Spark学习
Spark简介
1.Spark是什么
首先spark是一个计算引擎,而不是存储工具,计算引擎有很多:
第一代:MapReduce廉价机器实现分布式大数据处理
第二代:Tez基于MR优化了DAG,性能比MR快一些
第三代:Spark优先使用内存式计算引擎 ,国内目前主要应用的离线计算引擎
第四代:Flink:实时流式计算引擎 , 国内目前最主流实时计算引擎
spark的诞生原因就是因为MR太慢了,MR是基于磁盘的,而Spark是基于内存的。
2.Spark能做什么
实现离线数据批处理:类似于MapReduce、Pandas,写代码做处理:代码类的离线数据处理 。
实现交互式即时数据查询:类似于Hive、Presto、Impala,使 用SQL做即席查询分析:SQL类的离线数据处理
实现实时数据处理:类似于Storm、Flink实现分布式的实时计算:代码类实时计算或者SQL类的实时计算
实现机器学习的开发:代替传统一些机器学习工具
3.Spark组成部分
Hadoop的组成部分:common、MapReduce、Hdfs、Yarn
Spark Core:Spark最核心的模块,可以基于多种语言实现代码类的离线开发 【类似于MR】
Spark SQL:类似于Hive,基于SQL进行开发,SQL会转换为SparkCore离线程序 【类似Hive】
Spark Streaming:基于SparkCore之上构建了准实时的计算模块 【淘汰了】
Struct Streaming:基于SparkSQL之上构建了结构化实时计算模块 【替代了Spark Streaming】
Spark ML lib:机器学习算法库,提供各种机器学习算法工具,可以基于SparkCore或者SparkSQL实现开发。
4.各大计算引擎的对比
Impala:集成Hive实现数据分析,优点是性能最好,缺点数据接口比较少,只支持Hive和Hbase数据源 。 是一个基于CDH的一个软件,Impala 能写sql,它写出来的sql,叫 Impala SQL (大部分跟我们普通的sql没啥区别) ,操作hive或者hbase 速度非常快!
Presto:集成Hive实现数据分析,优点性能适中,支持数据源非常广泛,与大数据接口兼容性比较差 。Presto也可以写sql,只是写的sql叫做 Presto SQL (大部分跟我们普通的sql没啥区别) ,特点:可以跨数据源。比如mysql的表可以和oracle中的一个表关联查询。
SparkSQL:集成Hive实现数据分析,优点功能非常全面、开发接口多,学习成本低,缺点实时计算不够完善。实时计算交给了Flink。
5.Spark的应用
spark可以做数仓,数仓中也可以分层。
离线场景:实现离线数据仓库中的数据清洗、数据分析、即席查询等应用
实时场景:实现实时数据流数据处理,相对而言功能和性能不是特别的完善,工作中建议使用Flink替代。
6.spark五种模式
本地模式Local:一般用于做测试,验证代码逻辑,不是分布式运行,只会启动1个进程来运行所有任务。
集群模式Cluster:一般用于生产环境,用于实现PySpark程序的分布式的运行
Standalone:Spark自带的分布式资源平台,功能类似于YARN
YARN:Spark on YARN,将Spark程序提交给YARN来运行,工作中主要使用的模式
Mesos:类似于YARN,国外见得多,国内基本见不到
K8s:基于分布式容器的资源管理平台,运维层面的工具。
7.Spark为什么比MR快
1、MR不支持DAG【有向无环图】,计算过程是固定,一个MR 只有1个Map和1个Reduce构成。 一个Map和Reduce是一个过程,和另一个Map和Reduce是不一样的。

