中文NLP地址要素解析【阿里云:天池比赛】
比赛地址:中文NLP地址要素解析 https://tianchi.aliyun.com/notebook/467867?spm=a2c22.12281976.0.0.654b265fTnW3lu长期赛: 分数:87.7271 排名:长期赛:56(本次)/6990(团体或个人)方案:BERT-BiLSTM-CRF-NER 预训练模型:bert-base-chinese训练结果: F1 : 0.9040681554670564 accuracy : 0.9313805261730405 precision : 0.901296612724897 recall : 0.9068567961165048运行脚本: python run_bert_lstm_crf.py
代码解析:
模型:bert_lstm_crf.py:lstm+crf
import torch
import torch.nn as nn
from torchcrf import CRF
from transformers import AutoModelclass NERNetwork(nn.Module):def __init__(self, config, n_tags: int, using_lstm: bool = True) -> None:"""Initialize a NERDA NetworkArgs:bert_model (nn.Module): huggingface `torch` transformers.device (str): Computational device.n_tags (int): Number of unique entity tags (incl. outside tag)dropout (float, optional): Dropout probability. Defaults to 0.1."""super(NERNetwork, self).__init__()self.bert_encoder = AutoModel.from_pretrained(config.model_name_or_path)self.dropout = nn.Dropout(config.dropout)self.using_lstm = using_lstmout_size = self.bert_encoder.config.hidden_sizeif self.using_lstm:self.lstm = nn.LSTM(self.bert_encoder.config.hidden_size, config.lstm_hidden_size, num_layers=1,bidirectional=True, batch_first=True)out_size = config.lstm_hidden_size * 2self.hidden2tags = nn.Linear(out_size, n_tags) # BERT+Linearself.crf_layer = CRF(num_tags=n_tags, batch_first=True)def tag_outputs(self,input_ids: torch.Tensor,attention_mask: torch.Tensor,token_type_ids: torch.Tensor,) -> torch.Tensor:bert_model_inputs = {'input_ids': input_ids,'attention_mask': attention_mask,'token_type_ids': token_type_ids}outputs = self.bert_encoder(**bert_model_inputs)# apply drop-outlast_hidden_state = outputs.last_hidden_statelast_hidden_state = self.dropout(last_hidden_state)if self.using_lstm:last_hidden_state, _ = self.lstm(last_hidden_state)# last_hidden_state for all labels/tagsemissions = self.hidden2tags(last_hidden_state)return emissionsdef forward(self,input_ids: torch.Tensor,attention_mask: torch.Tensor,token_type_ids: torch.Tensor,target_tags: torch.Tensor):"""Model Forward IterationArgs:input_ids (torch.Tensor): Input IDs.attention_mask (torch.Tensor): Attention attention_mask.token_type_ids (torch.Tensor): Token Type IDs.Returns:torch.Tensor: predicted values."""emissions = self.tag_outputs(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)loss = -1 * self.crf_layer(emissions=emissions, tags=target_tags, mask=attention_mask.byte())return lossdef predict(self,input_ids: torch.Tensor,attention_mask: torch.Tensor,token_type_ids: torch.Tensor,):emissions = self.tag_outputs(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)return self.crf_layer.decode(emissions=emissions, mask=attention_mask.byte())
训练脚本:run_bert_lstm_crf.py
import numpy as np
import torch
import argparse
import os, json
import sys
from tqdm import tqdm
import sklearn.preprocessing
from transformers import AutoModel, AutoTokenizer, AutoConfig
from transformers import AdamW, get_linear_schedule_with_warmup
import transformers
import random
from preprocess import create_dataloader, get_semeval_data
from utils import compute_loss, get_ent_tags, batch_to_device, compute_f1, load_test_file
from bert_lstm_crf import NERNetwork
import logging
from config import args
sys.path.append(os.path.dirname(os.path.dirname(os.path.realpath(__file__))))logger = logging.getLogger('main')
logger.setLevel(logging.INFO)
fh = logging.FileHandler('log/log.txt', mode='w')
fh.setLevel(logging.INFO)
ch = logging.StreamHandler()
ch.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(funcName)s - %(lineno)d : %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh)
logger.addHandler(ch)seed = 42
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
# System based
random.seed(seed)
np.random.seed(seed)device = 'cuda' if torch.cuda.is_available() else 'cpu'
logger.info("Using device {}".format(device))# 预测
def predict(model, test_dataloader, tag_encoder, device, train=True):if train and model.training:logger.info("Evaluating the model...")model.eval()predictions = []for batch1 in test_dataloader:batch = batch_to_device(inputs=batch1, device=device)input_ids, attention_mask, token_type_ids = batch['input_ids'], batch['attention_mask'], batch['token_type_ids']with torch.no_grad():outputs = model.predict(input_ids=input_ids, attention_mask=attention_mask,token_type_ids=token_type_ids) # (batch_size,seq_length,num_classes)for i, predict_tag_seq in enumerate(outputs):preds = tag_encoder.inverse_transform(predict_tag_seq) # (with wordpiece)preds = [prediction for prediction, offset in zip(preds.tolist(), batch.get('offsets')[i]) ifoffset] # offsets = [1] + offsets + [1]preds = preds[1:-1]predictions.append(preds)return predictions# 训练
