利用LangChain与LLM打造个性化私有文档搜索系统
我们知道LLM(大语言模型)的底模是基于已经过期的公开数据训练出来的,对于新的知识或者私有化的数据LLM一般无法作答,此时LLM会出现“幻觉”。针对“幻觉”问题,一般的解决方案是采用RAG做检索增强。
但是我们不可能把所有数据都丢给LLM去学习,比如某个公司积累的某个行业的大量内部知识。此时就需要一个私有化的文档搜索工具了。
本文聊聊如何使用LangChain结合LLM快速做一个私有化的文档搜索工具。之前介绍过,LangChain几乎是LLM应用开发的第一选择,它的野心也比较大,它致力于将自己打造成LLM应用开发的最大社区。自然,它有这方面的成熟解决方案。
文末,还会向朋友们推荐一款非常好用的AI机器人和LLM API超市,价格实惠又稳定,还可以领一波福利。
1. RAG检索流程
使用 LangChain 实现私有化文档搜索的主要流程,如下图所示:
文档加载 → 文档分割 → 文档嵌入 → 向量化存储 → 文档检索 → 生成回答

2. 代码实践细节
2.1. 文档加载
首先,我们需要加载文档数据。文档可以是各种格式,比如文本文件、PDF、Word 等。使用 LangChain,可以轻松地加载这些文档。下面以PDF为例:
from langchain_community.document_loaders import PyPDFLoaderloader = PyPDFLoader("./GV2.pdf")
docs = loader.load()2.2. 文档分割
加载的文档通常会比较大,为了更高效地处理和检索,我们需要将文档分割成更小的段落或句子。LangChain 提供了便捷的文本分割工具,可以按句子、块长度等方式分割文档。
from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=50,chunk_overlap=20,separators=["\n", "。", "!", "?", ",", "、", ""],add_start_index=True,
)
texts = text_splitter.split_documents(docs)分割后的文档内容可以进一步用于生成向量。
2.3. 文档嵌入 Embeddings
文档分割后,我们需要将每一段文本转换成向量,这个过程称为文档嵌入。文档嵌入是将文本转换成高维向量,这是相似性搜索的关键。这里我们选择OpenAI的嵌入模型来生成文档的嵌入向量。
from langchain_openai import OpenAIEmbeddingsembeddings_model = OpenAIEmbeddings(openai_api_key="sk-xxxxxxxxxxx",openai_api_base="https://api.302.ai/v1",
)txts = [txt.page_content for txt in texts]embeddings = embeddings_model.embed_documents(txts)2.4. 文档向量化存储
接下来,我们需要将生成的向量化的文档,存入向量数据库中。向量数据库主要用来做相似性搜索,可以高效地存储和检索高维向量。LangChain 支持与多种向量数据库的集成,比如 Pinecone、FAISS、Chroma 等。
本文以FAISS为例,首先需要安装FAISS,直接使用pip install faiss-cpu安装。
from langchain_community.vectorstores import FAISSdb = FAISS.from_documents(texts, embeddings_model)
FAISS.save_local(db, "faiss_db2")2.5. 文档检索
当用户提出问题时,我们需要在向量数据库中检索最相关的文档。检索过程是计算用户问题的向量表示,然后在向量数据库中查找与之最相似的文档。最后将找到的文档内容,拼接成一个大的上下文。
向量数据库的检索支持多种模式,本文先用最简单的,后续再出文章继续介绍别的模式。
from langchain.retrievers.multi_query import MultiQueryRetrieverretriever = db.as_retriever()
# retriever = db.as_retriever(search_type="similarity_score_threshold",search_kwargs={"score_threshold":.1,"k":5})
# retriever = db.as_retriever(search_type="mmr")
# retriever = MultiQueryRetriever.from_llm(
# retriever = db.as_retriever(),
# llm = model,
# )context = retriever.get_relevant_documents(query="张学立是谁?")_content = ""
for i in context:_content += i.page_content2.6. 将检索内容丢给LLM作答
最后,我们需要将检索到的文档内容丢入到 prompt 中,让LLM生成回答。LangChain 可以PromptTemplate模板的方式,将检索到的上下文动态嵌入到 prompt 中,然后丢给LLM,这样可以生成准确的回答。
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParserquestion = "张学立是谁?"
template = [("system","你是一个处理文档的助手,你会根据下面提供<context>标签里的上下文内容来继续回答问题.\n 上下文内容\n <context>\n{context} \n</context>\n",),("human", "你好!"),("ai", "你好"),("human", "{question}"),
]
prompt = ChatPromptTemplate.from_messages(template)messages = prompt.format_messages(context=_content, question=question)
response = model.invoke(messages)output_parser = StrOutputParser()
output_parser.invoke(response)2.7. 完整代码
最后,将以上所有代码串起来,整合到一起,如下:
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParsermodel = ChatOpenAI(model_name="gpt-3.5-turbo",openai_api_key="sk-xxxxxxx",openai_api_base="https://api.302.ai/v1",
)loader = PyPDFLoader("./GV2.pdf")
docs = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=50,chunk_overlap=20,separators=["\n", "。", "!", "?", ",", "、", ""],add_start_index=True,
)
texts = text_splitter.split_documents(docs)embeddings_model = OpenAIEmbeddings(openai_api_key="sk-xxxxxxx",openai_api_base="https://api.302.ai/v1",
)
txts = [txt.page_content for txt in texts]
embeddings = embeddings_model.embed_documents(txts)db = FAISS.from_documents(texts, embeddings_model)
FAISS.save_local(db, "faiss_db2")retriever = db.as_retriever()template = [("system","你是一个处理文档的助手,你会根据下面提供<context>标签里的上下文内容来继续回答问题.\n 上下文内容\n <context>\n{context} \n</context>\n",),("human", "你好!"),("ai", "你好"),("human", "{question}"),
]
prompt = ChatPromptTemplate.from_messages(template)question = "张学立是谁?"
context = retriever.get_relevant_documents(query=question)
_content = ""
for i in context:_content += i.page_contentmessages = prompt.format_messages(context=_content, question=question)
response = model.invoke(messages)output_parser = StrOutputParser()
output_parser.invoke(response)2.8. 总结、推荐
通过 LangChain可以轻松实现私有化文档搜索,充分利用LLM的能力来处理和检索文档信息。按照文中的步骤,你也可以轻松实现。
好的问答系统离不开优秀的LLM,根据我的个人经验,OpenAI的大模型能力排名是Top1的。但是使用OpenAI不方便,不但需要梯子而且还不稳定。
一款好的LLM摆在面前,却用不了,着实头疼。有没有方便稳定的方式呢?当然有啦,我推荐一款AI自助平台,不但有问答机器人、文生图机器人、文生视频机器人,还有常见的LLM API,稳定又还便宜。具体使用方法见原文链接。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

