EMR Serverless Spark:一站式全托管湖仓分析利器
本文根据2024云栖大会实录整理而成,演讲信息如下:
演讲人:
李钰(绝顶) | 阿里云智能集团资深技术专家,阿里云 EMR 团队负责人
活动:
2024 云栖大会 AI - 开源大数据专场
数据平台技术演变
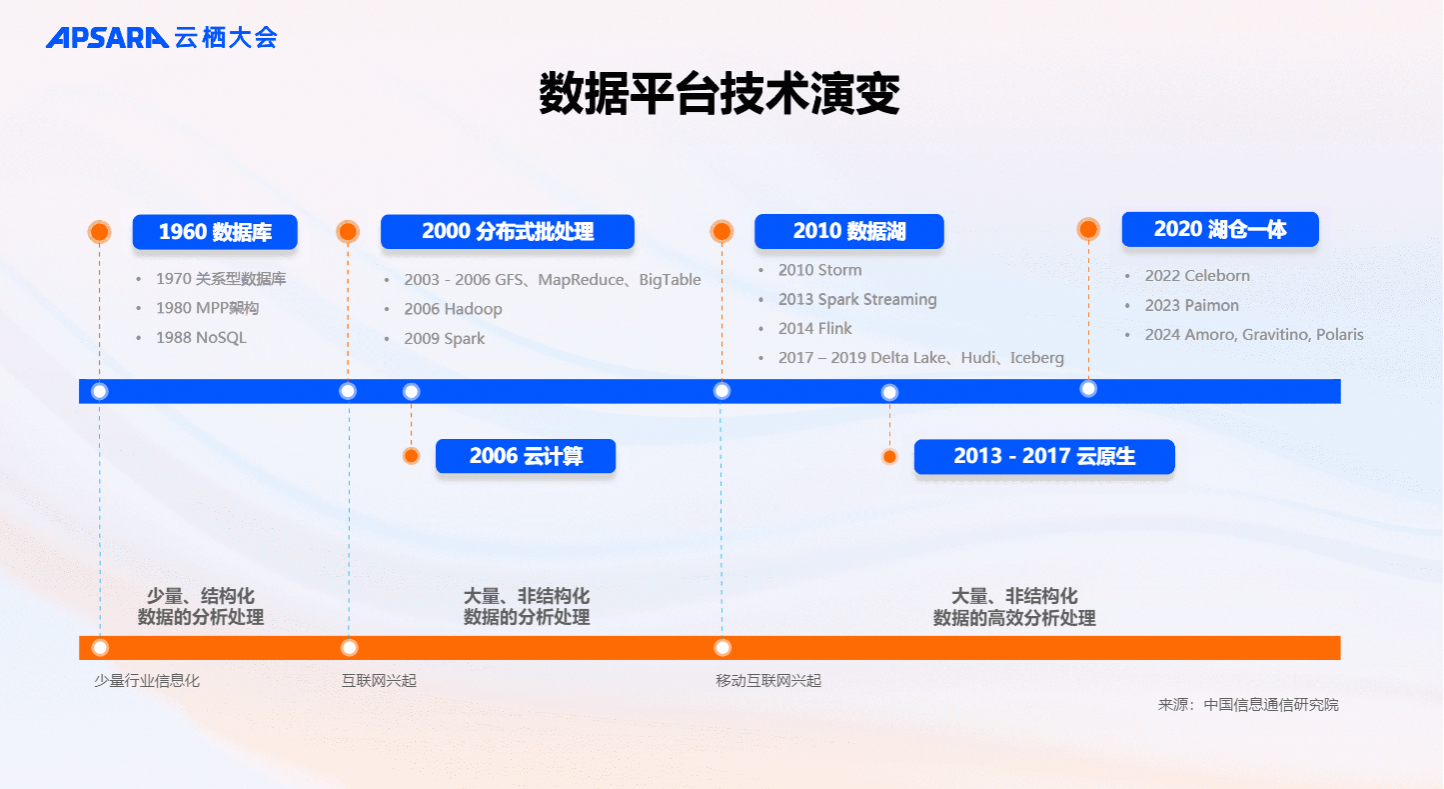
追溯数据处理软件及平台的演进历程,每一次大的架构升级与变迁都是由全球范围的新兴应用出现和落地触发的。具体来说,20世纪60-70年代数据库技术出现,数据库技术的普及和落地与个人计算机(PC)兴起的浪潮息息相关。直至21世纪初互联网应用爆发前,单机数据库技术在数据处理领域一直占据着统治地位。
进入21世纪,国外以Google的搜索引擎、Facebook的社交网络、Amazon的电子商务为标志,国内以百度、腾讯、阿里等为领军,标志着互联网应用开始大范围普及。互联网应用的普及,逐渐反映出传统单机数据库系统在处理能力与扩展性上存在的局限性难以支撑新兴业务的高速增长。Google在2003年发布了Google File System、2004年发布了MapReduce论文,标志着大数据技术时代的到来,引领了以Hadoop、HBase、Hive等为代表的开源大数据技术的兴起与发展。
随后,2007年iPhone的问世引领了智能手机时代的到来,推动移动互联网的兴起与应用多元化,进一步催生了计算引擎的发展。大约从2010年开始,以Apache Spark为代表的批处理引擎、以Apache Flink为代表的流处理引擎、以Presto为代表的OLAP分析引擎,逐渐成为数据处理领域的主流技术,满足了复杂多变的计算需求。
至2017年左右,随着直播与短视频等多媒体内容的爆发,数据形态趋向多模态,对数据处理框架的灵活性提出了更高要求。这一背景下,数据湖技术应运而生,旨在应对数据多样性带来的挑战。而2022年大语言模型的登场,揭开了人工智能应用时代的序幕,AI生成内容(AIGC)的飞速发展,不仅促使数据规模呈指数级增长,还进一步提升了非结构化、多模态数据的占比,对数据处理技术提出了全新的挑战与机遇。
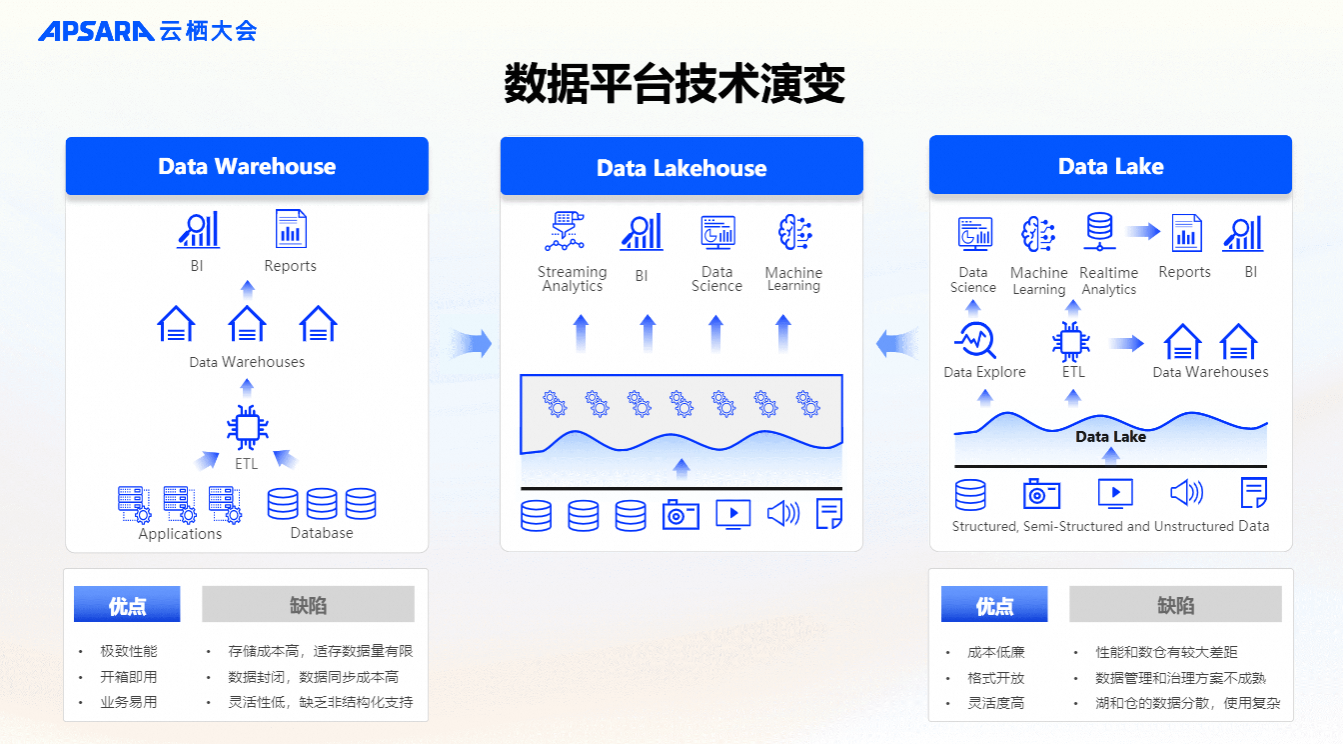
面对这些新兴挑战,传统数据架构显得力不从心,亟需向更适应当前需求的方向演进。传统数据仓库具备高度结构化的特点,开箱即用,然而其高昂的存储成本、较低的数据开放性和灵活性成为了主要痛点。尤其是在需要多场景使用时,如同时支持离线和实时分析的情况下,必须通过数据同步来导入导出,进一步增加了复杂度。随着多媒体数据的增长以及对数据灵活性的要求越来越高,基于对象存储的数据湖架构应运而生,这类架构以其低成本存储和高灵活性著称,同时也采用了更加开放的数据格式。但是,它们在事务支持方面相对较弱,性能上也无法完全取代数据仓库。
鉴于上述情况,往往需要采用混合策略:将相对成熟且价值较高的数据业务应用在数据仓库中进行,而相对新兴对灵活性要求较高的数据业务应用则基于数据湖部署。这种混合策略虽然能够在一定程度上满足需求,但不可避免地带来了额外的数据一致性维护成本以及数据冗余问题,增加了系统的整体复杂性。在AI应用即将普及的新时代背景下,可以预见未来几年内应用领域的变化将会异常迅速,继续沿用旧模式将不再可行,因为这会导致极高的成本支出及难以应对的业务复杂度增长。
因此,我们认为,融合了数据湖与数据仓库优点的数据湖仓一体架构Lakehouse是发展的必然趋势。该架构在数据湖的基础上进一步优化,同时具备数据仓库的能力。具体而言,从架构层面看,数据湖仓可分为三层:
-
底层是湖仓存储层:负责解决数据事务性、一致性与存储有效性。
-
中间层是湖仓管理层:专注于结构化、半结构化和非结构化数据统一元数据管理,解决数据治理及安全问题。
-
最上层是湖仓分析层:由多种计算引擎构成,其中Apache Spark是开源领域经过多年发展的明星项目。
在海外,Databricks已经提供了基于Spark构建的成熟的全托管产品,但在国内市场上仍缺乏相应的产品。为此,阿里云推出了EMR Serverless Spark,旨在填补这一空白,提供一个全面整合的数据湖仓解决方案。
EMR Serverless Spark 功能特性
接下来,我将介绍 EMR Serverless Spark 的主要功能与特性。正如前面提到的,在数据湖仓分析层,我们主要关注两个核心问题。首先,是业务易用性。所谓业务易用性,指的是能否通过一款湖仓分析产品,既能进行大数据处理,又能进行AI、数据科学处理。其次,性能也是一个至关重要的考量因素,在数据湖的基础上,其性能是否可以与传统数仓媲美。除易用性和性能之外,开放性也是不可忽视的一个因素。鉴于数据湖本身强调的是开放性和灵活性,因此EMR Serverless Spark设计时充分考虑了对开源Spark生态系统的全面兼容性。最后,云原生也是需要关注的因素。下面,我将从上述方面进一步展开。

