火山引擎VeDI数据服务平台:在电商场景中,如何解决API编排问题?
01 平台介绍
数据服务平台可以在保证服务高可靠性和高安全性的同时,为各业务线搭建数据服务统一出口,促进数据共享,为数据和应用之间建立了一座“沟通桥梁”。
同时,解决数据理解困难、异构、重复建设、审计运维困难等问题,实现统一且多样化数据服务以及数据应用价值最大化的目标。
在业务开发过程中,用户可以自行选择直查各种引擎,但各种引擎请求方式不同,返回数据格式不统一,需要针对各种引擎适配对应的查询代码,取数逻辑需要维护在代码中。
这样的取数方式,会给研发带来较大的接入成本、运维成本。当取数逻辑变更也会需要研发更改代码上线,可能导致上线期间线上取数逻辑的不一致。
而数据服务平台创建的API统一了查询和数据返回的格式,用户只需维护API中SQL的取数逻辑和请求参数即可,大大降低了上层应用获取数据的成本。
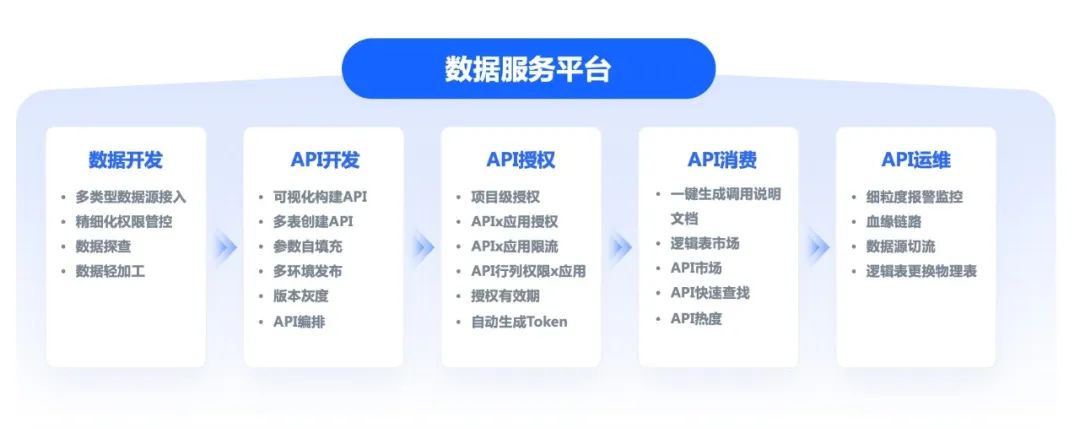
/ 领域介绍
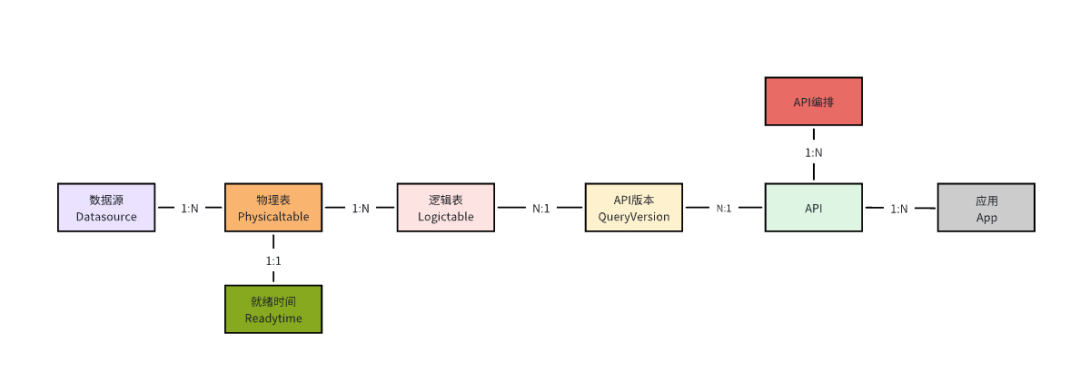
用户可以在数据服务平台上创建:项目、数据源、物理表/逻辑表、就绪时间、API、API编排,App应用(psm)等主体资源;
其中数据源包含查询数据库连接信息;物理表是底层数据源中的表;逻辑表是数据服务平台的概念,目的是能够增强物理表的能力,例如逻辑表监控报警、切换主备、授权调用等等;就绪时间是数据的最新可用日期;API和API编排是数据出口,应用即消费者身份标识。
/ 架构概览
DataLeap数据服务平台整个系统主要分为两个服务,平台服务和引擎服务。
在过去的一段时间内,主要从质量、效率、成本几个方面对数据服务平台的能力进行建设,在保障数据服务核心通道能力质量同时,提高用户使用平台承接数据链路需求的效率,降低使用数据服务的成本。
当前,数据服务平台已经具备了以下能力:
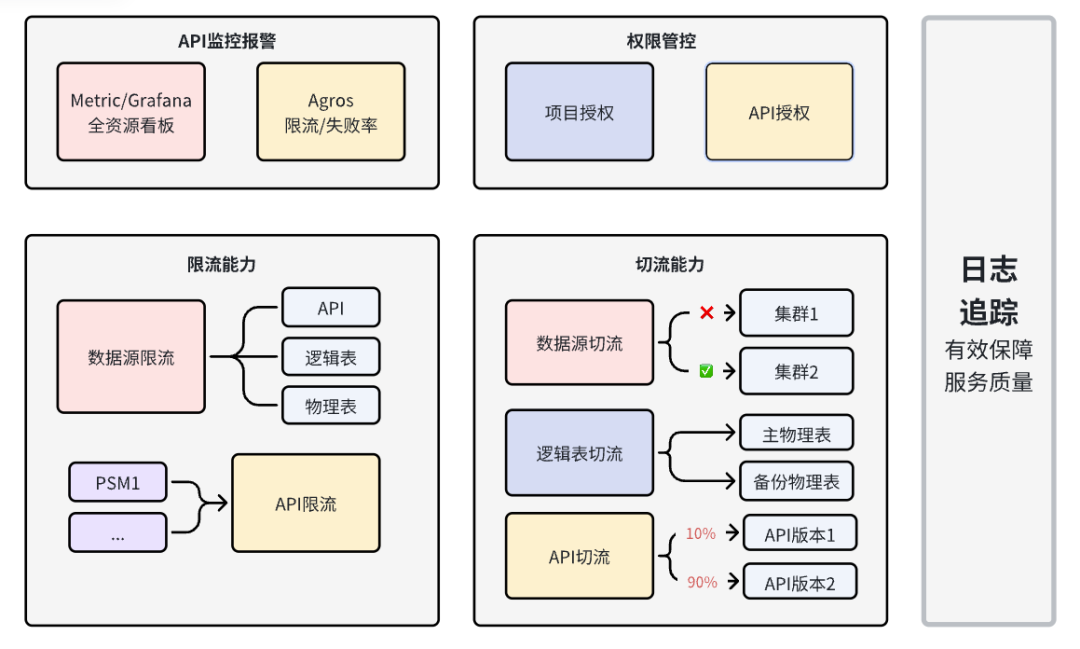
质量:保障数据通道的稳定与安全,为用户提供事前监控告警以及事中容灾的平台能力。
1. 监控告警
● 监控能力:数据服务引擎对查询的全部流量的,请求状态、耗时情况进行上报。基于上报数据,为用户搭建了API粒度监控看板,可以对API调用的SLA、PCT99等指标进行监控和分析。
● 告警能力:数据服务平台在API创建过程会为API绑定默认的失败率告警规则,并支持用户在平台上直接为API配置失败率以及耗时相关的告警。
2. 权限管控
● 项目级别:可以对PSM授予整个项目的权限,即PSM对该项目下所有API都有调用权限。
● API级别:可以对PSM授予API的权限,授权后,PSM具备该API的调用权限。
3. 限流能力
● 数据源:平台支持在数据源粒度上配置限流,即可以控制存储集群或库的整体从数据服务平台的出口流量的大小,主要用于存储并发能力较低的情况。数据源上层的所有物理表、逻辑表、API链路会共享数据的限流配置,能够有效防止突发流量对存储整体造成的冲击。
● API:平台支持在API粒度上配置限流,主要用于API共享场景,API Owner可以通过设置API限流,防止整体流量对底层造成过大压力,API上的所有访问PSM会共用该限流配置。
● API x PSM:平台支持对API配置访问PSM的精确限流,对于每个API已授权的PSM可以进行限流,超过QPS配置后,该PSM调用当前API的后续请求都会被拒绝。
4. 切流能力
● 数据源切流:数据服务平台支持在数据源上进行集群粒度的同机房、跨机房切流。在数仓提前进行了数据双链路建设的情况下,能够在集群整体故障、或者其他区域机房故障的情况下,对集群进行容灾切流。
● 逻辑表主备切换:
- 整表切换:逻辑表上支持对物理表配置备份表,并且能够一键切换链接的物理表,提供了表级别的容灾切流能力。
- 字段切换:对于NoSQL类存储,数据服务平台在整表备份的基础上,还提供了细化到字段级别的备份和切流能力。
● API版本管理:数据服务平台的API提供了版本管理的能力
