EfficientNet-B6模型实现ISIC皮肤镜图像数据集分类
项目源码获取方式见文章末尾! 回复暗号:13,免费获取600多个深度学习项目资料,快来加入社群一起学习吧。
《------往期经典推荐------》
项目名称
1.【基于opencv答题卡识别判卷】
2.【卫星图像道路检测DeepLabV3Plus模型】
3.【GAN模型实现二次元头像生成】
4.【CNN模型实现mnist手写数字识别】
5.【fasterRCNN模型实现飞机类目标检测】
6.【CNN-LSTM住宅用电量预测】
7.【VGG16模型实现新冠肺炎图片多分类】
8.【AlexNet模型实现鸟类识别】
9.【DIN模型实现推荐算法】
10.【FiBiNET模型实现推荐算法】
11.【钢板表面缺陷检测基于HRNET模型】
…
1. 项目简介
项目A065的目标是使用EfficientNet-B6模型实现皮肤镜图像分类,帮助识别皮肤病变的类型。随着深度学习技术的快速发展,计算机辅助诊断(CAD)工具逐渐在医疗影像分析中得到广泛应用。该项目聚焦于皮肤镜图像的分类,通过训练模型自动识别不同类型的皮肤病变,如黑色素瘤(MEL)、痣(NV)、基底细胞癌(BCC)等,从而为临床诊断提供支持。
项目采用EfficientNet-B6模型,该模型通过复合缩放方法在保持较高性能的同时减少计算资源的消耗。数据集使用ISIC 2018挑战赛提供的皮肤镜图像,经过数据预处理后,输入EfficientNet-B6进行特征提取和分类。项目的核心目标是提升分类精度,降低漏诊和误诊率,从而为皮肤病变检测提供一个可靠的自动化工具。
2.技术创新点摘要
EfficientNet-B6模型的应用与优化: 该项目采用了EfficientNet-B6模型,这是一种高效的卷积神经网络结构。EfficientNet通过复合缩放方法,在提升模型精度的同时降低了计算成本,尤其适用于计算资源受限的环境。EfficientNet-B6相较于较小的模型具备更高的参数量和计算复杂度,因此在处理高分辨率皮肤镜图像时能够提取更多细节特征,提升分类精度。此外,模型的分类器部分进行了定制,原有的分类层被替换为适应特定分类任务的输出层,确保其与皮肤病变分类任务的需求相匹配。
自定义数据集类与高效数据预处理: 项目中引入了自定义数据集类CustomDataset,不仅将图像和标签进行了对应管理,还通过标签映射实现了多类别标签的高效处理。数据预处理中,项目对输入图像进行尺寸调整,使其适应EfficientNet-B6的输入要求(528x528像素)。这种预处理保证了不同分辨率的皮肤镜图像能够一致输入模型,避免了图像尺寸差异带来的影响。同时,标准化操作(mean和std)也确保了图像输入的像素值分布在一定范围内,有助于模型更快收敛。
高效的优化器与损失函数选择: 项目选择了Ranger优化器,这是一个结合了Rectified Adam(RAdam)和Lookahead的混合优化器。Ranger优化器不仅拥有自适应的学习率调整机制,还结合了Lookahead策略的长远步长搜索,确保在深度学习训练过程中能够获得更稳定且高效的收敛效果。相比传统的SGD或Adam优化器,Ranger在这种复杂的多类别分类任务中能够更好地平衡模型的精度和收敛速度。此外,项目选择了交叉熵损失函数(CrossEntropyLoss),这是多类别分类任务中常见且有效的损失函数。
集成性能评估与可视化分析: 项目中不仅实现了模型的训练和验证流程,还设计了评估函数evaluate_model,使用准确率、精确率、召回率和F1评分等多种指标对模型性能进行综合评价。这些指标的选择有助于在不平衡数据集下全面评估模型的表现。为了便于直观分析,项目还集成了Matplotlib绘图工具,通过柱状图的方式将训练集、验证集和测试集的模型性能可视化。这种方式可以帮助研究者快速发现模型在不同数据集上的表现差异,从而进行针对性的优化调整。
3. 数据集与预处理
该项目使用的数据集来源于ISIC 2018挑战赛,这是一个公开的皮肤镜图像数据集,专门用于皮肤病变的分类任务。该数据集包含数千张标注了皮肤病变的高分辨率皮肤镜图像,类别包括黑色素瘤(MEL)、痣(NV)、基底细胞癌(BCC)、鳞状细胞癌(AKIEC)、良性角化病(BKL)、皮肤纤维瘤(DF)和血管病变(VASC)等。每张图像都配有相应的类别标签,便于监督学习。
数据预处理流程:
- 图像尺寸调整: EfficientNet-B6模型要求输入图像的尺寸为528x528像素。因此,在预处理过程中,所有的图像都被统一调整为这个尺寸,以保证输入模型时的格式一致。这一步骤有助于避免不同分辨率的图像对模型性能产生影响。
- 图像归一化: 归一化是深度学习图像处理中的重要步骤,该项目对每张图像进行了标准化处理。通过使用ImageNet的预训练模型参数,项目分别使用均值([0.485, 0.456, 0.406])和标准差([0.229, 0.224, 0.225])对图像的RGB通道进行归一化。归一化能够确保输入图像的像素值分布在合理的范围内,避免特定通道的亮度差异对模型造成干扰,加快模型的训练收敛速度。
- 标签处理: 项目使用的标签格式为多类别分类,涉及到皮肤病变的七个类别。数据集中,标签通过字典映射被转换为整数标签,便于模型进行分类任务。此操作不仅使标签与模型输出格式相匹配,还为后续的损失函数计算提供了便利。
总体来说,该项目的数据预处理步骤充分考虑了图像的尺寸、色彩信息以及标签处理等问题,为EfficientNet-B6模型的训练和推理提供了高质量的输入数据。这些预处理步骤在医学图像分析中十分关键,有助于提升模型的精度和泛化能力。

