Python 网络爬虫教程:从入门到高级的全面指南
Python 网络爬虫教程:从入门到高级的全面指南
引言
在信息爆炸的时代,网络爬虫(Web Scraping)成为了获取数据的重要工具。Python 以其简单易用的特性,成为了网络爬虫开发的首选语言。本文将详细介绍如何使用 Python 编写网络爬虫,从基础知识到高级技巧,配合实例和图示,帮助你快速掌握网络爬虫的核心概念和实践。

目录
- 什么是网络爬虫
- 环境准备
- 基础知识
- HTTP 协议
- HTML 结构
- 使用 Requests 库获取网页
- 使用 BeautifulSoup 解析 HTML
- 爬取动态网页
- 数据存储
- 反爬虫机制及应对策略
- 实战案例:爬取某电商网站商品信息
- 总结与展望
1. 什么是网络爬虫
网络爬虫是自动访问互联网并提取信息的程序。它可以用于数据采集、市场分析、学术研究等多种场景。简单来说,网络爬虫就是模拟用户在浏览器中的行为,获取网页内容。
2. 环境准备
在开始之前,你需要安装 Python 和相关库。建议使用 Python 3.x 版本。
安装 Python
你可以从 Python 官网 下载并安装最新版本。
安装必要库
使用 pip 安装 Requests 和 BeautifulSoup 库:
pip install requests beautifulsoup4
3. 基础知识
HTTP 协议
网络爬虫的基础是 HTTP 协议。HTTP(超文本传输协议)是客户端(如浏览器)与服务器之间通信的协议。常见的请求方法有:
- GET:请求数据
- POST:提交数据
HTML 结构
HTML(超文本标记语言)是网页的基本构建块。理解 HTML 结构有助于我们提取所需信息。
<!DOCTYPE html>
<html>
<head><title>示例网页</title>
</head>
<body><h1>欢迎来到我的网站</h1><p>这是一个示例段落。</p>
</body>
</html>
4. 使用 Requests 库获取网页
Requests 是一个简单易用的 HTTP 库,可以轻松发送 HTTP 请求。
示例代码
以下是一个简单的示例,获取某个网页的内容:
import requestsurl = 'http://example.com'
response = requests.get(url)if response.status_code == 200:print(response.text) # 打印网页内容
else:print('请求失败', response.status_code)
代码解析
requests.get(url):发送 GET 请求。response.status_code:检查请求是否成功。response.text:获取网页内容。
5. 使用 BeautifulSoup 解析 HTML
BeautifulSoup 是一个用于解析 HTML 和 XML 文档的库,可以方便地提取数据。
示例代码
from bs4 import BeautifulSouphtml_content = response.text
soup = BeautifulSoup(html_content, 'html.parser')# 提取标题
title = soup.title.string
print('网页标题:', title)# 提取所有段落
paragraphs = soup.find_all('p')
for p in paragraphs:print(p.text)
代码解析
BeautifulSoup(html_content, 'html.parser'):解析 HTML 内容。soup.title.string:获取网页标题。soup.find_all('p'):获取所有段落。
6. 爬取动态网页
对于使用 JavaScript 动态加载内容的网页,Requests 可能无法获取到所需数据。在这种情况下,可以使用 Selenium 库。
安装 Selenium
pip install selenium
示例代码
from selenium import webdriver# 设置 WebDriver(以 Chrome 为例)
driver = webdriver.Chrome(executable_path='path/to/chromedriver')
driver.get('http://example.com')# 获取网页内容
html_content = driver.page_source
driver.quit()soup = BeautifulSoup(html_content, 'html.parser')
# 继续解析...
代码解析
webdriver.Chrome():启动 Chrome 浏览器。driver.get(url):打开网页。driver.page_source:获取网页源代码。
7. 数据存储
爬取的数据需要存储,常见的存储方式包括 CSV 文件和数据库。
存储为 CSV 文件
import pandas as pddata = {'标题': [], '内容': []}for p in paragraphs:data['标题'].append(title)data['内容'].append(p.text)df = pd.DataFrame(data)
df.to_csv('output.csv', index=False)
代码解析
- 使用 Pandas 库创建 DataFrame。
df.to_csv('output.csv', index=False):将数据存储为 CSV 文件。
8. 反爬虫机制及应对策略
许多网站会采用反爬虫机制来防止数据被爬取。常见的策略包括:
- IP 限制:限制同一 IP 的请求频率。
- 验证码:要求用户输入验证码以验证身份。
应对策略
- 使用代理:通过代理服务器更换 IP。
- 设置请求头:伪装成浏览器请求。
示例代码
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}response = requests.get(url, headers=headers)
9. 实战案例:爬取某电商网站商品信息
示例目标
爬取某电商网站的商品名称和价格。
示例代码
import requests
from bs4 import BeautifulSoupurl = 'http://example-ecommerce.com/products'
headers = {'User-Agent': 'Mozilla/5.0'}response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')products = soup.find_all('div', class_='product')for product in products:name = product.find('h2').textprice = product.find('span', class_='price').textprint(f'商品名称: {name}, 价格: {price}')
代码解析
soup.find_all('div', class_='product'):查找所有商品的容器。product.find('h2').text:获取商品名称。product.find('span', class_='price').text:获取商品价格。
10. 总结与展望
本文详细介绍了 Python 网络爬虫的基础知识、实现步骤及实战案例。随着技术的不断发展,网络爬虫的应用场景也在不断扩大。未来,你可以结合机器学习等技术,进一步提升数据分析能力。
进一步学习
- 深入学习 Scrapy 框架。
- 探索数据清洗与分析工具(如 Pandas、NumPy)。
- 学习如何处理大规模数据。
希望这篇指南能帮助你快速上手 Python 网络爬虫!如果你有任何问题或想法,欢迎在评论区留言。
相关文章:
Python 网络爬虫教程:从入门到高级的全面指南
Python 网络爬虫教程:从入门到高级的全面指南 引言 在信息爆炸的时代,网络爬虫(Web Scraping)成为了获取数据的重要工具。Python 以其简单易用的特性,成为了网络爬虫开发的首选语言。本文将详细介绍如何使用 Python …...
详细解释)
深度学习:正则化(Regularization)详细解释
正则化(Regularization)详细解释 正则化(Regularization)是机器学习和统计建模领域中用以防止模型过拟合同时增强模型泛化能力的一种技术。通过引入额外的约束或惩罚项到模型的损失函数中,正则化能够有效地限制模型的…...