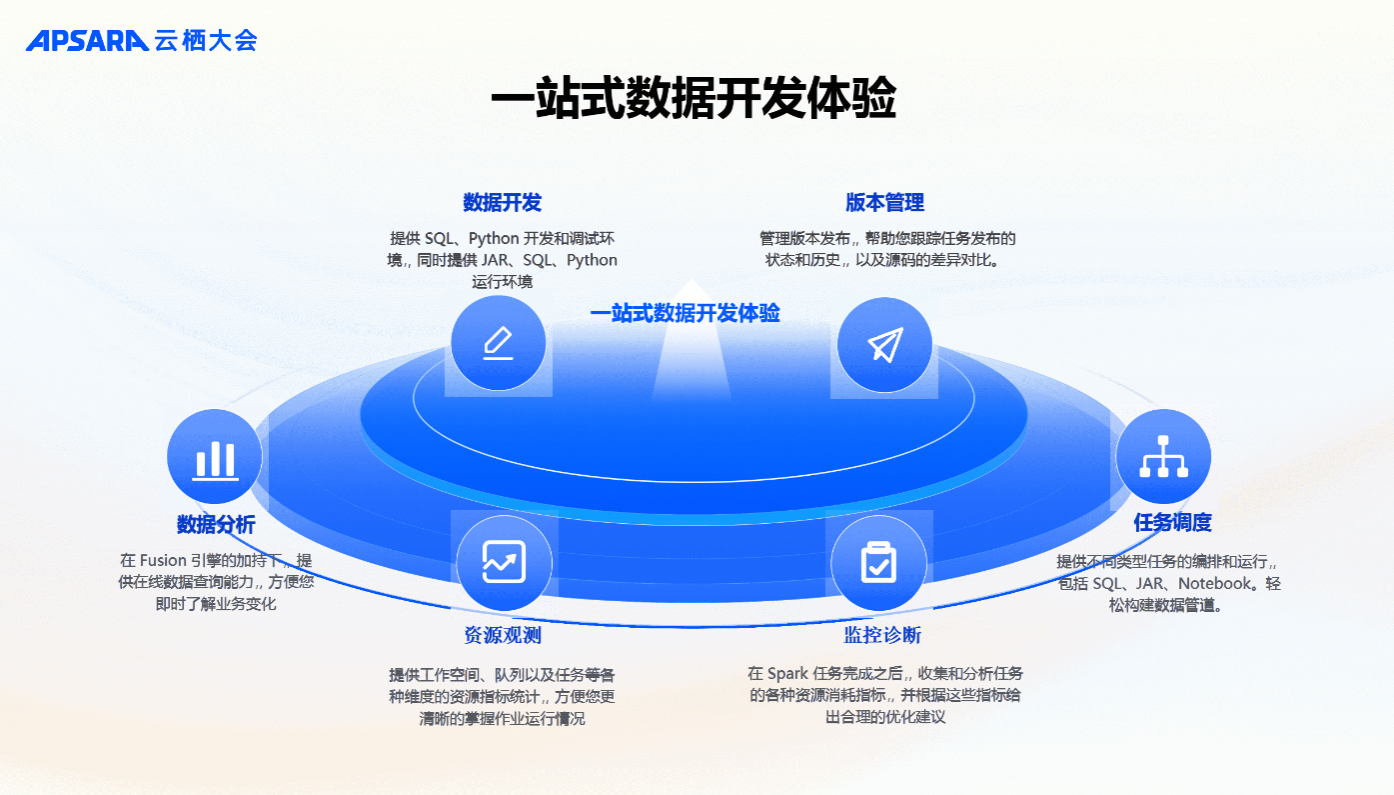
一站式数据开发
首先,从平台能力角度来看,EMR Serverless Spark提供了作业开发、调试、发布、调度等一站式数据开发体验。无论是传统的ETL、交互式数据分析、或者基于Python的数据科学数据业务,都可以基于 EMR Serverless Spark 进行开发。开发之后可以进行版本管理和生产上线,生产上线后,EMR Serverless Spark内置工作流可以进行任务调度,并对任务和工作流进行有效监控,资源使用情况方面也会全面关注。
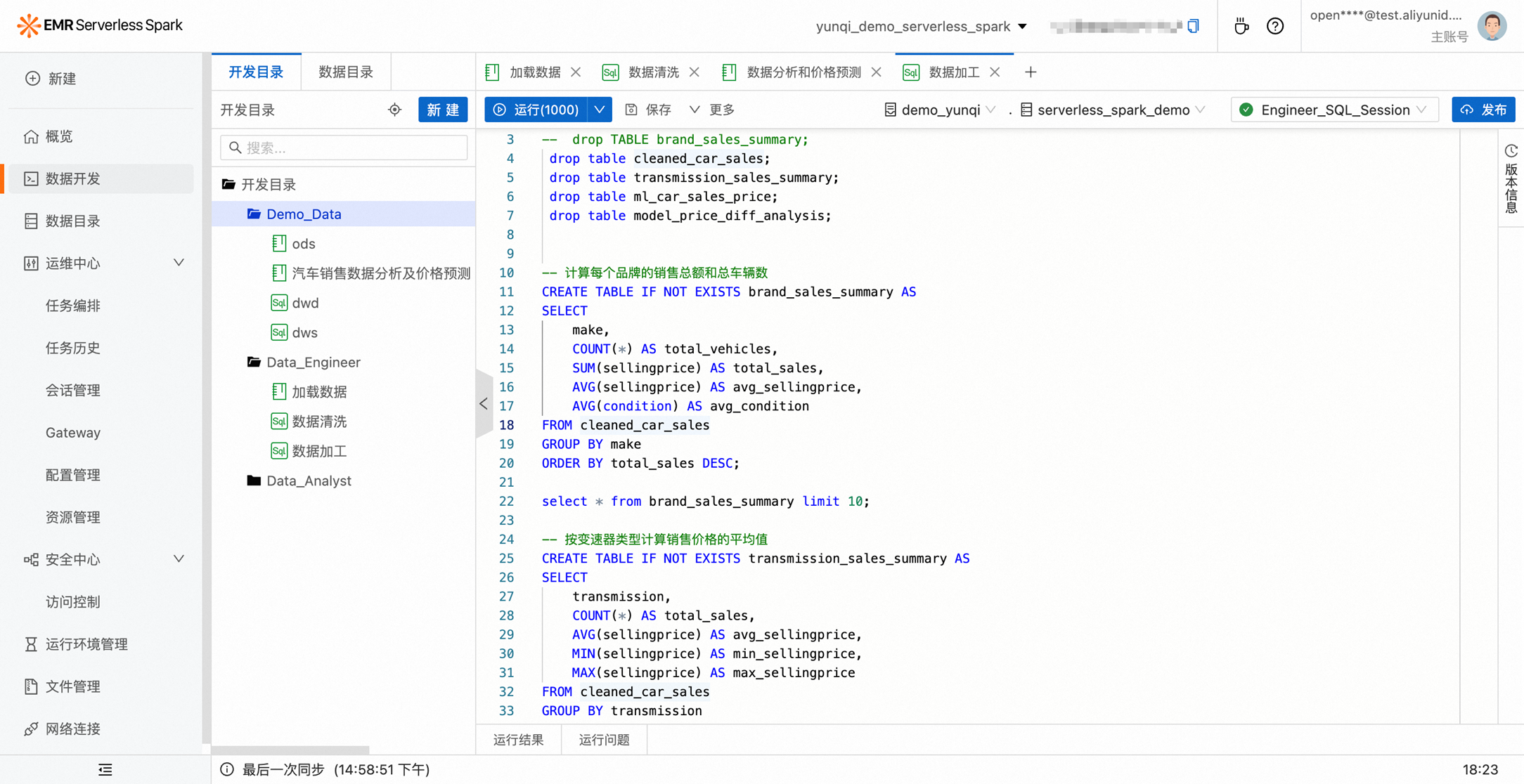
数据开发-内置SQL编辑器
在数据开发层面,EMR Serverless Spark 内置了一个SQL编辑器。支持用户编写 Interactive Query 和 ETLQuery,并支持将不同类型的 Query 提交到不同的资源队列中运行,从而实现对计算资源的有效管理和分配。我们的资源管理体系提供了队列与会话两种形式,便于用户根据需求区分开发环境与生产环境中的工作负载。同时,SQL editor 还支持元数据视图。用户可以看到元数据库表情况,并对这些库表进行增删改查等操作。
数据分析 – Notebook 交互式环境
除了内置 SQL 编辑器之外,EMR Serverless Spark还提供了交互式的Notebook环境。在Notebook中,用户不仅能够编写和执行SQL语句,还能用Python 进行开发,并且可以根据需求灵活地安装各种Python库,例如Pandas。此外,我们还提供了一套完善的运行环境管理。用户可以通过Notebook界面轻松开发大数据AI一体化应用。
