docker下迁移elasticsearch的问题与解决方案

🎏:你只管努力,剩下的交给时间
🏠 :小破站
docker下迁移elasticsearch的问题与解决方案
- 数据挂载
- 报错解决
- 权限问题
- 节点故障
直接上图,大致就是这样的操作
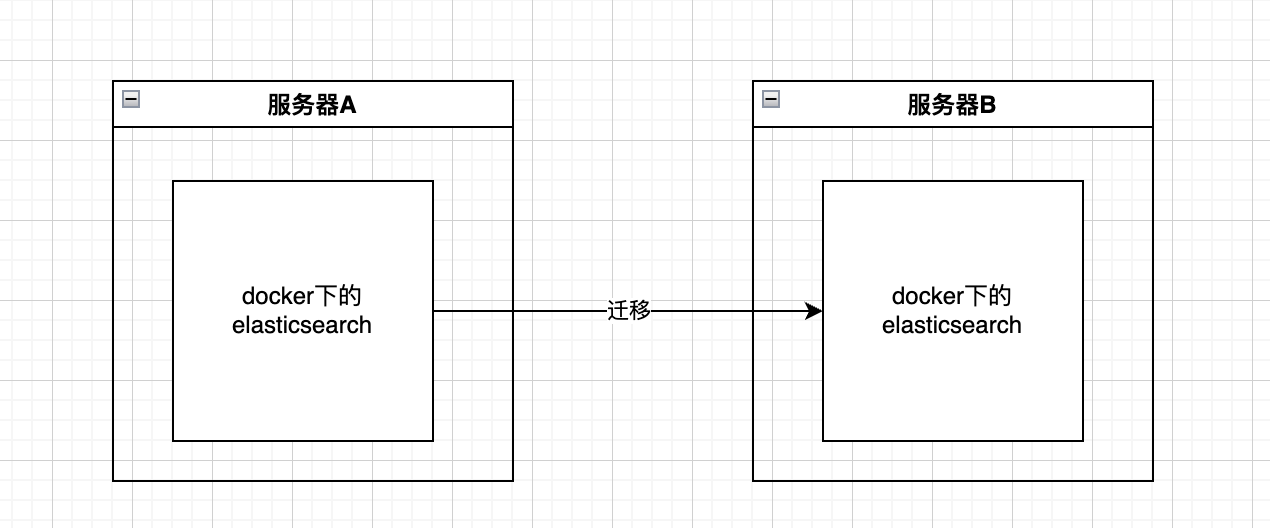
数据挂载
对于服务器A下的es如果你没有在启动容器的时候将数据挂载出来,就需要先进行docker cp,将容器中的数据拷贝到服务器中,
/usr/share/elasticsearch/data
将取出的数据,或者说挂载的数据,传输到另外一个服务器中,执行启动命令
警告:这里最好版本不要变动,以及启动时候的命令也和原服务器一致
至此迁移差不多就完成了。
报错解决
权限问题
java.lang.IllegalStateException: failed to obtain node locks, tried [[/usr/share/elasticsearch/data]] with lock id [0]; maybe these locations are not writable or multiple nodes were started without increasing [node.max_local_storage_nodes] (was [1])?
Likely root cause: java.nio.file.NoSuchFileException: /usr/share/elasticsearch/data/nodes/0/node.lockat java.base/sun.nio.fs.UnixException.translateToIOException(UnixException.java:92)at java.base/sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:106)at java.base/sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:111)at java.base/sun.nio.fs.UnixPath.toRealPath(UnixPath.java:825)at org.apache.lucene.store.NativeFSLockFactory.obtainFSLock(NativeFSLockFactory.java:108)at org.apache.lucene.store.FSLockFactory.obtainLock(FSLockFactory.java:41)at org.apache.lucene.store.BaseDirectory.obtainLock(BaseDirectory.java:45)at org.elasticsearch.env.NodeEnvironment$NodeLock.<init>(NodeEnvironment.java:229)at org.elasticsearch.env.NodeEnvironment.<init>(NodeEnvironment.java:298)at org.elasticsearch.node.Node.<init>(Node.java:427)at org.elasticsearch.node.Node.<init>(Node.java:309)at org.elasticsearch.bootstrap.Bootstrap$5.<init>(Bootstrap.java:234)at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:234)at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:434)at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:166)at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:157)at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:77)at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:112)at org.elasticsearch.cli.Command.main(Command.java:77)at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:122)at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:80)
For complete error details, refer to the log at /usr/share/elasticsearch/logs/docker-cluster.log
1. 节点锁文件丢失:/usr/share/elasticsearch/data/nodes/0/node.lock 文件不存在。可能是因为文件未被正确创建,或者数据目录的权限不足,导致 Elasticsearch 无法写入。
2. **目录或文件权限问题**:Elasticsearch 容器可能没有足够的权限访问或修改 /usr/share/elasticsearch/data 目录下的文件。
解决如下:
执行以下命令,重新启动即可
sudo chown -R 1000:1000 /acowbo/es # 假设你将 /acowbo/es 挂载到 /usr/share/elasticsearch/data
sudo chmod -R 775 /acowbo/es
节点故障
2024-10-29 02:15:31.912 ERROR 1 --- [io-11919-exec-4] o.a.c.c.C.[.[.[/].[dispatcherServlet] : Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Request processing failed; nested exception is ElasticsearchStatusException[Elasticsearch exception [type=search_phase_execution_exception, reason=all shards failed]]] with root cause