相关文章:
利用LangChain与LLM打造个性化私有文档搜索系统
我们知道LLM(大语言模型)的底模是基于已经过期的公开数据训练出来的,对于新的知识或者私有化的数据LLM一般无法作答,此时LLM会出现“幻觉”。针对“幻觉”问题,一般的解决方案是采用RAG做检索增强。 但是我们不可能把…...

linux中的软、硬链接
目录 引言 简单介绍 如何理解软硬链接 链接的应用 环路问题 引言 在Linux操作系统的广阔天地中,文件管理是其核心功能之一。而软链接和硬链接作为Linux文件系统中的两种特殊链接方式,它们为用户提供了灵活的文件访问途径和高效的磁盘空间利用手段。…...

Ubuntu 系统、Docker配置、Docker的常用软件配置(下)
前言 书接上文,现在操作系统已经有了,作为程序的载体Docker也安装配置好了,接下来我们需要让Docker发挥它的法力了。 Docker常用软件的安装 1.Redis 缓存安装 1.1 下载 docker pull redis:7.4.1 #可改为自己需要的版本 1.2 创建本地目录存储…...

jdk,openjdk,oraclejdk
Java是开发语言,不是软件。JDK是软件,使用OpenJDK是免费的,一直免费。而且OpenJDK正儿巴经的Java社区推出来的JDK。 Oracle JDK主要是面向付费能力强的企业用户,收费已经好多年了,不是一两年的事,JDK8是JDK…...