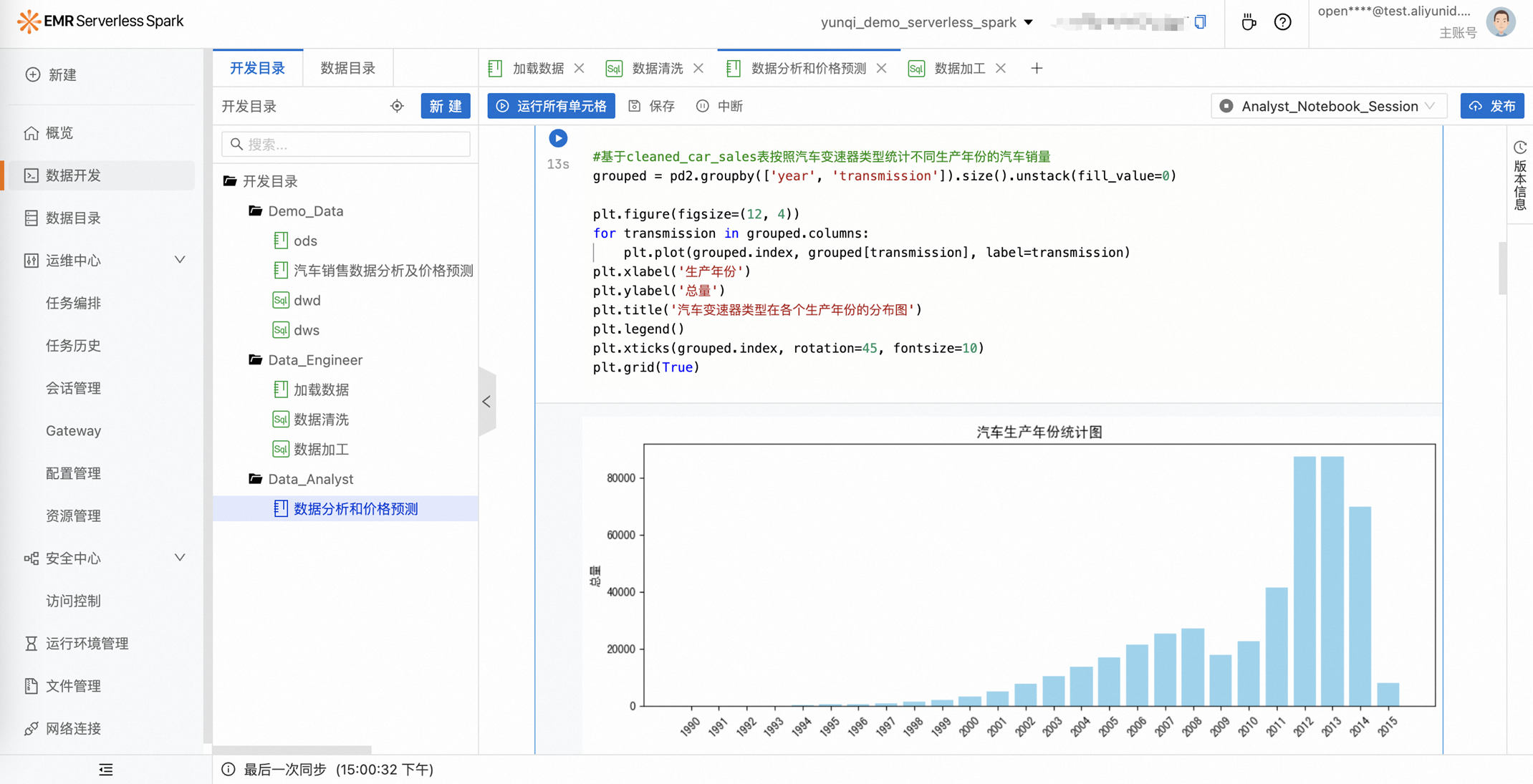
工作流调度
通过SQL编辑器或Notebook完成任务开发后,无论是单个SQL作业还是由多个脚本组成的Notebook作业,都可以通过EMR Serverless Spark 内置工作流进行调度。支持查看工作流运行情况,不同的工作流拓扑,还提供以拖拉拽方式便捷构建工作流的能力。
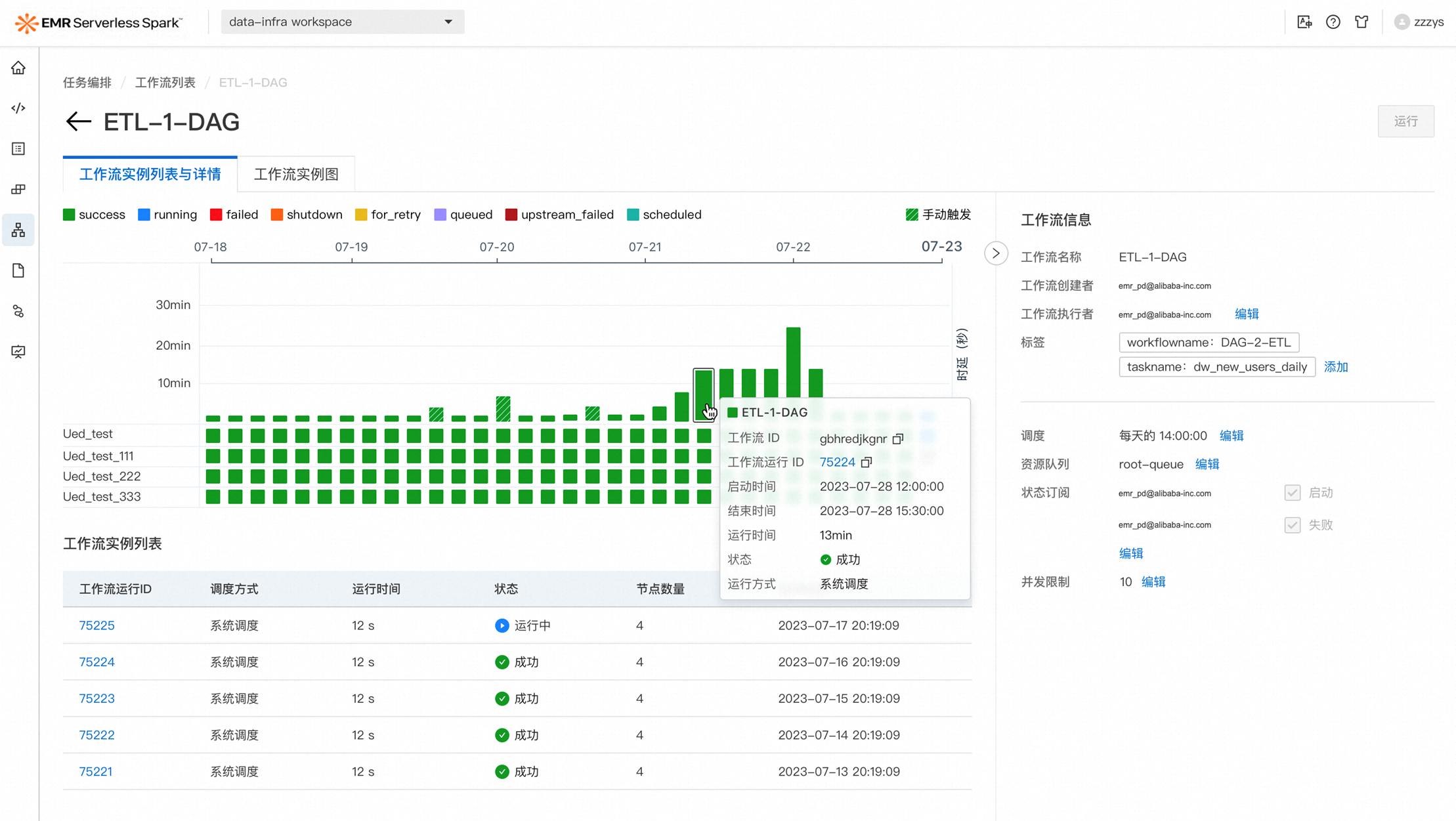
指标大盘
在工作流和任务调度启动后,EMR Serverless Spark支持通过指标大盘查看任务运行状态。提供 Spark 任务实例的 CPU、Memory、JVM、Driver scheduler、Executor – IO、Executor – Shuffle 等指标的可视化展示,还支持通过查看和分析作业CPU时、内存时等聚合性指标,识别性能瓶颈和异常情况,并进行优化和故障排查。
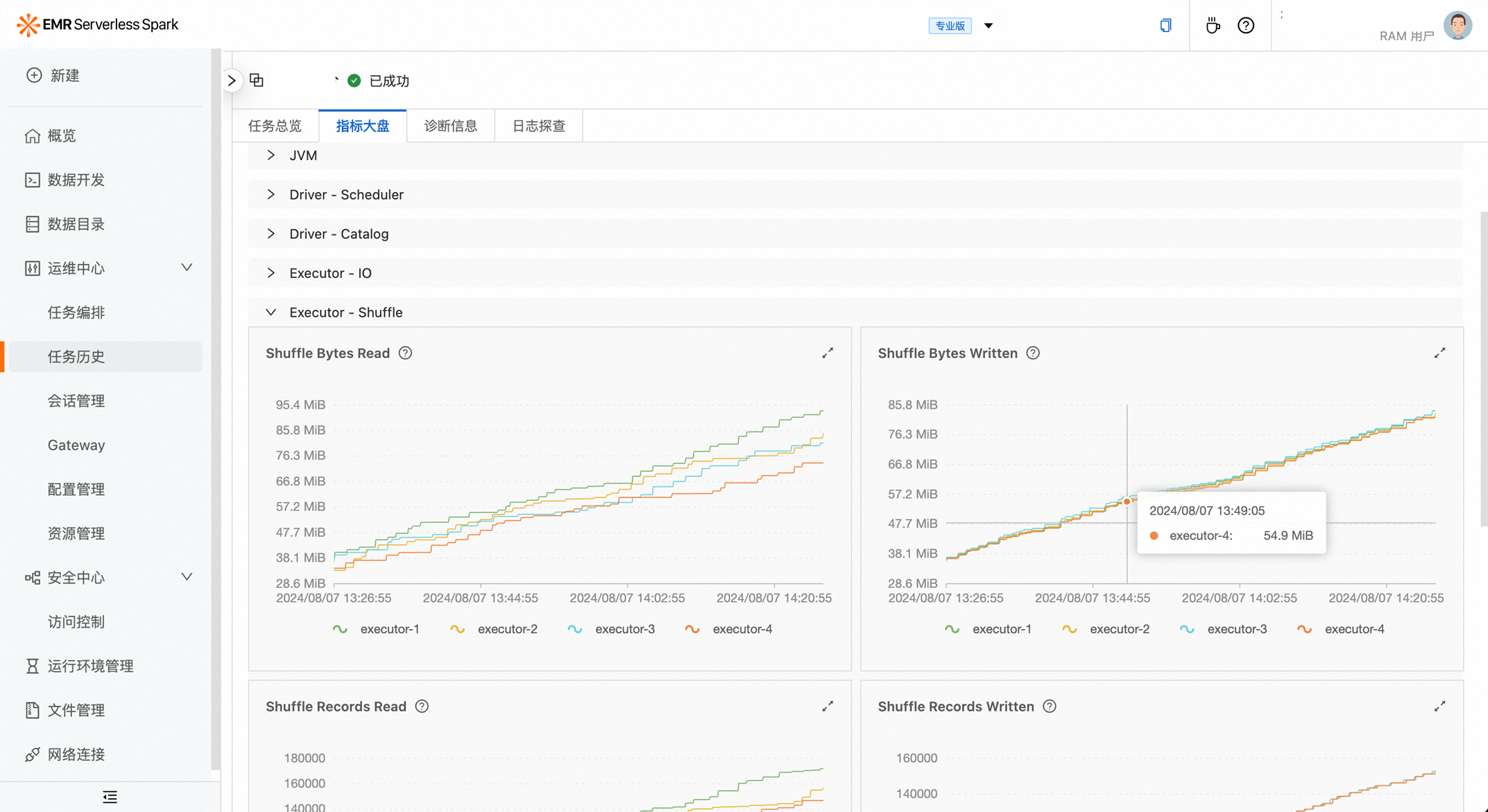
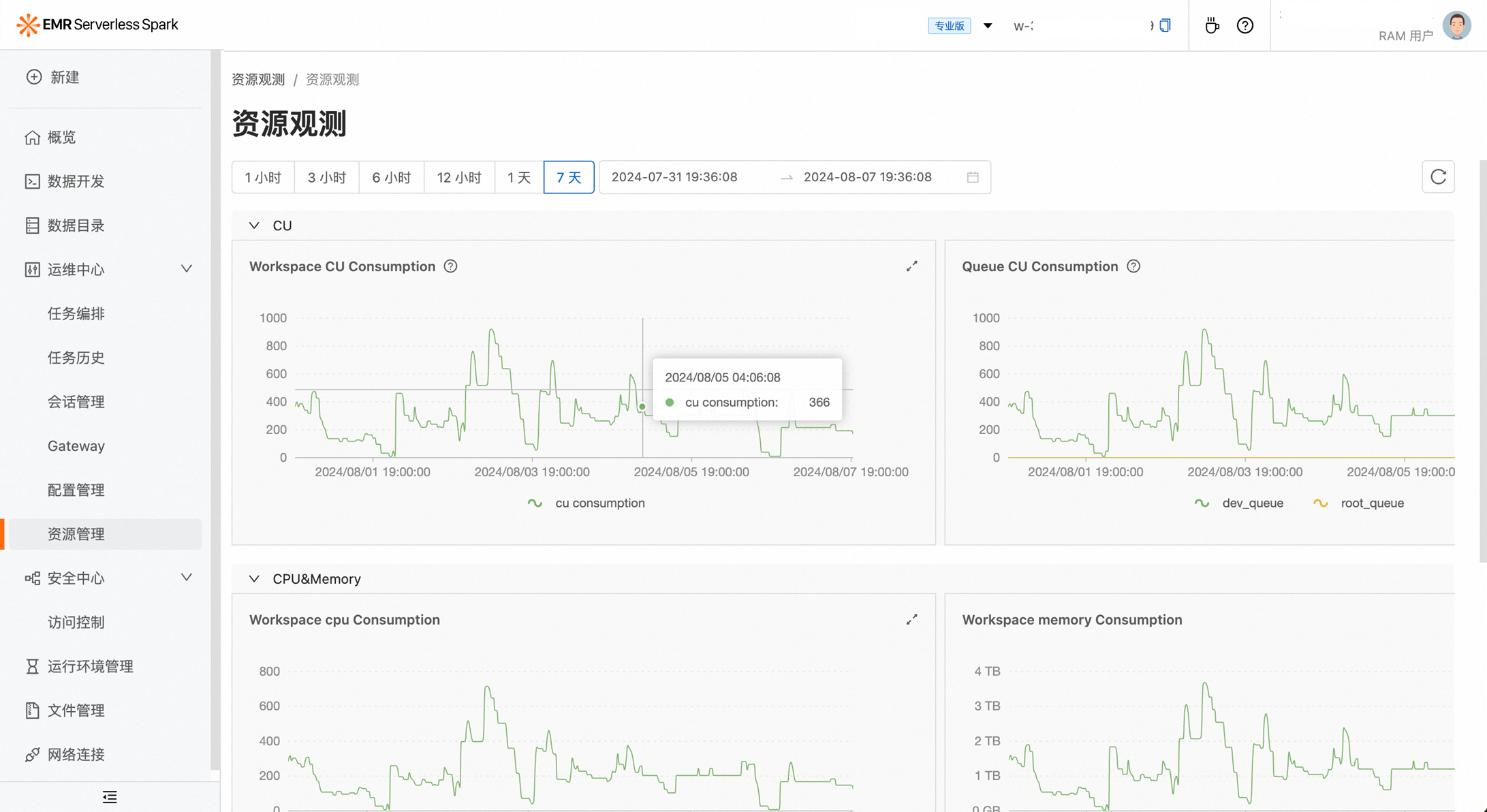
资源观测
此外,EMR Serverless Spark 提供完善的资源观测。用户可以根据部门或业务需求灵活地拆分资源队列。基于这些队列的资源使用情况,可以清晰地了解各个部门及业务线所占用的具体资源量。此外,针对不同队列之间的Quota限制,也支持动态调整。
监控诊断