4. 模型架构
1) 模型结构的逻辑
该项目的核心模型架构基于EfficientNet-B6,这是EfficientNet系列中的一种大型变体。EfficientNet通过一种称为复合缩放的技术优化了模型的宽度、深度和分辨率,从而在减少计算资源的同时提高了模型的准确性。EfficientNet-B6相较于其他版本(如B0-B5)具有更大的深度和更高的分辨率(528x528像素输入),使其在处理高分辨率图像(如皮肤镜图像)时表现更优。
模型架构的核心逻辑如下:
- EfficientNet-B6预训练模型:该项目加载了预训练的EfficientNet-B6模型,并通过ImageNet进行初始权重加载。这有助于模型在新的任务上进行迁移学习,避免从头开始训练,提高了模型的效率和性能。
- 分类器调整:EfficientNet-B6的原始分类器被替换为适应皮肤病变分类的输出层。在代码中,将EfficientNet-B6的分类器部分修改为5个输出节点,以匹配皮肤病变的类别数。这种方法确保了模型能够输出相应类别的概率分布,适应多类别分类任务。
整个模型架构的设计旨在利用EfficientNet的高效特征提取能力,结合医学图像的复杂性,帮助模型识别和区分细微的皮肤病变特征。
2) 模型的整体训练流程与评估指标
模型训练流程:
-
数据加载与准备:首先,通过自定义的
CustomDataset类加载训练、验证和测试数据集。每个数据集都经过了统一的预处理,包括图像尺寸调整、归一化等。 -
模型初始化:加载EfficientNet-B6模型,并替换其分类器层。使用Ranger优化器(结合了RAdam和Lookahead的优势)和交叉熵损失函数(CrossEntropyLoss)来定义模型的优化策略和损失计算。
-
训练循环:
- 模型训练过程中,数据通过DataLoader以批次的形式输入到EfficientNet-B6模型中。
- 对每个批次的数据,模型计算输出并与真实标签进行对比,通过交叉熵损失函数计算损失值。
- 使用Ranger优化器反向传播损失,更新模型的权重。
- 训练过程中输出每个epoch的累计损失,以跟踪训练进度。
-
模型评估:训练完成后,使用验证集和测试集对模型进行评估。评估流程包括在验证集和测试集上运行模型,获取预测结果,并与真实标签进行对比。
评估指标:
- 准确率(Accuracy) :表示模型预测正确的样本占总样本的比例,反映了模型整体的正确性。
- 精确率(Precision) :表示模型在所有预测为正类的样本中,实际为正类的比例,适合在关注模型预测的精度时使用。
- 召回率(Recall) :表示模型在所有实际为正类的样本中,成功被模型预测为正类的比例,适合在不希望漏检时使用。
- F1评分(F1 Score) :精确率和召回率的调和平均数,用于平衡精度和召回率之间的关系,特别适合不平衡数据集的评价。
5. 核心代码详细讲解
1. 数据预处理与特征工程
暂时无法在飞书文档外展示此内容
class CustomDataset(Dataset):定义了一个自定义的数据集类,该类继承自torch.utils.data.Dataset,用于管理和处理输入的图像和标签。self.img_paths = img_paths:存储传入的图像文件路径列表。label_to_int:将字符串标签转换为整数标签的映射字典。每个类别(如’MEL’, 'NV’等)被映射为一个唯一的整数,便于模型进行分类任务。self.labels = [label_to_int[label] for label in labels]:根据映射字典,将标签转换为对应的整数形式。self.transform = transform:存储数据增强或预处理操作,用于后续对图像的处理。
