最全Kafka知识宝典之Kafka的基本使用
一、基本概念
传统上定义是一个分布式的基于发布/订阅模式的消息队列,主要应用在大数据实时处理场景,现在Kafka已经定义为一个分布式流平台,用于数据通道处理,数据流分析,数据集成和关键任务应用
必须了解的四个特性:
1、Kafak可以无缝的支持多个生产者,也支持多个消费者从一个单独的消息流中读取数据,且各个消费者之间互不影响
2、Kafka还允许消费者非实时读取消息,因为Kafka将消息按一定顺序持久化到磁盘,保证了数据不会丢失,顺序写磁盘的效率比随机写内存还要高,而且以时间复杂度为O(1)的方式提供消息持久化能力,对TB级以上的数据也能保证常数时间的访问性能。
3、由于Kafka可横向扩展生产者、消费者、broker,使得集群可以轻松处理巨大的消息流,在处理大量数据的同时,还能保证亚秒级的消息延迟,实时性极高。
4、Kafka消息都会在集群中进行备份,每个分区都有一台server作为leader,其他server作为follwers,当leader宕机了,follower中的一台server会自动成为新的leader,继续有条不紊的工作,所以容错性很高且集群的负载是平衡的。
一句话总结Kafka:
Kafka 适合高吞吐量、低延迟和大规模数据流处理的场景,尤其是需要实时数据传输和处理的大数据应用,而其他 MQ 在这些方面可能无法满足性能要求。
二、Kafka的架构

