【大数据学习 | kafka】producer的参数与结构
1. producer的结构

producer:生产者
它由三个部分组成
interceptor:拦截器,能拦截到数据,处理完毕以后发送给下游,它和过滤器不同并不是丢弃数据,而是将数据处理完毕再次发送出去,这个默认是不存在的
serialiazer:序列化器,kafka中存储的数据是二进制的,所以数据必须经过序列化器进行处理,这个是必须要有的,将用户的数据转换为byte[]的工具类,其中k和v要分别指定
partitioner: 分区器,主要是控制发送的数据到topic的哪个分区中,这个默认也是存在的
record accumulator
本地缓冲累加器 默认32M
producer的数据不能直接发送到kafka集群中,因为producer和kafka集群并不在一起,远程发送的数据不是一次发送一条这样太影响发送的速度和性能,所以我们发送都是攒一批数据发一次,record accumulator就是一个本地缓冲区,producer将发送的数据放入到缓冲区中,另外一个线程会去拉取其中的数据,远程发送给kafka集群,这个异步线程会根据linger.ms和batch-size进行拉取数据。如果本地累加器中的数据达到batch-size或者是linger.ms的大小阈值就会拉取数据到kafka集群中,这个本地缓冲区不仅仅可以适配两端的效率,还可以批次形式执行任务,增加效率
batch-size 默认16KB
linger.ms 默认为0
生产者部分的整体流程
首先producer将发送的数据准备好
经过interceptor的拦截器进行处理,如果有的话
然后经过序列化器进行转换为相应的byte[]
经过partitioner分区器分类在本地的record accumulator中缓冲
sender线程会自动根据linger.ms和batch-size双指标进行管控,复制数据到kafka
2. producer的简单代码
2.1 准备:
引入maven依赖:
<dependencies><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.3.2</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.30</version></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency>
</dependencies>在resources文件中创建log4j.properties
log4j.rootLogger=info,console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c %M(): %m%n2.2 生产者中的设定参数
| 参数 | 含义 |
|---|---|
| bootstrap.servers | kafka集群的地址 |
| key.serializer | key的序列化器,这个序列化器必须和key的类型匹配 |
| value.serializer | value的序列化器,这个序列化器必须和value的类型匹配 |
| batch.size | 批次拉取大小默认是16KB |
| linger.ms | 拉取的间隔时间默认为0,没有延迟 |
| partitioner | 分区器存在默认值 |
| interceptor | 拦截器选的 |
2.3 全部代码
public class producer_test {public static void main(String[] args) {Properties pro = new Properties();pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop106:9092");//设定集群地址pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());//设定两个序列化器,其中StringSerializer是系统自带的序列化器,要和数据的类型完全一致pro.put(ProducerConfig.BATCH_SIZE_CONFIG, 16*1024);//batch-size默认是16KB,参数的单位是bytepro.put(ProducerConfig.LINGER_MS_CONFIG, 0);//默认等待批次时长是0KafkaProducer<String, String> producer = new KafkaProducer<String, String>(pro);ProducerRecord<String, String> record = new ProducerRecord<>("topic_a", "this is hainiu");//发送数据的时候有kv两个部分,但是一般k我们什么都不放,只放value的值producer.send(record);producer.close();}
}
在x-shell中观察消费的数据

相关文章:
【大数据学习 | kafka】producer的参数与结构
1. producer的结构 producer:生产者 它由三个部分组成 interceptor:拦截器,能拦截到数据,处理完毕以后发送给下游,它和过滤器不同并不是丢弃数据,而是将数据处理完毕再次发送出去,这个默认是不…...
2. 从服务器的主接口入手
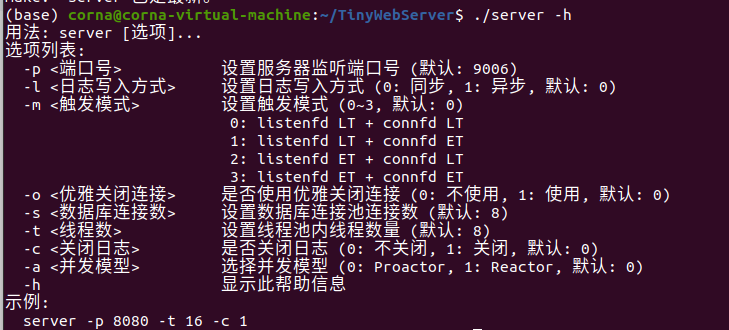
Webserver 的主函数 main.cpp,完成了哪些功能? #include "config.h"int main(int argc, char *argv[]) {string user "";string passwd "";string databasename "";Config config;config.parse_arg(argc, a…...

