Elasticsearch:在搜索中使用衰减函数(Gauss)
在我之前的文章 “Elasticsearch:使用 function_score 及 script_score 定制搜索结果的分数” 我有讲到 Decay 函数在搜索中的使用。在那里,我有一个例子讲述在规定的时间里,分数不进行衰减。同一的函数也可以适用于地理位置的搜索。位置搜索的范围在规定范围里可以不进行衰减,超过这个范围就会按照衰减函数进行衰减。
想象一下,你需要根据用户位置的接近程度对结果进行排序。完成此任务的方法之一是使用定位和衰减函数。 衰减函数可用于根据比例调整文档的相关性分数。
在我们的示例中,我们将注册一些餐厅,并从用户的位置返回最近的餐厅。
让我们创建我们的地图,现在我们将使用 geo_point 类型,因为我们将使用纬度和经度。
PUT restaurants
{"mappings": {"properties": {"title": {"type": "text"},"location": {"type": "geo_point"}}}
}现在让我们插入一些文档:
POST restaurants/_bulk
{"index":{}}
{"title":"McDonald's 1000","location":{"lat" : -23.525920 ,"lon" : -46.650211}}
{"index":{}}
{"title":"McDonald's Caneca","location":{"lat" : -23.553720 ,"lon" : -46.652940}}
{"index":{}}
{"title":"McDonald's Paulista","location":{"lat" : -23.565920 ,"lon" : -46.650210}}
{"index":{}}
{"title":"McDonald's - Shopping Pátio Higienópolis","location":{"lat" : -23.582460 ,"lon" : -46.688560}}上面的命令将创建 4 个位置文档。假如我们想在位置 [-23.542719, -46.653965] 进行搜索。它们的相对位置关系如下:
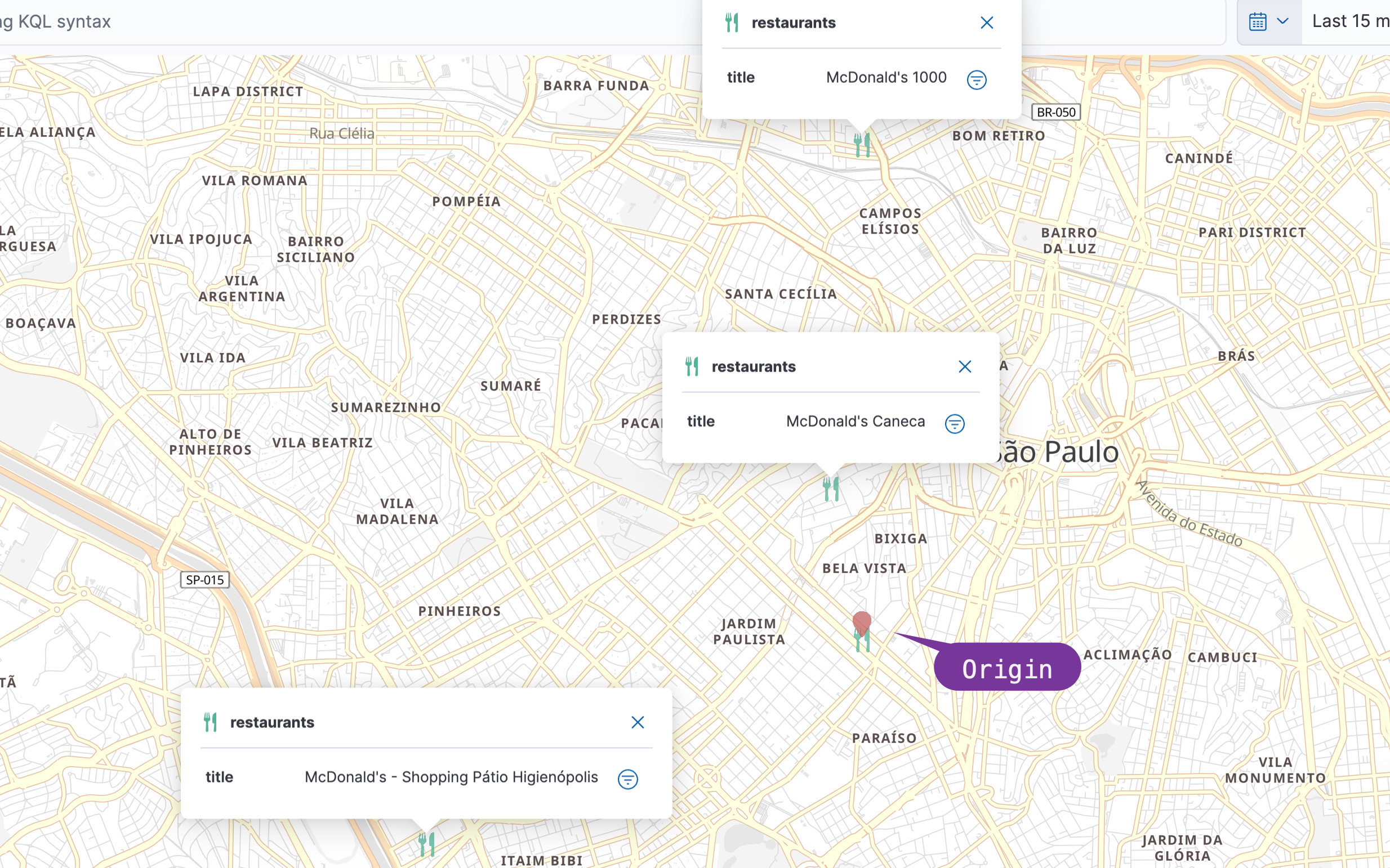
