MySQL(上)
一、SQL优化
1、如何定位及优化SQL语句的性能问题?创建的索引有没有被使用到?或者说怎么才可以知道这条语句运行很慢的原因?
对于性能比较低的sql语句定位,最重要的也是最有效的方法其实还是看sql的执行计划,而对于mysql来说,它其实也是提供了explain这样的命令可以便于查询sql的执行计划,并且通过执行计划,我们能够看到sql的执行情况,包括是否使用索引,使用了什么样的索引,以及使用索引的一些相关信息。
对于执行计划来说 它里面有几个非常关键的字段,比如说有key字段,这个字段就表示是否用了索引,如果没用索引,key字段就为null;同时还有type字段它表示使用索引的类型,索引的效果从差到好一般是全表索引,–index全索引树扫描,–》range范围查询–》ref(使用非唯一索引进行查找数据)–》eq-ref(使用主键索引或者唯一索引关联等)(type扫描方式由快到慢
system > const > eq_ref > ref > range > index > ALL
system:系统表,少量数据,往往不需要进行磁盘IO
const:常量连接
) possible key 可能使用到的索引 key length 索引的长度 extra信息,比如说有 using index,using where
2、大表数据的查询如何进行优化?
1>首先对于大表数据,第一个思路还是优化sql+去使用索引
2>使用缓存–如果说已经优化了sql,还可以通过使用缓存,将一些不会发生变化的比如配置信息,历史数据信息放到缓存redis中去
3>其次还可以做主从复制,读写分离,将大量的查询操作通过读库完成
4>做垂直拆分,也就是按照模块之间的耦合度将系统和数据拆分成更细粒度
5>做水平拆分, 这一步就需要选择一个合适的sharing key,同时为了有更好的查询效率,表结构也要有改动,应用也要改动,注意sq中尽量带sharding key,将数据定位到限定的表上去查,而不是扫描全部的表
3、关心过业务系统里面的sql耗时吗?统计过慢查询吗?对慢查询都怎么优化过?
其实在业务系统的开发中,我除了使用主键进行查询以外,别的其实都是会在测试库上查看对应的耗时和执行效率,而我们系统的慢查询统计都是运维在做的,他们会通过邮件或者短信电话等方式推送和反馈给我们。针对于慢查询的sql分析,我们一般的操作其实是从三方面入手,就是明确慢查询的原因到底是什么?是没有走索引?还是load了过多不需要的数据,还是表的数据量过大导致的?
而这三个方向 也有对应的处理方式 1>首先我们拿到sql会看下当前load的数据中有没有多余字段,如果说是因为load了多余的行导致的查询过慢,我们就优化sql,进行重写 2>其次看下有没有走索引,就是通过分析sql的执行计划(explain),获取索引的使用情况,如果说没有走索引,就修改语句,尽量去命中索引 3>如果对语句的优化已经无法进行,可以考虑表中的数据量是否太大,如果是的话可以进行横向或者纵向的分表。
4、如何去优化WHERE子句 ?
对于此类考题,先说明如何定位低效SQL语句,然后根据SQL语句可能低效的原因做排查,先从索引着手,如果索引没有问题,考虑以下几个方面,数据访问的问题,长难查询句的问题还是一些特定类型优化的问题,逐一回答。
SQL语句优化的一些方法如下: 1>对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2>应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num is null ‐‐ 可以在num上设置默认值0,确保表中num列,没有null值,然后这样查询:select id from t where num=0
3>应尽量避免在 where 子句中使用!=或<>操作符,否则引擎将放弃使用索引而进行全表扫描。
4>应尽量避免在 where 子句中使用or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num=10 or num=20 ‐‐ 可以这样查询:select id from t where num=10 union all select id from t where num=20
5>in 和 not in 也要慎用,否则会导致全表扫描,如: 1 select id from t where num in(1,2,3) ‐‐ 对于连续的数值,能用 between 就不要用 in 了:select id from t where num between 1 and 3
6>下面的查询也将导致全表扫描:select id from t where name like ‘%李%’,若要提高效率,可以考虑全文检索。
7>如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描: select id from t where num=@num ‐‐可以改为强制查询使用索引:select id from t with (index(索引名)) where num=@num
8>应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where num/2=100 ‐‐ 应改为:select id from t where num=100*2
9>应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where substring(name,1,3)=’abc’ ‐‐ name以abc开头的id应改为: select id from t where name like ‘abc%’
10>不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
5、MySQL数据库cpu飙升到500%的话他怎么处理?
当 cpu 飙升到 500%时,先用操作系统命令 top 命令观察是不是 mysqld 占用导致的,如果不是,找出占用高的进程,并进行相关处理。 如果是 mysqld 造成的, show processlist,看看里面跑的 session 情况,是不是有消耗资源的 sql 在运行。找出消耗高的 sql,看看执行计划是否准确,index-索引 是否缺失,或者实在是数据量太大造成。 一般来说,肯定要 kill 掉这些线程(同时观察 cpu 使用率是否下降),等进行相应的调整(比如说加索引、改 sql、改内存参数)之后,再重新跑这些 SQL。 也有可能是每个 sql 消耗资源并不多,但是突然之间,有大量的 session 连进来导致 cpu 飙升,这种情况就需要跟应用一起来分析为何连接数会激增,再做出相应的调整,比如说限制连接数等。
6、大表怎么优化?某个表有近千万数据,CRUD比较慢,如何优化?分库分表了是怎么做的?分表分库了有什么问题?有用到中间件么?他们的原理知道么?
当MySQL单表记录数过大时,数据库的CRUD性能会明显下降,一些常见的优化措施如下:
限定数据的范围: 务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内; 读/写分离: 经典的数据库拆分方案,主库负责写,从库负责读; 缓存: 使用MySQL的缓存,另外对重量级、更新少的数据可以考虑使用应用级别的缓存;
还有就是通过分库分表的方式进行优化,主要有垂直分表和水平分表
垂直分区: 根据数据库里面数据表的相关性进行拆分。 例如,用户表中既有用户的登录信息又有用户的基本信息,可以将用户表拆分成两个单独的表,甚至放到单独的库做分库。 简单来说垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表。 如下图所示,这样来说大家应该就更容易理解了。