根据错误日志中的信息,Elasticsearch 报告了 all shards failed 和 no_shard_available_action_exception 错误。这通常表示 Elasticsearch 集群中有一个或多个分片不可用
-
执行
curl -X GET "http://127.0.0.1:9200/_cluster/health?pretty",这里你换为自己的ip和端口{"cluster_name" : "docker-cluster","status" : "red","timed_out" : false,"number_of_nodes" : 1,"number_of_data_nodes" : 1,"active_primary_shards" : 17,"active_shards" : 17,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 2,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 89.47368421052632 }
Elasticsearch 集群的 status 为 red,这表示集群中有一些分片处于未分配状态,导致集群不能正常工作。特别是,你的集群中有 2 个未分配的分片(unassigned shards),这可能导致你遇到的 all shards failed 错误。
- 执行
curl -X GET "http://156.224.28.178:9200/_cat/shards?v&pretty"获取详细信息
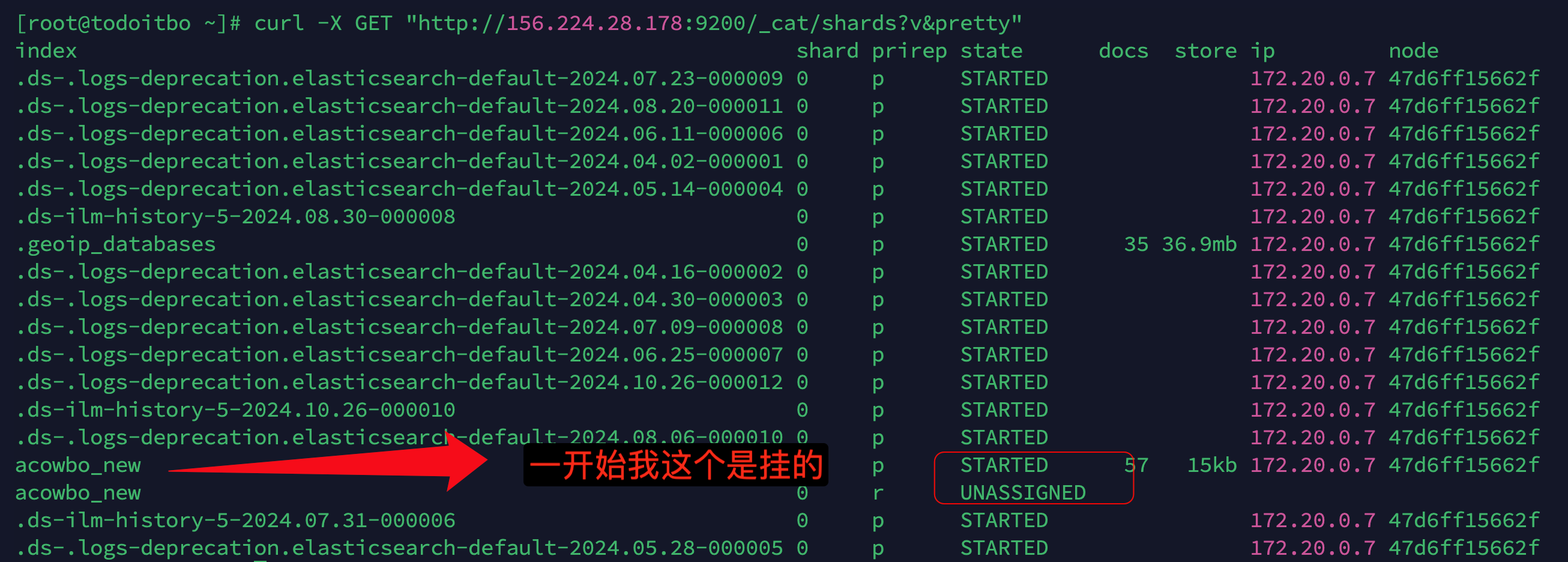
-
查看分片未分配的原因
curl -X GET "http://156.224.28.178:9200/_cluster/allocation/explain?pretty" -H 'Content-Type: application/json' -d '{"index": "acowbo_new","shard": 0,"primary": true }' -
结果如下
{"index" : "acowbo_new","shard" : 0,"primary" : true,"current_state" : "unassigned","unassigned_info" : {"reason" : "ALLOCATION_FAILED","at" : "2024-10-29T02:26:16.215Z","failed_allocation_attempts" : 5,"details" : "failed shard on node [GoDPmTuqSBavpUAHkq6yHQ]: failed to create index, failure IllegalArgumentException[Custom Analyzer [ik_analyzer] failed to find tokenizer under name [ik_smart]]","last_allocation_status" : "no"},"can_allocate" : "yes","allocate_explanation" : "can allocate the shard","target_node" : {"id" : "GoDPmTuqSBavpUAHkq6yHQ","name" : "47d6ff15662f","transport_address" : "172.20.0.8:9300","attributes" : {"ml.machine_memory" : "3973206016","xpack.installed" : "true","transform.node" : "true","ml.max_open_jobs" : "512","ml.max_jvm_size" : "268435456"}},"allocation_id" : "kGCNR2E2SjuOTRow7OtUEA","node_allocation_decisions" : [{"node_id" : "GoDPmTuqSBavpUAHkq6yHQ","node_name" : "47d6ff15662f","transport_address" : "172.20.0.8:9300","node_attributes" : {"ml.machine_memory" : "3973206016","xpack.installed" : "true","transform.node" : "true","ml.max_open_jobs" : "512","ml.max_jvm_size" : "268435456"},"node_decision" : "yes","store" : {"in_sync" : true,"allocation_id" : "kGCNR2E2SjuOTRow7OtUEA"}}] }
从错误信息来看,分片未能分配的原因是由于自定义分析器 ik_analyzer 未能找到名为 ik_smart 的分词器。这通常意味着在 Elasticsearch 的设置中配置的 ik_analyzer 依赖于一个未安装或未正确配置的分词器。
解决如下:
-
进入容器
docker exec -it 容器名/容器id /bin/bash -
执行
bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.16.2/elasticsearch-analysis-ik-7.16.2.zip
这里需要看你的es是什么版本的,就安装什么版本的插件
相关文章:
docker下迁移elasticsearch的问题与解决方案
欢迎来到我的博客,代码的世界里,每一行都是一个故事 🎏:你只管努力,剩下的交给时间 🏠 :小破站 docker下迁移elasticsearch的问题与解决方案 数据挂载报错解决权限问题节点故障 直接上图&#x…...