- 一键回退:在API误上线的情况,我们支持对版本进行一键回退。
- 版本灰度:基于API版本,我们支持了版本灰度发布(完全随机灰度、逐渐HASH灰度)能力,用户基于版本管理的新数据口径可以灰度发布到线上。
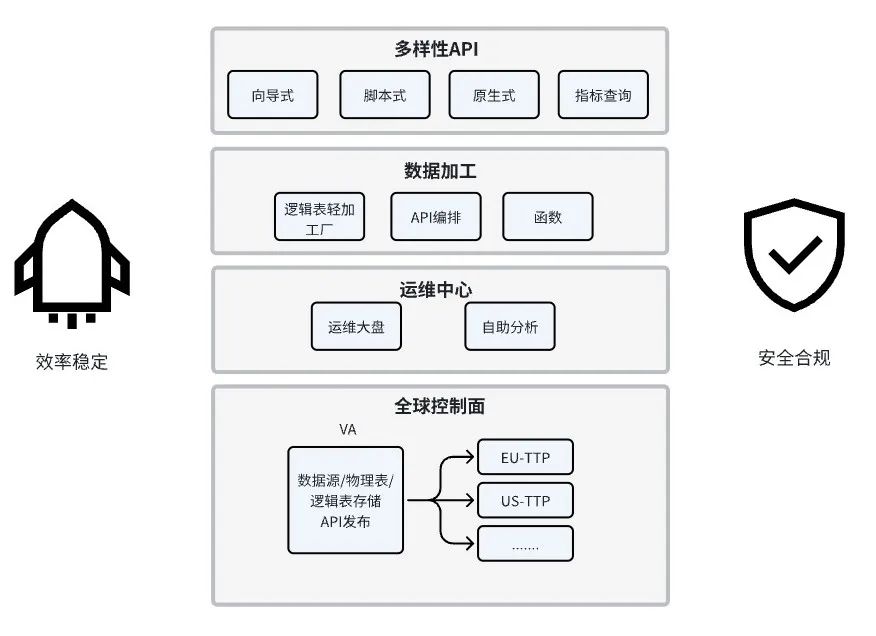
效率:
1. 多种API形式
● 脚本式:支持自行编写API的查询SQL,该方式可满足高阶需求,支持选择同源多张逻辑表进行处理。同时也支持了动态SQL(XML)。适用于同源多表Join等复杂SQL查询场景。
● 向导式:无需代码编写,在界面勾选配置即可快速生成API(仅支持单张逻辑表)。请求参数为Where条件、返回参数为Select字段,系统自动生成查询语句。简单易上手,适用于简单取数场景。
● 原生式:支持用户灵活查询数据集的一种Query,目标是对在圈选范围内逻辑表进行灵活的重组查询,适合数据分析面板类场景。
● 指标查询API:结合Nuwa的指标、维度配置,组合为一个API进行指标查询。
2. API编排能力:将于本文第二板块详细介绍
3. 函数能力:可以创建自定义函数,支持Python,JAVA等方式,在API前置或后置执行,以满足特定的数据处理。
4. 逻辑表轻加工
● 逻辑资产主题:数据服务平台的逻辑表支持了轻加工能力,用户可以将多张物理表或者逻辑表,通过主键关联的形式,聚合成一张新的逻辑表。主要用于构建逻辑宽表、数据主题、逻辑数仓APP层建设等场景。
5. 运维中心
● 智能问答:用户可以输入在使用过程中遇到的各种问题,基于数据服务平台的文档中心,分析助手会提炼出可能的解决方案和可供参考的文档链接。
● 查询分析:用户输入LOGID,系统会自动诊断本次查询过程中数据服务出现的报错情况,以及耗时情况。
结合报错信息,会给用户提供诊断意见。这个能力在部分场景提高线上问题排查定位的效率,解决了上层业务接入数据服务后对查询链路问题黑盒的情况。
● 运维大盘:提供整体的运维概况,支持按照项目或者业务线的粒度,来聚合查看整体API、数据源、物理表、逻辑表、PSM的使用情况。
提供了包括QPS、SLA、PCT以及活跃率等多种信息。让开发者和运维人员更方便地掌握数据资产的运行状况,能及时发现问题,来保证用户服务的稳定性和可用性。
● 自助分析:采用了AI技术来构建智能助手,提供智能问答和查询分析两种能力。
成本:目标帮助平台用户对数据服务平台的数据资产进行成本管理和治理,本模块能力处于建设中,未来会上线成本中心功能。
02 API编排介绍
/ API编排简介
1. 什么是API编排?
随着 API 的数量不断增加,单一的 API 调用已经无法满足复杂业务流程的需求。这就像我们平时做菜的时候面对众多食材,单靠直觉和经验可能难以保证每次都能烹饪出完美的菜肴。
这时候,我们需要一本食谱来指导如何将食材结合起来,使之成为一道佳肴。在 API 的世界里,这本食谱就是 API 编排。
2. 解决什么问题?
一个复杂的业务逻辑可能需要多个 API 的参与,业务侧还需要编写大量的代码将多个 API 关联使用,如果关联逻辑发生变更,还需要研发修改代码上线来支持,这样的模式,研发成本较高、可维护性较差。
基于类似的场景,下面举几个例子以帮助大家来更好的理解 API 编排可以解决哪些复杂业务场景:
● 目前有两个 API,一个是获取实时数据的 API,另一个是获取离线数据的 API,根据就绪时间判断是否要获取离线数据,如果就绪时间未就绪就查实时 API,已就绪就查离线 API。
● 业务场景中使用了多方数据源,想实现异构数据源的数据整合。
● 想对 API 的返回参数进行一些数据处理或者计算,例如电商平台希望根据用户的购买历史和浏览行为来提供个性化的产品推荐。API 节点首先调用产品信息 API 和用户行为 API 获取所需数据,然后编程节点对这些数据进行分析和处理,最终生成推荐列表。
API 编排主要是依赖各个 API 节点来拓展 API 的数据能力,所以想要高效快速实现一个 API 编排,API 的生产是第一步。
