Linux 进程间通信 共享内存_消息队列_信号量
共享内存
共享内存是一种进程间通信(IPC)机制,它允许多个进程访问同一块内存区域。这种方法可以提高效率,因为数据不需要在进程之间复制,而是可以直接在共享的内存空间中读写。

使用共享内存的步骤通常包括:
- 创建共享内存:一个进程shmget()创建共享内存区域。
- 映射共享内存:其他进程将该共享内存映射到自己的地址空间中的共享区中。
- 读写数据:进程可以在共享内存中读写数据,进行通信。
- 解除映射和删除:使用完后,进程解除映射并清理共享内存。

shmget()创建共享内存 获取标识符
int shmget(key_t key, size_t size, int shmflg);
#include <sys/shm.h>
参数
- key: 一个唯一的标识符,用于区分不同的共享内存段。可以使用
ftok函数生成。- size: 请求的共享内存段的大小(以字节为单位)。
- shmflg: 位图 控制标志,用于指定权限和其他选项。常见的选项包括:
IPC_CREAT: 如果共享内存段不存在则创建它。如果存在就获取它IPC_EXCL|IPC_CREAT:一起使用,表示如果共享内存段不存在就创建它,反之,存在则返回错误。(返回成功一定是创建新的共享内存)- 权限标志,例如
0666表示可读可写。返回值
- 成功时,返回共享内存标识符(非负整数)。(相当于FILE*)
- 失败时,返回
-1,并设置errno以指示错误类型。
key作为标识符但不能由系统创建分配给进程,而是由用户自己创建并给进程,但要确保key是唯一的。
我们知道key是不同进程找到同一个内存空间的关键,要确保它们的key是一样的。如果是系统分配fey,A进程先创建了共享内存获得一个keg,B进程如果想访问A创建的共享内存,就要获取到key,但A B进程相互独立不可能从A进程中获取到key。
但如果是用户给,可以让用户先生成唯一的key,再把key作为全局变量写在AB进程的源代码中,这样AB进程就可以通过同一个key访问到同一个共享内存了。
如何生成唯一的key?
ftok()
key_t ftok(const char *pathname, int proj_id); key_t key = ftok("/path/to/file", 'R'); // 'R' 是一个项目标识符ftok()函数是一个用于生成唯一键值的系统调用,它接受一个文件路径和一个项目标识符(也可以是数字,通常是一个字符),并返回一个唯一的key。这个方法基于文件的 inode 号,因此只要文件存在且未被删除,返回的key就会是唯一的。
ipcs -m命令 显示所有的共享内存信息
ipcs -m 用于显示系统中当前存在的共享内存段的信息。
ipcs -m
key shmid owner perms bytes nattch status
0x12345678 12345 user 666 1024 2这条命令会列出所有的共享内存段,包括它们的 shmid、键值、大小和其他信息。
bytes 1024 操作系统申请空间是按块为单位(4kb...)来申请空间的,4096*x。假设该操作系统块的大小为4kb如果你申请4097字节,还是会申请8kb空间,但只让你用4097字节的空间,越界就报错。
ipcrm -m命令删除共享内存段
ipcrm -m shmid
shmctl() 控制共享内存 IPC_RMID删除
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
参数
shmid:共享内存段的标识符,通常是通过shmget函数获取的。cmd:命令,用于指定要执行的操作,可以是以下常用值之一:
IPC_STAT:将共享内存段的信息填充到buf指向的结构中。IPC_RMID:标记共享内存段以便删除。SHM_LOCK:锁定共享内存段。SHM_UNLOCK:解锁共享内存段。SHM_INFO:获取共享内存的统计信息(POSIX扩展)。buf:指向shmid_ds结构的指针,用于存储共享内存的元数据。- 成功时返回 0。
- 失败时返回 -1,并设置
errno以指示错误原因。
shmat() 将共享内存挂接到自己的地址空间中
void* shmat(int shmid, const void* shmaddr, int shmflg);参数说明
- shmid: 共享内存段的标识符,通常通过
shmget()获取。- shmaddr: 指定共享内存挂接到虚拟地址空间的起始地址。如果为
NULL,系统会选择一个合适的地址。- shmflg: 标志位: 0默认附加模式,进程可以读写共享内存。
SHM_RDONLY: 只读模式,进程只能读取数据,不能写入。返回值
- 成功时,返回指向共享内存挂接到虚拟地址空间的起始地址。
- 失败时,返回
(void*) -1,并设置errno指示错误类型。
注意共享内存也是有权限的,进程如果没有对应的权限是不能完成挂接的。
shmid = shmget(IPC_PRIVATE, size, IPC_CREAT | 0666); // 创建共享内存,权限为可读可写在shmget()创建共享内存时,我们就可以设置权限0666:所有用户都可以读写。
如果不设置权限,默认权限是0600:创建者可读写 其他人无权限
shmdt()取消挂载
int shmdt(const void *shmaddr);const void *shmaddr:挂载到进程的虚拟地址空间的起始地址
shmdt()于从进程的地址空间分离已经附加的共享内存段。它不会删除共享内存段本身。
shmctl(IPC_RMID) :用于标记共享内存段为删除,等待所有附加的进程分离后释放资源。
共享内存通信速度最快
1.直接访问:共享内存允许多个进程直接访问同一块内存区域,避免了数据复制的开销。这与其他通信方式(如管道、消息队列等)不同,后者通常需要在进程之间复制数据
管道:数据从外设读取到进程A的内核空间,然后通过系统调用将数据写入管道。B通过系统调用从管道中读取数据,再将其拷贝到自己的内存中。
这种方式总共涉及四次拷贝:一次从外设到进程A的内核空间,一次从内核空间写入管道,一次从管道读取到进程B的内核空间,最后一次从内核空间到进程B的内存。
共享内存 :数据从外设读取到内核空间后,进程A和进程B可以直接访问共享的内存区域,避免了多次拷贝。
因此,总的拷贝次数减少为两次:一次从外设读取到内核空间,另一次是进程B直接从共享内存读取数据。
2.低延迟:由于不涉及操作系统内核的上下文切换,共享内存通信的延迟较低,特别适合需要高频率、低延迟的数据交换的场景。
3.高吞吐量:共享内存能够支持大量数据的快速传输,适合处理大规模数据或高并发的情况。
4.减少系统调用:其他通信机制往往需要进行系统调用,而共享内存可以减少这种需求,从而提升性能。

