Elasticsearch —— ES 环境搭建、概念、基本操作、文档操作、SpringBoot继承ES
文章中会用到的文件,如果官网下不了可以在这下
链接: https://pan.baidu.com/s/1SeRdqLo0E0CmaVJdoZs_nQ?pwd=xr76
提取码: xr76
一、 ES 环境搭建
注:环境搭建过程中的命令窗口不能关闭,关闭了服务就会关闭(除了修改设置后重启的)
● 安装 ES
ES 下载地址: https://www.elastic.co/cn/downloads/elasticsearch 默认打开是最新版本
7.6.1 版下载:
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.1-windows-x86_64.zip
新建一个文件夹,重名为 ES ,将 elasticsearch-7.6.1-windows-x86_64.zip 解压
在 bin 目录中 双击启动 elasticsearch.bat

访问 http://127.0.0.1:9200

成功
● 安装数据可视化界面 elasticsearch head
前提需要安装 nodejs
github 下载 elasticsearch head : https://github.com/mobz/elasticsearch-head/
解压 elasticsearch-head-master.zip
从界面访问 9200 服务会出现跨域问题
在 es/elasticsearch-7.6.1/config 目录中的 elasticsearch.yml 文件最底下配置
# 开启跨域
http.cors.enabled: true
# 所有人访问
http.cors.allow-origin: "*"

重启 elasticsearch (重新运行elasticsearch.bat)
命令行进入目录(在 \es\elasticsearch-head-master 中)

分别输入:
npm install
*回车
npm run start
*回车

然后访问 http://localhost:9100 或 http://127.0.0.1:9100

成功
● 安装可视化 kibana 组件
下载版本要和 ES 版本一致
下载地址https://www.elastic.co/cn/downloads/kibana: 默认打开是最新版本
7.6.1 下载版 :https://artifacts.elastic.co/downloads/kibana/kibana-7.6.1-windows-x86_64.zip
解压 kibana-7.6.1-windows-x86_64.zip,汉化 kibana
修改 \es\kibana-7.6.1-windows-x86_64\config 目录下的 kibana.yml 文件
i18n.locale: "zh-CN


双击 bin 目录下的 kibana.bat 启动

访问 http://localhost:5601 或 http://127.0.0.1:5601

● 安装 ik 分词器插件
7.6.1 版下载: https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.1/elasticsearch- analysis-ik-7.6.1.zip
解压 elasticsearch-analysis-ik-7.6.1.zip,在 \es\elasticsearch-7.6.1\plugins 目录下创建名称为ik的文件夹,将解压后的文件复制到 ik 目录。


自定义 ik 分词器(非必要,可以根据实际情况选择配置)
在 elasticsearch-7.6.1\plugins\ik\config
添加 xxx.dic 文件 定义词组
.dic 文件必须是 utf-8 编码格式,否则启动报错
在 IKAnalyzer.cfg.xml 文件添加自定义分词器文件



* 记得重启 elasticsearch
在 Kibana 中打开控制台

在没有安装 ik 分词器时
GET _analyze
{"analyzer": "standard","text": "我是中国人"
}
可以看到在没有启用 ik分词器时,分的关键词是单字为组的,不符合正常使用。
这是使用 ik分词器后的:
最少切分:

最细粒度划分:

二、 ES 基本概念
elasticsearch 是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为 json 格式后存储在 elasticsearch 中。
索引:同类型文档的集合
文档:一条数据就是一个文档,es 中是 Json 格式
字段:Json 文档中的字段
映射:索引中文档的约束,比如字段名称、类型

● 关系行数据库 MySQL 和 elasticsearch 对比

| MySQL | Elasticsearch | 说明 |
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| ROW | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| CoLumn | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
Elasticsearch:擅长海量数据的搜索、分析、计算

● 正向索引和倒排索引
Mysql 采用正向索引:基于文档 id 创建索引。查询词条时必须先找到文档,而判断是否包含搜索的内容. elasticsearch 采用倒排索引:
文档(document):每条数据就是一个文档
词条(term):文档按照语义分成的词语


