[MySQL#11] 索引底层(2) | B+树 | 索引的CURD | 全文索引
目录
1.B+树的特点
索引结构
复盘
其他数据结构的对比
B树与B+树总结
聚簇索引与非聚簇索引
辅助索引
2. 索引操作
主键索引
1. 创建主键索引
第一种方式
第二种方式
第三种方式
2. 查询索引
第一种方法
第二种方法
第三种方法
3. 删除索引
删除主键索引
删除其他索引
4. 特点
唯一索引
1. 创建
第一种方式
第二种方式
第三种方式
2. 删除唯一索引
3. 特点
普通索引
第一种方式
第二种方式
第三种方式
9. 普通索引的特点
复合索引
多列索引的创建
复合索引的工作原理
复合索引的应用场景
索引创建原则
索引总结
3.全文索引
创建
查询与全文索引
总结
1.B+树的特点
叶子节点保存有数据,非叶子节点不要数据
- 非叶子节点:不存数据,只存储目录项,可以存储更多的目录项。
- 目录页:一个目录页可以管理更多的叶子Page,使树更“矮胖”,减少I/O次数,提高效率。
叶子节点全部用链表级联起来
- 链表级联:叶子节点用链表级联,便于进行范围查找,提高查询效率。
索引结构
- InnoDB的索引结构:MySQL InnoDB存储引擎使用B+树作为索引结构。
- 主键索引:默认情况下,如果没有指定主键,MySQL会自动生成一个隐藏列作为主键。
- 普通索引:用户可以建立其他列的索引,这些索引也是B+树结构。
复盘
- Page分类:Page分为目录页和数据页。目录页只放各个下级Page的最小键值。
- 查找过程:自顶向下查找,只需加载部分目录页到内存,大大减少I/O次数。
- 索引构建:构建索引就是在MySQL内存中构建B+树,以指定列作为key值。
其他数据结构的对比
- 链表:线性遍历,效率低。
- 二叉搜索树:可能退化成线性结构,效率不稳定。
- AVL & 红黑树:虽然平衡,但树高较高,I/O次数多。
- Hash:适合点查询,但在范围查找方面表现不佳。
B+ vs B
B树

B+树

- B+树非叶子节点不存数据,数据都在叶子节点,并且所有叶子节点用链式结构连接起来。
- 而B树每一个节点内既包含目录项又包含数据,所有B树除了叶子节点有数据路上节点也会包含数据。还有B树的叶子节点是没有被链式结构连接起来的。
那为什么mysql没有使用B树而用的B+呢?
第一,mysql认为如果给非叶子节点增加数据,也就意味着单个page里能够保存的目录项变少了,意味着一个页目录所能管理的子目录子page就变少了,一旦变少了,在逻辑上这棵B树会比B+树更高一些更瘦一些,也就意味从根道叶子节点搜索的时候,要经过更多的节点要经历更多次IO,算法和IO带来的成本,永远都是IO带来的成本更高的。
第二,B树的叶子节点没有相连,也就意味着想进行范围查找,依旧要重新遍历这颗B树。而一旦重新遍历B树也就注定在遍历的时候需要每次查B树,可能有些page并不在内存里,又需要在进行IO,同时每次查效率也很慢,不像B+树找到起始位置线性遍历,一定拿到的是有效范围内所有数据。
B树与B+树总结
- B树:每个节点内既包含目录项又包含数据,树高较高,I/O次数多。
- B+树:非叶子节点不存数据,树更矮,I/O次数少,叶子节点用链表级联,便于范围查找。
例:演示一个Max.Degree=3 的B+树

数据结构演示链接
聚簇索引与非聚簇索引
非聚簇索引
- MyISAM存储引擎,索引和数据分离,适合某些场景。
- MyISAM 引擎同样使用B+树作为索引结果,叶节点的data域存放的是数据记录的地址。下图为 MyISAM表的主索引, Col1 为主键。

聚簇索引
- InnoDB存储引擎,数据和索引放在一起,提高查询效率。

下面我们见一下现象,文件结构
InnoDB:

test1.frm:表结构数据。test1.ibd:主键索引和用户数据。
MyISAM(分离):
CREATE TABLE myisam_test (id INT PRIMARY KEY
) ENGINE=MyISAM;test2.frm:表结构数据。test2.MYD:数据记录。test2.MYI:索引 数据指针。