消息队列

os提供一个队列,A B进程都可以看到这个队列,把结构体struct data作为结点放入队列,再让另一个进程拿该节点,实现通信。
怎么知道这个节点是其他进程放的呢?
用户要自己创建struct data,里面有int type标识符,定义A进程标识符1 B为2,这样就可以区分拿与自己标识符不同的节点。
msgget() msgctl()
这两个函数用法和shmget() shmctl() 差不多
int msgget(key_t key, int msgflg);
参数说明:
key: 消息队列的键值,可以通过ftok()函数生成。msgflg: 控制消息队列的行为,通常使用以下标志:
IPC_CREAT: 如果消息队列不存在则创建一个。IPC_EXCL: 如果消息队列已经存在,调用失败。- 权限位(如
0666)控制访问权限。返回值:
- 成功时返回消息队列的标识符(非负整数)。
- 失败时返回 -1。
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
参数说明:
msqid: 消息队列的标识符。cmd: 控制命令,可以是以下之一:
IPC_STAT: 获取消息队列的状态信息。IPC_SET: 设置消息队列的属性。IPC_RMID: 删除消息队列。buf: 指向msqid_ds结构的指针,用于存放或设置属性。返回值:
- 成功时返回 0。
- 失败时返回 -1。
ipcs -q ipcrm -m
ipcs -q 用于显示当前系统中所有的消息队列的信息。
------ Message Queues --------
key msqid owner perms used-bytes
0x12345678 12345 user1 666 0
0x87654321 12346 user2 666 0
ipcrm -m删除共享内存段
ipcrm -m <shmid>
msgsnd() msgrcv() 特有
msgsnd() msgrcv()是消息队列特有的函数
msgsnd() 发送消息
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
参数说明:
msqid: 消息队列的标识符。msgp: 指向要发送的消息节点的指针,消息的结构体struct msgbuf要以标识符long mtype开头msgsz: 消息内容的字节数(不包括mtype)。msgflg: 自己的标识符,常用值包括IPC_NOWAIT(如果队列已满则不等待,直接返回错误)。0: 默认行为,发送或接收消息时会阻塞,直到操作成功。返回值:
- 成功时返回 0。
- 失败时返回 -1。
msgrcv() 接收消息
int msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);
参数说明:
msqid: 消息队列的标识符。msgp: 指向接收消息的缓冲区的指针。指向struct datamsgsz: 消息内容的最大字节数(不包括mtype)。msgtyp: 指定接收消息的标识符mtype,可以是特定类型的消息(如1),也可以是0(接收任何类型的消息)或-1(接收队列中最早的消息)。msgflg: 控制接收行为的标志,常用值包括IPC_NOWAIT(如果队列为空则不等待,直接返回错误)。返回值:
- 成功时返回接收到的消息字节数。
- 失败时返回 -1。
信号量
信号量是一种用于进程间同步和互斥的机制,主要用于控制多个进程对共享资源的访问。它通过维护一个整型计数器来实现,计数器的值表示可用资源的数量或状态。

