深度学习之经典网络-AlexNet详解
AlexNet 是一种经典的卷积神经网络(CNN)架构,在 2012 年的 ImageNet 大规模视觉识别挑战赛(ILSVRC)中表现优异,将 CNN 引入深度学习的新时代。AlexNet 的设计在多方面改进了卷积神经网络的架构,使其能够在大型数据集上有效训练。以下是 AlexNet 的详解:
1. AlexNet 架构概述
AlexNet 有 8 层权重层,包括 5 层卷积层和 3 层全连接层(FC 层),并引入了一些重要的创新,包括激活函数、Dropout 正则化和重叠池化。它通过增加网络的深度和宽度,结合 GPU 加速,极大提升了 CNN 的能力。
2. AlexNet 架构细节

(1)输入层:
- 输入图像的尺寸为 227x227x3(RGB 3 通道图像)。
- AlexNet 采用的是 ImageNet 数据集,其图像分辨率较高,因此需要更大的卷积核和池化核。
(2)卷积层(Conv Layers):
- 第一层卷积层(Conv1):卷积核大小为 11x11,步长为 4,使用 96 个滤波器。输出的特征图尺寸为 55x55x96。经过 ReLU 激活函数处理。
- 第二层卷积层(Conv2):卷积核大小为 5x5,步长为 1,使用 256 个滤波器。由于输入图像较大,为减小计算量,每次滑动 1 像素,并采用了最大池化。输出的特征图尺寸为 27x27x256。
- 第三、四、五层卷积层(Conv3、Conv4、Conv5):分别采用 3x3 的卷积核,步长为 1,滤波器数分别为 384、384 和 256。
(3)激活函数(ReLU):
- AlexNet 是第一个在每一层卷积层之后使用 ReLU(Rectified Linear Unit)激活函数的网络。与 sigmoid 激活函数不同,ReLU 不会出现梯度消失问题,且能加快训练速度。
(4)池化层(Pooling Layers):
- 使用最大池化(Max Pooling),窗口大小为 3x3,步长为 2。
- AlexNet 引入了“重叠池化”,即池化窗口的步长小于窗口的大小(3x3 池化窗口和 2 步长),使得池化层能够更好地提取空间信息。
(5)全连接层(Fully Connected Layers):
- AlexNet 的最后 3 层是全连接层。
- FC6 层:输入是前一层展平后的特征图,输出为 4096 个节点。
- FC7 层:与 FC6 类似,输出也为 4096 个节点。
- FC8 层:为最终的输出层,节点数等于类别数(在 ImageNet 数据集中为 1000),通过 softmax 得到每个类别的概率。
(6)Dropout 正则化:
- 在全连接层中,AlexNet 引入了 Dropout 正则化,将随机的神经元设为 0,以减少过拟合。Dropout 率为 0.5,即每个神经元有 50% 的概率不参与计算。
(7)局部响应归一化(Local Response Normalization, LRN):
- LRN 是一种正则化技术,通过对某一层激活值进行归一化操作,增加了模型的泛化能力。虽然 LRN 不再是现代 CNN 的标准,但在 AlexNet 中有效防止了某些神经元的权值变得过大。
3. AlexNet 的创新点