三、 ES 索引库基本操作
● 创建索引库
mapping 属性 : mapping 是对索引库中文档的约束,常见的 mapping 属性包括:
type:字段数据类型,常见的简单类型有:
字符串:text(可分词的文本),keyword(精确值,例如:品牌,国家,邮箱)
数值:long、integer、short、byte、double、float、
布尔:boolean
日期:date
对象:object
index:是否创建索引参与搜索,默认为 true,如果不需要参与搜索设置为 false
analyzer:使用哪种分词器
实例,创建一个新闻索引库:
PUT /news
{
"mappings": {
"properties": {
"id":{
"type": "integer",
"index": false
},
"title":{
"type": "text",
"analyzer": "ik_max_word"
},
"img":{
"type": "keyword",
"index": false
},
"operTime":{
"type": "date",
"index": false
}
}
}
}
● 查询索引库
语法: GET /索引库名
实例: GET /news

● 删除索引库
语法: DELETE /索引库名
实例: DELETE /news

● 修改索引库
索引库和 mapping 一旦创建无法修改(不能删除索引),但是可以添加新的字段,语法如下:
PUT /news/_mapping
{
"properties":{
"count":{
"type":"long"
}
}
}

四、 ES 文档操作
● 新增文档
语法:
POST /索引库名/_doc/文档 id
{
“字段名 1”:”值 1”
“字段名 2”:”值 2”
.....
}
POST /news/_doc/1
{"id":1,"title":"小米公司发布最新小米手机","img":"1111111111.jpg","dzcount":30
}POST /news/_doc/2
{"id":2,"title":"华为公司最新科技","img":"2222222222.jpg","dzcount":22
}● 查询文档
语法:
GET /索引库名/_doc/文档 id
GET /news/_doc/1● 删除文档
语法:
DELETE /索引库名/_doc/文档 id
DELETE /news/_doc/3● 修改文档
POST /索引库名/_update/文档 id
{
"doc":{
"要修改的字段":"新值"
}
}
● 搜索文档(分词查询)
GET /news/_search
{
"query":{
"match":{
"title":"手机"
}
}
}
GET /news/_search
{"query":{"match":{"title":"小米公司"}}
}
五、 SpringBoot 集成 ES
● 搭建
官网地址: https://www.elastic.co/guide/en/elasticsearch/client/index.html
指定版本,版本必须与安装的 ES 版本一致(在 pom.xml 中)
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.6.1</elasticsearch.version>
</properties>
添加依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
添加初始化 RestHighLevelClient 的配置类
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class ElasticSearchConfig {@Beanpublic RestHighLevelClient restHighLevelClient(){RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));return client;}}
● 索引库操作
• 创建索引库
CreateIndexRequest request = new CreateIndexRequest("users");CreateIndexResponsecreateIndexResponse = restHighLevelClient.indices().create(request,RequestOptions.DEFAULT);• 判断索引库是否存在
GetIndexRequest request = new GetIndexRequest("users");boolean exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);• 删除索引库
DeleteIndexRequest indexRequest = new DeleteIndexRequest("users");AcknowledgedResponse delete = restHighLevelClient.indices().delete(indexRequest, RequestOptions.DEFAULT);delete.isAcknowledged();//返回 true 删除成功,返回 false 删除失败新建一个 EStest.java 类
● 文档操作
• 添加文档
//将新闻添加到 mysql 的同时,将数据同步更新到 ES,为搜索提供数据
News news = new News();
news.setId(3);
news.setTitle("美国今年要总统选择,拜登着急了");
news.setImg("aaaaasssss.jpg");
IndexRequest indexRequest = new IndexRequest("news").id(news.getId().toString());
//将对象转为 json 存进 ES
indexRequest.source(new ObjectMapper().writeValueAsString(news),XContentType.JSON);
restHighLevelClient.index(indexRequest,RequestOptions.DEFAULT);• 修改文档
News news = new News();
news.setId(3);
news.setTitle("中国航母开往美国,准备开战,拜登着急了");
news.setImg("dddddddddddd.jpg");
UpdateRequest updateRequest = new UpdateRequest("news",news.getId().toString());
updateRequest.doc(new ObjectMapper().writeValueAsString(news), XContentType.JSON);
restHighLevelClient.update(updateRequest,RequestOptions.DEFAULT);• 查询文档
GetRequest getRequest = new GetRequest("news","1");
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
//获取查询的内容,返回 json 格式
String json = getResponse.getSourceAsString();
//使用 jackson 组件将 json 字符串解析为对象
News news = new ObjectMapper().readValue(json, News.class);• 删除文档
DeleteRequest deleteRequest = new DeleteRequest("news","1");
DeleteResponse delete = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);• 搜索文档
SearchRequest searchRequest = new SearchRequest("news");
SearchRequest searchRequest = new SearchRequest("news");
//精确条件查询
searchRequest.source().query(QueryBuilders.termQuery("title","美国"));
//发送查询请求
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//接收查询结果
SearchHits hits = search.getHits();
//组装查询结果
ArrayList<News> list = new ArrayList<>();
//取出结果集
for (SearchHit searchHit : hits.getHits()){
String json = searchHit.getSourceAsString();
News news = new ObjectMapper().readValue(json,News.class);
list.add(news);
}相关文章:
Elasticsearch —— ES 环境搭建、概念、基本操作、文档操作、SpringBoot继承ES
文章中会用到的文件,如果官网下不了可以在这下 链接: https://pan.baidu.com/s/1SeRdqLo0E0CmaVJdoZs_nQ?pwdxr76 提取码: xr76 一、 ES 环境搭建 注:环境搭建过程中的命令窗口不能关闭,关闭了服务就会关闭(除了修改设置后重启的…...

