一种情况&am…...
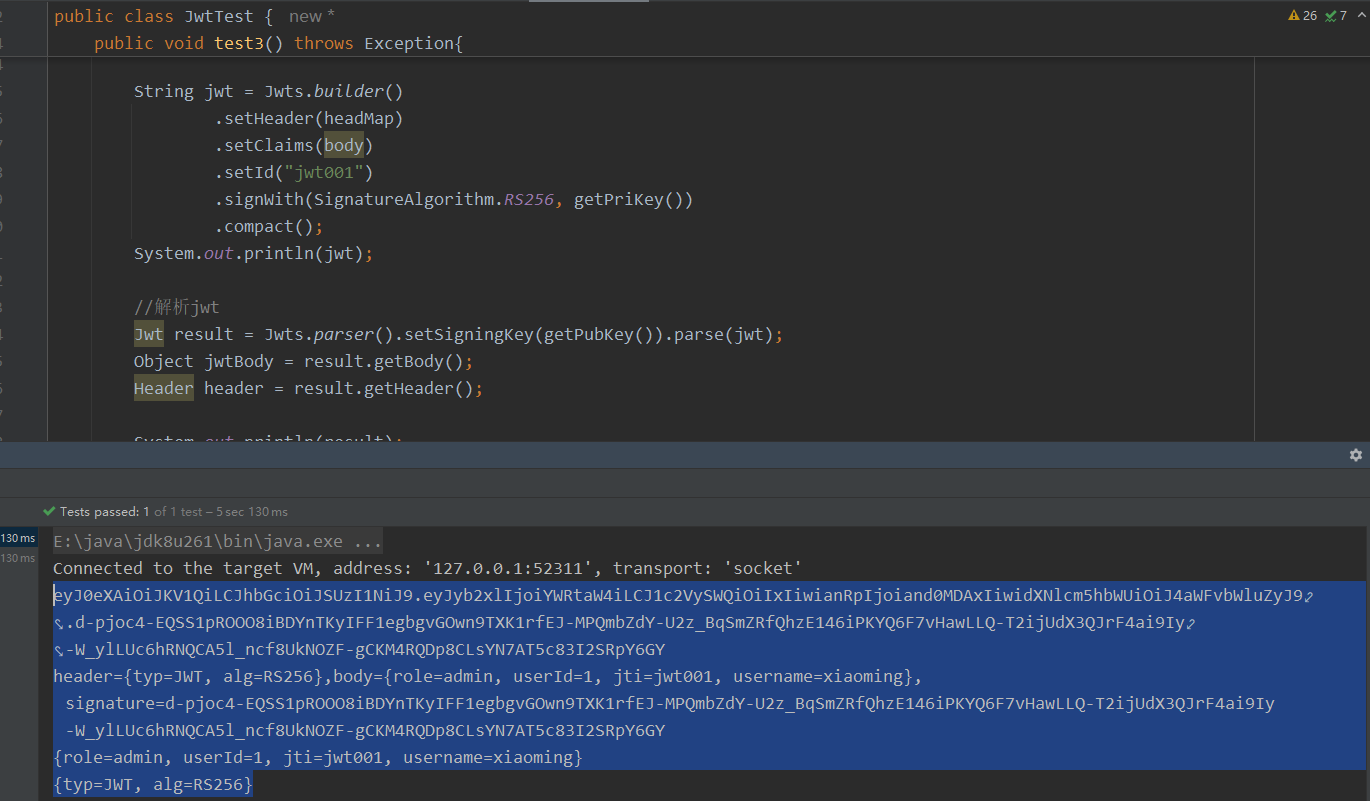
后台管理系统的通用权限解决方案(八)认证机制介绍、JWT介绍与jjwt框架的使用
文章目录 1 认证机制介绍1.1 HTTP Basic Auth1.2 Cookie-Session Auth1.3 OAuth1.4 Token Auth 2 JWT2.1 JWT介绍2.2 JWT的数据结构2.2.1 JWT头2.2.2 JWT有效载荷2.2.3 JWT签名 3 jjwt3.1 jjwt介绍3.2 jjwt案例 1 认证机制介绍 1.1 HTTP Basic Auth HTTP Basic Auth 是一种简…...