Docker Hub 镜像加速器
零、参考资料 https://gist.github.com/y0ngb1n/7e8f16af3242c7815e7ca2f0833d3ea6Daemon proxy configuration | Docker Docs 一、解决方案 1、问题现象 Error response from daemon: Get "https://index.docker.io/v1/search?qcarlasim%2Fcarla&n25": dia…...

DevOps赋能:优化业务价值流的实战策略与路径(上)
上篇:价值流引领与可视化体系构建 一、前言 在快速迭代的软件项目和产品开发生态中,我们始终围绕两个核心目标:一是确保每一项工作都能为客户创造实际价值,这是产品团队的核心使命;二是确保这些有价值的工作能够高效…...

int的取值范围
原码(True form):原码是一种计算机中对数字的二进制表示方法,数码序列中最高位为符号位,符号位为0表示正数,符号位为1表示负数;其余有效值部分用二进制的绝对值表示。 反码…...
:IDC: Boost Text-to-Image Retrieval via Indirect and Direct Connections)
图文检索(16):IDC: Boost Text-to-Image Retrieval via Indirect and Direct Connections
IDC: Boost Text-to-Image Retrieval via Indirect and Direct Connections 摘要3 方法3.1 直接连接3.2 间接连接3.3 DLB 正则化 结论 发布时间(2024 LREC-COLING) 标题:IDC:通过间接和直接连接增强文本到图像的检索 摘要 本文&…...

企业数字化转型:重识、深思、重启新征程-亿发
在当下这个日新月异的时代,企业数字化转型已然成为众多企业竞相追逐的发展方向,可真正能将其领悟透彻并有效落地实施的企业,却并非比比皆是。此刻,亿发软件针对企业数字化转型展开一次更为深入的重识、全面的深思,进而…...
)
仓颉刷题录-字符串数字转换(一)
文章目录 背景题目:交换后字典序最小的字符串个人感受 这是双子专栏: Cangjie仓颉程序设计-个人总结 本专栏还在持续更新: 仓颉编程cangjie刷题录 背景 报名了一个仓颉的比赛,感觉条件要求挺低的,就想上。哈哈哈。但…...

SpringBoot【实用篇】- 配置高级
文章目录 目标:1.ConfigurationProperties2.宽松绑定/松散绑定3. 常用计量单位绑定4.数据校验 目标: ConfigurationProperties宽松绑定/松散绑定常用计量单位绑定数据校验 1.ConfigurationProperties ConfigurationProperties 在学习yml的时候我们了解…...

liunx CentOs7安装MQTT服务器(mosquitto)
查找 mosquitto 软件包 yum list all | grep mosquitto出现以上两个即可进行安装,如果没有出现则需要安装EPEL软件库。 yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm查看 mosquitto 信息 yum info mosquitto安装 mosquitt…...

【银河麒麟高级服务器操作系统】虚拟机lvm分区丢失现象分析及解决建议
了解更多银河麒麟操作系统全新产品,请点击访问 麒麟软件产品专区:https://product.kylinos.cn 开发者专区:https://developer.kylinos.cn 文档中心:https://documentkylinos.cn 环境描述 系统环境 物理机/虚拟机/云/容器 虚拟…...

Android 原子性类型都有哪些
1. 基本类型原子类 AtomicInteger:用于对整数进行原子操作,如incrementAndGet()方法可以原子地将当前值加1并返回新值,getAndSet()方法可以原子地设置新值并返回旧值。AtomicLong:和AtomicInteger类似,用于长整型的原…...

MySQL(上)
一、SQL优化 1、如何定位及优化SQL语句的性能问题?创建的索引有没有被使用到?或者说怎么才可以知道这条语句运行很慢的原因? 对于性能比较低的sql语句定位,最重要的也是最有效的方法其实还是看sql的执行计划,而对于mysql来说&a…...

ffplay 实现视频流中音频的延迟
ffplay -rtsp_transport tcp -i rtsp://admin:1234qwer192.168.1.64:554/Streaming/Channels/101 -vn -af "adelay5000|5000"在这个命令中: -vn 参数表示只播放音频。 -af "adelay5000|5000" 参数表示将音频延迟5000毫秒(即5秒&…...