Freertos学习日志(1)-基础知识
目录 1.什么是Freertos? 2.为什么要学习RTOS? 3.Freertos多任务处理的原理 1.什么是Freertos? RTOS,即(Real Time Operating System 实时操作系统),是一种体积小巧、确定性强的计算机操作系统…...

CentOS9 Stream 支持输入中文
CentOS9 Stream 支持输入中文 方法一:确保 gnome-control-center 和相关组件已更新方法二:手动添加输入法源配置方法三:配置 .xinputrc 文件方法四:检查语言包 进入centos9 stream后,点击右上角电源键,点击…...

基于向量检索的RAG大模型
一、什么是向量 向量是一种有大小和方向的数学对象。它可以表示为从一个点到另一个点的有向线段。例如,二维空间中的向量可以表示为 (𝑥,𝑦) ,表示从原点 (0,0)到点 (𝑥,𝑦)的有向线段。 1.1、文本向量 1…...

【力扣 + 牛客 | SQL题 | 每日5题】牛客SQL热题216,217,223
也在牛客力扣写了一百来题了,个人感觉力扣的SQL题要比牛客的高三档的难度。(普遍来说) 1. 牛客SQL热题216:统计各个部门的工资记录数 1.1 题目: 描述 有一个部门表departments简况如下: dept_nodept_named001Marke…...

Unity humanoid 模型头发动画失效问题
在上一篇【Unity实战笔记】第二十二 提到humanoid 模型会使原先的头发动画失效,如下图所示: 头发摆动的是generic模型和动画,不动的是humanoid模型和动画 一开始我是尝试过在模型Optimize Game objects手动添加缺失的头发骨骼的,奈…...

最全Kafka知识宝典之Kafka的基本使用
一、基本概念 传统上定义是一个分布式的基于发布/订阅模式的消息队列,主要应用在大数据实时处理场景,现在Kafka已经定义为一个分布式流平台,用于数据通道处理,数据流分析,数据集成和关键任务应用 必须了解的四个特性…...