同时 API 编排的测试、调用和 API 一样,可以把一个 API 编排视为一个 API。
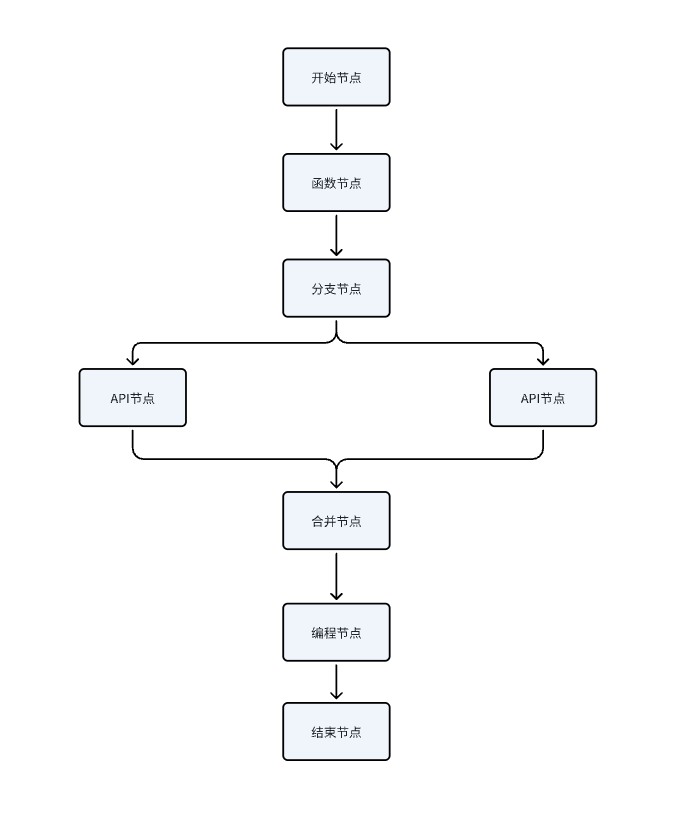
针对编排中目前已有的七个节点,下面表格中有详细的介绍:
| 节点类型 | 节点含义 | 节点依赖 |
| 开始节点 | 编排的起始节点,需要输入参数,类似 API 的请求参数 | 输入参数 |
| 结束节点 | 编排的输出节点,数据出口,类似 API 的返回参数 | 上游输出 |
| API节点 | 可以选择当前项目下所有脚本式、向导式API | 当前项目下的API |
| 函数节点 | 支持Faas、自定义函数 | Faas、Python、Jar |
| 分支节点 | 控制数据的流向,根据上游节点的输入进行条件判断,从而决定数据流向下游哪个节点 | 上游输入&条件判断 |
| 编程节点 | 支持Python,可以编写Python脚本进行数据处理 | tos、Minio、lego |
| 合并节点 | 支持上游多个节点的append、merge、join配置 | 上游节点的输出 |
/ 原理介绍
1. 编排架构
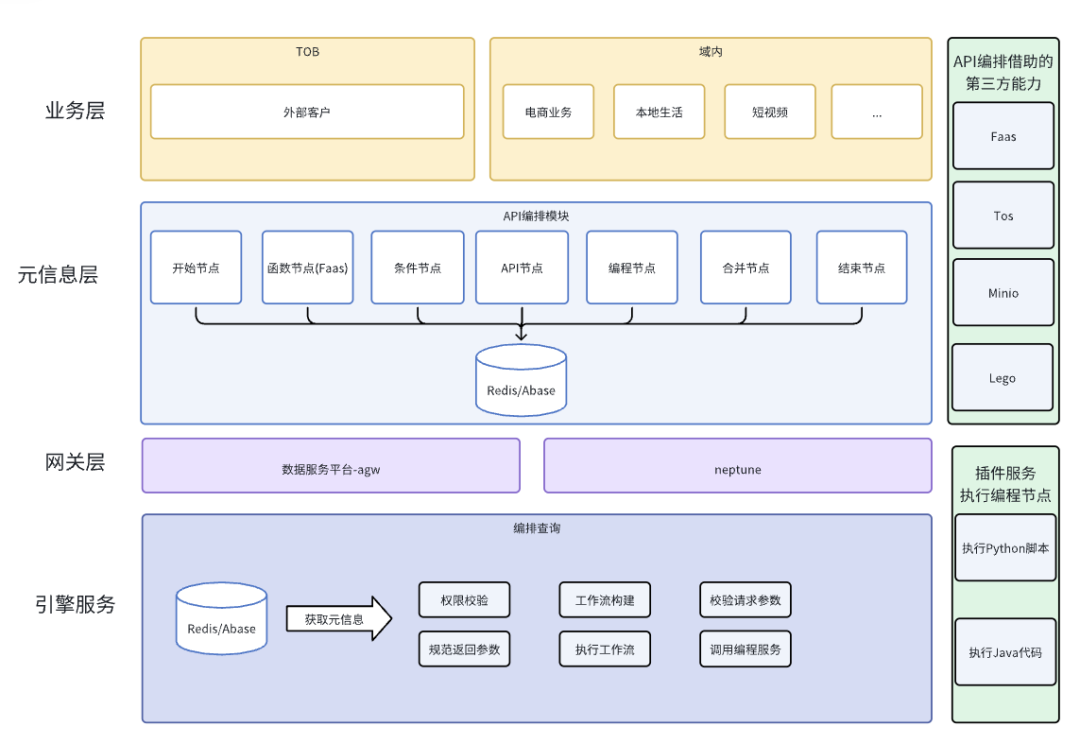
API编排目前作为数据服务平台较为进阶的功能,一方面需要保证调用方式和原有API调用一致,尽量让用户以最小的方式接入编排;
另一方面又要求数据服务平台的引擎在执行编排过程中无需进行复杂的元信息拼装。我们将编排的元信息拼接到了API的元信息中,这样编排也能复用API的一些例如QPS、缓存等配置信息。
因为考虑到目前API元信息结构已经比较复杂,在一些SQL较长,输入输出参数、绑定逻辑表较多的业务场景中属于大Key,大Key的元信息会一定程度上导致引擎执行耗时长,元信息存储使用的redis、abase的内存消耗大等一系列问题。
所以我们并没有将编排内所有节点的元信息一并组装到API元信息中。目前元信息中存储的是编排的调用链路,各个节点的元信息作为单独的key单独存储。
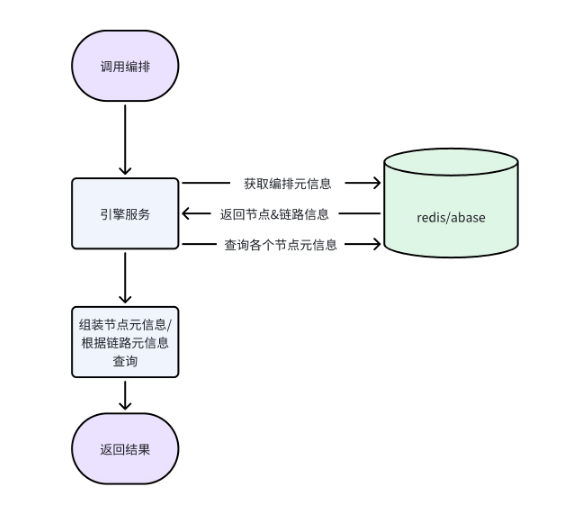
2. 编排执行原理
● 整体方案设计
在API编排 中,主要有两类元素:节点和有向边,节点是进行数据处理的基本单元,也是数据服务平台提供给用户进行自定义数据处理的节点;有向边是数据传输的抽象表示,是用户设置的数据输入和输出。
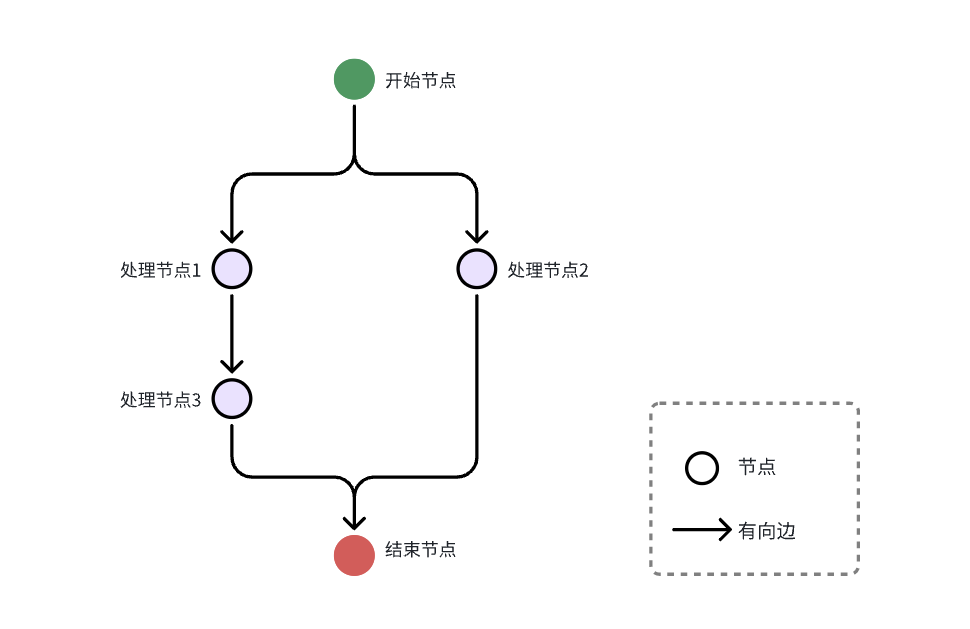
调度执行流程图:
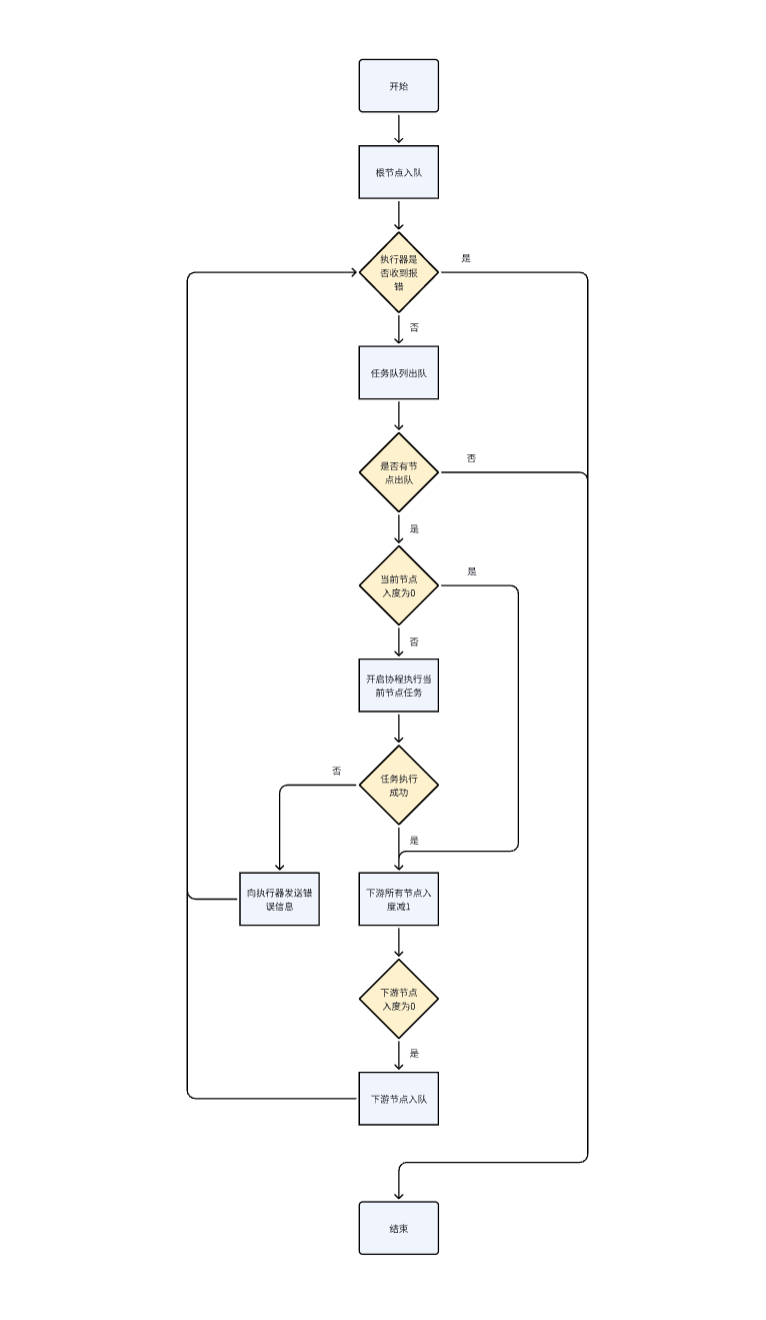
数据服务平台的编排调度能力如下:
- 编排DAG 合法性检测,例如:环的校验、孤立节点检测
- 节点可以选择性调度下游节点,没有被任意上游节点调度的节点不会被执行
- 节点的超时设置、限流、重试
- 日志和埋点接入
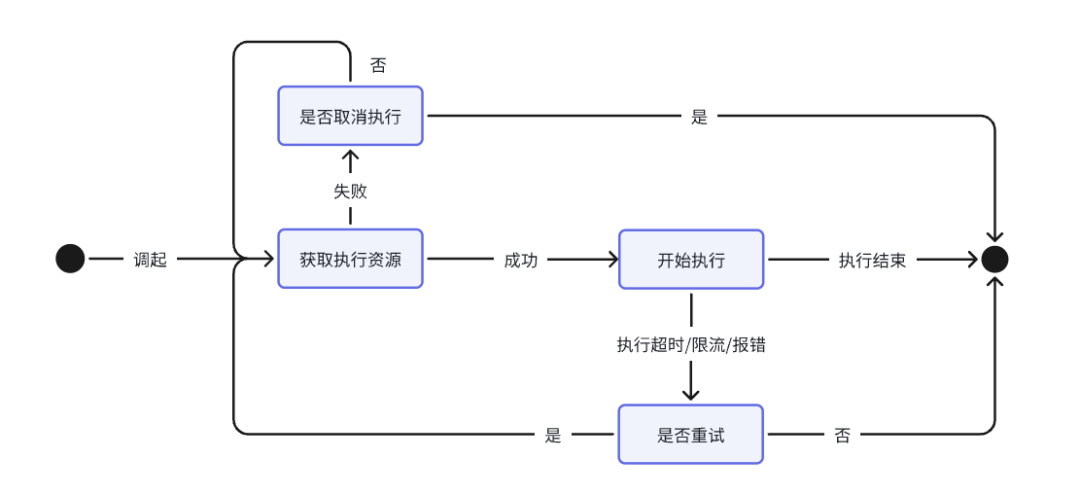
每个节点的状态机如下:
● 详细方案设计
数据服务平台的编排任务主要是让输入数据通过特定的工作流加工后,返回输出结果。编排服务主要是工作流的构建和调度,与很多其它的编排调度系统类似,核心在于构建 DAG(Directed Acyclic Graph,有向无环图)。
数据服务平台的编排调度与其它编排调度框架构建 DAG 图 Directed Acyclic Graph,有向无环图)并调度执行的不同之处在于:
1. 只有一个开始节点和一个结束节点
2. 数据经过每个节点的加工之后,可以有选择的传递给下游若干个节点
3. 部分节点可以在运行时有选择的调度它的下游节点,而不是全部调度
数据服务平台对编排调度框架的要求是高性能、低时延,易扩展,根据自己的需求,我们开发了一套更适合的编排调度框架,主要细节如下:
1. 静态构建 DAG 结构,运行时节点可以参数和判断条件动态选择调度下游
2. 数据保存在各个节点的输入输出中,减少存储在公共变量中导致的竞态访问
