【快速上手】pyspark 集群环境下的搭建(Standalone模式)
目录
前言 :
一、spark运行的五种模式
二、 安装步骤
安装前准备
1.第一步:安装python
2.第二步:在bigdata01上安装spark
3.第三步:同步bigdata01中的spark到bigdata02和03上
三、集群启动/关闭
四、打开监控界面验证
前言:
spark有五种运行模式,本文介绍在集群环境下Standalone模式的搭建!!!YARN模式请前往下篇文章。
一、spark运行的五种模式
1、本地模式:
Local:一般用于做测试,验证代码逻辑,不是分布式运行,只会启动1个进程来运行所有任务。
2、集群模式:
Cluster:一般用于生产环境,用于实现PySpark程序的分布式的运行
①Standalone:Spark自带的分布式资源平台,功能类似于YARN
②YARN:Spark on YARN,将Spark程序提交给YARN来运行,工作中主要使用的模式
③Mesos:类似于YARN,国外见得多,国内基本见不到
④K8s:基于分布式容器的资源管理平台,运维层面的工具。
二、 安装步骤
安装前准备
(1)首先准备至少三台服务器 —— 我的三台服务器分别是:bigdata01 bigdata02 bigdata03
(2)各个服务器上都要安装jdk 和 hadoop
(3)在bigdata01服务器上有同步的脚本:xsync.sh(不是必须的)
我的所有安装包放在/opt/modules下,解压在/opt/installs下
1.第一步:安装python
通过Anaconda 安装 ,因为这个软件不仅有python还有其他的功能,比单纯安装python功能要强大。分别在bigdata01 bigdata02 bigdata03上安装Anaconda
Anaconda3-2021.05-Linux-x86_64.sh放在了我的资源里,需要的自取!!!
①.上传:将Anaconda上传到/opt/modules下
cd /opt/modules
②安装
# 添加执行权限
chmod u+x Anaconda3-2021.05-Linux-x86_64.sh
# 执行
sh ./Anaconda3-2021.05-Linux-x86_64.sh
# 过程
#第一次:【直接回车,然后按q】
Please, press ENTER to continue
>>>
#第二次:【输入yes】
Do you accept the license terms? [yes|no]
[no] >>> yes
#第三次:【输入解压路径:/opt/installs/anaconda3】
[/root/anaconda3] >>> /opt/installs/anaconda3#第四次:【输入yes,是否在用户的.bashrc文件中初始化Anaconda3的相关内容】
Do you wish the installer to initialize Anaconda3
by running conda init? [yes|no]
[no] >>> yes③刷新环境变量
source /root/.bashrc
④激活虚拟环境,如果需要关闭就使用:conda deactivate
conda activate
⑤编辑环境变量
vi /etc/profile
# 添加以下内容
export ANACONDA_HOME=/opt/installs/anaconda3
export PATH=$PATH:$ANACONDA_HOME/bin⑥刷新环境变量,并且做一个软链接
# 刷新环境变量
source /etc/profile
# 创建软连接
ln -s /opt/installs/anaconda3/bin/python3 /usr/bin/python3
# 验证
echo $ANACONDA_HOME