机器学习中的数据可视化:常用库、单变量图与多变量图绘制方法
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...
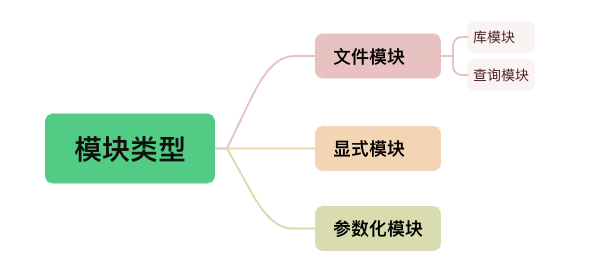
CodeQL学习笔记(3)-QL语法(模块、变量、表达式、公式和注解)
最近在学习CodeQL,对于CodeQL就不介绍了,目前网上一搜一大把。本系列是学习CodeQL的个人学习笔记,根据个人知识库笔记修改整理而来的,分享出来共同学习。个人觉得QL的语法比较反人类,至少与目前主流的这些OOP语言相比&…...

代码随想录训练营Day11 | 226.翻转二叉树 - 101. 对称二叉树 - 104.二叉树的最大深度 - 111.二叉树的最小深度
226.翻转二叉树 题目链接:226.翻转二叉树思路:遍历二叉树,遍历的时候交换左右节点即可代码: TreeNode* invertTree(TreeNode* root) {reverse(root);return root;}// 迭代法,层序遍历void f2(TreeNode* root) {queue…...

“死鱼眼”,不存在的,一个提词小技巧,拯救的眼神——将内容说给用户,而非读给用户!
视频录制时,死鱼眼问题常见 即便内容再好,眼神死板也会减分 痛点真痛:拍视频时容易紧张 面对镜头,许多人难免紧张 神情僵硬,眼神无光,甚至忘词 这不仅影响表现,还让人难以专注 忘我场景&#x…...

深度学习在复杂系统中的应用
引言 复杂系统由多个相互作用的组成部分构成,这些部分之间的关系往往是非线性的,整体行为难以通过简单的线性组合来预测。这类系统广泛存在于生态学、气象学、经济学和社会科学等多个领域,具有动态演变、自组织、涌现现象以及多尺度与异质性…...

vue3图片懒加载
背景 界面很长,屏幕不能一下装下所有内容,如果以进入首页就把所有内容都加载完的话所需时间较长,会影响用户体验,所以可以当用户浏览到时再去加载。 代码 新建index.ts文件 src下新建directives文件夹,并新建Index…...

总结一些高级的SQL技巧
1. 窗口函数 窗函数允许在查询结果的每一行上进行计算,而不需要将数据分组。这使得我们可以计算累积总和、排名等。 SELECT employee_id,salary,RANK() OVER (ORDER BY salary DESC) AS salary_rank FROM employees;2. 公用表表达式 (CTE) CTE 提供了一种更清晰的…...

无人机飞手考证热,装调检修技术详解
随着无人机技术的飞速发展和广泛应用,无人机飞手考证热正在持续升温。无人机飞手不仅需要掌握飞行技能,还需要具备装调检修技术,以确保无人机的安全、稳定和高效运行。以下是对无人机飞手考证及装调检修技术的详细解析: 一、无人机…...

AI资讯快报(2024.10.27-11.01)
1.<国家超级计算济南中心发布系列大模型> 10月28日,以“人才引领创新 开放赋能发展”为主题的第三届山东人才创新发展大会暨第十三届“海洽会”集中展示大会在山东济南举行。本次大会发布了国家超级计算济南中心大模型,包括“智匠工业大模型、知风…...

范式的简单理解
第二范式 消除非键属性对键的部分依赖 第三范式 消除一个非键属性对另一个非键属性的依赖 表中的每个非键属性都应该依赖于键,整个键,而且只有键(键可能为两个属性) 第四范式 多值依赖于主键...

活着就好20241103
🌞 早晨问候:亲爱的朋友们,大家早上好!今天是2024年11月3日,第44周的第七天,也是本周的最后一天,农历甲辰[龙]年十月初三。在这金秋十一月的第三天,愿清晨的第一缕阳光如同活力的源泉…...

