基于前馈神经网络模型和卷积神经网络的MINIST数据集训练
目录
前馈神经网络FNN模型
卷积神经网络CNN模型
前馈神经网络FNN模型
'''
@author: lxy
@function: model--mnist
@date : 2024/10/25
@email : 13102790991@163.com
'''# 导入必要的库
import torch
import torch.nn as nn
import torchvision.datasets as dsets
import torchvision.transforms as transforms
from torch.nn.init import normal_,constant_
from torch.autograd import Variable
# 设置超参数
input_size = 784 # 输入层大小,因为MNIST数据集的图片是28x28大小的
hidden_size1 = 128
hidden_size2 = 64
num_class = 10 # 类别数,MNIST数据集有10个数字类别
num_epochs = 10 # 训练的轮数
batch_size = 50 # 每批次的样本数量
learning_rate = 0.01 # 学习率# 准备数据集
# MNIST数据集的加载,包括训练集和测试集
train_dataset = dsets.MNIST(root='./data', train=True,transform=transforms.ToTensor(),download=True)
test_dataset = dsets.MNIST(root='./data', train=False,transform=transforms.ToTensor())# 将数据集封装成DataLoader,方便批量加载和打乱数据
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False)class FNN(nn.Module):def __init__(self, input_size, hidden_size1,hidden_size2,num_classes):super(FNN, self).__init__()self.fc1 = nn.Linear(input_size, hidden_size1) # 隐藏层normal_(self.fc1.weight, mean=0, std=0.01)constant_(self.fc1.bias, val=1.0)self.fc2 = nn.Linear(hidden_size1, hidden_size2) # 隐藏层normal_(self.fc2.weight, mean=0, std=0.01)constant_(self.fc2.bias, val=1.0)self.fc3 = nn.Linear(hidden_size2, num_classes) # 输出层normal_(self.fc3.weight, mean=0, std=0.01)constant_(self.fc3.bias, val=1.0)def forward(self, x):x = torch.relu(self.fc1(x)) # 使用 ReLU 激活函数x = torch.relu(self.fc2(x))out = self.fc3(x)return out# 实例化模型
model = FNN(input_size, hidden_size1,hidden_size2,num_class)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)# 训练模型
for epoch in range(num_epochs): # 遍历所有的epochfor i, (images, labels) in enumerate(train_loader): # 遍历每个批次的数据images = Variable(images.view(-1, 28 * 28)) # 将图片展平labels = Variable(labels)optimizer.zero_grad() # 梯度清零outputs = model(images) # 前向传播loss = criterion(outputs, labels) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新权重if (i + 1) % 100 == 0:print('Epoch: [%d/%d], Step: [%d/%d], Loss: %.4f'% (epoch + 1, num_epochs, i + 1, len(train_loader), loss.item()))print('模型训练完成')# 保存模型权重
torch.save(model.state_dict(), 'model.pkl')
print('模型保存完成')# 测试模型
correct = 0
total = 0
for images, labels in test_loader:images = Variable(images.view(-1, 28 * 28))outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()# 打印测试精度
print(f'模型的精度为:{100 * correct / total:.2f}%')
print('测试完成')运行结果:
Epoch: [1/10], Step: [100/1200], Loss: 2.3350
Epoch: [1/10], Step: [200/1200], Loss: 2.3100
Epoch: [1/10], Step: [300/1200], Loss: 2.2857
Epoch: [1/10], Step: [400/1200], Loss: 2.2872
Epoch: [1/10], Step: [500/1200], Loss: 2.3032
Epoch: [1/10], Step: [600/1200], Loss: 2.3065
Epoch: [1/10], Step: [700/1200], Loss: 2.2811
Epoch: [1/10], Step: [800/1200], Loss: 2.3087
Epoch: [1/10], Step: [900/1200], Loss: 2.2884
Epoch: [1/10], Step: [1000/1200], Loss: 2.3137
Epoch: [1/10], Step: [1100/1200], Loss: 2.2961
Epoch: [1/10], Step: [1200/1200], Loss: 2.3011
Epoch: [2/10], Step: [100/1200], Loss: 2.2949
Epoch: [2/10], Step: [200/1200], Loss: 2.3026
Epoch: [2/10], Step: [300/1200], Loss: 2.2837
Epoch: [2/10], Step: [400/1200], Loss: 2.2555
Epoch: [2/10], Step: [500/1200], Loss: 2.2819
Epoch: [2/10], Step: [600/1200], Loss: 2.2609
Epoch: [2/10], Step: [700/1200], Loss: 2.2413
Epoch: [2/10], Step: [800/1200], Loss: 2.1767
Epoch: [2/10], Step: [900/1200], Loss: 1.9502
Epoch: [2/10], Step: [1000/1200], Loss: 1.9029
