数据采集(全量采集和增量采集)
全量采集:采集全部数据
3、全量采集
vim students_all.json{"job": {"setting": {"speed": {"channel": 1},"errorLimit": {"record": 0,"percentage": 0.02}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "root","password": "123456","splitPk": "id","column": ["id","name","age","gender","clazz","update_time"],"connection": [{"table": ["students"],"jdbcUrl": ["jdbc:mysql://master:3306/bigdata31"]}]}},"writer": {"name": "hdfswriter","parameter": {"defaultFS": "hdfs://master:9000","fileType": "text","path": "/data/students_all/dt=${dt}","fileName": "students","column": [{"name": "id","type": "STRING"},{"name": "name","type": "STRING"},{"name": "age","type": "INT"},{"name": "gender","type": "STRING"},{"name": "clazz","type": "STRING"},{"name": "update_time","type": "STRING"}],"writeMode": "truncate","fieldDelimiter": ","}}}]}
}# 创建分区目录
hdfs dfs -mkdir -p /data/students_all/dt=2024-10-21
# 执行datax脚本
datax.py -p"-Ddt=2024-10-21" students_all.json
# 增加分区
hive -e "alter table students_all add if not exists partition(dt='2024-10-21');"增量采集:就只采集新插入或修改的数据
1、原表需要有一个更新时间字段
CREATE TABLE `students` (`id` bigint(20) ,`name` varchar(255) ,`age` bigint(20),`gender` varchar(255) ,`clazz` varchar(255),`update_time` datetime NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ;2、在hive中创建分区表
create external table if not exists students_all(id bigint comment '学生id',name string comment '学生姓名',age bigint comment '学生年龄',sex string comment '学生性别',clazz string comment '学生班级',update_time string comment '更新时间'
) comment '学生信息表'
partitioned by (dt string)
row format delimited fields terminated by ','
stored as textfile
location 'hdfs://master:9000/data/students_all';4、创建增量表
create external table if not exists students_acc(id bigint comment '学生id',name string comment '学生姓名',age bigint comment '学生年龄',sex string comment '学生性别',clazz string comment '学生班级',update_time string comment '更新时间'
) comment '学生信息表'
partitioned by (dt string)
row format delimited fields terminated by ','
stored as textfile
location 'hdfs://master:9000/data/students_acc';5、增量采集更新的数据
vim students_acc.json{"job": {"setting": {"speed": {"channel": 1},"errorLimit": {"record": 0,"percentage": 0.02}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "root","password": "123456","splitPk": "id","where": "substr(update_time,1,10)='${dt}'","column": ["id","name","age","gender","clazz","update_time"],"connection": [{"table": ["students"],"jdbcUrl": ["jdbc:mysql://master:3306/bigdata31"]}]}},"writer": {"name": "hdfswriter","parameter": {"defaultFS": "hdfs://master:9000","fileType": "text","path": "/data/students_acc/dt=${dt}","fileName": "students","column": [{"name": "id","type": "STRING"},{"name": "name","type": "STRING"},{"name": "age","type": "INT"},{"name": "gender","type": "STRING"},{"name": "clazz","type": "STRING"},{"name": "update_time","type": "STRING"}],"writeMode": "truncate","fieldDelimiter": ","}}}]}
}# 创建分区目录
hdfs dfs -mkdir -p /data/students_acc/dt=2024-10-22
# 执行datax脚本
datax.py -p"-Ddt=2024-10-22" students_acc.json
# 增加分区
hive -e "alter table students_acc add if not exists partition(dt='2024-10-22');"6、合并数据
vim student_merge.sqlinsert overwrite table students_all partition(dt='${dt}')
selectid,name,age,sex,clazz,update_time
from(selectid,name,age,sex,clazz,update_time,row_number() over (partition byidorder byupdate_time desc) as rfrom(select*fromstudents_allwheredt = '${diff_dt}'union allselect*fromstudents_accwheredt = '${dt}') as a) as b
wherer = 1;hive -f student_merge.sql -d dt=2024-10-22 -d diff_dt=2024-10-21spark-sql \
--master yarn \
--deploy-mode client \
--num-executors 2 \
--executor-cores 1 \
--executor-memory 2G \
--conf spark.sql.shuffle.partitions=1 \
-f student_merge.sql -d dt=2024-10-22 -d diff_dt=2024-10-21相关文章:
)
数据采集(全量采集和增量采集)
全量采集:采集全部数据 3、全量采集 vim students_all.json {"job": {"setting": {"speed": {"channel": 1},"errorLimit": {"record": 0,"percentage": 0.02}},"content": [{…...