AlexNet 的创新之处主要体现在以下几点:
-
ReLU 激活函数的应用:
通过使用 ReLU,AlexNet 成功避免了 sigmoid 和 tanh 激活函数可能导致的梯度消失问题,从而加速了训练过程。 -
重叠池化:
重叠池化减小了过拟合风险,使得网络能更好地进行特征提取和层次化表示。 -
Dropout 正则化:
Dropout 的引入在当时是一个非常重要的创新,它通过让神经元随机失活来防止过拟合。 -
多 GPU 训练:
AlexNet 在 GPU 上进行了分布式训练,将不同的卷积层分配到两个 GPU 上,从而加速了计算。 -
数据增强:
AlexNet 使用数据增强(如随机剪裁、镜像翻转和颜色扰动),进一步增加了训练数据的多样性,减少了过拟合风险。
模型特性
- 所有卷积层都使用ReLU作为非线性映射函数,使模型收敛速度更快
- 在多个GPU上进行模型的训练,不但可以提高模型的训练速度,还能提升数据的使用规模
- 使用LRN对局部的特征进行归一化,结果作为ReLU激活函数的输入能有效降低错误率
- 重叠最大池化(overlapping max pooling),即池化范围z与步长s存在关系z>s,避免平均池化(average pooling)的平均效应
- 使用随机丢弃技术(dropout)选择性地忽略训练中的单个神经元,避免模型的过拟合
4. AlexNet 的优势和局限性
- 优势:
- AlexNet 通过加深网络层数和增加神经元数量,提高了模型的表现力。
- 使用 GPU 进行加速计算,使得大规模数据集上的训练成为可能。
- Dropout、重叠池化和数据增强等技术有效地降低了过拟合风险。
- 局限性:
- AlexNet 参数数量较多,导致计算资源需求较大。
- 在深度增加的同时,过大的全连接层会导致大量参数和计算。
- LRN 归一化的效果有限,现代模型往往使用批归一化(Batch Normalization)来取代。
5. AlexNet 的影响
VGGNet、GoogLeNet 和 ResNet 等网络都在 AlexNet 的基础上进行了改进和扩展。
6.代码示例
PyTorch 中的 AlexNet 实现:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader# 定义 AlexNet 模型结构
class AlexNet(nn.Module):def __init__(self, num_classes=1000): # 默认输出1000类,可根据任务调整super(AlexNet, self).__init__()# 特征提取部分,包括卷积和池化层self.features = nn.Sequential(nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2), # 第1个卷积层,输出96个特征图nn.ReLU(inplace=True), # 激活函数,ReLUnn.MaxPool2d(kernel_size=3, stride=2), # 第1个最大池化层nn.Conv2d(96, 256, kernel_size=5, padding=2), # 第2个卷积层nn.ReLU(inplace=True), # 激活函数nn.MaxPool2d(kernel_size=3, stride=2), # 第2个最大池化层nn.Conv2d(256, 384, kernel_size=3, padding=1), # 第3个卷积层nn.ReLU(inplace=True), # 激活函数nn.Conv2d(384, 384, kernel_size=3, padding=1), # 第4个卷积层nn.ReLU(inplace=True), # 激活函数nn.Conv2d(384, 256, kernel_size=3, padding=1), # 第5个卷积层nn.ReLU(inplace=True), # 激活函数nn.MaxPool2d(kernel_size=3, stride=2) # 第3个最大池化层)# 分类部分,包含全连接层和 Dropout 层self.classifier = nn.Sequential(nn.Dropout(0.5), # Dropout层,防止过拟合nn.Linear(256 * 6 * 6, 4096), # 全连接层,输入尺寸为 256*6*6,输出4096nn.ReLU(inplace=True), # 激活函数nn.Dropout(0.5), # 第二个Dropout层nn.Linear(4096, 4096), # 第二个全连接层nn.ReLU(inplace=True), # 激活函数nn.Linear(4096, num_classes) # 最后一个全连接层,输出类别数)# 定义前向传播过程def forward(self, x):x = self.features(x) # 经过特征提取层x = x.view(x.size(0), 256 * 6 * 6) # 展平特征图用于输入全连接层x = self.classifier(x) # 经过分类层return x# 数据预处理,定义图像转换操作
transform = transforms.Compose([transforms.Resize(256), # 调整图像大小到256transforms.CenterCrop(227), # 中心裁剪为227x227大小,符合AlexNet输入要求transforms.ToTensor(), # 转换为Tensortransforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])# 加载 CIFAR10 数据集,训练集和测试集分别创建 DataLoader
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) # 设置批次大小和打乱数据test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)# 初始化模型、损失函数和优化器
model = AlexNet(num_classes=10) # CIFAR10 任务设置10个输出类别
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 检查是否有 GPU 加速
model.to(device) # 将模型移动到设备上criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,用于分类任务
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9) # 随机梯度下降优化器# 训练模型
def train(model, device, train_loader, criterion, optimizer, epoch):model.train() # 设置模型为训练模式for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 将数据移动到设备上optimizer.zero_grad() # 清空梯度output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新模型参数if batch_idx % 100 == 0: # 每100个批次打印一次训练状态print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)}]\tLoss: {loss.item():.6f}')# 测试模型
def test(model, device, test_loader, criterion):model.eval() # 设置模型为评估模式test_loss = 0 # 初始化测试损失correct = 0 # 初始化正确分类的数量with torch.no_grad(): # 禁用梯度计算for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data) # 前向传播test_loss += criterion(output, target).item() # 累积测试损失pred = output.argmax(dim=1, keepdim=True) # 获取预测的最大概率类别correct += pred.eq(target.view_as(pred)).sum().item() # 统计正确分类的数量test_loss /= len(test_loader.dataset) # 计算平均损失accuracy = 100. * correct / len(test_loader.dataset) # 计算准确率print(f'\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%)\n')# 主循环:训练和测试
num_epochs = 10 # 定义训练轮数
for epoch in range(1, num_epochs + 1):train(model, device, train_loader, criterion, optimizer, epoch) # 调用训练函数test(model, device, test_loader, criterion) # 调用测试函数
相关文章:
深度学习之经典网络-AlexNet详解
AlexNet 是一种经典的卷积神经网络(CNN)架构,在 2012 年的 ImageNet 大规模视觉识别挑战赛(ILSVRC)中表现优异,将 CNN 引入深度学习的新时代。AlexNet 的设计在多方面改进了卷积神经网络的架构,…...