在我们的查询中,我们将使用 Function score query | Elasticsearch Guide [8.6] | Elastic 和 Gaussian 函数,我们希望距离半径 500 米的人获得最大得分(origin - offset <= value <= origin + offset)和 200m (scale) 分数将开始下降。根据 Gaussian function的曲线分布,超过一定的范围衰减非常之快,以至于很快到 0。
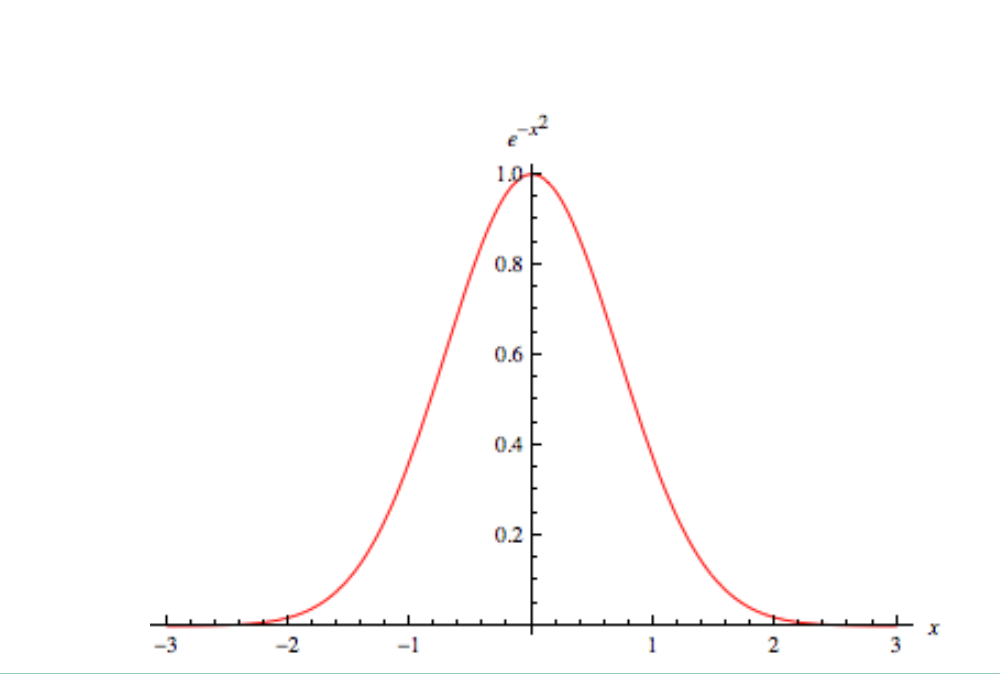
在第一个测试中,我们将使用原点 -23.561581、-46.659540。 此搜索的结果将是最接近的(请注意分数如何随着离原点越远而降低):
GET restaurants/_search?filter_path=**.hits
{"query": {"function_score": {"query": {"match": {"title": {"query": "McDonald's"}}},"functions": [{"gauss": {"location": {"origin": {"lat": -23.542719,"lon": -46.653965},"offset": "500m","scale": "200m","decay": "0.5"}},"weight": 10}],"boost_mode": "replace"}}
}参数说明:
| 项目 | 说明 |
|---|---|
| origin | 用于计算距离的原点。 必须以数字字段的数字、日期字段的日期和地理字段的地理点的形式给出。 地理和数字字段必填。 对于日期字段,默认值为现在。 origin 支持日期数学(例如 now-1h)。 |
| scale | 所有类型都需要。 定义距离原点的距离 + 偏移量,在该距离处计算的分数将等于衰减参数。 对于地理字段:可以定义为数字+单位(1km,12m,...)。 默认单位是米。 对于日期字段:可以定义为数字+单位(“1h”、“10d”、… )。 默认单位是毫秒。 对于数字字段:任何数字。 |
| offset | 如果定义了偏移量,衰减函数将只计算距离大于定义的偏移量的文档的衰减函数。 默认值为 0。 |
| decay | decay 参数定义了如何在按比例给定的距离对文档进行评分。 如果没有定义衰减,则距离 scale 的文档将得分为 0.5。 |
上述查询在离 origin 开始的 200m + 500m 开始进行衰减。它的衰减因子为 0.5。在这个以 200m + 500m 为圆半径的文档得分值将保持不变。
运行上面查询的结果为:
{"hits": {"hits": [{"_index": "restaurants","_id": "QxqBNYYB2XodIZsbBsV5","_score": 0.0010342363,"_source": {"title": "McDonald's Caneca","location": {"lat": -23.55372,"lon": -46.65294}}},{"_index": "restaurants","_id": "QhqBNYYB2XodIZsbBsV5","_score": 1.2783469e-14,"_source": {"title": "McDonald's 1000","location": {"lat": -23.52592,"lon": -46.650211}}},{"_index": "restaurants","_id": "RBqBNYYB2XodIZsbBsV5","_score": 3.5952473e-33,"_source": {"title": "McDonald's Paulista","location": {"lat": -23.56592,"lon": -46.65021}}},{"_index": "restaurants","_id": "RRqBNYYB2XodIZsbBsV5","_score": 0,"_source": {"title": "McDonald's - Shopping Pátio Higienópolis","location": {"lat": -23.58246,"lon": -46.68856}}}]}
}正像我们看到的那样,搜索的结果是我们所期望的。从返回的分数来看在范围里的文档的分数不受影响,但是一旦超出范围,搜索到的文档的分数会被加权并得到衰减。
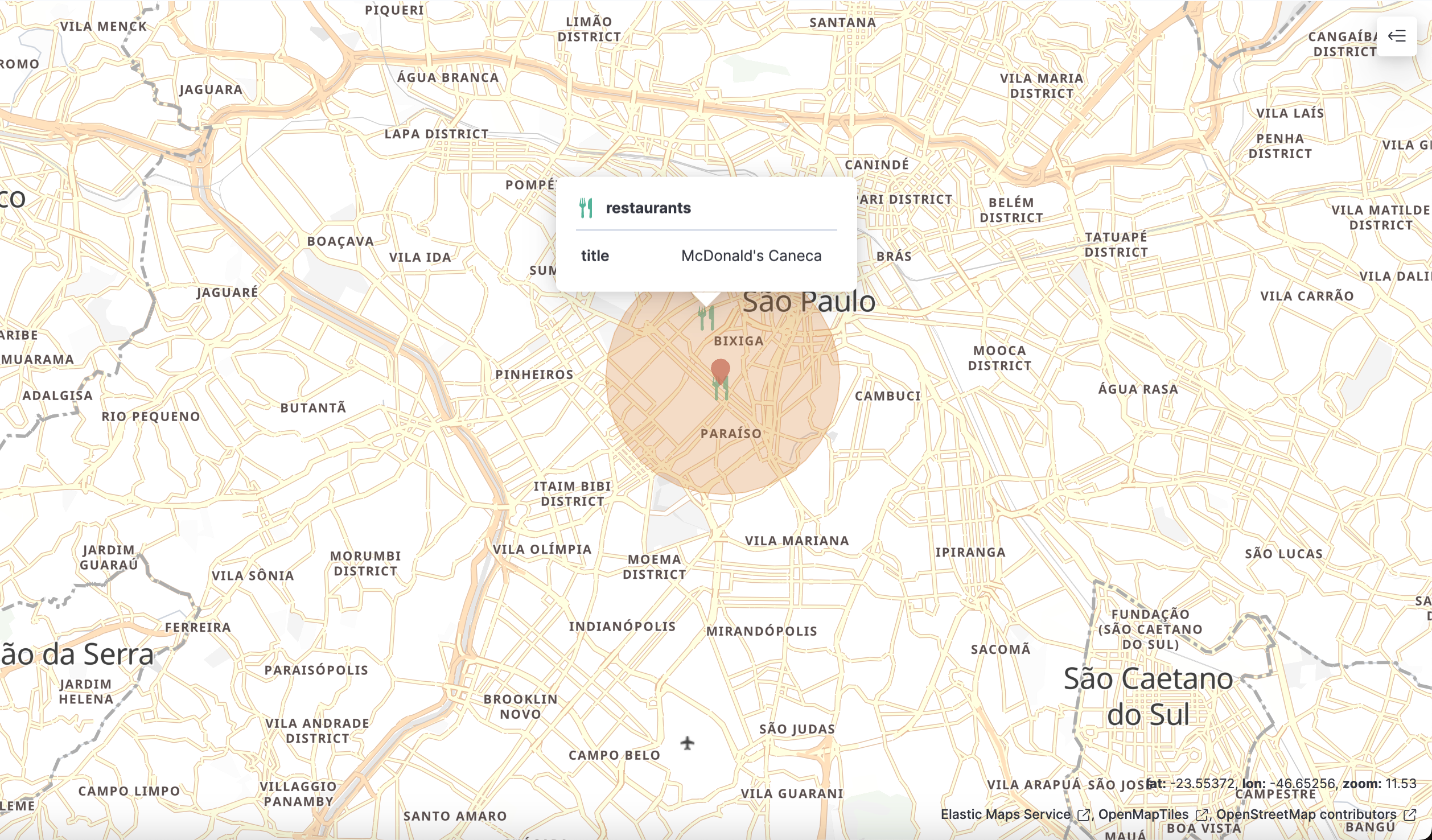
我们再次修改 origin 的位置到 -23.542719, -46.653965。它们的相对关系显示如下:
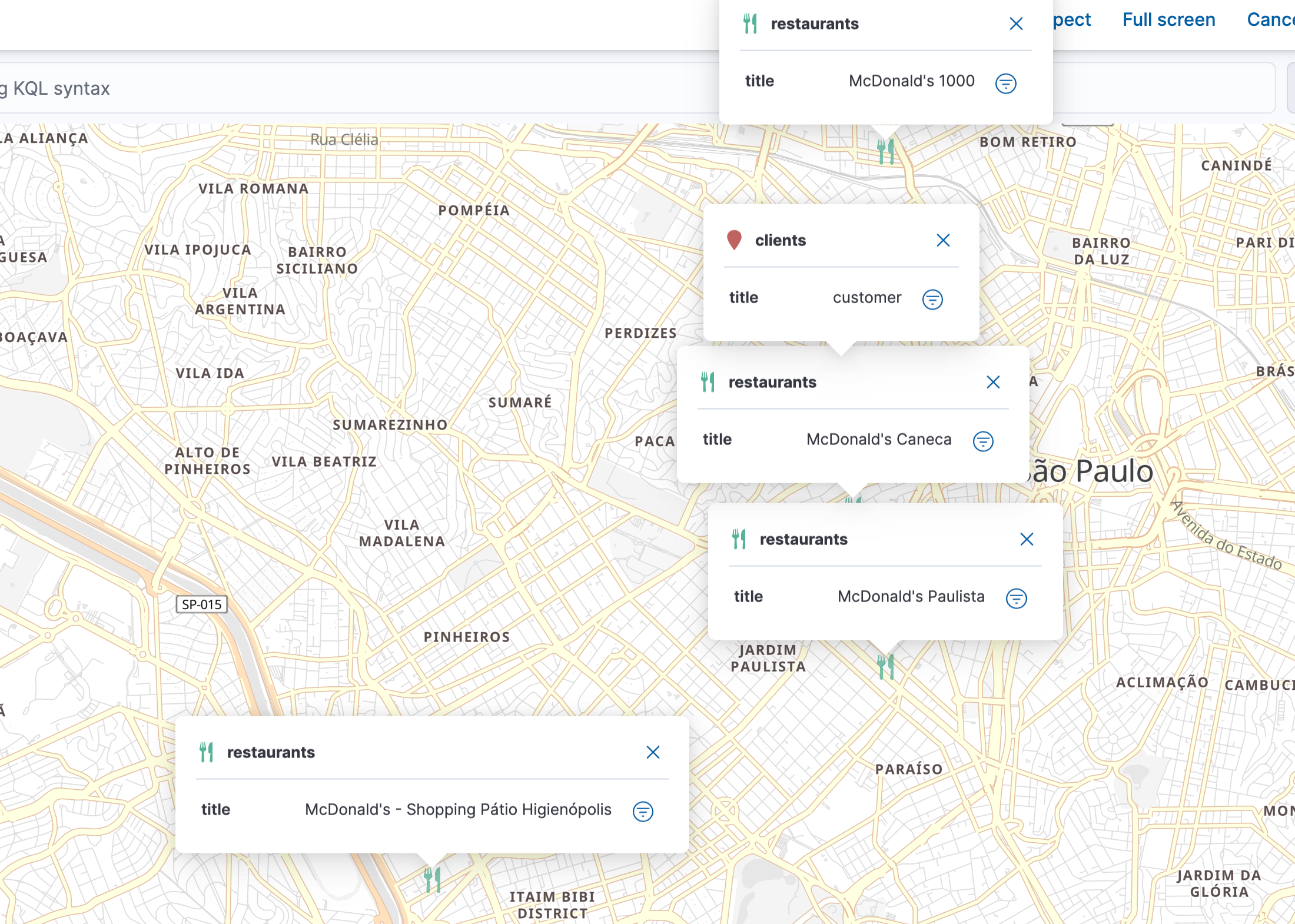
我们再次进行搜索:
GET restaurants/_search?filter_path=**.hits