垂直拆分的优点: 可以使得行数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护。
垂直拆分的缺点: 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决。此外,垂直分区会让事务变得更加复杂;
垂直分表 把主键和一些列放在一个表,然后把主键和另外的列放在另一个表中
适用场景 1、如果一个表中某些列常用,另外一些列不常用 2、可以使数据行变小,一个数据页能存储更多数据,查询时减少I/O次数
缺点 有些分表的策略基于应用层的逻辑算法,一旦逻辑算法改变,整个分表逻辑都会改变,扩展性较差。对于应用层来说,逻辑算法增加开发成本,管理冗余列,查询所有数据需要join操作。
水平分区: 保持数据表结构不变,通过某种策略存储数据分片。这样每一片数据分散到不同的表或者库中,达到了分布式的目的。 水平拆分可以支撑非常大的数据量。 水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
数据库水平拆分 水品拆分可以支持非常大的数据量。需要注意的一点是:分表仅仅是解决了单一表数据过大的问题,但由于表的数据还是在同一台机器上,其实对于提升MySQL并发能力没有什么意义,所以 水平拆分最好分库 。 水平拆分能够支持非常大的数据量存储,应用端改造也少,但分片事务难以解决 ,跨界点Join性能较差,逻辑复杂。
《Java工程师修炼之道》的作者推荐尽量不要对数据进行分片,因为拆分会带来逻辑、部署、运维的各种复杂度 ,一般的数据表在优化得当的情况下支撑千万以下的数据量是没有太大问题的。如果实在要分片,尽量选择客户端分片架构,这样可以减少一次和中间件的网络I/O。
水平分表: 表很大,分割后可以降低在查询时需要读的数据和索引的页数,同时也降低了索引的层数,提高查询次数

