Linux基础环境搭建(CentOS7)- 安装Scala和Spark
#Linux基础环境搭建(CentOS7)- 安装Scala和Spark
Linux基础环境搭建(CentOS7)- 安装Scala和Spark
大家注意以下的环境搭建版本号,如果版本不匹配有可能出现问题!(spark不要下2.4版本的 会报错,下载3.0的)
一、Scala下载及安装
Scala是一门多范式的编程语言,一种类似java的编程语言,设计初衷是实现可伸缩的语言 、并集成面向对象编程和函数式编程的各种特性。 
Scala的下载
Scala下载链接:通过网盘分享的文件:scala-2.11.8.tgz.zip
链接: https://pan.baidu.com/s/1IArx9RTfmV3ipwcxH1Vsew?pwd=vbha 提取码: vbha
将下载的安装包通过Xftp传输到Linux虚拟机中
Scala安装
创建工作路径/usr/scala,下载scala安装包到/opt/software中,然后解压至工作路径。
mkdir /usr/scala #创建工作路径
cd /opt/software #进入安装包的文件夹
tar -zxvf scala-2.11.12.tgz -C /usr/scala/ #解压zookeeper
cd /usr/scala/scala-2.11.12/二、配置Scala环境变量
修改/etc/profile文件,配置scala环境变量。
vim /etc/profile#set scala
export SCALA_HOME=/usr/scala/scala-2.11.12
export PATH=$PATH:$SCALA_HOME/bin
source /etc/profile #生效环境变量
scala -version #查看scala是否安装成功
如果出现版本号,表示scala安装成功
三、同步其他虚拟机
以上已经在主节点master上配置完成Scala,现在可以将该配置好的安装文件远程拷贝到集群中的各个结点对应的目录下:(在master执行)
scp -r /etc/profile root@slave1:/etc/profile #将环境变量profile文件分发到slave1节点
scp -r /etc/profile root@slave2:/etc/profile #将环境变量profile文件分发到slave2节点
scp -r /usr/scala root@slave1:/usr/ #将scala文件分发到slave1节点
scp -r /usr/scala root@slave2:/usr/ #将scala文件分发到slave2节点上述是第一次安装没创建过的因为我创建过单独的文件所以是
scp -r /etc/profile root@slave1:/etc/profile #将环境变量profile文件分发到slave1节点
scp -r /etc/profile root@slave2:/etc/profile #将环境变量profile文件分发到slave2节点
scp -r /export/servers/scale root@slave1:/export/servers/ #将scala文件分发到slave1节点
scp -r /export/servers/scale root@slave2:/export/servers/ #将scala文件分发到slave2节点生效两个从节点的环境变量
source /etc/profile #slave1和slave2都要执行四、Spark下载及安装
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。

Spark的下载
Spark下载链接: https://pan.baidu.com/s/1TsKDtHtPwSCX3d00mZhD7g?pwd=f83p
提取码: f83p
将下载的安装包通过Xftp传输到Linux虚拟机中
Spark安装
创建工作路径/usr/spark,下载spark安装包到/opt/software中,然后解压至工作路径。
mkdir /usr/spark #创建工作路径
cd /opt/software #进入安装包的文件夹
tar -zxvf spark-2.4.1-bin-hadoop2.7.tgz -C /usr/spark/ #解压spark
cd /usr/spark/spark-2.4.1-bin-hadoop2.7/因为我之前已经创建过了 所以就不按照上面的了
spark-3.0.0-bin-hado.tgz
tar -zxvf spark-2.4.0-bin-without-hadoop.tgz -C /export/servers/spark
mv spark-2.4.0-bin-without-hadoop spark-2.4.0
cd spark-2.4.0/
五、配置spark-env.sh文件
配置文件spark-env.sh,进入spark配置文件夹conf,将spark-env.sh.template文件拷贝一份命名为spark-env.sh,spark在启动时会找这个文件作为默认配置文件。
cd /usr/spark/spark-2.4.1-bin-hadoop2.7/conf/
cp spark-env.sh.template spark-env.sh对spark-env.sh文件配置如下:(在master执行)
vim spark-env.sh添加如下内容:
export SPARK_MASTER_IP=master
export SCALA_HOME=/usr/scala/scala-2.11.12
export SPARK_WORKER_MEMORY=8g
export JAVA_HOME=/usr/java/jdk1.8.0_171
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.7.3/etc/hadoop因为之前已经创建过了 所以就不再按照上面的了
export SPARK_MASTER_IP=master
export SCALA_HOME=/export/servers/scale/scala-2.11.8
export SPARK_WORKER_MEMORY=8g
export JAVA_HOME=/export/servers/jdk
export HADOOP_HOME=/export/servers/hadoop
export HADOOP_CONF_DIR=/export/servers/hadoop/etc/hadoop
六、配置Spark从节点,修改slaves文件
注意slaves节点中只包含节点信息,其他注释不需要
cd /usr/spark/spark-2.4.1-bin-hadoop2.7/conf/
cp slaves.template slaves
vim slaves添加如下内容:
master
slave1
slave2七、配置Spark环境变量
修改/etc/profile文件,配置Spark环境变量。
vim /etc/profile#set spark
export SPARK_HOME=/usr/spark/spark-2.4.1-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin这里我之前创建过文件所以就不按照上面的了
#set spark
export SPARK_HOME=/export/servers/spark/spark-2.4.0
export PATH=$PATH:$SPARK_HOME/bin