CSDN资源变现
根据搜索结果,CSDN资源变现主要有以下几种方式: 1、上传付费资源: 用户可以在CSDN上上传资源并设置付费,其他用户支付费用下载这些资源,上传者则获得一部分收益。这种方式适合上传大量资源,通过量变达到质变…...
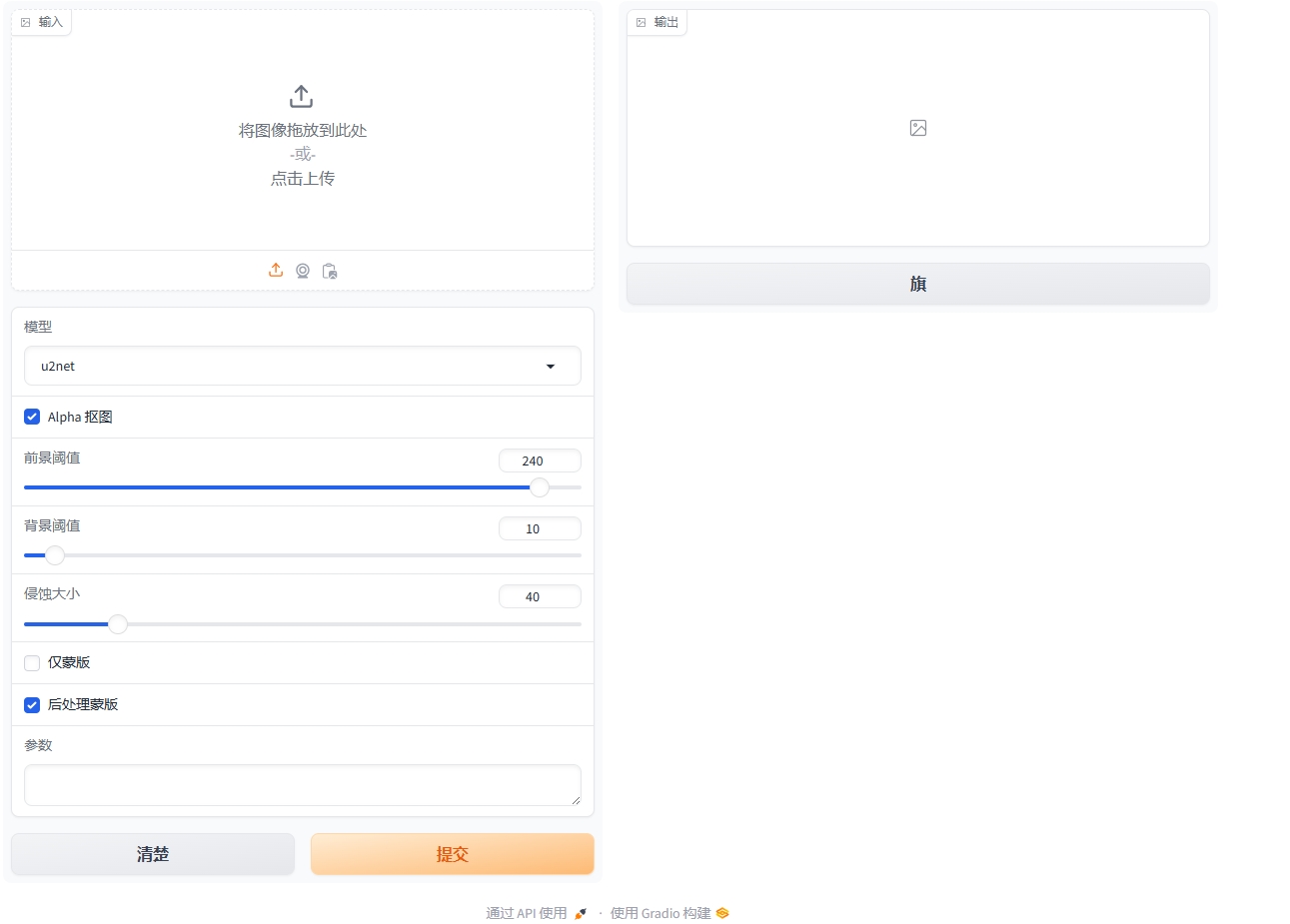
Rembg模型构建教程
一、介绍 Rembg,全称为“Remove Background”,是一款基于深度学习的图像背景去除工具。它的主要功能是通过智能识别图像中的前景物体,并将其从背景中分离出来,从而创建具有透明背景的图像。 二、基础环境 系统:Ubun…...