适用场景 1、表中的数据本身就有独立性,例如表中分表记录各个地区的数据或者不同时期的数据,特别是有些数据常用,有些不常用。 2、需要把数据存放在多个介质上。
水平切分的缺点 1、给应用增加复杂度,通常查询时需要多个表名,查询所有数据都需UNION操作 2、在许多数据库应用中,这种复杂度会超过它带来的优点,查询时会增加读一个索引层的磁盘次数
下面补充一下数据库分片的两种常见方案: 客户端代理:分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现。 当当网的 ShardingJDBC 、阿里的TDDL是两种比较常用的实现。
中间件代理:在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。 我们现在谈的 Mycat、360的Atlas、网易的DDB等等都是这种架构的实现。
二、索引
1、什么是索引?索引的优缺点?
索引在项目中非常常见,它是一种帮助MySQL高效获取数据的数据结构,主要用来提高数据检索效率。
优点:
1>提高数据检索效率,降低数据库的I/O成本;
2>索引列可以对数据进行排序,降低数据排序的成本,也能减少CPU的消耗。
缺点:
1>建立索引会占用物理空间;
2>会降低表的增删改的效率,因为每次对表记录进行增删改,需要进行动态维护索引,导致增删改时间变长。
2、什么情况下需要建索引?
-
主键自动创建唯一索引
-
较频繁的作为查询条件的字段
-
查询中排序的字段,查询中统计或者分组的字段
3、什么情况下不建索引?
-
表记录太少的字段
-
经常增删改的字段
-
唯一性太差的字段,不适合单独创建索引。比如性别,民族,政治面貌
4、索引主要有哪几种分类?
MySQL主要的几种索引类型:1.普通索引 2.唯一索引 3.主键索引 4.组合索引 5.全文索引。
普通索引: 是最基本的索引,它没有任何限制 唯一索引: 索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一 主键索引: 是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。 组合索引: 一个索引包含多个列,实际开发中推荐使用组合索引。 全文索引: 全文搜索的索引。FULLTEXT 用于搜索很长一篇文章的时候,效果最好。只能用于InnoDB或MyISAM表,只能为CHAR、VARCHAR、TEXT列创建。
主键索引和唯一索引的区别:
主键必唯一,但是唯一索引不一定是主键;
一张表上只能有一个主键,但是可以有一个或多个唯一索引。
5、索引的数据结构有哪些?
索引的数据结构主要有B+树和哈希表,对应的索引分别为B+树索引和Hash索引。InnoDB引擎的索引类型有B+树索引和Hash索引,默认的索引类型为B+树索引。
Hash索引
哈希索引是基于哈希表实现的,当我们要给某张表某列增加索引时,存储引擎会对这列进行哈希计算得到哈希码,将哈希码的值作为哈希表的key值,将指向数据行的指针作为哈希表的value值。这样查找一个数据的时间复杂度就是O(1),一般多用于精确查找。所以在= in <=>(安全等于的时候)塔的效率是非常,但我们开发一般会选择Btree,因为Hash会存在如下一些缺点。
1>Hash索引仅仅能满足"=",“IN"和”<=>"查询,不能使用范围查询。 2>Hash 索引无法被用来避免数据的排序操作。 3>Hash索引不能利用部分索引键查询。 4>Hash索引在任何时候都不能避免表扫描。 5>Hash索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
为什么B+树比B树更适合实现数据库索引? 1>B+ 树叶子结点之间用双向链表有序连接,所以扫描全部数据只需扫描一遍叶子结点,利于扫库和范围查询;B 树由于非叶子结点也存数据,所以只能通过中序遍历按序来扫。也就是说,对于范围查询和有序遍历而言,B+ 树的效率更高。 2>B+ 树更相比 B 树减少了 I/O 读写的次数。由于索引文件很大因此索引文件存储在磁盘上,B+ 树的非叶子结点只存关键字不存数据,因而单个页可以存储更多的关键字,即一次性读入内存的需要查找的关键字也就越多,磁盘的随机 I/O 读取次数相对就减少了。 3>B+树的查询效率更加稳定,任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
6、什么是聚集索引,什么是非聚集索引?
聚集索引是指数据与索引放在一起,B+树的叶子节点保存了整行数据,通常只有一个聚集索引,一般是由主键构成。
-
如果表设置了主键,则主键就是聚集索引
-
如果表没有主键,则会默认第一个NOT NULL,且唯一(UNIQUE)的列作为聚集索引
-
以上都没有,则会默认创建一个隐藏的row_id作为聚集索引
聚集索引要比非聚集索引查询效率高很多。
非聚集索引(普通索引、二级索引)则是数据与索引分开存储,B+树的叶子节点保存的是主键值(聚集索引的值),可以有多个非聚簇索引,通常我们自定义的索引都是非聚集索引。
聚集索引查询:如果查询条件为主键(聚集索引),则只需扫描一次B+树即可通过聚集索引定位到要查找的行记录数据。
非聚集索引查询:如果查询条件为普通索引(非聚集索引),需要扫描两次B+树,第一次扫描通过普通索引定位到聚集索引的值(主键的值),然后第二次扫描通过聚集索引的值定位到要查找的行记录数据。
7、知道什么是回表查询吗?
回表查询是指通过二级索引找到对应的主键值,然后再通过主键值查询聚集索引中对应的整行数据的过程。需要扫描两次索引B+树,它的性能较扫一遍索引树更低。
8、什么是覆盖索引?
覆盖索引是指在SELECT查询中,返回的列全部能在索引中找到,避免了回表查询,提高了性能。使用覆盖索引可以减少对主键索引的查询次数,提高查询效率。
例子:
非聚集索引查询的sql:
select id,age from user where age = 30;
这个sql我们是不是就不用回表查询了,因为在非聚集索引的叶子节点上已经有id和age的值。所以根本不需要拿着id的值再去聚集索引定位行记录数据了。也就是在这一颗索引树上就可以完成对数据的检索,这样就实现了覆盖索引。
如果这个sql是:
select id,age,name from user where age = 30;
那就不能实现索引覆盖了,因为name的值在age索引树上是没有的,还是需要拿着id的值再去聚集索引定位行记录数据。但是如果我们对age和name做一个组合索引idx_age_name(age,name),那就又可以实现索引覆盖了。
9、什么是最左匹配原则?
如果我们创建了(age, name)的组合索引,那么其实相当于创建了(age)、(age, name)两个索引,这被称为最佳左前缀特性。因此我们在创建组合索引时应该将最常用作限制条件的列放在最左边,依次递减。
最左前缀匹配原则:在MySQL建立联合索引时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。
10、索引失效的场景?
-
组合索引未使用最左前缀,例如组合索引(age,name),where name='张三’不会使用索引;
-
or会使索引失效。如果查询字段相同,也可以使用索引。例如where age=20 or age=30(索引生效),where age=20 or name=‘张三’(这里就算你age和name都单独建索引,还是一样失效);
-
如果列类型是字符串,不使用引号。例如where name=张三(索引失效),改成where name=‘张三’(索引有效);
-
like未使用最左前缀,where A like ‘%China’;
-
在索引列上做任何操作计算、函数,会导致索引失效而转向全表扫描;
-
如果mysql估计使用全表扫描要比使用索引快,则不使用索引。
11、索引的创建原则?
-
索引列的区分度越高,索引的效果越好。比如使用性别这种区分度很低的列作为索引,效果就会很差。
-
尽量使用短索引,对于较长的字符串进行索引时应该指定一个较短的前缀长度,因为较小的索引涉及到的磁盘I/O较少,查询速度更快。
-
索引不是越多越好,每个索引都需要额外的物理空间,维护也需要花费时间。
-
利用最左前缀原则。
相关文章:
MySQL(上)
一、SQL优化 1、如何定位及优化SQL语句的性能问题?创建的索引有没有被使用到?或者说怎么才可以知道这条语句运行很慢的原因? 对于性能比较低的sql语句定位,最重要的也是最有效的方法其实还是看sql的执行计划,而对于mysql来说&a…...