Epoch: [2/10], Step: [1100/1200], Loss: 1.5652
Epoch: [2/10], Step: [1200/1200], Loss: 1.4752
Epoch: [3/10], Step: [100/1200], Loss: 1.3914
Epoch: [3/10], Step: [200/1200], Loss: 1.2248
Epoch: [3/10], Step: [300/1200], Loss: 1.2547
Epoch: [3/10], Step: [400/1200], Loss: 1.0720
Epoch: [3/10], Step: [500/1200], Loss: 0.8522
Epoch: [3/10], Step: [600/1200], Loss: 1.0576
Epoch: [3/10], Step: [700/1200], Loss: 0.8513
Epoch: [3/10], Step: [800/1200], Loss: 0.7558
Epoch: [3/10], Step: [900/1200], Loss: 0.8906
Epoch: [3/10], Step: [1000/1200], Loss: 0.6811
Epoch: [3/10], Step: [1100/1200], Loss: 0.7370
Epoch: [3/10], Step: [1200/1200], Loss: 0.7120
Epoch: [4/10], Step: [100/1200], Loss: 0.7183
Epoch: [4/10], Step: [200/1200], Loss: 0.6526
Epoch: [4/10], Step: [300/1200], Loss: 1.0557
Epoch: [4/10], Step: [400/1200], Loss: 0.9142
Epoch: [4/10], Step: [500/1200], Loss: 0.6779
Epoch: [4/10], Step: [600/1200], Loss: 0.4618
Epoch: [4/10], Step: [700/1200], Loss: 0.9941
Epoch: [4/10], Step: [800/1200], Loss: 0.6586
Epoch: [4/10], Step: [900/1200], Loss: 0.8161
Epoch: [4/10], Step: [1000/1200], Loss: 0.4814
Epoch: [4/10], Step: [1100/1200], Loss: 0.7023
Epoch: [4/10], Step: [1200/1200], Loss: 0.5938
Epoch: [5/10], Step: [100/1200], Loss: 0.5277
Epoch: [5/10], Step: [200/1200], Loss: 0.6421
Epoch: [5/10], Step: [300/1200], Loss: 0.6591
Epoch: [5/10], Step: [400/1200], Loss: 0.7547
Epoch: [5/10], Step: [500/1200], Loss: 0.5321
Epoch: [5/10], Step: [600/1200], Loss: 0.7591
Epoch: [5/10], Step: [700/1200], Loss: 0.8456
Epoch: [5/10], Step: [800/1200], Loss: 0.4955
Epoch: [5/10], Step: [900/1200], Loss: 0.6119
Epoch: [5/10], Step: [1000/1200], Loss: 0.4185
Epoch: [5/10], Step: [1100/1200], Loss: 0.7572
Epoch: [5/10], Step: [1200/1200], Loss: 0.3567
Epoch: [6/10], Step: [100/1200], Loss: 0.4471
Epoch: [6/10], Step: [200/1200], Loss: 0.4590
Epoch: [6/10], Step: [300/1200], Loss: 0.5883
Epoch: [6/10], Step: [400/1200], Loss: 0.7611
Epoch: [6/10], Step: [500/1200], Loss: 0.3657
Epoch: [6/10], Step: [600/1200], Loss: 0.4927
Epoch: [6/10], Step: [700/1200], Loss: 0.3680
Epoch: [6/10], Step: [800/1200], Loss: 0.5498
Epoch: [6/10], Step: [900/1200], Loss: 0.2330
Epoch: [6/10], Step: [1000/1200], Loss: 0.4561
Epoch: [6/10], Step: [1100/1200], Loss: 0.4381
Epoch: [6/10], Step: [1200/1200], Loss: 0.5882
Epoch: [7/10], Step: [100/1200], Loss: 0.2238
Epoch: [7/10], Step: [200/1200], Loss: 0.1837
Epoch: [7/10], Step: [300/1200], Loss: 0.3769
Epoch: [7/10], Step: [400/1200], Loss: 0.2923
Epoch: [7/10], Step: [500/1200], Loss: 0.3122
Epoch: [7/10], Step: [600/1200], Loss: 0.3876
Epoch: [7/10], Step: [700/1200], Loss: 0.4610
Epoch: [7/10], Step: [800/1200], Loss: 0.2549
Epoch: [7/10], Step: [900/1200], Loss: 0.3639
Epoch: [7/10], Step: [1000/1200], Loss: 0.5007
Epoch: [7/10], Step: [1100/1200], Loss: 0.4893
Epoch: [7/10], Step: [1200/1200], Loss: 0.3306
Epoch: [8/10], Step: [100/1200], Loss: 0.3167
Epoch: [8/10], Step: [200/1200], Loss: 0.5069
Epoch: [8/10], Step: [300/1200], Loss: 0.2262
Epoch: [8/10], Step: [400/1200], Loss: 0.3192
Epoch: [8/10], Step: [500/1200], Loss: 0.3022
Epoch: [8/10], Step: [600/1200], Loss: 0.3831
Epoch: [8/10], Step: [700/1200], Loss: 0.3850
Epoch: [8/10], Step: [800/1200], Loss: 0.2427
Epoch: [8/10], Step: [900/1200], Loss: 0.2228
Epoch: [8/10], Step: [1000/1200], Loss: 0.5374
Epoch: [8/10], Step: [1100/1200], Loss: 0.2917
Epoch: [8/10], Step: [1200/1200], Loss: 0.2410
Epoch: [9/10], Step: [100/1200], Loss: 0.2362