我们之前学过管道,我们把管道的资源看作一个整体,要写整个资源所有地方都可以写,要读都可以读。
现在我们把整个资源,分成多份,一个进程访问一份。整个资源,有部分可能在写入,还有部分可能在读,不同进程,访问共享资源,有一定并发性。
1.但是我们怎么知道整个资源里面还有多少份没有进程占用?
我们可以用一个计算器count来记录里面剩余个数,count=16 每进入一个进程count--(这种操作称作P操作),出去count++(V操作)。
P操作(等待):
- 当线程或进程希望访问某个共享资源时,它会执行P操作。这个操作的作用是检查信号量的值:
- 如果信号量的值大于0,表示资源可用,线程可以继续执行,并且信号量的值减1。
- 如果信号量的值为0,表示资源不可用,线程会被阻塞,直到信号量的值变为正。
V操作(释放):
- 当线程或进程完成对共享资源的使用后,会执行V操作。这个操作的作用是将信号量的值增加1,表示资源现在可用。如果有其他线程在等待这个资源,执行V操作后会唤醒其中一个等待的线程。
2.现在有出现一个问题怎么让不同进程看到同一个count呢?
可以用共享内存 管道 让进程与进程间建立联系就可以3.但这样又有一个新问题,count++这种操作并不是原子性的,多个线程同时修改同一数据引发数据竞争。
使用二进制信号量(或互斥锁),可以确保在任何时刻只有一个线程或进程能够访问临界区(共享资源)。当一个线程进入临界区时,它会调用 P 操作(等待),如果信号量值为 0,其他线程会被阻塞,直到该线程调用 V 操作(释放),将信号量值加 1。
信号量可以分为两种类型:
1.二进制信号量。count==1
2.计数信号量。count>1
1.semget()
可以创建nsems个信号量,一个信号量管理count个资源。
int semget(key_t key, int nsems, int semflg);
key: 唯一标识符。nsems: 信号量的数量。semflg: 权限标志(如IPC_CREAT、0666)。
2.semctl()
控制信号量集的操作,如获取、设置信号量值或删除信号量。
int semctl(int semid, int semnum, int cmd, ...);
semid: 信号量集标识符。semnum: 信号量在集合中的索引。cmd: 操作命令(如SETVAL、GETVAL、IPC_RMID等)。
semnum:信号量集合允许我们同时管理多个信号量,
semnum就是用来指定我们想要操作的具体信号量。在一个信号量集合中,每个信号量都有一个唯一的索引,从 0 开始编号。例如,如果一个信号量集合中有三个信号量,索引将是 0、1 和 2。
3.semop()
执行对信号量的操作,如 P(wait)和 V(signal)。
int semop(int semid, struct sembuf *sops, size_t nsops);struct sembuf {unsigned short sem_num; // 信号量在集合中的索引short sem_op; // 要执行的操作(正数表示 V 操作,负数表示 P 操作)short sem_flg; // 操作标志(如 `IPC_NOWAIT`)
};
semid: 信号量集标识符。sops: 指向sembuf结构数组的指针,定义了要执行的操作。nsops: 数组中操作的数量。(对nsops个信号量进行PV操作)
ipcs -s
显示当前系统中所有的信号量信息,包括信号量的标识符、拥有者、权限和其他相关信息。
------ Semaphore Arrays --------
KEY ID OWNER PERMS NSEMS
0x12345678 12345 user 666 1
System V怎么实现IPC的
1.应用角度,看IPC属性

struct shmid_ds里面是共享内存的属性,第一个成员变量就是struct ipc_prem结构体。而消息队列 信号量同样也是以struct ipc_prem结构体开头,struct ipc_prem结构体里面就保存着key值。也就是说不同 IPC 机制可以通过相同的方式来管理和控制访问权限,不同的IPC机制都有自己的一套key值,所以共享内存 消息队列 信号量的key可能重复,但在一种IPC机制中key是唯一的。
2.从内核角度,看IPC结构

有全局的结构体ipc_ids,里面有struct ipc_id_ary* entries指向结构体ipc_id_ary。
结构体ipc_id_ary最后一个成员变量是柔性数组,也就是说它可以动态保存kern_ipc_perm指针。kern_ipc_perm结构体里面保存的是IPC不同机制共同的属性。

为什么说kern_ipc_perm结构体里面保存的是IPC不同机制共同的属性?
因为在不同PC机制的属性中第一个成员变量就是kern_ipc_perm结构体,其他成员变量都是根据不同IPC的实现机制特别增加的。