从上图就可以看出,Kafka的几个核心角色:生产者、消费者、Broker、zookeeper
product
生产者可以向消息队列发送各种类型的消息,由消费者消费。
这里注意,这里的生产者是可以有多个生产者服务的实例的
consumer
消费者从broker中消费消息。
这里需要注意,消费者也可以包含多个消费者实例,去消费同一个topic中的消息
总结:生产者与消费者都可以有多个,他们之间由topic来绑定关系
zookeeper
ZooKeeper 负责跟踪 Kafka 集群中的所有 Broker 节点,确保每个节点的状态(在线或离线)都被准确记录。其主要目的就是对所有broker做管理。比如:当某个主题的分区需要选举一个新的领导者时,ZooKeeper 负责协调这一过程,确保选举过程的公平性和一致性。
Broker
Broker就是Kafka消息服务的实例,可以部署多个broker形成kafka集群,在broker当中主要由下面这么几个角色来组成,我们以数据库的形式来类比介绍:
topic
这个相当于数据库中的数据表名,一个业务有一张表,也就是有一个topic,生产者往这个topic写消息,消费者从这个topic读消息
partition
这个相当于分表的概念,一张数据表太大了,查询影响性能,所以将一张大表水平拆分成多张表。所以partition就是将一个大的topic数据拆分成多个分区
Replication
这个是对每个partition做个备份,指定了一个partition需要多少个备份,那么我就会备份几份均匀分配到集群中所有的broker上
Leader&Follower
每个分区都有一个leader以及0个或者多个follower,在创建topic时,Kafka会将每个分区的leader均匀地分配在每个broker上,我们正常使用kafka是感觉不到leader、follower的存在的。
但其实,所有的读写操作都是由leader处理,而所有的follower都复制leader的日志数据文件,如果leader出现故障时,follower就会被选举为leader。
- Kafka中的leader负责处理读写操作,而follower只负责副本数据的同步
- 如果leader出现故障,其他follower会被重新选举为leader
- follower像一个consumer一样,拉取leader对应分区的数据,并保存到日志数据文件中
三、消息模型
消息由生产者发送到kafka集群后,会被消费者消费,一般来说我们的消费模型有两种:推送模型(psuh)和拉取模型(pull)
首先明确一下推拉模式到底是在讨论消息队列的哪一个步骤,一般而言我们在谈论推拉模式的时候指的是 Comsumer 和 Broker 之间的交互。
默认的认为 Producer 与 Broker 之间就是推的方式,即 Producer 将消息推送给 Broker,而不是 Broker 主动去拉取消息。
推模式
推模式指的是消息从 Broker 推向 Consumer,即 Consumer 被动的接收消息,由 Broker 来主导消息的发送
优点:
- 消息实时性高, Broker 接受完消息之后可以立马推送给 Consumer
- 对于消费者使用来说更简单,简单啊就等着,反正有消息来了就会推过来。
缺点:
- 推送速率难以适应消费速率,推模式的目标就是以最快的速度推送消息,当生产者往 Broker 发送消息的速率大于消费者消费消息的速率时,随着时间增长就会把消费者撑死,因为根本消费不过来啊
- 并且不同的消费者的消费速率还不一样,身为 Broker 很难平衡每个消费者的推送速率,如果要实现自适应的推送速率那就需要在推送的时候消费者告诉 Broker ,我不行了你推慢点吧,然后 Broker 需要维护每个消费者的状态进行推送速率的变更。
拉模式
拉模式指的是 Consumer 主动向 Broker 请求拉取消息,即 Broker 被动的发送消息给 Consumer
优点:
- 拉模式主动权就在消费者身上了,消费者可以根据自身的情况来发起拉取消息的请求,假设当前消费者觉得自己消费不过来了,它可以根据一定的策略停止拉取,或者间隔拉取都行。
- 拉模式下 Broker 就相对轻松了,它只管存生产者发来的消息,至于消费的时候自然由消费者主动发起,来一个请求就给它消息呗,从哪开始拿消息,拿多少消费者都告诉它,它就是一个没有感情的工具人,消费者要是没来取也不关它的事。
- 拉模式可以更合适的进行消息的批量发送,基于推模式可以来一个消息就推送,也可以缓存一些消息之后再推送,但是推送的时候其实不知道消费者到底能不能一次性处理这么多消息,而拉模式就更加合理,它可以参考消费者请求的信息来决定缓存多少消息之后批量发送。
缺点:
- 消息延迟,毕竟是消费者去拉取消息,但是消费者怎么知道消息到了呢?所以它只能不断地拉取,但是又不能很频繁地请求,太频繁了就变成消费者在攻击 Broker 了,因此需要降低请求的频率,比如隔个 2 秒请求一次,你看着消息就很有可能延迟 2 秒了。
- 消息忙请求,忙请求就是比如消息隔了几个小时才有,那么在几个小时之内消费者的请求都是无效的,在做无用功。
Kafka是什么模式
RocketMQ 和 Kafka 都选择了拉模式,当然业界也有基于推模式的消息队列如 ActiveMQ
Kafka采用了一种长轮询模式,这是基于拉模式的
Kafka 在拉请求中有参数,可以使得消费者请求在 “长轮询” 中阻塞等待。
简单的说就是消费者去 Broker 拉消息,定义了一个超时时间,也就是说消费者去请求消息,如果有的话马上返回消息,如果没有的话消费者等着直到超时,然后再次发起拉消息请求。注意:阻塞是发生在broker端的。
并且 Broker 也得配合,如果消费者请求过来,有消息肯定马上返回,没有消息那就建立一个延迟操作,等条件满足了再返回
四、Kafka的安装使用
1、安装
我们以三点Kafka节点的形式对Kafka进行安装部署
创建数据目录
mkdir -p /tmp/kafka/broker{1..3}/{data,logs}创建配置文件
vi docker-compose.yamlversion: '2'