辅助索引
- InnoDB:辅助索引的叶子节点只包含对应记录的主键值,需要进行回表查询。
- MyISAM:辅助索引和主键索引类似,叶子节点包含数据记录的地址。
注意:
- 所以一张表没有指明任何主键,mysql默认会给表添加默认主键也会以B+树结构呈现,只不过我没有设立主键就只能线性遍历。
- 如果我们指明主键默认我们的表会配上主键索引,会以我们自己设置的主键为key值设立主键索引。如果我们指明主键索引,未来还想给其他列设置索引,我们可以手动添加。
- 添加之后会在mysql内部重新构建B+树,以MyISAM为例会指向记录,如果是InnoDB保存的是主键值方便我们快速索引。换句话说,
- 一个表可能会建立主键索引或者其他普通索引,不管建立任何索引最终在mysql中一张表可能会有多颗B+树。
- 索引语法上分三类:主键索引、唯一键索引、普通索引,但其实宏观上就两类一个是主键索引,指明就用主键的没有指明就用默认的。一个是普通索引,包括唯一索引。
2. 索引操作
主键索引
1. 创建主键索引
第一种方式
在创建表时直接指定 primary key
create table test1(id int primary key, name varchar(30));- 说明:在字段名后指定
primary key,MySQL会根据该列构建主键索引。
第二种方式
在创建表的最后指定某列或某几列为主键索引
create table test2(id int, name varchar(30), primary key(id));- 说明:在表定义的最后指定某列或某几列为主键。
第三种方式
创建表以后再添加主键
create table test3(id int, name varchar(30));
alter table test3 add primary key(id);- 说明:先创建表,再通过
alter table添加主键。
2. 查询索引
第一种方法
使用 show keys from 表名
show keys from test1;第二种方法
使用 show index from 表名
show index from test1;第三种方法
使用 desc 表名
desc test1;- 说明:信息较为简略,主要用于查看表结构。

3. 删除索引
删除主键索引
- 第一种方法
alter table 表名 drop primary key;删除其他索引
- 第二种方法
alter table 表名 drop index 索引名;- 第三种方法
drop index 素引名 on 表名;4. 特点

- 一个表中最多有一个主键索引
- 主键索引的效率高(主键不可重复)
- 创建主键索引的列,值不能为null,且不能重复
- 主键索引的列基本上是int
唯一索引
1. 创建
第一种方式
- 在表定义时指定
unique唯一属性
create table test4(id int primary key, name varchar(30) unique);第二种方式
- 在表定义的最后指定某列或某几列为
unique
create table test5(id int primary key, name varchar(30), unique(name));第三种方式
- 创建表以后再添加唯一键
create table test6(id int primary key, name varchar(30));
alter table test6 add unique(name);- 说明:添加唯一键后,表中会有两个B+树,一个是主键索引,另一个是以指定列构建的唯一索引。
2. 删除唯一索引
- 使用
alter table删除索引
alter table 表名 drop index 索引名;- 说明:唯一索引的删除方式与普通索引相同,不能使用
drop unique。

为什么说这个呢,我们发现主键很特殊,构建是 add primary key,删除是 drop primary key 这没问题。
- 但是删除唯一键不能用drop unique,用的是drop index。
- 未来你会发现我们删除普通索引用的也是drop index。
- 说明unique索引本身也是一个普通索引。只不过指明它是uniqe是为了照顾表中的约束关系。
- 其实在索引层面,普通索引和唯一键索引都是一般索引。
- 最特殊的就是主键索引。
3. 特点
- 一个表中可以有多个唯一索引(唯一是指 无重复数据)
- 查询效率高
- 如果在某一列建立唯一索引,必须保证这列不能有重复数据
- 如果一个唯一索引上指定
not null,等价于主键索引
普通索引
创建
第一种方式
- 在表定义的最后指定某列为索引
create table test8(id int primary key,name varchar(20),email varchar(30),index(name)
);第二种方式
- 创建完表以后指定某列为普通索引
create table test9(id int primary key,name varchar(20),email varchar(30)
);
alter table test9 add index(name);- 说明:普通索引和唯一索引在结构上没有区别,都是B+树。
第三种方式
- 创建一个索引名为
idx_name的索引
create table test10(id int primary key,name varchar(20),email varchar(30)
);
create index idx_name on test10(name);9. 普通索引的特点