暂时无法在飞书文档外展示此内容
getitem(self, index):这是数据集类的核心方法,用于根据索引获取图像及其对应的标签。Image.open(img_path).convert('RGB'):通过PIL库打开图像文件,并将其转换为RGB格式,以确保图像输入的颜色通道一致。self.transform(image):如果指定了预处理(如图像归一化或尺寸调整),则应用这些操作。return image, label:返回处理后的图像及其对应的标签。
2. 模型架构的构建
暂时无法在飞书文档外展示此内容
efficientnet_b6(pretrained=True):加载预训练的EfficientNet-B6模型。通过设置pretrained=True,模型使用在ImageNet上预训练的权重,这有助于在皮肤镜图像分类任务上进行迁移学习,提升模型的收敛速度和准确性。model.classifier[1] = nn.Linear(model.classifier[1].in_features, 5):EfficientNet-B6的原始分类器被替换。nn.Linear创建了一个线性层,将分类器的输出调整为5个节点,对应项目中的5个皮肤病变类别。model.classifier[1].in_features提取分类器的输入特征数量,以适应新任务。
3. 模型训练与优化
暂时无法在飞书文档外展示此内容
optimizer = Ranger(model.parameters(), lr=1e-3):使用Ranger优化器,这是一种结合了RAdam和Lookahead的优化算法。它比传统的SGD或Adam更高效,能够在复杂的多类别分类任务中实现更快的收敛和更好的性能。lr=1e-3设置了学习率。criterion = nn.CrossEntropyLoss():使用交叉熵损失函数(CrossEntropyLoss),这是多类别分类任务中最常用的损失函数。它能够衡量模型输出的概率分布与真实标签之间的差异。
暂时无法在飞书文档外展示此内容
model.train():将模型设置为训练模式。这一步很重要,因为它启用了诸如Dropout等训练时特有的操作。for epoch in range(num_epochs):定义训练的轮次。num_epochs参数控制模型将经过多少次完整的训练集迭代。images, labels = data:从数据加载器中获取图像及其对应的标签。images, labels = images.to(device), labels.to(device):将图像和标签移动到GPU或CPU上,具体取决于设备配置。optimizer.zero_grad():每个训练步骤开始前,将优化器中的梯度清零,以避免梯度累积。outputs = model(images):将图像输入模型,获得预测结果。loss = criterion(outputs, labels):计算模型输出与真实标签之间的损失。loss.backward():进行反向传播,计算每个参数的梯度。optimizer.step():更新模型的参数,使得损失减少。running_loss += loss.item() * images.size(0):累计当前批次的损失值。epoch_loss = running_loss / len(dataloader.dataset):计算平均损失,输出每个epoch的损失值。
4. 模型评估与可视化
暂时无法在飞书文档外展示此内容
