kafka客户端消费者吞吐量优化
问题背景
业务场景
mq消息消费实时性要求不高,期望可以牺牲一部分实时性,换取吞吐量,例如:数据库单条insert优化为batchInsert。优化后结果不符合预期:消费者消费消息的batchSize远小于实际配置的max.poll.records,导致在批量消息达到时想要聚合mq批量操作业务数据效果与单条处理效果类似。于是翻查影响kafka吞吐量的相关配置
原因分析
Kafka 的 poll() 方法返回的消息数量与 batch.size 参数并不是直接相关的,影响 Kafka 消费者 poll() 时能获取消息数量的因素有很多。让我们逐步分析这些因素,并探讨可能的优化方法。
影响 poll() 返回消息数量的因素
**max.poll.records**** 设置**max.poll.records限制了每次poll()获取的消息最大数量。即使batch.size设置得较大,如果max.poll.records较小,poll()获取的消息数依然受限制。
- 消息生产速度
- 如果生产者写入 Kafka 的速度较慢,消费端的
poll()方法在调用时可能没有足够的消息积累,因此无法返回足够多的消息。 - 解决方案:监控生产者的写入速度和 Kafka 的积压情况,确保有足够的消息被生产和累积。
- 如果生产者写入 Kafka 的速度较慢,消费端的
- 分区数量与消费者线程数
- 如果 Kafka topic 的分区数量较少,且每个消费者线程处理一个或多个分区,那么分区中的消息总量可能不足,导致每次
poll()返回的消息数较少。 - 解决方案:确保 topic 分区数量合理,并且适当增加消费者实例,以提高并行处理能力。
- 如果 Kafka topic 的分区数量较少,且每个消费者线程处理一个或多个分区,那么分区中的消息总量可能不足,导致每次
**fetch.min.bytes**** 和**fetch.max.wait.ms**设置**fetch.min.bytes:消费者从 Kafka 获取消息时,设置了一个最小的字节数,当数据量不足时,Kafka 将等待更多的数据写入。fetch.max.wait.ms:当fetch.min.bytes的数据量未达到时,Kafka 消费者会等待一定的时间再返回消息。如果设置过短,可能会在消息不足时提早返回。- 优化思路:增加
fetch.min.bytes值,使消费者等待更多数据积累后再返回。同时适当调整fetch.max.wait.ms,确保不会过早返回消息。
- 消费者的
**poll()**调用频率- 消费者应用程序调用
poll()的频率也影响返回的消息数量。如果频繁调用poll(),每次返回的消息可能较少。 - 解决方案:适当调整
poll()的调用频率,确保消费者等待足够的消息后再调用。
- 消费者应用程序调用
**session.timeout.ms**** 和**heartbeat.interval.ms**设置**- 如果这些参数配置不当,Kafka 消费者可能会因为过频繁发送心跳而导致每次
poll()间隔较短,未能积累足够的消息。 - 解决方案:增加
session.timeout.ms和heartbeat.interval.ms的值,允许消费者有足够时间poll()更多消息。
- 如果这些参数配置不当,Kafka 消费者可能会因为过频繁发送心跳而导致每次
优化建议
- **增加 **
**max.poll.records**- 将
max.poll.records设置得更大,以确保每次poll()尽可能多地返回消息。例如,尝试将其从默认的 500 增加到 1000 或更大。
- 将
- **调整
**fetch.min.bytes**和 ****fetch.max.wait.ms**- 可以将
fetch.min.bytes增加到 1MB 或 5MB,这样消费者将会等待 Kafka 收集到足够的消息再返回。也可以适当增加fetch.max.wait.ms,让 Kafka 多等待一段时间再返回消息。
- 可以将
- 监控消费者调用的频率
- 适当降低
poll()的调用频率,确保 Kafka 消费者有时间积累足够的数据。
- 适当降低
- 增加分区数
- 确保 Kafka topic 有足够的分区,使得每个分区中可以累积足够的消息。此外,可以考虑增加消费者数量来并行处理消息。
通过这些配置调整,你可以增加每次 poll() 获取的消息数量,从而提高批量处理效率。
参数含义
**fetch.max.wait.ms**
- 描述:
fetch.max.wait.ms是 Kafka 消费者端的配置,表示当消费者从 Kafka broker 请求消息时,如果可用的数据量不足fetch.min.bytes,消费者最多会等待的时间(毫秒)。当超出这个时间后,即使没有足够的数据,也会返回当前已经积累的消息。 - 用途:
- 这个参数主要用于优化消费者在没有足够数据的情况下的等待时间。通过设定一个合理的
fetch.max.wait.ms,消费者可以等待更多数据积累来提高吞吐量,但不会因数据不足无限等待。 - 如果消息到达频率低,消费者就会等待
fetch.max.wait.ms毫秒后返回;如果数据积累足够快,消费者会尽早返回。
- 这个参数主要用于优化消费者在没有足够数据的情况下的等待时间。通过设定一个合理的
- 默认值: 通常默认值是 500 毫秒。
- 场景: 应用于从本地 Kafka broker 拉取消息的延迟和吞吐量控制。
**remote.fetch.max.wait.ms**
- 描述:
remote.fetch.max.wait.ms是 Kafka 远程存储机制相关的一个参数。远程存储是在 Kafka 3.0 引入的架构优化,允许将过期的日志段(log segments)存储在远程存储介质上,如云存储(Amazon S3,Google Cloud Storage 等),而不是一直保留在本地磁盘上。remote.fetch.max.wait.ms控制 Kafka 代理从远程存储拉取过期日志段时,最大等待的时间。 - 用途:
- 当消费者尝试读取的数据已经从本地磁盘迁移到远程存储时,Kafka 代理会从远程存储系统中拉取该段数据。
remote.fetch.max.wait.ms就是用来限制 Kafka 在从远程存储读取数据时的最大等待时间。 - 远程存储拉取通常比本地拉取要慢,因为涉及外部存储系统,所以这个参数用于优化消费者在这种情况下的性能。
- 当消费者尝试读取的数据已经从本地磁盘迁移到远程存储时,Kafka 代理会从远程存储系统中拉取该段数据。
- 场景: 应用于 Kafka 从远程存储拉取过期消息的等待时间控制。
fetch.min.bytes
fetch.min.bytes 是 Kafka 消费者端的一个配置参数,它用于控制每次从 Kafka broker 拉取数据时的最小数据量。这个参数决定了消费者拉取消息时的行为,影响数据批量处理的效率和延迟。
参数作用:
- 功能:指定 Kafka broker 每次返回给消费者的消息的最小字节数。当消费者发起拉取请求时,Kafka broker 会等待消息积累到至少
fetch.min.bytes指定的字节数后,再将数据返回给消费者。 - 如果 broker 在
fetch.max.wait.ms时间内没有积累到足够的数据(即fetch.min.bytes),它会返回当前可用的数据量,即使小于fetch.min.bytes。
默认值:
- 默认值为 1,意味着 broker 不需要等待消息积累到一定的字节数,只要有消息(即使只有一条消息),就可以立即返回给消费者。
使用场景:
- 高吞吐量场景:
- 如果你的应用需要批量处理 Kafka 消息,可以将
fetch.min.bytes设置得大一些,确保每次拉取的数据足够多,以减少频繁的网络请求。 - 适合需要处理大批量数据的系统,比如数据分析或日志处理系统。这时,你可以设置较高的
fetch.min.bytes,让 Kafka broker 等待更多消息积累后再返回。
- 如果你的应用需要批量处理 Kafka 消息,可以将
- 低延迟场景:
- 如果你希望 Kafka 消息能尽快被消费,不希望消费者等待消息积累,你可以将
fetch.min.bytes保持默认值(1)。这时,broker 会在有数据可供消费时尽快返回,减少延迟。 - 适合需要快速响应的系统,比如实时监控或流数据处理。
- 如果你希望 Kafka 消息能尽快被消费,不希望消费者等待消息积累,你可以将
如果poll(100ms),fetch.max.wait.ms=500ms,那么100ms后mq未达到fetch.min.bytes。客户端会得到当前的records吗?
不会
例子:
假设有以下配置:
fetch.min.bytes = 1MBfetch.max.wait.ms = 500ms- 消费者调用了
poll()向 broker 请求数据。
情况1:Broker 上的消息量 < 1MB
- 当消费者请求数据时,broker 上只有 500KB 的消息。
- Broker 会等到
fetch.max.wait.ms(500ms),试图等待更多消息的到达。 - 如果在 500ms 内消息累积达到了 1MB,broker 会立即返回这 1MB 的消息。
- 如果 500ms 过去了,仍然没有足够的消息(比如只有 700KB),broker 会返回这些 700KB 的消息。