为什么不同IPC机制的属性中第一个成员变量一定是kern_ipc_perm结构体?
因为结构体ipc_id_ary中柔性数组保存的是kern_ipc_perm指针,如果共享内存 消息队列 信号量它们属性第一个成员变量是kern_ipc_perm,那么就可以指向他们的结构体属性。
这样ipc_id_ary数组就可以找到每个创建的共享内存 消息队列 信号量的属性,进而进行管理。
其实我们shmget() msgget() semget()获取的id就是它们在ipc_id_ary数组的下标。
和key值一样,id在一种IPC机制中是唯一的,但在不同IPC机制中可能相同。
也就是说一个ipc_id_ary数组中指向的全是相同IPC机制的属性。

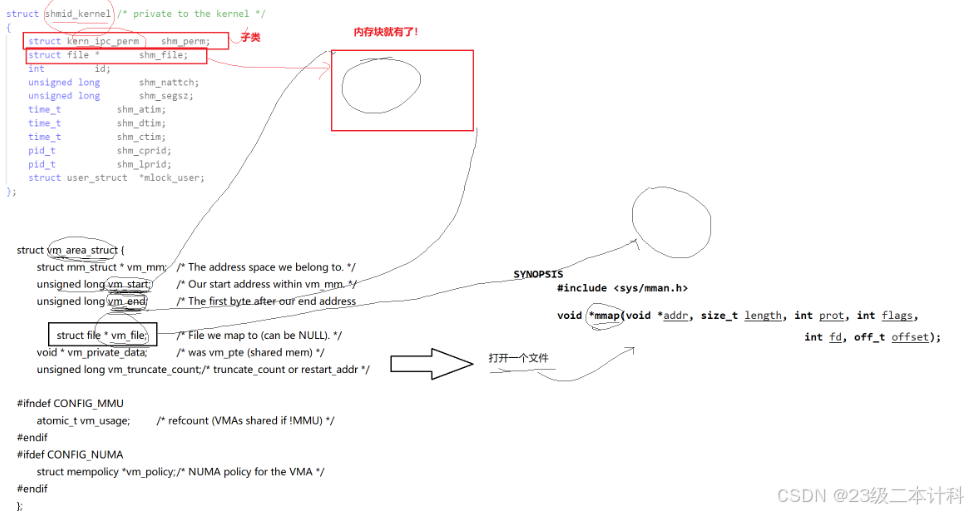
其实共享内存是一种文件
在共享内存的属性中有struct file*的指针,它指向一个文件,文件有inode,知道它的数据块的物理地址。vm_start vm_end是共享内存在虚拟地址空间的起始地址 结束地址,把它与指向文件的内存块的物理地址建立映射关系,进程可以通过这个映射直接访问文件内容。
相关文章:
Linux 进程间通信 共享内存_消息队列_信号量
共享内存 共享内存是一种进程间通信(IPC)机制,它允许多个进程访问同一块内存区域。这种方法可以提高效率,因为数据不需要在进程之间复制,而是可以直接在共享的内存空间中读写。 使用共享内存的步骤通常包括:…...
Mybatis自定义日志打印
一,目标 替换?为具体的参数值统计sql执行时间记录执行时间过长的sql,并输出信息到文档(以天为单位进行存储) 平常打印出来的sql都是sql一行,参数一行。如图: 二,理论 这里我们主要通过Mybatis…...

【在Linux世界中追寻伟大的One Piece】Socket编程TCP(续)
目录 1 -> V2 -Echo Server多进程版本 2 -> V3 -Echo Server多线程版本 3 -> V3-1 -多线程远程命令执行 4 -> V4 -Echo Server线程池版本 1 -> V2 -Echo Server多进程版本 通过每个请求,创建子进程的方式来支持多连接。 InetAddr.hpp #pragma…...

面试高频问题:C/C++编译时内存五个分区
在面试时,C/C++编译时内存五个分区是经常问到的问题,面试官通过这个问题来考察面试者对底层的理解。在平时开发时,懂编译时内存分区,也有助于自己更好管理内存。 目录 内存分区的定义 内存分区的重要性 代码区 数据区 BSS区 堆区 栈区 静态内存分配 动态内存分配…...
阅读博士论文《功率IGBT模块健康状态监测方法研究》
IGBT的失效可以分为芯片级失效和封装级失效。其中封装级失效是IGBT模块老化的主要原因,是多种因素共同作用的结果。在DBC的这种结构中,流过芯片的负载电流通过键合线传导到 DBC上层铜箔,再经过端子流出模块。DBC与芯片和提供机械支撑的基板之…...

