基于CNN-RNN的影像报告生成
项目源码获取方式见文章末尾! 600多个深度学习项目资料,快来加入社群一起学习吧。
《------往期经典推荐------》
项目名称
1.【PaddleNLP的FAQ问答机器人】
2.【卫星图像道路检测DeepLabV3Plus模型】
3.【GAN模型实现二次元头像生成】
4.【CNN模型实现mnist手写数字识别】
5.【fasterRCNN模型实现飞机类目标检测】
6.【CNN-LSTM住宅用电量预测】
7.【VGG16模型实现新冠肺炎图片多分类】
8.【AlexNet模型实现鸟类识别】
9.【DIN模型实现推荐算法】
10.【FiBiNET模型实现推荐算法】
11.【钢板表面缺陷检测基于HRNET模型】
…
1. 项目简介
本项目旨在通过深度学习模型自动生成医疗影像的文本描述,特别是针对X光影像的诊断报告编写。该项目基于当前热门的Encoder-Decoder框架,将卷积神经网络(CNN)与循环神经网络(RNN)结合,充分发挥两者在图像特征提取与序列生成方面的优势。在项目中,使用ResNet-101模型从图像中提取特征,再将这些特征输入长短期记忆网络(LSTM),以生成适用于医学诊断的文本描述。医学影像自动报告生成在医疗行业中具有重要应用价值,通过将深度学习模型应用于影像分析,帮助医生减少误诊并节省时间,支持资深医生专注于病人的治疗,尤其适合用于具有重复性工作的影像科。在数据集选择上,本项目使用了印第安纳大学胸部X光图像数据集,专注于FINDINGS部分,项目的文本生成模型将进一步增强医疗图像领域中自动化辅助诊断的能力。