source /etc/profile #生效环境变量八、同步其他虚拟机
以上已经在主节点master上配置完成spark,现在可以将该配置好的安装文件远程拷贝到集群中的各个结点对应的目录下:(在master执行)
scp -r /etc/profile root@slave1:/etc/profile #将环境变量profile文件分发到slave1节点
scp -r /etc/profile root@slave2:/etc/profile #将环境变量profile文件分发到slave2节点
scp -r /usr/spark root@slave1:/usr/ #将scala文件分发到slave1节点
scp -r /usr/spark root@slave2:/usr/ #将scala文件分发到slave2节点这里我改成自己之前创建的地方了
scp -r /export/servers/spark root@slave1:/export/servers/
scp -r /export/servers/spark root@slave2:/export/servers/
生效两个从节点的环境变量
source /etc/profile #slave1和slave2都要执行九、开启Spark环境(master节点)
/usr/spark/spark-2.4.1-bin-hadoop2.7/sbin/start-all.sh
jps #三个节点/export/servers/spark/spark-2.4.0/sbin/start-all.shmaster节点 
slave1节点 
slave2节点 
因为我们只设置了slave1和slave2两个Worker 所以只要master节点的进程有Master,slave1和slave2节点都有Worker,即代表启动成功!
十、Spark客户端连接
cd /usr/spark/spark-2.4.1-bin-hadoop2.7/bin/
spark-shell --master spark://master:7077若出现以下界面,则代表连接成功 
十一、查看Spark集群状态
在浏览器输入localhost:8080,如图: 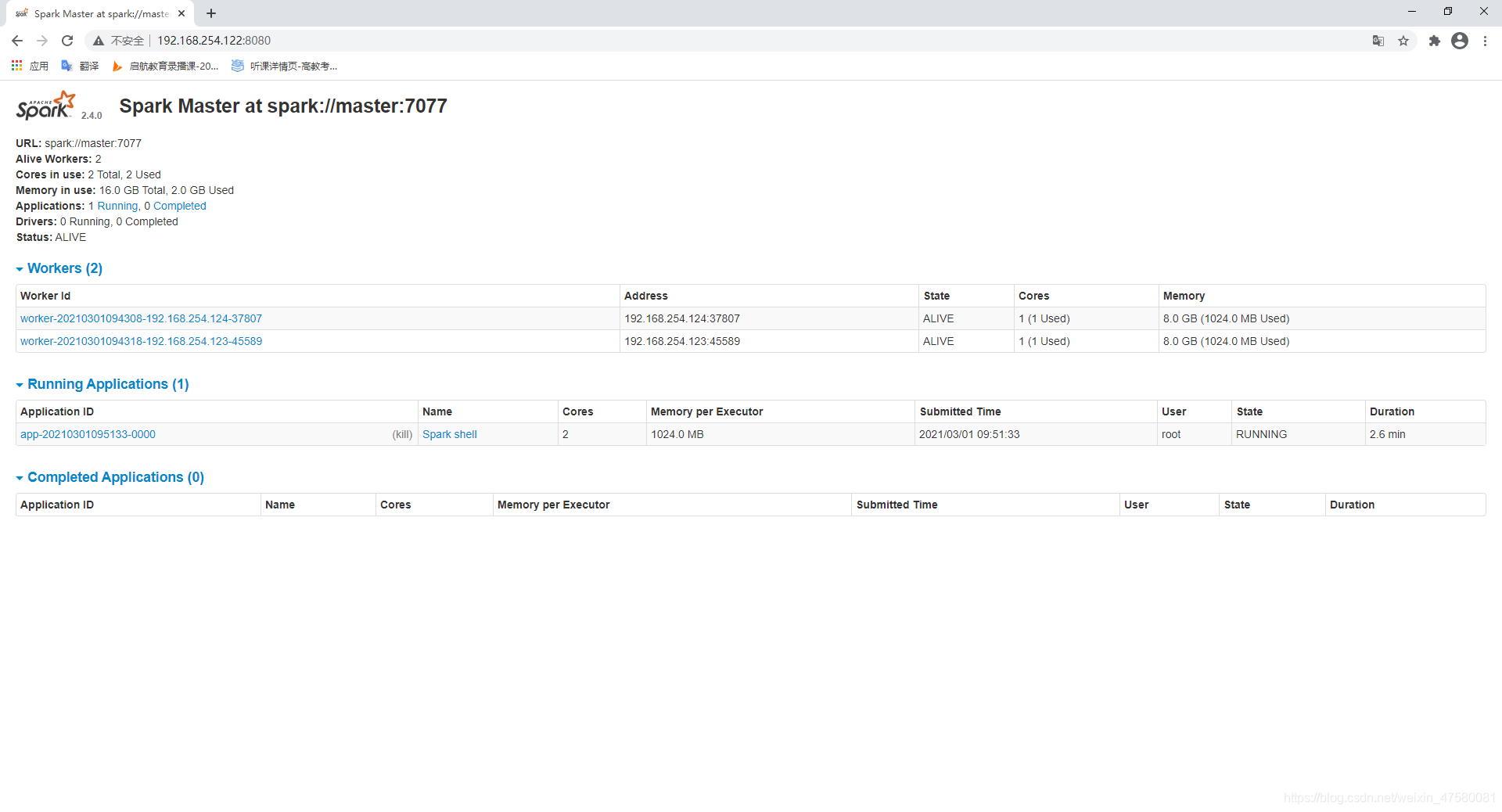 如果情况一样的话,就成功安装好scala和spark啦~
如果情况一样的话,就成功安装好scala和spark啦~
相关文章:
Linux基础环境搭建(CentOS7)- 安装Scala和Spark
#Linux基础环境搭建(CentOS7)- 安装Scala和Spark Linux基础环境搭建(CentOS7)- 安装Scala和Spark 大家注意以下的环境搭建版本号,如果版本不匹配有可能出现问题!(spark不要下2.4版本的 会报错…...
SpringBoot 下的Excel文件损坏与内容乱码问题
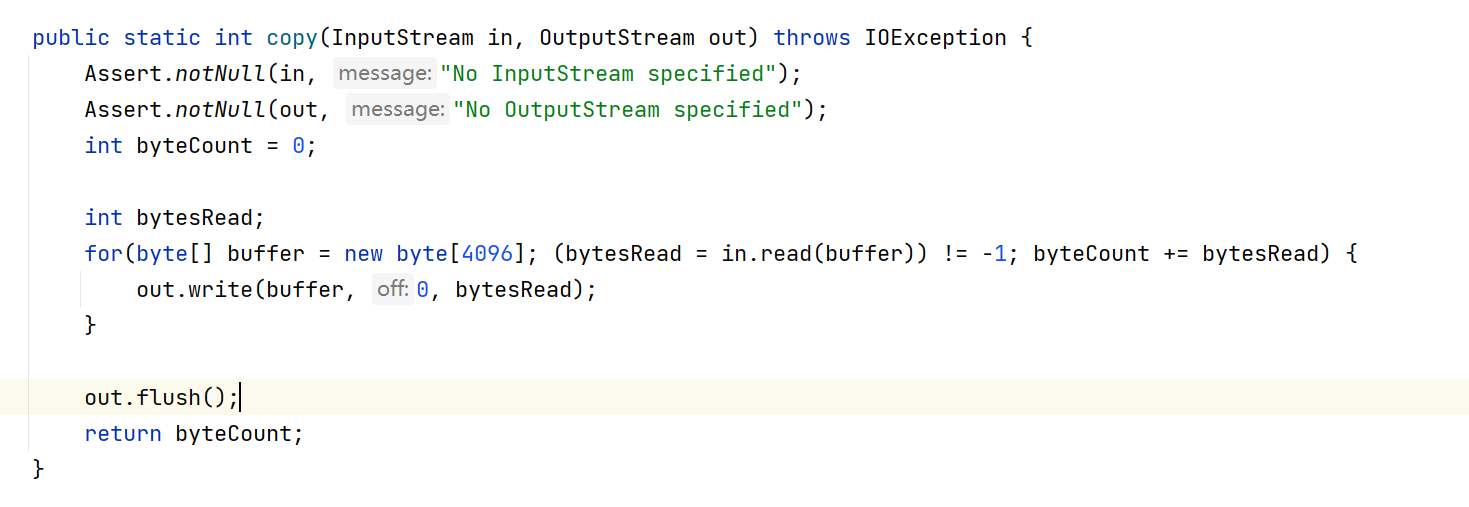
序言 随着打包部署的方式的改变,原本正常运行的代码可能带来一些新的问题,比如我们现在使用SpringBoot 的方式生成Jar包直接运行,就会对我们再在Resource下的Excel文件产生影响,导入与预期不符的情况发生cuiyaonan2000163.com 比…...