Spring ApplicationContext接口
ApplicationContext接口是Spring框架中更高级的IoC容器接口,扩展了BeanFactory接口,提供了更多的企业级功能。ApplicationContext不仅具备BeanFactory的所有功能,还增加了事件发布、国际化、AOP、资源加载等功能。 ApplicationContext接口的…...
[perl] 数组与哈希
数组变量以 符号开始,元素放在括号内 简单举例如下 #!/usr/bin/perl names ("a1", "a2", "a3");print "\$names[0] $names[0]\n"; print "size: ",scalar names,"\n";$new_names shift(names); …...
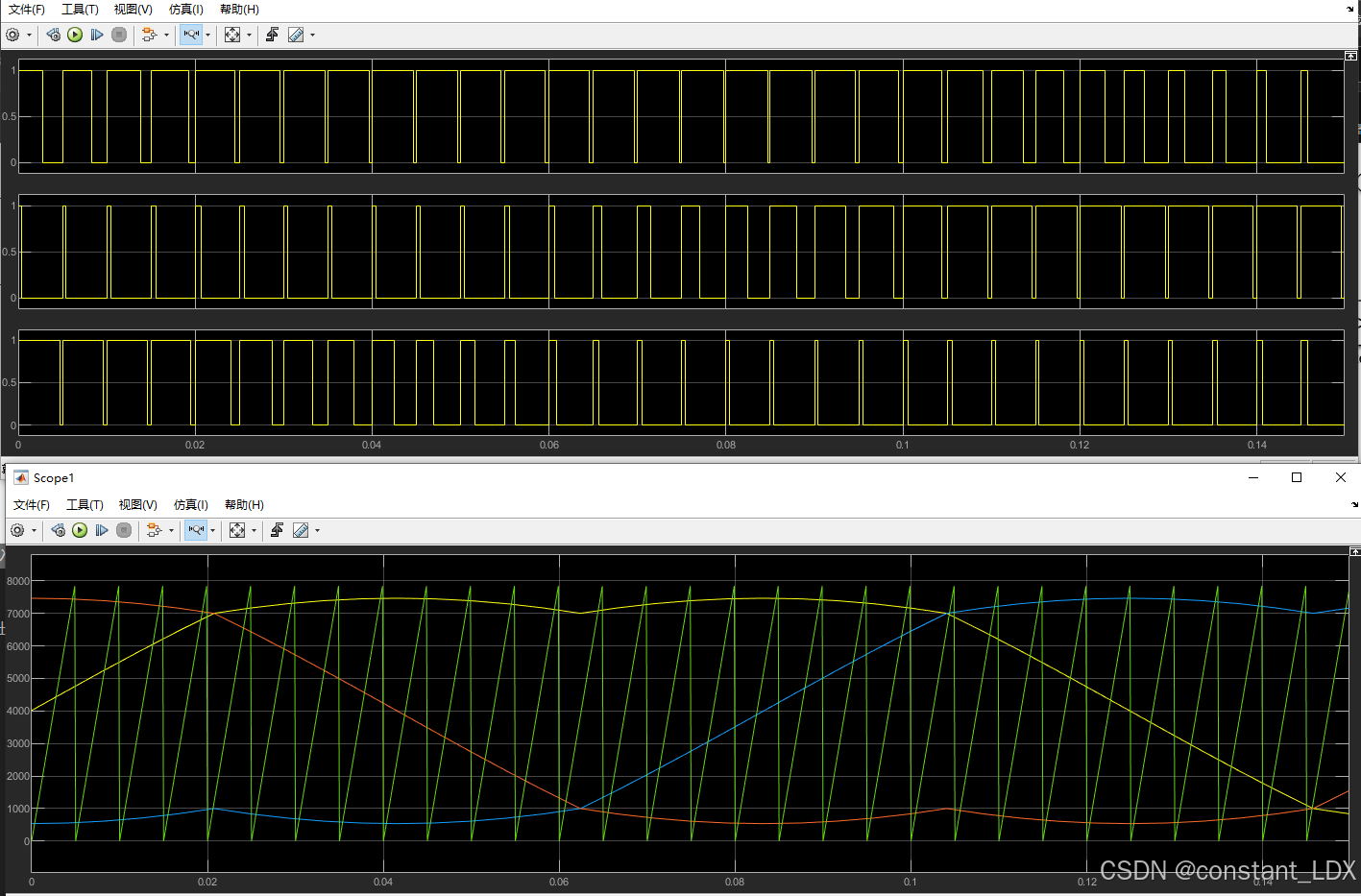