def train(args,train_dataloader,tag_encoder,train_conll_tags,test_conll_tags,test_dataloader):n_tags = tag_encoder.classes_.shape[0]logger.info("n_tags : {}".format(n_tags))print_loss_step = len(train_dataloader) // 5evaluation_steps = len(train_dataloader) // 2logger.info("Under an epoch, loss will be output every {} step, and the model will be evaluated every {} step".format(print_loss_step, evaluation_steps))model = NERNetwork(args, n_tags=n_tags)if args.ckpt is not None:load_result = model.load_state_dict(torch.load(args.ckpt, map_location='cpu'), strict=False)logger.info("Load ckpt to continue training !")logger.info("missing and unexcepted key : {}".format(str(load_result)))model.to(device=device)logger.info("Using device : {}".format(device))optimizer_parameters = model.parameters()optimizer = AdamW(optimizer_parameters, lr=args.learning_rate)num_train_steps = int(len(train_conll_tags) // args.train_batch_size // args.gradient_accumulation_steps) * args.epochswarmup_steps = int(num_train_steps * args.warmup_proportion)logger.info("num_train_steps : {}, warmup_proportion : {}, warmup_steps : {}".format(num_train_steps,args.warmup_proportion,warmup_steps))scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps, num_training_steps=num_train_steps)global_step = 0previous_f1 = -1predictions = predict(model=model, test_dataloader=test_dataloader, tag_encoder=tag_encoder, device=device)f1 = compute_f1(pred_tags=predictions, golden_tags=test_conll_tags)if f1 > previous_f1:logger.info("Previous f1 score is {} and current f1 score is {}".format(previous_f1, f1))previous_f1 = f1for epoch in range(args.epochs):model.train()model.zero_grad()training_loss = 0.0for iteration, batch in tqdm(enumerate(train_dataloader)):batch = batch_to_device(inputs=batch, device=device)input_ids, attention_mask, token_type_ids = batch['input_ids'], batch['attention_mask'], batch['token_type_ids']loss = model(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids,target_tags=batch['target_tags']) # (batch_size,seq_length,num_classes)# target_tags将CLS和SEP赋予标签Otraining_loss += loss.item()loss.backward()if (iteration + 1) % args.gradient_accumulation_steps == 0:optimizer.step()scheduler.step()optimizer.zero_grad()global_step += 1if (iteration + 1) % print_loss_step == 0:training_loss /= print_loss_steplogger.info("Epoch : {}, global_step : {}/{}, loss_value : {} ".format(epoch, global_step, num_train_steps,training_loss))training_loss = 0.0if (iteration + 1) % evaluation_steps == 0:predictions = predict(model=model, test_dataloader=test_dataloader, tag_encoder=tag_encoder,device=device)f1 = compute_f1(pred_tags=predictions, golden_tags=test_conll_tags)if f1 > previous_f1:torch.save(model.state_dict(), args.best_model)logger.info("Previous f1 score is {} and current f1 score is {}, best model has been saved in {}".format(previous_f1, f1, args.best_model))previous_f1 = f1else:args.patience -= 1logger.info("Left patience is {}".format(args.patience))if args.patience == 0:logger.info("Total patience is {}, run our of patience, early stop!".format(args.patience))returnmodel.zero_grad()model.train()# 生成测试数据
def my_test(args,tag_encoder,valid_dataloader):n_tags = tag_encoder.classes_.shape[0]logger.info("n_tags : {}".format(n_tags))model = NERNetwork(args, n_tags=n_tags)if args.best_model is not None:load_result = model.load_state_dict(torch.load(args.best_model, map_location='cpu'), strict=False)logger.info("Load ckpt to continue training !")logger.info("missing and unexcepted key : {}".format(str(load_result)))model.to(device=device)predictions = predict(model=model, test_dataloader=valid_dataloader, tag_encoder=tag_encoder, device=device,train=False)sentences = valid_dataloader.dataset.sentences# 指定文件名file_name = "output_new.txt"# 打开文件,以写入模式写入数据with open(file_name, "w", encoding="utf-8") as file:index = 0for prediction in predictions:sentence = sentences[index]sentence_str = ''.join(sentence)prediction_str = ' '.join(prediction)line = f"{index + 1}\u0001{sentence_str}\u0001{prediction_str}\n"# logger.info(f"line={line}")assert len(sentence) == len(prediction)file.write(line)index += 1def main():if not os.path.exists(args.save_dir):logger.info("save_dir not exists, created!")os.makedirs(args.save_dir, exist_ok=True)train_conll_data = get_semeval_data(split='train', dir=args.file_path, word_idx=1, entity_idx=3)test_conll_data = get_semeval_data(split='dev', dir=args.file_path, word_idx=1, entity_idx=3)valid_conll_data = load_test_file(split='valid', dir=args.file_path)logger.info("train sentences num : {}".format(len(train_conll_data['sentences'])))logger.info("test sentences num : {}".format(len(test_conll_data['sentences'])))logger.info("Logging some examples...")for _ in range(5):i = random.randint(0, len(test_conll_data['tags']) - 1)sen = test_conll_data['sentences'][i]ent = test_conll_data['tags'][i]for k in range(len(sen)):logger.info("{} {}".format(sen[k], ent[k]))logger.info('-' * 50)tag_scheme = get_ent_tags(all_tags=train_conll_data.get('tags'))tag_outside = 'O'if tag_outside in tag_scheme:del tag_scheme[tag_scheme.index(tag_outside)]tag_complete = [tag_outside] + tag_schemeprint(tag_complete, len(tag_complete))with open(os.path.join(args.save_dir, 'label.json'), 'w') as f:json.dump(obj=' '.join(tag_complete), fp=f)logger.info("Tag scheme : {}".format(' '.join(tag_scheme)))logger.info("Tag has been saved in {}".format(os.path.join(args.save_dir, 'label.json')))tag_encoder = sklearn.preprocessing.LabelEncoder()tag_encoder.fit(tag_complete)transformer_tokenizer = AutoTokenizer.from_pretrained(args.model_name_or_path)transformer_config = AutoConfig.from_pretrained(args.model_name_or_path)train_dataloader = create_dataloader(sentences=train_conll_data.get('sentences'),tags=train_conll_data.get('tags'),transformer_tokenizer=transformer_tokenizer,transformer_config=transformer_config,max_len=args.max_len,tag_encoder=tag_encoder,tag_outside=tag_outside,batch_size=args.train_batch_size,num_workers=args.num_workers,take_longest_token=args.take_longest_token,is_training=True)test_dataloader = create_dataloader(sentences=test_conll_data.get('sentences'),tags=test_conll_data.get('tags'),transformer_tokenizer=transformer_tokenizer,transformer_config=transformer_config,max_len=args.max_len,tag_encoder=tag_encoder,tag_outside=tag_outside,batch_size=args.test_batch_size,num_workers=args.num_workers,take_longest_token=args.take_longest_token,is_training=False)valid_dataloader = create_dataloader(sentences=valid_conll_data.get('sentences'),tags=valid_conll_data.get('tags'),transformer_tokenizer=transformer_tokenizer,transformer_config=transformer_config,max_len=args.max_len,tag_encoder=tag_encoder,tag_outside=tag_outside,batch_size=args.test_batch_size,num_workers=args.num_workers,take_longest_token=args.take_longest_token,is_training=False)train(args=args, train_dataloader=train_dataloader,tag_encoder=tag_encoder,train_conll_tags=train_conll_data.get('tags'),test_conll_tags=test_conll_data.get('tags'),test_dataloader=test_dataloader)my_test(args=args,tag_encoder=tag_encoder,valid_dataloader=valid_dataloader)if __name__ == "__main__":main()
配置config.py
import argparseparser = argparse.ArgumentParser()
# input and output parameters
# 预训练模型
parser.add_argument('--model_name_or_path', default='/data/nfs/baozhi/models/google-bert_bert-base-chinese', help='path to the BERT')
# 微调后的模型保存路径
parser.add_argument('--best_model', default='saved_models/pytorch_model_20241031_v2.bin', help='path to the BERT')
# 训练数据目录
parser.add_argument('--file_path', default='data/com334', help='path to the ner data')
# 数据保留目录
parser.add_argument('--save_dir', default='saved_models/', help='path to save checkpoints and logs')
parser.add_argument('--ckpt', default=None, help='Fine tuned model')
# training parameters
# 学习率
parser.add_argument('--learning_rate', default=3e-5, type=float)
parser.add_argument('--weight_decay', default=1e-5, type=float)
# epochs
parser.add_argument('--epochs', default=15, type=int)
parser.add_argument('--train_batch_size', default=64, type=int)
parser.add_argument('--gradient_accumulation_steps', default=1, type=int)
parser.add_argument('--lstm_hidden_size', default=150, type=int)
parser.add_argument('--test_batch_size', default=64, type=int)
parser.add_argument('--max_grad_norm', default=1, type=int)
parser.add_argument('--warmup_proportion', default=0.1, type=float)
# 最大长度
parser.add_argument('--max_len', default=200, type=int)
parser.add_argument('--patience', default=100, type=int)
# 正则化系数
parser.add_argument('--dropout', default=0.5, type=float)# Other parameters
parser.add_argument('--seed', type=int, default=42, help='random seed')
parser.add_argument('--num_workers', default=1, type=int)
parser.add_argument('--take_longest_token', default=False, type=bool)
args = parser.parse_args()
数据处理:preprocess.py
import re
import warnings
import sklearn.preprocessing
import torch
import transformers
import os,jsonclass DataSet():def __init__(self,sentences: list,tags: list,transformer_tokenizer: transformers.PreTrainedTokenizer,transformer_config: transformers.PretrainedConfig,max_len: int,tag_encoder: sklearn.preprocessing.LabelEncoder,tag_outside: str,take_longest_token: bool = True,pad_sequences: bool = True) -> None:"""Initialize DataSetReaderInitializes DataSetReader that prepares and preprocesses DataSet for Named-Entity Recognition Task and training.Args:sentences (list): Sentences.tags (list): Named-Entity tags.transformer_tokenizer (transformers.PreTrainedTokenizer): tokenizer for transformer.transformer_config (transformers.PretrainedConfig): Configfor transformer model.max_len (int): Maximum length of sentences after applyingtransformer tokenizer.tag_encoder (sklearn.preprocessing.LabelEncoder): Encoderfor Named-Entity tags.tag_outside (str): Special Outside tag. like 'O'pad_sequences (bool): Pad sequences to max_len. Defaultsto True."""self.sentences = sentencesself.tags = tagsself.transformer_tokenizer = transformer_tokenizerself.max_len = max_lenself.tag_encoder = tag_encoderself.pad_token_id = transformer_config.pad_token_idself.tag_outside_transformed = tag_encoder.transform([tag_outside])[0]self.take_longest_token = take_longest_tokenself.pad_sequences = pad_sequencesdef __len__(self):return len(self.sentences)def __getitem__(self, item):sentence = self.sentences[item]tags = self.tags[item]# encode tagstags = self.tag_encoder.transform(tags)# check inputs for consistancyassert len(sentence) == len(tags)input_ids = []target_tags = []tokens = []offsets = []# for debugging purposes# print(item)for i, word in enumerate(sentence):# bert tokenizationwordpieces = self.transformer_tokenizer.tokenize(word)if self.take_longest_token:piece_token_lengths = [len(token) for token in wordpieces]word = wordpieces[piece_token_lengths.index(max(piece_token_lengths))]wordpieces = [word] # 仅仅取最长的tokentokens.extend(wordpieces)# make room for CLS if there is an identified word pieceif len(wordpieces) > 0:offsets.extend([1] + [0] * (len(wordpieces) - 1))# Extends the ner_tag if the word has been split by the wordpiece tokenizertarget_tags.extend([tags[i]] * len(wordpieces))if self.take_longest_token:assert len(tokens) == len(sentence) == len(target_tags)# Make room for adding special tokens (one for both 'CLS' and 'SEP' special tokens)# max_len includes _all_ tokens.if len(tokens) > self.max_len - 2:msg = f'Sentence #{item} length {len(tokens)} exceeds max_len {self.max_len} and has been truncated'warnings.warn(msg)tokens = tokens[:self.max_len - 2]target_tags = target_tags[:self.max_len - 2]offsets = offsets[:self.max_len - 2]# encode tokens for BERT# TO DO: prettify this.input_ids = self.transformer_tokenizer.convert_tokens_to_ids(tokens)input_ids = [self.transformer_tokenizer.cls_token_id] + input_ids + [self.transformer_tokenizer.sep_token_id]# fill out other inputs for model. target_tags = [self.tag_outside_transformed] + target_tags + [self.tag_outside_transformed]attention_mask = [1] * len(input_ids)# set to 0, because we are not doing NSP or QA type task (across multiple sentences)# token_type_ids distinguishes sentences.token_type_ids = [0] * len(input_ids)offsets = [1] + offsets + [1]# Padding to max length # compute padding lengthif self.pad_sequences:padding_len = self.max_len - len(input_ids)input_ids = input_ids + ([self.pad_token_id] * padding_len)attention_mask = attention_mask + ([0] * padding_len)offsets = offsets + ([0] * padding_len)token_type_ids = token_type_ids + ([0] * padding_len)target_tags = target_tags + ([self.tag_outside_transformed] * padding_len)return {'input_ids': torch.tensor(input_ids, dtype=torch.long),'attention_mask': torch.tensor(attention_mask, dtype=torch.long),'token_type_ids': torch.tensor(token_type_ids, dtype=torch.long),'target_tags': torch.tensor(target_tags, dtype=torch.long),'offsets': torch.tensor(offsets, dtype=torch.long)}def create_dataloader(sentences,tags,transformer_tokenizer,transformer_config,max_len,tag_encoder,tag_outside,batch_size=1,num_workers=1,take_longest_token=True,pad_sequences=True,is_training=True):if not pad_sequences and batch_size > 1:print("setting pad_sequences to True, because batch_size is more than one.")pad_sequences = Truedata_reader = DataSet(sentences=sentences,tags=tags,transformer_tokenizer=transformer_tokenizer,transformer_config=transformer_config,max_len=max_len,tag_encoder=tag_encoder,tag_outside=tag_outside,take_longest_token=take_longest_token,pad_sequences=pad_sequences)# Don't pad sequences if batch size == 1. This improves performance.data_loader = torch.utils.data.DataLoader(data_reader, batch_size=batch_size, num_workers=num_workers, shuffle=is_training)return data_loaderdef get_conll_data(split: str = 'train',limit_length: int = 196,dir: str = None) -> dict:assert isinstance(split, str)splits = ['train', 'dev', 'test']assert split in splits, f'Choose between the following splits: {splits}'# set to default directory if nothing else has been provided by user.assert os.path.isdir(dir), f'Directory {dir} does not exist. Try downloading CoNLL-2003 data with download_conll_data()'file_path = os.path.join(dir, f'{split}.txt')assert os.path.isfile(file_path), f'File {file_path} does not exist. Try downloading CoNLL-2003 data with download_conll_data()'# read data from file.with open(file_path, 'r') as f:lines = f.readlines()sentences = []sentence = []entities = []entity = []sentences = []labels = []sentence = []label = []pua_pattern = re.compile("[\uE000-\uF8FF]|[\u200b\u200d\u200e]")for line in lines:line = line.strip()if len(line) == 0:if len(sentence) > 0:sentences.append(sentence)labels.append(label)sentence = []label = []else:parts = line.split()word = parts[0]tag = parts[1]word = re.sub(pua_pattern, "", word) # 删除这些私有域字符if word:sentence.append(word)label.append(tag)if len(sentence) > 0:sentences.append(sentence)labels.append(label)return {'sentences': sentences, 'tags': labels}def get_semeval_data(split: str = 'train',limit_length: int = 196,dir: str = None,word_idx=1,entity_idx=4) -> dict:assert isinstance(split, str)splits = ['train', 'dev', 'test']assert split in splits, f'Choose between the following splits: {splits}'# set to default directory if nothing else has been provided by user.assert os.path.isdir(dir), f'Directory {dir} does not exist. Try downloading CoNLL-2003 data with download_conll_data()'file_path = os.path.join(dir, f'{split}.txt')assert os.path.isfile(file_path), f'File {file_path} does not exist. Try downloading CoNLL-2003 data with download_conll_data()'# read data from file.with open(file_path, 'r', encoding='utf-8') as f:lines = f.readlines()sentences = []sentence = []entities = []entity = []sentences = []labels = []sentence = []label = []pua_pattern = re.compile("[\uE000-\uF8FF]|[\u200b\u200d\u200e]")for line in lines:line = line.strip()if len(line) == 0:if len(sentence) > 0:sentences.append(sentence)labels.append(label)sentence = []label = []else:parts = line.split()word = parts[0]tag = parts[1]word = re.sub(pua_pattern, "", word) # 删除这些私有域字符if word:sentence.append(word)label.append(tag)if len(sentence) > 0:sentences.append(sentence)labels.append(label)return {'sentences': sentences, 'tags': labels}