3. 通过任务队列保存可以并发执行的任务,同一任务队列中的任务并发执行
4. 任务之间相互独立,任务与调度器解耦
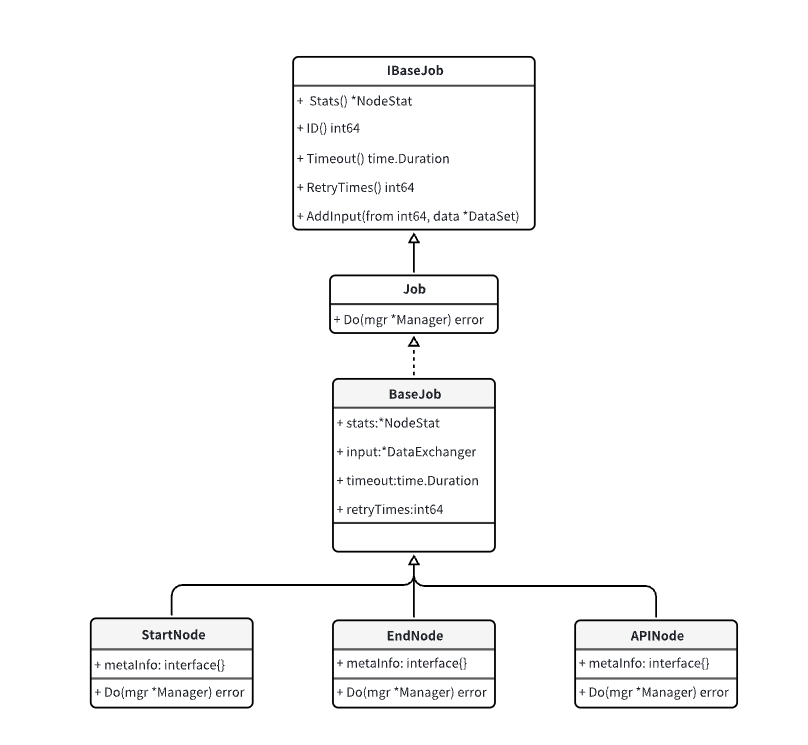
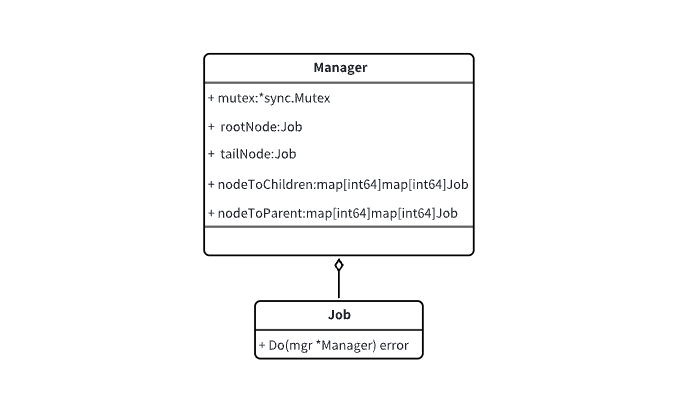
代码UML类图如下:
1. 调度节点设计
每个节点会转换成一个执行任务,结构定义如下:
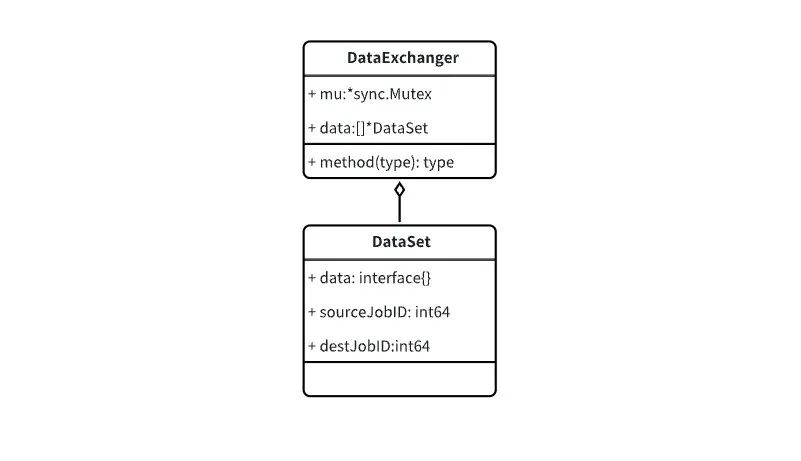
2. 数据封装设计
3. 调度器设计
4. 调度执行逻辑
在初始时,根据元信息构建 DAG,并进行有效性验证,然后初始化每个节点的 inDegree 和 skipInDegree 为上游节点依赖数,最后按照调度执行逻辑进行调度,在全部任务执行完成之后,返回最终数据或者执行中发生的错误。
03 电商场景最佳实践
/ 场景一:
直播大屏分钟数据的冷热分离
1. 业务背景
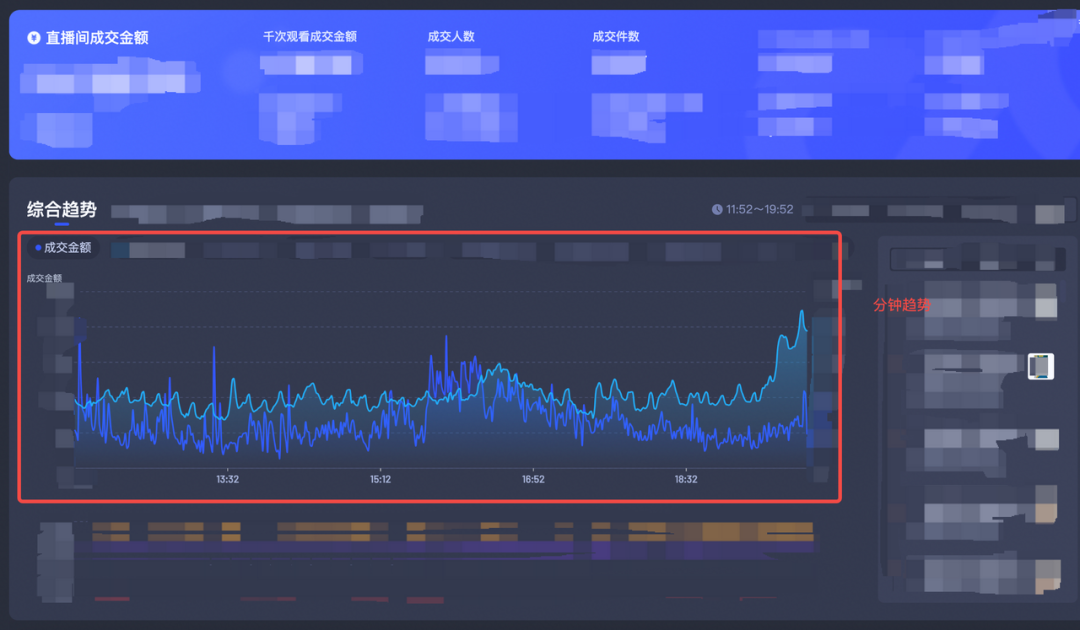
直播大屏是面向电商主播、商家,提供直播间核心实时数据,在直播过程中依据实时数据做相关决策,比如在流量下降时投流、发福袋等,是典型实时盯盘场景。
数据团队提供的实时数据需具备查询QPS高、数据延迟秒级、数据更新秒级、数据准确性高和稳定性高的特点,尤其是当大屏上核心指标出现的短暂GMV停更、分钟数据跌0的情况,如5~8分钟,会有大面积用户客诉。
为了满足实时数据的上述特点,我们的存储选型主要是Abase,数据格式是hash结构,此结构在分钟数据or 大in的场景下,查询放大非常的明显,极端情况下可能会打爆底层存储,出现大量查询失败,从而导致线上故障的发生。
2. 当前痛点
● Abase Hgetall性能低下,频繁出现查询失败的问题:
当前我们的分钟数据主要是Abase hash列存表,在数据服务平台的查询过程中,底层是使用了hgetall指令,该指令的性能比较差,会走到rocksdb的scan操作,由于scan queue限制可能导致部分hgetall命令查询失败,平台查询会报查询你失败。
因scan queue的size是abase侧配置的,为了对磁盘进行保护,不可能无限制的调大scan queue。
为了解决此问题,我们对所在的核心Abase集群HashScan进行摸查,查询流量TOP2表分别是直播间分钟、直播间商品分钟,流量达到了85%以上。
因此我们只需要完成这两份数据的迁移,很大程度上可以缓解查询失败频繁的问题,达到提升Abase集群整体的稳定性、降低OS服务的查询失败率
● 数据下游服务多,服务端实现编排逻辑,切换成本高:
下游服务20+,不同业务方都需实现一堆ifelse编排逻辑,代码可读性较低,彼此间不能复用,按照以往切换经验来说,一般需花费一个Q下游才能切换完成
● 底层存储持续迭代时,服务端均需迭代,迭代成本高:
当后续切换到新存储时,下游服务端需要再走一次之前的切换流程,如新建API->服务端编排逻辑调整->新服务测试->新服务发布等等,迭代成本比较高
3.解决方案
● 冷热数据分离:直播间开播是冷热分布非常的明显,即开播7天内直播间占比达到99.9%以上,因此直播大屏上的查询同样具备冷热分布的特点。
我们只需要在热查询时换存储,如redis,承担主要的查询压力,冷数据的查询打到abase,通过这样的查询策略,可以很大程度上缓解Abase集群的压力,同时保证了大屏链路的稳定性
● 使用API编排来实现冷热数据编排逻辑:以直播间分钟趋势API编排接口为例,如下图,整体链路中,最核心的是分支节点,通过是否开播7天的标识位分别查询对应的冷热数据,即开播7日内读redis,开播超过7日的读取abase
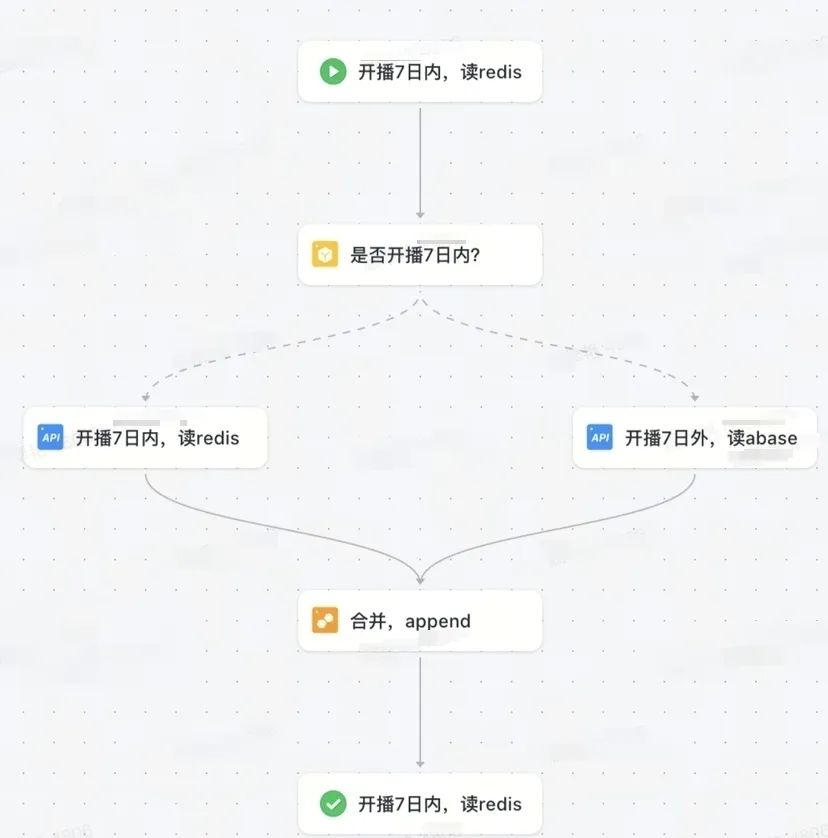
PS:API编排对应的时间比较函数还不支持整型,我们需要服务端对开播时间进行简单加工,未来时间比较函数支持整型的话,可以去掉此处加工逻辑
4.效果&收益