官宣下代GPU存在缺陷,50系显卡或将迎来涨价
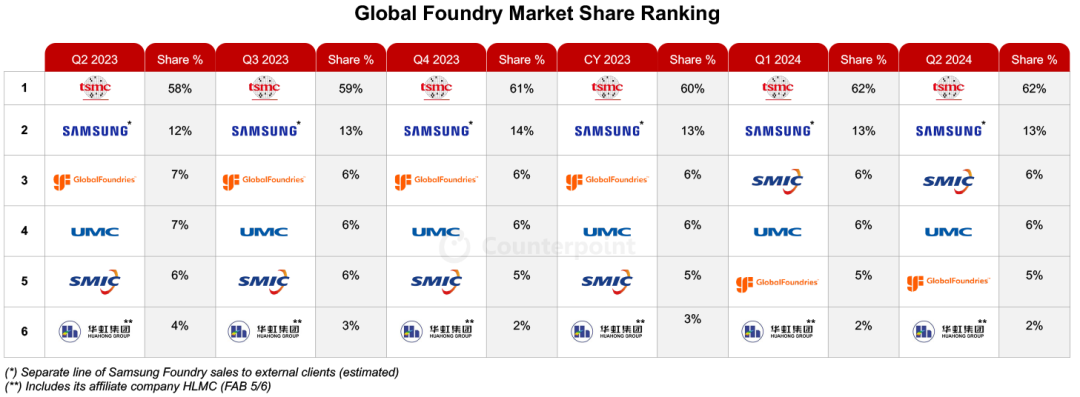
如果说 AMD 在 Ryzen 3000 系列还是和 intel 在 CPU 方面棋差一着的话,Ryzen 5000 系列就是打了个漂亮的翻身仗了。 凭借先进的 7nm 工艺制程和全新架构,让后来 intel 急忙推出「14nm」的 11 代酷睿也难以望其项背。 直到 intel 12 代发布的时候…...
使用pytorch实现LSTM预测交通流
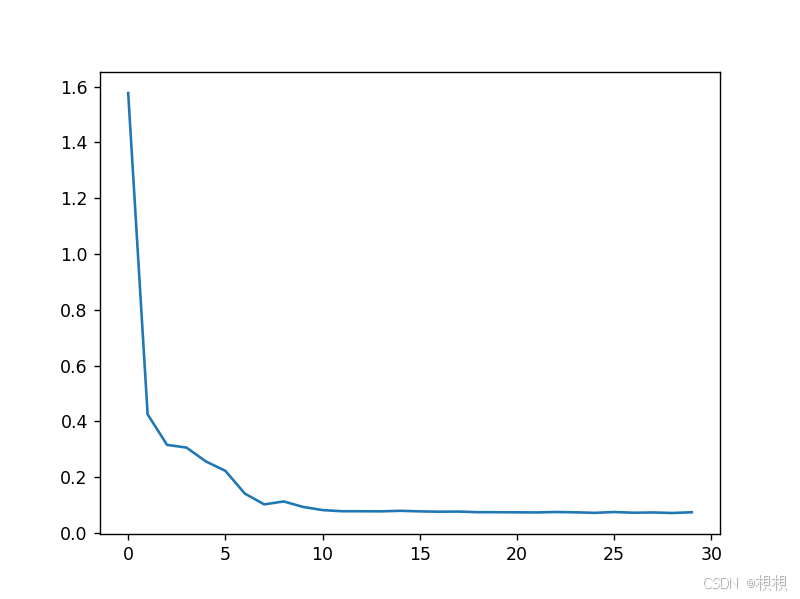
原始数据: 免费可下载原始参考数据 预测结果图: 根据测试数据test_data的真实值real_flow,与模型根据测试数据得到的输出结果pre_flow 完整源码: #!/usr/bin/env python # _*_ coding: utf-8 _*_import pandas as pd import nu…...
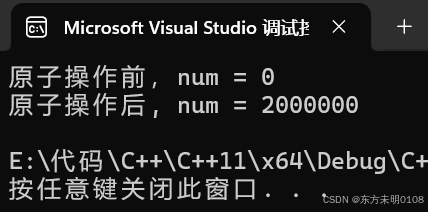
C/C++(八)C++11
目录 一、C11的简介 二、万能引用与完美转发 1、万能引用:模板中的 && 引用 2、完美转发:保持万能引用左右值属性的解决方案 三、可变参数模板 1、可变参数模板的基本使用 2、push 系列和 emplace 系列的区别 四、lambda表达式…...