工具类:utils.py
import os
from io import BytesIO
from pathlib import Path
from urllib.request import urlopen
from zipfile import ZipFile
import ssl
from typing import Callable
import torch
from seqeval.metrics import accuracy_score, classification_report, f1_score, precision_score, recall_score
import logging
import relogger = logging.getLogger('main.utils')def load_test_file(split: str = 'train',dir: str = None):file_path = os.path.join(dir, f'{split}.txt')sentences = []labels = []pua_pattern = re.compile("[\uE000-\uF8FF]|[\u200b\u200d\u200e]")with open(file_path, 'r', encoding='utf-8') as f:for line in f:ids, words = line.strip().split('\001')# 要预测的数据集没有label,伪造个O,words = re.sub(pua_pattern, '', words)label = ['O' for x in range(0, len(words))]sentence = []for c in words:sentence.append(c)sentences.append(sentence)labels.append(label)return {'sentences': sentences, 'tags': labels}# return sentences, labelsdef download_unzip(url_zip: str,dir_extract: str) -> str:"""Download and unzip a ZIP archive to folder.Loads a ZIP file from URL and extracts all of the files to a given folder. Does not save the ZIP file itself.Args:url_zip (str): URL to ZIP file.dir_extract (str): Directory where files are extracted.Returns:str: a message telling, if the archive was succesfullyextracted. Obviously the files in the ZIP archive areextracted to the desired directory as a side-effect."""# suppress ssl certificationctx = ssl.create_default_context()ctx.check_hostname = Falsectx.verify_mode = ssl.CERT_NONEprint(f'Reading {url_zip}')with urlopen(url_zip, context=ctx) as zipresp:with ZipFile(BytesIO(zipresp.read())) as zfile:zfile.extractall(dir_extract)return f'archive extracted to {dir_extract}'def download_conll_data(dir: str = None) -> str:"""Download CoNLL-2003 English data set.Downloads the [CoNLL-2003](https://www.clips.uantwerpen.be/conll2003/ner/) English data set annotated for Named Entity Recognition.Args:dir (str, optional): Directory where CoNLL-2003 datasets will be saved. If no directory is provided, data will be saved to a hidden folder '.dane' in your home directory. Returns:str: a message telling, if the archive was in fact succesfully extracted. Obviously the CoNLL datasets areextracted to the desired directory as a side-effect.Examples:>>> download_conll_data()>>> download_conll_data(dir = 'conll')"""# set to default directory if nothing else has been provided by user.if dir is None:dir = os.path.join(str(Path.home()), '.conll')return download_unzip(url_zip='https://data.deepai.org/conll2003.zip',dir_extract=dir)def match_kwargs(function: Callable, **kwargs) -> dict:"""Matches Arguments with FunctionMatch keywords arguments with the arguments of a function.Args:function (function): Function to match arguments for.kwargs: keyword arguments to match against.Returns:dict: dictionary with matching arguments and theirrespective values."""arg_count = function.__code__.co_argcount # 14args = function.__code__.co_varnames[:arg_count] # 'self', 'input_ids', 'attention_mask', 'token_type_ids', 'position_ids', 'head_mask', 'inputs_embeds'args_dict = {}for k, v in kwargs.items():if k in args:args_dict[k] = vreturn args_dictdef get_ent_tags(all_tags):ent_tags = set()for each_tag_sequence in all_tags:for each_tag in each_tag_sequence:ent_tags.add(each_tag)return list(ent_tags)def batch_to_device(inputs, device):for key in inputs.keys():if type(inputs[key]) == list:inputs[key] = torch.LongTensor(inputs[key])inputs[key] = inputs[key].to(device)return inputsdef compute_loss(preds, target_tags, masks, device, n_tags):# initialize loss function.lfn = torch.nn.CrossEntropyLoss()# Compute active loss to not compute loss of paddingsactive_loss = masks.view(-1) == 1active_logits = preds.view(-1, n_tags)active_labels = torch.where(active_loss,target_tags.view(-1),torch.tensor(lfn.ignore_index).type_as(target_tags))active_labels = torch.as_tensor(active_labels, device=torch.device(device), dtype=torch.long)# Only compute loss on actual token predictionsloss = lfn(active_logits, active_labels)return lossdef compute_f1(pred_tags, golden_tags, from_test=False):assert len(pred_tags) == len(golden_tags)count = 0for pred, golden in zip(pred_tags, golden_tags):try:assert len(pred) == len(golden)except:print(len(pred), len(golden))print(count)raise Exception('length is not consistent!')count += 1result = classification_report(y_pred=pred_tags, y_true=golden_tags, digits=4)f1 = f1_score(y_pred=pred_tags, y_true=golden_tags)acc = accuracy_score(y_pred=pred_tags, y_true=golden_tags)precision = precision_score(y_pred=pred_tags, y_true=golden_tags)recall = recall_score(y_pred=pred_tags, y_true=golden_tags)if from_test == False:logger.info('\n' + result)logger.info("F1 : {}, accuracy : {}, precision : {}, recall : {}".format(f1, acc, precision, recall))return f1else:print(result)print("F1 : {}, accuracy : {}, precision : {}, recall : {}".format(f1, acc, precision, recall))return f1
附:源码
比赛地址:中文NLP地址要素解析方案:BERT-BiLSTM-CRF-NER资源-CSDN文库
相关文章:

中文NLP地址要素解析【阿里云:天池比赛】
比赛地址:中文NLP地址要素解析 https://tianchi.aliyun.com/notebook/467867?spma2c22.12281976.0.0.654b265fTnW3lu长期赛: 分数:87.7271 排名:长期赛:56(本次)/6990(团体或个人)方案…...

使用AddressSanitizer内存检测
修改cmakelist.txt,在project(xxxx)后面追加: option(MEM_CHECK "memory check with AddressSanitizer" OFF) if(MEM_CHECK)set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fsanitizeaddress")set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS…...

11月1日星期五今日早报简报微语报早读
11月1日星期五,农历十月初一,早报#微语早读。 1、六大行今日起实施存量房贷利率新机制。 2、谷歌被俄罗斯罚款35位数,罚款远超全球GDP。 3、山西吕梁:女性35岁前登记结婚,给予1500元奖励。 4、我国人均每日上网时间…...

实用篇:Postman历史版本下载
postman历史版本下载步骤 1.官方历史版本发布信息 2.点进去1中的链接,往下滑动;选择你想要的版本 例如下载v11.18版本 3.根据操作系统选择 mac:mac系统postman下载 window:window系统postman下载 4.在old version里找到对应版本下载即可 先点击download 再点击free downlo…...

微服务实战系列之玩转Docker(十七)
导览 前言Q:如何实现etcd数据的可视化管理一、创建etcd集群1. 节点定义2. 集群成员2.1 docker ps2.2 docker exec2.3 etcdctl member list 二、发布数据1. 添加数据2. 数据共享 三、可视化管理1. ETCD Keeper入门1.1 简介1.2 安装1.2.1 定义compose.yml1.2.2 启动ke…...
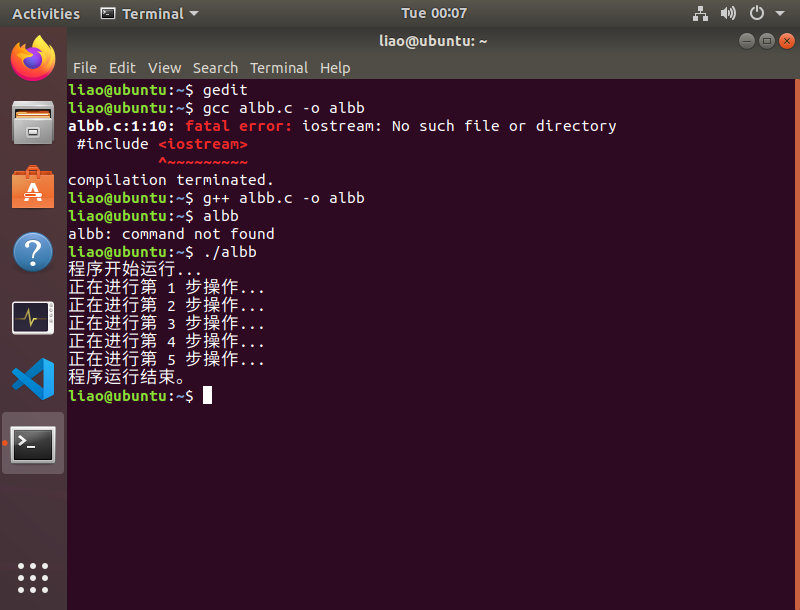
操作系统-实验报告单(1)
目录 1 实验目标 2 实验工具 3 实验内容、实验步骤及实验结果 一、安装虚拟机及Ubuntu 5、*存在虚拟机不能安装的问题 二、Ubuntu基本操作 1、桌面操作 2、终端命令行操作 三、在Ubuntu下运行C程序 3、*Ubuntu中编写一个Hello.c的主要程序 4 实验总结 实 验 报 告…...

