Gradio DataFrame分页功能详解:从入门到实战
Gradio DataFrame分页功能详解:从入门到实战
- 1. 引言
- 2. 为什么需要分页?
- 3. 环境准备
- 4. 基础知识准备
- 5. 代码实现
- 5.1 创建示例数据
- 5.2 分页状态管理
- 5.3 分页核心逻辑
- 5.4 创建Gradio界面
- 6. 关键功能解析
- 6.1 页码计算
- 6.2 数据切片
- 7. 使用示例
- 8. 实用技巧
- 9. 常见问题解答
- 10. 进阶优化建议
- 11. 总结
- 12. 完整代码
1. 引言
大家好!今天我要和大家分享如何使用Gradio实现DataFrame的分页功能。如果你正在开发数据展示界面,经常需要处理大量数据,那么分页功能就变得非常重要。本文将从基础开始,一步步教你如何实现一个专业的分页系统。
2. 为什么需要分页?
想象一下,如果你有一个包含1000条记录的表格,全部显示在一个页面上会有什么问题:
- 页面加载缓慢
- 用户体验差
- 不容易找到特定数据
- 系统资源消耗大
所以,我们需要分页功能来解决这些问题!
3. 环境准备
首先,确保你已经安装了必要的Python包:
pip install gradio pandas numpy
4. 基础知识准备
在开始之前,你需要了解:
- Python基础语法
- pandas的基本操作
- 简单的Gradio使用经验
5. 代码实现
5.1 创建示例数据
首先,我们需要一些示例数据来测试我们的分页功能:
def create_sample_data(rows=100):"""创建示例数据"""data = {'ID': range(1, rows + 1),'Name': [f'用户{i}' for i in range(1, rows + 1)],'Score': np.random.randint(60, 100, rows),'Date': pd.date_range(start='2024-01-01', periods=rows).strftime('%Y-%m-%d').tolist()}return pd.DataFrame(data)
这段代码会创建一个包含ID、姓名、分数和日期的数据表。
5.2 分页状态管理
我们使用一个专门的类来管理分页状态:
@dataclass
class PaginationState:"""分页状态管理类"""current_page: int = 1 # 当前页码page_size: int = 10 # 每页显示条数total_pages: int = 1 # 总页数
5.3 分页核心逻辑
下面是处理分页的核心类:
class DataFramePaginator:"""DataFrame分页管理器"""def __init__(self, page_size: int = 10):self.page_size = page_sizedef get_page_data(self, df: pd.DataFrame, page_num: int) -> pd.DataFrame:"""获取指定页的数据"""# 计算总页数total_pages = len(df) // self.page_size + (1 if len(df) % self.page_size > 0 else 0)# 确保页码在有效范围内page_num = max(1, min(page_num, total_pages))# 计算当前页的数据范围start_idx = (page_num - 1) * self.page_sizeend_idx = min(start_idx + self.page_size, len(df))# 返回当前页的数据return df.iloc[start_idx:end_idx]
5.4 创建Gradio界面
现在,让我们把所有东西组合在一起:
def create_ui():with gr.Blocks() as demo:# 创建界面组件with gr.Row():table = gr.DataFrame(interactive=False)with gr.Row():prev_button = gr.Button("上一页")next_button = gr.Button("下一页")page_dropdown = gr.Dropdown(choices=["1"], value="1", label="跳转到页")# 设置回调函数...return demodemo = create_ui()
demo.launch()
6. 关键功能解析
6.1 页码计算
total_pages = len(df) // page_size + (1 if len(df) % page_size > 0 else 0)
这行代码计算总页数:
len(df) // page_size: 计算完整的页数1 if len(df) % page_size > 0 else 0: 如果有余下的记录,加一页
6.2 数据切片
start_idx = (page_num - 1) * page_size
end_idx = min(start_idx + page_size, len(df))
current_page_data = df.iloc[start_idx:end_idx]
这段代码:
- 计算当前页的起始索引
- 计算结束索引(注意不要超过数据总长度)
- 使用iloc获取对应的数据切片
7. 使用示例
# 创建示例数据
df = create_sample_data(100) # 创建100行数据# 创建分页器
paginator = DataFramePaginator(page_size=10)# 获取第一页数据
first_page = paginator.get_page_data(df, 1)
8. 实用技巧
-
数据量控制
- 建议每页显示10-20条数据
- 可以添加页码大小选择功能
-
性能优化
- 使用缓存机制
- 避免频繁重新计算
-
用户体验
- 添加加载提示
- 保持界面响应速度
9. 常见问题解答
Q: 为什么我的页码计算结果不对?
A: 检查是否正确处理了除法运算和余数。
Q: 数据更新后页码怎么处理?
A: 需要重新计算总页数,并确保当前页码有效。
10. 进阶优化建议
- 添加搜索功能
- 实现排序功能
- 添加数据过滤
- 实现数据导出功能
11. 总结
本文介绍了如何使用Gradio实现DataFrame的分页功能。通过合理的代码组织和清晰的逻辑结构,我们实现了一个实用的分页系统。希望这篇教程对你有帮助!
12. 完整代码
import gradio as gr
import pandas as pd
import numpy as np
from dataclasses import dataclass
from typing import List, Dict, Tuple, Any, Optional
import random@dataclass
class PaginationState:"""分页状态管理类"""current_page: int = 1page_size: int = 10total_pages: int = 1def to_dict(self) -> dict:return {"current_page": self.current_page,"page_size": self.page_size,"total_pages": self.total_pages}class DataFramePaginator:"""DataFrame分页管理器"""def __init__(self, page_size: int = 10):self.page_size = page_sizeself.pagination_states: Dict[str, PaginationState] = {}def calculate_total_pages(self, df: pd.DataFrame) -> int:"""计算总页数"""return len(df) // self.page_size + (1 if len(df) % self.page_size > 0 else 0)def get_page_data(self, df: pd.DataFrame, page_num: int) -> pd.DataFrame:"""获取指定页的数据"""total_pages = self.calculate_total_pages(df)page_num = max(1, min(page_num, total_pages))start_idx = (page_num - 1) * self.page_sizeend_idx = min(start_idx + self.page_size, len(df))return df.iloc[start_idx:end_idx]def get_pagination_state(self, df_id: str, df: pd.DataFrame) -> PaginationState:"""获取或创建分页状态"""if df_id not in self.pagination_states:self.pagination_states[df_id] = PaginationState(current_page=1,page_size=self.page_size,total_pages=self.calculate_total_pages(df))return self.pagination_states[df_id]def update_pagination_state(self, df_id: str, page_num: int, df: pd.DataFrame) -> None:"""更新分页状态"""state = self.get_pagination_state(df_id, df)state.current_page = page_numstate.total_pages = self.calculate_total_pages(df)def create_sample_data(prefix: str, rows: int = 100) -> pd.DataFrame:"""创建示例数据"""data = {'ID': range(1, rows + 1),f'{prefix}_Name': [f'{prefix}用户{i}' for i in range(1, rows + 1)],f'{prefix}_Score': np.random.randint(60, 100, rows),f'{prefix}_Date': pd.date_range(start='2024-01-01', periods=rows).strftime('%Y-%m-%d').tolist()}return pd.DataFrame(data)class MultiDataFrameUI:"""多DataFrame界面管理器"""def __init__(self, df_count: int = 10):self.df_count = df_countself.paginator = DataFramePaginator()self.dataframes = {f"df_{i}": create_sample_data(f"表格{i}", random.randint(30, 100))for i in range(1, df_count + 1)}def create_df_components(self) -> Tuple[Dict[str, Any], List[Any]]:"""创建DataFrame相关的UI组件"""components = {}updates = []for df_id in self.dataframes.keys():with gr.Row():components[f"{df_id}_table"] = gr.DataFrame(interactive=False,label=f"数据表 {df_id}")with gr.Row():components[f"{df_id}_prev"] = gr.Button("上一页",elem_id=f"{df_id}_prev")components[f"{df_id}_next"] = gr.Button("下一页",elem_id=f"{df_id}_next")components[f"{df_id}_page"] = gr.Dropdown(choices=["1"],value="1",label="跳转到页",elem_id=f"{df_id}_page")# 收集需要更新的组件updates.extend([components[f"{df_id}_table"],components[f"{df_id}_prev"],components[f"{df_id}_next"],components[f"{df_id}_page"]])return components, updatesdef update_table(self,df_id: str,page_num: int,*args) -> Tuple[pd.DataFrame, gr.Button, gr.Button, gr.Dropdown]:"""更新表格显示内容"""df = self.dataframes[df_id]self.paginator.update_pagination_state(df_id, page_num, df)state = self.paginator.get_pagination_state(df_id, df)current_page_data = self.paginator.get_page_data(df, state.current_page)page_choices = [str(i) for i in range(1, state.total_pages + 1)]return (current_page_data,gr.update(interactive=(state.current_page > 1)),gr.update(interactive=(state.current_page < state.total_pages)),gr.update(choices=page_choices, value=str(state.current_page)))def setup_callbacks(self, components: Dict[str, Any]) -> None:"""设置组件回调"""for df_id in self.dataframes.keys():# 上一页按钮回调components[f"{df_id}_prev"].click(lambda pg, id=df_id: self.update_table(id,int(pg) - 1),inputs=[components[f"{df_id}_page"]],outputs=[components[f"{df_id}_table"],components[f"{df_id}_prev"],components[f"{df_id}_next"],components[f"{df_id}_page"]])# 下一页按钮回调components[f"{df_id}_next"].click(lambda pg, id=df_id: self.update_table(id,int(pg) + 1),inputs=[components[f"{df_id}_page"]],outputs=[components[f"{df_id}_table"],components[f"{df_id}_prev"],components[f"{df_id}_next"],components[f"{df_id}_page"]])# 页码下拉框回调components[f"{df_id}_page"].change(lambda pg, id=df_id: self.update_table(id,int(pg)),inputs=[components[f"{df_id}_page"]],outputs=[components[f"{df_id}_table"],components[f"{df_id}_prev"],components[f"{df_id}_next"],components[f"{df_id}_page"]])def main():# 创建界面实例ui = MultiDataFrameUI(df_count=10)# 创建Gradio界面with gr.Blocks() as demo:gr.Markdown("# 多表格分页示例")# 创建组件components, updates = ui.create_df_components()# 设置回调ui.setup_callbacks(components)# 初始化显示for df_id in ui.dataframes.keys():demo.load(lambda id=df_id: ui.update_table(id, 1),outputs=[components[f"{df_id}_table"],components[f"{df_id}_prev"],components[f"{df_id}_next"],components[f"{df_id}_page"]])demo.launch()if __name__ == "__main__":main()
相关文章:

Gradio DataFrame分页功能详解:从入门到实战
Gradio DataFrame分页功能详解:从入门到实战 1. 引言2. 为什么需要分页?3. 环境准备4. 基础知识准备5. 代码实现5.1 创建示例数据5.2 分页状态管理5.3 分页核心逻辑5.4 创建Gradio界面 6. 关键功能解析6.1 页码计算6.2 数据切片 7. 使用示例8. 实用技巧9…...

[OPEN SQL] FOR ALL ENTRIES IN
FOR ALL ENTRIES IN 语句用于从一个内部表中检索与另一个内部表中指定字段匹配的记录 语法格式 SELECT ... FOR ALL ENTRIES IN <itab> WHERE <cond>. <itab>:插入目标数据内表 <cond>:查询条件 使用FOR ALL ENTRY IN 语句时&…...
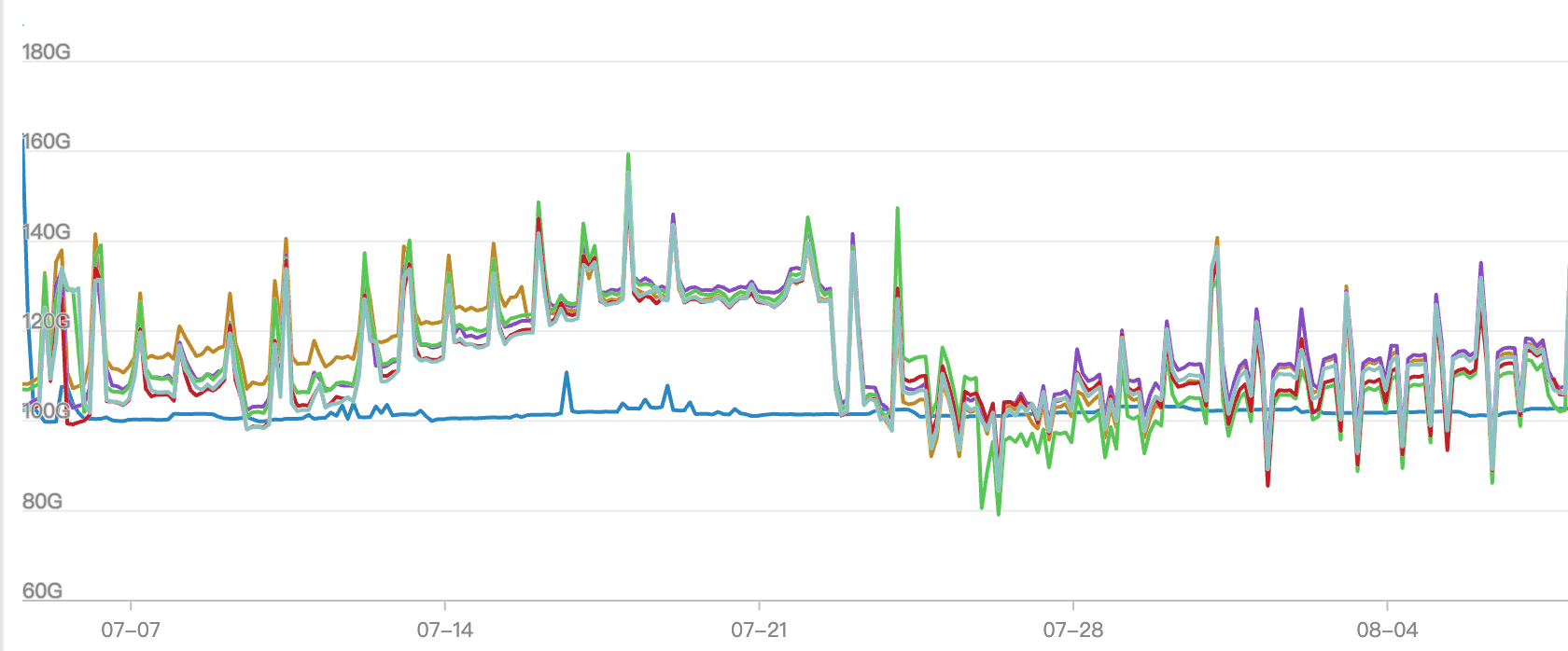
每日互动基于 Apache DolphinScheduler 从容应对ClickHouse 大数据入库瓶颈