● 服务加工逻辑清晰:通过API编排的能力,我们实现了可视化拖拽式服务开发,无需盘点底层的代码逻辑,一眼识别出服务加工逻辑,对服务后续迭代、线上问题排查都非常的友好;
● 服务逻辑切换口径统一:口径使用API编排来收敛,理论上均可通过PSM授权来接入,但由于涉及到跨团队权限问题,目前是相同项目下可授权使用,不同项目下可复制对应的API编排接口后使用
● 迭代成本低:后续再遇到底层存储切换类似的场景,只需要在API节点替换新的API,走一次API编排的版本发布即可
● 大屏稳定性提升:下游切换完成后,Abase集群的hgetall查询次数下降77.6%(19.34亿->4.3亿),下游查询基本不会再出现失败频繁的情况
/ 场景二:
电商天指标的实时离线数据切换
1. 业务背景
某大屏产品上需透出电商一些天指标,一般的查询流程为 当离线数据未就绪时用实时数据兜底,离线数据就绪后直接查询对应的离线数据表,返回离线数据,并在产品上进行相关数据披露
2. 当前痛点
● 服务端维护实时离线切换的代码逻辑,分散在各处,迭代成本高:
在数据服务平台完成对应逻辑表就绪时间回调配置,会生产对应的回调任务,下游服务端会使用OS 平台提供的RPC接口拿到离线表的就绪时间,跟查询参数中的日期进行大小比对后,从而实现实时离线切换的逻辑,当遇到底层存储频繁切换时,迭代成本高
● 下游大量使用原生式API,动态生成的查询SQL支持多个场景,运维成本极高:
因历史技术债务,下游使用了大量的原生API,同一个API可复用在多个场景,由于业务数据平台目前是不支持此类API字段级别血缘,因此不能准确识别到此类API到底有几种查询、具体的返回结果等,当线上出现问题时,需要服务端人肉检索出相应的查询语句,问题排查定位时间花费大,运维成本极高
3. 解决方案
● API编排支持就绪时间:分支节点能够拿到离线表的就绪时间,基于就绪时间进行判断是读离线数据,还是实时数据
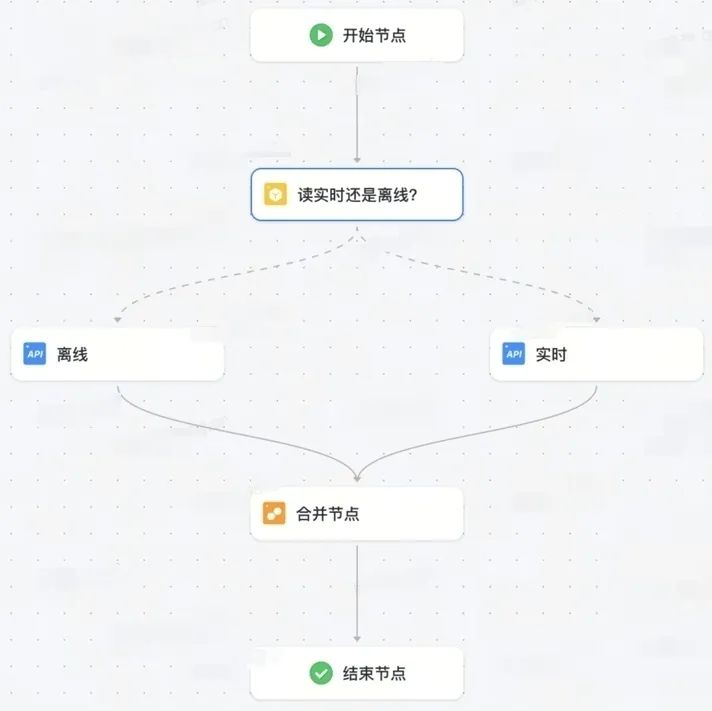
以电商分载体天指标实时离线切换接口为例,我们对图中核心的两个节点,进行简单阐述:
● 分支节点,实现实时离线切换逻辑:
- 读离线数据接口:查询日期 = 离线就绪日期 or 就绪日期> 查询日期,即 date = LOGIC_TABLE_DATE_PARTITION(logic_table_id) or LOGIC_TABLE_DATE_PARTITION(logic_table_id) > date
- 读实时数据接口:查询日期 为 今日 or ( 日期为昨日,离线就绪日期 < 昨日)即date = curdate or LOGIC_TABLE_DATE_PARTITION(logic_table_id) < date
● 合并节点,实现实时离线接口数据合并逻辑:
建议是两边API返回参数完全一致,且采用Append模式合并,未来的话能够支持API返回参数不一致,取他们的并集来实现合并
4. 效果&收益
● API编排收口实时离线切换逻辑,加工逻辑清晰,迭代成本低:
通过API编排的能力,我们实现了可视化拖拽式服务开发,无需盘点底层的代码逻辑,一眼识别出服务加工逻辑,后续若遇到存储切换 or 其他类似场景的话,前者切换对应的API节点,后者直接在现有的API编排接口上另存新编排接口,只需要替换相关API接口即可,开发迭代成本低
● 下游使用脚本式API,能够建立清晰的产品模块->API->OS表的消费血缘,大幅度降低API运维成本:
使用API编排的附加收益,我们能够建立比较系统且全面的消费端血缘,当线上遇到问题时,能够快速定位到OS表、查询脚本以及影响的产品模块,并能给出恰当的止损手段,能有效提升线上问题的排查效率。
相关文章:
火山引擎VeDI数据服务平台:在电商场景中,如何解决API编排问题?
01 平台介绍 数据服务平台可以在保证服务高可靠性和高安全性的同时,为各业务线搭建数据服务统一出口,促进数据共享,为数据和应用之间建立了一座“沟通桥梁”。 同时,解决数据理解困难、异构、重复建设、审计运维困难等问题&#x…...