rom定制系列------小米8青春版定制安卓14批量线刷固件 原生系统
💝💝💝小米8青春版。机型代码platina。官方最终版为 12.5.1安卓10的版本。客户需要安卓14的固件以便使用他们的软件。根据测试,原生pixeExpe固件适配兼容性较好。为方便客户批量进行刷写。修改固件为可fast批量刷写。整合底层分区…...

CATIA许可证常见问题解答
在使用CATIA软件的过程中,许可证问题常常是用户关心的焦点。为了帮助大家更好地理解和解决这些问题,我们整理了一份CATIA许可证常见问题解答,希望能为您提供便捷的参考。 问题一:如何激活CATIA许可证? 解答:…...

PySpark Standalone 集群部署教程
目录 1. 环境准备 1.1 配置免密登录 2. 下载并配置Spark 3. 配置Spark集群 3.1 配置spark-env.sh 3.2 配置spark-defaults.conf 3.3 设置Master和Worker节点 3.4 设配置log4j.properties 3.5 同步到所有Worker节点 4. 启动Spark Standalone集群 4.1 启动Master节点 …...

【源码+文档】基于SpringBoot+Vue旅游网站系统【提供源码+答辩PPT+参考文档+项目部署】
作者简介:✌CSDN新星计划导师、Java领域优质创作者、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流。✌ 主要内容:🌟Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能…...

9.排队模型-M/M/1
1.排队模型 在Excel中建立排队模型可以帮助分析系统中的客户流动和服务效率。以下是如何构建简单排队模型的步骤: 1.确定模型参数 到达率(λ):客户到达系统的平均速率(例如每小时到达的客户数)。服务率&…...

【GO学习笔记 go基础】编译器下载安装+Go设置代理加速+项目调试+基础语法+go.mod项目配置+接口(interface)
编译器下载&安装 下载并安装go1.23.2.windows-amd64.msi默认安装再C:\Program Files\Go\ PS C:\Users\kingchuxing\Documents> go version go version go1.23.2 windows/amd64Go设置GOPROXY国内加速 windows // 启用 Go Modules 功能 PS C:\Users\kingchuxing…...

从0开始学习shell脚本
了解Shell和Shell脚本 Shell:Shell是一个命令解释器,用来执行用户输入的命令。常用的Shell包括Bash、Zsh、Ksh等。Linux默认的Shell通常是Bash。 Shell脚本:Shell脚本是由一系列命令组成的文件,脚本可以运行一连串命令ÿ…...

官方工具重装Windows 11当前版本 /绕过硬件检查/免U盘
官方工具重装Windows 11当前版本 /绕过硬件检查/免U盘 官方工具重装Windows 11当前版本 /绕过硬件检查/免U盘_win11安装跳过检测-CSDN博客...
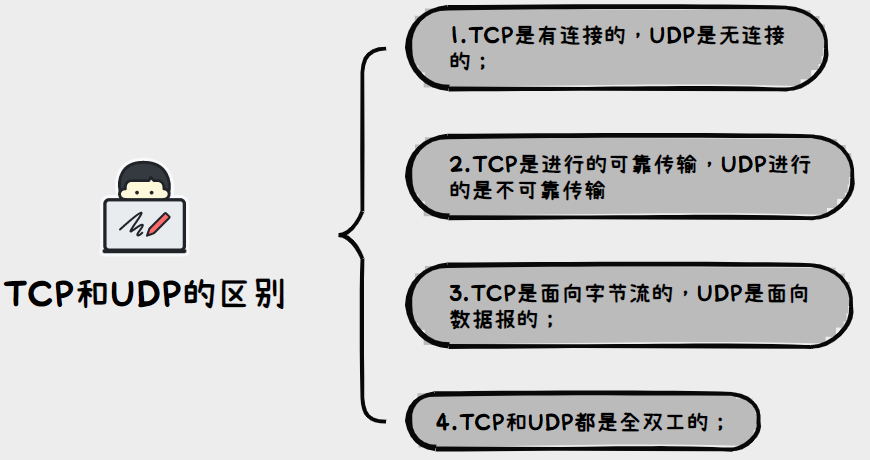
JavaEE初阶---网络原理/UDP服务器客户端程序
文章目录 1.网络初识2.网络编程2.1TCP/UDP区别介绍2.2UDP的socket api使用2.3UDP协议里面的服务器客户端程序 1.网络初识 网络和计算机类似:都是属于军用》民用; 网络诞生于美苏争霸时期,当时就感觉核战争一触即发,形式非常严峻…...
)
每天10个vue面试题(六)
1、对Vue设计原则的理解? 渐进式JavaScript框架:与其它大型框架不同的是,Vue被设计为可以自底向上逐层应用。Vue的核心库只关注视图层,不仅易于上手,还便于与第三方库或既有项目整合。另一方面,当与现代化…...