2.技术创新点摘要
首先,项目利用了基于ImageNet预训练的ResNet-101模型进行医学影像特征提取,并且在去除ResNet的全连接层后,通过恒等映射(identity mapping)进一步优化特征的提取与保持,避免了在传输至LSTM前的特征信息丢失。这一设计有效地保留了图像的全局特征,有助于后续文本生成阶段获取更加丰富的上下文信息。此外,使用ResNet-101预训练模型不仅提高了模型的泛化能力,也通过迁移学习减少了对大规模医疗数据标注的需求,这在医学影像报告生成的任务中尤其实用。
其次,项目在数据处理阶段通过解析XML格式的医疗影像报告,自动生成包含影像描述的CSV文件,并对描述文本进行清洗和标准化处理。这样的文本预处理步骤显著提升了数据质量,并在后续的字典构建中使用了频率统计方法。该方法剔除仅出现一次的低频单词,从而使模型的词汇表更为精简且高效,减少稀疏词汇对模型训练的干扰。这一过程通过对描述词汇的频率排序与筛选,大幅优化了文本生成模型的训练效果。
最后,在文本生成方面,项目构建了一个高效的词汇表字典,包括了特别设计的符号(如、、、),用于处理文本的序列化表示。这一设计不仅确保了文本生成的连续性,还通过特殊符号的引入提升了模型在应对不完整或未知文本片段时的表现。总体而言,项目创新性地结合了图像特征提取的预训练迁移学习、低频词过滤的词汇优化及符号标记等技术,形成了针对医疗影像描述生成任务的高效端到端模型。
3. 数据集与预处理
本项目使用的数据集为印第安纳大学胸部X射线集合(IU X射线),该数据集包括7470对胸部X射线图像及其相应的诊断报告。每张图像对应的报告包含多个部分(如印象、发现等),项目仅选择FINDINGS部分用于生成影像描述文本。该数据集图像质量高,内容涉及广泛的医学诊断标签,平均每张图像包含2.2个标签和约5.7个句子,这使得模型能基于丰富的语义特征生成专业的影像描述。
在数据预处理方面,项目首先对原始数据进行解压和解析,将XML格式的报告文本转化为结构化的CSV文件,并提取与影像对应的FINDINGS内容。为了确保输入数据质量,文本数据经过清洗,去除了无意义的标点和符号,并统一为小写。图像数据则经过一系列预处理操作,包括归一化和尺寸调整,以便于输入深度学习模型。特别地,项目通过ImageNet预训练的ResNet-101模型进行图像特征提取,删除模型最后的全连接层,将图像转换为2048维特征向量,便于后续的文本生成。
此外,项目在文本预处理过程中建立了词汇表,通过词频统计剔除仅出现一次的低频词,确保模型的词汇表精简且高效。这一步骤有助于减少数据稀疏性,提高模型训练效率并增强生成文本的准确性。整体预处理流程确保了图像和文本输入的标准化,为模型的训练与推理奠定了高质量的数据基础。
4. 模型架构
- 模型结构的逻辑
本项目的模型架构基于ResNet-101和LSTM的组合,旨在从医学影像中生成描述性文本。首先,ResNet-101网络(去除了最后的全连接层)被用于提取X光影像的特征,产生一个2048维的特征向量,并通过一个线性层映射到嵌入维度。此特征向量作为序列生成的初始输入,用于提供影像的全局上下文信息。LSTM网络是文本生成的核心部分,使用多层架构来增强模型的记忆和生成能力。LSTM的输入包含影像特征和词汇表嵌入(embedding),词汇表通过词嵌入层(Embedding Layer)实现,生成的序列依次预测单词,最终通过全连接层映射至词汇空间。
模型还配备了生成模块,通过“束搜索”(Beam Search)算法优化生成文本。束搜索算法可以在预测过程中维持多个可能的序列路径,从而生成质量更高的描述文本,避免了简单贪心搜索可能带来的语句质量下降。
- 模型的整体训练流程和评估指标
模型训练流程分为数据预处理、特征提取、序列生成及评估几个主要步骤:
- 数据加载与划分:数据按80:20的比例划分为训练集和验证集,所有图像特征均通过ResNet-101提取并存储。文本数据经过词典映射处理,生成序列化输入,设定了和标记以保证文本生成的完整性。
- 训练过程:训练时,影像特征向量通过嵌入层与文本序列一起输入LSTM网络,生成的预测序列在输出层进行词汇映射。目标序列标签与预测结果进行交叉熵损失计算,从而优化模型权重。整个训练通过批次加载器(DataLoader)以批量输入方式实现,每个批次均采用填充和截断策略(padding/truncating)来处理不等长的序列。
- 评估指标:在验证过程中,项目采用常用的文本生成评价指标(如BLEU得分)对生成的描述文本进行评估,以衡量生成文本与真实报告的相似性。BLEU得分的高低直接反映了模型在影像描述生成中的准确性和流畅性。此外,还通过观察生成文本的词汇丰富度、句子结构等方面的表现,来评估模型的实际生成效果。
5. 核心代码详细讲解
1) 特征工程:ResNet特征提取与保存
暂时无法在飞书文档外展示此内容
model = resnet101(pretrained=True):加载ImageNet上预训练的ResNet-101模型,用于医学影像特征提取。del model.fc:移除ResNet最后的全连接层,避免对图像特征进行任何进一步的分类或降维,以保持特征信息的完整性。model.fc = lambda x: x:将全连接层替换为恒等映射,使得ResNet的输出直接成为2048维度的特征向量。h5py.File(...):创建一个用于保存图像特征的h5文件,使得特征存储便于后续调用。
2) 数据读取与预处理:处理XML报告文本生成CSV
暂时无法在飞书文档外展示此内容
xml2csv(path):解析XML格式的医疗报告文件,提取图像路径和对应的报告FINDINGS部分,生成结构化的CSV文件。glob.glob(path + '/*.xml'):遍历指定路径下所有XML文件,读取医学影像的描述。itemlists = root.getElementsByTagName('parentImage'):从XML结构中找到每个影像的路径信息,结合后续的文本字段保存为CSV格式。
3) 模型架构:图像到文本生成模型定义
暂时无法在飞书文档外展示此内容
self.fc = paddle.nn.Linear(2048, embedding_dim):将ResNet提取的2048维特征映射到词嵌入空间,便于与词汇嵌入一同输入LSTM网络。self.embedding = paddle.nn.Embedding(vocab_size, embedding_dim):定义词嵌入层,将词汇表映射到高维空间,增强序列生成的表达能力。self.rnn = paddle.nn.LSTM(...):LSTM层构建,用于序列化特征输入,生成描述文本。
4) 训练与评估:束搜索算法生成文本
暂时无法在飞书文档外展示此内容
beam_search(...):采用束搜索(Beam Search)算法生成文本描述。此算法可以维持多个候选序列,从中选出最佳描述。TopN(self.beam_size):维护束搜索的前beam_size个候选描述,以确保候选序列的质量。get_topk_words(...):返回最高概率的k个词,用于扩展候选序列。
6. 模型优缺点评价
优点
- 特征提取精准:通过预训练的ResNet-101模型获取高质量图像特征,保留了丰富的医学影像细节,增强了对影像细节的描述能力。
- 结合LSTM序列生成:模型结合了LSTM网络,在生成影像描述时利用上下文关系,提高了生成文本的连贯性与医学用词准确性。
- 束搜索算法优化:采用束搜索在生成文本过程中进行优化,提升生成描述的流畅性和准确度。
缺点
- 依赖大规模标注数据:模型对标注数据依赖性较高,而医疗影像数据标注成本昂贵,数据不足可能导致模型生成的描述不够准确。
- 生成速度相对较慢:束搜索虽然提升了生成质量,但在大束宽度下导致生成速度变慢,可能不适合实时应用。
- 缺少多模态增强:仅基于影像特征生成文本,未能结合其他患者信息(如病史、检查结果等),限制了生成文本的全面性。
改进方向
- 数据增强与迁移学习:可引入对图像的更丰富的增强方法,如随机裁剪、旋转等,增加模型的泛化能力。还可以尝试其他医学影像数据集的迁移学习,丰富模型的特征表示。
- 超参数调整:可调节LSTM层数、隐层维度或束搜索宽度,以在生成质量与速度之间取得平衡。
- 多模态融合:将患者的文本数据(如电子病历)与影像数据结合,构建多模态模型,以生成更加个性化、细致的描述。
全部项目数据集、代码、教程点击下方名片
相关文章:
基于CNN-RNN的影像报告生成
项目源码获取方式见文章末尾! 600多个深度学习项目资料,快来加入社群一起学习吧。 《------往期经典推荐------》 项目名称 1.【PaddleNLP的FAQ问答机器人】 2.【卫星图像道路检测DeepLabV3Plus模型】 3.【GAN模型实现二次元头像生成】 4.【CNN模型实现…...