从落地到磁盘的那一刻,上一个过程已经结束了,下一个过程和上一个过程没有关系了。
2、MR是一个基于磁盘的计算框架,读写效率比较低
3、MR的Task计算是进程级别的,每次运行一个Task都需要启动一个进程,然后运行结束还是释放进程,比较慢。【一个进程可以包含多个线程,比如qq是一个进程,发消息,传文件是一个个线程】
MapTask:进程
ReduceTask:进程
进程启动和销毁是比较耗时的
spark为什么那么快?
1、Spark支持DAG,一个Spark程序中的过程是不固定,由代码 所决定。
2、Task任务都是线程级别的
3、计算是基于内存的。
| 区别 | MapReduce | Spark |
| 计算流程结构 | 1个Map+1个Reduce,每步 结果都必须进入磁盘 | 支持DAG,一个程序中可以有多个Map、Reduce过程,多个Map之间的操作可以 直接在内存中完成 |
| Shuffle过程 | 分区、排序、分组 | 会根据具体的操作来经过不同的过程 |
| Task运行方式 | 进程: MapTask ReduceTask | 进程之启动一次,所有的Task都以线程方式存在,不需要频繁启动、申请资源 |
相关文章:
Spark学习
Spark简介 1.Spark是什么 首先spark是一个计算引擎,而不是存储工具,计算引擎有很多: 第一代:MapReduce廉价机器实现分布式大数据处理 第二代:Tez基于MR优化了DAG,性能比MR快一些 第三代:Spark…...

一些小细节代码笔记汇总
Python cv2抓取摄像头图片保存到本地 import cv2 import datetime, ossavePath "E:/Image/"if not os.path.exists(savePath):os.makedirs(savePath)cap cv2.VideoCapture(0) capture Falseif not cap.isOpened():print("无法打开摄像头")exit()while…...

L4.【LeetCode笔记】链表题的VS平台调试代码
不用调用87.【C语言】数据结构之链表的头插和尾插文章提到的头插函数 记下这个模板代码,可用于在Visual Studio上调试出问题的测试用例 如创建链表[1,2,3,4,5] #include <stdilb.h> // Definition for singly-linked list.struct ListNode {int val;struct ListNode *…...

JavaCV 之高斯滤波:图像降噪与细节保留的魔法
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/literature?__c=1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编程,高并发设计,Springboot和微服务,熟悉Linux,ESXI虚拟化以及云原生Docker和K8s…...

VsCode显示空格
ctrl shift p选择Preferences: Open User Settings (JSON) 加上"editor.renderWhitespace": "all" {"cmake.configureOnOpen": true,"files.encoding": "gb2312","editor.fontVariations": false,"edito…...

.Net C# 基于EFCore的DBFirst和CodeFirst
DBFirst和CodeFirst 1 概念介绍 1.1 DBFirst(数据库优先) 含义:这种模式是先创建数据库架构,包括表、视图、存储过程等数据库对象。然后通过实体框架(Entity Framework)等工具,根据已有的数据…...

w012基于springboot的社区团购系统设计
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…...

笔记本降频超鬼锁屏0.39电脑卡到不行解决办法实操记录
1、最开始没发现cpu问题,我发现我电脑突然异常的卡顿,最开始我怀疑是不是微软win用久了或者自动更新导致的问题,于是自己重装了操作系统 发现问题依然存在 2、我怀疑难道我的 cpu 内存 固态硬盘 其中一个有点问题?心想要是硬盘的…...

优选算法第四讲:前缀和模块
优选算法第四讲:前缀和模块 1.[模板]前缀和2.【模板】二维前缀和3.寻找数组的中心下标4.除自身以外数组的乘积5.和为k的子数组6.和可被k整除的子数组7.连续数组8.矩阵区域和 1.[模板]前缀和 链接: link #include <iostream> #include <vector> using…...

ubuntu20.04 加固方案-设置限制su命令用户组
一、编辑/etc/pam.d/su配置文件 打开终端。 使用文本编辑器(如vim)编辑/etc/pam.d/su文件。 vim /etc/pam.d/su 二、添加配置参数 在打开的配置文件的中,添加以下参数: auth required pam_wheel.so 创建 wheel 组 并添加用户 …...

TDengine数据备份与恢复
TDengine数据备份与恢复 一、数据备份和恢复介绍二、基于 taosdump 进行数据备份恢复三、基于 taosExplorer 进行数据备份恢复3.1 taosExplorer 的安装与配置3.2 使用taosExplorer 进行数据备份 一、数据备份和恢复介绍 官网地址:TDengine - 数据备份和恢复 为了防止…...
2024最新的开源博客系统:vue3.x+SpringBoot 3.x 前后端分离
本文转载自:https://fangcaicoding.cn/article/54 大家好!我是方才,目前是8人后端研发团队的负责人,拥有6年后端经验&3年团队管理经验,截止目前面试过近200位候选人,主导过单表上10亿、累计上100亿数据…...