最后,考虑到作业调优本身是一个相当复杂的过程,所以EMR Serverless Spark 还提供针对单个作业进行一键诊断的能力。能够智能化分析作业是否存在数据倾斜、垃圾回收等方面的异常,并基于诊断结果提供明确建议,以帮助用户更高效地优化作业。
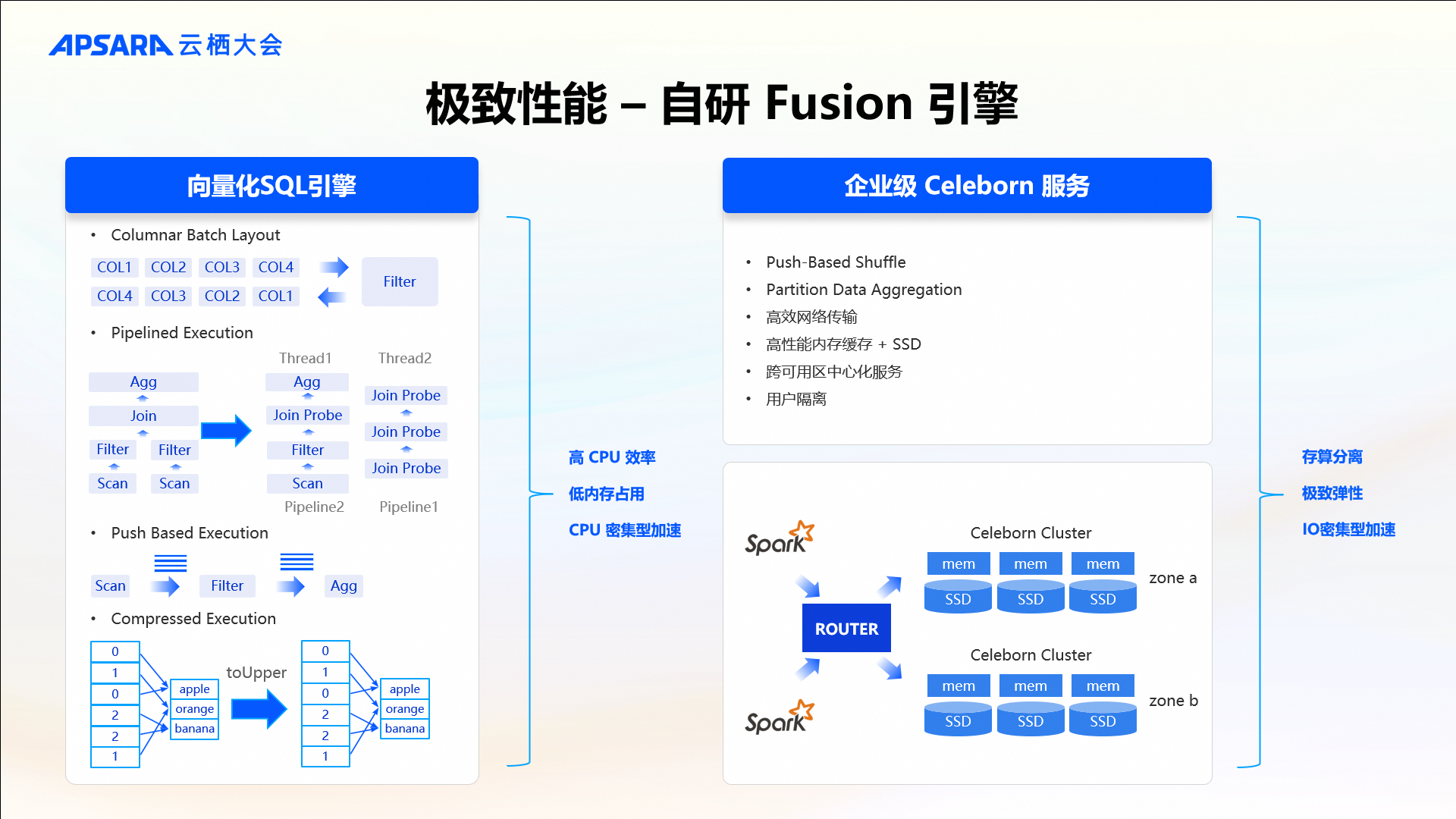
极致性能 - 自研 Fusion 引擎
除了强大的平台能力,EMR Serverless Spark 还提供自主研发的企业级内核—Fusion Engine。这款引擎在两个方面做了极致的性能优化:
-
面向CPU密集型业务:提供基于C++语言实现的 Native 向量化 SQL 引擎,充分利用SIMD指令集加速运算过程,显著降低CPU和内存开销。
-
面向I/O密集型业务:基于我们贡献给Apache社区的开源Celeborn项目,我们内置了Remote Shuffle Service,支持多租户和资源隔离,同时提供极致弹性,实现I/O密集型业务加速。
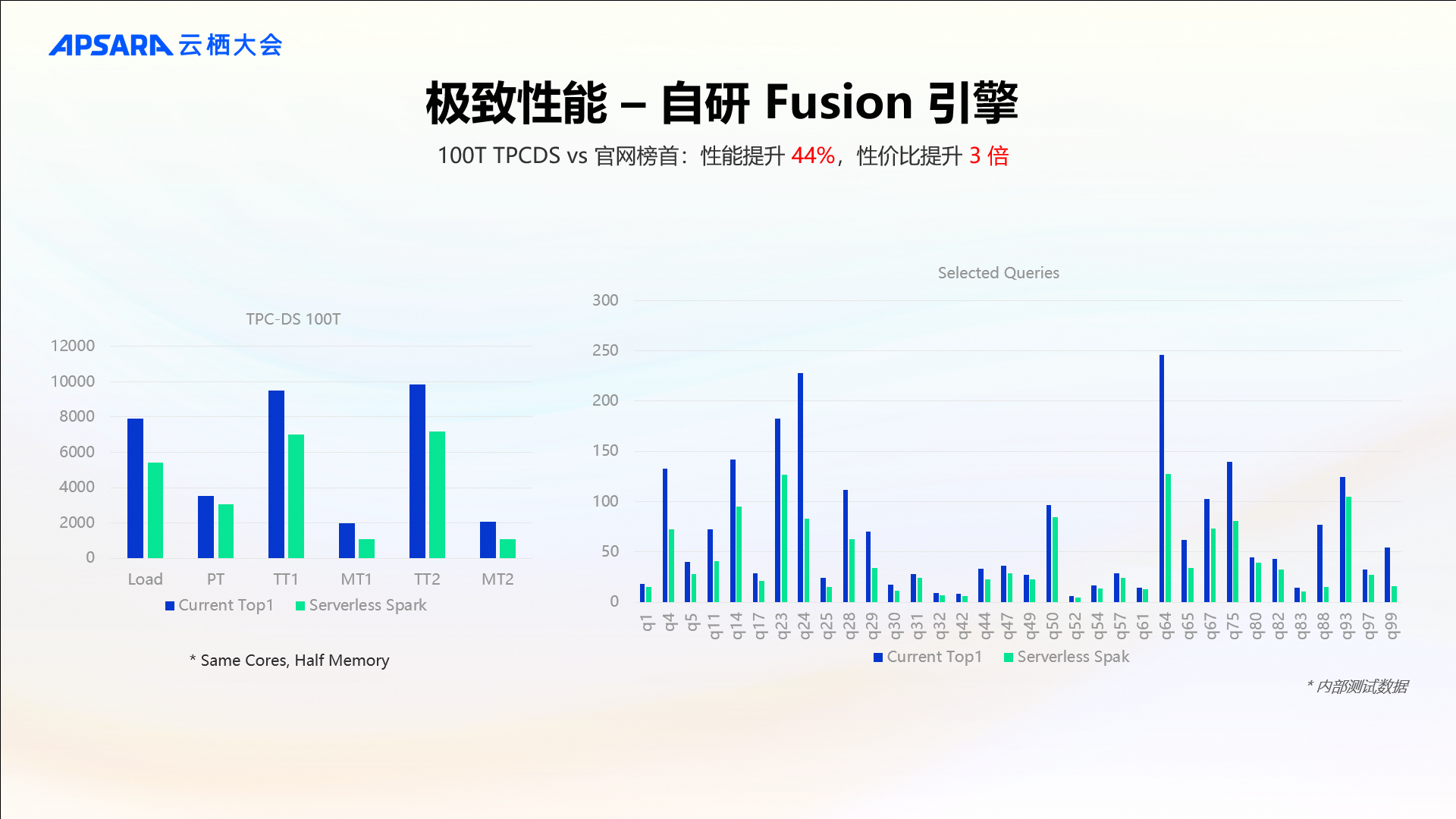
根据TPC-DS基准测试结果表明,在10TB规模下,相较于Apache Spark,EMR Serverless Spark能够实现5倍左右的性能提升;而在更大规模(如100TB)的数据量上,相比TPCDS榜首暨 DataBricks 在2021年提交的成绩,EMR Serverless Spark 则实现了44%左右的性能增长,同时性价比提升3倍。由此可见,EMR Serverless Spark 自研 Fusion 引擎的极致性能。