- 一个表中可以有多个普通索引,普通索引在实际开发中用得较多
- 如果某列需要创建索引,但该列有重复值,应使用普通索引
复合索引
多列索引的创建
问题:创建索引时只能在某一列创建吗?如果表中有多列信息,是否可以创建以多列为key值的索引结构?
答案:可以!
示例:
create table test11(id int primary key,name varchar(20),email varchar(30)
);
create index idx_name_email on test11(name, email);解释:
- 创建复合索引:我们以
name和email两列建立索引。 - 索引数量:创建复合索引后,表中显示有三个索引,但这并不意味着新增了两个B+树。
复合索引的工作原理
- 单一B+树:复合索引实际上只构建了一颗B+树,而不是两颗。
- 键值组合:这颗B+树的键值是由
name和email两列值组合而成。 - 搜索条件:在搜索时,这两列必须同时满足条件才能找到目标记录。
示例:
- 索引名称:复合索引的名称默认为
idx_name_email,以多列中的第一列name作为索引名称。 - 删除索引:删除复合索引时,只需一次操作即可删除整个复合索引。
alter table test11 drop index idx_name_email;复合索引的应用场景
何时使用复合索引:

- 避免回表:InnoDB普通索引的叶子节点放的是表的主键的key值,这意味着需要回表查询。但如果以
name和email构建复合索引,未来高频查询时,可以直接通过name和email查找,数据本身就在这颗复合索引的B+树里,无需回表。 - 索引覆盖:如果查询条件和返回值都在复合索引的列中,可以直接从索引中获取数据,无需回表,这种情况称为索引覆盖。
- 最左匹配原则:MySQL在索引匹配时是从左侧开始向右匹配。例如,可以按
name或name和email查找,但不能直接按email查找。
示例:
- 查询姓名和QQ号:
create table test12(id int primary key,name varchar(20),qq varchar(20)
);
create index idx_name_qq on test12(name, qq);-
- 查询:通过
name查找qq号,可以直接从复合索引中获取数据,无需回表。
- 查询:通过
select qq from test12 where name = '张三';索引创建原则
1. 频繁作为查询条件的字段:应该创建索引。
2. 唯一性太差的字段:不适合单独创建索引,即使频繁作为查询条件。
- 示例:给性别打上索引,但性别只有男和女,构建出的B+树并不优秀。
3. 更新非常频繁的字段:不适合作创建索引。
- 示例:考试信息更改太频繁,索引创建出来是为了方便查询,频繁修改不仅影响数据,还会调整索引结构。
4. 不会出现在 where 子句中的字段:不应创建索引。
- 示例:某些字段从未在
where子句中出现,创建索引没有意义。
适合创建索引:
- 高频读取
- 低频修改
- 唯一性高
- 避免冗余:避免在唯一性差或更新频繁的字段上创建索引。
索引总结
- 主键索引:一个表中最多一个,效率高,值不能为null且不能重复。
- 唯一索引:一个表中可以有多个,查询效率高,值不能重复。
- 普通索引:一个表中可以有多个,适用于有重复值的列。
- 复合索引:将多列值放在一起充当键值,构建B+树,查找时必须满足多列值一致。
3.全文索引
B+树索引:
- 键值字段:通常较短,如
id、qq等。 - 用途:用于快速找到一条记录或记录中的某一列或几列。
全文索引:
- 键值字段:通常较长,如文章内容,每行内容可能包含数千个字符。
- 用途:用于在长文本中查找特定的内容,而不仅仅是找到一条记录。
创建
当对文章字段或有大量文字的字段进行检索时,会使用到全文索引。MySQL提供全文索引机制,但有以下要求:
- 存储引擎:必须是MyISAM。
- 语言支持:默认支持英文,不支持中文。如果需要对中文进行全文检索,可以使用sphinx的中文版(coreseek)。
示例:
CREATE TABLE articles (id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,title VARCHAR(200),body TEXT,FULLTEXT (title, body)
) engine=MyISAM;插入数据:
INSERT INTO articles (title, body) VALUES('MySQL Tutorial', 'DBMS stands for DataBase ...'),('How To Use MySQL Well', 'After you went through a ...'),('Optimizing MySQL', 'In this tutorial we will show ...'),('1001 MySQL Tricks', '1. Never run mysqld as root. 2. ...'),('MySQL vs. YourSQL', 'In the following database comparison ...'),('MySQL Security', 'When configured properly, MySQL ...');查询与全文索引
普通查询:
select * from articles where body like '%database%';- 问题:虽然查询出数据,但没有使用到全文索引。
- 检查:可以使用
explain工具查看查询是否使用了索引。