引言 大家好,我叫张琦,来自每日互动,担任大数据平台架构师。今天我将分享我们团队在基于Apache DolphinScheduler实现ClickHouse零压入库过程中的实践经验。 这个实践项目涉及到两个关键组件:Apache DolphinScheduler和ClickHous…...
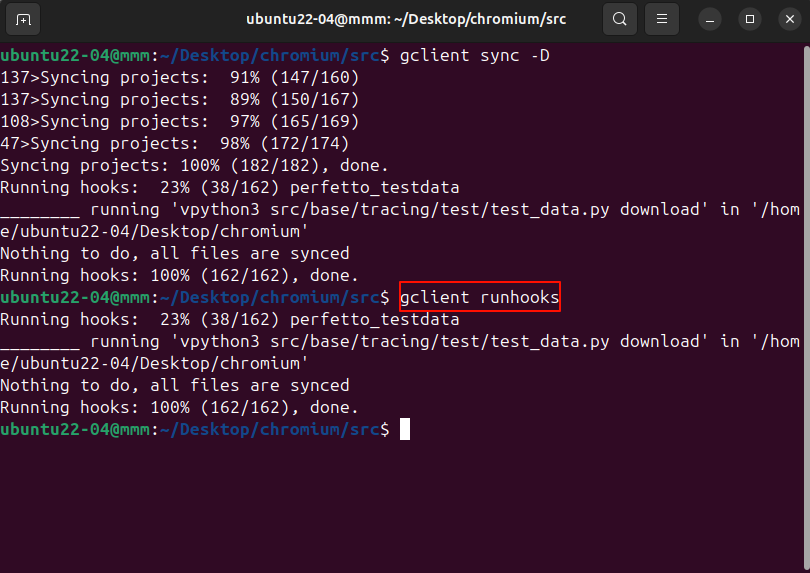
Chromium127编译指南 Linux篇 - 同步第三方库以及Hooks(六)
引言 在成功克隆 Chromium 源代码仓库并建立新分支之后,配置开发环境成为至关重要的下一步。这一过程涉及获取必要的第三方依赖库以及设置钩子(hooks),这些步骤对于确保后续的编译和开发工作能够顺利进行起着决定性作用。本指南旨…...
并通过 Binder 通信提供服务)
在 Android 设备上部署一个 LLM(大语言模型)并通过 Binder 通信提供服务
在 Android 设备上部署一个 LLM(大语言模型)并通过 Binder 通信提供服务,需要以下几个步骤。具体实现是通过定义一个 Android HAL 服务,并且在 init.rc 文件中启动该服务。我们将一步一步解释如何实现一个可通过 Binder 通信的服务(如 vendor.te.aimodel-service)。 一 …...