services:zookeeper:container_name: zookeeperimage: wurstmeister/zookeeperrestart: unless-stoppedhostname: zoo1ports:- "2181:2181"networks:- kafkakafka1:container_name: kafka1image: wurstmeister/kafkaports:- "9092:9092"environment:KAFKA_ADVERTISED_HOST_NAME: 192.168.245.253 ## 修改:宿主机IPKAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.245.253:9092 ## 修改:宿主机IPKAFKA_ZOOKEEPER_CONNECT: "zoo1:2181"KAFKA_ADVERTISED_PORT: 9092KAFKA_BROKER_ID: 1KAFKA_LOG_DIRS: /kafka/datavolumes:- /tmp/kafka/broker1/logs:/opt/kafka/logs- /tmp/kafka/broker1/data:/kafka/datadepends_on:- zookeepernetworks:- kafkakafka2:container_name: kafka2image: wurstmeister/kafkaports:- "9093:9092"environment:KAFKA_ADVERTISED_HOST_NAME: 192.168.245.253 ## 修改:宿主机IPKAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.245.253:9093 ## 修改:宿主机IPKAFKA_ZOOKEEPER_CONNECT: "zoo1:2181"KAFKA_ADVERTISED_PORT: 9093KAFKA_BROKER_ID: 2KAFKA_LOG_DIRS: /kafka/datavolumes:- /tmp/kafka/broker2/logs:/opt/kafka/logs- /tmp/kafka/broker2/data:/kafka/datadepends_on:- zookeepernetworks:- kafkakafka3:container_name: kafka3image: wurstmeister/kafkaports:- "9094:9092"environment:KAFKA_ADVERTISED_HOST_NAME: 192.168.245.253 ## 修改:宿主机IPKAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.245.253:9094 ## 修改:宿主机IPKAFKA_ZOOKEEPER_CONNECT: "zoo1:2181"KAFKA_ADVERTISED_PORT: 9094KAFKA_BROKER_ID: 3KAFKA_LOG_DIRS: /kafka/datavolumes:- /tmp/kafka/broker3/logs:/opt/kafka/logs- /tmp/kafka/broker3/data:/kafka/datadepends_on:- zookeepernetworks:- kafkakafka-manager:image: sheepkiller/kafka-manager ## 镜像:开源的web管理kafka集群的界面environment:ZK_HOSTS: 192.168.245.253 ## 修改:宿主机IPports:- "9000:9000" ## 暴露端口networks:- kafka
networks:kafka:driver: bridge启动
docker-compose up -d2、命令行使用
首先进入kafka容器内部:
docker exec -it kafka1 /bin/bash进入到Kafka安装目录
cd /opt/kafka执行脚本
创建主题
sh bin/kafka-topics.sh --zookeeper zookeeper:2181 --create --topic test查看所有主题
sh bin/kafka-topics.sh --zookeeper zookeeper:2181 -list查看分区情况
sh bin/kafka-topics.sh --zookeeper zookeeper:2181 --describe --topic test创建分区以及副本
sh bin/kafka-topics.sh --zookeeper zookeeper:2181 --create --topic test --partitions 3 --replication-factor 3扩容分区
sh bin/kafka-topics.sh --zookeeper zookeeper:2181 --partitions 4 --alter --topic test测试生产者发送消息
sh bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
测试消费者接收消息
sh bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
五、SpringBoot整合Kafka
1、添加依赖
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-kafka</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency>
</dependencies>2、配置Kafka
spring:kafka:bootstrap-servers: localhost:9092consumer:group-id: my-groupauto-offset-reset: earliestproducer:key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializerconsumer:key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer3、创建生产者
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;@Service
public class KafkaProducer {@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;public void sendMessage(String topic, String message) {kafkaTemplate.send(topic, message);System.out.println("Sent message: " + message);}
}4、创建消费者
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;@Service
public class KafkaConsumer {@KafkaListener(topics = "test", groupId = "my-group")public void consume(String message) {System.out.println("Received message: " + message);}
}相关文章:
最全Kafka知识宝典之Kafka的基本使用
一、基本概念 传统上定义是一个分布式的基于发布/订阅模式的消息队列,主要应用在大数据实时处理场景,现在Kafka已经定义为一个分布式流平台,用于数据通道处理,数据流分析,数据集成和关键任务应用 必须了解的四个特性…...

