Redis 的使⽤和原理
第一章:初识 Redis
1.1盛赞 Redis
1.2 Redis 特性
1. 速度快

2. 基于键值对的数据结构服务器
3. 丰富的功能
4. 简单稳定
5. 客⼾端语⾔多
6. 持久化(Persistence)

7. 主从复制(Replication)

8. ⾼可⽤(High Availability)和分布式(Distributed)
1.3 Redis 使⽤场景
1.3.1 Redis 可以做什么
1. 缓存(Cache)
2. 排⾏榜系统
3. 计数器应⽤
4. 社交⽹络
5. 消息队列系统
1.3.2 Redis 不可以做什么
第⼆章 Redis 常⻅数据类型
2.1.1 基本全局命令
KEYS

EXISTS

DEL

EXPIRE

TTL


TYPE

2.1.2 数据结构和内部编码


2.1.3 单线程架构
1. 引出单线程模型
redis单线程,只有一个线程去接收处理所有的请求,并不是服务器进程内部只有一个线程,其实也有很多线程,这些线程都在处理网络IO

上面这个情况,可能会有线程安全问题

其实redis服务器并不会有这种情况,因为redis服务器是单线程服务器,把接收到的请求串行执行,多个请求到达redis队列中,也是需要进行排队等候的.
redis能够使用单线程模型,很好的工作,是因为redis处理的业务逻辑是短平快,不消耗CPU资源,如果一个操作执行的时间太长,就会影响其他的请求的执行
2.为什么redis是单线程,速度还能这么快,效率这么高?
他的速度快和效率高是与关系性数据库(MySQL,Orcale)进行对比
1.redis直接访问的是内存,而关系性数据库访问的硬盘
2.redis的核心功能,比关系性数据库的核心功能要简单,数据库对于数据的插入查询,都有更复杂的功能支持,
3.单线程模型,减少了不必要的线程竞争开销,redis每个操作都是短平快,不涉及特别消耗cpu的操作
4.处理网络IO的时候,使用了epoll这样的IO多路复用机制,IO多路复用机制,一个线程就可以处理多个socket,,epoll事件通知/回调机制,一个线程可以完成好多任务,前提是这些任务的交互不频繁,大部分时间都在等,可以采取epoll多路复用机制

1.String 字符串
在redis中,所以的key都是string类型,value的数据类型才有差异

常见命令
SET


GET

MGET
MSET



SETNX


计数命令

INCR
INCRBY
DECR
DECYBY
INCRBYFLOAT

APPEND

GETRANGE

SETRANGE

STRLEN

命令⼩结

内部编码





典型使⽤场景
缓存(Cache)功能


举一个例子来理解一下缓存
这是一段伪代码
redis这样的缓存,经常存储"热点"数据(被高频使用的数据),最近一段时间都会反复用到的数据,

计数(Counter)功能

共享会话(Session)


⼿机验证码



2.Hash 哈希

常见命令
1.HSET
2.HGET
3.HEXISTS
4.HDEL

5.HKEYS


6.HGETALL

7.HMGET

8.HLEN
9.HSETNX
10.HINCRBY

命令⼩结



内部编码
ziplist(压缩列表):
hashtable(哈希表):


1)当 field 个数⽐较少且没有⼤的 value 时,内部编码为 ziplist:
2)当有 value ⼤于 64 字节时,内部编码会转换为 hashtable:
3)当 field 个数超过 512 时,内部编码也会转换为 hashtable:
使⽤场景


注意

缓存⽅式对⽐
1. 原⽣字符串类型
2. 序列化字符串类型,例如 JSON 格式

3. 哈希类型
关于内聚和耦合
高内聚:有关联的代码紧密联系在一起

低耦合:代码的各个模块之间影响不大

3.List列表


列表类型的特点:
第⼀:
第⼆
第三

常见命令
LPUSH(头插)
LPUSHX

RPUSH(尾插)
RPUSHX
LRANGE

LPOP(头删)

RPOP(尾删)
LINDEX

LINSERT
LLEN

LREM
指定元素精准删除

1.当count>0时,从头开始删除指定元素的次数

2.当count<0时,从尾开始删除指定元素的次数

3.当count=0时,删除全部指定的元素

LTRIM
只保留范围内的元素


LSET
根据下标修改元素


阻塞版本命令
BLPOP
BRPOP

内部编码
ziplist(压缩列表):
linkedlist(链表):
quicklist
每个节点都是一个压缩列表,以链表的形式连接起来


使⽤场景
作为数组

消息队列



微博 Timeline

4.set集合
基本命令
SADD

SMEMBERS

SISMEMBER

SCARD
SPOP

SMOVE
SREM
集合间操作

SINTER

SINTERSTORE

SUNION

SUNIONSTORE

SDIFF


SDIFFSTORE

命令小结

内部编码
intset(整数集合):
hashtable(哈希表):