【每日C/C++问题】
一、 结构体和联合体有什么区别?能否在声明过程当中缺省名字?(需要写清楚使用方法) 结构体的各个成员占用不同的内存空间,总大小是所有成员大小之和(结构体字节对齐): typedef str…...
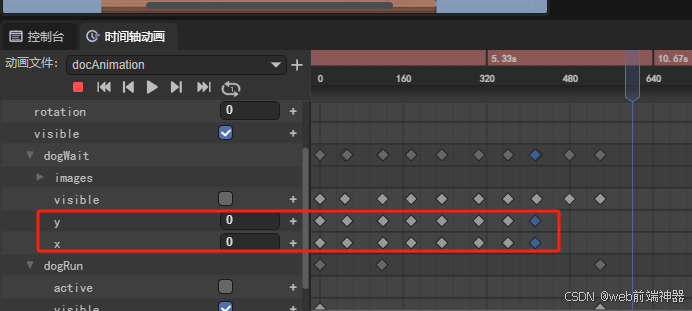
layaair做帧动画,等待一秒之后移动坐标,坐标位置明明相同,执行的时候却会抖动。
如下图:我将1秒后面的位置与0秒的坐标位置设置为一样,然后再第二秒的时候再设置位置移动。也就是想实现这个效果,小狗先停在这里一秒,然后再开始行走。现在的问题是停在这里依然抖动一下,也就是根本就停不住。还是会变…...
SAP分包业务中能否应用后继物料?
近期物流用户在工作中遇到新的问题。在分包业务中的原材料后继(物料主数据设定非连续标识及后继物料)不成功问题。对于未知应用,需要先研究期可行性,与问题或故障不同,如果系统本身就不支持,再多分析测试也…...