机器学习中的数据可视化:常用库、单变量图与多变量图绘制方法
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...
CodeQL学习笔记(3)-QL语法(模块、变量、表达式、公式和注解)
最近在学习CodeQL,对于CodeQL就不介绍了,目前网上一搜一大把。本系列是学习CodeQL的个人学习笔记,根据个人知识库笔记修改整理而来的,分享出来共同学习。个人觉得QL的语法比较反人类,至少与目前主流的这些OOP语言相比&…...

代码随想录训练营Day11 | 226.翻转二叉树 - 101. 对称二叉树 - 104.二叉树的最大深度 - 111.二叉树的最小深度
226.翻转二叉树 题目链接:226.翻转二叉树思路:遍历二叉树,遍历的时候交换左右节点即可代码: TreeNode* invertTree(TreeNode* root) {reverse(root);return root;}// 迭代法,层序遍历void f2(TreeNode* root) {queue…...

“死鱼眼”,不存在的,一个提词小技巧,拯救的眼神——将内容说给用户,而非读给用户!
视频录制时,死鱼眼问题常见 即便内容再好,眼神死板也会减分 痛点真痛:拍视频时容易紧张 面对镜头,许多人难免紧张 神情僵硬,眼神无光,甚至忘词 这不仅影响表现,还让人难以专注 忘我场景&#x…...

深度学习在复杂系统中的应用
引言 复杂系统由多个相互作用的组成部分构成,这些部分之间的关系往往是非线性的,整体行为难以通过简单的线性组合来预测。这类系统广泛存在于生态学、气象学、经济学和社会科学等多个领域,具有动态演变、自组织、涌现现象以及多尺度与异质性…...

vue3图片懒加载
背景 界面很长,屏幕不能一下装下所有内容,如果以进入首页就把所有内容都加载完的话所需时间较长,会影响用户体验,所以可以当用户浏览到时再去加载。 代码 新建index.ts文件 src下新建directives文件夹,并新建Index…...

总结一些高级的SQL技巧
1. 窗口函数 窗函数允许在查询结果的每一行上进行计算,而不需要将数据分组。这使得我们可以计算累积总和、排名等。 SELECT employee_id,salary,RANK() OVER (ORDER BY salary DESC) AS salary_rank FROM employees;2. 公用表表达式 (CTE) CTE 提供了一种更清晰的…...

无人机飞手考证热,装调检修技术详解
随着无人机技术的飞速发展和广泛应用,无人机飞手考证热正在持续升温。无人机飞手不仅需要掌握飞行技能,还需要具备装调检修技术,以确保无人机的安全、稳定和高效运行。以下是对无人机飞手考证及装调检修技术的详细解析: 一、无人机…...

AI资讯快报(2024.10.27-11.01)
1.<国家超级计算济南中心发布系列大模型> 10月28日,以“人才引领创新 开放赋能发展”为主题的第三届山东人才创新发展大会暨第十三届“海洽会”集中展示大会在山东济南举行。本次大会发布了国家超级计算济南中心大模型,包括“智匠工业大模型、知风…...

范式的简单理解
第二范式 消除非键属性对键的部分依赖 第三范式 消除一个非键属性对另一个非键属性的依赖 表中的每个非键属性都应该依赖于键,整个键,而且只有键(键可能为两个属性) 第四范式 多值依赖于主键...

活着就好20241103
🌞 早晨问候:亲爱的朋友们,大家早上好!今天是2024年11月3日,第44周的第七天,也是本周的最后一天,农历甲辰[龙]年十月初三。在这金秋十一月的第三天,愿清晨的第一缕阳光如同活力的源泉…...

《华为工作法》读书摘记
无论做什么事情,首先要明确的就是做事的目标。目标是引导行动的关键,也是证明行动所具备的价值的前提,所以目标管理成了企业与个人管理的重要组成部分。 很多时候,勤奋、努力并不意味着就一定能把工作做好,也并不意味…...

【Unity基础】初识UI Toolkit - 运行时UI
Unity中的UI工具包(UI Toolkit)不但可以用于创建编辑器UI,同样可以来创建运行时UI。 关于Unity中的UI系统以及使用UI工具包创建编辑器UI可以参见: 1. Unity中的UI系统 2. 初识UI Toolkit - 编辑器UI 本文将通过一个简单示例来…...