ElSelect 组件的 onChange 和 onInput 事件的区别
偶然遇到一个问题,在 ElSelect 组件中设置 filterable 属性后,监测不到复制粘贴的内容,也就意味着不能调用接口,下拉框内容为空。 简要代码如下: <ElSelectstyle"width: 256px"multiplev-model{siteIdL…...

加密与数据提取:保护隐私的新途径
加密与数据提取:保护隐私的新途径 在数字化时代,数据已成为驱动社会进步和经济发展的关键要素。然而,随着数据量的爆炸性增长,个人隐私保护成为了一个亟待解决的问题。如何在利用数据价值的同时,确保个人隐私不被侵犯…...
波澜壮阔的一生」2024年11月1日)
博客摘录「 宋宝华:Linux文件读写(BIO)波澜壮阔的一生」2024年11月1日
同时内核会给第2页标识一个PageReadahead标记,意思就是如果app接着读第2页,就可以预判app在做顺序读,这样我们在app读第2页的时候,内核可以进一步异步预读。 每个bio对应的硬盘里面一块连续的位置,每一块硬盘里面连续…...

使用华为云数字人可以做什么
在数字化和智能化快速发展的今天,企业面临着如何提升客户体验、优化运营效率的挑战。华为云数字人作为一种创新的智能交互解决方案,为企业提供了全新的可能性,助力企业在各个领域实现智能化升级。 提升客户服务体验 华为云数字人能够模拟真…...
leetcode刷题记录——(十六)349. 两个数组的交集
(一)问题描述 . - 力扣(LeetCode). - 备战技术面试?力扣提供海量技术面试资源,帮助你高效提升编程技能,轻松拿下世界 IT 名企 Dream Offer。https://leetcode.cn/problems/intersection-of-two-arrays/ …...

vue3实现规则编辑器
组件用于创建和编辑复杂的条件规则,支持添加、删除条件和子条件,以及选择不同的条件类型。 可实现json数据和页面显示的转换。 代码实现 : index.vue: <template><div class"allany-container"><div class"co…...

【快速上手】pyspark 集群环境下的搭建(Standalone模式)
目录 前言 : 一、spark运行的五种模式 二、 安装步骤 安装前准备 1.第一步:安装python 2.第二步:在bigdata01上安装spark 3.第三步:同步bigdata01中的spark到bigdata02和03上 三、集群启动/关闭 四、打开监控界面验证 前…...

中文NLP地址要素解析【阿里云:天池比赛】
比赛地址:中文NLP地址要素解析 https://tianchi.aliyun.com/notebook/467867?spma2c22.12281976.0.0.654b265fTnW3lu长期赛: 分数:87.7271 排名:长期赛:56(本次)/6990(团体或个人)方案…...

使用AddressSanitizer内存检测
修改cmakelist.txt,在project(xxxx)后面追加: option(MEM_CHECK "memory check with AddressSanitizer" OFF) if(MEM_CHECK)set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fsanitizeaddress")set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS…...

11月1日星期五今日早报简报微语报早读
11月1日星期五,农历十月初一,早报#微语早读。 1、六大行今日起实施存量房贷利率新机制。 2、谷歌被俄罗斯罚款35位数,罚款远超全球GDP。 3、山西吕梁:女性35岁前登记结婚,给予1500元奖励。 4、我国人均每日上网时间…...