使用three.js 实现 自定义绘制平面的效果
使用three.js 实现 自定义绘制平面的效果 预览 import * as THREE from three import { OrbitControls } from three/examples/jsm/controls/OrbitControls.jsconst box document.getElementById(box)const scene new THREE.Scene()const camera new THREE.PerspectiveCam…...
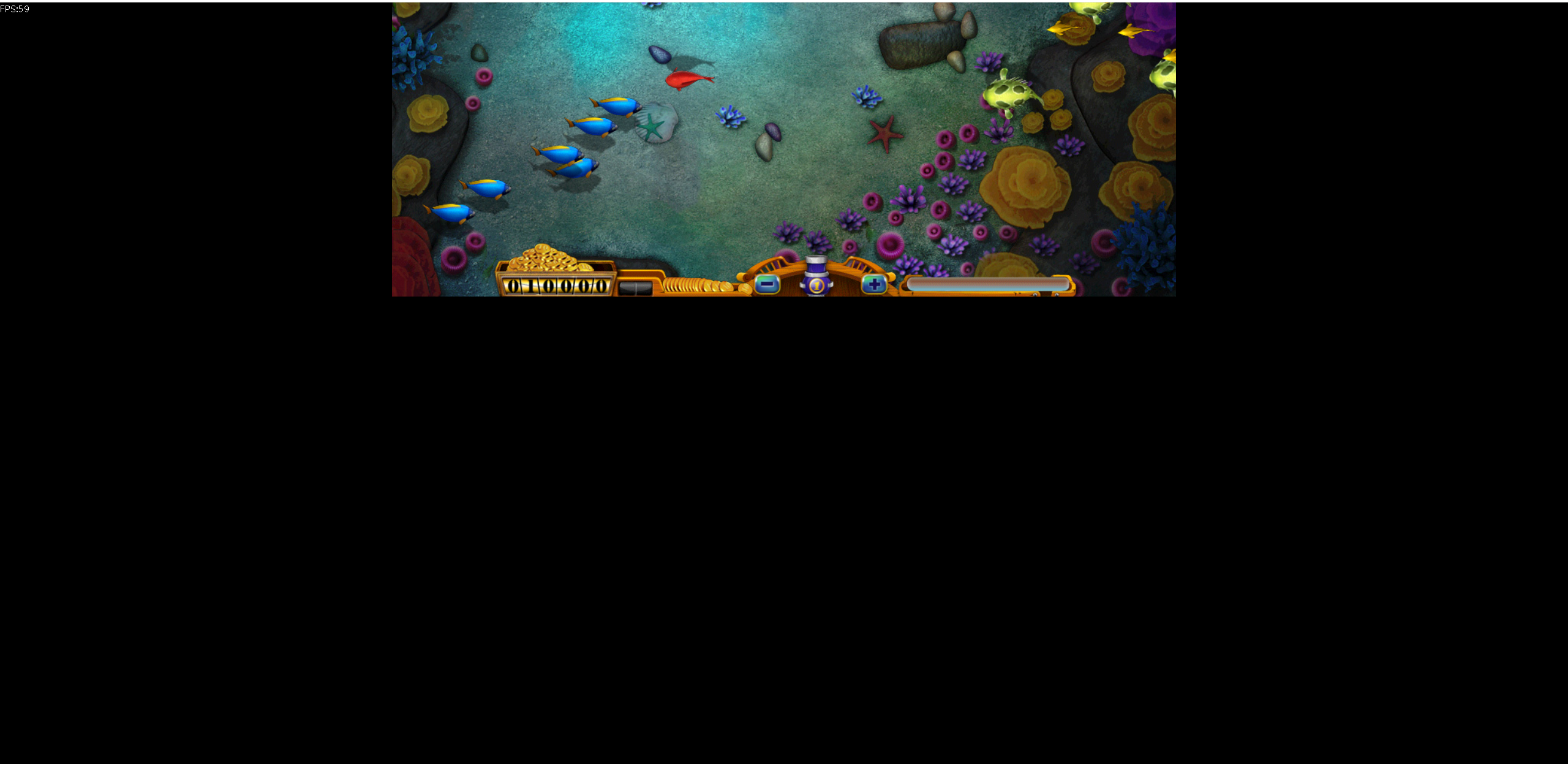
玩转Docker | 使用Docker部署捕鱼网页小游戏
玩转Docker | 使用Docker部署捕鱼网页小游戏 一、项目介绍项目简介项目预览二、系统要求环境要求环境检查Docker版本检查检查操作系统版本三、部署捕鱼网页小游戏下载镜像创建容器检查容器状态下载项目内容查看服务监听端口安全设置四、访问捕鱼网页小游戏五、总结一、项目介绍…...
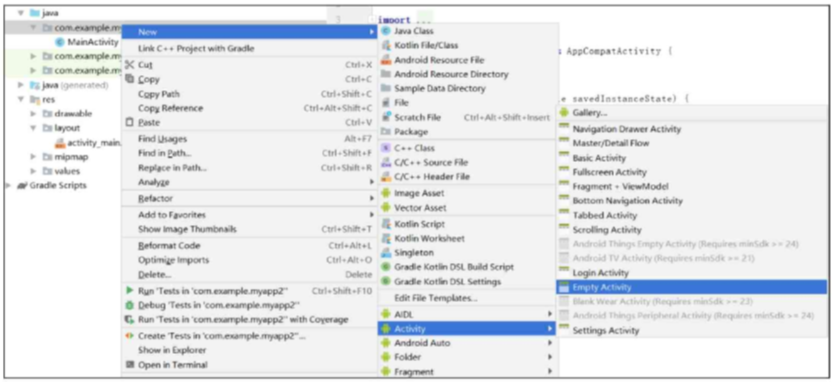
第2章 Android App开发基础
第 2 章 Android App开发基础 bilibili学习地址 github代码地址 本章介绍基于Android系统的App开发常识,包括以下几个方面:App开发与其他软件开发有什么不一 样,App工程是怎样的组织结构又是怎样配置的,App开发的前后端分离设计…...
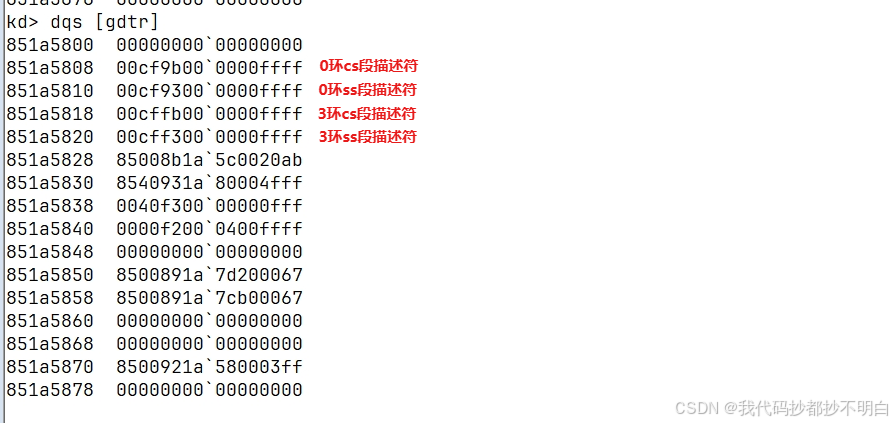
通过 SYSENTER/SYSEXIT指令来学习系统调用
SYSENTER指令—快速系统调用 指令格式没有什么重要的内容,只有opcode ,没有后面的其他字段 指令的作用: 执行快速调用到特权级别0的系统过程或例程。SYSENTER是SYSEXIT的配套指令。该指令经过优化,能够为从运行在特权级别3的用户代码到特权级别0的操作系统或执行过程…...