研究中的“异质性”、“异质性结果”是指?
“异质性”这个词在统计学和研究中指的是数据、现象或群体之间的差异,即不同个体、组别、区域或时间点的表现或特征并不相同。相对的概念是“同质性”,即所有个体或组别在某一方面表现相同或接近。 异质性(Heterogeneity)的含义 …...

Springboot整合AOP和redis
aop pom.xml <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactId> </dependency> 开启自动代理 注意:在完成了引入AOP依赖包后,一般来说并不需要去做其他…...

freetype学习总结
freetype学习总结 目录 freetype学习总结1. LCD显示字符问题引入2. freetype概念2.1 嵌入式设备使用FreeType的方法步骤2.2 嵌入式设备使用FreeType的注意事项 3. freetype官方C示例3.1 example1.c源码 4. 嵌入式设备上使用FreeType的简单示例4.1 简单示例代码4.2 代码分析 5. …...

上海亚商投顾:沪指缩量调整 华为概念股午后爆发
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 市场全天震荡调整,沪指、深成指午后跌超1%,创业板指一度跌逾2%,尾盘跌幅有…...

操作系统与进程【单身狗定制版】
大家好呀 我是浪前 今天给大家讲解的是操作系统与进程 祝愿所有点赞关注的人,身体健康,一夜暴富,升职加薪迎娶白富美!!! 点我领取迎娶白富美大礼包 前言: 我们今天我们来学习操作系统 当然啦,操作系统是一个很庞大的…...

监听el-table中 自定义封装的某个组件的值发现改变调用函数
监听el-table中 自定义封装的某个组件的值发现改变调用函数 当你在一个 el-table 中使用封装的自定义组件作为单元格内容时,监听这个组件的值变化并调用函数,可以通过以下步骤实现: 创建自定义组件:首先创建一个自定义的 Vue 组…...
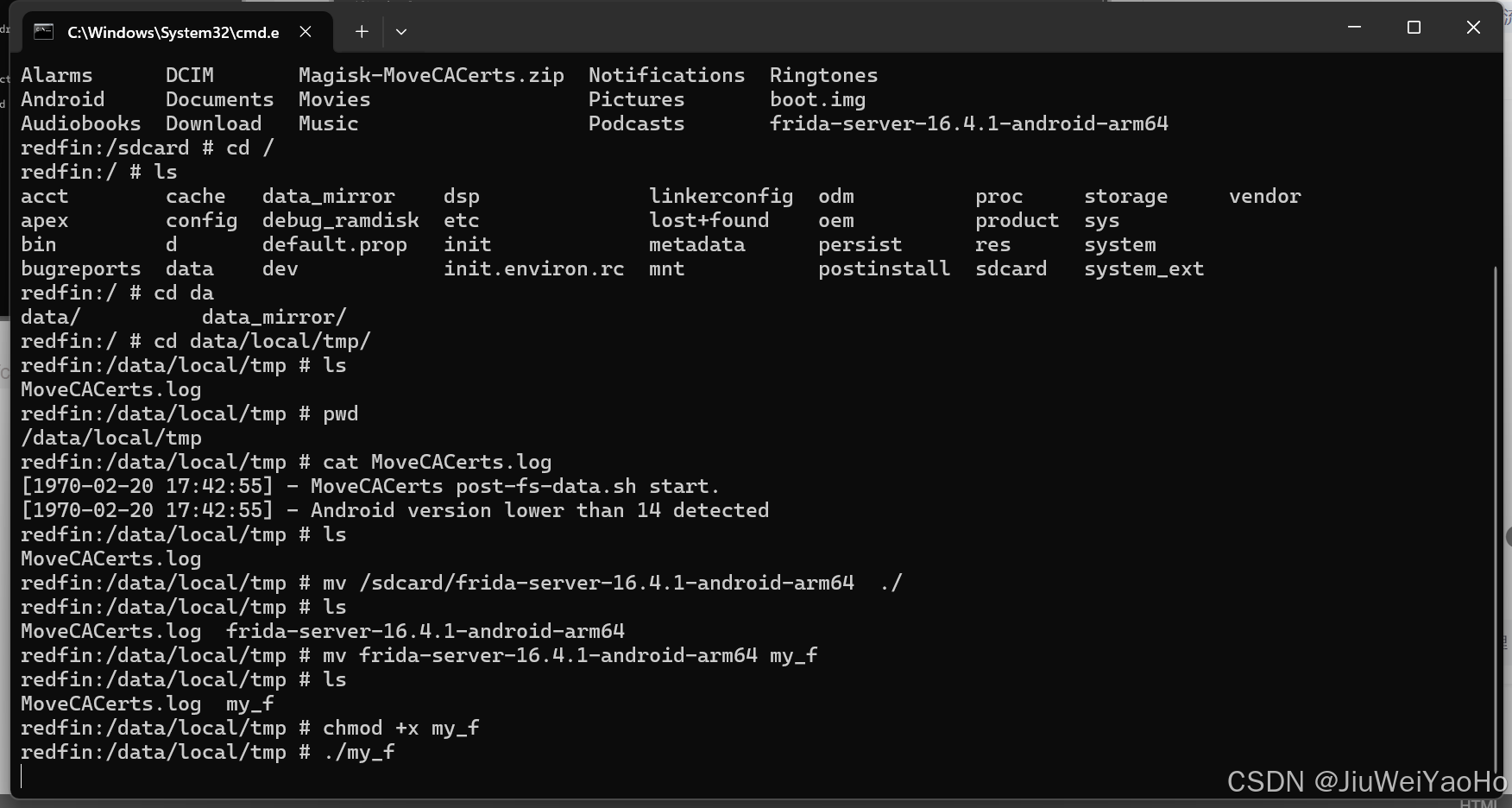
frida安装
开始安装 frida https://github.com/frida/frida/releases 下载安装的时候查看自己手机是多少位的 adb shell getprop ro.product.cpu.abi # 按照自己的机型下载进行解压里面有个文件放入到手机中开始进入手机 然后按照下面的图执行命令 其中log 我只是看了下 不需要执行因为刚…...