使⽤场景
1.使用set来保存用户的标签

2.使用set来计算共同好友,基于集合求交集


Zset 有序集合



常见命令
zadd

ZCARD
ZCOUNT


ZRANGE

ZREVRANGE

ZRANGEBYSCORE

ZPOPMAX

BZPOPMAX

ZPOPMIN
BZPOPMIN
ZRANK

ZREVRANK
ZSCORE
ZREM
ZREMRANGEBYRANK
ZREMRANGEBYSCORE
ZINCRBY
集合间操作

ZINTERSTORE(交集)


ZUNIONSTORE并集

命令⼩结


内部编码
ziplist(压缩列表):
当有序集合的元素个数⼩于 zset-max-ziplist-entries 配置(默认 128 个), 同时每个元素的值都⼩于 zset-max-ziplist-value 配置(默认 64 字节)时,Redis 会⽤ ziplist 来作
skiplist(跳表):
使⽤场景

相关文章:
Redis 的使⽤和原理
第一章:初识 Redis 1.1盛赞 Redis Redis 是⼀种基于键值对(key-value)的 NoSQL 数据库,与很多键值对数据库不同的是,Redis 中的值可以是由 string(字符串)、hash(哈希)、list&…...

前端学Java
一:语法 1、注解 注解(Annotation)是Java中的一种特殊类型的语法,它可以被用来为代码提供元数据。元数据是关于数据的数据,注解可以用于类、方法、变量等的描述与标记。 理解注解可以从以下几个方面入手:…...

VR游戏:多人社交将是VR的下一个风口
第一部分:创业笔记 1. 市场趋势 从单机游戏转向多人互动体验:随着技术的进步,VR游戏正从单机模式向多人互动体验转变。代表作品如Rec Room、Phasmophobia、Among Us和Breachers等,这些游戏的成功证明了多人互动模式的巨大潜力。…...
的不同)
Docker与虚拟机(VM)的不同
Docker与虚拟机(VM)在实现的原理上存在显著的不同,主要体现在以下几个方面: 一、基础原理 Docker 利用Linux内核的特性,如容器(containers)、命名空间(namespaces)和控制…...

Pr 视频效果:透视
效果面板/视频效果/透视 Video Effects/Perspective Adobe Premiere Pro 的视频效果中,透视 Perspective效果组主要用于在二维平面的视频剪辑中模拟三维空间的透视效果。 通过调整这些效果,可以改变图像的视角、添加阴影、创造立体感,增强画面…...

C 语言标准库 - <limit.h>
简介 <limits.h> 是 C 标准库中的一个头文件,定义了各种数据类型的限制。这些宏提供了有关整数类型(char、short、int、long 和 long long 等)和其他数据类型的最大值和最小值的信息。 这些限制指定了变量不能存储任何超出这些限制的…...

Python | Leetcode Python题解之第519题随机翻转矩阵
题目: 题解: class Solution:def __init__(self, m: int, n: int):self.m mself.n nself.total m * nself.map {}def flip(self) -> List[int]:x random.randint(0, self.total - 1)self.total - 1# 查找位置 x 对应的映射idx self.map.get(x,…...

大数据新视界 -- 大数据大厂之提升 Impala 查询效率:索引优化的秘籍大揭秘(上)(3/30)
💖💖💖亲爱的朋友们,热烈欢迎你们来到 青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而 我的…...

【AI工作流】FastGPT - 深入解析FastGPT工作流编排:从基础到高级应用的全面指南
文章目录 一、工作流编排概述二、FastGPT的节点类型1. 基础功能插件(1) 文本输出(2) 功能调用(3) 工具(4) 外部调用(5) 其他 2. 系统插件3. 团队插件 三、工作流中的流向结语 在当今快速发展的人工智能领域,工作流编排的能力已成为提升用户体验和应用效率的关键因素…...