Nginx开发实战——网络通信(一)
文章目录 Nginx开发框架信号处理函数的进一步完善(避免僵尸子进程)(续)ngx_signal.cxxngx_process_cycle.cxx 网络通信实战客户端和服务端1. 解析一个浏览器访问网页的过程2.客户端服务器角色规律总结 网络模型OSI 7层网络模型TCP/IP 4层模型3.TCP/IP的解释和比喻 最…...
w外链如何跳转微信小程序
要创建外链跳转微信小程序,主要有以下几种方法: 使用第三方工具生成跳转链接: 注册并登录第三方外链平台:例如 “W外链” 等工具。前往该平台的官方网站,使用手机号、邮箱等方式进行注册并登录账号。选择创建小程序外…...
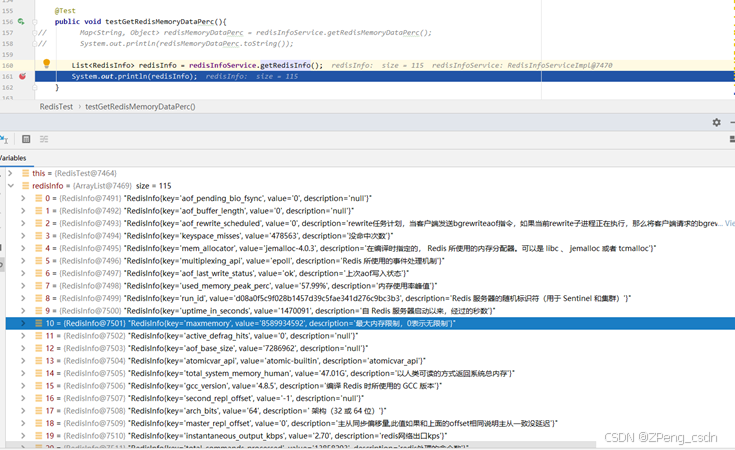
获取平台Redis各项性能指标
业务场景 在XXXX项目中把A网的过车数据传到B网中,其中做了一个业务处理,就是如果因为网络或者其他原因导致把数据传到B网失败,就会把数据暂时先存到redis里,并且执行定时任务重新发送失败的。 问题 不过现场的情况比较不稳定。出…...
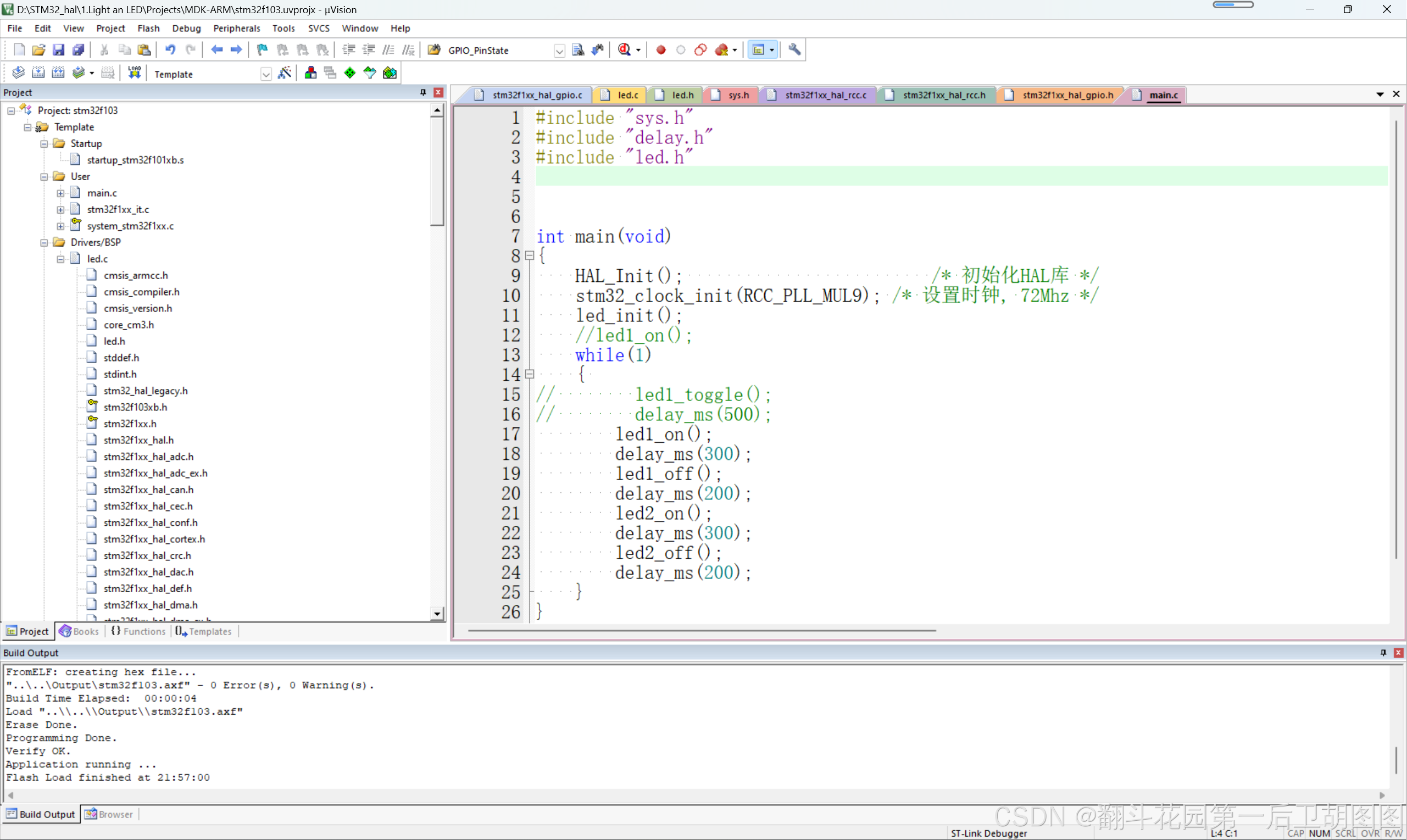
STM32 HAL 点灯
首先从点灯开始 完整函数如下: #include "led.h" #include "sys.h"//包含了stm32f1xx.h(包含各种寄存器定义、中断向量定义、常量定义等)//初始化GPIO口 void led_init(void) {GPIO_InitTypeDef gpio_initstruct;//打开…...