电机学习-SPWM原理及其MATLAB模型
SPWM原理及其MATLAB模型 一、SPWM原理二、基于零序分量注入的SPWM三、MATLAB模型 一、SPWM原理 SPWM其实是相电压的控制方式,定义三相正弦相电压的表达式: { V a m V m sin ω t V b m V m sin ( ω t − 2 3 π ) V c m V m sin ( ω t 2…...
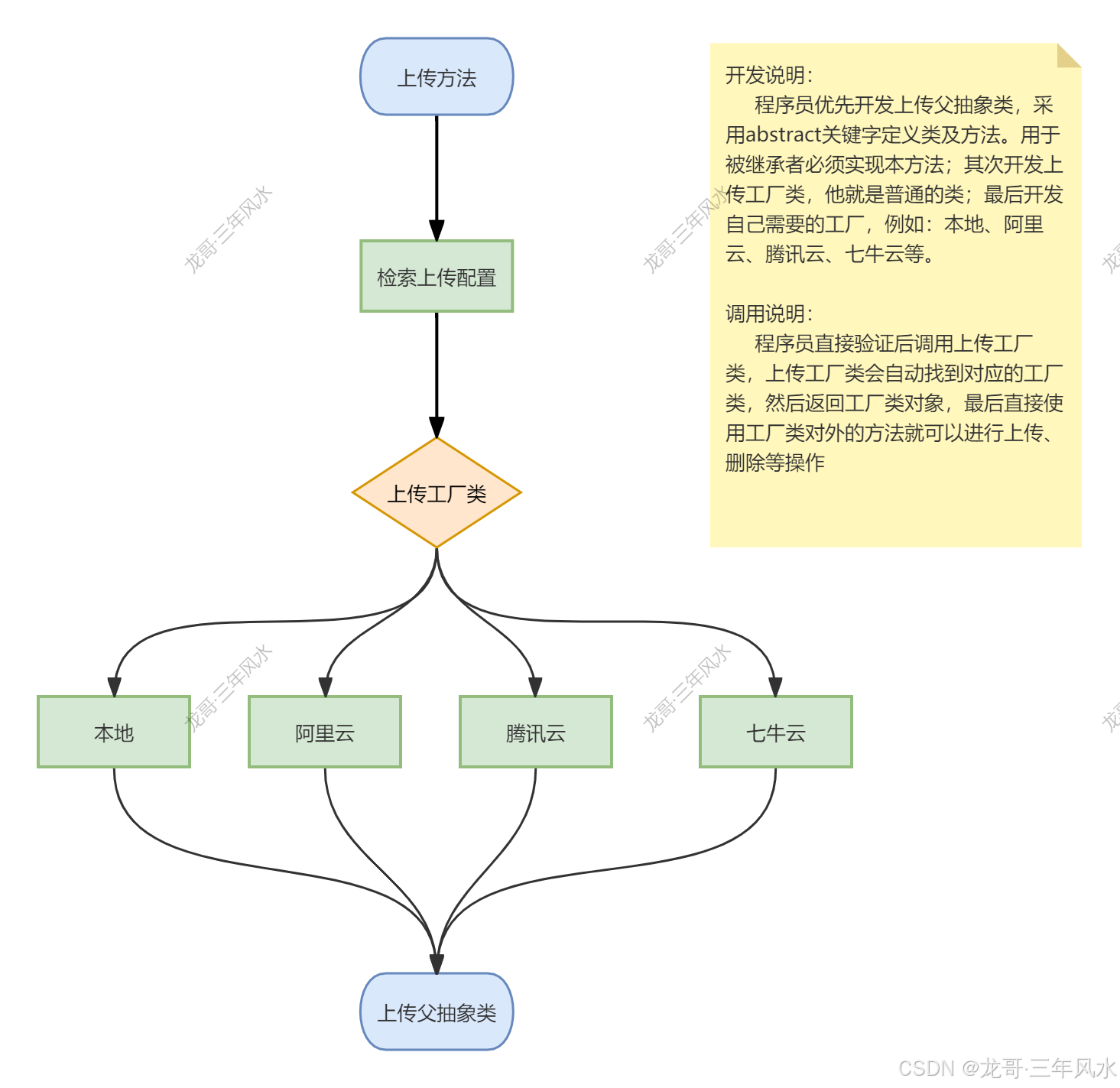
群控系统服务端开发模式-应用开发-腾讯云上传工厂及七牛云上传工厂开发
记住业务流程图,要不然不清楚自己封装的是什么东西。 一、腾讯云工厂开发 切记在根目录下要安装腾讯云OSS插件,具体代码如下: composer require qcloud/cos-sdk-v5 在根目录下extend文件夹下Upload文件夹下channel文件夹中,我们修…...