使用全文索引查询:
select * from articles where match(title, body) against ('database');设置:

match:匹配条件。against:匹配的关键字,这里是database。
检查:
explain select * from articles where match(title, body) against ('database');解释:
type:fulltext表示使用了全文索引。key:表示使用了哪个索引。
总结
- 全文索引:用于在长文本中查找特定内容,特别适用于文章或大量文字的字段。
- 创建:需要使用
FULLTEXT关键字,并且表的存储引擎必须是MyISAM。 - 查询:使用
match和against关键字进行全文索引查询,可以显著提高查询效率。
相关文章:
[MySQL#11] 索引底层(2) | B+树 | 索引的CURD | 全文索引
目录 1.B树的特点 索引结构 复盘 其他数据结构的对比 B树与B树总结 聚簇索引与非聚簇索引 辅助索引 2. 索引操作 主键索引 1. 创建主键索引 第一种方式 第二种方式 第三种方式 2. 查询索引 第一种方法 第二种方法 第三种方法 3. 删除索引 删除主键索引 删除…...

一个指针可以被声明为 `volatile`
一个指针可以被声明为 volatile。当指针被声明为 volatile 时,指针本身的地址值可能会在程序之外的控制下发生变化,这意味着编译器在使用该指针时必须每次都重新从内存中读取它的地址,而不能假设指针的地址保持不变。 为什么指针可以是 vola…...

[0260].第25节:锁的不同角度分类
MySQL学习大纲 我的数据库学习大纲 从不同维度对锁的分类: 1.对数据操作的类型划分:读锁和写锁 1.1.读锁 与 写锁概述: 1.对于数据库中并发事务的读-读情况并不会引起什么问题。对于写-写、读-写或写-读这些情况可能会引起一些问题,需要使用…...

android数组控件Textview
说明:android循环控件,注册和显示内容 效果图: step1: E:\projectgood\resget\demozz\IosDialogDemo-main\app\src\main\java\com\example\iosdialogdemo\TimerActivity.java package com.example.iosdialogdemo;import android.os.Bundl…...

openpnp - 手工修改配置文件(元件高度,size,吸嘴)
文章目录 openpnp - 手工修改配置文件(元件高度,size,吸嘴)概述笔记parts.xmlpackages.xml 手工将已经存在的NT1,NT2拷贝出来改名备注END openpnp - 手工修改配置文件(元件高度,size,吸嘴) 概述 载入新板子贴片准备时,除了引入Named CSV文件,还要在ope…...

Java 集合一口气讲完!(中)d=====( ̄▽ ̄*)b
Java 队列 Java集合教程 - Java队列 队列是只能在其上执行操作的对象的集合两端的队列。 队列有两个末端,称为头和尾。 在简单队列中,对象被添加到尾部并从头部删除并首先删除首先添加的对象。 Java Collections Framework支持以下类型的队列。 简单…...

位运算:计算机科学中的基本操作
深入探讨位运算:计算机科学中的基本操作 位运算是计算机科学中的一种重要工具,它直接作用于数据的二进制位,能够高效地进行数据处理。本文将详细介绍位运算的基本概念、种类以及其实际应用。 什么是位运算? 位运算是对整数的二…...