【http作业】
1.关闭防火墙 [rootlocalhost ~]# systemctl stop firewalld #关闭防火墙 [rootlocalhost ~]# setenforce 0 2.下载nginx包 [rootlocalhost ~]# mount /dev/sr0 /mnt #挂载目录 [rootlocalhost ~]# yum install nginx -y #下载nginx包 3.增加多条端口 [rootlocalhost ~]# n…...

WPF+MVVM案例实战(十一)- 环形进度条实现
文章目录 1、运行效果2、功能实现1、文件创建与代码实现2、角度转换器实现3、命名空间引用3、源代码下载1、运行效果 2、功能实现 1、文件创建与代码实现 打开 Wpf_Examples 项目,在Views 文件夹下创建 CircularProgressBar.xaml 窗体文件。 CircularProgressBar.xaml 代码实…...

简述MCU微控制器
目录 一、MCU 的主要特点: 二、常见 MCU 系列: 三、应用场景: MCU 是微控制器(Microcontroller Unit)的缩写,指的是一种小型计算机,专门用于嵌入式系统。它通常集成了中央处理器(…...

微服务的雪崩问题
微服务的雪崩问题: 微服务调用链路中的某个服务故障,引起整个链路种的所有微服务都不可用。这就是微服务的雪崩问题。(级联失败),具体表现出来就是微服务之间相互调用,服务的提供者出现阻塞或者故障&#x…...