情况2:Broker 上的消息量 >= 1MB
- 如果消费者请求时,broker 上已经有 1MB 或更多消息,broker 会立即返回这些消息,不再等待
fetch.max.wait.ms。
**fetch.max.wait.ms**** 与 **fetch.min.bytes** 配合的意义:**
**fetch.min.bytes**设置了消费者希望每次拉取的最小数据量,这样可以避免频繁拉取少量消息,提高吞吐量。**fetch.max.wait.ms**防止消费者因为等不到足够多的消息而无限期等待,设置了一个时间上限。如果在这个时间内没有足够的数据,broker 仍然会返回已有的数据,避免消费者一直没有数据处理。
fetch.max.wait.ms 与 poll的超时应该相等比较合理,这样poll不会在mq消息量不足的时候拉到空数据空跑浪费cpu资源?
不是
理解两者的关系:
**fetch.max.wait.ms**:- 这是 Kafka broker 在消息不足时等待积累更多数据的最大时间。如果在这段时间内没有更多数据到达,broker 会返回已经积累的消息(即使小于
fetch.min.bytes)。 - 主要目的是避免过于频繁的拉取请求,减少网络传输的开销,增加单次拉取的消息量。
- 这是 Kafka broker 在消息不足时等待积累更多数据的最大时间。如果在这段时间内没有更多数据到达,broker 会返回已经积累的消息(即使小于
**poll()**** 超时时间**:- 这是 Kafka 消费者客户端在本地等待 broker 返回数据的最大时间。
- 如果在
poll()超时时间内 broker 没有返回数据,poll()会返回空结果,并且消费者会继续下一轮poll()。 - 主要目的是控制消费者的等待时间,以确保在没有数据的情况下不会阻塞太久。
两者的配合:
- 将
**fetch.max.wait.ms**与**poll()**超时时间设置为相等:如果poll()的超时时间等于fetch.max.wait.ms,理论上可以避免poll()过早返回空数据,因为 broker 正在等待积累足够的数据。
这种配置的好处是可以减少消费者空跑的概率,尤其是在消息量较小的场景中。它确保了在 poll() 的等待时间内,broker 至少有足够的时间来积累消息,最大限度地提高单次拉取的数据量。
- 实际应用中的权衡:
- 在实际场景中,将
**fetch.max.wait.ms**设置略小于**poll()**超时时间可能是更合理的选择。例如,你可以设置fetch.max.wait.ms为 500ms,poll()超时时间为 600ms。这种配置让 broker 有足够时间积累数据,并且消费者poll()方法也有足够时间等待 broker 返回数据。 - 如果
poll()超时时间与fetch.max.wait.ms完全相等,有时可能会导致poll()稍微早于 broker 返回数据,从而造成一些无效的poll()调用。稍微延长poll()时间可以避免这一问题。
- 在实际场景中,将
其他因素影响:
- 消息吞吐量和延迟:过长的
fetch.max.wait.ms和poll()时间会增加数据的累积量,但也可能增加处理延迟。如果应用对实时性要求较高,可能需要缩短这两个时间,使得消费者更频繁地获取消息。 - CPU 和网络资源:延长这两个时间可以减少空跑和频繁的拉取请求,从而节省 CPU 和网络资源。但如果设置过长,可能会造成消费者响应不及时,特别是当消息积压严重时。
示例:
假设 fetch.max.wait.ms 设置为 500ms,poll() 超时时间设置为 600ms:
- 如果在 500ms 内 broker 积累了足够消息,broker 会立即返回数据,消费者的
poll()将会在接收到消息后立刻处理。 - 如果 broker 在 500ms 内没有积累到足够的消息,它会返回当前可用的数据,
poll()超时不会过早触发,确保了消费者不会空跑。 - 如果
poll()超时时间设置得比fetch.max.wait.ms短,消费者可能会在 broker 还未返回数据之前超时,导致空轮询。
总结:
- 一般建议:可以将
poll()超时时间设置得稍微大于fetch.max.wait.ms,这样可以确保 broker 有足够时间积累消息,同时避免poll()过早超时。 - 合理的设置:
fetch.max.wait.ms= 500ms,poll()超时 = 600ms。这样 broker 可以最大限度积累数据,消费者也有足够时间等待数据返回,避免空跑。
这种策略会帮助你在减少空轮询和提高批量处理效率之间找到平衡。
相关文章:

kafka客户端消费者吞吐量优化
问题背景 业务场景 mq消息消费实时性要求不高,期望可以牺牲一部分实时性,换取吞吐量,例如:数据库单条insert优化为batchInsert。优化后结果不符合预期:消费者消费消息的batchSize远小于实际配置的max.poll.records&a…...
电子工程师-高质量工具包
目录 来源 高质量工具包介绍 总体框架如下 ZL01-各类元器件相关资料 ZL02-电源设计资料 ZL03-大厂参考资料 ZL04-开发工具 ZL05-仿真工具 ZL06-各类电路接口设计指南 ZL07-付费专栏全集 ZL08-优质电子书 ZL09-硬件工程师 ZL10FPGA工程师教程 ZL10-PCB设计教程 Z…...

简单认识redis - 12 redis锁
在斜体样式**redis中,不同的问题有不一样的解决办法,那么锁也有不同的锁来解决不一样的问题,下面将举出几个常用的redis锁。 1. SETNX锁(简单独占锁) 原理: SETNX(SET if Not eXistsÿ…...

基于springboot+vue车辆充电桩管理系统
基于springbootvue车辆充电桩管理系统 摘 要 随着信息化时代的到来,管理系统都趋向于智能化、系统化,车辆充电桩管理系统也不例外,但目前国内仍都使用人工管理,市场规模越来越大,同时信息量也越来越庞大,…...
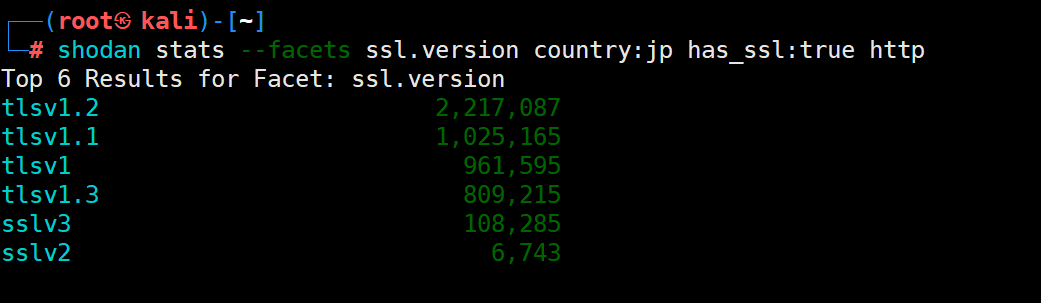
shodan用法(完)
声明 学习视频来自B 站up主泷羽sec,如涉及侵权马上删除文章。 笔记的只是方便各位师傅学习知识,以下网站只涉及学习内容,其他的都与本人无关,切莫逾越法律红线,否则后果自负。 shodan 今天,我们把shoda…...

【若依框架】代码生成详细教程,15分钟搭建Springboot+Vue3前后端分离项目,基于Mysql8数据库和Redis5,管理后台前端基于Vue3和Element Plus,开发小程序数据后台
今天我们来借助若依来快速的搭建一个基于springboot的Java管理后台,后台网页使用vue3和 Element Plus来快速搭建。这里我们可以借助若依自动生成Java和vue3代码,这就是若依的强大之处,即便你不会Java和vue开发,只要跟着石头哥也可…...