{"query": {"function_score": {"query": {"match": {"title": {"query": "McDonald's"}}},"functions": [{"gauss": {"location": {"origin": {"lat": -23.542719,"lon": -46.653965},"offset": "500m","scale": "200m","decay": "0.5"}},"weight": 10}],"boost_mode": "replace"}}
}我们可以看到如下的结果:
{"hits": {"hits": [{"_index": "restaurants","_id": "QxqBNYYB2XodIZsbBsV5","_score": 0.0010342363,"_source": {"title": "McDonald's Caneca","location": {"lat": -23.55372,"lon": -46.65294}}},{"_index": "restaurants","_id": "QhqBNYYB2XodIZsbBsV5","_score": 1.2783469e-14,"_source": {"title": "McDonald's 1000","location": {"lat": -23.52592,"lon": -46.650211}}},{"_index": "restaurants","_id": "RBqBNYYB2XodIZsbBsV5","_score": 3.5952473e-33,"_source": {"title": "McDonald's Paulista","location": {"lat": -23.56592,"lon": -46.65021}}},{"_index": "restaurants","_id": "RRqBNYYB2XodIZsbBsV5","_score": 0,"_source": {"title": "McDonald's - Shopping Pátio Higienópolis","location": {"lat": -23.58246,"lon": -46.68856}}}]}
}这是介绍衰减函数的方法之一,我希望它有用。
相关文章:
Elasticsearch:在搜索中使用衰减函数(Gauss)
在我之前的文章 “Elasticsearch:使用 function_score 及 script_score 定制搜索结果的分数” 我有讲到 Decay 函数在搜索中的使用。在那里,我有一个例子讲述在规定的时间里,分数不进行衰减。同一的函数也可以适用于地理位置的搜索。位置搜索…...