链表详解(三)
目录 链表功能实现链表的查找SLNode* SLFind(SLNode* phead, SLNDataType x)代码 链表任意位置前插入void SLInsert(SLNode**pphead,SLNode* pos, SLNDataType x)代码 链表任意位置前删除void SLErase(SLNode**pphead,SLNode* pos)代码 链表任意位置后插…...

[智能体-69]:重新认知MCP:协议不生产智能,只是AI全域交互的标准化基石
MCP只是提供了大模型、编排调度、外部工具能够进行结构化交流的标准,而整个系统的智能主要依赖编排调度,与外部软件系统的交互取决于外部工具,包括外部语音交互、视觉交互、数字化交互。当下MCP(Model Context Protocol࿰…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...

告别浪费!SolidWorks企业级共享方案,实现降本增效全攻略
还在为 SolidWorks 高昂的硬件投入和混乱的图纸管理头疼?告别“一人一机”的浪费模式,企业级共享方案才是降本增效的正解。这套攻略基于“1 台高性能服务器 云飞云共享云桌面”架构,帮你把硬件成本砍掉 60%,把软件利用率翻倍。一…...

2026智慧校园规划必读:如何在预算吃紧下选到高性价比方案
✅作者简介:合肥自友科技 📌核心产品:智慧校园平台(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...
)
Mysql:事务管理(中)
在前面的章节中,我们提到了 MVCC(多版本并发控制),它巧妙地通过“版本快照”解决了“读-写”冲突,实现了非阻塞读。但如果两个事务同时执行 UPDATE 操作修改同一行数据,即 写-写(Write-Write&am…...

论文润色深度测评:GPT-5.5 + Gemini 3.1 Pro:教你学会1+1>2的论文润色方法
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 2026年的科研圈,AI工具的选择已经从有没有变成了强不强,七哥评测了GPT…...

Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例
Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例 想象一下,医生通过CT扫描将人体内部结构分层呈现,而GIS中的"渔网"工具同样能对城市路网进行"切片式"分析。这种空间离散化技术&…...

ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南
ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 核心关键词:ZTE光猫工厂模式解锁 长尾关键词: ZT…...

Taotoken的审计日志功能为企业API安全与合规管理提供支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的审计日志功能为企业API安全与合规管理提供支持 当企业决定将大模型能力集成到内部业务流程中时,IT管理员和安…...

艾尔登法环存档迁移终极指南:3分钟解决角色转移难题
艾尔登法环存档迁移终极指南:3分钟解决角色转移难题 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档版本不兼容而烦恼吗?EldenRingSaveCopier 是你的终极解决…...