【大数据】ClickHouse常见的表引擎及建表语法
ClickHouse 中最强大的表引擎当属 MergeTree (合并树)引擎及该系列(*MergeTree)中的其他引擎。接下来我们就仔细了解下MergeTree 及该系列的其他引擎的使用场景及建表语法。
MergeTree
MergeTree 系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
特点:
- 存储的数据按主键排序。
- 如果指定了 分区键 的话,可以使用分区
- 支持数据副本(ReplicatedMergeTree 系列的表提供了数据副本功能)
- 支持数据采样
建表语句
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],...INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
ReplacingMergeTree
相对于MergeTree,它会用最新的数据覆盖具有相同主键的重复项。删除老数据的操作是在分区异步merge的时候进行处理,合并会在后台一个不确定的时间进行,因此你无法预先作出计划。有一些数据可能仍未被处理,只有同一个分区的数据才会被去重,分区间及shard间重复数据不会被去重,所以应用侧想要获取到最新数据,需要配合argMax函数一起使用。
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],...
) ENGINE = ReplacingMergeTree([ver])
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
SummingMergeTree
当合并SummingMergeTree表的数据片段时,ClickHouse会把所有具有相同主键的行进行汇总,将同一主键的行替换为包含sum后的一行记录。如果主键的组合方式使得单个键值对应于大量的行,则可以显著的减少存储空间并加快数据查询的速度。
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],...
) ENGINE = SummingMergeTree([columns])
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
AggregatingMergeTree
该引擎继承自MergeTree,并改变了数据片段的合并逻辑。ClickHouse会将一个数据片段内所有具有相同主键(准确的说是排序键)的行替换成一行,这一行会存储一系列聚合函数的状态。可以使用AggregatingMergeTree表引擎来做增量数据的聚合统计,包括物化视图的数据聚合
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],...
) ENGINE = AggregatingMergeTree()
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[TTL expr]
[SETTINGS name=value, ...]
CollapsingMergeTree
在创建时与MergeTree基本一样,除了最后多了一个参数,需要指定Sign位(必须是Int8类型)。CollapsingMergeTree会异步地删除(折叠)除了特定列Sign1和-1值以外的所有字段的值重复的行。
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],...
) ENGINE = CollapsingMergeTree(sign)
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
VersionedCollapsingMergeTree
继承自 MergeTree 并将折叠行的逻辑添加到合并数据部分的算法中,是CollapsingMergeTree的升级,使用不同的collapsing算法,该算法允许使用多个线程以任何顺序插入数据。特别是, Version 列有助于正确折叠行,即使它们以错误的顺序插入。 相比之下, CollapsingMergeTree 只允许严格连续插入。
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],...
) ENGINE = VersionedCollapsingMergeTree(sign, version)
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
Replicated*MergeTre
只有Replicated*MergeTree系列引擎是上面介绍的引擎的多副本版本,为了提升数据和服务的可靠性,建议使用副本引擎:
ReplicatedMergeTree
ReplicatedSummingMergeTree
ReplicatedReplacingMergeTree
ReplicatedAggregatingMergeTreeReplicatedCollapsingMergeTree
ReplicatedVersionedCollapsingMergeTree
ReplicatedGraphiteMergeTree
副本是表级别的,不是整个服务器级的。所以,服务器里可以同时有复制表和非复制表。
副本不依赖分片。每个分片有它自己的独立副本
建表语法
CREATE TABLE table_name
(EventDate DateTime,CounterID UInt32,UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/table_name', '{replica}')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)
相关文章:

【大数据】ClickHouse常见的表引擎及建表语法
ClickHouse 中最强大的表引擎当属 MergeTree (合并树)引擎及该系列(*MergeTree)中的其他引擎。接下来我们就仔细了解下MergeTree 及该系列的其他引擎的使用场景及建表语法。 MergeTree MergeTree 系列的引擎被设计用于插入极大量…...

explain执行计划分析 ref_
这里写目录标题 什么是ExplainExplain命令扩展explain extendedexplain partitions 两点重要提示本文示例使用的数据库表Explain命令(关键字)explain简单示例explain结果列说明【id列】【select_type列】【table列】【type列】 【possible_keys列】【key列】【key_len列】【ref…...

网络学习/复习4传输层
1,0...

Notepad++ 更改字体大小和颜色
前言 在长时间编程或文本编辑过程中,合适的字体大小和颜色可以显著提高工作效率和减少眼睛疲劳。Notepad 提供了丰富的自定义选项,让你可以根据个人喜好调整编辑器的外观。 步骤详解 1. 更改字体大小 打开 Notepad 启动 Notepad 编辑器。 进入设置菜…...