Epoch: [9/10], Step: [200/1200], Loss: 0.6535
Epoch: [9/10], Step: [300/1200], Loss: 0.4043
Epoch: [9/10], Step: [400/1200], Loss: 0.1589
Epoch: [9/10], Step: [500/1200], Loss: 0.2606
Epoch: [9/10], Step: [600/1200], Loss: 0.3407
Epoch: [9/10], Step: [700/1200], Loss: 0.4839
Epoch: [9/10], Step: [800/1200], Loss: 0.3456
Epoch: [9/10], Step: [900/1200], Loss: 0.2724
Epoch: [9/10], Step: [1000/1200], Loss: 0.3831
Epoch: [9/10], Step: [1100/1200], Loss: 0.2052
Epoch: [9/10], Step: [1200/1200], Loss: 0.4371
Epoch: [10/10], Step: [100/1200], Loss: 0.3577
Epoch: [10/10], Step: [200/1200], Loss: 0.5289
Epoch: [10/10], Step: [300/1200], Loss: 0.3724
Epoch: [10/10], Step: [400/1200], Loss: 0.6010
Epoch: [10/10], Step: [500/1200], Loss: 0.4006
Epoch: [10/10], Step: [600/1200], Loss: 0.2830
Epoch: [10/10], Step: [700/1200], Loss: 0.4382
Epoch: [10/10], Step: [800/1200], Loss: 0.2223
Epoch: [10/10], Step: [900/1200], Loss: 0.4305
Epoch: [10/10], Step: [1000/1200], Loss: 0.3229
Epoch: [10/10], Step: [1100/1200], Loss: 0.2160
Epoch: [10/10], Step: [1200/1200], Loss: 0.2330
模型训练完成
模型保存完成
模型的精度为:91.00%
测试完成Process finished with exit code 0
数据集处理部分:
1、数据存储路径(root='./data')。如果本地没有数据集文件,download=True 将从网上下载 MNIST 数据集,并保存到指定路径。
2、
- train=True 和 train=False 参数分别加载训练集和测试集。
- 这将 MNIST 数据集自动划分成两个独立的数据集:一个用于模型训练(训练集),一个用于模型评估(测试集)
3、transform=transforms.ToTensor() 将图像数据从 PIL 图像或 NumPy 数组格式转换为 PyTorch 张量,还会将图像的像素值从 [0, 255] 归一化为 [0, 1] 的范围
transforms.ToTensor()和归一化函数transforms.Normalize()的使用
Pytorch的torch.utils.data中Dataset以及DataLoader等详解
模型训练部分:
梯度清零optimizer.zero_grad()-->前向传播outputs = model(images) --->计算损失loss = criterion(outputs, labels) --->反向传播误差loss.backward()---->更新权重optimizer.step()
通过 enumerate() 可以同时获取批次的索引 i 和数据 images, labels
enumerate函数深度剖析
_, predicted = torch.max(outputs.data, 1)中需要注意:
1、max括号内的第二个参数1是指定了要沿着哪个维度寻找最大值。在这里,表示沿着每个样本的类别输出维度,最后函数返回两个值:预测类别输出的概率最大值和对应的索引。
2、_是一个惯用的占位符,用于忽略函数返回的第一个值(即最大值本身),只保留了预测的类别索引。
卷积神经网络CNN模型
'''
@author: lxy
@function: minist recognition based in CNN model
@date : 2024/10/29
'''
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoaderclass CNN_minist(nn.Module):def __init__(self):super(CNN_minist, self).__init__()# 第一个卷积模块self.conv1 = nn.Sequential(# 卷积层nn.Conv2d(in_channels=1, # 输入通道数(灰度图像为1)out_channels=16, # 输出通道数(卷积核数量)kernel_size=5, # 卷积核的大小stride=1, # 卷积步长padding=2 # 填充,使得输出与输入的宽高相同),nn.ReLU(), # 激活函数,增加非线性nn.MaxPool2d(kernel_size=2) # 最大池化层,减小特征图尺寸)# 第二个卷积模块self.conv2 = nn.Sequential(nn.Conv2d(16, 32, 5, 1, 2), # 输入通道数为16,输出通道数为32nn.ReLU(), # 激活函数nn.MaxPool2d(2) # 最大池化层)'''原始图像像素:28*28*1经过第一个卷积层: 28*28*16(填充Padding为2)经过第一个池化层:14*14*16经过第二个卷积层:14*14*32经过第二个池化层:7*7*32'''# 全连接层,输入为7*7*32,输出为10(分类数)self.out = nn.Linear(7 * 7 * 32, 10)def forward(self, x: torch.Tensor):# 前向传播过程x = self.conv1(x) # 经过第一个卷积模块x = self.conv2(x) # 经过第二个卷积模块x = x.view(x.size(0), -1) # 将特征图展平为一维output = self.out(x) # 通过全连接层得到输出return outputdef start():input_size = 28 # 输入图像的尺寸为28x28num_classes = 10 # 标签类别数量(数字0-9)num_epochs = 3 # 训练的总轮数batch_size = 64 # 每个批次的样本数量# 下载和加载训练集train_dataset = datasets.MNIST(root='./data',train=True, # 使用训练集transform=transforms.ToTensor(), # 转换为Tensor格式download=True) # 下载数据集# 下载和加载测试集test_dataset = datasets.MNIST(root='./data',train=False, # 使用测试集transform=transforms.ToTensor(), # 转换为Tensor格式download=True) # 下载数据集# 构建训练和测试的批量数据加载器train_loader = DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True) # 打乱训练数据test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size,shuffle=False) # 