《华为工作法》读书摘记
无论做什么事情,首先要明确的就是做事的目标。目标是引导行动的关键,也是证明行动所具备的价值的前提,所以目标管理成了企业与个人管理的重要组成部分。 很多时候,勤奋、努力并不意味着就一定能把工作做好,也并不意味…...

容器镜像深度解析与生产级部署实战指南
1. 项目概述:从容器镜像名到高效部署实践的深度解析最近在梳理内部容器镜像仓库时,一个名为containers/ramalama的镜像引起了我的注意。这个名字乍一看有些无厘头,甚至带点戏谑,但在容器化部署的实践中,这类看似随意的…...
)
告别python-pcl!用pclpy在Windows上轻松玩转PCL点云处理(Python 3.6/3.7保姆级教程)
告别python-pcl!用pclpy在Windows上轻松玩转PCL点云处理(Python 3.6/3.7保姆级教程) 在三维视觉和机器人领域,点云处理一直是核心技术难点之一。PCL(Point Cloud Library)作为开源领域的标杆工具库&#x…...
HSTracker:macOS平台炉石传说智能数据分析与决策辅助系统
HSTracker:macOS平台炉石传说智能数据分析与决策辅助系统 【免费下载链接】HSTracker A deck tracker and deck manager for Hearthstone on macOS 项目地址: https://gitcode.com/gh_mirrors/hs/HSTracker HSTracker是一款专为macOS平台设计的炉石传说智能套…...

Gitee领跑本土化开发体验:深度解析国内代码托管平台的选择之道
在数字化转型浪潮中,代码托管平台已成为开发者团队不可或缺的基础设施。国内市场经过多年发展,已经从单一的海外平台依赖,逐步形成了多元化的平台选择生态。其中,Gitee凭借其本土化优势脱颖而出,成为众多国内开发团队的…...

SHA-3:从海绵构造到KECCAK-p,深入解析新一代哈希函数核心
1. 为什么我们需要SHA-3? 记得我第一次接触哈希函数时,用的还是SHA-1。那时候做文件校验,用SHA-1生成个摘要,感觉既方便又安全。直到后来看到新闻说SHA-1被破解了,我才意识到密码学世界的变化有多快。这就是SHA-3诞生的…...

HPM5361EVK开发板深度体验:480MHz RISC-V MCU实战开发与性能评测
1. 项目概述:从开箱到点亮,一个真实的HPM5361EVK上手体验上次聊了HPM5361EVK开发板的开箱和硬件初印象,很多朋友后台留言,催更实际的上手体验和性能测试。确实,一块开发板好不好,光看参数和做工是远远不够的…...
)
Mac小白必看:手把手教你用终端命令重建丢失的Recovery HD分区(附详细路径解释)
Mac用户自救指南:彻底掌握Recovery HD分区修复全流程 当你发现CommandR组合键失效时,那种无助感我深有体会。去年帮朋友修复一台二手MacBook时,我们花了整整一个下午才搞明白为什么恢复模式无法启动——原来前主人为了腾出空间删除了Recovery…...

深入解析瑞芯微RK3399/RK3288平台ISP驱动:从V4L2框架到Camera Sensor联动
1. 项目概述 在嵌入式Linux开发,特别是涉及多媒体处理的项目中,图像信号处理器(ISP)驱动的理解往往是打通摄像头应用链路的关键一环,也是很多开发者感觉“黑盒”最多的地方。最近在调试基于瑞芯微RK3399和RK3288平台的…...

RabbitMQ-C测试框架深度解析:单元测试、集成测试与模糊测试
RabbitMQ-C测试框架深度解析:单元测试、集成测试与模糊测试 【免费下载链接】rabbitmq-c RabbitMQ C client 项目地址: https://gitcode.com/gh_mirrors/ra/rabbitmq-c RabbitMQ-C是一个功能强大的RabbitMQ C客户端库,为确保其稳定性和可靠性&…...

终极ModEngine2指南:从零开始掌握魂类游戏模组引擎
终极ModEngine2指南:从零开始掌握魂类游戏模组引擎 【免费下载链接】ModEngine2 Runtime injection library for modding Souls games. WIP 项目地址: https://gitcode.com/gh_mirrors/mo/ModEngine2 想要为《黑暗之魂3》或《艾尔登法环》添加自定义内容却苦…...