【深度学习滑坡制图|论文解读3】基于融合CNN-Transformer网络和深度迁移学习的遥感影像滑坡制图方法
【深度学习滑坡制图|论文解读3】基于融合CNN-Transformer网络和深度迁移学习的遥感影像滑坡制图方法 【深度学习滑坡制图|论文解读3】基于融合CNN-Transformer网络和深度迁移学习的遥感影像滑坡制图方法 文章目录 【深度学习滑坡制图|论文解读3】基于融合CNN-Transformer网络和…...

《计算机原理与系统结构》学习系列——处理器(下)
系列文章目录 目录 流水线冒险数据冒险数据相关与数据冒险寄存器先读后写旁路取数使用型冒险阻塞 控制冒险分支引发的控制冒险假设分支不发生动态分支预测双预测位动态分支预测缩短分支延迟带冒险控制的单周期流水线图 异常MIPS中的异常MIPS中的异常处理另一种异常处理机制非精…...

JDK新特性(8-21)数据类型-直接内存
目录 Jdk 新特性 JDK 8 特性 默认方法实现作用:可以使接口更加灵活,不破坏现有实现的情况下添加新的方法。 函数式接口 StreamAPI JDK 9 特性 JDK 10 特性 JDK 11 特性 JDK 14 特性 JDK 17 特性 JDK 21 特性 数据类型 基本数据类型和引用数据类型的区别…...

003-Kotlin界面开发之声明式编程范式
概念本源 在界面程序开发中,有两个非常典型的编程范式:命令式编程和声明式编程。命令式编程是指通过编写一系列命令来描述程序的运行逻辑,而声明式编程则是通过编写一系列声明来描述程序的状态。在命令式编程中,程序员需要关心程…...

QT pro项目工程的条件编译
QT pro项目工程的条件编译 前言 项目场景:项目中用到同一型号两个相机,同时导入两个版本有冲突,编译不通过, 故从编译就区分相机导入调用,使用宏区分 一、定义宏 在pro文件中定义宏: DEFINES USE_Cam…...

深度学习之经典网络-AlexNet详解
AlexNet 是一种经典的卷积神经网络(CNN)架构,在 2012 年的 ImageNet 大规模视觉识别挑战赛(ILSVRC)中表现优异,将 CNN 引入深度学习的新时代。AlexNet 的设计在多方面改进了卷积神经网络的架构,…...

部署Prometheus、Grafana、Zipkin、Kiali监控度量Istio
1. 模块简介 Prometheus 是一个开源的监控系统和时间序列数据库。Istio 使用 Prometheus 来记录指标,跟踪 Istio 和网格中的应用程序的健康状况。Grafana 是一个用于分析和监控的开放平台。Grafana 可以连接到各种数据源,并使用图形、表格、热图等将数据…...

结合 Spring Boot Native 和 Spring Boot 构建高性能服务器架构
随着云计算和微服务架构的普及,开发者们不断寻求提高应用性能和用户体验的解决方案。Spring Boot Native 的出现,利用 GraalVM 的原生映像特性,使得 Java 应用的启动速度和资源占用得到了显著改善。本文将深入探讨如何将前端应用使用 Spring …...
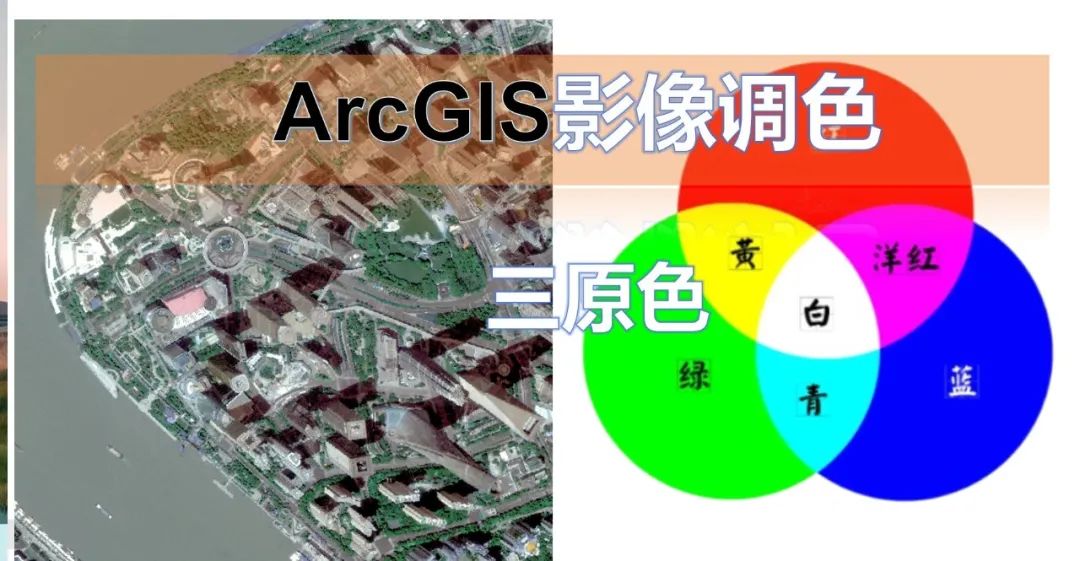
ArcGIS影像调色(三原色)三原色调整
本期主要介绍ArcGIS影像调色(三原色) ArcGIS影像调色(三原色),对比度、亮度、gamma。红绿蓝三原色调整。 视频学习 ArcGIS影像调色(三原色)...