【数据结构】二叉树——判断是否为完全二叉树
一、思路 有完全二叉树的解释 我们想要判断二叉树是否为完全二叉树 我们可以用队列来实现 我们先将根节点入队列 再将根节点出队列,判断取出节点是否为空、 若不为空将该节点的左右节点入队列 左右节点为空也入队列 若为空则停止入队列 然后判断队列中是否有 NUL…...

FFmpeg 4.3 音视频-多路H265监控录放C++开发十. 多线程控制帧率。循环播放,QT connect 细节,
在前面,我们总结一下前面的代码。 在 FactoryModeForAVFrameShowSDL 构造函数中 init SDL。 通过 QT timerevent机制,通过startTimer(10);每隔10ms,就会调用timerEvent事件。 在timerEvent事件中,真正的去 读取数据,…...

近百万奖金!2024 Web3.0 创新大赛重磅来袭!
10月30日,中国互联网协会与香港Web3.0协会共同组织举办的2024 Web3.0 创新大赛在上海举行启动会,宣布大赛正式在DataFountain竞赛平台(简称DF平台,http://www.datafountain.cn)启动上线。 大赛面向社会各界征集参赛团队…...

gRPC 一种现代、开源、高性能的远程过程调用 (RPC) 可以在任何地方运行的框架
背景介绍 gRPC 是一种现代开源高性能远程过程调用 (RPC) 可以在任何环境中运行的框架。它可以有效地连接服务 在数据中心内和数据中心之间,具有对负载平衡、跟踪、 运行状况检查和身份验证。它也适用于最后一英里 分布式计算,用于…...
cmake系列-怎么构建不同的C++程序目标文件(可执行程序、动态库、静态库)
目录 生成可执行程序生成动态库生成静态库 我们编写的C代码不仅仅只是为了生成可执行程序,有的时候可能是为了生成动态库或者静态库,那么如果用cmake来构建的话,应该怎么做呢,怎么指定是生成可执行程序,还是生成动态库…...