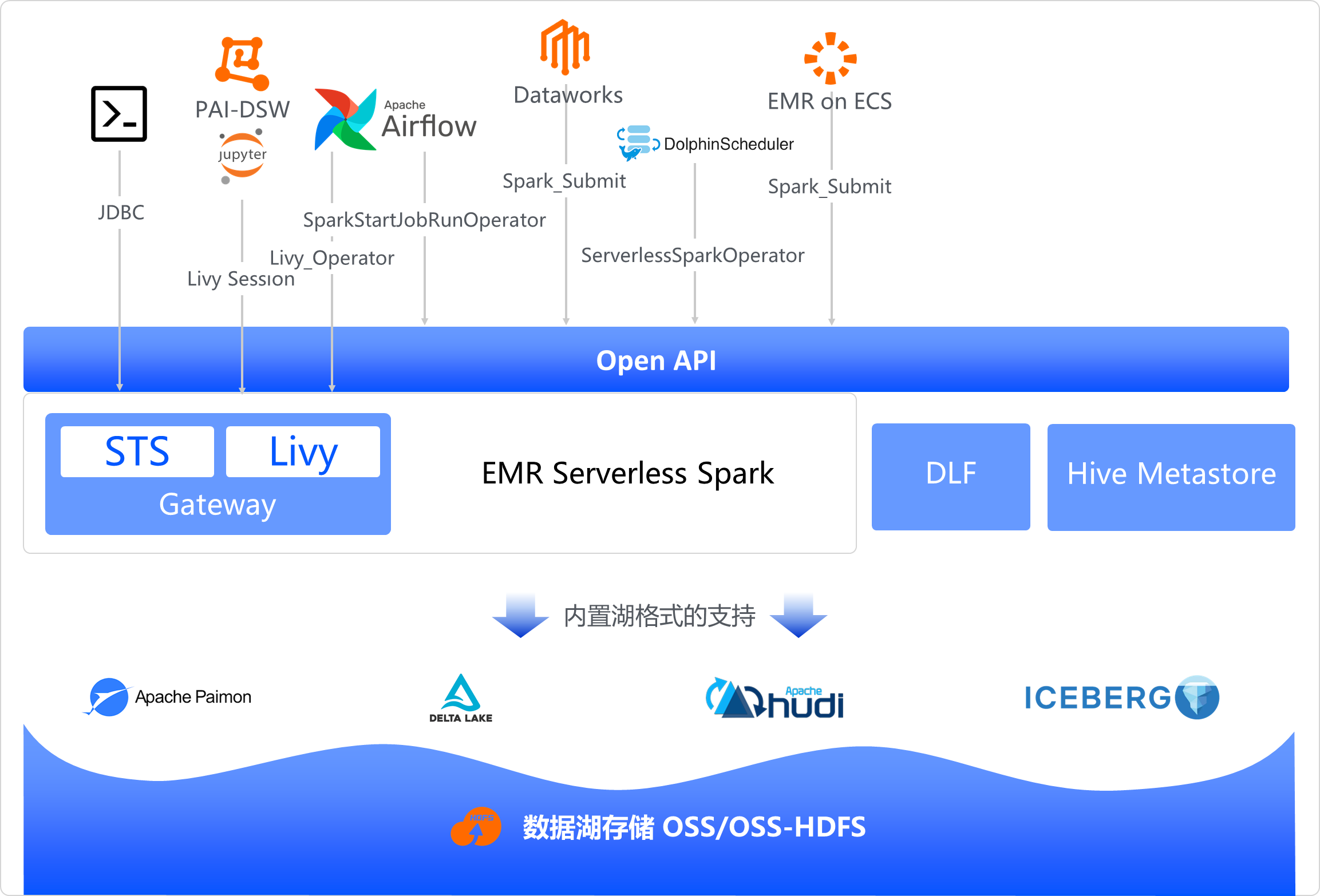
全方位生态兼容
最后值得一提的是,EMR Serverless Spark还具备全方位生态兼容性。它不仅可以无缝对接阿里云 DLF 2.0元数据管理系统和全托管存储解决方案,同时也支持与Hive Metastore等开源元数据管理系统集成,确保使用 HMS + OSS 进行元数据管理和数据存储的场景也能很好的支持。此外,在数据提交方面,EMR Serverless Spark也提供了多种接入方式,包括但不限于Livy Gateway、Thrift Server以及JDBC接口。针对工作流调度,EMR Serverless Spark 基于 OpenAPI 提供官方的 Airflow 和 DolphinScheduler Operator。最后还支持以 Spark_submit 命令提交任务,兼容开源提交方式。通过上述措施,EMR Serverless Spark 致力于打造一个全方位兼容Spark生态系统的数据湖仓分析平台,为广大用户提供更加便携高效的使用体验。
客户案例
接下来,我将向大家介绍两个已经在生产环境中使用 EMR Serverless Spark 的客户案例。
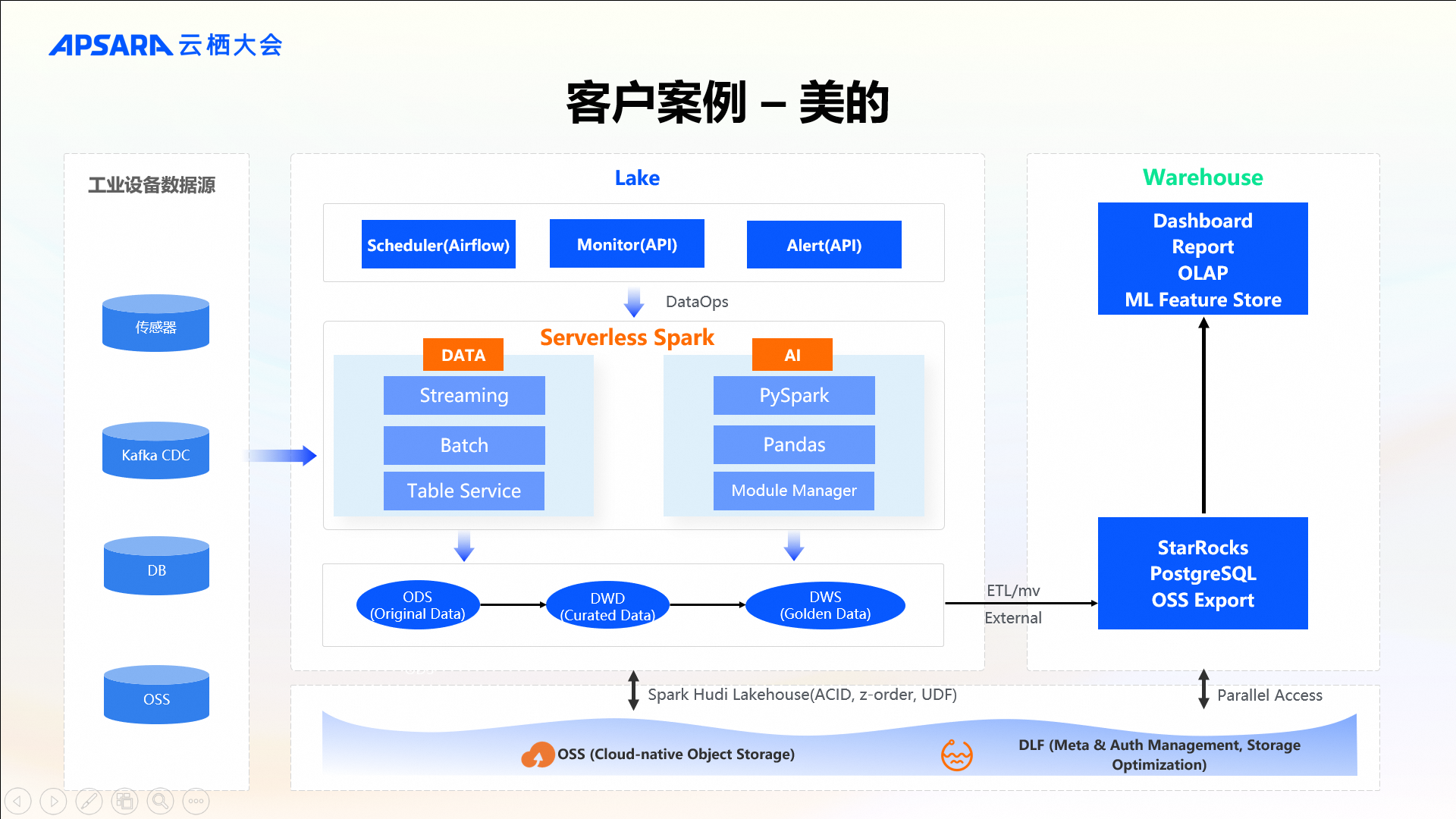
客户案例-美的
美的集团的数据湖仓架构完全基于 EMR Serverless Spark 构建。首先它利用Spark Streaming技术将工业设备数据源中数据流式写入到基于Hudi格式的数据湖仓当中。尽管我们在OpenLake框架内推荐使用Paimon作为首选湖格式,但 EMR Serverless Spark 产品全面支持包括Iceberg、Hudi及Delta Lake在内的多种流行湖存储方案。无论采用何种湖格式,均需进行Compaction 以提升查询效率。在此过程中,美的则充分利用了EMR Serverless Spark提供的资源来进行Compaction。此外,美的使用EMR Serverless Spark 进行数据清洗。从原始的ODS层,基于 EMR Serverless Spark 进行 ETL,然后生成明细数据,再结合业务特点对明细层的数据做进一步抽取,生成更高维的指标供业务使用。在AI应用场景下,美的同样依赖于 EMR Serverless Spark的强大支持。借助 EMR Serverless Spark Notebook能力,开发人员可以安装自定义Python库,结合自研算法,对数据进行聚合与分析。最终,无论是数仓链路产生的数据,还是AI相关的基础数据,都将被统一导出至StarRocks中,以便于企业内部进行 BI 报表分析。综上所述,美的基于 EMR Serverless Spark 进行一站式数据湖仓分析,促进了数字化转型进程中的效率提升与创新实践。