三台服务器都安装Anaconda 都一样 安装步骤!!!
2.第二步:在bigdata01上安装spark
spark-3.1.2-bin-hadoop3.2.tgz放在了我的资源里,需要的自取!!!
①上传解压安装:上传安装包到/opt/modules
cd /opt/modules
tar -zxf spark-3.1.2-bin-hadoop3.2.tgz -C /opt/installs
②重命名
cd /opt/installs
mv spark-3.1.2-bin-hadoop3.2 spark-standalone
③构建软连接
ln -s spark-standalone spark
④在HDFS上创建程序日志存储目录
注意:!!!首先如果没有启动hdfs,需要启动一下
# 第一台机器启动HDFS
start-dfs.sh
# 创建程序运行日志的存储目录
hdfs dfs -mkdir -p /spark/eventLogs/⑤修改配置文件:
spark-env.sh配置文件:
cd /opt/installs/spark/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh# 22行:申明JVM环境路径以及Hadoop的配置文件路径
export JAVA_HOME=/opt/installs/jdk
export HADOOP_CONF_DIR=/opt/installs/hadoop/etc/hadoop
# 60行左右
export SPARK_MASTER_HOST=bigdata01 # 主节点所在的地址
export SPARK_MASTER_PORT=7077 #主节点内部通讯端口,用于接收客户端请求
export SPARK_MASTER_WEBUI_PORT=8080 #主节点用于供外部提供浏览器web访问的端口
export SPARK_WORKER_CORES=1 # 指定这个集群总每一个从节点能够使用多少核CPU
export SPARK_WORKER_MEMORY=1g #指定这个集群总每一个从节点能够使用多少内存
export SPARK_WORKER_PORT=7078
export SPARK_WORKER_WEBUI_PORT=8081
export SPARK_DAEMON_MEMORY=1g # 进程自己本身使用的内存
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://bigdata01:9820/spark/eventLogs/ -Dspark.history.fs.cleaner.enabled=true"
# Spark中提供了一个类似于jobHistoryServer的进程,就叫做HistoryServer, 用于查看所有运行过的spark程序
spark-defaults.conf:Spark属性配置文件
mv spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf# 末尾
spark.eventLog.enabled true
spark.eventLog.dir hdfs://bigdata01:9820/spark/eventLogs
spark.eventLog.compress true
workers:从节点地址配置文件
mv workers.template workers
vim workers# 删掉localhost,添加以下内容
bigdata01
bigdata02
bigdata03
log4j.properties:日志配置文件
mv log4j.properties.template log4j.properties
vim log4j.properties# 19行:修改日志级别为WARN
log4j.rootCategory=WARN, console
3.第三步:同步bigdata01中的spark到bigdata02和03上
- 如果你bigdata01上有同步脚本,直接执行下面命令即可:
# 同步spark-standalone
xsync.sh /opt/installs/spark-standalone/
# 同步软链接
xsync.sh /opt/installs/spark- 如果没有,需要按照上面bigdata01的步骤在bigdata02 bigdata03上再安装一遍。
三、集群启动/关闭
- 启动master:
cd /opt/installs/spark sbin/start-master.sh -
启动所有worker:
sbin/start-workers.sh -
启动日志服务:
sbin/start-history-server.sh - 要想关闭某个服务,将start换为stop
四、打开监控界面验证
master监控界面:http://bigdata01:8080/
日志服务监控界面:http://bigdata01:18080/


相关文章:
【快速上手】pyspark 集群环境下的搭建(Standalone模式)
目录 前言 : 一、spark运行的五种模式 二、 安装步骤 安装前准备 1.第一步:安装python 2.第二步:在bigdata01上安装spark 3.第三步:同步bigdata01中的spark到bigdata02和03上 三、集群启动/关闭 四、打开监控界面验证 前…...

中文NLP地址要素解析【阿里云:天池比赛】
比赛地址:中文NLP地址要素解析 https://tianchi.aliyun.com/notebook/467867?spma2c22.12281976.0.0.654b265fTnW3lu长期赛: 分数:87.7271 排名:长期赛:56(本次)/6990(团体或个人)方案…...

使用AddressSanitizer内存检测
修改cmakelist.txt,在project(xxxx)后面追加: option(MEM_CHECK "memory check with AddressSanitizer" OFF) if(MEM_CHECK)set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fsanitizeaddress")set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS…...

11月1日星期五今日早报简报微语报早读
11月1日星期五,农历十月初一,早报#微语早读。 1、六大行今日起实施存量房贷利率新机制。 2、谷歌被俄罗斯罚款35位数,罚款远超全球GDP。 3、山西吕梁:女性35岁前登记结婚,给予1500元奖励。 4、我国人均每日上网时间…...