Qt:信号和槽
目录 关于信号 connect函数 关于connect connect的使用 自定义信号、自定义槽 自定义槽 第一种方式自定义槽 第二种方式自定义槽 自定义信号 信号槽 带参数的信号槽 参数个数一致的示例 参数个数不一致的示例 Q_OBJECT 信号和槽存在的意义 disconnect函数 使用…...

可以免费商用的字体下载
这里介绍一个开源仓库,收录的可以免费商用的字体,目前中文字体1308款,英文字体980款,共约2288多款字体。 Description Free fonts that can be used commercially.There are currently 1308 Chinese fonts and 980 English font…...

centos7之LVS-TUNNEL模式
介绍 优缺点以及适用场景 优点:能负载更多的Realserver减轻LB的压力。LVS和Realserver可以不再同一网段。 缺点:tun模式的开销比较大(出口流量大),性能不如DR模式。不支持端口转发。后端Realserver系统必须支持tunnel协议。 适用ÿ…...

Linux驱动开发(3):字符设备驱动
上一章节我们了解到什么是内核模块,模块的加载卸载详细过程以及内核模块的使用等内容。 本章,我们将学习驱动相关的概念,理解字符设备驱动程序的基本框架,并从源码上分析字符设备驱动实现和管理。 主要内容有如下五点:…...

提升3倍效率的Windows桌面端酷安社区解决方案:基于UWP平台的高性能第三方客户端
提升3倍效率的Windows桌面端酷安社区解决方案:基于UWP平台的高性能第三方客户端 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP Coolapk-UWP是一款基于UWP平台的第三方酷安客户…...

台州华声汽车音响改装店推荐,资深玩家都去这几家
在汽车音响改装领域,选择一家靠谱的门店,往往比挑选器材本身更考验车主的眼光。对于追求极致听感的资深玩家而言,改装的成败不仅取决于喇叭、功放等硬件的参数,更在于安装工艺、声学调校与项目统筹能力。近期,笔者深度…...

告别字幕与水印:LTX 2.3工作流,一键高效清除,附详细使用方法。
一、LTX2.3功能介绍 核心功能:一键去除视频字幕和水印 工作流程: 上传视频 设置参数 设置提示词(提示词固定不变) 点击运行,即可输出没有水印和字幕的视频 ⬇️⬇️⬇️ 1.核心模型 水印去除模型字幕去除模型 2.模型…...

教育科技项目如何通过Taotoken平衡AI功能效果与接口成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 教育科技项目如何通过Taotoken平衡AI功能效果与接口成本 在在线教育或培训类应用的开发与运营中,文本生成与总结功能已…...

Hotkey Detective:3分钟找出Windows热键冲突元凶,重获键盘控制权
Hotkey Detective:3分钟找出Windows热键冲突元凶,重获键盘控制权 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-de…...

Buck电路纹波太大?可能是你的电容和ESR没选对!三种RC场景下的实战分析与选型指南
Buck电路纹波优化实战:电容与ESR选型的三维决策框架 实验室里示波器屏幕上那条本该平滑的直流输出波形,此刻却像心电图般剧烈起伏——这是每位电源工程师都经历过的"纹波焦虑"时刻。当我们面对Buck电路输出纹波超标问题时,传统定性…...

Diablo Edit2:暗黑破坏神2存档编辑器终极指南,5分钟掌握角色修改神器
Diablo Edit2:暗黑破坏神2存档编辑器终极指南,5分钟掌握角色修改神器 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾在暗黑破坏神2中花费数小时刷装备却一无所获&…...

词达人自动化助手终极指南:如何让英语学习效率提升10倍
词达人自动化助手终极指南:如何让英语学习效率提升10倍 【免费下载链接】cdr 微信词达人,高正确率,高效简洁。支持班级任务及自选任务 项目地址: https://gitcode.com/gh_mirrors/cd/cdr 你是否曾经面对堆积如山的英语词汇任务感到力不…...

把闲置NAS变成数据中枢:Docker部署MySQL全流程与Python连接实战
把闲置NAS变成数据中枢:Docker部署MySQL全流程与Python连接实战 家里那台吃灰的NAS,除了存电影和备份照片,还能干点更有技术含量的事吗?当然可以!今天我们就来彻底激活它的潜力,将它打造成家庭数据处理的&q…...

孤胆英雄的黄昏,社会化智能的黎明:一文看透 Multi-Agent 架构底层逻辑
在过去的一两年里,我们见证了单体大语言模型(LLM)的疯狂进化。我们给它穿上基建外骨骼(Harness),给它挂载无数的函数工具(Skills),试图把它打造成一个无所不能的“全栈超…...