GPT-Sovits-1-数据处理
1.1 切割音频 将音频切割为多个10s内的片段 1.2 降噪 这一步用的是modelscope的pipeline 如果要去除背景音,可以用傅立叶转为为频谱,去除低频部分后再转回来 1.3 提取音频特征 这里用到了 funasr 库 这一步目的是输出音频样本的《文本标签文件》&am…...

web前端多媒体标签设置(图片,视频,音频)以及图片热区(usemap)的设置
多媒体标签运用 在HTML中有以下常见多媒体标签: <img> (图像标签) - 作用:用于在网页中嵌入图像。 - 示例: <img src"image.jpg" alt"这是一张图片"> 。其中 src 属性指定图像的…...

尚硅谷react教程_扩展_stateHook
1.类式组件写 import React, {Component} from react;export default class Demo extends Component {state {count:0}add () > {this.setState(state>({count:state.count1}))}render() {return (<div><h2>当前求和为{this.state.count}</h2><b…...

专线物流公共服务平台:数据驱动,标准引领,共创金融双赢新时代
专线物流公共服务平台:数据驱动,标准引领,共创金融双赢新时代 在当今这个数据驱动、标准引领、金融赋能的经济发展新时代,专线物流作为商贸流通领域的重要一环,正面临着前所未有的机遇与挑战。为应对复杂多变的市场环…...
界面控件DevExpress JS ASP.NET Core v24.1亮点 - 支持Angular 18
DevExtreme拥有高性能的HTML5 / JavaScript小部件集合,使您可以利用现代Web开发堆栈(包括React,Angular,ASP.NET Core,jQuery,Knockout等)构建交互式的Web应用程序。从Angular和Reac,…...

Spring之依赖注入(DI)和控制反转(IoC)——配置文件、纯注解
依赖注入 依赖注入(Dependency Injection,简称 DI)与控制反转(loC)的含义相同,只不过这两 个称呼是从两个角度描述的同一个概念。对于一个 Spring 初学者来说,这两种称呼很难理解, 下面我们将通过简单的语言来描述这两个概念。 当Java对象&…...

基于SpringBoot的宠物健康咨询系统的设计与实现
摘 要 传统信息的管理大部分依赖于管理人员的手工登记与管理,然而,随着近些年信息技术的迅猛发展,让许多比较老套的信息管理模式进行了更新迭代,宠物健康知识信息因为其管理内容繁杂,管理数量繁多导致手工进行处理不…...
Lucene的使用方法与Luke工具(2)
文章目录 第2章 Lucene快速入门2.1 项目搭建2.1.1 SQL语句2.1.2 maven依赖2.1.3 实体类:2.1.4 编写DAO: 2.2 建立索引2.2.1 步骤:2.2.2 实现代码: 2.3 Luke工具2.3.1 运行界面介绍:1)主界面2)文…...

【客户端开发】electron 中无法使用 js-cookie 的问题
产生问题的原因 谷歌浏览器升级之后,出于安全考虑,cookie的SameSite属性默认值由None变为Lax,对于跨域的请求,禁止携带cookie。electron内核是chromium内核,所以也会有这个限制。 Cookie的SameSite属性用来限制第三方 Cookie&…...

kafka客户端消费者吞吐量优化
问题背景 业务场景 mq消息消费实时性要求不高,期望可以牺牲一部分实时性,换取吞吐量,例如:数据库单条insert优化为batchInsert。优化后结果不符合预期:消费者消费消息的batchSize远小于实际配置的max.poll.records&a…...
电子工程师-高质量工具包
目录 来源 高质量工具包介绍 总体框架如下 ZL01-各类元器件相关资料 ZL02-电源设计资料 ZL03-大厂参考资料 ZL04-开发工具 ZL05-仿真工具 ZL06-各类电路接口设计指南 ZL07-付费专栏全集 ZL08-优质电子书 ZL09-硬件工程师 ZL10FPGA工程师教程 ZL10-PCB设计教程 Z…...