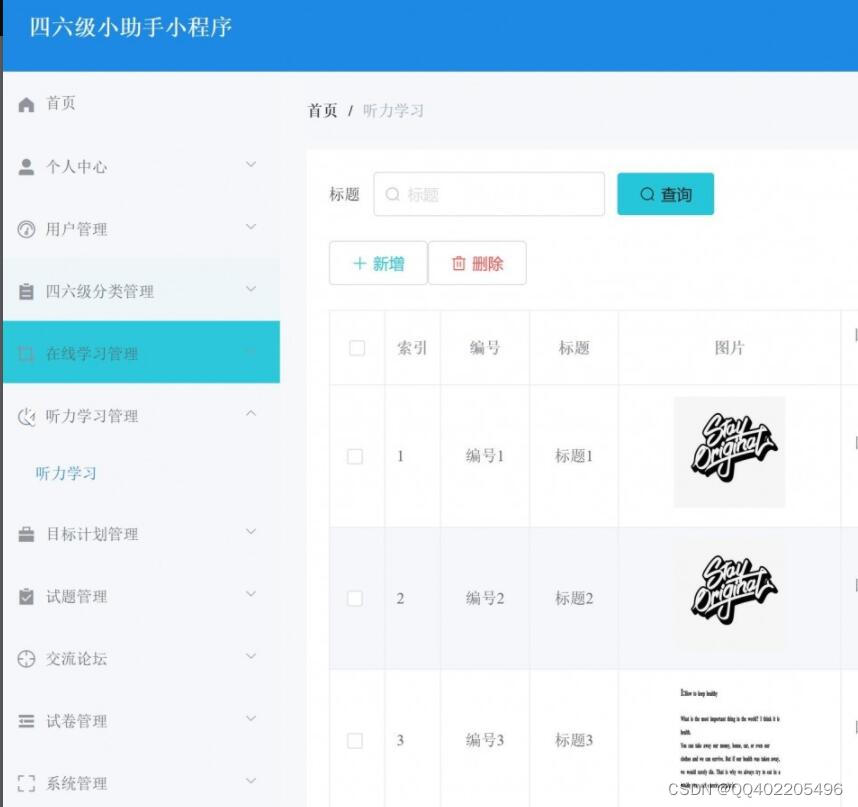
微信小程序 Springboot英语在线学习助手系统 uniapp
四六级助手系统用户端是基于微信小程序端,管理员端是基于web端,本系统是基于java编程语言,mysql数据库,idea开发工具, 系统分为用户和管理员两个角色,其中用户可以注册登陆小程序,查看英语四六级…...

LeetCode算法题解——双指针2
LeetCode算法题解——双指针2第五题思路代码第六题思路代码第七题思路代码这里介绍双指针在数组中的第二类题型:两端夹击。 第五题 977. 有序数组的平方 题目描述: 给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的…...

线性杂双功能peg化试剂——HS-PEG-COOH,Thiol-PEG-Acid
英文名称:HS-PEG-COOH,Thiol-PEG-Acid 中文名称:巯基-聚乙二醇-羧基 HS-PEG-COOH是一种含有硫醇和羧酸的线性杂双功能聚乙二醇化试剂。它是一种有用的带有PEG间隔基的交联或生物结合试剂。巯基或SH、巯基或巯基选择性地与马来酰亚胺、OPSS、…...
Linux第三讲
目录 三、 磁盘和文件管理和使用检测和维护 3.1 磁盘目录 3.2 安装软件 3.2.1 rpm命令 3.2.2 克隆虚拟机 3.2.3 yum或压缩包方式安装jdk 3.2.4 使用虚拟机运行SpringBoot项目 3.2.5 安装mysql80(57) 3.2.6 运行web项目 3.2.7 安装tomcat 三、 …...