部署Prometheus、Grafana、Zipkin、Kiali监控度量Istio
1. 模块简介 Prometheus 是一个开源的监控系统和时间序列数据库。Istio 使用 Prometheus 来记录指标,跟踪 Istio 和网格中的应用程序的健康状况。Grafana 是一个用于分析和监控的开放平台。Grafana 可以连接到各种数据源,并使用图形、表格、热图等将数据…...

结合 Spring Boot Native 和 Spring Boot 构建高性能服务器架构
随着云计算和微服务架构的普及,开发者们不断寻求提高应用性能和用户体验的解决方案。Spring Boot Native 的出现,利用 GraalVM 的原生映像特性,使得 Java 应用的启动速度和资源占用得到了显著改善。本文将深入探讨如何将前端应用使用 Spring …...
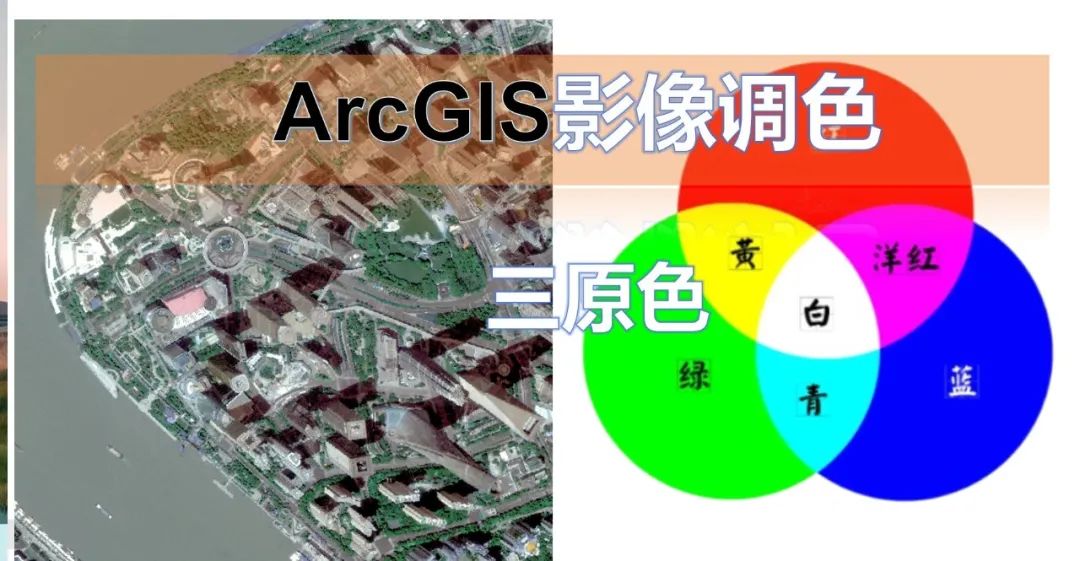
ArcGIS影像调色(三原色)三原色调整
本期主要介绍ArcGIS影像调色(三原色) ArcGIS影像调色(三原色),对比度、亮度、gamma。红绿蓝三原色调整。 视频学习 ArcGIS影像调色(三原色)...