使用ffmpeg和mediamtx模拟多通道rtsp相机
首先下载ffmpeg,在windows系统上直接下载可执行文件,并配置环境变量即可在命令行当中调用执行。 下载地址: https://ffmpeg.org/再在github上下载mediamtx搭建rtsp服务器,使用ffmpeg将码流推流到rtsp服务器。 下载地址࿱…...

windows系统类似于linux的nohup命令后台启动jar服务
一、首先新建一个后缀名为.bat文件 二、将jar包放在与jar包同一个路径下 三、编写.bat文件 echo off start javaw -Xms512m -Xmx1024m -XX:PermSize256m -XX:MaxPermSize512m -XX:MaxNewSize512m -jar xxxxx-22900.jar >> StartupLog.log 2>&1 & exit 四…...

2024 Rust现代实用教程 流程控制与函数
文章目录 一、if流程控制与match模式匹配1.流程控制2. IF流程控制3.match 表达式 二、循环与break continue以及与迭代的区别1.Rust中的循环Loops2.break && continue3.迭代4.循环与迭代的不同 三、函数基础与Copy值参数传递1.函数的基础知识2.Copy by value 四、函数值…...

stm32入门教程--USART外设 超详细!!!
目录 简介 什么是UART? 什么是USART? 简介 USART(Universal Synchron /Asynchronous Receiver /Transmitter)通用同步/异步收发器 1、USART是STM32内部集成的硬件外设,可根据数据寄存器的一个字节数据自动生成数据帧…...

再探“构造函数”(2)友元and内部类
文章目录 一. 友元‘全局函数’作友元‘成员函数’作友元‘类‘作友元 内部类 一. 友元 何时会用到友元呢? 当想让(类外面的某个函数/其它的类)访问 某个类里面的(私有或保护的)内容时,可以选择使用友元。 友元提供了一种突破&a…...

ffmpeg+vue2
一、安装依赖 npm install ffmpeg/core ffmpeg/ffmpeg "ffmpeg/core": "^0.10.0", "ffmpeg/ffmpeg": "^0.10.1",二、配置ffmpeg 安装好插件以后,需要配置一下代码,否则会报错: 1、在vue.config.js…...

基于深度学习YOLOv10的电动二轮车目标检测、轨迹跟踪、测距算法
基于深度学习YOLOv10的电动二轮车目标检测、轨迹跟踪、测距算法 基于深度学习YOLOv10的电动二轮车目标检测、轨迹跟踪、测距算法引言YOLOv10简介目标检测轨迹跟踪测距算法实际应用结论 基于深度学习YOLOv10的电动二轮车目标检测、轨迹跟踪、测距算法 二轮电动车的目标检测、跟踪…...

鸿蒙ArkTS中的image组件
开发文档很详尽,就在DevEco中的API参考,可以随时调出来进行学习。 在鸿蒙官网也有非常详尽的资料,地址:开发说明-API参考概述 - 华为HarmonyOS开发者 (huawei.com) 这里,就学习image组件的一般用法以及使用SVG图标和字…...
LeetCode 684.冗余连接:拓扑排序+哈希表(O(n)) 或 并查集(O(nlog n)-O(nα(n)))
【LetMeFly】684.冗余连接:拓扑排序哈希表(O(n)) 或 并查集(O(nlog n)-O(nα(n))) 力扣题目链接:https://leetcode.cn/problems/redundant-connection/ 树可以看成是一个连通且 无环 的 无向 图。 给定往…...

让空气净化器“很听话”-置入NRK3502离线语音控制芯片
一、产品市场 随着智能家居的快速发展,人们对家居环境的舒适度与健康性要求日益提升,空气净化器作为改善室内空气质量的重要设备,其智能化升级变得尤为关键。让空气净化器“很听话”,不再仅仅是一个遥不可及的设想,而…...
8个Visio最佳替代软件推荐,每一款都堪称绘图神器
上午好,我的网工朋友。 绘图软件Visio是微软旗下知名的绘图软件,可用来绘制各种可视化图形,包括但不限于:流程图、人物关系图、组织架构图、思维导图、UML图、泳道图、甘特图、知识地图、软件架构图、鱼骨图等 它支持绘制的图形…...

小学生如何学好GESP
一、按年龄段科学规划学习路径 1. 6–9岁(小学低年级):重在逻辑启蒙,不急于学代码 A、核心任务:培养计算思维、问题拆解、条件判断等能力。 B、推荐方式: (1)、…...

SOCD Cleaner终极指南:告别游戏输入冲突,开启精准操作新时代
SOCD Cleaner终极指南:告别游戏输入冲突,开启精准操作新时代 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在《街头霸王6》中因为同时按下左右方向键而错失连招机会࿱…...

Cursor插件开发实战:基于LSP与静态分析的代码导航增强
1. 项目概述:一个为开发者“减负”的Cursor插件如果你和我一样,日常开发重度依赖Cursor这款AI驱动的代码编辑器,那你肯定也经历过这样的时刻:面对一个陌生的代码库,想快速了解某个函数、类或者变量的定义位置ÿ…...

FakeLocation:安卓应用级位置模拟终极解决方案
FakeLocation:安卓应用级位置模拟终极解决方案 【免费下载链接】FakeLocation Xposed module to mock locations per app. 项目地址: https://gitcode.com/gh_mirrors/fak/FakeLocation 在数字时代,位置隐私已成为每个Android用户必须面对的重要问…...

国家十四五课题背书,镜像视界无感定位解决ReID跨镜全场景痛点
国家十四五课题背书,镜像视界无感定位解决ReID跨镜全场景痛点在数字孪生、视频孪生技术全面落地的当下,全域跨镜目标追踪与精准定位已成为智慧安防、智慧园区、智慧港口、军工厂管控、危化品园区管理等领域的核心刚需。传统跨镜追踪技术长期依赖ReID&…...
)
别再手动输数据了!手把手教你用Fluent的Profile功能导入实验数据(附CSV文件模板)
别再手动输数据了!手把手教你用Fluent的Profile功能导入实验数据(附CSV文件模板) 在计算流体力学(CFD)分析中,准确导入实验数据或第三方软件的计算结果作为边界条件,往往是确保仿真可靠性的关键…...

归档日志较多导致磁盘使用率100%,数据库停止服务
文章目录环境症状问题原因解决方案环境 系统平台:银河麒麟 (鲲鹏) 版本:9.0 症状 数据库服务停止,对外停止响应。 问题原因 服务器磁盘使用率100%,数据库服务因此停止。 解决方案 1、检查服务器磁盘…...

告别枯燥表格!用Power BI的矩形树图,5分钟搞定你的销售利润可视化分析
商业数据可视化实战:用Power BI矩形树图5分钟呈现销售利润洞察 在每周的销售复盘会议上,你是否经常面对这样的困境:手头有一份密密麻麻的Excel表格,包含了各省市、各产品的销售利润数据,却难以快速向团队传达关键业务洞…...

Rust构建的轻量级文件搜索工具fltr:高性能文本检索新选择
1. 项目概述:一个轻量级、高性能的本地文件搜索工具在开发或日常文件管理工作中,我们常常面临一个看似简单却极其恼人的问题:如何在成千上万的文件中,快速、精准地找到包含特定关键词或符合特定模式的那一个?无论是定位…...
)
地理学者必抢的AI协同时代入场券:NotebookLM+QGIS工作流搭建指南(仅限首批内测用户验证版)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM地理学研究辅助的范式革命 从静态文献到动态知识图谱 NotebookLM 通过语义切片与向量对齐技术,将地理学经典文献(如《人文地理学导论》《自然地理学原理》ÿ…...