model.eval():将模型设置为评估模式,停用Dropout等仅在训练时启用的操作。with torch.no_grad():在评估时禁用梯度计算,以减少内存开销并提高评估效率。outputs = model(images):将测试集的图像输入模型,获得输出。_, predicted = torch.max(outputs, 1):通过torch.max函数获取每个图像的预测类别。accuracy_score, precision_score, recall_score, f1_score:计算多种评估指标,包括准确率、精确率、召回率和F1评分。这些指标帮助全面衡量模型的性能。
6. 模型优缺点评价
模型优点:
- 高效的特征提取能力:该项目使用EfficientNet-B6模型,该模型通过复合缩放技术在保证高精度的同时减少了计算开销。对于皮肤镜图像这种高分辨率且细节丰富的数据,EfficientNet-B6能够有效提取细微特征,帮助模型更好地区分类别。
- 迁移学习的应用:使用预训练的EfficientNet-B6模型,使得训练过程更加高效,并且在皮肤镜图像分类任务上能快速达到较好的精度。预训练的权重来自ImageNet大规模数据集,提供了很好的初始特征表示,减少了训练所需的数据量和时间。
- 创新的优化器选择:项目选择了Ranger优化器,这是结合了RAdam和Lookahead两种优化策略的混合优化器,能够在复杂的多类别分类任务中实现更快的收敛和更好的模型性能。
- 多种评估指标:模型不仅采用了准确率作为评估标准,还包括精确率、召回率和F1评分,确保模型在不平衡数据集下能够综合评估分类效果,全面衡量模型性能。
模型缺点:
- 数据增强不足:代码中未显示数据增强的详细实现。对于医学影像这种可能存在数据不均衡和有限的数据集,数据增强(如旋转、翻转、随机裁剪等)可以进一步提升模型的鲁棒性,减少过拟合。
- 分类器输出层较单一:虽然分类器输出被调整为适合皮肤病变的5个类别,但仍然可以考虑进一步调整分类器的结构,使得其更好适应特定的医学图像分类任务。
- 超参数调整有限:项目中使用的学习率为1e-3,但未进行其他超参数(如batch size、学习率衰减等)的探索,这可能导致模型在某些情况下无法充分发挥其潜力。
改进方向:
- 数据增强:可以增加数据增强方法,如旋转、随机裁剪、颜色抖动等,以提高模型对不同变形图像的鲁棒性,尤其在医学图像领域,这对小样本数据非常有帮助。
- 模型结构优化:可以尝试在EfficientNet的基础上增加特定的医学图像分类模块,如多分支网络或注意力机制,进一步提升模型的特征提取能力。
- 超参数调优:进行更多的超参数搜索,如学习率、优化器类型、batch size等,找到最优的组合以提升模型的训练速度和最终性能。
- 多任务学习:引入多任务学习,结合分类任务和分割任务,进一步提升模型的泛化能力。
👍感谢小伙伴们点赞、关注! 如有其他项目需求的,可以在评论区留言,抽空制作更新!
✌粉丝福利:点击下方名片↓↓↓
回复暗号:13,免费获取600多个深度学习项目资料,快来加入社群一起学习吧。
相关文章:
EfficientNet-B6模型实现ISIC皮肤镜图像数据集分类
项目源码获取方式见文章末尾! 回复暗号:13,免费获取600多个深度学习项目资料,快来加入社群一起学习吧。 《------往期经典推荐------》 项目名称 1.【基于opencv答题卡识别判卷】 2.【卫星图像道路检测DeepLabV3Plus模型】 3.【G…...
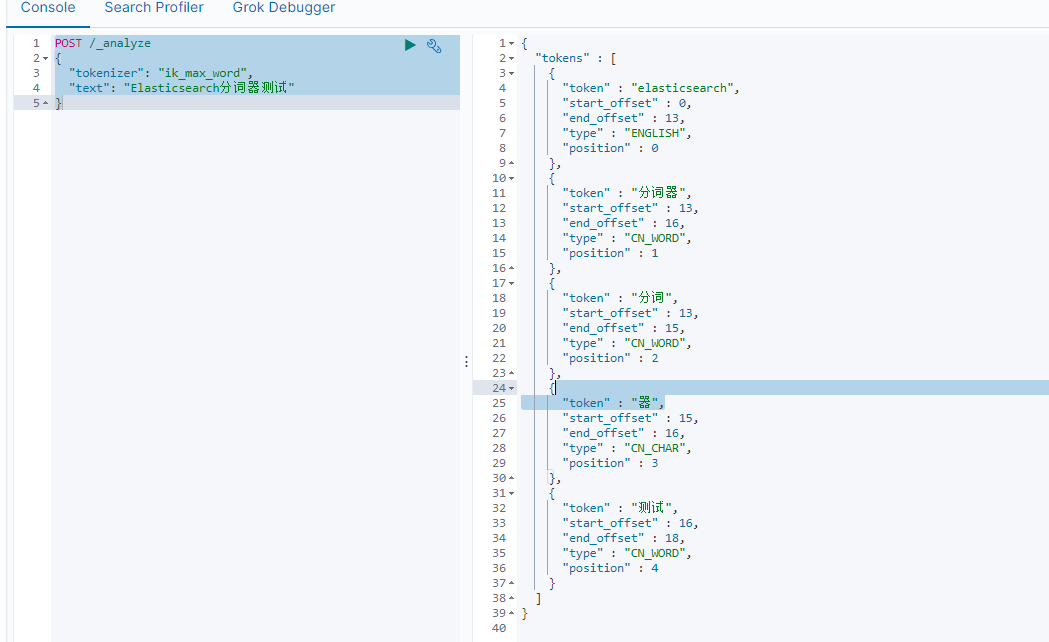
Elasticsearch分词器基础安装
简介 Elasticsearch (ES) 是一个基于 Lucene 的搜索引擎,分词器是其核心组件之一,负责对文本数据进行分析和处理。 1. 文本分析 分词器将输入的文本拆分成一个个单独的词(tokens),以便后续的索引和搜索。例如&#x…...