向量的基础知识和矩阵向量的坐标旋转
向量的基础: 定义: 既有大小,又有方向的量叫做向量(Vector)。 在几何上,向量用有向线段来表示,有向线段长度表示向量的大小,有向线段的方向表示向量的方向。其实有向线段本身也是向…...
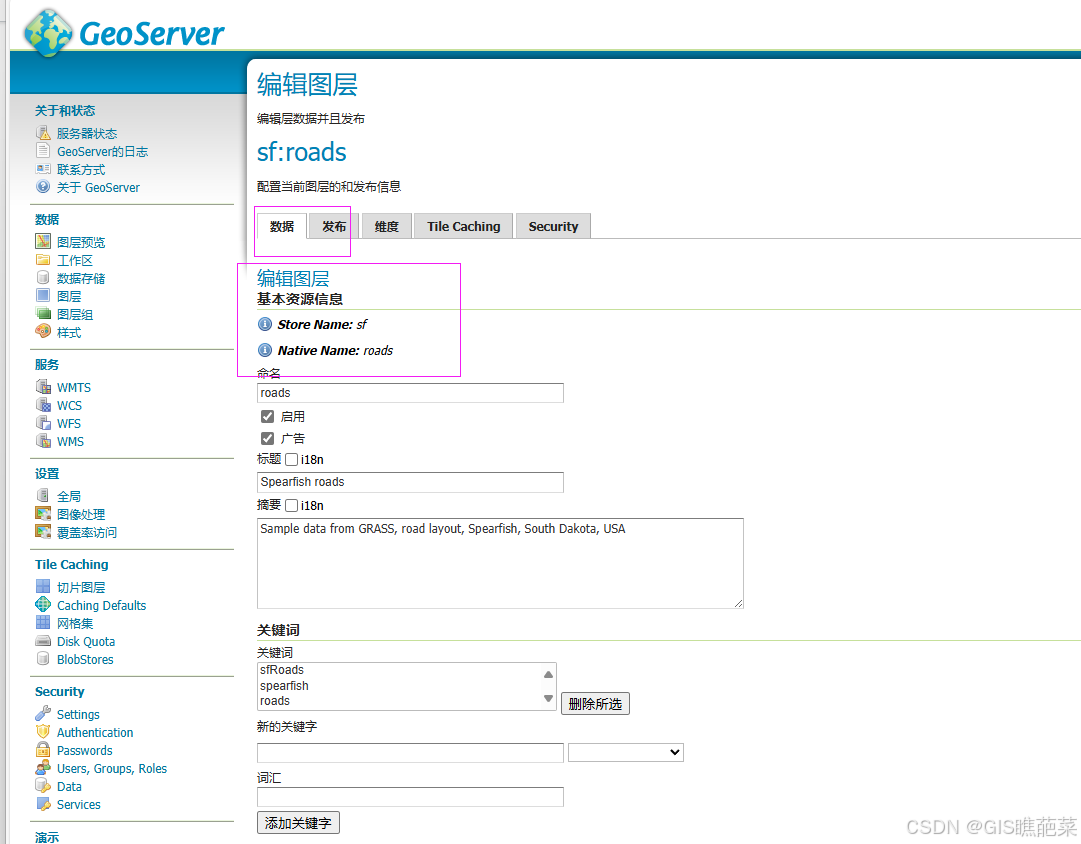
GeoSever发布图层(保姆姬)
发布服务的具体步骤。 1. 安装 GeoServer 下载 GeoServer 安装包:GeoServer 官网按照安装说明进行安装,可以选择 Windows、Linux 或其他平台。 2. 启动 GeoServer 启动 GeoServer 通常通过访问 http://localhost:8080/geoserver 进行。默认用户名和密…...