测试数据不打乱myModel = CNN_minist() # 实例化模型criterion = nn.CrossEntropyLoss() # 选择交叉熵损失作为损失函数optimizer = optim.Adam(myModel.parameters(), lr=0.001) # 选择Adam优化器# 开始训练for epoch in range(num_epochs):for idx, data in enumerate(train_loader):inputs, labels = data # 获取输入数据和标签myModel.train() # 设置模型为训练模式optimizer.zero_grad() # 梯度归零,防止累加outputs = myModel(inputs) # 前向传播,得到模型输出loss = criterion(outputs, labels) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新模型参数# 每100步输出一次损失if (idx + 1) % 100 == 0:print('Epoch: [%d/%d], Step: [%d/%d], Loss: %.4f'% (epoch + 1, num_epochs, idx + 1, len(train_loader), loss.item()))print('模型训练完成')# 测试模型correct = 0 # 正确预测的数量total = 0 # 总预测数量with torch.no_grad(): # 关闭梯度计算for inputs, labels in test_loader:outputs = myModel(inputs) # 前向传播得到输出_, predicted = torch.max(outputs.data, 1) # 预测结果total += labels.size(0) # 更新总样本数correct += (predicted == labels).sum().item() # 统计正确预测的数量# 打印模型在测试集上的精度print(f'模型的精度为:{100 * correct / total:.2f}%')print('测试完成')# 启动训练和测试过程
start()
Epoch: [1/3], Step: [100/938], Loss: 0.1791
Epoch: [1/3], Step: [200/938], Loss: 0.1613
Epoch: [1/3], Step: [300/938], Loss: 0.1663
Epoch: [1/3], Step: [400/938], Loss: 0.0369
Epoch: [1/3], Step: [500/938], Loss: 0.1555
Epoch: [1/3], Step: [600/938], Loss: 0.2144
Epoch: [1/3], Step: [700/938], Loss: 0.1035
Epoch: [1/3], Step: [800/938], Loss: 0.0371
Epoch: [1/3], Step: [900/938], Loss: 0.0677
Epoch: [2/3], Step: [100/938], Loss: 0.0502
Epoch: [2/3], Step: [200/938], Loss: 0.1408
Epoch: [2/3], Step: [300/938], Loss: 0.0790
Epoch: [2/3], Step: [400/938], Loss: 0.1037
Epoch: [2/3], Step: [500/938], Loss: 0.0250
Epoch: [2/3], Step: [600/938], Loss: 0.0199
Epoch: [2/3], Step: [700/938], Loss: 0.0180
Epoch: [2/3], Step: [800/938], Loss: 0.0766
Epoch: [2/3], Step: [900/938], Loss: 0.0188
Epoch: [3/3], Step: [100/938], Loss: 0.0366
Epoch: [3/3], Step: [200/938], Loss: 0.0248
Epoch: [3/3], Step: [300/938], Loss: 0.0155
Epoch: [3/3], Step: [400/938], Loss: 0.0330
Epoch: [3/3], Step: [500/938], Loss: 0.0067
Epoch: [3/3], Step: [600/938], Loss: 0.0412
Epoch: [3/3], Step: [700/938], Loss: 0.0165
Epoch: [3/3], Step: [800/938], Loss: 0.0459
Epoch: [3/3], Step: [900/938], Loss: 0.1818
模型训练完成
模型的精度为:98.97%
测试完成模型构建部分
在 PyTorch 中,Sequential 是一个方便的容器,用于将多个层(layer)按顺序组合在一起,形成一个简单的神经网络模型。使用 Sequential 可以让我们以更简洁的方式定义模型结构,而不需要显式地编写 forward 方法。
EG:
import torch import torch.nn as nn import torch.optim as optim import torchvision.transforms as transforms from torchvision import datasets# 定义一个简单的卷积神经网络 class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.model = nn.Sequential(nn.Conv2d(1, 16, kernel_size=3, padding=1), # 输入1个通道,输出16个通道nn.ReLU(),nn.MaxPool2d(kernel_size=2), # 最大池化nn.Conv2d(16, 32, kernel_size=3, padding=1), # 输入16个通道,输出32个通道nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Flatten(), # 展平nn.Linear(32 * 7 * 7, 10) # 输入特征为32*7*7,输出为10个类别)def forward(self, x):return self.model(x)# 实例化模型 model = SimpleCNN()# 打印模型结构 print(model)Sequential的使用和搭建实战可见输出与sequential内容一致
SimpleCNN((model): Sequential((0): Conv2d(1, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU()(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(3): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): ReLU()(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(6): Flatten(start_dim=1, end_dim=-1)(7): Linear(in_features=1568, out_features=10, bias=True)) )Process finished with exit code 0Sequential的使用和搭建实战
相关文章:

基于前馈神经网络模型和卷积神经网络的MINIST数据集训练
目录 前馈神经网络FNN模型 卷积神经网络CNN模型 前馈神经网络FNN模型 author: lxy function: model--mnist date : 2024/10/25 email : 13102790991163.com # 导入必要的库 import torch import torch.nn as nn import torchvision.datasets as dsets import torchvision.t…...

Vue3中Element Plus==el-eialog弹框中的input无法获取表单焦点
有弹框情况下 <template> <input ref"input" /> </template> <script setup> import { ref, onMounted } from vue // 声明一个 ref 来存放该元素的引用 // 必须和模板里的 ref 同名 const input ref(null) onMounted(() > { ne…...

16.网工入门篇--------介绍下网络服务及应用
一、网络服务的概念 网络服务是指通过网络提供的软件功能或设施,它允许不同的设备和用户在网络环境中进行信息交换、资源共享和协作。这些服务基于各种网络协议,以实现高效、可靠的通信。 二、常见网络服务类型 (一)文件传输服务 …...

区分 electron 全屏和最大化
一. 全屏 在 Electron 中,当窗口处于全屏状态时,通常不能直接使用 JavaScript 来改变窗口大小。这是出于安全和用户体验的考虑,以防止意外的窗口大小变化影响全屏体验。 1. 退出全屏后再调整大小 检测全屏状态,退出全屏并调整大…...
)
封装一个请求的hook(react函数组件)
对于后台系统,上面筛选,下面表格分页的页面,这个hook非常实用 omitBy方法:过滤不为undefined的对象属性 export const omitBy <T extends IObject, K extends keyof T>(object:T, predicate:(value:T[K]) > boolean):I…...
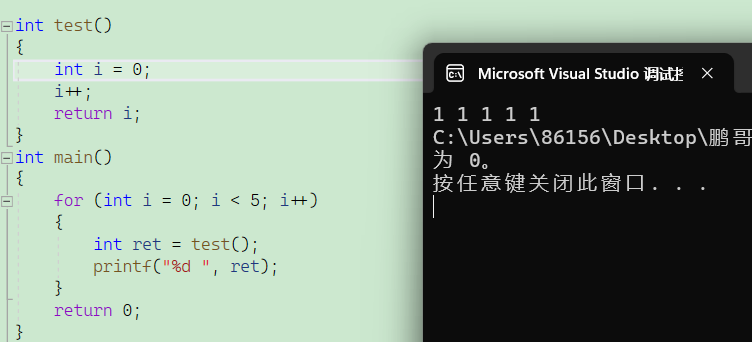
c语言内存块讲解
文章目录 前言一、栈区1、栈区的特点:1.1 自动管理1.2 后进先出1.3 有限大小1.4 高速访问1.5 栈区存储方向 2、栈区使用注意事项 二、堆区1、堆区的定义2、堆区的特点3、堆区的内存分配与释放4、注意事项: 三、全局/静态存储区1、全局存储区1.1 全局变量…...