Django-邮件发送
邮件相关协议: SMTP(负责发送): IMAP(负责收邮件): POP3(负责收邮件): 两者区别: Django发邮件: 邮箱相关配置: settings中&…...

SchooWeb2--基于课堂学习到的知识点2
SchoolWeb2 form表单input控件中各type中value值含义 默认值 text password hidden 提交给服务器的值 select option radio属性的name含义 name值相同表示是同一组单选框中的内容 script的位置 head标签 在head中使用script可以保证在页面加载时进行加载ÿ…...

Android.mk 写法
目录放在odm/bundled_uninstall_back-app/VantronMdm/VantronMdm.apk LOCAL_PATH : $(my-dir) include $(CLEAR_VARS) LOCAL_MODULE : VantronMdm LOCAL_MODULE_CLASS : APPS LOCAL_MODULE_PATH : $(TARGET_OUT_ODM)/bundled_uninstall_back-app LOCAL_SRC_FILES : $(LOCAL_M…...

精通Javascript 函数式array.forEach的8个案例
JavaScript是当今流行语言中对函数式编程支持最好的编程语言。我们继续构建函数式编程的基础,在前文中分解介绍了帮助我们组织思维的四种方法,分别为: array.reduce方法 帮你精通JS:神奇的array.reduce方法的10个案例 array.map方…...