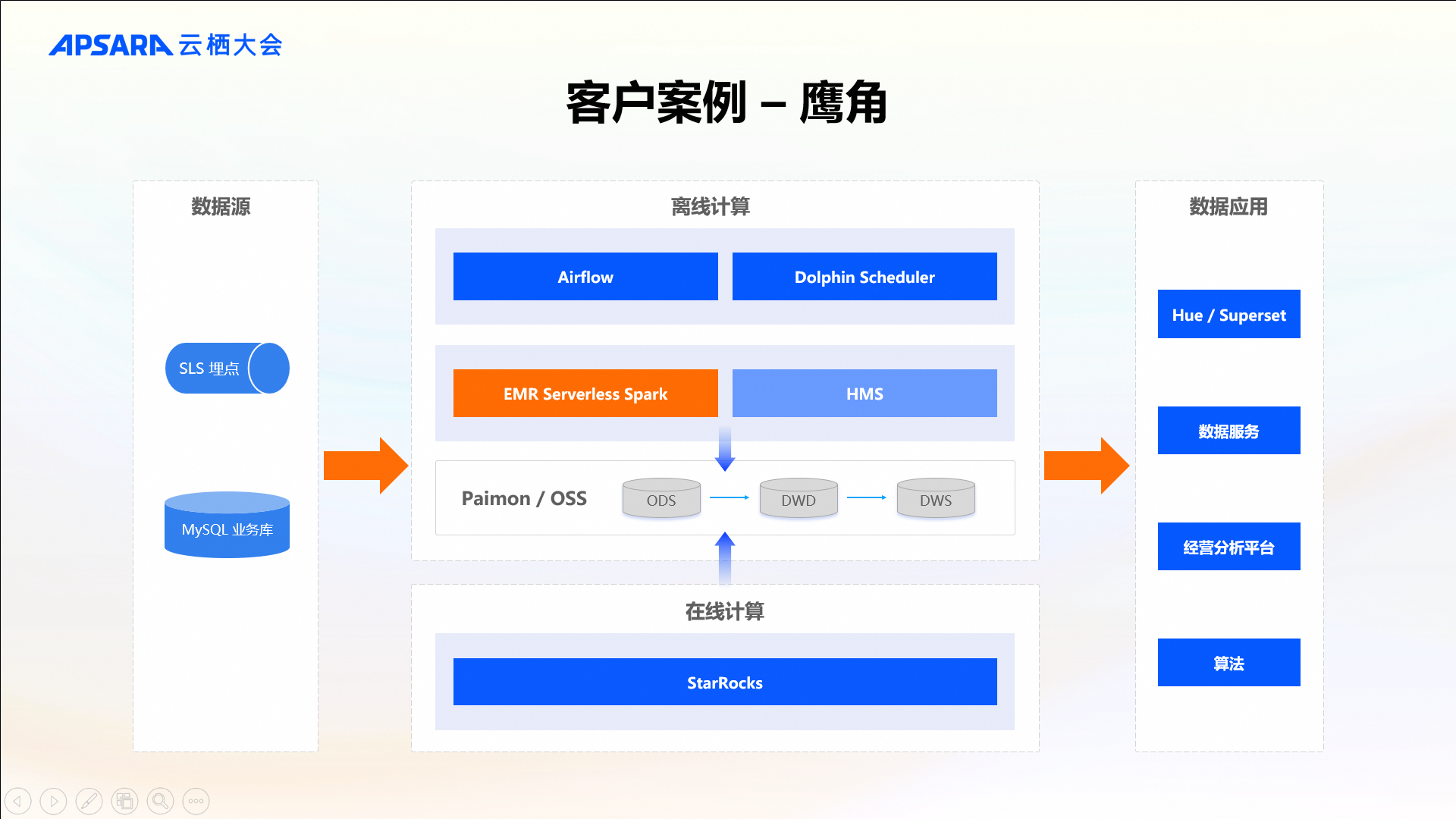
客户案例-鹰角网络
第二个案例是知名游戏公司上海鹰角网络科技,鹰角采用基于 EMR Serverless Spark 的开源兼容解决方案。首先,鹰角使用 Flink CDC 进行数据同步与入湖,采用的是Paion数据湖格式。完成数据入湖之后,整个数仓的数据处理链路则完全基于 EMR Serverless Spark进行数据清洗和提取。值得注意的是,在工作流调度方面,鹰角同时部署了Airflow与DolphinScheduler两种不同的调度框架。对于编码能力较强的数据工程师而言,Airflow 提供了更为灵活且强大的能力以支持构建高度定制化的工作流程;而针对编码能力相对较弱的数据分析师,则可以通过 DolphinScheduler 提供的图形化界面轻松创建并管理相对简单的作业调度计划。无论采用Airflow还是DolphinScheduler进行调度,通过 EMR Serverless Spark 提供的 Operator,都能够无缝接入 EMR Serverless Spark 服务,确保了资源利用效率的最大化以及运维成本的有效控制。鹰角同样选用 StarRocks 作为实时OLAP分析的核心组件;数据展示则是使用Superset。此外,EMR Serverless Spark 也支持海外服务,鹰角海外Region已经开始使用EMR Serverless Spark。
通过以上两个案例可以发现,无论是一站式湖仓分析或大规模离线计算,EMR Serverless Spark 在实际生产环境中都得到了很好的应用。
DEMO
接下来我们以汽车销售场景为例,演示如何利用 EMR Serverless Spark平台,结合 DLF2.0 和 Paimon 构建Lakehouse,完成数据加载、ETL处理、数据可视化和预测分析的全过程。
视频链接:https://cloud.video.taobao.com/vod/nXtj_Ip2TqouF9By57OthZIsoOaWMzgWQaFu0iWyUSc.mp4
阿里云 EMR Serverless Spark 版已于2024年9月14日正式商业化售卖,欢迎体验!
如果您在使用 EMR Serverless Spark 版的过程中遇到任何疑问,可加入钉钉群(群号:58570004119)咨询。
为了助力 LakeHouse 架构在企业中的实践与落地,阿里云 EMR 技术团队联合 Apache Paimon 社区,联合举办“ Apache Spark & Paimon,助力 LakeHouse 架构生产落地”线下 Meetup,邀请阿里云、VIVO、美团等众多业内大咖分享 LakeHouse 架构的核心技术和最佳实践经验,为大数据从业者提供一个开放的分享与交流平台。
点击下方链接或扫描二维码立即报名:https://x.sm.cn/4mJeCkB