接口测试 —— Postman 变量了解一下!
Postman变量是在Postman工具中使用的一种特殊功能,用于存储和管理动态数据。它们可以用于在请求的不同部分、环境或集合之间共享和重复使用值。 Postman变量有以下几种类型: 1、环境变量(Environment Variables): 环境变量是在…...

鸿蒙系统:核心特性、发展历程与面临的机遇与挑战
好动与不满足是进步的第一必需品 文章目录 前言重要特点和组成部分核心特性主要组件发展历程 机遇挑战总结 前言 鸿蒙系统(HarmonyOS)是由华为技术有限公司开发的一款面向全场景的分布式操作系统。它旨在为用户提供更加流畅、安全且高效的数字生活体验&…...
从0到1,用Rust轻松制作电子书
我之前简单提到过用 Rust 做电子书,今天分享下如何用Rust做电子书。制作电子书其实用途广泛,不仅可以用于技术文档(对技术人来说非常方便),也可以制作用户手册、笔记、教程等,还可以应用于文学创作。 如果…...

半天入门!锂电池剩余寿命预测(Python)
往期精彩内容: 时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较 全是干货 | 数据集、学习资料、建模资源分享! EMD变体分解效果最好算法——CEEMDAN(五)-CSDN博客 拒绝信息泄露!VMD滚动分…...

学生党头戴式耳机哪款音质更胜一筹?TOP4好音质头戴式耳机推荐
在挑选头戴式耳机时,市场上琳琅满目的品牌和型号常常让人目不暇接。究竟哪个学生党头戴式耳机哪款音质更胜一筹?这已成为许多人面临的难题。由于每个人对耳机的偏好各有侧重——一些人追求音质的纯净,一些人重视佩戴的舒适性,而另…...

数据结构 ——— 二叉树的概念及结构
目录 二叉树的概念 特殊的二叉树 一、满二叉树 二、完全二叉树 二叉树的概念 二叉树树示意图: 从以上二叉树示意图可以看出: 二叉树每个节点的度不大于 2 ,那么整个二叉树的度也不大于 2 ,但是也不是每个节点都必须有 2 个…...

【React】React 的核心设计思想
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 React 的核心设计思想引言声明式编程声明式 vs 命令式示例 组件化组件的优势组件…...

C++ 二叉树进阶:相关习题解析
目录 1. 二叉树创建字符串。 2. 二叉树的分层遍历1 3. 二叉树的分层遍历2 4. 二叉树的最近公共祖先 5. 将二叉搜索树转换为排序的双向链表 6. 从前序与中序遍历序列构造二叉树 7. 从中序与后序遍历序列构造二叉树 8. 二叉树的前序遍历,非递归迭代实现 9.…...

Matlab实现蚁群算法求解旅行商优化问题(TSP)(理论+例子+程序)
一、蚁群算法 蚁群算法由意大利学者Dorigo M等根据自然界蚂蚁觅食行为提岀。蚂蚁觅食行为表示大量蚂蚁组成的群体构成一个信息正反馈机制,在同一时间内路径越短蚂蚁分泌的信息就越多,蚂蚁选择该路径的概率就更大。 蚁群算法的思想来源于自然界蚂蚁觅食&a…...

2024年10月HarmonyOS应用开发者基础认证全新题库
注意事项:切记在考试之外的设备上打开题库进行搜索,防止切屏三次考试自动结束,题目是乱序,每次考试,选项的顺序都不同 这是基础认证题库,不是高级认证题库注意看清楚标题 高级认证题库地址:20…...

kafka 分布式(不是单机)的情况下,如何保证消息的顺序消费?
大家好,我是锋哥。今天分享关于【kafka 分布式(不是单机)的情况下,如何保证消息的顺序消费?】面试题?希望对大家有帮助; kafka 分布式(不是单机)的情况下,如何保证消息的…...