ffplay 实现视频流中音频的延迟
ffplay -rtsp_transport tcp -i rtsp://admin:1234qwer192.168.1.64:554/Streaming/Channels/101 -vn -af "adelay5000|5000"在这个命令中: -vn 参数表示只播放音频。 -af "adelay5000|5000" 参数表示将音频延迟5000毫秒(即5秒&…...

CSDN资源变现
根据搜索结果,CSDN资源变现主要有以下几种方式: 1、上传付费资源: 用户可以在CSDN上上传资源并设置付费,其他用户支付费用下载这些资源,上传者则获得一部分收益。这种方式适合上传大量资源,通过量变达到质变…...
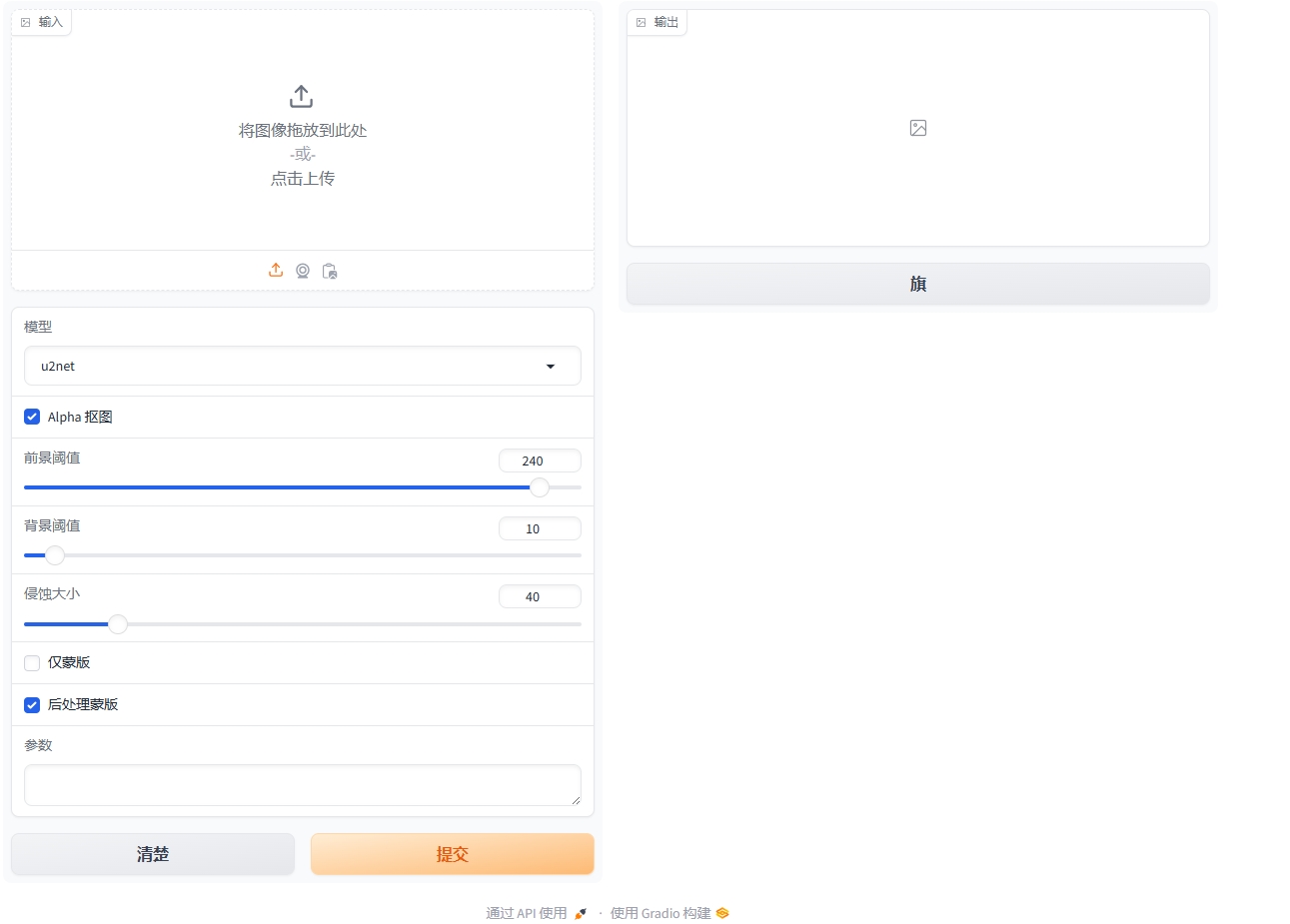
Rembg模型构建教程
一、介绍 Rembg,全称为“Remove Background”,是一款基于深度学习的图像背景去除工具。它的主要功能是通过智能识别图像中的前景物体,并将其从背景中分离出来,从而创建具有透明背景的图像。 二、基础环境 系统:Ubun…...