nginx上传文件超过限制大小、响应超时、反向代理请求超时等问题解决
1、文件大小超过限制 相关配置: client_max_body_size: Syntax:client_max_body_size size;Default:client_max_body_size 1m;Context:http, server, location 2、连接超时: proxy_read_timeout: Syntax:proxy_read_timeout time;Default…...

第16课 核心函数(方法)
掌握常用的内置函数及其用法。 数学类函数:abs、divmod、max、min、pow、round、sum。 类型转换函数:bool、int、float、str、ord、chr、bin、hex、tuple、list、dict、set、enumerate、range、object。 序列操作函数:all、any、filter、m…...

【工具变量】中国制造2025试点城市数据集(2000-2023年)
数据简介:《中国制造2025》是中国ZF于2015年5月8日印发的一项战略规划,旨在加快制造业的转型升级,提升制造业的质量和效益,实现从制造大国向制造强国的转变。该规划是中国实施制造强国战略的第一个十年行动纲领,明确提…...
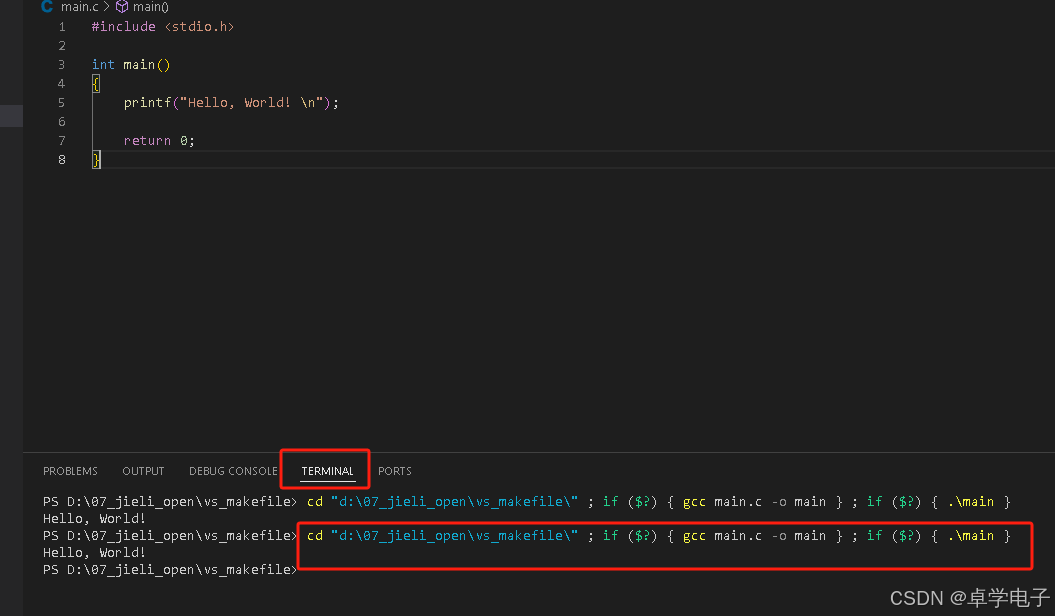
vscode makfile编译
MinGW-w64下载安装 为了在 Windows 上安装 GCC,您需要安装 MinGW-w64。 MinGW-w64 是一个开源项目,它为 Windows 系统提供了一个完整的 GCC 工具链,支持编译生成 32 位和 64 位的 Windows 应用程序。 访问 MinGW-w64 的主页 mingw-w64.org…...
PostgreSQL数据库操作示例)
(四)PostgreSQL数据库操作示例
删除有外键约束的表 最近做数据库练习遇到一个问题,数据库里面有一个表,存在外键约束,我想要删除,所以必须先删除这些外键约束。 查询外键约束 查找外键约束:当你需要知道某个表的外键约束及其引用关系时࿰…...