数据分析案例-苹果品质数据可视化分析+建模预测
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

沈阳乐晟睿浩科技有限公司抖音小店运营创新
在当今这个数字化迅猛发展的时代,电子商务已经成为推动经济增长的重要引擎。而在电商的广阔舞台上,短视频与直播带货的崛起无疑是最为耀眼的明星之一。作为这一领域的佼佼者,抖音小店凭借其庞大的用户基础和独特的算法优势,吸引了…...

【前端】CSS知识梳理
基础:标签选择器、类选择器、id选择器和通配符选择器 font:font-style(normal) font-weight(400) font-size(16px) /line-height(0) font-family(宋体) 复合: 后代选择器( )、子选择器(>)、并集选择器(…...
)
【奇点智能大会·治理白皮书首发】:基于27家头部AI企业的服务治理数据,验证出唯一有效的3维可观测性模型(QPS/Token耗时/上下文漂移)
更多请点击: https://intelliparadigm.com 第一章:大模型服务治理:奇点智能大会 在2024年奇点智能大会上,大模型服务治理成为核心议题。随着LLM推理服务规模化部署,如何统一调度、细粒度限流、多租户隔离与可观测性闭…...

工程师的幽默密码:从二进制笑话到技术漫画创作指南
1. 项目概述:当硬件工程师拿起画笔作为一名在电子设计领域摸爬滚打了十几年的工程师,我的日常总是被Verilog代码、时序约束、PCB走线和各种数据手册所包围。电路板上的世界是精确而严肃的,电压、电流、时钟周期,一切都必须分毫不差…...

基于copaw-code构建代码语义搜索系统:从原理到实践
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫QSEEKING/copaw-code。这名字乍一看有点摸不着头脑,但如果你对代码搜索、智能辅助编程或者大模型应用开发感兴趣,那这个仓库绝对值得你花时间研究。简单来说,它是一套围…...

第四部分-Docker网络与存储——18. 自定义网络
18. 自定义网络 1. 自定义网络概述 自定义网络允许用户根据需求创建具有特定配置的网络,相比默认的 bridge 网络,提供了更好的隔离性、DNS 解析和灵活性。 ┌────────────────────────────────────────────…...

如何用MAA助手彻底解放双手:明日方舟智能自动化工具终极指南
如何用MAA助手彻底解放双手:明日方舟智能自动化工具终极指南 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https…...

为什么顶尖AI产品团队正秘密重构设计系统?——AI原生用户体验的4层认知断层与SITS 2026破局公式
更多请点击: https://intelliparadigm.com 第一章:AI原生用户体验设计:SITS 2026交互设计新趋势 AI原生体验不再将模型能力“封装后隐藏”,而是让智能成为界面的第一公民——用户在输入框中键入自然语言时,系统实时推…...

AI工具搭建自动化视频生成输出审核
# AI工具搭建视频生成中的数据脱敏:一个Python开发者的实战笔记 做视频自动生成这件事,碰到的第一个坎往往不是技术选型,而是数据安全。特别是当视频里要展示真实用户数据的时候,总不能把用户的姓名、手机号、住址这些敏感信息直接…...

PCL2启动器:Minecraft玩家的终极免费启动工具完全指南
PCL2启动器:Minecraft玩家的终极免费启动工具完全指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL PCL2启动器是一款专为Minecraft玩家设计的开源启动工具&…...

智能网盘加速方案:3步实现下载速度飞跃
智能网盘加速方案:3步实现下载速度飞跃 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾被百度网盘的下载速度折磨到崩溃?当急需下载重要文件时…...

NormalMap-Online:三步实现GPU加速的法线贴图生成,重新定义3D材质制作流程
NormalMap-Online:三步实现GPU加速的法线贴图生成,重新定义3D材质制作流程 【免费下载链接】NormalMap-Online NormalMap Generator Online 项目地址: https://gitcode.com/gh_mirrors/no/NormalMap-Online 还在为3D模型表面细节不足而烦恼吗&…...