VS+Qt解决提升控件后,包含头文件格式不对问题处理
一、前言 VSQt 提升控件后,在uic目录下会生成ui相关的初始化文件,对于提升的控件头文件包含的格式为#include<> 而非 #include “ ” 导致无法找到头文件。如果手动修改为 #include “ ”相当麻烦,甚至每次编译都要修改一遍,…...

opencv - py_imgproc - py_filtering filtering 过滤-卷积平滑
文章目录 平滑图像目标2D 卷积(图像过滤)图像模糊(图像平滑)1. 平均2. 高斯模糊3. 中值模糊4. 双边滤波 其他资源 平滑图像 目标 学习: 使用各种低通滤波器模糊图像将定制滤波器应用于图像(2D 卷积&…...
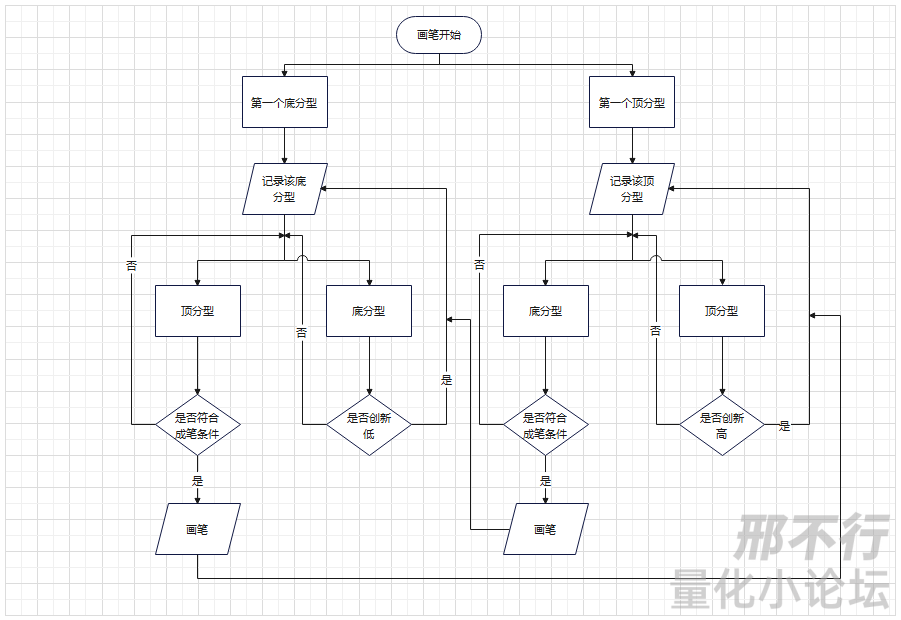
精华帖分享|缠论系列 -笔
本文来源于量化小论坛策略分享会板块精华帖,作者为吴奕萱,发布于2023年6月4日。 以下为精华帖正文: 01 笔 昨天讲了3根K线组合关系的完全分类,按照逻辑,其实我们会考虑是不是应该讲4根、5根K线的组合关系了。 精华帖…...

Java项目实战II基于Spring Boot的文理医院预约挂号系统的设计与实现(开发文档+数据库+源码)
目录 一、前言 二、技术介绍 三、系统实现 四、文档参考 五、核心代码 六、源码获取 全栈码农以及毕业设计实战开发,CSDN平台Java领域新星创作者,专注于大学生项目实战开发、讲解和毕业答疑辅导。 一、前言 在医疗资源日益紧张的背景下࿰…...

NumPy Ndarray学习
1.NumPy Ndarray 对象简介 NumPy 最重要的特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。ndarray 对象是用于存放同类型元素的多维数组。ndarray 中的每个元素在内存中都有相同存储大小的区域。 2.N…...

Browserslist 配置
Browserslist 是一个工具和规范,用于定义和共享支持的浏览器列表,以便在前端开发中管理不同工具的兼容性。这些工具可以包括 Babel、Autoprefixer、ESLint 等,它们都可以使用 Browserslist 提供的配置来确定应支持哪些浏览器及其版本。 主要…...

vue2中的v-bind相当于原生js的什么
在 Vue 2 中,v-bind 是一个指令,用于动态地将一个或多个属性绑定到 DOM 元素上。它相当于在原生 JavaScript 中直接操作 DOM 元素属性的方法。 v-bind 的基本用法 在 Vue 中,v-bind 可以这样使用: <!-- 绑定一个属性 -->…...

c语言-scanf函数的用法
文章目录 一、scanf是什么?二、通过scanf进行赋值scanf 输入一段带空格的句子, %[^\n] 格式字符串。 三、赋值忽略符 一、scanf是什么? 函数原型:int scanf ( const char * format, … ); scanf是一个格式输出库函数,…...