向量的基础知识和矩阵向量的坐标旋转
向量的基础: 定义: 既有大小,又有方向的量叫做向量(Vector)。 在几何上,向量用有向线段来表示,有向线段长度表示向量的大小,有向线段的方向表示向量的方向。其实有向线段本身也是向…...
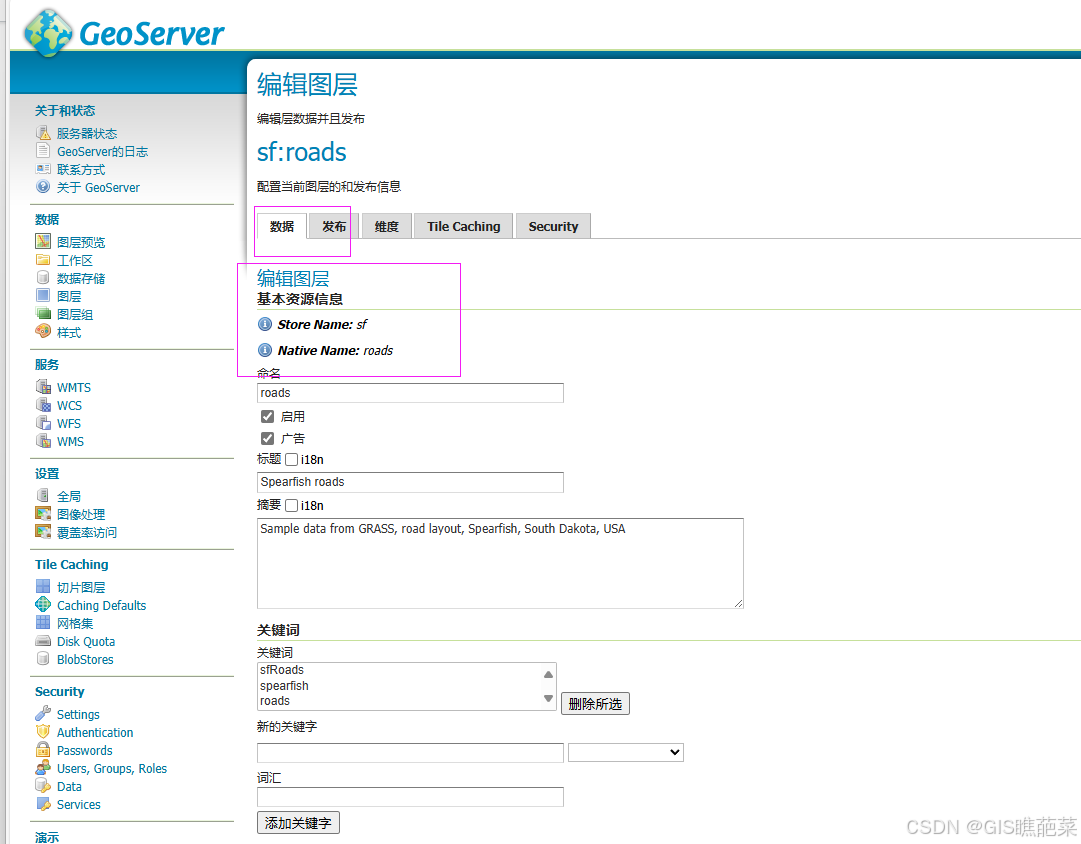
GeoSever发布图层(保姆姬)
发布服务的具体步骤。 1. 安装 GeoServer 下载 GeoServer 安装包:GeoServer 官网按照安装说明进行安装,可以选择 Windows、Linux 或其他平台。 2. 启动 GeoServer 启动 GeoServer 通常通过访问 http://localhost:8080/geoserver 进行。默认用户名和密…...