Java基础(4)——构建字符串(干货)
今天聊Java构建字符串以及其内存原理 我们先来看一个小例子。一个是String,一个是StringBuilder. 通过结果对比,StringBuilder要远远快于String. String/StringBuilder/StringBuffer这三个构建字符串有什么区别? 拼接速度上,StringBuilder…...

logback日志脱敏后异步写入文件
大家项目中肯定都会用到日志打印,目的是为了以后线上排查问题方便,但是有些企业对输出的日志包含的敏感(比如:用户身份证号,银行卡号,手机号等)信息要进行脱敏处理。 哎!我们最近就遇到了日志脱敏的改造。可…...

电容的基本知识
1.电容的相关公式 2.电容并联和串联的好处 电容并联的好处: 增加总电容值: 并联连接的电容器可以增加总的电容值,这对于需要较大电容值来滤除高频噪声或储存更多电荷的应用非常有用。 改善频率响应: 并联不同的电容值可以设计一个滤波器,以在特定的频率范围内提供更好的滤…...

3406硬核量化总结:黄大年茶思屋34期5题全解 重塑华为全球全栈技术霸权战略
华夏之光永存・硬核总结:黄大年茶思屋5题全解对华为战略的决定性价值 一、华为核心战略:全栈自主可控,构建端边云网芯一体化技术霸权 华为的核心战略是根技术全自研、全链路闭环、全场景覆盖,以芯片为底座、网络为联接、操作系统为中枢、AI为引擎、云为载体、行业应用为出…...

奇点大会周边酒店技术适配白皮书:支持会议直播推流、多设备协同充电、边缘计算终端供电的5家硬核之选
更多请点击: https://intelliparadigm.com 第一章:奇点智能技术大会周边酒店推荐 核心推荐区域 奇点智能技术大会主会场位于上海张江科学城AI创新集聚区,建议优先选择地铁2号线(广兰路站)及13号线(中科路…...

Noto字体库完整指南:如何为全球项目选择完美字体解决方案
Noto字体库完整指南:如何为全球项目选择完美字体解决方案 【免费下载链接】noto-fonts Noto fonts, except for CJK and emoji 项目地址: https://gitcode.com/gh_mirrors/no/noto-fonts 当你开发面向全球用户的应用或网站时,是否曾遇到过这样的…...

3步解锁知网文献:caj2pdf开源工具让你的学术阅读无界
3步解锁知网文献:caj2pdf开源工具让你的学术阅读无界 【免费下载链接】caj2pdf Convert CAJ (China Academic Journals) files to PDF. 转换中国知网 CAJ 格式文献为 PDF。佛系转换,成功与否,皆是玄学。 项目地址: https://gitcode.com/gh_…...

Spring Statemachine详解底层和落地
一、什么是状态机?为什么 Spring 要专门封装它 1.1 从“if-else 海啸”说起 在任何一个具有多状态的生命周期管理场景中,这种代码非常常见: if (order.getStatus() == OrderStatus.CREATED) {if (event == Event.PAY) {// 支付逻辑order.setStatus(OrderStatus.PAID);} e…...

物联网LoRa系列-2:从感知到应用,详解LoRa在分层架构中的关键角色
1. LoRa技术入门:从无线通信到物联网连接 第一次接触LoRa是在五年前的一个智慧农业项目上。当时客户需要在2000亩的茶园部署环境监测系统,传统WiFi和4G网络要么覆盖不足,要么功耗太高。当我看到LoRa终端设备在单节电池供电下能工作3年时&…...

观察taotoken平台在多模型聚合调用下的路由稳定性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察 Taotoken 平台在多模型聚合调用下的路由稳定性 在构建依赖大模型能力的生产应用时,服务的持续可用性是核心诉求之…...

Entire Dashboard:可视化AI编程协作过程,解决Git上下文丢失难题
1. 项目概述如果你和我一样,最近几年在开发工作中深度依赖了像 Cursor、Claude Code 这类 AI 编程助手,那你肯定也遇到过类似的困惑:Git 提交记录里只有冷冰冰的代码变更,但那些真正驱动我写出这段代码的 AI 对话、思考过程、被否…...

独立开发者如何借助Taotoken快速试验不同模型效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken快速试验不同模型效果 对于独立开发者或产品经理而言,在验证一个产品创意或构建原型时&…...
:10个必须嵌入的可解释性锚点与审计追踪模式)
AI原生设计“黑匣子”终结者(SITS 2026合规白皮书节选):10个必须嵌入的可解释性锚点与审计追踪模式
更多请点击: https://intelliparadigm.com 第一章:AI原生设计范式跃迁:从黑箱智能到SITS 2026可审计基线 AI系统正经历一场根本性重构:设计重心从“能否运行”转向“为何可信”。SITS 2026(Software-Intelligence Tra…...