实用篇:Postman历史版本下载
postman历史版本下载步骤 1.官方历史版本发布信息 2.点进去1中的链接,往下滑动;选择你想要的版本 例如下载v11.18版本 3.根据操作系统选择 mac:mac系统postman下载 window:window系统postman下载 4.在old version里找到对应版本下载即可 先点击download 再点击free downlo…...

微服务实战系列之玩转Docker(十七)
导览 前言Q:如何实现etcd数据的可视化管理一、创建etcd集群1. 节点定义2. 集群成员2.1 docker ps2.2 docker exec2.3 etcdctl member list 二、发布数据1. 添加数据2. 数据共享 三、可视化管理1. ETCD Keeper入门1.1 简介1.2 安装1.2.1 定义compose.yml1.2.2 启动ke…...
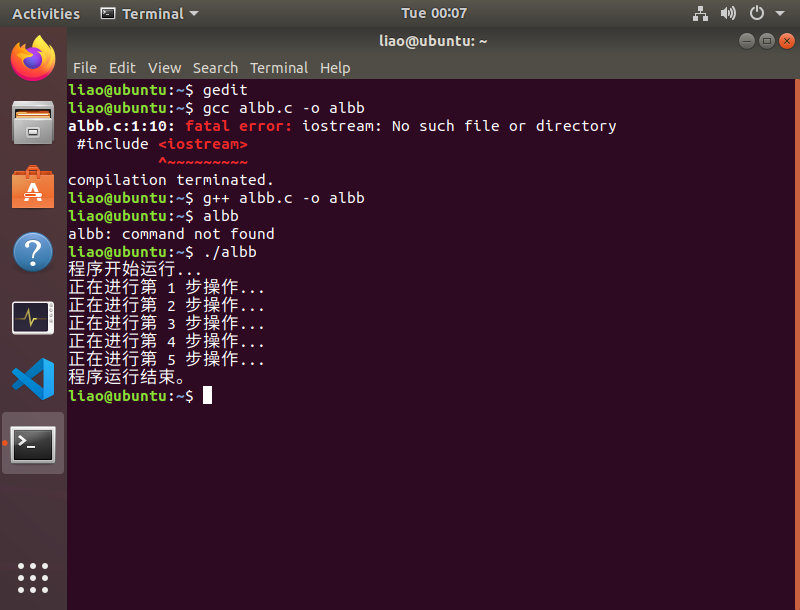
操作系统-实验报告单(1)
目录 1 实验目标 2 实验工具 3 实验内容、实验步骤及实验结果 一、安装虚拟机及Ubuntu 5、*存在虚拟机不能安装的问题 二、Ubuntu基本操作 1、桌面操作 2、终端命令行操作 三、在Ubuntu下运行C程序 3、*Ubuntu中编写一个Hello.c的主要程序 4 实验总结 实 验 报 告…...

rom定制系列------小米8青春版定制安卓14批量线刷固件 原生系统
💝💝💝小米8青春版。机型代码platina。官方最终版为 12.5.1安卓10的版本。客户需要安卓14的固件以便使用他们的软件。根据测试,原生pixeExpe固件适配兼容性较好。为方便客户批量进行刷写。修改固件为可fast批量刷写。整合底层分区…...

CATIA许可证常见问题解答
在使用CATIA软件的过程中,许可证问题常常是用户关心的焦点。为了帮助大家更好地理解和解决这些问题,我们整理了一份CATIA许可证常见问题解答,希望能为您提供便捷的参考。 问题一:如何激活CATIA许可证? 解答:…...

PySpark Standalone 集群部署教程
目录 1. 环境准备 1.1 配置免密登录 2. 下载并配置Spark 3. 配置Spark集群 3.1 配置spark-env.sh 3.2 配置spark-defaults.conf 3.3 设置Master和Worker节点 3.4 设配置log4j.properties 3.5 同步到所有Worker节点 4. 启动Spark Standalone集群 4.1 启动Master节点 …...

【源码+文档】基于SpringBoot+Vue旅游网站系统【提供源码+答辩PPT+参考文档+项目部署】
作者简介:✌CSDN新星计划导师、Java领域优质创作者、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流。✌ 主要内容:🌟Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能…...

9.排队模型-M/M/1
1.排队模型 在Excel中建立排队模型可以帮助分析系统中的客户流动和服务效率。以下是如何构建简单排队模型的步骤: 1.确定模型参数 到达率(λ):客户到达系统的平均速率(例如每小时到达的客户数)。服务率&…...