MacOS如何读取磁盘原始的扇区内容,恢复误删除的数据
MacOS 也是把磁盘当成一个文件,也是可以使用 dd来读取,命行令行如下: sudo dd if/dev/disk2 bs512 count1 skip100 ofsector_100.bin 这个就是读取 /dev/disk2这个磁盘每100这个sector, bs表示扇区大小是512. 但是你直接用读,应…...

创客匠人:打造IP陷入迷茫?20位大咖直播如何破局,实现财富增长
就在明天! 11月4日-8日,全球创始人IP领袖峰会线上启动会——《2025年知识IP创新增长训练营*20位各界大咖标杆集体赋能》直播活动,即将重磅来袭! 20位行业大咖5大篇章主题内容的强大组合,将为你逐一精彩呈现ÿ…...

视觉目标检测标注xml格式文件解析可视化 - python 实现
视觉目标检测任务,通常用 labelimage标注,对应的标注文件为xml。 该示例来源于开源项目:https://gitcode.com/DataBall/DataBall-detections-100s/overview 读取 xml 标注文件,并进行可视化示例如下: #-*-coding:ut…...

clion远程配置docker ros2
CLION与docker中的ROS2环境构建远程连接 设备前提开启SSH服务CLION配置CLION配置CLION IDE远程连接过程实现CLION SSH 远程部署 开启fastlio2debug之旅 设备前提 本地宿主机:UBUNTU 20.04 docker container:ros2_container (内置环境ROS2 humble) 通过之前的tcp连接…...

微信小程序 uniapp 腾讯地图的调用
/* 提前在您的app.json上加上这些代码 "permission": { "scope.userLocation": { "desc": "你的位置信息将用于地图中定位" } …...
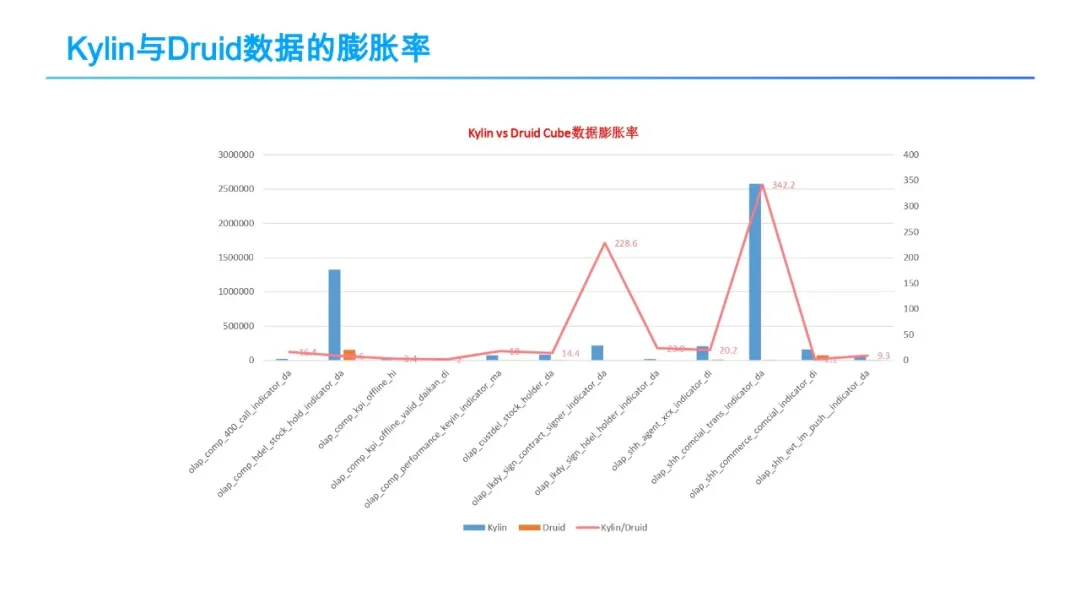
OLAP平台架构演化历程
OLAP平台架构演化历程 0 导读 随着大数据的持续发展及数字化转型的兴起,大数据OLAP分析需求越来越迫切,不论是大型互联网企业,还是中小型传统企业,都在积极探索及实践OLAP引擎选型及平台架构建设,大数据技术的蓬勃发展…...