百度季报图解:营收321亿 AI业务占比首次过半 DAA重塑AI价值标准
雷递网 雷建平 5月18日百度集团(纳斯达克:BIDU及香港联交所:9888(港元柜台)及89888(人民币柜台))今天公布其截至2026年3月31日止第一季度的未经审计财务业绩,财报显示&am…...

Bootstrap Magic自定义组件开发:扩展你的主题生成能力
Bootstrap Magic自定义组件开发:扩展你的主题生成能力 【免费下载链接】bootstrap-magic Bootstrap themes generator made with AngularJS 项目地址: https://gitcode.com/gh_mirrors/bo/bootstrap-magic Bootstrap Magic是一款基于AngularJS构建的Bootstra…...

BesTV_R3300-L S905L芯片刷机实战:从驱动识别到固件烧录的完整避坑指南
1. 认识你的BesTV_R3300-L盒子 我手头这台BesTV_R3300-L盒子已经吃灰大半年了,原厂系统用起来卡顿不说,还经常弹出各种广告。拆开外壳看到S905L芯片的那一刻,我就知道这玩意儿有救——毕竟这是刷机圈里的"老熟人"了。先给新手朋友科…...

深度解析Thorium浏览器:Chromium性能优化的终极实战指南
深度解析Thorium浏览器:Chromium性能优化的终极实战指南 【免费下载链接】thorium Chromium fork named after radioactive element No. 90. Source code and Linux releases. Windows/MacOS/ARM builds served in different repos, links are towards the top of t…...

Prism `IContainerRegistry` 详细调查与讲解
Prism IContainerRegistry 详细调查与讲解 1. 什么是 IContainerRegistry? IContainerRegistry 是 Prism Library 提供的依赖注入容器抽象注册接口。它位于 Prism.Ioc 命名空间。 作用:在 PrismApplication 的 protected override void RegisterTypes(IC…...

CLI工具集claw:模块化设计与插件化架构深度解析
1. 项目概述:一个面向开发者的现代化CLI工具集最近在GitHub上看到一个名为opsyhq/claw的项目,第一眼就被它简洁的名字吸引了。claw,中文意思是“爪子”,听起来就很有力量感和抓取感。点进去一看,果然,这是一…...

别再只盯着大厂光环了:聊聊外包经历对技术人真正的价值与局限
外包经历的技术价值辩证:从职业跳板到能力陷阱的深度思考 当招聘网站上"大厂外包"的职位描述与诱人薪资同时出现时,很多技术人都会面临职业选择的十字路口。我们习惯性地将外包岗位视为"二等公民",却鲜少客观分析这段经历…...

两阶段目标检测器核心原理与流程详解
两阶段目标检测器的核心思想是:第一阶段先找候选区域,第二阶段再对候选区域做分类和精修。典型代表是: R-CNN Fast R-CNN Faster R-CNN Mask R-CNN现在最典型的是 Faster R-CNN / Mask R-CNN,所以我以它为主来讲。1. 两阶段目标检…...

【信息科学与工程学】【物理/化学科学和工程技术】知识体系 第四十篇 低空/高空领域中的力学知识 01
低空与高空(地球大气层内/地球大气层外)领域的核心力学知识。 编号:001 类别:流体力学 / 连续介质力学 领域:低空飞行器空气动力学 力学模型配方:Navier-Stokes方程组(可压缩/不可压缩) 数学分析:求解控制流体运动的质量、动量和能量守恒偏微分方程组。 定理/算法…...
的保姆级安装与排错)
在国产UOS系统上搞定Horizon Client for Linux(ARM版)的保姆级安装与排错
在国产UOS系统上搞定Horizon Client for Linux(ARM版)的保姆级安装与排错 当国产操作系统遇上企业级虚拟桌面,技术适配的挑战往往超出预期。最近在华为鲲鹏920芯片的终端上部署Horizon Client时,那些在x86环境下一帆风顺的安装步骤…...