2024年10月23日Github流行趋势
项目名称:hiteshchoudhary / apihub 项目维护者:wajeshubham, atulbhatt-system32, jwala-anirudh, arnb-smnta, shrey-dadhaniya 项目介绍:您自己的API Hub,用于学习和掌握API交互。非常适合前端、移动开发人员和后端开发人员。 …...
YOLOv6-4.0部分代码阅读笔记-dbb_transforms.py
dbb_transforms.py yolov6\layers\dbb_transforms.py 目录 dbb_transforms.py 1.所需的库和模块 2.def transI_fusebn(kernel, bn): 3.def transII_addbranch(kernels, biases): 4.def transIII_1x1_kxk(k1, b1, k2, b2, groups): 5.def transIV_depthconcat(kernel…...
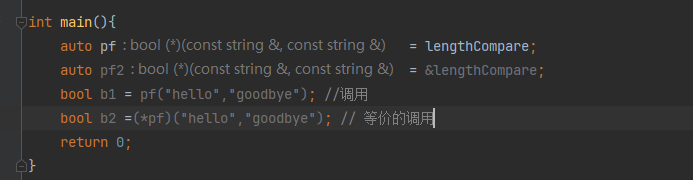
C++ 基础语法 一
C 基础语法 一 文章目录 C 基础语法 一const 限定符常量指针类型别名autodecltypeQStringvector迭代器指针和数组显示转换static_castconst_cast 函数尽量使用常量引用数组形参不要返回局部对象的引用和指针返回数组指针 C四种转换内联函数constexpr函数函数指针 const 限定符 …...

B2020 分糖果
题目描述 某个幼儿园里,有 55 位小朋友编号依次为 1,2,3,4,51,2,3,4,5 他们按照自己的编号顺序围坐在一张圆桌旁。他们身上有若干糖果,现在他们玩一个分糖果游戏。从 11 号小朋友开始,将自己的糖果均分成 33 份(如果有多余的糖果…...
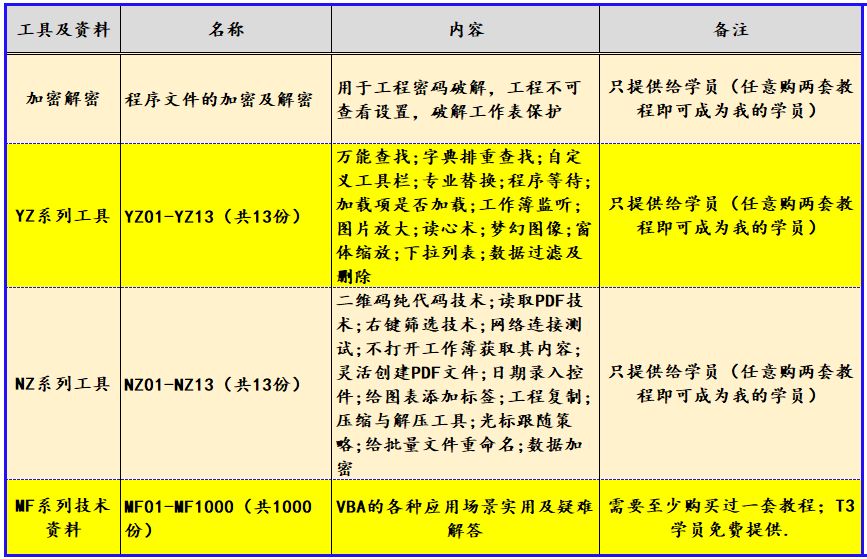
VBA字典与数组第二十讲:如何在代码运行时创建数组
《VBA数组与字典方案》教程(10144533)是我推出的第三套教程,目前已经是第二版修订了。这套教程定位于中级,字典是VBA的精华,我要求学员必学。7.1.3.9教程和手册掌握后,可以解决大多数工作中遇到的实际问题。…...

字符串统计(Python)
接收键盘任意录入,分别统计大小写字母、数字及其它字符数量,打印输出。 (笔记模板由python脚本于2024年11月02日 08:23:31创建,本篇笔记适合熟悉python字符串并懂得基本编程技法的coder翻阅) 【学习的细节是欢悦的历程】 Python 官网…...