简单认识redis - 12 redis锁
在斜体样式**redis中,不同的问题有不一样的解决办法,那么锁也有不同的锁来解决不一样的问题,下面将举出几个常用的redis锁。 1. SETNX锁(简单独占锁) 原理: SETNX(SET if Not eXistsÿ…...

基于springboot+vue车辆充电桩管理系统
基于springbootvue车辆充电桩管理系统 摘 要 随着信息化时代的到来,管理系统都趋向于智能化、系统化,车辆充电桩管理系统也不例外,但目前国内仍都使用人工管理,市场规模越来越大,同时信息量也越来越庞大,…...
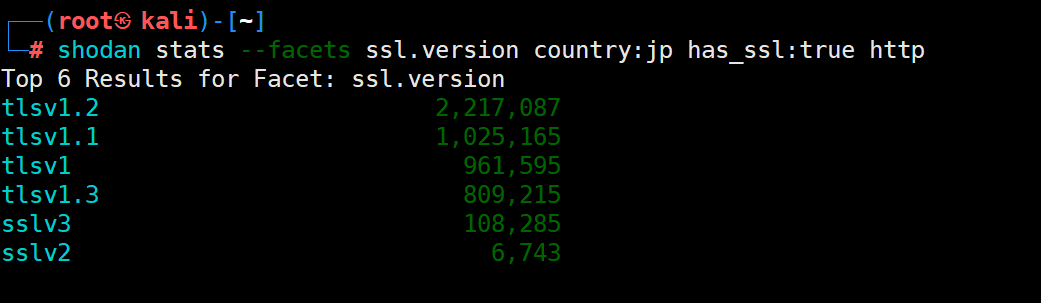
shodan用法(完)
声明 学习视频来自B 站up主泷羽sec,如涉及侵权马上删除文章。 笔记的只是方便各位师傅学习知识,以下网站只涉及学习内容,其他的都与本人无关,切莫逾越法律红线,否则后果自负。 shodan 今天,我们把shoda…...

【若依框架】代码生成详细教程,15分钟搭建Springboot+Vue3前后端分离项目,基于Mysql8数据库和Redis5,管理后台前端基于Vue3和Element Plus,开发小程序数据后台
今天我们来借助若依来快速的搭建一个基于springboot的Java管理后台,后台网页使用vue3和 Element Plus来快速搭建。这里我们可以借助若依自动生成Java和vue3代码,这就是若依的强大之处,即便你不会Java和vue开发,只要跟着石头哥也可…...

转子侧串级调速系统和双馈调速系统
转子侧串级调速系统和双馈调速系统是两种不同的电机调速技术,它们在基本原理、效率以及应用场景等方面存在区别。以下是详细的对比分析: 基本原理 转子侧串级调速系统:通过在绕线式异步电动机的转子回路中串入一个可调节的附加电势࿰…...
AI学习指南自然语言处理篇-Transformer模型的实践
AI学习指南自然语言处理篇 - Transformer模型的实践 目录 引言Transformer模型概述 自注意力机制编码器-解码器结构 环境准备Transformer模型的实现 编码器实现解码器实现Transformer模型整体实现 Transformer在NLP任务中的应用 文本分类机器翻译 总结与展望 引言 在过去的数…...

【LVGL速成】LVGL修改标签文本(GUI Guider生成的字库问题)
目录 前置篇章: 一.问题背景 二.失败方案 三.成功方案 1.Gui guider的源码结构 2.手动生成字体 3.Keil中配置相关文件 编辑 4.修改文字 四.字体样式函数说明 前置篇章: 【LVGL快速入门(二)】LVGL开源框架入门教程之框架使用(UI界面设计)_lvgl…...