AI 大模型的发展趋势是怎样的?
AI 大模型的发展趋势呈现出多方面的特点,包括技术、应用、商业模式等多个维度,具体如下: 技术层面: 多模态融合:未来,AI 大模型将不断加强对多模态数据的处理能力,融合文本、图像、音频、视频等…...
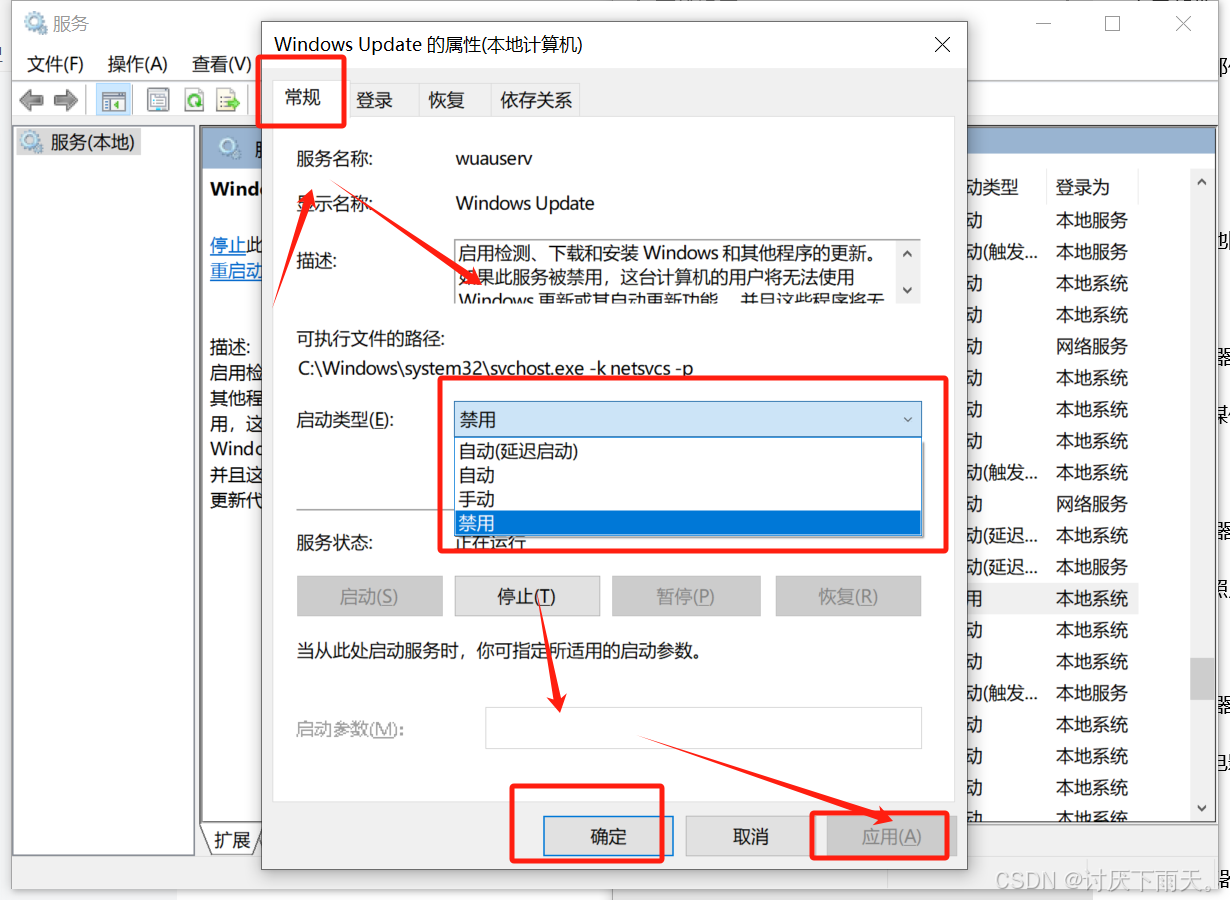
win10怎么关掉自动更新-小白必看
1.搜索栏搜索服务单机点开 2.在服务里面找到windows Update服务双击进去 3.如下图把他禁用然后点应用即可...

大学城水电资源管理:Spring Boot解决方案
1系统概述 1.1 研究背景 随着计算机技术的发展以及计算机网络的逐渐普及,互联网成为人们查找信息的重要场所,二十一世纪是信息的时代,所以信息的管理显得特别重要。因此,使用计算机来管理大学城水电管理系统的相关信息成为必然。开…...

躺平成长-运营日记-第三天
开源竞争: (自己没有办法完全掌握技术的时候就开源掉,培养出更多的技术依赖,让更多的人完善你的技术,那么这不就是在砸罐子吗?一个行业里面你不去砸罐子,其他人就会砸罐子,你不如先砸…...
智慧税务管理:金融企业报税效率与合规性提升
前言 在数字化浪潮席卷全球的今天,金融行业正面临前所未有的挑战与机遇。如何在复杂的税务环境中保持合规并提高效率,已成为每个金融企业的重中之重。今天小编就为大家介绍一下如何通过借助智能税务平台,实现税务管理的智能化革新࿰…...

linux之网络子系统-用户层接收数据包之同步阻塞方案
一、前言 之前讲述了网络包是如何从网卡送到协议栈的,接下来内核还有一项重要的工作,就是在协议栈接收处理完输入包后要通知到用户进程,如何用户进程接收到并处理这些数据。 进程与内核配合有多种方案,这里我们这分析两种典型的…...

【天线&空中农业】花生霉变检测系统源码&数据集全套:改进yolo11-LVMB
改进yolo11-goldyolo等200全套创新点大全:花生霉变检测系统源码&数据集全套 1.图片效果展示 项目来源 人工智能促进会 2024.11.01 注意:由于项目一直在更新迭代,上面“1.图片效果展示”和“2.视频效果展示”展示的系统图片或者视…...