安科瑞AMB400分布式光纤测温系统解决方案--远程监控、预警,预防电气火灾
安科瑞戴婷 可找我Acrel-Fanny 安科瑞AMB400电缆分布式光纤测温具有多方面的特点和优势: 工作原理: 基于拉曼散射效应。激光器产生大功率的光脉冲,光在光纤中传播时会产生散射。携带有温度信息的拉曼散射光返回光路耦合器,耦…...

docker-compose安装rabbitmq 并开启延迟队列和管理面板插件(rabbitmq_delayed_message_exchange)
问题: 解决rabbitmq-plugins enable rabbitmq_delayed_message_exchange :plugins_not_found 我是在docker-compose环境部署的 services:rabbitmq:image: rabbitmq:4.0-managementrestart: alwayscontainer_name: rabbitmqports:- 5672:5672- 15672:156…...
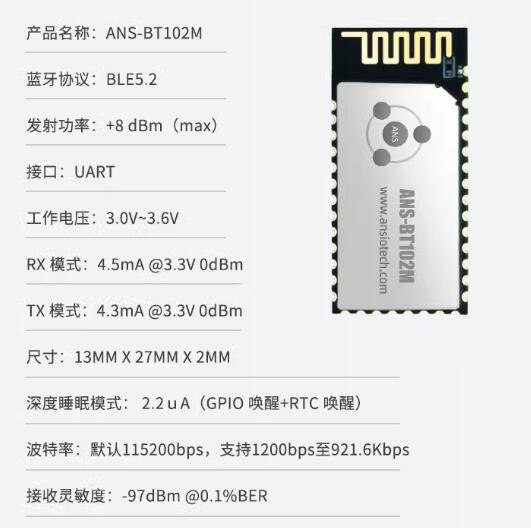
低功耗蓝牙模块在车联网中的应用
目前,没有一种无线技术可以适合所有的车联网应用,目前对于距离短、功耗低、数据速率低的应用,最常见的选择是2.4G、红外和蓝牙技术。其中蓝牙5.0及以上版本受到大家的青睐,因为它与4.2版本相比通讯距离更长和数据吞吐量更高&#…...

Gitee push 文件
1、背景 想将自己的plecs仿真放到git中管理,以防丢失,以防乱改之后丢失之前版本仿真。此操作说明默认用户已下载git。 2、操作步骤 2.1 开启Git Bash 在文件夹中右键,开启Git Bash。 2.2 克隆文件 在Git Bash中打git clone git地址&#…...