MPSK(BPSK/QPSK/8PSK)调制解调的Matlab仿真全套
一、概述 MPSK(BPSK、QPSK、8PSK)等是常用的相位调制方式,本文对数据获取、比特流组织、基带调制、上变频发送、添加噪声、接收下变频、基带解调、数据还原等过程进行仿真。 模块化、通用化设计,将函数分为(1)数据读取转比特流;(2)基带调制【参数控制调制类型】;(…...
编写程序)
如何为STM32的EXTI(外部中断)编写程序
要为STM32的EXTI(外部中断)编写程序,你需要遵循以下步骤: 1. 初始化GPIO 首先,需要初始化连接到外部中断线的GPIO引脚。这个引脚需要配置为输入模式,并且根据需要选择上拉、下拉或浮空。 GPIO_InitTypeDe…...
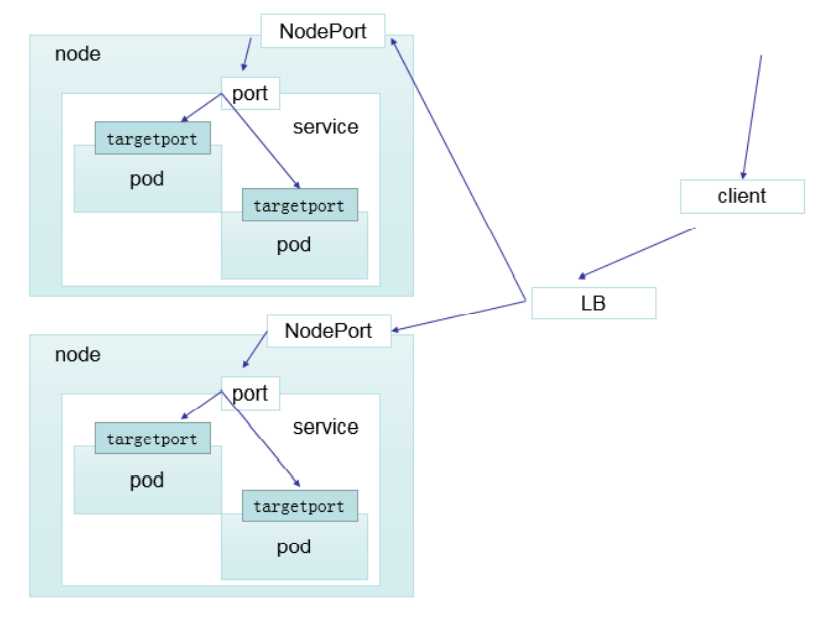
八、快速入门Kubernetes之service
文章目录 Service:one: VIP和Service代理:star: 代理模式分类2、iptables代理模式3、ipvs代理模式 :two: ClusterIP:three:实列Service:four: Headless Service实列:five: NodePort:six: LoadBalancer:seven: ExternalName Service ⭐️ 概念:Kubernetes Service 定…...

JVM 类加载机制详解
JVM 类加载机制详解 在 Java 虚拟机(JVM)中,类加载机制是一个非常重要的组成部分,它负责将类的字节码文件加载到内存中,并进行一系列的处理,最终使类能够被虚拟机使用。本文将详细介绍 JVM 类加载机制的相…...

在 JavaScript 中,`Array.prototype.filter` 方法用于创建一个新数组,该数组包含通过测试的所有元素
文章目录 1、概念在你的代码中的作用示例总结 2、实战3、formattedProducts4、filteredProducts 1、概念 在 JavaScript 中,Array.prototype.filter 方法用于创建一个新数组,该数组包含通过测试的所有元素。具体来说,filter 方法会遍历数组中…...

63 mysql 的 行锁
前言 我们这里来说的就是 我们在 mysql 这边常见的 几种锁 行共享锁, 行排他锁, 表意向共享锁, 表意向排他锁, 表共享锁, 表排他锁 意向共享锁, 意向排他锁, 主要是 为了表粒度的锁获取的同步判断, 提升效率 意向共享锁, 意向排他锁 这边主要的逻辑意义是数据表中是否有任…...

ubuntu文件编辑操作
Vim 基本操作指南 在 vim 中打开文件后,可以按照以下步骤进行编辑和保存: 进入插入模式 打开文件后,默认情况下 vim 处于命令模式,无法直接输入文本。按下 i 键进入插入模式(会看到左下角显示 -- INSERT --࿰…...

Nuxt.js 应用中的 nitro:config 事件钩子详解
title: Nuxt.js 应用中的 nitro:config 事件钩子详解 date: 2024/11/2 updated: 2024/11/2 author: cmdragon excerpt: nitro:config 是 Nuxt 3 中的一个生命周期钩子,允许开发者在初始化 Nitro 之前自定义 Nitro 的配置。Nitro 是 Nuxt 3 的服务器引擎,负责处理请求、渲…...
)
【前端】项目中遇到的问题汇总(长期更新)
一、联调交互类 1、出现一个数据在当前页面进行了修改,另外一个页面的同一数据并未同步更改 当前的数据经过调用接口修改更新以后,if(code 200) 将当前数据存入store.dispatch, 然后另一个地方获取该数据,直接获取存入的数据,这…...

DAY73WEB 攻防-支付逻辑篇篡改属性值并发签约越权盗用算法溢出替换对冲
知识点: 1、支付逻辑-商品本身-修改-数量&价格&属性等 2、支付逻辑-营销折扣-优惠券&积分&签约&试用等 3、支付逻辑-订单接口-替换&并发&状态值&越权支付等 支付逻辑常见测试: 熟悉常见支付流程:选择商品…...

2024 Rust现代实用教程:Ownership与结构体、枚举
文章目录 一、Rust的内存管理模型1.GC(Stop the world)2.C/C内存错误大全3.Rust的内存管理模型 二、String与&str1.String与&str如何选择2.Example 三、枚举与匹配模式1.常见的枚举类型:Option和Result2.匹配模式 四、结构体、方法、…...