占地1.1万平,2亿投资的智能仓储系统:高架库、AGV、码垛机器人……
导语 大家好,我是社长,老K。专注分享智能制造和智能仓储物流等内容。 我国调味料市场近年来展现出惊人的增长潜力,各大品牌纷纷加大投入,力求在竞争中脱颖而出。 广东美味鲜调味食品有限公司,作为行业内的佼佼者&#…...

一个小程序如何对接多个收款账户?
背景 我又来了,之前对接过网约巴士系统 网约巴士旅游专线平台搭建历程,运营了两年多了。在运营中完善、在完善中学习,一直是不变的真理。有一句话说得好:先做一个垃圾、用起来再说。 今天又需要升级了,需求是&#…...
L2G4000 InternVL 部署微调实践闯关任务
一、理解多模态大模型的常见设计模式,可以大概讲出多模态大模型的工作原理。 视频地址 开源的多模态大模型:InternVL,Qwen-VL,LLaVA 闭源的:GPT-4o 研究重点:不同模态特征空间的对齐 BLIP2 将图像特征对…...

asynDriver-6-端口驱动
本地串口 drvAsynSerialPort驱动支持设备连接到IOC上串口。 用drvAsynSerialPortConfigure和asynSetOption命令配置串口: drvAsynSerialPortConfigure("portName","ttyName",priority,noAutoConnect,noProcessEosIn) asynSetOption("po…...