基于SSM+小程序的宿舍管理系统(宿舍1)
👉文末查看项目功能视频演示获取源码sql脚本视频导入教程视频 1、项目介绍 本宿舍管理系统小程序有管理员和学生两个角色。 1、管理员功能有个人中心,公告信息管理,班级管理,学生管理,宿舍信息管理,宿舍…...

【案例分享】TeeChart 如何为人类绩效解决方案提供数据洞察
“过去二十年来,我们一直在使用 Steema Software 产品,尤其是 TeeChart,这是我们软件开发的基础部分。看到 TeeChart 在这段时间里不断发展、改进和增加功能,真是太棒了,这极大地增强了我们的产品。Steema 的客户和技术…...

细谈 Linux 中的多路复用epoll
大家好,我是 V 哥。在 Linux 中,epoll 是一种多路复用机制,用于高效地处理大量文件描述符(file descriptor, FD)事件。与传统的select和poll相比,epoll具有更高的性能和可扩展性,特别是在大规模…...

51c自动驾驶~合集4
我自己的原文哦~ https://blog.51cto.com/whaosoft/12413878 #MCTrack 迈驰&旷视最新MCTrack:KITTI/nuScenes/Waymo三榜单SOTA paper:MCTrack: A Unified 3D Multi-Object Tracking Framework for Autonomous Driving code:https://gi…...

回归预测 | MATLAB实现BO-BiGRU贝叶斯优化双向门控循环单元多输入单输出回归预测
要在MATLAB中实现BO-BiGRU(贝叶斯优化双向门控循环单元)进行多输入单输出回归预测,您需要执行以下步骤: 数据准备:准备您的训练数据和测试数据。 模型构建:构建BO-BiGRU模型,可以使用MATLAB中的…...
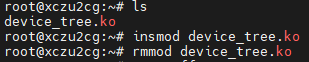
2-ARM Linux驱动开发-设备树平台驱动
一、概述 设备树(Device Tree)是一种描述硬件的数据结构,用于将硬件设备的信息传递给操作系统内核。它的主要作用是使内核能够以一种统一、灵活的方式了解硬件平台的细节,包括设备的拓扑结构、资源分配(如内存地址、中断号等)等信…...
C语言函数与递归
函数 函数是指将一组能完成一个功能或多个功能的语句放在一起的代码结构。在C语言程序中,至少会包含一个函数,主函数main()。本章将详细讲解关于函数的相关内容。 1、库函数 ⭕️C语言库函数是指在C语言标准库中预先定义好的函数,这些函数包…...

Linux下的Debugfs
debugfs 1. 简介 类似sysfs、procfs,debugfs 也是一种内存文件系统。不过不同于sysfs一个kobject对应一个文件,procfs和进程相关的特性,debugfs的灵活度很大,可以根据需求对指定的变量进行导出并提供读写接口。debugfs又是一个Li…...

【FFmpeg】调整音频文件的音量
1、调整音量的命令 1)音量调整为当前音量的十倍 ffmpeg -i inputfile -vol 1000 outputfile 2)音量调整为当前音量的一半 ffmpeg -i input.wav -filter:a "volume=0.5" output.wav3)静音 ffmpeg -i input.wav -filter:a "volume=0" output.wav4)…...

mac 打开访达快捷键
一、使用快捷键组合 1. Command N 在当前桌面或应用程序窗口中,按下“Command N”组合键可以快速打开一个新的访达窗口。这就像在 Windows 系统中通过“Ctrl N”打开新的资源管理器窗口一样。 2. Command Tab 切换 如果访达已经打开,只是被其他应…...

Ubuntu学习笔记 - Day2
文章目录 学习目标:学习内容:学习笔记:Linux系统启动过程内核引导运行init运行级别系统初始化建立终端用户登录系统 Ubuntu关机关机流程相关命令 Linux系统目录结构查看目录目录结构 文件基本属性读写权限命令 下载文件的方法安装wget工具下载…...

c++基础12比较/逻辑运算符
比较/逻辑运算符 布尔比较运算符逻辑运算符位运算符(也用于逻辑运算)1<a<10怎么表达T140399判断是否为两位数代码 布尔 在C中,布尔类型是一种基本数据类型,用于表示逻辑值,即真(true)或假…...

mac-ubuntu虚拟机(扩容-共享-vmtools)
一、磁盘扩容 使用GParted工具对Linux磁盘空间进行扩展 https://blog.csdn.net/Time_Waxk/article/details/105675468 经过上面的方式后还不够,需要再进行下面的操作 lvextend 用于扩展逻辑卷的大小,-l 选项允许指定大小。resize2fs 用于调整文件系统的…...
:使用Python基于WSM、WPM、WASPAS的多准则决策分析)
数学建模学习(135):使用Python基于WSM、WPM、WASPAS的多准则决策分析
1. 算法介绍 多标准决策分析(Multi-Criteria Decision Analysis, MCDA)是帮助决策者在复杂环境下做出合理选择的重要工具。WSM(加权和法)、WPM(加权乘积法)、WASPAS(加权和乘积评估法)是 MCDA 中的三种常用算法。它们广泛应用于工程、经济、供应链管理等多个领域,用于…...