SQLite从入门到精通面试题及参考答案
目录 SQLite 是什么? SQLite 的优点有哪些? 轻量级与易于部署 零配置和低维护成本 良好的兼容性和跨平台性 高性能和可靠性 SQLite 的局限性有哪些? 并发处理能力有限 缺乏用户管理和权限控制功能 有限的扩展性 有限的网络支持 SQLite 和其他数据库系统(如 MyS…...

【C/C++】字符/字符串函数(0)(补充)——由ctype.h提供
零.导言 除了字符分类函数,字符转换函数也是一类字符/字符串函数。 C语言提供了两种字符转换函数,分别是 toupper , tolower。 一.什么是字符转换函数? 顾名思义,即转换字符的函数,如大写字母转小写字母&am…...

Git 的特殊配置文件
文章目录 1.前言2.Git 标准配置文件.gitignore作用格式示例 .gitattributes作用格式示例 .gitmodules作用格式示例 .gitconfig作用格式示例 3.非 Git 标准约定文件.gitkeep简介示例 .gitacls作用格式示例 参考文献 1.前言 Git 是一个强大的版本控制系统,它使用多个…...

数据的表现形式(1)
数据的表现形式 西文字符编码 ASCII码(美国信息交换标准码) 计算机内部用一个字节(8位二进制),来存放一个7位ASCII码,最高位为“0”,共 可以表示128个不同字符 ASCII码中,0是48&…...

《高频电子线路》—— 调幅
文章内容来源于【中国大学MOOC 华中科技大学通信(高频)电子线路精品公开课】,此篇文章仅作为笔记分享。 调幅 普通调幅 AM 普通调幅,也属于线性调制,需要了解其时域和频域。 时域(表达式) vΩ…...

ubuntu22.04安装ROS2Humble
参考链接 Ubuntu22.04——ROS2安装以及小海龟画圆 Ubuntu 22.04 安装 ros noetic Slam_in_autonomous_driving(一) 环境配置...

软中端,硬中断(学习笔记)
/proc/softirqs 提供了软中断的运行情况; /proc/interrupts 提供了硬中断的运行情况。 以下图片展示的是软中断内容: 在查看 /proc/softirqs 文件内容时,你要特别注意以下这两点。 第一,要注意软中断的类型,也就是这…...

scIDST:弱监督学习推断单细胞转录组数据中的疾病进展阶段
背景:患者来源组织中的单个细胞,每个都处于不同的病理阶段,因此这种细胞变异性阻碍了随后的差异基因表达分析。 结果:为了克服这种异质性问题,作者提出了一种新的深度学习方法,scIDST,该方法可以…...

Linux 下执行定时任务之 Systemd Timers
不知道 ECS 因为什么缘故,上面安装的 MySQL 服务老是不定期挂掉,本来想通过 Linux 得 Cron 配置个半小时的定时检测任务,结果一直没有执行,因此又尝试使用了 Systemd Timers 进行了重新配置,简要做个记录。 Systemd Ti…...

flutter 专题二 Flutter状态管理之Riverpod 0.8.4
一 、flutter 有哪些状态管理方式 Flutter的状态管理方式有很多,Redux、 Bloc、 MobX、Provider等等。单单一个Provider,我也见到了各种组合,例如ChangeNotifier Provider / StateNotifier Provider( freezed)。各…...

【Linux】从零开始使用多路转接IO --- poll
碌碌无为,则余生太长; 欲有所为,则人生苦短。 --- 中岛敦 《山月记》--- 从零开始使用多路转接IO 1 前言1 poll接口介绍3 代码编写4 总结 1 前言 上一篇文章我们学习了多路转接中的Select,其操作很简单,但有一些缺…...

Docker配置宿主机目录和网络映射
容器挂载宿主机目录 在Docker中,你可以通过-v或--volume选项将宿主机的目录挂载到容器中。这可以让你在容器和宿主机之间共享文件。 例如,如果你想将宿主机的/home/user/data目录挂载到容器的/data目录,你可以使用以下命令: do…...