NVR小程序接入平台/设备EasyNVR多个NVR同时管理视频监控新选择
在数字化转型的浪潮中,视频监控作为安防领域的核心组成部分,正经历着前所未有的技术革新。随着技术的不断进步和应用场景的不断拓展,视频监控系统的兼容性、稳定性以及安全性成为了用户关注的焦点。NVR小程序接入平台/设备EasyNVR,…...
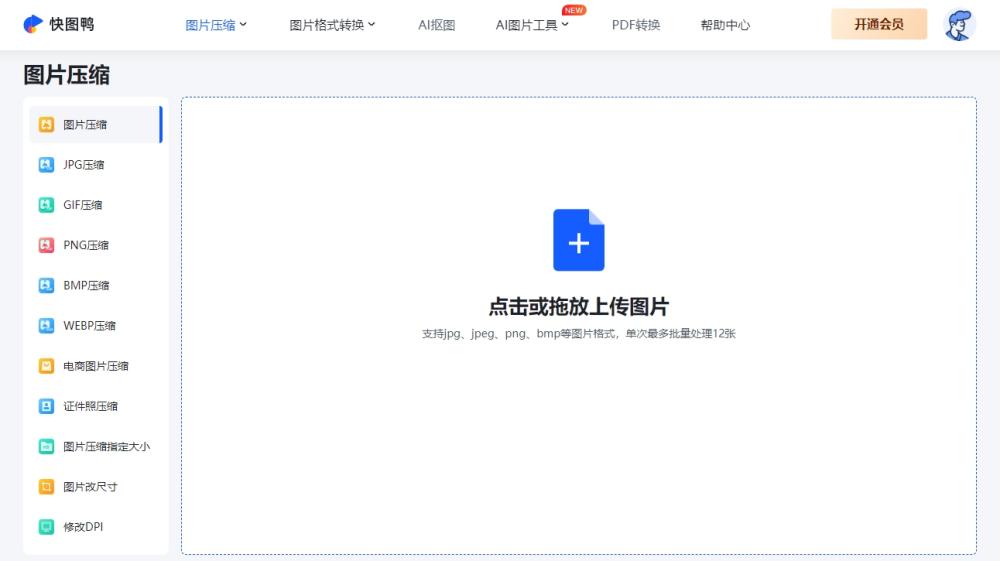
怎样能把图片做压缩处理?学会4款在线工具高效压缩图片
随着现在图片质量不断的提高,导致图片的大小也越来越大,很多的网上平台只能上传比较小的图片,那么可以使用压缩图片或者图片改尺寸的方式来修改图片大小,那么图片压缩的操作技巧是什么样的呢?本文将带大家了解4个操作简…...

ZooKeeper 客户端API操作
文章目录 一、节点信息1、创建节点2、获取子节点并监听节点变化3、判断节点是否存在4、客户端向服务端写入数据写入请求直接发给 Leader 节点写入请求直接发给 follow 节点 二、服务器动态上下线监听1、监听过程2、代码 三、分布式锁1、什么是分布式锁?2、Curator 框架实现分布…...
-限幅滤波法)
常用滤波算法(一)-限幅滤波法
文章目录 一、限幅滤波法原理二、C语言实现限幅滤波法三、代码解析定义限制值:限幅滤波函数:模拟获取新数据:主函数: 四、结论 限幅滤波法 限幅滤波法,作为一种简单而有效的滤波方法,通过限制信号的幅值范围…...

江协科技STM32学习- P33 实验-软件I2C读写MPU6050
🚀write in front🚀 🔎大家好,我是黄桃罐头,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝…...
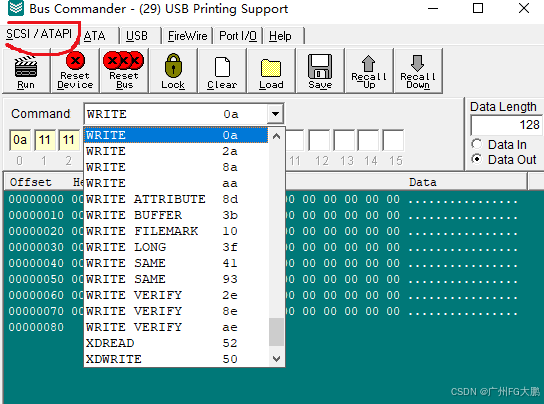
BusHound工具的使用-调试USB
12 1.Capture(捕捉按钮)、2.Save(保存按钮)、3.Setting(设置要监听的,输入输出)、4.Device(选择要监听的设备)、5.Help(帮助按钮)、6.Exit(退出按钮)。 一、Capture页面 1.Device 表示是29设备端口,打印机。 2.Phase,各类协议,…...