OpenGL入门004——使用EBO绘制矩形
本节将利用EBO来绘制矩形 文章目录 一些概念EBO 实战简介utilswindowFactory.hRectangleModel.hRectangleModel.cpp main.cppCMakeLists.txt最终效果 一些概念 EBO 概述: Element Buffer Object 用于存储顶点的索引数据,以便在绘制图形时可以重用顶点数…...

Python中`__str__`和`__repr__`的区别(最清晰解释)
Python中__str__和__repr__的区别(最最最清晰的解释) 在Python的面向对象编程体系中,__str__和__repr__这两个特殊方法具有独特且重要的作用,尽管它们都涉及对象的字符串表示形式的定义,但在功能和使用场景上存在显著…...
Community Enterprise Operating System
起源与背景 CentOS项目始于2003年,由一群热心的Linux用户和开发者共同发起。 它的诞生旨在为用户提供一个免费且与RHEL高度兼容的操作系统,满足那些希望使用RHEL的稳定性和安全性但又不想支付商业许可费用的用户和组织的需求。 CentOS社区会将Red Hat…...
X (Twitter)养号指南:2024最新攻略
X (Twitter)作为活跃用户数以亿计的社交媒体平台,用户数依然在不断增长,其中巨大的流量吸引着个人用户与品牌和卖家。 Twitter养号是有必要的,有大量案例表明养好号,可以大幅度降低账号被冻结的几率,并提升账号的稳定…...

^M 字符处理
windows用的是\r\n来做分行的linux是\n 一、文本格式转换中的^M符号 跨平台文本文件: 当在Windows系统下编辑的文本文件被转移到Unix/Linux系统下打开时,由于Windows系统使用CRLF(\r\n)作为行结束符,而Unix/Linux系统…...

vxe-table v4.8+ 与 v3.10+ 虚拟滚动支持动态行高,虚拟渲染更快了
Vxe UI vue vxe-table v4.8 与 v3.10 解决了老版本虚拟滚动不支持动态行高的问题,重构了虚拟渲染,渲染性能大幅提升了,行高自适应和列宽拖动都支持,大幅降低虚拟渲染过程中的滚动白屏,大量数据列表滚动更加流畅。 自适…...
【新闻文本分类识别】Python+CNN卷积神经网络算法+深度学习+人工智能+机器学习+文本处理
一、介绍 文本分类识别系统。本系统使用Python作为主要开发语言,首先收集了10种中文文本数据集(“体育类”, “财经类”, “房产类”, “家居类”, “教育类”, “科技类”, “时尚类”, “时政类”, “游戏类”, “娱乐类”),然…...

算法效率的计算
目录 一、如何衡量一个算法的好坏?二、时间复杂度1. 时间复杂度的计算方法2. 时间复杂度习题 三、空间复杂度1. 空间复杂度的计算方法2. 空间复杂度习题 四、常见复杂度对比五、复杂度oj题1. 消失的数字2. 轮转数组 一、如何衡量一个算法的好坏? 如果一…...

迷茫内耗的一天
迷茫的一天 今天看了看动态规划,不知不觉看了三四个小时,英语也没背,项目也已经停止了一个星期就看了几个小时的xml文件(不停ctrlB),好累,感觉要学的好多。这难道是必经之路吗? 一个星期算法已经刷了40道题…...

【android12】【AHandler】【4.AHandler原理篇ALooper类方法全解】
AHandler系列 【android12】【AHandler】【1.AHandler异步无回复消息原理篇】-CSDN博客 【android12】【AHandler】【2.AHandler异步回复消息原理篇】-CSDN博客 【android12】【AHandler】【3.AHandler原理篇AHandler类方法全解】-CSDN博客 其他系列 本人系列文章-CSDN博客…...