相关文章:
EMR Serverless Spark:一站式全托管湖仓分析利器
本文根据2024云栖大会实录整理而成,演讲信息如下: 演讲人: 李钰(绝顶) | 阿里云智能集团资深技术专家,阿里云 EMR 团队负责人 活动: 2024 云栖大会 AI - 开源大数据专场 数据平台技术演变 …...

Linux find 匹配文件内容
在Linux中,你可以使用find命令结合-exec或者-execgrep来查找匹配特定内容的文件。以下是一些示例: 查找当前目录及其子目录下所有文件内容中包含"exampleText"的文件: find . -type f -exec grep -l "exampleText" {} \…...
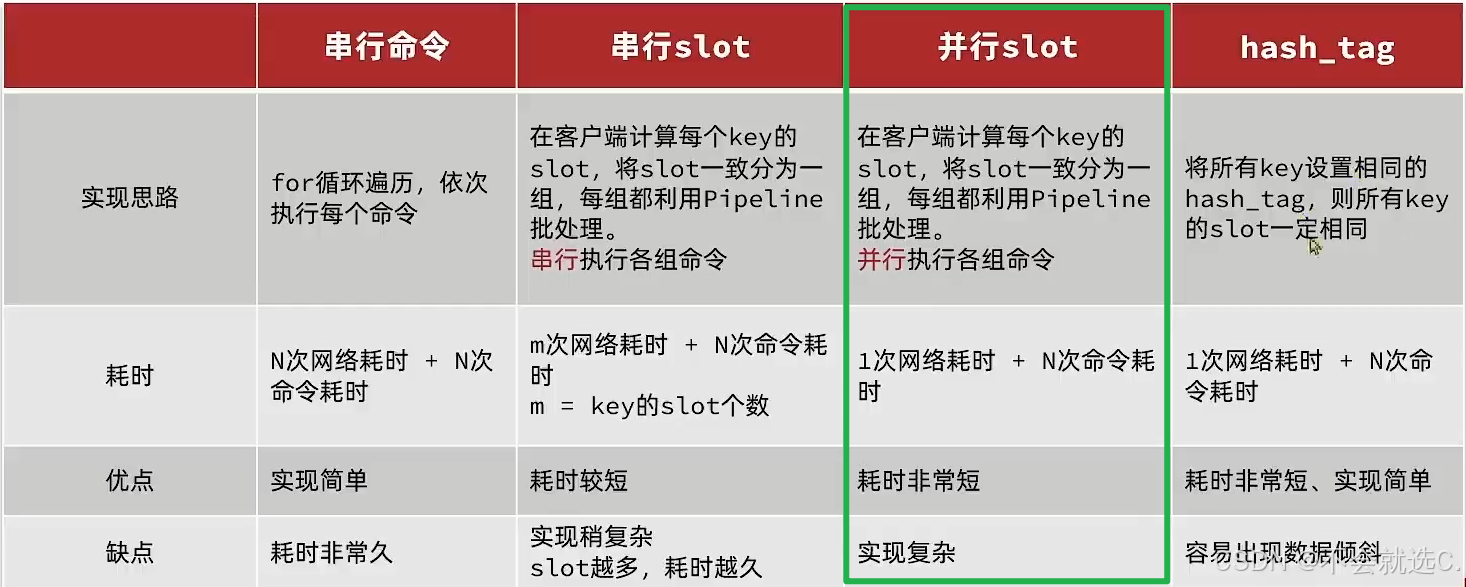
【Redis优化——如何优雅的设计key,优化BigKey,Pipeline批处理Key】
Redis优化——如何优雅的设计key,优化BigKey,Pipeline批处理Key 一、Key的设计1. 命名规范2. 长度限制在44字节以内 二、BigKey优化1. 查找bigkey2. 删除BigKey3. 优化BigKey 三、Pipeline批处理Key1. 单节点的Pipeline2. 集群下的Pipeline 一、Key的设计…...
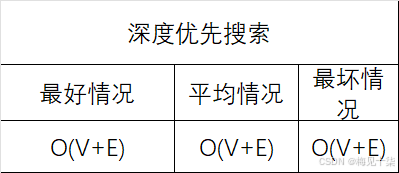
数据结构与算法分析:你真的理解图算法吗——深度优先搜索(代码详解+万字长文)
一、前言 图是计算机科学中用来表示复杂结构信息的一种基本结构。本章我们会讨论一些通用的围表示法,以及一些频繁使用的图算法。本质上来说,一个图包含一个元素集合(也就是顶点),以及元素两两之间的关系(也就是边),由于应用范围所限,本章我们仅仅讨论简单图,简单围并不会如(a…...
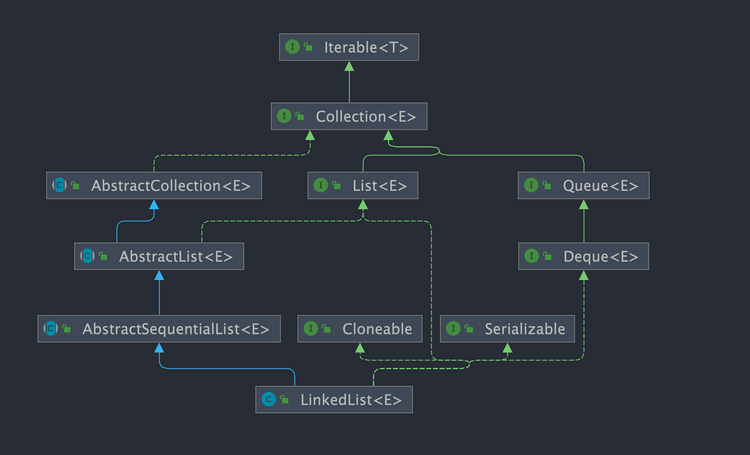
LinkedList 分析
LinkedList 简介 LinkedList 是一个基于双向链表实现的集合类,经常被拿来和 ArrayList 做比较。关于 LinkedList 和ArrayList的详细对比,我们 Java 集合常见面试题总结(上)有详细介绍到。 双向链表 不过,我们在项目中一般是不会使用到 Link…...
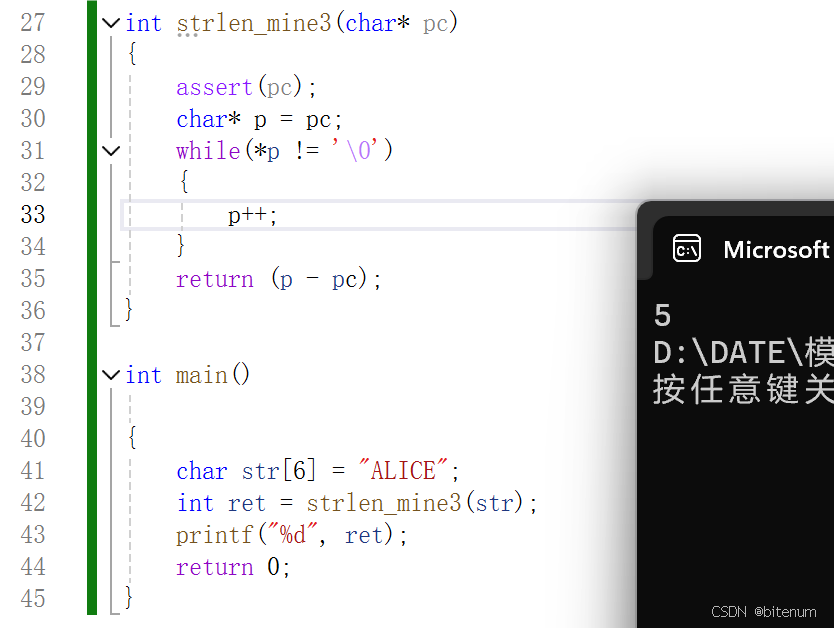
【C/C++】模拟实现strlen
学习目标: 使用代码模拟实现strlen。 逻辑: strlen 需要输入一个字符串数组类型的变量,并且返回一个整型类型的数据。strlen 需要计算字符串数组有多少个元素。 代码1:使用计数器 #define _CRT_SECURE_NO_WARNINGS 1 #include&…...
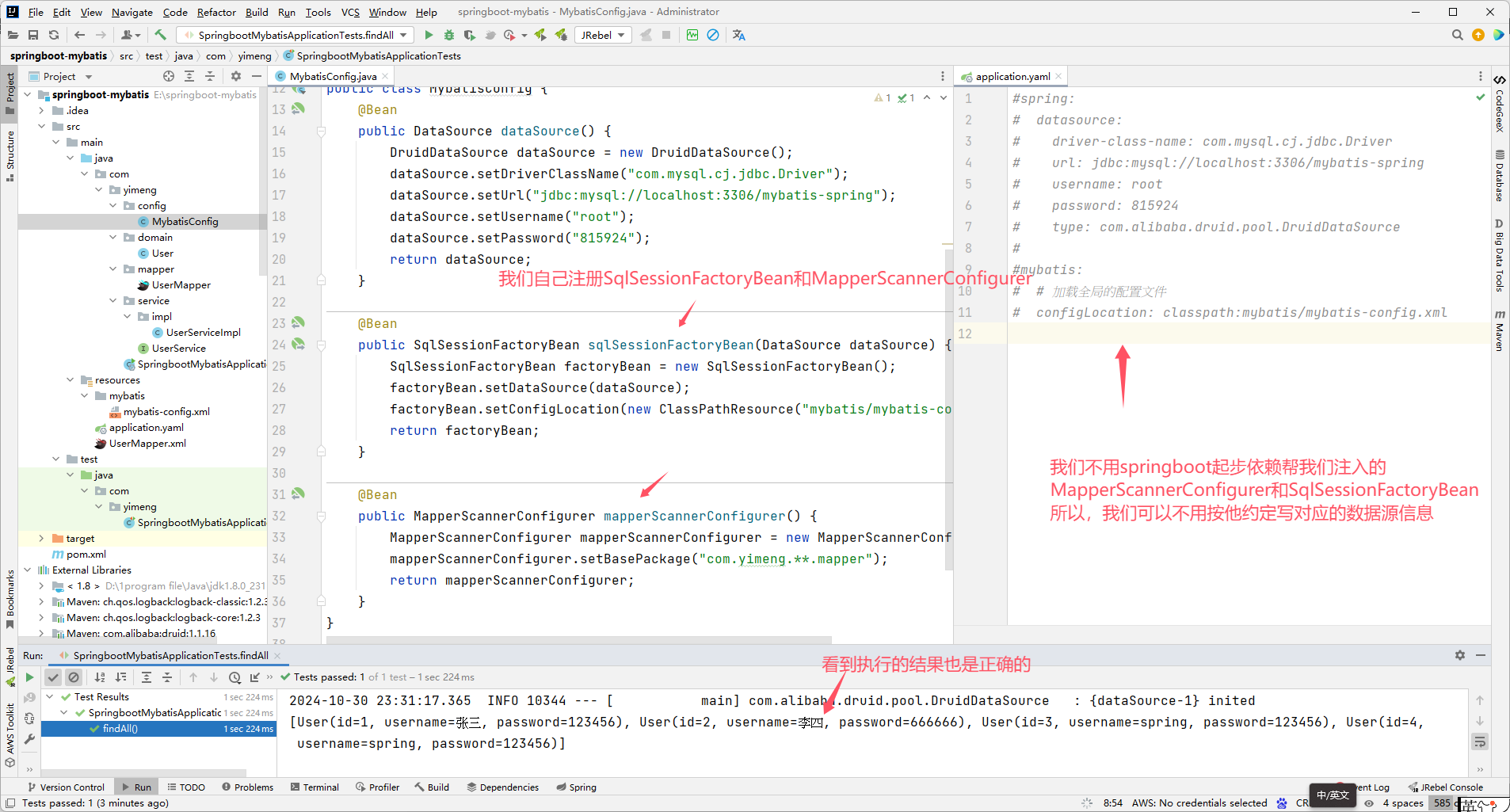
mybatis从浅入深一步步演变分析
mybatis从浅入深一步步演变分析 版本一:不使用代理(非spring) package com.yimeng.domain;public class User {private int id;private String username;private String password;public int getId() {return id;}public void setId(int id…...
Java阶段三02
第3章-第2节 一、知识点 面向接口编程、什么是spring、什么是IOC、IOC的使用、依赖注入 二、目标 了解什么是spring 理解IOC的思想和使用 了解IOC的bean的生命周期 理解什么是依赖注入 三、内容分析 重点 了解什么是spring 理解IOC的思想 掌握IOC的使用 难点 理解IO…...
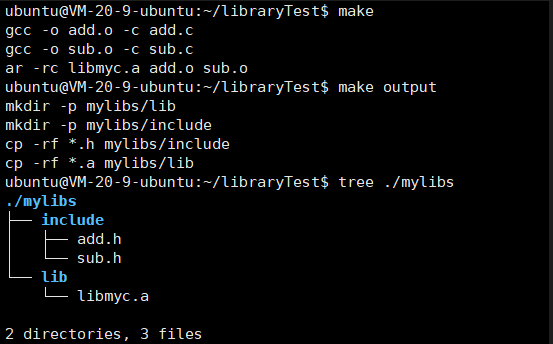
【Linux】掌握库的艺术:我的动静态库封装之旅
🌈个人主页:Yui_ 🌈Linux专栏:Linux 🌈C语言笔记专栏:C语言笔记 🌈数据结构专栏:数据结构 🌈C专栏:C 文章目录 1.什么是库1.2 认识动静态库1.2.1 动态库1.2.2…...
UE5动画控制 基础
素材 mixamo先去选择一个character 点击下载 就这个下载下来 然后选几个animation, 记得勾选 把动作下载了 without skin就是只要动作 然后把他们放在一个文件夹里先 UE里导入 找一个文件夹,直接拖拽进来那个character的fbx,默认配置就…...