转子侧串级调速系统和双馈调速系统
转子侧串级调速系统和双馈调速系统是两种不同的电机调速技术,它们在基本原理、效率以及应用场景等方面存在区别。以下是详细的对比分析: 基本原理 转子侧串级调速系统:通过在绕线式异步电动机的转子回路中串入一个可调节的附加电势࿰…...
AI学习指南自然语言处理篇-Transformer模型的实践
AI学习指南自然语言处理篇 - Transformer模型的实践 目录 引言Transformer模型概述 自注意力机制编码器-解码器结构 环境准备Transformer模型的实现 编码器实现解码器实现Transformer模型整体实现 Transformer在NLP任务中的应用 文本分类机器翻译 总结与展望 引言 在过去的数…...

【LVGL速成】LVGL修改标签文本(GUI Guider生成的字库问题)
目录 前置篇章: 一.问题背景 二.失败方案 三.成功方案 1.Gui guider的源码结构 2.手动生成字体 3.Keil中配置相关文件 编辑 4.修改文字 四.字体样式函数说明 前置篇章: 【LVGL快速入门(二)】LVGL开源框架入门教程之框架使用(UI界面设计)_lvgl…...

C语言项目实践-贪吃蛇
⽬录: 1. 游戏背景 2. 游戏效果演⽰ 3. 实现的⽬标 4. 实现的定位 5. 技术要点 6. 贪吃蛇游戏设计与分析 7. 贪吃蛇游戏数据结构设计 8. 相关Win32API介绍 9. 参考代码 正文开始 1. 游戏背景 贪吃蛇是久负盛名的游戏,它也和俄罗斯⽅块…...

在kanzi 3.9.8里使用API创建自定义材质
1. kanzi studio设置 1.1 创建一个纹理贴图,起名Render Target Texture 1.2 创建一个Image节点,使用该贴图 2. 代码设置 2.1 创建一个自定义节点类 class mynode2d : public Node2D { public: virtual void renderOverride(Renderer3D& renderer…...
IDEA中通义灵码的使用技巧
大家好,我是 V 哥。在日常写代码的过程中,通过 AI 工具辅助开发已是当下程序员惯用的方式,V 哥在使用了众多的 AI 工具后,多数情况下,选择通义灵码来辅助开发,尤其是解释代码和生成单元测试功能甚是好用&am…...

JS中let var 和const区别
在JavaScript中,let、var 和 const 都是用来声明变量的关键字,但它们之间有几个关键的区别: 作用域(Scope): var 声明的变量拥有函数作用域(function scope),这意味着如果 var 变量在…...

ansible详细介绍和具体步骤
Ansible简介 1.1 Ansible的基本概念 Ansible是一款开源的自动化工具,旨在简化IT操作的复杂性。它由Michael DeHaan创建,并于2012年发布,随后在2015年被Red Hat收购。Ansible的核心理念是“简单即美”,它通过使用YAML(…...

利用LangChain与LLM打造个性化私有文档搜索系统
我们知道LLM(大语言模型)的底模是基于已经过期的公开数据训练出来的,对于新的知识或者私有化的数据LLM一般无法作答,此时LLM会出现“幻觉”。针对“幻觉”问题,一般的解决方案是采用RAG做检索增强。 但是我们不可能把…...

linux中的软、硬链接
目录 引言 简单介绍 如何理解软硬链接 链接的应用 环路问题 引言 在Linux操作系统的广阔天地中,文件管理是其核心功能之一。而软链接和硬链接作为Linux文件系统中的两种特殊链接方式,它们为用户提供了灵活的文件访问途径和高效的磁盘空间利用手段。…...

Ubuntu 系统、Docker配置、Docker的常用软件配置(下)
前言 书接上文,现在操作系统已经有了,作为程序的载体Docker也安装配置好了,接下来我们需要让Docker发挥它的法力了。 Docker常用软件的安装 1.Redis 缓存安装 1.1 下载 docker pull redis:7.4.1 #可改为自己需要的版本 1.2 创建本地目录存储…...

jdk,openjdk,oraclejdk
Java是开发语言,不是软件。JDK是软件,使用OpenJDK是免费的,一直免费。而且OpenJDK正儿巴经的Java社区推出来的JDK。 Oracle JDK主要是面向付费能力强的企业用户,收费已经好多年了,不是一两年的事,JDK8是JDK…...