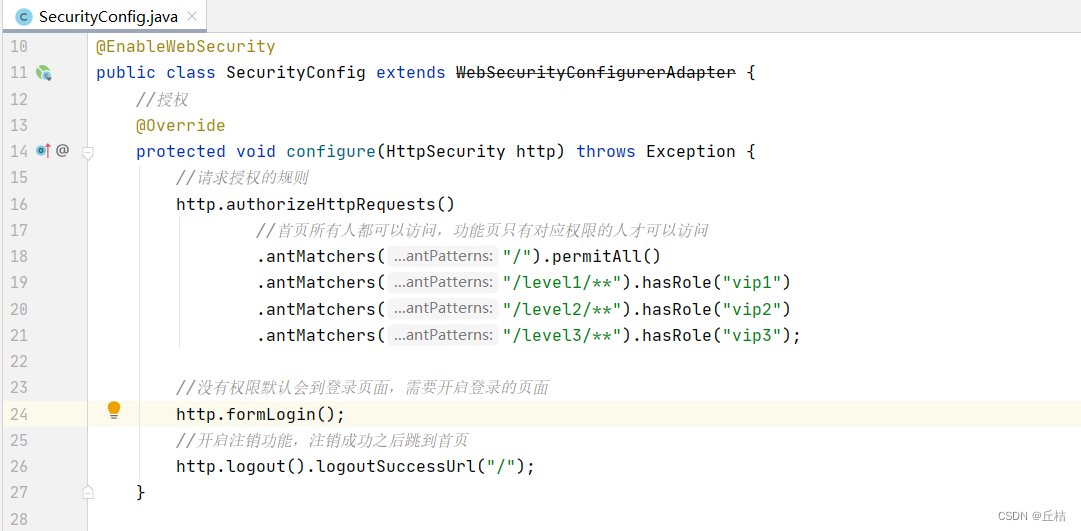
SpringBoot07:SpringSecurity
Security是什么? 是一个安全框架。可以用来做认证和授权 官网:Spring Security SpringSecurity环境搭建 1、创建一个新的project 2、导入thymeleaf依赖 <dependency><groupId>org.thymeleaf</groupId><artifactId>thymeleaf…...

C++ 浅谈之 STL Vector
C 浅谈之 STL Vector HELLO,各位博友好,我是阿呆 🙈🙈🙈 这里是 C 浅谈系列,收录在专栏 C 语言中 😜😜😜 本系列阿呆将记录一些 C 语言重要的语法特性 🏃&…...
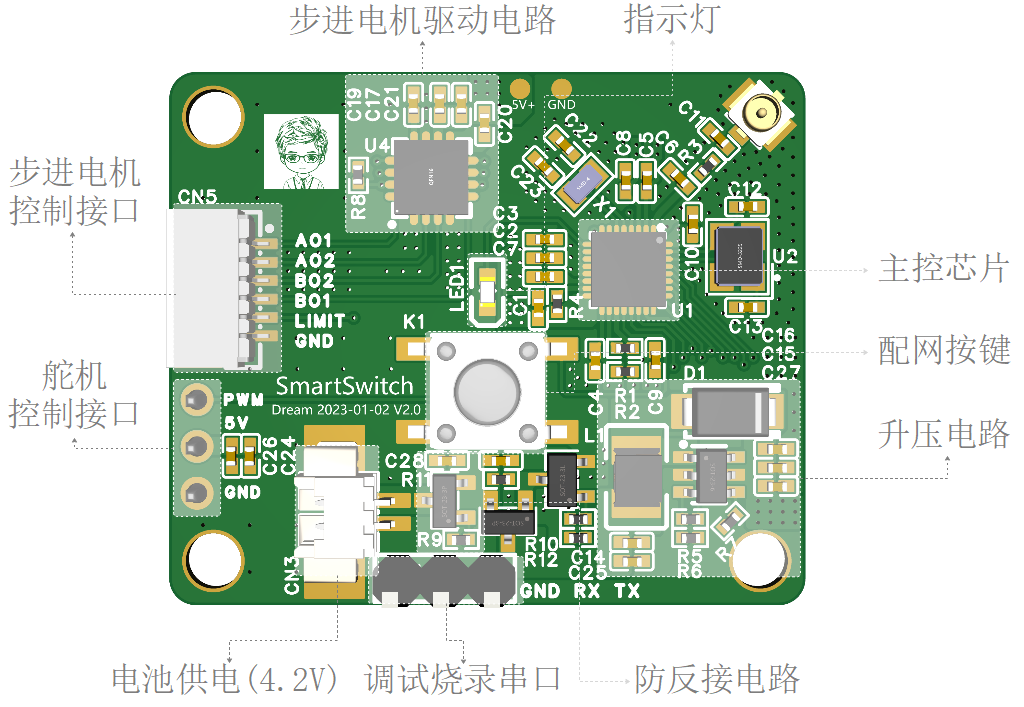
【个人作品】非侵入式智能开关
一、产品简介 一款可以通过网络实现语音、APP、小程序控制,实现模拟手动操作各种开关的非侵入式智能开关作品。 非侵入式,指的是不需要对现有的电路和开关做任何改动,只需要将此设备使用魔术无痕胶带固定在旁边即可。 以下为 ABS 材质的渲…...