Hadoop生态圈框架部署(四)- Hadoop完全分布式部署
文章目录 前言一、Hadoop完全分布式部署(手动部署)1. 下载hadoop2. 上传安装包2. 解压hadoop安装包3. 配置hadoop配置文件3.1 虚拟机hadoop1修改hadoop配置文件3.1.1 修改 hadoop-env.sh 配置文件3.3.2 修改 core-site.xml 配置文件3.3.3 修改 hdfs-site…...

Spring Boot 与 Vue 共铸卓越采购管理新平台
作者介绍:✌️大厂全栈码农|毕设实战开发,专注于大学生项目实战开发、讲解和毕业答疑辅导。 🍅获取源码联系方式请查看文末🍅 推荐订阅精彩专栏 👇🏻 避免错过下次更新 Springboot项目精选实战案例 更多项目…...

支付系统架构设计:从交易核心到资金核算的稳定性实践
1. 支付系统总览:从业务到资金的桥梁但凡涉及在线交易的公司,支付系统都是其技术架构中当之无愧的“心脏”。它远不止是调用一个第三方支付接口那么简单,而是一套连接用户、业务、资金渠道和内部账务的复杂工程体系。一个设计得当的支付系统&…...

[2026最新版] 保姆级 Burp Suite 安装教程
在Windows上安装教程如下: 文件下载:点我下载(NAS分享链接,若链接过期或无法下载,请联系作者:zeyun4699gmail.com) 步骤一:下载来自我上传的文件(你会得到步骤二的图片…...

网站推广新纪元:品牌100工程引领下的精准引流与高效转化
在数字化转型的浪潮中,72%的企业网站上线后却陷入了“无人问津”的尴尬境地。缺乏系统的推广策略,仅31%的企业能通过科学推广实现流量与转化双提升。品牌100工程在深度陪跑实践中发现,2026年的网站推广已告别“盲目投放”时代,更注…...

OpenWebUI智能管道:连接本地AI模型与高性能推理后端
1. 项目概述:一个连接OpenWebUI与本地AI模型的智能管道最近在折腾本地大语言模型(LLM)的朋友,估计都绕不开OpenWebUI(原名Ollama WebUI)这个项目。它提供了一个极其美观、功能强大的Web界面,让我…...

Manus开源框架:高效探索与开发灵巧手抓取技能
1. 项目概述与核心价值最近在机器人抓取领域,一个名为“Manus Open Claw Skill Hunter and Developer”的项目引起了我的注意。这个项目由Simplio Labs开源,它不是一个具体的硬件爪子,也不是一个单一的算法,而是一个专门用于发现、…...

零基础转行信息安全,老师傅来支招
现在这个环境下,转行做信息安全的人已经越来越少了,但还是有热爱这一行的人。 今天,我们以零基础入行为例,按照下面的成长路径,来分析分析从2025年的招聘数据来看,需要哪些能力。 对零基础转行的人来说&a…...

Harness层加密传输:Agent通信安全
Harness层加密传输:Agent通信安全 标题选项 《CI/CD管道的“隐形长城”:深入Harness Agent通信全链路加密传输机制》《从握手到数据:拆解Harness云原生平台Agent-Manager层加密传输的核心原理与实践》《DevOps安全必知:Harness如…...

终极代码阅读神器:MultiHighlight智能高亮插件完整指南
终极代码阅读神器:MultiHighlight智能高亮插件完整指南 【免费下载链接】MultiHighlight Jetbrains IDE plugin: highlight identifiers with custom colors 🎨💡 项目地址: https://gitcode.com/gh_mirrors/mu/MultiHighlight 你是否…...

3步掌握N_m3u8DL-CLI-SimpleG:让M3U8视频下载变得像复制粘贴一样简单
3步掌握N_m3u8DL-CLI-SimpleG:让M3U8视频下载变得像复制粘贴一样简单 【免费下载链接】N_m3u8DL-CLI-SimpleG N_m3u8DL-CLIs simple GUI 项目地址: https://gitcode.com/gh_mirrors/nm3/N_m3u8DL-CLI-SimpleG 在数字内容日益丰富的今天,M3U8格式视…...

【Nanobot】README09_LEVEL4 添加新聊天渠道
【Nanobot】README09_LEVEL4 添加新聊天渠道 源码地址:https://github.com/HKUDS/nanobot 🎯 目标 指导如何为 nanobot 添加新的聊天渠道(如 Signal、Matrix、Line 等)。 📋 添加新 Channel 的步骤 步骤 1࿱…...