[免费]基于Python的Django+Vue3在线考试系统【论文+源码+SQL脚本】
大家好,我是java1234_小锋老师,看到一个不错的基于Python的DjangoVue3在线考试系统,分享下哈。 项目视频演示 【免费】基于Python的DjangoVue3在线考试系统 Python毕业设计_哔哩哔哩_bilibili 项目介绍 本论文提出并实现了一种基于Python…...

Python使用爬虫
一、基本介绍 爬虫(Web Scraping)是一种自动化获取网页内容的技术,它通过编写程序模拟浏览器的行为,从互联网上抓取网页数据。爬虫可以用于多种目的,比如数据收集、信息整合、自动化测试等。 二、常用的库 1、Request…...

CommunityToolkit.Mvvm如何使用
CommunityToolkit.Mvvm 是一个现代、快速和模块化的 MVVM 库,用于 .NET 应用程序。以下是如何使用 CommunityToolkit.Mvvm 的基本步骤: 安装包: 你可以通过 NuGet 包管理器安装 CommunityToolkit.Mvvm。在 Visual Studio 中,你可以…...
Python小游戏20——超级玛丽
首先,你需要确保你的Python环境中安装了pygame库。如果还没有安装,可以使用以下命令进行安装: bash pip install pygame 运行效果展示 代码展示 python import pygame import sys # 初始化pygame pygame.init() # 设置屏幕尺寸 screen_width …...
)
配置文件格式(xml、properties、yml/yaml)
配置文件格式(xml、properties、yml/yaml) 配置文件格式一、XML二、properties三、yml/yaml基本语法yml数据格式1、对象/Map集合1、数组/List/Set集合 配置文件格式 什么是配置文件?: 配置文件是包含应用程序或系统配置信息的文件…...

CentOS 7 软件/程序安装示例
安装软件/程序 wget,前提需要用 root 用户 1、搜索软件/程序 yum search wget 搜索到软件/程序。 2、安装软件/程序 yum -y install wget 安装完成。...

Python绘制正弦函数图形
1,绘制正弦函数图形,让数学看得见, import math # 导入函数模块 import turtle # 导入turtle模块,用于绘图t turtle.Turtle() # 创建对象 turtle.bgcolor("#2dded9") # 设置背景颜色 t.pencolor(blue) # 设置画笔…...

【LVGL-列表部件 lv_list_create】
LVGL-列表部件 lv_list_create ■ LVGL-列表部件-函数■ 修改样式-■ 修改样式- 背景色■ 修改样式- 改变项的颜色-label■ 修改样式- 改变项的颜色-btn ■ 事件(Event)■ 示例0:综合■ 示例1(自动出现滚动)■ 示例2(滚动捕捉&…...

【P2-6】ESP8266 WIFI模块在STA模式下实现UDP与电脑/手机网络助手通信——UDP数据透传
前言:完成ESP8266 WIFI模块在STA模式下实现UDP与电脑/手机网络助手通信——实现UDP数据透传 STA模式,通俗来说就是模块/单片机去连接路由器/热点来通信。 UDP协议,是传输层协议,UDP没有服务器和客户端的说法。 本实验需要注意,wifi模块/单片机与电脑/手机需要连接在同一个…...
-----剪枝基本概念)
从零学习大模型(十)-----剪枝基本概念
剪枝的基本概念 模型压缩中的地位:剪枝是模型压缩中的重要技术之一,它通过减少模型的参数量来降低计算资源的需求。对于大型神经网络,尤其是像BERT、GPT等参数量级巨大的模型,剪枝可以有效地减少模型的内存占用和计算量ÿ…...

Jest进阶知识:模拟 ES6 类 - 掌握类的依赖模拟与方法监听技巧
引言 在现代前端开发中,ES6 类(class)是常用的一种面向对象编程方式。在测试类的时候,我们经常需要模拟类的依赖,以避免外部因素对测试结果的影响。Jest 提供了强大的工具来模拟类及其方法,确保测试的高效…...