Docker Hub 镜像加速器
零、参考资料 https://gist.github.com/y0ngb1n/7e8f16af3242c7815e7ca2f0833d3ea6Daemon proxy configuration | Docker Docs 一、解决方案 1、问题现象 Error response from daemon: Get "https://index.docker.io/v1/search?qcarlasim%2Fcarla&n25": dia…...

DevOps赋能:优化业务价值流的实战策略与路径(上)
上篇:价值流引领与可视化体系构建 一、前言 在快速迭代的软件项目和产品开发生态中,我们始终围绕两个核心目标:一是确保每一项工作都能为客户创造实际价值,这是产品团队的核心使命;二是确保这些有价值的工作能够高效…...

Raspberry Pi Pico手动进入Bootloader模式:解决Arduino IDE上传失败
1. 项目概述:为什么我们需要手动进入Bootloader模式?如果你玩过Raspberry Pi Pico,并且尝试用Arduino IDE给它上传程序,大概率会遇到这么个情况:你满怀期待地点击了“上传”按钮,IDE底部的状态栏开始滚动编…...

如何高效配置跨平台网盘直链解析工具:技术实现与实战指南
如何高效配置跨平台网盘直链解析工具:技术实现与实战指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天…...
)
51单片机控制LED灯实现流水灯效果(程序+Proteus仿真)
51单片机控制LED灯实现流水灯效果(程序Proteus仿真) 【下载地址】51单片机控制LED灯实现流水灯效果程序Proteus仿真 本资源提供了一个完整的项目,使用51单片机控制LED灯实现流水灯效果。资源内容包括Keil5 C语言程序和Proteus软件仿真文件&am…...

CircuitFusion:多模态融合技术在芯片设计PPA预测中的应用
1. CircuitFusion:硬件设计领域的多模态融合革命在芯片设计领域,RTL(寄存器传输级)到GDSII(物理版图)的转换过程一直面临着"预测鸿沟"的挑战。传统EDA工具通常在完成逻辑综合后才能准确评估时序、…...

2026年AI工程化的5大发展趋势:从模型到产品的必经之路
2026年AI工程化的5大发展趋势:从模型到产品的必经之路 导读: AI模型越来越强大,但如何将其稳定、高效地部署到生产环境?本文结合我过去3年的MLOps实战经验,深度剖析2026年AI工程化的核心趋势,助你从“会调参…...
)
告别仿真报错!手把手教你用Quartus II 21.1和ModelSim 2022.1创建Testbench(附完整代码)
Quartus II与ModelSim联合仿真实战:从零构建高可靠性Testbench 在数字电路设计领域,仿真验证环节往往决定着项目成败。据统计,超过60%的FPGA开发时间消耗在功能验证阶段,而其中近半问题源于Testbench编写不当或仿真环境配置错误。…...

【技术解析】从点测量到全场感知:DIC三维应变测量如何革新传统应变片测试范式
1. 从点到面的技术革命:为什么我们需要全场应变测量? 记得我第一次接触材料力学测试时,导师让我用传统应变片测量一块铝合金板的拉伸变形。我花了整整三天时间,在试样上贴了二十多个应变片,结果数据还是支离破碎。那时…...
)
保姆级教程:用VMware Workstation Pro 16给虚拟机装Win11,手把手教你用Ghost镜像(含UEFI/BIOS切换避坑)
VMware Workstation Pro 16实战:零基础Ghost安装Windows 11全流程解析 在虚拟化技术日益普及的今天,使用VMware Workstation Pro创建虚拟机已成为开发者测试新系统的首选方案。特别是对于Windows 11这样的新操作系统,直接在物理机上安装可能存…...

如何彻底解决macOS多设备滚动冲突:Scroll Reverser完全指南
如何彻底解决macOS多设备滚动冲突:Scroll Reverser完全指南 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是不是经常在MacBook触控板和鼠标之间切换时࿰…...

HLS技术解析:从原理到FPGA开发实战
1. HLS技术概述与评估背景高等级综合(High-Level Synthesis, HLS)技术正在重塑FPGA开发范式。作为从业十年的硬件加速工程师,我见证了这项技术从实验室走向工业界的全过程。传统RTL开发需要手动编写每一行寄存器传输级代码,而HLS允许开发者用C等高级语言…...