忘记无线网络密码的几种解决办法
排名由简单到复杂 1网线直连; 2查看密码备份文件; 3问人要密码; 4已连接无线设备生成二维码扫描即可上网; 5路由器有wps功能,设备输入pin码可上网; 6已连接电脑右键wifi名,选择属性,…...

git add你真的用明白了吗?你还在无脑git add .?进入暂存区啥意思?
git add 命令用于将文件的改动添加到暂存区(staging area),为下一次提交做好准备。简单来说,它标记了哪些文件或改动会被纳入下次 git commit 中。以下是 git add 的作用和使用场景: 1. 作用 git add 将指定文件或文…...

Vue-Route
一、相关理解 1. vue-router的理解 vue的一个插件库,专门用来实现SPA应用 2. 对SPA应用的理解 单页Web应用整个应用只有一个完整的页面点击页面中的导航链接不会刷新页面,只会做页面的局部更新数据需要通过ajax请求获取 3. 路由的理解 什么是路由 …...

字符串逆序(c语言)
错误代码 #include<stdio.h>//字符串逆序 void reverse(char arr[], int n) {int j 0;//采用中间值法//访问数组中第一个元素和最后一个元素//交换他们的值,从而完成了字符串逆序//所以这个需要临时变量for (j 0; j < n / 2; j){char temp arr[j];arr[…...
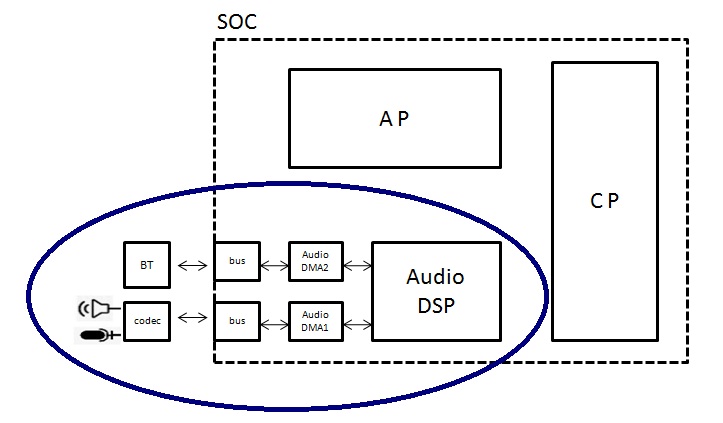
芯片上音频相关的验证
通常芯片设计公司(比如QUALCOMM)把芯片设计好后交由芯片制造商(比如台积电)去生产,俗称流片。芯片设计公司由ASIC部门负责设计芯片。ASIC设计的芯片只有经过充分的验证(这里说的验证是FPGA(现场…...
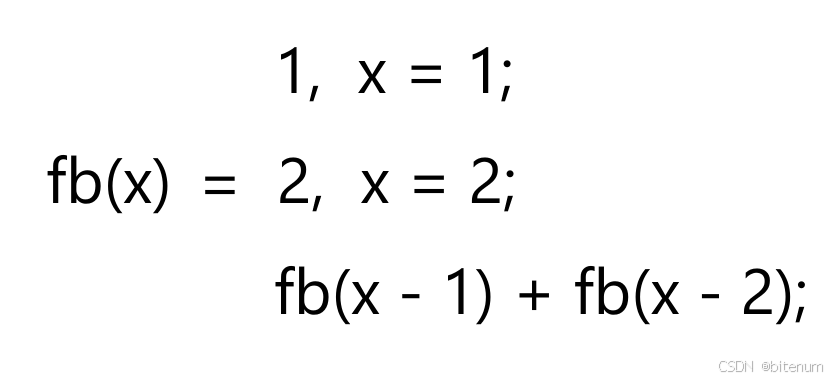
【C/C++】函数的递归
1.什么是递归? 递归就是递推和回归,以数学函数f(x) x为例: 递推:f(x) f(x - 1) 1 ; f(x - 1) f(x - 2) 1 ; f(x - 2) …… 回归:……; f(x - 2) f(x - 1) 1 ; f(x - 1) f(x) 1; 可以看出, 递推和…...