AI带货主播插件开发之商品推荐模块!
AI带货主播,作为新兴的人工智能技术应用领域,正逐渐改变着电商直播的格局,在这一领域,商品推荐模块是提升用户体验、增加销售额的关键一环。 本文将探讨AI带货主播插件的商品推荐模块开发,并分享五段关键的源代码&…...

使用Nginx作为反向代理和负载均衡器
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 使用Nginx作为反向代理和负载均衡器 引言 Nginx 简介 安装 Nginx Ubuntu CentOS 配置 Nginx 作为反向代理 配置 Nginx 作为负载…...

【数据结构二叉树】C非递归算法实现二叉树的先序、中序、后序遍历
引言: 遍历二叉树:指按某条搜索路径巡访二叉树中每个结点,使得每个结点均被访问一次,而且仅被访问一次。 除了层次遍历外,二叉树有三个重要的遍历方法:先序遍历、中序遍历、后序遍历。 1、递归算法实现先序、中序、后…...

终端工作空间新选择:从 tmux 到 Zellij 的迁移与实战
1. 为什么需要从 tmux 迁移到 Zellij 作为一个用了五年 tmux 的老用户,我最初对 Zellij 这个"新玩具"是持怀疑态度的。直到有一次在远程服务器上调试时,tmux 的窗格突然卡死,所有工作进度瞬间归零,我才开始认真寻找替代…...

Fusion 360安装后想改位置?别重装!试试这个Windows符号链接‘乾坤大挪移’
Fusion 360安装路径迁移:无需重装的Windows符号链接实战指南 你是否遇到过这样的困扰——Fusion 360默认安装在C盘,随着项目文件增多,宝贵的SSD空间被快速吞噬?传统认知告诉我们,软件一旦安装就无法更改路径࿰…...
Binary Linear Equation Group)
7th grade math (2026.05.15)Binary Linear Equation Group
Binary Linear Equation Group 七年纪(下)数学第十章《二元一次方程组》作业评价参考答案-zwf 错误题型分析...

番茄小说下载器终极指南:如何轻松构建个人离线图书馆
番茄小说下载器终极指南:如何轻松构建个人离线图书馆 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否经常在地铁、高铁或飞机上想要阅读番茄小说,…...
pc手机通用)
堕落千金—黑蔷薇与欲望之火 2026最新版免费下载 (看到请立即转存 资源随时失效)pc手机通用
下载链接 Build.6769958|整合DLC|容量1.1GB|官方简体中文|支持键盘.鼠标 在互动叙事与成人向角色扮演游戏(RPG)的市场中,《堕落千金—黑蔷薇与欲望之火》(以下简称《黑蔷薇》)自发布以来便凭借其精致的美术风格与沉浸…...

Allegro中Route Keepout、Design Outline和Cutout到底怎么用?一张图讲清PCB布局中的‘禁区’设置
Allegro中三大边界工具实战指南:Route Keepout、Design Outline与Cutout的精准运用 在PCB设计领域,边界定义如同城市规划中的红线,既决定了板卡的物理形态,又影响着电气性能的发挥。Cadence Allegro作为行业标准工具,提…...

SIFT和ORB到底怎么选?图像配准实战对比,看完这篇你就懂了
SIFT与ORB图像配准实战指南:如何根据项目需求选择最佳算法 在计算机视觉领域,图像配准是许多应用的基础环节,从医疗影像分析到增强现实,从卫星图像处理到工业检测,都离不开高效准确的特征匹配技术。当开发者面对SIFT和…...

R语言clusterProfiler包KEGG富集分析报错?别慌,这份2024最新避坑指南帮你搞定
R语言clusterProfiler包KEGG富集分析2024避坑实战指南 当你在深夜的实验室里盯着RStudio不断弹出的红色报错信息,第十次尝试调整enrichKEGG参数却依然看到"replacement has length zero"这个令人绝望的提示时,可能已经忍不住要摔键盘了。这份…...
精准选声公式大公开)
ElevenLabs声音库实战速配:7类行业场景(播客/教育/游戏)精准选声公式大公开
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs声音库核心能力全景图解 ElevenLabs 声音库并非传统意义上的静态音频集合,而是一套基于深度神经语音合成(DNNS)的实时可编程语音基础设施。其核心能力围绕…...
)
人机协同中的“因为-所以”、“if-then”(如果-那么)
在人机协同中,“因为-所以”和“if-then”(如果-那么)是两种截然不同但紧密相关的逻辑范式。简单来说,“if-then”是机器的“计算”语言,而“因为-所以”是人类“算计(谋算)”与因果推理的核心。…...