20.体育馆使用预约系统(基于springboot和vue的Java项目)
目录 1.系统的受众说明 2.开发环境与技术 2.1 Java语言 2.2 MYSQL数据库 2.3 IDEA开发工具 2.4 Spring Boot框架 3.需求分析 3.1 可行性分析 3.1.1 技术可行性 3.1.2 经济可行性 3.1.3 操作可行性 3.2 系统流程分析 3.3 系统性能需求 3.4 系统功能需求 4.系…...

unity3d————三角函数练习题
先上代码: public class SinCos : MonoBehaviour {public float moveSpeed 10f; //前进的速度public float changValue 5f; //左右的速度public float changeSize 5f; //左右的幅度float time 0;void Update(){this.transform.Translate(Vector3.forwa…...

如何在Linux系统中使用Git进行版本控制
如何在Linux系统中使用Git进行版本控制 Git简介 安装Git 在Debian/Ubuntu系统中安装 在CentOS/RHEL系统中安装 初始化Git仓库 配置全局用户信息 基本的Git命令 添加文件到暂存区 查看状态 提交更改 查看提交历史 工作流 分支管理 切换分支 合并分支 远程仓库 添加远程仓库 推…...
)
Ubuntu编译linux内核指南(适用阿里云、腾讯云等远程服务器;包括添加Android支持)
在 Ubuntu 上编译内核的步骤如下: 1、安装必要的依赖包: 这里和你chatgpt的略有不同 sudo apt-get update sudo apt-get install build-essential libncurses-dev bison flex libssl-dev libelf-dev dwarves 后续如果遇到“FAILED: load BTF from vmlinux: Invalid argum…...

[MySQL]DQL语句(一)
查询语句是数据库操作中最为重要的一系列语法。查询关键字有 select、where、group、having、order by、imit。其中imit是MySQL的方言,只在MySQL适用。 数据库查询又分单表查询和多表查询,这里讲一下单表查询。 基础查询 # 查询指定列 SELECT * FROM …...
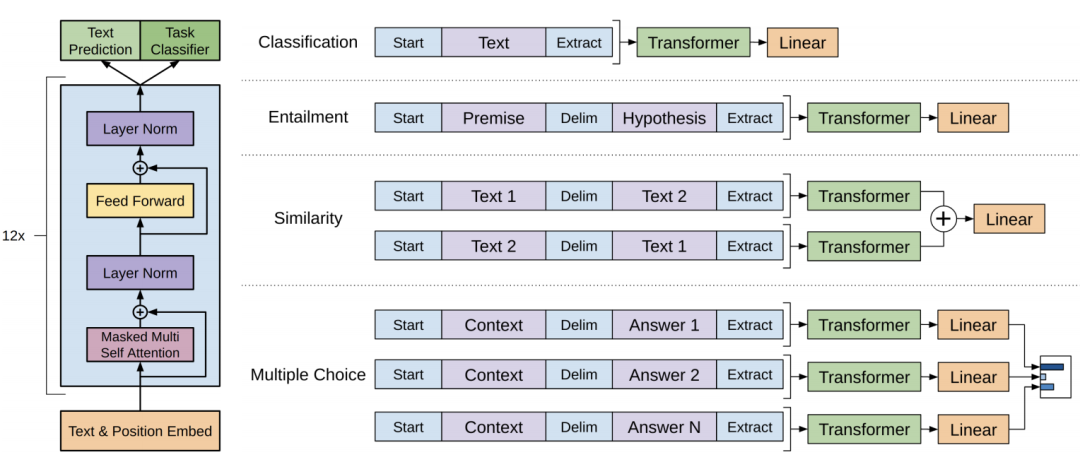
GPT原理;ChatGPT 等类似的问答系统工作流程如下;当用户向 ChatGPT 输入一个问题后:举例说明;ChatGPT不是通过索引搜索的传统知识库
目录 GPT原理 GPT架构 GPT 主要基于 Transformer 的解码器部分 ChatGPT 等类似的问答系统工作流程如下: 用户输入 文本预处理 模型处理 答案生成 输出回答 当用户向 ChatGPT 输入一个问题后:举例说明 文本预处理: ChatGPT不是通过索引搜索的传统知识库 GPT GPT…...