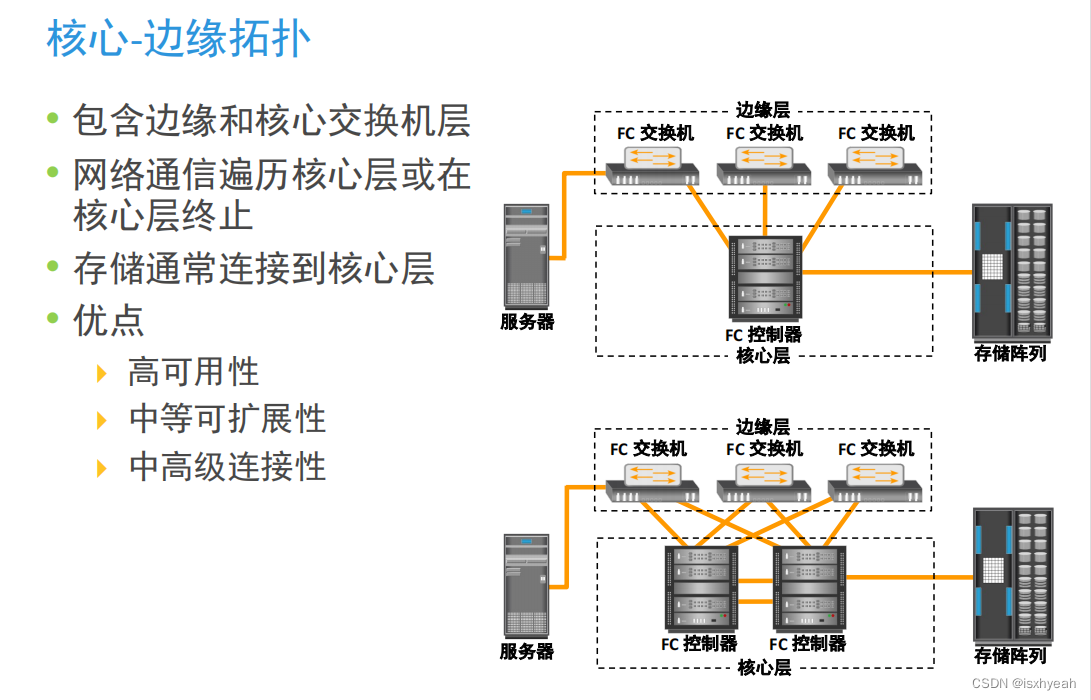
数据存储技术复习(三)未完
module4智能存储系统是功能丰富且可提供高度优化的I/o处理能力的RAID阵列。请绘制智能存储系统架构,并说明其各个关键组件的主要功能。前端缓存后端物理磁盘2.智能存储系统中,使用缓存进行的写入操作与直接写入到磁盘相比,可以带来…...

ThinkPHP数据库迁移工具
安装 composer require topthink/think-migration 创建迁移工具文件 //执行命令,创建一个操作文件,一定要用大驼峰写法,如下 php think migrate:create AnyClassNameYouWant //执行完成后,会在项目根目录多一个database目录,这里面存放类库操作文件 //文件名类似/database/m…...

代理模式(Proxy Pattern)
代理模式定义: 提供了对目标对象另外的访问方式;即通过代理对象访问目标对象。举个例子:猪八戒去找高翠兰结果是孙悟空变的,可以这样理解:把高翠兰的外貌抽象出来,高翠兰和孙悟空都实现了这个接口ÿ…...

Elasticesearch内存详解
1.ES基本概念 为了更好的理解内存,我们先看一下ES的基本概念。 1.1 cluster 集群 多个节点组合在一起就形成了一个集群,在每个ES节点中,我们可以通过配置集群的名称来使各个节点组合在一起,成为一个集群。当某些节点的集群名称一样,ES会自动根据配置文件中的地址找到这些…...
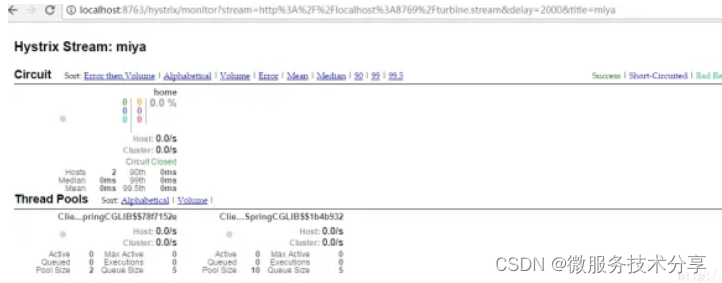
SpringCloud之断路器聚合监控
一、Hystrix Turbine简介 看单个的Hystrix Dashboard的数据并没有什么多大的价值,要想看这个系统的Hystrix Dashboard数据就需要用到Hystrix Turbine。Hystrix Turbine将每个服务Hystrix Dashboard数据进行了整合。Hystrix Turbine的使用非常简单,只需要…...
凭借这份《2022测试八股文》候选者逆袭面试官,offer拿到手软
《2023测试面试八股文》800 道软件测试面试真题,高清打印版打包带走,横扫软件测试面试高频问题,涵盖测试理论、Linux、MySQL、Web 测试、接口测试、App 测试、Python、Selenium、性能测试、LordRunner、计算机网络、数据结构与算法、逻辑思维…...