前端Nginx的安装与应用
目录 一、前端跨域方式 1.1、CORS(跨域资源共享) 1.2、JSONP(已过时) 1.3、WebSocket 1.4、PostMessage 1.5、Nginx 二、安装 三、应用 四、命令 4.1、基本操作命令 4.2、nginx.conf介绍 4.2.1、location模块 4.2.2、反向代理配置 4.2.3、负载均衡模块 4.2.4、通…...

Java设计模式(代理模式整理中ing)
一、代理模式 1、代理模式定义: 代理模式:由于某些原因要给某对象提供一个代理以控制对该对象的访问,这时访问对象不适合或者不能够直接引用目标对象,代理对象作为访问对象与目标对象之间的中介进行连接调控调用。 2、代理模式的…...

第J9周:Inception v3算法实战与解析(pytorch版)
>- **🍨 本文为[🔗365天深度学习训练营]中的学习记录博客** >- **🍖 原作者:[K同学啊]** 📌本周任务:📌 了解并学习InceptionV3相对与InceptionV1有哪些改进的地方 使用Inception完成天气…...

如何封装一个axios,封装axios有哪些好处
什么是Axios Axios 是一个基于 Promise 的 HTTP 客户端,用于在浏览器和 Node.js 中发送异步网络请求。它简化了发送 GET、POST、PUT、DELETE 等请求的过程,并且支持请求拦截、响应拦截、取消请求和自动处理 JSON 数据等功能。 为什么要封装Axios 封装…...

圈复杂度>12=技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露
更多请点击: https://codechina.net 第一章:圈复杂度>12技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露 当函数圈复杂度(Cyclomatic Complexity)持续高于12,它不再是…...

免费解锁AMD Ryzen隐藏性能:SMUDebugTool终极指南
免费解锁AMD Ryzen隐藏性能:SMUDebugTool终极指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcod…...

PDF差异对比神器diff-pdf:告别文档核对烦恼,提升工作效率的智能解决方案
PDF差异对比神器diff-pdf:告别文档核对烦恼,提升工作效率的智能解决方案 【免费下载链接】diff-pdf A simple tool for visually comparing two PDF files 项目地址: https://gitcode.com/gh_mirrors/di/diff-pdf 你是否曾在核对PDF文档时感到头疼…...

如何用500KB工具完全替代AWCC:AlienFX Tools终极指南
如何用500KB工具完全替代AWCC:AlienFX Tools终极指南 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 你是否厌倦了Alienware Command Cente…...

如何免费解锁AMD Ryzen处理器隐藏性能?SMUDebugTool完整使用指南
如何免费解锁AMD Ryzen处理器隐藏性能?SMUDebugTool完整使用指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: …...

别再乱调了!深度解析URP相机Culling Mask与Occlusion Culling,让你的游戏性能提升一个档次
别再乱调了!深度解析URP相机Culling Mask与Occlusion Culling,让你的游戏性能提升一个档次在Unity游戏开发中,性能优化是一个永恒的话题。尤其是使用URP(Universal Render Pipeline)进行开发时,相机的合理配…...

从零开始,在Hermes Agent项目中接入Taotoken服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从零开始,在Hermes Agent项目中接入Taotoken服务 基础教程类,引导使用Hermes Agent框架的开发者完成接入&a…...

Infineon/Cypress设备上Keil C51评估编译器4K版本使用指南
1. C51评估编译器在Infineon/Cypress设备上的使用指南作为一名长期从事嵌入式开发的工程师,我经常需要处理各种编译器的授权和版本问题。最近在Infineon/Cypress平台上使用Keil C51编译器时,遇到了评估版2K代码限制的问题。经过一番探索,我发…...

全方位防护矿山开采三维透明化智能安全防控整体方案
依托黎阳之光核心技术矿山开采三维透明化智能安全防控整体方案一、方案前言1.建设背景矿山开采井下巷道错综复杂、采掘工作面地质隐蔽,顶板、透水、瓦斯、边坡失稳、三违作业、设备故障为高发安全风险。传统二维监控、分散监测系统存在场景碎片化、地质不可视、风险…...
并计算卫星坐标)
保姆级教程:用Python解析北斗广播星历文件(RINEX 3.04格式)并计算卫星坐标
北斗卫星坐标计算实战:Python解析RINEX 3.04星历全流程 当我们需要获取北斗卫星的精确位置时,广播星历文件是最直接的数据来源。这份看似晦涩的文本文件,实际上包含了计算卫星位置所需的所有轨道参数。本文将带你从零开始,完整实现…...