Sunshine游戏串流架构深度解析:3种高效部署方案完全指南
Sunshine游戏串流架构深度解析:3种高效部署方案完全指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine作为一款开源自托管的游戏串流服务器,为Mo…...

LC-SLM高精度波面生成:从原理、标定到闭环校正的完整指南
1. 项目概述与核心价值最近在实验室里折腾一个光学精密测量项目,核心需求是生成一个特定形状、高精度的光波面。这玩意儿在光学检测、自适应光学、全息成像甚至一些前沿的微纳加工领域都是刚需。比如,你想检测一个非球面镜的面形误差,最直接的…...

Verilog时钟分频实战:从偶数、奇数到小数分频的设计与实现
1. 项目概述:从零开始掌握Verilog时钟分频 在数字电路和FPGA设计中,时钟信号是驱动整个系统同步运行的“心跳”。然而,一个系统往往需要多种不同频率的时钟来驱动不同的模块,比如高速的处理器核心和低速的外设接口。直接使用多个外…...

Svelte动态光标实现:状态驱动与Spring动画的交互设计
1. 项目概述:一个会“思考”的鼠标指针如果你在开发一个需要高度沉浸感和交互反馈的Web应用,比如一个设计工具、一个游戏界面,或者一个希望用户能“感受”到页面元素质感的网站,那么一个静态的、系统默认的鼠标指针就显得有些格格…...

CircuitPython FancyLED库:专业级可寻址LED色彩动画开发指南
1. 项目概述:为什么需要FancyLED?在嵌入式开发,尤其是物联网和交互式装置项目中,可寻址LED(如NeoPixel、DotStar)已经成为构建动态视觉反馈的核心组件。无论是制作一个会呼吸的氛围灯,还是一个能…...
)
ElevenLabs匈牙利语音合成效果深度测评(实测12种场景+WAV/MP3/SSML对比数据)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs匈牙利语音合成技术概览 ElevenLabs 自 2023 年起逐步扩展其多语言支持能力,匈牙利语(hu-HU)作为东欧高复杂度音系语言的代表,于 v2.5 API 版本…...

从真空袋到回流焊:一份给硬件创业团队的元器件储存与使用避坑指南
从真空袋到回流焊:硬件创业团队的元器件储存与使用避坑指南 当你拆开一包全新的芯片,是否曾想过这些看似坚固的小方块其实对环境湿度极其敏感?对于资源有限的硬件创业团队来说,正确处理MSL(湿度敏感等级)元…...

Raspberry Pi Imager终极指南:快速上手树莓派系统安装
Raspberry Pi Imager终极指南:快速上手树莓派系统安装 【免费下载链接】rpi-imager The home of Raspberry Pi Imager, a user-friendly tool for creating bootable media for Raspberry Pi devices. 项目地址: https://gitcode.com/gh_mirrors/rp/rpi-imager …...

BES平台音频算法集成避坑指南:从声加ENC案例看副核调度与内存优化
BES平台音频算法深度优化:从ENC案例剖析多核调度与内存管理 在蓝牙音频芯片领域,BES平台凭借其出色的能效比和灵活的架构设计,已成为众多高端TWS耳机厂商的首选方案。然而,当工程师们尝试将ENC(环境噪声消除࿰…...

终极M3U8视频下载神器:3步搞定加密流媒体!
终极M3U8视频下载神器:3步搞定加密流媒体! 【免费下载链接】m3u8-downloader 一个M3U8 视频下载(M3U8 downloader)工具。跨平台: 提供windows、linux、mac三大平台可执行文件,方便直接使用。 项目地址: https://gitcode.com/gh_mirrors/m3u8d/m3u8-do…...