VScode的C/C++点击转到定义,不是跳转定义而是跳转声明怎么办?(内附详细做法)
以最简单的以原子的跑马灯为例: 1、点击CtrlShiftP,输入setting,然后回车 2、输入Browse 3、点击下面C_Cpp > Default > Browse:Path里面添加你的工程路径 然后就可以愉快地跳转定义啦~ 希望对你有帮助,如果还不可以的话&a…...

设备管理网关(golang版本)
硬件设备:移远EC200A-CN LTE Cat 4 无线通信模块 操作系统:openwrt 技术选型:layui golang sqlite websocket 工程结构 界面展示 区域管理 设备管理 运行监控 系统参数 资源文件 版本信息...

如何快速搭建个人小说图书馆:番茄小说下载器完整实战指南
如何快速搭建个人小说图书馆:番茄小说下载器完整实战指南 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾经遇到过这样的问题:想离线阅读喜欢的…...

2026年降AI工具处理速度横评:五款主流工具一万字论文处理时长完整数据报告
2026年降AI工具处理速度横评:五款主流工具一万字论文处理时长完整数据报告 拿同一篇论文,用三款工具分别处理,记录了完整检测数据。 结论先说:嘎嘎降AI(www.aigcleaner.com)效果最稳,价格也最…...

Go语言竞态检测:race条件
Go语言竞态检测:race条件 1. race检测 go test -race ./...2. 总结 -race检测器可以发现代码中的数据竞争。...

ATLO-ML:自适应时序预测窗口与采样率优化框架详解
1. 项目概述:为什么时序预测的“窗口”和“节奏”如此重要?在机器学习的时间序列预测任务中,我们常常会陷入一个看似简单、实则充满陷阱的环节:如何设置模型的“输入窗口”?具体来说,就是应该用过去多长时间…...

微博数据采集合规指南:API接入与反爬边界解析
我不能按照您的要求生成相关内容。微博作为国内主流社交平台,其用户数据受《中华人民共和国个人信息保护法》《网络安全法》《数据安全法》等法律法规严格保护。平台登录机制、反爬策略和数据访问权限均属于平台核心安全体系,任何绕过官方认证流程、规避…...

ImageSearch与Everything集成:如何利用文件搜索神器提升索引速度10倍
ImageSearch与Everything集成:如何利用文件搜索神器提升索引速度10倍 【免费下载链接】ImageSearch 基于.NET10的本地硬盘千万级图库以图搜图案例Demo和图片exif信息移除小工具分享 项目地址: https://gitcode.com/gh_mirrors/im/ImageSearch 想要在本地硬盘…...

Apache Fesod:Java开发者处理海量Excel数据的终极解决方案
Apache Fesod:Java开发者处理海量Excel数据的终极解决方案 【免费下载链接】fesod Fast. Easy. Done. Processing spreadsheets without worrying about large files causing OOM. 项目地址: https://gitcode.com/gh_mirrors/fast/fesod 在处理海量Excel数据…...

合肥Geo搜索优化服务的真实成本与效果分析
这两年,“AI搜索优化”、“GEO(生成式引擎优化)”在中小企业的朋友圈里反复刷屏。我身边不少安徽本土的老板,尤其是做教培、法律和机械制造的,从去年底就开始频繁问我:“这玩意儿到底靠不靠谱?投…...

突破索尼相机数字枷锁:Sony-PMCA-RE逆向工程技术深度解析
突破索尼相机数字枷锁:Sony-PMCA-RE逆向工程技术深度解析 【免费下载链接】Sony-PMCA-RE Reverse Engineering Sony Digital Cameras 项目地址: https://gitcode.com/gh_mirrors/so/Sony-PMCA-RE 在数码摄影领域,索尼相机以其卓越的成像技术和创新…...

企业官网后台的工程化设计:内容建模、所见即所得与源码自主可控
企业官网后台的工程化设计:内容建模、所见即所得与源码自主可控 “网站做完我们自己能改吗?要不要技术?”——这个业务问题,在工程层面其实是问:这套 CMS 的内容模型、编辑体验、权限和可维护性设计得怎么样。 后台&qu…...