全志A133 android10 LVDS幅值调节
一,问题现象 系统使用LVDS接口屏幕,进入系统有些界面会闪,图像抖动; 二,解决办法: 1.调试 调节LCD0的LVDS电压幅度,寄存器地址是0x06511220(具体是在User Manual中的LCD LVDS Ana…...
弃用 RestTemplate,来了解一下官方推荐的 WebClient !
在 Spring Framework 5.0 及更高版本中,RestTemplate 已被弃用,取而代之的是较新的 WebClient。这意味着虽然 RestTemplate 仍然可用,但鼓励 Spring 开发人员迁移到新项目的 WebClient。 WebClient 优于 RestTemplate 的原因有几个ÿ…...
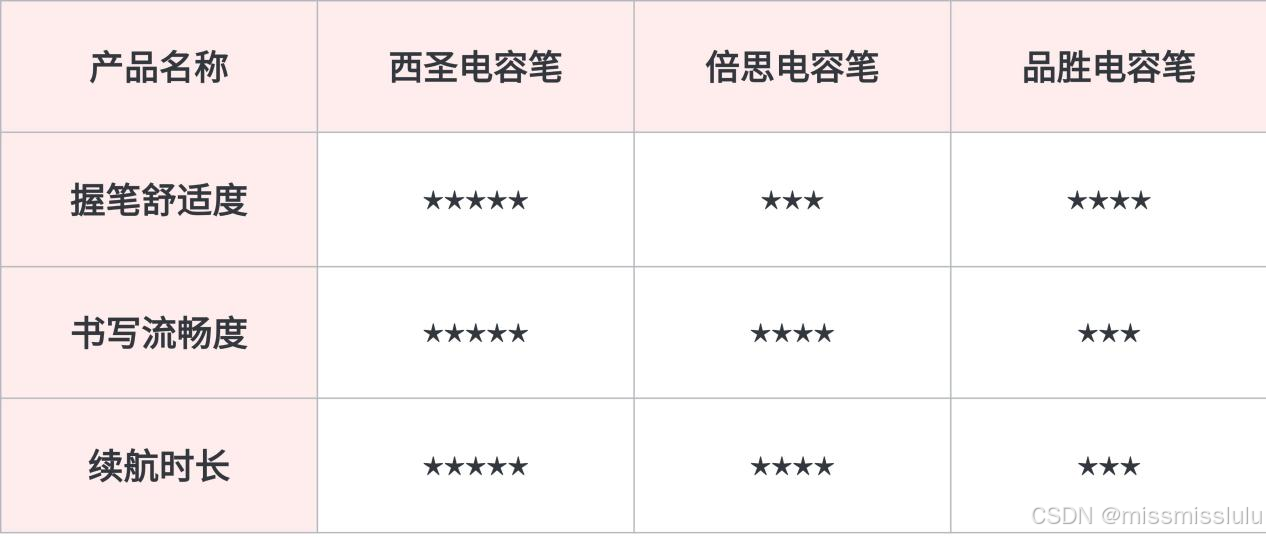
西圣、倍思、品胜电容笔孰强孰弱?多维度对比测评三款平替电容笔
在近年来,平替电容笔以其亲民的价格和优质的性能变现,成为市场上备受追捧的选择。然而,某些品牌为了吸引消费者,降低价格的同时常采用劣质材料,结果握笔体验差,书写效果糟糕,甚至在长时间使用后…...

VS2022配置调试Qt源代码
需要保证源代码和项目使用的版本匹配,符号需要注意是64位还是32位,并且用msvc。 1. 设置源代码路径 2. 设置调试PDB路径 这里最好把4个地方都加进去,防止某些不常用PDB被漏掉。 D:\Qt\5.15.2\msvc2019_64\bin D:\Qt\5.15.2\msvc2019_64\lib…...