MMed-RAG:专为医学视觉语言模型设计的多功能多模态系统
MMed-RAG:专为医学视觉语言模型设计的多功能多模态系统 论文大纲提出背景全流程优化空雨伞分析空:观察现象层雨:分析原因层伞:解决方案层 三问分析WHAT - 问题是什么?WHY - 原因是什么?HOW - 如何解决&…...
)
数据采集(全量采集和增量采集)
全量采集:采集全部数据 3、全量采集 vim students_all.json {"job": {"setting": {"speed": {"channel": 1},"errorLimit": {"record": 0,"percentage": 0.02}},"content": [{…...

Qwen3-TTS-Tokenizer-12Hz快速上手:支持多种音频格式一键处理
Qwen3-TTS-Tokenizer-12Hz快速上手:支持多种音频格式一键处理 1. 认识Qwen3-TTS-Tokenizer-12Hz 1.1 音频编解码器是什么 想象你有一个装满水的桶,想要把它运到远处。直接搬运很费力,但如果把水倒进密封袋里,运输就轻松多了。音…...

基于GTE文本向量的智能应用开发:快速构建文本分析服务
基于GTE文本向量的智能应用开发:快速构建文本分析服务 1. GTE文本向量技术概览 GTE(General Text Embedding)文本向量模型是当前中文自然语言处理领域的重要技术突破。这个基于ModelScope的预训练模型能够将文本转换为高维向量表示…...
Pixel Aurora Engine开发者指南:Diffusers集成与LoRA热加载详解
Pixel Aurora Engine开发者指南:Diffusers集成与LoRA热加载详解 1. 像素极光引擎概述 Pixel Aurora Engine是一款专为像素艺术生成设计的AI绘图工作站,采用复古8-bit游戏风格界面,将现代扩散模型技术与经典像素美学完美结合。这款引擎的核心…...

实战应用:利用快马平台模拟鸿蒙pc版与手机的笔记跨设备同步功能
最近在研究鸿蒙系统的跨设备协同功能,特别是PC端和手机端之间的数据同步场景。作为一个开发者,我很好奇这种分布式能力在实际项目中如何落地。于是我用InsCode(快马)平台快速搭建了一个模拟原型,下面分享下实现思路和过程。 项目整体设计 这个…...

ComfyUI-Manager下载加速终极指南:3倍性能提升实战解析
ComfyUI-Manager下载加速终极指南:3倍性能提升实战解析 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various cust…...

丹青识画系统AI编程辅助:基于代码理解的智能影像处理脚本生成
丹青识画系统AI编程辅助:基于代码理解的智能影像处理脚本生成 最近在折腾一些图像处理的小项目,经常需要写一些重复性的脚本,比如批量调整图片尺寸、识别特定物体轮廓、或者给图片加滤镜。每次都得翻文档、查API,虽然代码不复杂&…...

当数字音频遇见时间魔法:FLAC如何为你的音乐收藏施展无损压缩
当数字音频遇见时间魔法:FLAC如何为你的音乐收藏施展无损压缩 【免费下载链接】flac Free Lossless Audio Codec 项目地址: https://gitcode.com/gh_mirrors/fl/flac 你是否曾为音乐收藏占用过多硬盘空间而烦恼?是否在音质与存储效率之间难以抉择…...

专业解决方案:Windows 11 LTSC系统一键安装微软商店完整指南
专业解决方案:Windows 11 LTSC系统一键安装微软商店完整指南 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore Windows 11 LTSC系统以其卓越…...

如何让Windows播放器支持所有视频格式:终极媒体解码解决方案
如何让Windows播放器支持所有视频格式:终极媒体解码解决方案 【免费下载链接】LAVFilters LAV Filters - Open-Source DirectShow Media Splitter and Decoders 项目地址: https://gitcode.com/gh_mirrors/la/LAVFilters 你是否曾经遇到过这样的烦恼…...
)
别再到处找教程了!Linux服务器上保姆级搭建YApi接口管理平台(含Node.js 12.13.0 + MongoDB 7.0.14配置)
企业级YApi私有化部署实战:从零构建高可用接口管理平台 在数字化转型浪潮中,API已成为企业系统互联的核心纽带。根据Postman 2023年度报告,超过82%的中大型企业正在使用专门的API管理工具来提升开发协作效率。YApi作为国产开源API管理平台的佼…...