OmniGen: Unified Image Generation(代码的复现)
文章目录 论文简介模型的部署需要下载的预训练权重 模型的生成效果图像编辑的效果风格迁移的效果 总结 论文简介 OmniGen的github项目地址 OmniGen: Unified Image Generation。OmniGen 在各种图像生成任务中都表现出了卓越的性能,并可能大大超过现有扩散模型的极…...

keepalive+mysql8双主
1.概述 利用keepalived实现Mysql数据库的高可用,KeepalivedMysql双主来实现MYSQL-HA,我们必须保证两台Mysql数据库的数据完全一致,实现方法是两台Mysql互为主从关系,通过keepalived配置VIP,实现当其中的一台Mysql数据库…...

C#-基础构造函数、析构函数
一:基础的构造函数 实例化对象时 调用的函数,主要是用来初始化成员变量的。 在构造函数时,对象的初始化是自动完成的,为默认值,但为满足一些特殊数据的初始化操作。可不使用系统默认给的构造函数 基本语法ÿ…...

Ubuntu删除docker
文章目录 安装依赖1.安装操作系统:2.CPU支持 安装docker1.查看系统版本2.执行卸载 安装依赖 1.安装操作系统: 高于 Ubuntu 20.04(LTS) 版本 2.CPU支持 ARM和X86_64 安装docker 1.查看系统版本 cat /etc/*releas*uname -a2.执行卸载 检查本地dock…...

系统地介绍Qt的QtConcurrent模块
本文使用了AI生成的内容,请注意甄别! 本文系统地介绍Qt的QtConcurrent模块,它允许开发者无需使用低级线程原语(如互斥锁、读写锁、等待条件或信号量)即可编写多线程程序。下面将由浅入深地逐步介绍这一内容:…...

【进阶sql】复杂sql收集及解析【mysql】
开发时会出现,必须写一些较复杂sql的场景 可能是给会sql的客户 提供一些统计sql 或是临时需要统计数据信息但是 开发一个统计功能有来不及的情况 也可能是报表系统组件 只支持 sql统计的情况 特地记录下这些sql 作为积累 substring 截取查询出的字符串ÿ…...

达梦检查工具dmdbchk的性能
摘要: 本文介绍了dmdbchk的基础使用,例如检查信号量,其性能大约是10GB/分钟,新版本的会更快。 当数据库出问题时,可能会考虑用dmdbchk工具检查数据文件和库内部是否出现异常。对于450G的库会耗时多久? 答&…...

Docker是什么
docker是什么 docker本质docker和虚拟机的区别docker架构Docker Registry镜像仓库分类镜像仓库工作机制docker Hub docker本质 Docker 本质其实是 LXC 之类的增强版,它本身不是容器,而是容器的易用工具。容 器是 linux 内核中的技术,Docker 只…...

Vue进阶指南:Watch 和 Computed 的深度理解
前言 在 Vue.js 开发中,我们常常会用到 watch 和 computed。虽然它们都能用来监听和处理数据的变化,但在使用场景和性能上有显著的区别。本篇文章会通过通俗易懂的方式给你讲解 Vue.js 中 watch 和 computed 的区别和使用方法。 基本概念 Computed&am…...