《链表篇》---两两交换链表中的节点(中等)
题目传送门 1.定义一个虚拟节点链接链表 2.定义一个当前节点指向虚拟节点 3.在当前节点的下一个节点和下下一个节点都不为null的情况下。 定义 node1和node2。保存当前节点后面两个节点的地址。cur.next node2;node1.next node2.next;node2.next node1;cur node1; 4.返回re…...

Fakelocation 步道乐跑(Root真机篇)
前言:需要 Fakelocation,真机Root,步道乐跑,Dia,MT管理器系统需求 Fakelocation | MT管理器 | Dia | 环境模块 任务一 真机Root(德尔塔,过momo,刷环境模块) 任务二 前往Dia查看包名(…...
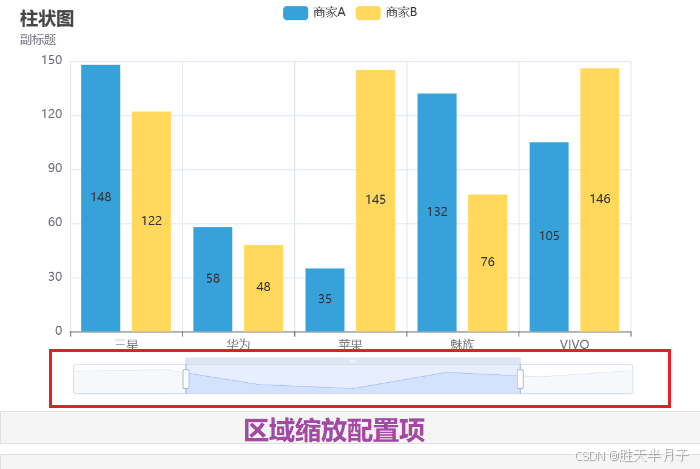
PyEcharts | 全局配置项中初始配置项和区域缩放配置项的使用
全局配置项可通过set_global_opts方法设置 一个图像主要的内容 引入包 from pyecharts.charts import Bar,Line from pyecharts import options as opts from pyecharts.faker import Faker from pyecharts.globals import ThemeType,RenderTypefrom pyecharts.globals imp…...

突破语言壁垒:Cohere 发布多语言大模型 Aya Expanse
前沿科技速递🚀 在多语言大模型领域,Cohere 再次迎来了突破!10月24日,Cohere的研究实验室 Cohere For AI 正式发布了最新的多语言AI模型家族 —— Aya Expanse。该系列模型开放了8B和32B参数两个版本,为全球AI爱好者带来了崭新的多…...

内容安全与系统构建加速,助力解决生成式AI时代的双重挑战
内容安全与系统构建加速,助力解决生成式AI时代的双重挑战 0. 前言1. PRCV 20241.1 大会简介1.2 生成式 Al 时代的内容安全与系统构建加速 2. 生成式 AI2.1 生成模型2.2 生成模型与判别模型的区别2.3 生成模型的发展 3. GAI 内容安全3.1 GAI 时代内容安全挑战3.2 图像…...

Scrapy源码解析:DownloadHandlers设计与解析
1、源码解析 代码路径:scrapy/core/downloader/__init__.py 详细代码解析,请看代码注释 """Download handlers for different schemes"""import logging from typing import TYPE_CHECKING, Any, Callable, Dict, Gener…...

shell基础-awk
awk 是一个强大的文本处理工具,广泛用于 Unix 和 Linux 系统中。它可以用来处理和分析文本文件,特别是那些包含结构化数据的文件。以下是 awk 的基础知识和一些常用示例。 基本概念 记录和字段: 记录:awk 处理的每一行文本称为一…...