流畅!HTMLCSS打造网格方块加载动画
效果演示 这个动画的效果是五个方块在网格中上下移动,模拟了一个连续的加载过程。每个方块的动画都是独立的,但是它们的时间间隔和路径被设计为相互协调,以创建出流畅的动画效果。 HTML <div class"loadingspinner"><…...

linux命令之top(Linux Command Top)
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 本人主要分享计算机核心技…...
笔记)
数据结构-希尔排序(ShellSort)笔记
看动画理解 【数据结构】八大排序(超详解附动图源码)_数据结构排序-CSDN博客 一 基本思想 先选定一个整数gap,把待排序文件中所有记录分成gap个组,所有距离为gap的记录分在同一组内,并对每一组内的元素进行排序。 然后将gap逐渐减小重复上…...

Junit + Mockito保姆级集成测试实践
一、做好单测,慢即是快 对于单元测试的看法,业界同仁理解多有不同,尤其是在业务变化快速的互联网行业,通常的问题主要有,必须要做吗?做到多少合适?现在没做不也挺好的吗?甚至一些大…...

软件项目管理要点
一.项目管理 1.盈亏平衡分析 销售额固定成本可变成本税费利润 当利润为0的时候就是盈亏平衡点。 2.范围管理 范围定义的输入包括:项目章程、项目范围管理计划、组织过程资产、批准的变更申请。 3.时间管理 项目时间管理中的过程包括活动定义、活动排序、活动的资…...

ESP8266 连接 MQTT 服务器EMQX 连接MQTTX
目录 1.先用有一台自己的云服务器 2. 使用FinalShell连接阿里云云服务器ECS 3.安装宝塔 4.在云服务器打开8888端口 5.使用外网面板地址打开宝塔面板 6.安装Docker 7.下载emqx 8.打开emqxWeb 界面 9.下载MQTTX 10.EMQX加一个客户端 11.开始通信 12.加入单片机ESP8266 …...

Python中如何处理异常情况?
1、Python中如何处理异常情况? 在Python中,处理异常情况通常使用try/except语句。try语句块包含可能会引发异常的代码,而except语句块包含处理异常的代码。如果try块中的代码引发了异常,控制流将立即转到相应的except块。 以下是…...

openpnp - 在openpnp中单独测试相机
文章目录 openpnp - 在openpnp中单独测试相机概述笔记END openpnp - 在openpnp中单独测试相机 概述 底部相机的位置不合适, 重新做了零件,准备先确定一下相机和吸嘴的距离是多少才合适。 如果在设备上直接实验,那么拆装调整相机挺麻烦的。 准备直接在电…...

Spark窗口函数
1、 Spark中的窗口函数 窗口就是单纯在行后面加一个列 可以套多个窗口函数,但彼此之间不能相互引用,是独立的 窗口函数会产生shuffle over就是用来划分窗口的 (1) 分组聚合里面的函数,基…...

Idea、VS Code 如何安装Fitten Code插件使用
博主主页:【南鸢1.0】 本文专栏:JAVA 目录 编辑 简介 所用工具 1、Idea如何安装插件 1.idea下载插件 2.需要从外部下载然后在安装, 2、VS Code如何安装插件 总结 简介 Fitten Code是由非十大模型驱动的AI编程助手,它可以自动生成代…...

如何5分钟部署小鹿快传:零基础P2P文件传输终极指南
如何5分钟部署小鹿快传:零基础P2P文件传输终极指南 【免费下载链接】deershare 小鹿快传,一款在线P2P文件传输工具,使用WebSocket WebRTC技术 项目地址: https://gitcode.com/gh_mirrors/de/deershare 小鹿快传(DeerShare…...

DeltaV私有协议逆向分析与流量识别实战
1. 这不是普通工控协议——DeltaV私有协议为何让安全团队彻夜难眠Emerson DeltaV,这个名字在石化、制药、精细化工等连续流程工业现场几乎等同于“控制系统心脏”。但真正让一线自动化工程师和网络安全人员同时皱眉的,从来不是它那套成熟稳定的DCS架构&a…...
)
Midjourney构图进阶实战指南(98%用户从未调过的--sref与--style参数协同逻辑大揭秘)
更多请点击: https://intelliparadigm.com 第一章:Midjourney构图进阶实战指南(98%用户从未调过的--sref与--style参数协同逻辑大揭秘) 在Midjourney V6中, --sref(Style Reference)与 --style…...

酷安UWP桌面客户端完整指南:大屏幕高效刷酷安的终极方案
酷安UWP桌面客户端完整指南:大屏幕高效刷酷安的终极方案 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 还在为手机小屏幕刷酷安而感到眼睛酸痛吗?想在27寸大屏幕上…...

PDF怎么转Word不变形?2026保留原排版方法与软件推荐
PDF转Word时遇到排版错乱是许多办公人士的共同困扰。无论是报告、合同还是设计稿,排版混乱往往意味着需要重新手工调整,浪费大量时间。本文整合了2026年最实用的PDF转Word保留原排版方法,以及各类软件工具的详细对比,帮助你快速找…...

从‘Hello World’到工业通信:我的第一个C++ ADS客户端连接倍福PLC踩坑实录
从零搭建C ADS客户端:一位工程师的倍福PLC连接实战手记 第一次在Visual Studio里看到那个红色的编译错误时,我盯着屏幕足足愣了五分钟。"LNK2019: 无法解析的外部符号 __imp_AdsPortOpen",这行冰冷的报错彻底击碎了我以为照着官方…...

UDEV Gothic字体测试与质量保证:确保跨平台兼容性的完整流程
UDEV Gothic字体测试与质量保证:确保跨平台兼容性的完整流程 【免费下载链接】udev-gothic UDEV Gothic は、ユニバーサルデザインフォントのBIZ UDゴシックと、 開発者向けフォントの JetBrains Mono を合成した、プログラミング向けフォントです。 项目地址: ht…...

Proteus仿真进阶:用STM32F103驱动L298,深入理解PWM占空比与电机速度的映射关系
Proteus仿真进阶:用STM32F103驱动L298,深入理解PWM占空比与电机速度的映射关系 在嵌入式开发中,电机控制是一个经典且实用的课题。很多教程会告诉你如何通过STM32的PWM输出让电机转起来,但很少有人解释为什么代码中会出现"10…...

【职场】职场里,“被喜欢“和“被重用“是两件完全不同的事
职场里,"被喜欢"和"被重用"是两件完全不同的事我见过太多这样的人。 在公司里人缘极好,谁都说他靠谱,谁都愿意跟他合作。 开会时第一个帮人倒水,群里消息第一个回复,同事生日永远记得,…...

技术分享 | 彻底解决图片“躺平”问题:Java 后端强制校准图片方向
在日常开发中,你是否遇到过这样的情况:前端上传了一张手机拍摄的照片,预览时明明是正的,存入服务器后却莫名其妙地“躺平”了,或者逆时针旋转了 90 度?以下方案用于强制旋转图片这通常是因为 JPEG 图片的 E…...