实用篇:Postman历史版本下载
postman历史版本下载步骤 1.官方历史版本发布信息 2.点进去1中的链接,往下滑动;选择你想要的版本 例如下载v11.18版本 3.根据操作系统选择 mac:mac系统postman下载 window:window系统postman下载 4.在old version里找到对应版本下载即可 先点击download 再点击free downlo…...

微服务实战系列之玩转Docker(十七)
导览 前言Q:如何实现etcd数据的可视化管理一、创建etcd集群1. 节点定义2. 集群成员2.1 docker ps2.2 docker exec2.3 etcdctl member list 二、发布数据1. 添加数据2. 数据共享 三、可视化管理1. ETCD Keeper入门1.1 简介1.2 安装1.2.1 定义compose.yml1.2.2 启动ke…...
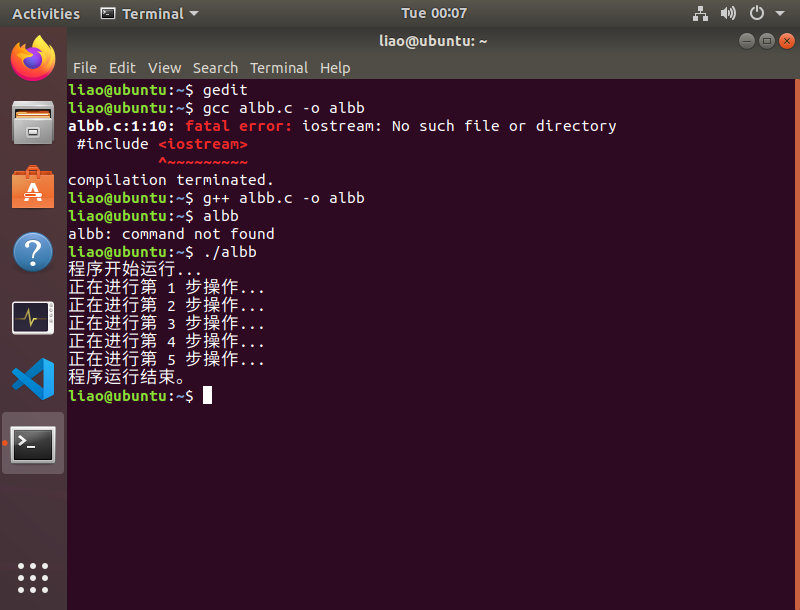
操作系统-实验报告单(1)
目录 1 实验目标 2 实验工具 3 实验内容、实验步骤及实验结果 一、安装虚拟机及Ubuntu 5、*存在虚拟机不能安装的问题 二、Ubuntu基本操作 1、桌面操作 2、终端命令行操作 三、在Ubuntu下运行C程序 3、*Ubuntu中编写一个Hello.c的主要程序 4 实验总结 实 验 报 告…...

rom定制系列------小米8青春版定制安卓14批量线刷固件 原生系统
💝💝💝小米8青春版。机型代码platina。官方最终版为 12.5.1安卓10的版本。客户需要安卓14的固件以便使用他们的软件。根据测试,原生pixeExpe固件适配兼容性较好。为方便客户批量进行刷写。修改固件为可fast批量刷写。整合底层分区…...

CATIA许可证常见问题解答
在使用CATIA软件的过程中,许可证问题常常是用户关心的焦点。为了帮助大家更好地理解和解决这些问题,我们整理了一份CATIA许可证常见问题解答,希望能为您提供便捷的参考。 问题一:如何激活CATIA许可证? 解答:…...

PySpark Standalone 集群部署教程
目录 1. 环境准备 1.1 配置免密登录 2. 下载并配置Spark 3. 配置Spark集群 3.1 配置spark-env.sh 3.2 配置spark-defaults.conf 3.3 设置Master和Worker节点 3.4 设配置log4j.properties 3.5 同步到所有Worker节点 4. 启动Spark Standalone集群 4.1 启动Master节点 …...

【源码+文档】基于SpringBoot+Vue旅游网站系统【提供源码+答辩PPT+参考文档+项目部署】
作者简介:✌CSDN新星计划导师、Java领域优质创作者、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流。✌ 主要内容:🌟Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能…...