@Controller 和 @RestController 区别
功能范畴: Controller:用于定义一个控制器类,主要用于处理用户请求并返回视图(通常是HTML页面)。常常与 Spring MVC 的视图解析器一起使用。RestController:是一个特殊类型的控制器,用于返回数据而不是视图…...

终极Vue 3日期时间选择器:如何构建企业级日期处理解决方案
终极Vue 3日期时间选择器:如何构建企业级日期处理解决方案 【免费下载链接】vue3-date-time-picker Datepicker component for Vue 3 项目地址: https://gitcode.com/gh_mirrors/vu/vue3-date-time-picker Vue3-DateTime-Picker是一个基于Vue 3 Composition …...

基于RAG与代码专用嵌入模型构建本地智能代码库问答系统
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“smart-codebase”。光看名字,你可能觉得这又是一个关于代码智能化的工具,但仔细研究其设计和实现思路,你会发现它瞄准的是一个非常具体且高频的痛点:如…...

量子生成分类技术:原理、优势与应用解析
1. 量子生成分类技术概述量子生成分类(Quantum Generative Classification, QGC)是一种基于量子计算原理的新型机器学习范式,它从根本上改变了传统分类任务的实现方式。与常见的判别式学习方法不同,QGC采用生成式学习策略…...

高光谱图像分类避坑指南:Hughes现象、同物异谱,这些坑你踩过吗?
高光谱图像分类实战避坑手册:从Hughes现象到模型优化的深度解析 当你的高光谱分类模型在验证集上表现优异,却在真实场景中频频失误时,或许正遭遇着这个领域特有的"暗礁"。不同于常规RGB图像分类,高光谱数据特有的图谱合…...

抖音无水印视频下载全攻略:douyin-downloader开源工具终极指南
抖音无水印视频下载全攻略:douyin-downloader开源工具终极指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallba…...

基于SpringBoot+Vue的CRM客户管理系统毕设
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Vue框架的CRM客户管理系统以解决传统客户关系管理中存在的信息孤岛现象与业务流程低效问题。当前企业客户管理普遍面临数据…...
增强代码的层级结构注意事项)
不使用void HAL_TIM_Encoder_MspInit(TIM_HandleTypeDef* tim_encoderHandle)增强代码的层级结构注意事项
这是正常用cube Max生成的代码,这里以设置编码器为例。 GPIO初始化函数放在HAL_TIM_Encoder_MspInit这个回调函数中。代码正常运行/* TIM3 init function */ void MX_TIM3_Init(void) {TIM_Encoder_InitTypeDef sConfig {0};TIM_MasterConfigTypeDef sMasterConfig…...
)
别再手动改配置了!Spring Boot项目集成Apollo配置中心保姆级教程(含热更新实战)
Spring Boot与Apollo配置中心深度整合:告别重启的配置管理革命 在微服务架构盛行的今天,传统配置文件管理方式正面临前所未有的挑战。每次修改数据库连接池参数需要重启服务?调整线程池大小必须中断业务?这些困扰Java开发者多年的…...

【RS-M1系列-2】揭秘螺旋扫描:RS-M1如何重塑点云数据格局
1. 螺旋扫描:RS-M1的核心创新点 第一次拿到RS-M1的点云数据时,我就被它独特的螺旋扫描模式惊艳到了。与传统机械旋转式雷达那种"转圈圈"的扫描方式完全不同,RS-M1的5个激光通道通过一面振镜实现了螺旋状的扫描轨迹。这就像用五支笔…...

为什么92%的开发者首次调用PlayAI翻译API会触发token溢出?3步诊断清单+4类典型错误码速查表
更多请点击: https://intelliparadigm.com 第一章:PlayAI多语种同步翻译功能详解 PlayAI 的多语种同步翻译功能基于端到端神经机器翻译(NMT)架构,支持实时语音流输入与毫秒级文本输出,覆盖中、英、日、韩…...