Python 的 Pygame 库来开发一个游戏
import pygame import random# 初始化 Pygame pygame.init()# 设置屏幕大小 screen_width 800 screen_height 600 screen pygame.display.set_mode((screen_width, screen_height))# 设置标题 pygame.display.set_caption("飞机大战")# 加载图片 player_img pyga…...
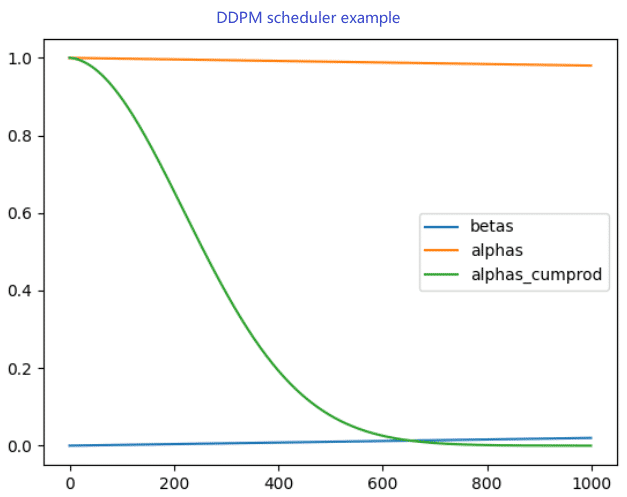
diffusion model 学习笔记
条件引导的 diffusion 对于无条件的DDPM 而言 p ( x t ∣ x 0 ) ∼ N ( α t ˉ x 0 , 1 − α t ˉ ⋅ I ) p(x_t | x_0) \sim \mathcal{N}( \sqrt{\bar{\alpha_t}} x_0, 1-\bar{\alpha_t} \cdot \mathrm{I} ) p(xt∣x0)∼N(αtˉ x0,1−αtˉ⋅I) 可以得到…...
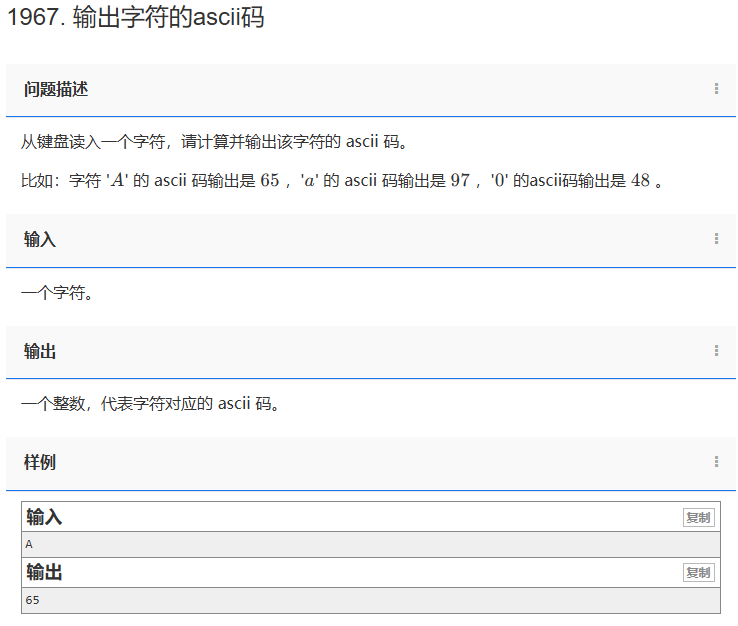
【C++题解】1967. 输出字符的ascii码
欢迎关注本专栏《C从零基础到信奥赛入门级(CSP-J)》 问题:1967. 输出字符的ascii码 类型:字符串、字符型 题目描述: 从键盘读入一个字符,请计算并输出该字符的 ascii 码。 比如:字符 ‘A’ …...

抖音去水印下载器终极指南:批量保存视频、音乐、图集和直播
抖音去水印下载器终极指南:批量保存视频、音乐、图集和直播 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback …...

中兴光猫终极管理工具:一键开启工厂模式与永久Telnet完全指南
中兴光猫终极管理工具:一键开启工厂模式与永久Telnet完全指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu zteOnu是一款专为中兴光猫设备设计的开源管理工具,…...

RPG Maker MV Decrypter:解决游戏资源保护与合法访问的技术平衡方案
RPG Maker MV Decrypter:解决游戏资源保护与合法访问的技术平衡方案 【免费下载链接】RPG-Maker-MV-Decrypter You can decrypt RPG-Maker-MV Resource Files with this project ~ If you dont wanna download it, you can use the Script on my HP: 项目地址: ht…...
)
【免费下载】 JIRA用户操作指南(详细版)
JIRA用户操作指南(详细版) 【下载地址】JIRA用户操作指南详细版 JIRA用户操作指南(详细版)欢迎使用JIRA用户操作指南,本指南旨在帮助您全面理解并高效地使用JIRA这一强大的问题跟踪与项目管理工具 项目地址: https:/…...

超导量子处理器校准技术:频率分配与门优化
1. 超导量子处理器校准技术概述超导量子处理器校准是量子计算硬件实现中的关键环节,其核心目标是通过系统化的参数优化和误差抑制,确保量子比特能够可靠地执行高保真度的量子门操作。在Zuchongzhi 3.1处理器的研发过程中,我们成功集成了105个…...

强烈的“似曾相识“感:由于人类左右大脑处理信息的速度并非完全同步,在某些特殊瞬间,这个流程会被打乱
海马效应(既视现象) 目录 海马效应(既视现象) 核心科学原理 高发场景与人群 典型例子 海马效应,科学上称为既视现象(Dj vu),是指人在从未真实经历过的当下场景中,突然产生强烈的"似曾相识"感,误以为眼前的一切曾经发生过的认知错觉。它并非玄学中的"…...
)
高校学生综合测评管理系统(10054)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

从医院PACS到你的Python脚本:手把手教你用pydicom库读写和修改DICOM文件
从医院PACS到Python脚本:pydicom实战医学影像处理指南 医学影像数据正以每年30%的速度增长,而DICOM作为医疗影像存储与传输的国际标准,承载着CT、MRI等设备产生的海量数据。在临床研究、AI模型训练和医疗信息化建设中,开发者经常需…...

终极指南:Ghost补丁管理系统与第三方依赖维护最佳实践
终极指南:Ghost补丁管理系统与第三方依赖维护最佳实践 【免费下载链接】Ghost Independent technology for modern publishing, memberships, subscriptions and newsletters. 项目地址: https://gitcode.com/GitHub_Trending/gh/Ghost Ghost作为一款强大的现…...

APK Installer终极指南:在Windows电脑上快速安装Android应用的完整方案
APK Installer终极指南:在Windows电脑上快速安装Android应用的完整方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否厌倦了在电脑和手机之间来回传…...