Docker-微服务项目部署
环境准备 1.微服务项目 参考:通过网盘分享的文件:wolf2w_cloud.zip 链接: https://pan.baidu.com/s/1Lr4k6LPIJ59gVNA_DgKM_Q?pwdkjxt 提取码: kjxt 前端项目:trip-mgrsite-ui,trip-website-ui,trip-wenda-ui 服务项…...

测试Bug提交报告模板
撰写测试Bug提交说明时,清晰、详细和准确是至关重要的。这有助于开发团队快速理解问题、重现Bug并修复它。以下是一个测试Bug提交说明的模板,可以根据实际情况进行调整: 测试Bug提交说明 1. Bug基本信息 Bug编号:[系统自动生成…...

MybatisPlus - 核心功能
文章目录 1.MybatisPlus实现基本的CRUD快速开始常见注解常见配置 2.使用条件构建造器构建查询和更新语句条件构造器自定义SQLService接口 官网 MybatisPlus无侵入和方便快捷. MybatisPlus不仅仅可以简化单表操作,而且还对Mybatis的功能有很多的增强。可以让我们的开…...
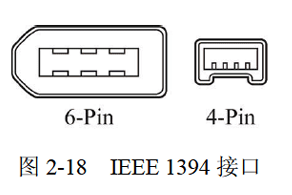
小柴冲刺软考中级嵌入式系统设计师系列二、嵌入式系统硬件基础知识(6)嵌入式系统总线及通信接口
目录 越努力,越幸运! flechazo 小柴冲刺软考中级嵌入式系统设计师系列总目录 一、PCI、PCI-E 等接口基本原理与结构 1、PCI (1)高速性。 (2)即插即用性。 (3)可靠性。 (4)复杂性。 (5)自动配置。 (6)共享中断。 (7)扩展性好。 (8)多路复用。…...

利用字典对归一化后的数据0误差还原
假设我对精度要求很高,高到无法容忍有任何误差,那么我先将x按照大小排序,然后归一化,用字典将归一化前后的x存储下来,在深度学习时使用归一化后的x进行处理,但是最后画图等处理时,我用字典取出归…...

HarmonyOS:UIAbility组件概述
一、概述 UIAbility组件是一种包含UI的应用组件,主要用于和用户交互。 UIAbility的设计理念: 原生支持应用组件级的跨端迁移和多端协同。支持多设备和多窗口形态。 UIAbility划分原则与建议: UIAbility组件是系统调度的基本单元,…...

12寸半导体厂说的华夫区是什么意思
1\什么是华夫板 在半导体行业中,“华夫区”通常指的是“华夫板”(Waffle Slab),这是一种特殊设计的楼板,其表面具有许多均匀分布的孔洞,这些孔洞形成了回风通道,用于电子芯片厂房等对空气洁净度有极高要求的环境。华夫板的设计和施工对于保证洁净室的功能发挥至关重要。…...

数据结构之链式结构二叉树的实现(进阶版)
本篇文章主要讲解链式二叉树的层序遍历以及判断是否为一棵完全二叉树 二者将会用到之前学过的队列知识,是将队列和二叉树的整合 一、如何将之前已经写好的文件加入当前的编译界面 如图所示,打开我们需要加入文件所在的文件夹,找到我们要加…...
【高等数学】3-2多元函数积分学
1. 二重积分 可以想象你有一块不规则的平面薄板,它在一个平面区域上。二重积分就是用来求这个薄板的质量(假设薄板的面密度函数是)。 把区域划分成许多非常小的小方块(类似于把一块地划分成很多小格子),在每个小方块上,密度近似看成是一个常数,然后把每个小方块的质量加…...

【传知代码】智慧医疗:纹理特征VS卷积特征
🍑个人主页:Jupiter. 🚀 所属专栏:传知代码 欢迎大家点赞收藏评论😊 目录 论文概述纹理特征和深度卷积特征算法流程数据预处理方法纹理特征提取深度卷积特征提取分类网络搭建代码复现BLS_Model.py文件——分类器搭建py…...