在canon的生活
街道地址 朝阳区针织路23号中国人寿金融中心33层 大家好!【ji建军】 今天是在我佳能工作的最后一天,1989毕业后入公司,从一而终,三十五年整。 感谢宫里总经理和历届领导对我的信任和教导; (唐晓阳老师、内…...

rag 进行 全局聚合的结构性失败 解析
rag 进行 全局聚合的结构性失败 解析 目录 rag 进行 全局聚合的结构性失败 解析 一句话核心结论 逐句拆解原文含义 1. 前提:什么是"全局聚合"? 2. 致命问题:采样引入不可纠正的选择偏差 农情任务实例:直观感受结构性偏差 真实数据分布(12M农情CSV,共12000条上…...

JavaScript进阶:ES6+特性与异步编程
JavaScript进阶:ES6特性与异步编程 1. 技术分析 1.1 ES6概述 ES6为JavaScript带来了革命性的改进: ES6特性变量声明: let, const箭头函数: () > {}解构赋值: const {a, b} obj类: class语法模块化: import/export异步编程:Promiseasync/awaitGenerat…...
)
告别Rufus!在Ubuntu 22.04上用Ventoy打造你的万能Windows安装盘(附PE系统集成)
在Ubuntu 22.04上使用Ventoy打造全能Windows安装与维护工具盘 作为一名长期以Linux为主力系统的开发者,难免会遇到需要为朋友或备用机安装Windows的场景。传统方案往往要求我们临时切换到Windows环境使用Rufus等工具,既低效又违背Linux用户的习惯。本文将…...

2026实测:专业降AI率软件选这款就对了
2026 年降 AIGC 工具已经从“机械式语义调整”进化为多维度智能优化系统,核心评估指标涵盖 AI 痕迹去除精准度、学术表达一致性、格式结构完整性、长段落逻辑稳定性、内容改写适配性以及高校检测合规性。本次测评覆盖 5 款主流工具,测试场景包括中英文论…...

工位是公司的,腰是自己的:00后正在重塑职场观
来自:推荐一个程序员编程资料站:http://cxyroad.com副业赚钱专栏:https://xbt100.top2024年IDEA最新激活方法后台回复:激活码CSDN免登录复制代码插件下载:CSDN复制插件以下是正文。我是小路。最近看到一个特别有意思的…...

Komanda代码嵌入功能详解:Gist、JSFiddle和Twitter无缝集成
Komanda代码嵌入功能详解:Gist、JSFiddle和Twitter无缝集成 【免费下载链接】komanda The IRC Client For Developers 项目地址: https://gitcode.com/gh_mirrors/ko/komanda Komanda作为一款面向开发者的IRC客户端,提供了强大的代码嵌入功能&…...
)
ArcGIS Pro 3.x 批量处理遥感栅格:用Python脚本实现自动化转点、计算与导出(附完整代码)
ArcGIS Pro 3.x 遥感栅格自动化处理实战:从数据清洗到生产级流水线构建 遥感数据分析师常常需要处理TB级的时序栅格数据,比如月度NDVI指数、地表温度或降水分布。传统手动操作不仅效率低下,还容易因人为失误导致数据不一致。本文将分享如何基…...

ncmdump终极指南:5分钟解锁网易云音乐NCM加密文件
ncmdump终极指南:5分钟解锁网易云音乐NCM加密文件 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾在网易云音乐下载了心爱的歌曲,却发现只能在特定客户端播放?当你想在车载音响、智能音箱…...

3步快速部署海风小店微信小程序商城 - 开源免费商用实战指南
3步快速部署海风小店微信小程序商城 - 开源免费商用实战指南 【免费下载链接】hioshop-miniprogram 微信小程序商城,开源免费商用,海风小店 项目地址: https://gitcode.com/gh_mirrors/hi/hioshop-miniprogram 海风小店是一款基于Node.jsThinkJSM…...

Captain AI助Ozon Listing全链路优化,流量与转化双提升
Listing是Ozon商家获取流量、提升转化的核心载体,优质的Listing能让商品在海量竞品中脱颖而出,而多数商家却深陷“标题违规、主图不达标、关键词无效”的困境,导致商品曝光低、转化率差,难以突破运营瓶颈。Captain AI深耕Ozon Lis…...