9.排队模型-M/M/1
1.排队模型 在Excel中建立排队模型可以帮助分析系统中的客户流动和服务效率。以下是如何构建简单排队模型的步骤: 1.确定模型参数 到达率(λ):客户到达系统的平均速率(例如每小时到达的客户数)。服务率&…...

【GO学习笔记 go基础】编译器下载安装+Go设置代理加速+项目调试+基础语法+go.mod项目配置+接口(interface)
编译器下载&安装 下载并安装go1.23.2.windows-amd64.msi默认安装再C:\Program Files\Go\ PS C:\Users\kingchuxing\Documents> go version go version go1.23.2 windows/amd64Go设置GOPROXY国内加速 windows // 启用 Go Modules 功能 PS C:\Users\kingchuxing…...

从0开始学习shell脚本
了解Shell和Shell脚本 Shell:Shell是一个命令解释器,用来执行用户输入的命令。常用的Shell包括Bash、Zsh、Ksh等。Linux默认的Shell通常是Bash。 Shell脚本:Shell脚本是由一系列命令组成的文件,脚本可以运行一连串命令ÿ…...

官方工具重装Windows 11当前版本 /绕过硬件检查/免U盘
官方工具重装Windows 11当前版本 /绕过硬件检查/免U盘 官方工具重装Windows 11当前版本 /绕过硬件检查/免U盘_win11安装跳过检测-CSDN博客...
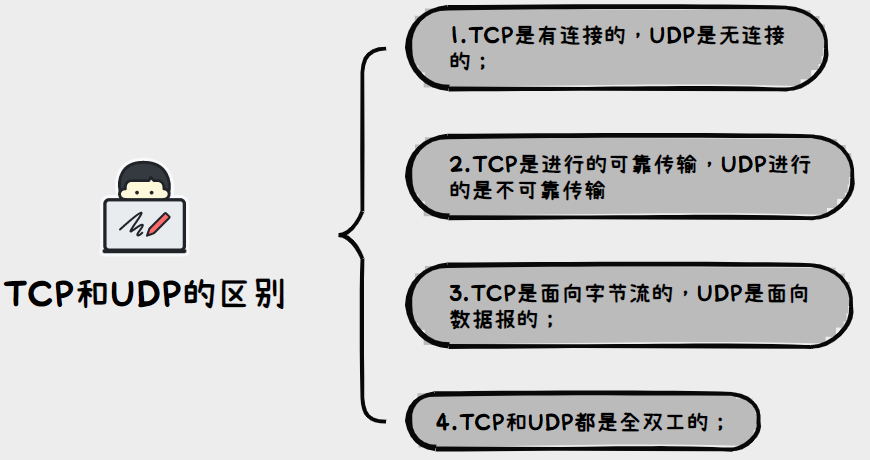
JavaEE初阶---网络原理/UDP服务器客户端程序
文章目录 1.网络初识2.网络编程2.1TCP/UDP区别介绍2.2UDP的socket api使用2.3UDP协议里面的服务器客户端程序 1.网络初识 网络和计算机类似:都是属于军用》民用; 网络诞生于美苏争霸时期,当时就感觉核战争一触即发,形式非常严峻…...
)
每天10个vue面试题(六)
1、对Vue设计原则的理解? 渐进式JavaScript框架:与其它大型框架不同的是,Vue被设计为可以自底向上逐层应用。Vue的核心库只关注视图层,不仅易于上手,还便于与第三方库或既有项目整合。另一方面,当与现代化…...

Qt:信号和槽
目录 关于信号 connect函数 关于connect connect的使用 自定义信号、自定义槽 自定义槽 第一种方式自定义槽 第二种方式自定义槽 自定义信号 信号槽 带参数的信号槽 参数个数一致的示例 参数个数不一致的示例 Q_OBJECT 信号和槽存在的意义 disconnect函数 使用…...