【GO学习笔记 go基础】编译器下载安装+Go设置代理加速+项目调试+基础语法+go.mod项目配置+接口(interface)
编译器下载&安装 下载并安装go1.23.2.windows-amd64.msi默认安装再C:\Program Files\Go\ PS C:\Users\kingchuxing\Documents> go version go version go1.23.2 windows/amd64Go设置GOPROXY国内加速 windows // 启用 Go Modules 功能 PS C:\Users\kingchuxing…...

FontCenter:AutoCAD字体管理终极解决方案,彻底告别字体缺失困扰
FontCenter:AutoCAD字体管理终极解决方案,彻底告别字体缺失困扰 【免费下载链接】FontCenter AutoCAD自动管理字体插件 项目地址: https://gitcode.com/gh_mirrors/fo/FontCenter 你是否曾经在打开AutoCAD图纸时遇到过字体缺失的尴尬?…...

免费压缩包密码恢复工具:ArchivePasswordTestTool终极指南
免费压缩包密码恢复工具:ArchivePasswordTestTool终极指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经因为忘记压…...

DdddOcr:5分钟掌握Python验证码识别,彻底告别手动输入![特殊字符]
DdddOcr:5分钟掌握Python验证码识别,彻底告别手动输入!🚀 【免费下载链接】ddddocr 带带弟弟 通用验证码识别OCR pypi版 项目地址: https://gitcode.com/gh_mirrors/dd/ddddocr 还在为繁琐的验证码输入而烦恼吗?…...
)
用一台旧笔记本和朋友联机玩《我的世界》Fear Nightfall整合包,保姆级开服教程(含SakuraFrp配置)
用旧笔记本搭建《我的世界》Fear Nightfall联机服务器的完整指南 1. 为什么选择旧笔记本作为服务器主机? 对于许多《我的世界》玩家来说,和朋友一起体验大型整合包是件令人兴奋的事,但租用云服务器的高昂成本往往让人望而却步。实际上&…...

MPC Video Renderer:让你的Windows视频播放体验焕然一新的终极指南
MPC Video Renderer:让你的Windows视频播放体验焕然一新的终极指南 【免费下载链接】VideoRenderer Внешний видео-рендерер 项目地址: https://gitcode.com/gh_mirrors/vi/VideoRenderer 还在为Windows系统上的视频播放效果感到失望吗&…...

如何快速上手Hertz.dev:5分钟完成首个全双工音频对话
如何快速上手Hertz.dev:5分钟完成首个全双工音频对话 【免费下载链接】hertz-dev first base model for full-duplex conversational audio 项目地址: https://gitcode.com/gh_mirrors/he/hertz-dev 想要体验革命性的全双工音频对话技术吗?Hertz.…...

RA6M3 HMI开发板SDHI接口与SD卡存储性能深度测评
1. 项目概述:从一块开发板到人机交互界面的探索最近在做一个工业现场数据监控终端的原型,核心需求是在一块屏幕上实时显示传感器数据、设备状态,并且能通过触摸屏进行简单的参数设置。选型的时候,瑞萨电子的RA6M3 HMI Board进入了…...

Windows字体美化终极指南:No!! MeiryoUI恢复你的系统字体自定义权
Windows字体美化终极指南:No!! MeiryoUI恢复你的系统字体自定义权 【免费下载链接】noMeiryoUI No!! MeiryoUI is Windows system font setting tool on Windows 8.1/10/11. 项目地址: https://gitcode.com/gh_mirrors/no/noMeiryoUI 还在为Windows系统单调的…...

如何选择最适合的许可证扫描工具:LicenseFinder与其他工具的全面对比分析
如何选择最适合的许可证扫描工具:LicenseFinder与其他工具的全面对比分析 【免费下载链接】LicenseFinder Find licenses for your projects dependencies. 项目地址: https://gitcode.com/gh_mirrors/li/LicenseFinder 在当今开源软件盛行的时代,…...
)
DeepSeek LeetCode 2509.查询树中环的长度 public int[] cycleLengthQueries(int n, int[][] queries)
这道题的核心是找到两个节点在完全二叉树中的路径长度,然后计算环的长度。关键思路:1. 完全二叉树的节点编号规律:节点 i 的父节点是 i/2 2. 两个节点之间的路径长度 深度差 2 LCA深度差 3. 环的长度 路径长度 1(加回重复的L…...