Python-创建并调用自定义文件中的模块/函数
背景:在Python编程中,我们常常需要创建自己的专属文件,以便帮助我们更高效,快捷地完成任务。那么在Python中我们怎么创建并调用自己文件中的模块/函数呢? 在Python中调用自定义文件,通常是指调用自己编写的Python模块…...
Kali Linux
起源与背景 Kali Linux是一个基于Debian的开源Linux发行版,专门为信息安全工作者和渗透测试员设计。它是由Offensive Security Ltd.开发和维护的,作为BackTrack的继承者而诞生。BackTrack是一个流行的安全测试发行版,但为了提供更好的支持和…...

DiffusionDet: Diffusion Model for Object Detection—用于对象检测的扩散模型论文解析
DiffusionDet: Diffusion Model for Object Detection—用于对象检测的扩散模型论文解析 这是一篇发表在CVPR 2023的一篇论文,因为自己本身的研究方向是目标跟踪,之前看了一点使用扩散模型进行多跟踪的论文,里面提到了DiffusionDet因此学习一…...

H5GG iOS脚本引擎终极指南:三分钟掌握无需越狱的游戏修改神器
H5GG iOS脚本引擎终极指南:三分钟掌握无需越狱的游戏修改神器 【免费下载链接】H5GG an iOS Mod Engine with JavaScript APIs & Html5 UI 项目地址: https://gitcode.com/gh_mirrors/h5/H5GG H5GG是一款革命性的iOS脚本引擎和内存修改工具,通…...

Context-Mode:基于React Context的模式化状态管理新范式
1. 项目概述:一个为现代前端开发量身定制的状态管理新范式 最近在重构一个中后台项目时,我又一次陷入了状态管理的泥潭。组件间层层传递的 props 像一团乱麻,全局 store 里塞满了各种不相关的数据,每次修改一个状态都得小心翼…...

Linux环境变量与env命令:从核心原理到高级实战应用
1. 项目概述:为什么环境变量是Linux的“隐形指挥棒”在Linux世界里,我们每天都在和各种命令、程序打交道。你有没有想过,为什么ls命令在任何目录下都能直接运行?为什么python命令启动的是Python 3而不是Python 2?又或者…...

【网络编程】UDP协议
目录 协议格式 特点 1.无连接(Connectionless) 2. 不可靠(Unreliable) 3. 面向报文(Message-Oriented) 常见问题 协议格式 特点 1.无连接(Connectionless) 特点:在…...

Cursor AI插件开发:从代码补全到智能动作执行的范式演进
1. 项目概述:当AI代码助手遇上插件生态最近在GitHub上看到一个挺有意思的项目,叫RightbrainAI/cursor-plugin。光看名字,可能很多用惯了Cursor的朋友会眼前一亮,以为这是Cursor编辑器官方或者某个社区大神出的插件。但点进去仔细一…...

SteamVR Unity插件实战:构建跨平台VR交互系统的完整方案
SteamVR Unity插件实战:构建跨平台VR交互系统的完整方案 【免费下载链接】steamvr_unity_plugin SteamVR Unity Plugin - Documentation at: https://valvesoftware.github.io/steamvr_unity_plugin/ 项目地址: https://gitcode.com/gh_mirrors/st/steamvr_unity_…...

别死记硬背!用‘小明小红在操场’的JavaScript题,彻底搞懂this、call和箭头函数
从操场运动到代码执行:用生活场景拆解JavaScript的this与箭头函数 操场上的小明和小红正在运动,这个看似简单的场景却暗藏JavaScript中this指向的玄机。当我们把人物动作转化为代码时,this的指向问题往往成为初学者的"绊脚石"。本文…...

All in Token,三个运营商建Token工厂,中国移动跟进Token经营 三大运营商争夺AI阵地
随着Token(词元)经营战略的密集落地,三大运营商在AI领域的竞争愈发激烈。在日前举行的2026移动云大会上,中国移动正式发布了Token运营生态体系与移动模型服务平台MoMA,宣布接入超300款模型,并通过Token集约…...

UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器
UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool 你是否曾好奇计算机启动时底层发生了什么?想要深入了解UEFI固件的…...

Lingoose框架实战:构建智能客服工单处理AI工作流
1. 项目概述:从“Lingo”到“Goose”,一个AI应用编排框架的诞生如果你最近在折腾大语言模型应用,尤其是想把OpenAI、Anthropic这些API的能力整合到自己的业务流程里,那你大概率已经体会过那种“胶水代码”的烦恼了。今天要聊的这个…...