SQLite从入门到精通面试题及参考答案
目录 SQLite 是什么? SQLite 的优点有哪些? 轻量级与易于部署 零配置和低维护成本 良好的兼容性和跨平台性 高性能和可靠性 SQLite 的局限性有哪些? 并发处理能力有限 缺乏用户管理和权限控制功能 有限的扩展性 有限的网络支持 SQLite 和其他数据库系统(如 MyS…...

【C/C++】字符/字符串函数(0)(补充)——由ctype.h提供
零.导言 除了字符分类函数,字符转换函数也是一类字符/字符串函数。 C语言提供了两种字符转换函数,分别是 toupper , tolower。 一.什么是字符转换函数? 顾名思义,即转换字符的函数,如大写字母转小写字母&am…...

第08章 FastAPI 与 SSE 流式 RAG 后端
第08章 FastAPI 与 SSE 流式 RAG 后端 到目前为止,知识库、检索工具、MCP 客户端都已经就绪,但仍缺少一个面向最终用户的入口。本章用 FastAPI 把整条 RAG 链路串起来:接收前端发来的自然语言问题,调用 MCP 工具检索相关工单&…...

AI驱动博客平台CodeBlog-app:开发者技术分享的智能解决方案
1. 项目概述:一个为开发者而生的AI驱动博客平台最近在GitHub上看到一个挺有意思的开源项目,叫CodeBlog-ai/codeblog-app。光看名字,你可能会觉得这又是一个普通的博客系统,或者是一个AI写作工具。但当我深入去研究它的代码和设计理…...

用PCA给高维数据‘瘦身’:从鸢尾花数据集到人脸图像,实战对比降维效果与可视化技巧
用PCA给高维数据‘瘦身’:从鸢尾花数据集到人脸图像,实战对比降维效果与可视化技巧 当面对成百上千维的数据时,我们常会陷入"维度灾难"的困境——计算资源吃紧、模型训练缓慢,更糟的是噪声干扰导致分析结果失真。主成分…...

Taotoken用量看板如何帮助个人开发者管理月度预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助个人开发者管理月度预算 对于独立工作的个人开发者而言,项目预算往往是决定技术选型与使用策…...

激光切割外壳设计全流程:从创客工具到产品级制造的实战指南
1. 项目概述:为什么选择激光切割来做外壳?如果你和我一样,捣鼓过不少电子项目,从简单的Arduino温湿度计到复杂的树莓派家庭服务器,那你一定为“给它们找个家”这件事头疼过。3D打印太慢,开模注塑成本又高得…...

I2C地址冲突全解析:从原理到实战的嵌入式系统设计指南
1. I2C地址:嵌入式系统设计的“门牌号”与“交通规则”如果你玩过单片机或者树莓派,肯定对I2C不陌生。两根线,SDA和SCL,就能挂上一堆传感器、显示屏、扩展芯片,听起来简直是嵌入式开发的“万金油”。但真正上手后&…...
)
【限时解密】ElevenLabs未文档化的/v1/text-to-speech/{voice_id}/with-timing接口:获取逐词时间戳+音素级对齐数据(仅剩3个Beta白名单通道)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs英文语音生成的核心能力与技术定位 ElevenLabs 是当前业界领先的 AI 语音合成平台,其英文语音生成能力建立在自研的端到端神经声学模型(如 ElevenMultilingualV2&…...

Helm-Git插件:无缝集成Git与Helm,实现Kubernetes Chart的GitOps部署
1. 项目概述:Helm与Git的桥梁 如果你和我一样,长期在Kubernetes生态里打转,那你对Helm一定不陌生。作为Kubernetes的包管理器,它用Chart这个概念,把复杂的应用部署打包得井井有条。但不知道你有没有遇到过这样的场景&…...

开源流程编排引擎FlowCue:基于DAG与事件驱动的自动化工作流实践
1. 项目概述:FlowCue是什么,以及它为何值得关注如果你是一名开发者,尤其是经常和API、数据流、自动化任务打交道的后端或全栈工程师,那么你肯定对“流程编排”这个概念不陌生。简单来说,就是把一系列独立的操作&#x…...

基于MCP协议构建Naver搜索服务器,为AI智能体赋能实时信息获取
1. 项目概述:一个连接AI与实时信息的桥梁最近在折腾AI应用开发,特别是围绕OpenAI的Assistant API和Claude的Tool Use功能时,我一直在思考一个问题:如何让这些强大的AI模型摆脱其知识库的“时间枷锁”,获取到最新、最实…...