第十七课 component组件解析
component组件解析 component组件的写法在众多组件写法中算是比较简单的,component组件结构组成如下: 1)组件名 2)组件模板 3)利用Vue对象进行生成 基础示例: <div id"app"><test>…...

求余和求模是不是一样的,就要看看计算机中的 fix 和 floor 区别
在计算机中,fix和floor是两个不同的取整函数,它们各自有不同的取整规则。以下是fix和floor的详细区别: 一、定义与功能 fix函数 定义:fix函数是朝零方向取整的函数,即它会返回小于或等于(对于正数…...

00 递推和递归的核心讲解
递归的步骤 说 f(n)含义返回/xx f(n)等价式子在第二步中观察趋势,发现边界值(分类递归)和终止值(return) 递归优化思路 记忆化 递推/动态规划的步骤 说f(n)含义循环 关系式列 初值 综上,题目分为两类&a…...

深度学习常用开源数据集介绍【持续更新】
DIV2K 介绍:DIV2K是一个专为 图像超分辨率(SR) 任务设计的高质量数据集,广泛应用于计算机视觉领域的研究和开发。它包含800张高分辨率(HR)训练图像和100张高分辨率验证图像,每张图像都具有极高…...

LVGUI字体瘦身实战:如何为你的IoT设备定制一个超小的中文字体库
LGVUI字体瘦身实战:为IoT设备定制超小中文字体库的工程化解决方案 在嵌入式物联网设备开发中,每一KB的Flash和RAM都弥足珍贵。当你的智能温控器需要显示"当前温度:25℃"或者电子秤要呈现"净重:0.5kg"时&#…...

高效浏览器视频嗅探工具:猫抓扩展完整使用指南
高效浏览器视频嗅探工具:猫抓扩展完整使用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch)…...

构建动态技能图谱:从数据模型到自动化可视化的完整实践
1. 项目概述:一个技能图谱的诞生最近在GitHub上看到一个挺有意思的项目,叫dortort/skills。乍一看,这只是一个个人仓库,但点进去你会发现,它远不止是一个简单的代码集合。它更像是一张动态的、可视化的个人技能地图&am…...

Apache Burr:用状态机模式构建Python流式应用
1. 项目概述:一个用于构建流式应用的Python框架最近在折腾一些实时数据处理和模型推理的项目,从简单的日志分析到复杂的在线推荐,总感觉现有的工具链要么太重,要么太散。想要一个既能处理流式数据,又能轻松集成机器学习…...

AI原生产品管理:多智能体协作如何重塑产品开发工作流
1. 项目概述:当AI成为你的产品经理最近在GitHub上看到一个挺有意思的项目,叫NathanJCW/ai-native-pm-cortex。光看名字,你大概能猜到它想做什么——“AI原生的产品经理大脑”。这可不是一个简单的聊天机器人插件,它试图构建一个完…...

Biomni项目解析:大语言模型与生物医学知识图谱融合实践
1. 项目概述:当大语言模型遇见生物医学知识图谱最近在探索如何让大语言模型(LLM)在专业领域,特别是生物医学这种信息密集、关系复杂的领域,变得更“靠谱”一点。相信很多同行都遇到过类似的问题:直接问Chat…...

g1810,g3810,ip2700,g5080,g1800,ts3380,TS8380,ts6480报错5B00,P07,E08,5b02,1704,1700,5b04,佳能v6.200,亲测有用。
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...
)
ElevenLabs克隆成功率从31%飙升至96.7%:基于LPC共振峰校准+Prosody Transfer双引擎微调法(实测数据包已脱敏上传)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs语音克隆方法概览 ElevenLabs 提供了高保真、低延迟的语音克隆能力,其核心依赖于少量高质量语音样本(通常 1–3 分钟)与上下文感知的零样本/少样本微调技术…...

WarcraftHelper:魔兽争霸3终极增强插件5分钟快速上手指南
WarcraftHelper:魔兽争霸3终极增强插件5分钟快速上手指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专为魔兽争…...

中鼎智能冲刺港股:年营收18.8亿 诺力股份是实控股东
雷递网 雷建平 5月16日中鼎智能(无锡)科技股份有限公司(简称:“中鼎智能”)日前更新招股书,准备在港交所上市。截至2026年3月31日止三个月,与上年同期相比,中鼎智能录得相对稳定的收…...