51c大模型~合集12
我自己的原文哦~ https://blog.51cto.com/whaosoft/11564858 #ProCo 无限contrastive pairs的长尾对比学习 , 个人主页:https://andy-du20.github.io 本文介绍清华大学的一篇关于长尾视觉识别的论文: Probabilistic Contrastive Learning for Long-Tailed Visua…...

大模型 RAG 面试真题大全
最近这一两周不少互联网公司都已经开始秋招提前批面试了。 不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。 最近,我们又陆续整理了很多大厂的面试题,帮助一些球友…...

【django】Django REST Framework 构建 API:APIView 与 ViewSet
目录 1、APIView 2、ViewSet 3、APIVIew例子 3.1 模型定义 3.2 序列化器定义 3.3 使用视图 3.3.1 ProductListCreateAPIView 类 3.3.2 ProductRetrieveUpdateDestroyAPIView 类 3.4 配置url 3.5 测试 3.5.1 查询全部 3.5.2 添加产品 3.5.3 查询单个产品 3.5.4 修…...

TOEIC 词汇专题:旅游计划篇
TOEIC 词汇专题:旅游计划篇 制定旅行计划时,尤其是跨国旅游,会涉及到很多独特的英语词汇。以下是与“旅游计划”相关的托业词汇,帮助你更加自如地规划行程。 1. 旅行服务和优惠 出发前了解一下与服务和优惠相关的常用词汇&#…...

个人自动化技能库构建指南:从Python脚本到Cron定时任务
1. 项目概述:一个为“摸鱼”场景设计的自动化技能库最近在GitHub上看到一个挺有意思的项目,叫my-copaw-skill。光看这个名字,就透着一股子“打工人”的幽默感——“copaw”这个词,我琢磨着应该是“copilot”(副驾驶/助…...

别再死记硬背了!用这5个真实项目案例,彻底搞懂Python函数参数与返回值
别再死记硬背了!用这5个真实项目案例,彻底搞懂Python函数参数与返回值 函数是Python编程的基石,但很多初学者在学完基础语法后,面对实际项目依然无从下手。本文将通过5个真实开发场景,带你从"会用"到"懂…...

Speechless:三步完成微博PDF备份的终极免费Chrome扩展
Speechless:三步完成微博PDF备份的终极免费Chrome扩展 【免费下载链接】Speechless 把新浪微博的内容,导出成 PDF 文件进行备份的 Chrome Extension。 项目地址: https://gitcode.com/gh_mirrors/sp/Speechless 在数字时代,我们的社交…...

Zotero插件市场:三步快速上手的插件管理神器
Zotero插件市场:三步快速上手的插件管理神器 【免费下载链接】zotero-addons Zotero Add-on Market | Zotero插件市场 | Browsing, installing, and reviewing plugins within Zotero 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-addons 想象一下&a…...

5大优势解析:如何高效使用免费离线OCR工具
5大优势解析:如何高效使用免费离线OCR工具 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。 项目…...

如何用PCL2启动器打造完美的Minecraft模组体验:从零到精通的完整指南
如何用PCL2启动器打造完美的Minecraft模组体验:从零到精通的完整指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL 你是否厌倦了每次启动Minecraft都要手动配…...

终极qmcdump指南:5分钟掌握QQ音乐加密格式解密技巧
终极qmcdump指南:5分钟掌握QQ音乐加密格式解密技巧 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump qmcdump是…...

Qdrant客户端库实战:从向量数据库连接到生产级应用开发
1. 项目概述:从向量数据库到应用落地的桥梁如果你最近在折腾大模型应用,或者想给自己的产品加上一个“智能大脑”,那你大概率绕不开一个词:向量数据库。简单来说,它就像一个能理解“意思”的超级搜索引擎,不…...

别再让某个用户占满硬盘了!手把手教你用Linux quota给CentOS 7/8的/home目录设置磁盘限额
别再让某个用户占满硬盘了!手把手教你用Linux quota给CentOS 7/8的/home目录设置磁盘限额 想象一下这样的场景:你管理的服务器上,十几个开发人员共享着同一个存储空间。某天突然收到警报——磁盘空间不足!调查后发现,一…...
)
别再让用户等上传!用@ffmpeg/ffmpeg在浏览器里直接压缩视频(附ThinkPHP项目实战)
浏览器端视频压缩实战:基于FFmpeg.wasm与ThinkPHP的高效集成方案 引言 在当今内容为王的互联网时代,视频已成为用户生成内容(UGC)的核心载体。然而,高清视频带来的大文件体积往往成为用户体验的瓶颈——上传等待时间长…...