可以免费商用的字体下载
这里介绍一个开源仓库,收录的可以免费商用的字体,目前中文字体1308款,英文字体980款,共约2288多款字体。 Description Free fonts that can be used commercially.There are currently 1308 Chinese fonts and 980 English font…...

centos7之LVS-TUNNEL模式
介绍 优缺点以及适用场景 优点:能负载更多的Realserver减轻LB的压力。LVS和Realserver可以不再同一网段。 缺点:tun模式的开销比较大(出口流量大),性能不如DR模式。不支持端口转发。后端Realserver系统必须支持tunnel协议。 适用ÿ…...

GitHub Desktop汉化神器:3分钟让英文界面变中文
GitHub Desktop汉化神器:3分钟让英文界面变中文 【免费下载链接】GitHubDesktop2Chinese GithubDesktop语言本地化(汉化)工具 【GitHub桌面客户端中文汉化】 项目地址: https://gitcode.com/gh_mirrors/gi/GitHubDesktop2Chinese 还在为GitHub Desktop的英文…...
)
Midjourney色调分离终极手册(仅限Pro用户内部流通的17个未公开--no--参数组合)
更多请点击: https://codechina.net 第一章:Midjourney色调分离的核心原理与视觉语义边界 色调分离(Tonal Separation)在 Midjourney 并非原生参数,而是通过提示词工程、风格化权重控制与隐式潜在空间引导协同实现的视…...

ncmdump终极教程:3分钟解锁网易云音乐NCM加密格式
ncmdump终极教程:3分钟解锁网易云音乐NCM加密格式 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM格式文件无法在其他播放器使用而烦恼吗?ncmdump就是你需要的终极解决方案…...

从欧氏距离到余弦相似度:5种距离度量如何影响你的KNN模型?用Scikit-learn实战对比
从欧氏距离到余弦相似度:5种距离度量如何影响你的KNN模型?用Scikit-learn实战对比 在机器学习的世界里,K近邻算法(KNN)因其简单直观而广受欢迎。但很多实践者往往只关注k值的选择,却忽略了另一个同等重要的超参数——距离度量。就…...

为Hermes Agent配置自定义Provider并指向Taotoken聚合服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Hermes Agent配置自定义Provider并指向Taotoken聚合服务 Hermes Agent 是一个功能强大的智能体开发框架,它支持通过自…...

树莓派CM4刀片服务器设计:从电源管理到集群部署全解析
1. 项目概述:当树莓派计算模块遇上“刀片式”设计如果你和我一样,是个树莓派的老玩家,从最初的Model B一路玩到最新的5代,那你肯定对树莓派计算模块(Compute Module,简称CM)又爱又恨。爱的是它把…...

AI赋能泳装设计——让科技与时尚共舞
AI赋能泳装设计——让科技与时尚共舞当AI遇见泳装:北京先智先行用智能技术重新定义夏日时尚夏日的脚步渐近,泳装市场即将迎来年度销售旺季。在这个看脸的时代,消费者对泳装的要求早已不止于"能穿",更追求个性化、时尚感…...

掌握AMD Ryzen处理器精细调控:SMUDebugTool实战指南
掌握AMD Ryzen处理器精细调控:SMUDebugTool实战指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitc…...

从PostgreSQL老手视角:快速上手华为GaussDB极简版,这些操作习惯几乎一样
从PostgreSQL老手视角:快速上手华为GaussDB极简版的10个关键习惯迁移 如果你已经习惯了PostgreSQL的命令行操作和配置逻辑,第一次接触华为GaussDB时会有种奇妙的熟悉感——就像走进一间重新装修过的老房子,家具摆放的位置几乎没变,…...

深入Linux内存管理:从虚拟内存到OOM Killer的完整解析
1. 从物理到虚拟:内存管理的演进与核心挑战干了这么多年系统开发和性能调优,内存问题始终是那个最让人头疼,但又不得不面对的“老朋友”。无论是半夜被报警叫醒处理线上服务的OOM(Out of Memory)崩溃,还是为…...