C语言项目实践-贪吃蛇
⽬录: 1. 游戏背景 2. 游戏效果演⽰ 3. 实现的⽬标 4. 实现的定位 5. 技术要点 6. 贪吃蛇游戏设计与分析 7. 贪吃蛇游戏数据结构设计 8. 相关Win32API介绍 9. 参考代码 正文开始 1. 游戏背景 贪吃蛇是久负盛名的游戏,它也和俄罗斯⽅块…...

保姆级教程:用Python+Matplotlib处理微波辐射计LV2数据,绘制专业温度廓线图
科研级气象数据可视化:PythonMatplotlib处理微波辐射计数据的完整实践指南 清晨5点23分,实验室的微波辐射计刚刚完成一次完整的温度廓线扫描。屏幕上跳动的数字背后,隐藏着从地面到平流层的大气热力学密码。对于大气科学研究者而言࿰…...

攻防演练:Ettercap 实战中间人攻击与防御指南
1. 认识Ettercap:网络攻防的双刃剑 第一次接触Ettercap是在2015年的一次企业内网渗透测试中。当时我们需要模拟黑客攻击路径,测试公司内部网络的安全性。这个看起来其貌不扬的命令行工具,只用了几条简单的ARP欺骗命令,就成功劫持了…...

从 XChat 到超级 APP 生态:小程序生态为什么成为了超级APP的最佳技术选型
2026年4月17日,XChat 正式登陆苹果 App Store。 马斯克一直想做一个美国版的微信的目标已经实现:端对端加密、无广告、无追踪,注册只需要一个 X 账号,不需要手机号。马斯克给它的目标也很直接——X 要从社交平台,变成「…...
)
GitHub本周热门项目(2026-05-18)
GitHub 本周热门项目推荐 更新时间:2026-05-18 数据来源:GitHub Trending 🔥 TOP 10 热门项目 1. mattpocock/skills 一句话描述:面向真实工程师的技能框架,提供Claude Code等AI编码工具的专业技能扩展。 项目信息详…...

TPS5430玩点不一样的:15V输入如何生成一个干净的-12V电源?电路设计与极性电容防炸指南
TPS5430负压生成实战:从15V到-12V的电路设计精要 在模拟电路设计中,双电源供电系统(如12V)是音频设备、运算放大器和高精度ADC的常见需求。然而,当系统仅提供单路正电压输入时,如何高效生成稳定的负电压轨成…...

CircuitFusion:多模态AI在集成电路设计中的革命性应用
1. 集成电路设计的多模态革命:CircuitFusion技术解析在AI芯片设计领域,一个令人头疼的现实是:随着芯片复杂度呈指数级增长,传统设计流程已难以应对。以7nm工艺节点为例,单个芯片可能包含数十亿个晶体管,设计…...
)
告别UUID!用Apache Commons Lang3的RandomStringUtils生成更灵活的随机字符串(Java实战)
告别UUID!用Apache Commons Lang3的RandomStringUtils生成更灵活的随机字符串(Java实战) 在Java开发中,生成随机字符串的需求无处不在——从用户邀请码、临时密码到订单编号,我们经常需要快速生成一串既随机又可读的字…...

波动率交易神器volatility-trading:基于Euan Sinclair理论的完整工具集
波动率交易神器volatility-trading:基于Euan Sinclair理论的完整工具集 【免费下载链接】volatility-trading A complete set of volatility estimators based on Euan Sinclairs Volatility Trading 项目地址: https://gitcode.com/gh_mirrors/vo/volatility-tr…...
)
QT ToolButton的5个隐藏技巧与3个常见坑,新手避雷指南(基于Qt 6.5)
QT ToolButton的5个隐藏技巧与3个常见坑,新手避雷指南(基于Qt 6.5) 在模仿现代软件工具栏设计时,QT的ToolButton组件往往是实现专业级交互的关键。但许多开发者第一次使用时会发现,这个看似简单的按钮藏着不少"陷…...

构建金融级 AI Agent:Claude for Financial Services 架构解析
一、 金融 AI 的核心挑战:通用 LLM 的局限性 在金融实战中,通用大模型(如 Claude 3.5, GPT-4)直接上岗会面临三大障碍: 幻觉风险:在财务建模中,极小的数值偏差即可导致估值错误。数据孤岛&#…...