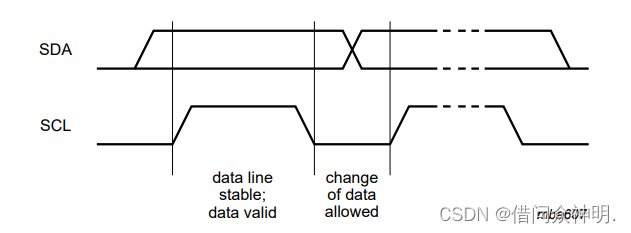
【i2c协议介绍】
文章目录协议简单介绍五种速度模式master/slave和transmitter/receiver关系第一种情况:master作为transmitter,slave作为receiver第二种情况:当master作为receiver,slave作为transmitteri2c基本信号start产生stop信号数据传输有效…...

167. 两数之和 II - 输入有序数组
给你一个下标从 1 开始的整数数组 numbers ,该数组已按 非递减顺序排列 ,请你从数组中找出满足相加之和等于目标数 target 的两个数。如果设这两个数分别是 numbers[index1] 和 numbers[index2] ,则 1 < index1 < index2 < numbers…...

编译与链接------《程序员的自我修养》
本篇整理于《程序员的自我修养》一书中编译与链接相关知识,整理的目的是为了更加深入的了解编译于链接的更多底层知识,面对程序运行时种种性能瓶颈我们束手无策。我们看到的是这些问题的现象,但是却很难看清本质,所有这些问题的本质就是软件运…...

5分钟搞懂 强缓存与协商缓存
Ⅰ、http缓存 HTTP 缓存策略 分为 > 「强制缓存」 和 「协商缓存」 为什么需要 HTTP 缓存 呢 ? 👇 直接使用缓存速度 >> 远比重新请求快 缓存对象有那些呢 ?👇 「图片」 「JS文件」 「CSS文件」 等等 文章目录Ⅰ、http缓存Ⅱ…...
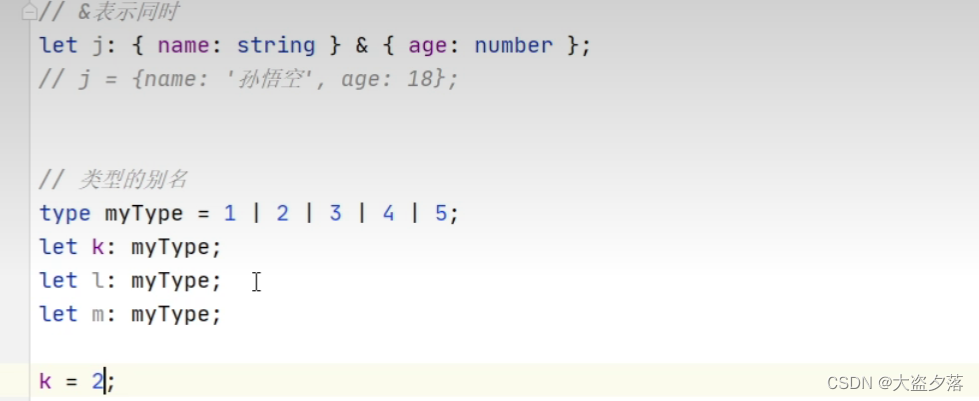
Ts笔记第一天
文章目录安装 ts运行环境 nodeTS类型数字 、字符串 和布尔类型字面量any 和unknown类型断言void和neverobjectArraytuple 元组enum 枚举安装 ts运行环境 node node-v看版本号 2. 安装ts -g全局安装 npm i -g typescript // 这里全局安装 -s安装无法使用tsc 创建一个01.ts文…...

Android 12 Activity启动流程
Android 12 Activity启动过程 参考文献: startActivity启动过程分析 Activity启动流程(Android 12) 概述 Activity启动发起后,是通过Binder最终交由system进程中的AMS来完成。 一、启动流程 frameworks/base/core/java/android/app/Activity.java f…...
)
Google Maps路线优化突遭瓶颈?Gemini大模型如何将平均行程时间压缩23.6%(2024Q2实测数据)
更多请点击: https://intelliparadigm.com 第一章:Google Maps路线优化突遭瓶颈?Gemini大模型如何将平均行程时间压缩23.6%(2024Q2实测数据) 当Google Maps在高并发城市网格中遭遇动态交通建模失准、实时事件响应延迟…...
)
从‘能用’到‘优雅’:Python函数设计的3个坏味道与5个重构技巧(附代码对比)
从‘能用’到‘优雅’:Python函数设计的3个坏味道与5个重构技巧(附代码对比) 在Python开发中,函数是最基本的代码组织单元。许多开发者能够快速实现功能,却往往忽视了函数设计的质量。本文将揭示三种典型的函数设计&qu…...

3步搭建你的英雄联盟智能助手:LeagueAkari完整操作指南
3步搭建你的英雄联盟智能助手:LeagueAkari完整操作指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 想象一下,当你正…...
)
从PCB走线到天线:手把手教你搞定Sx1262射频前端阻抗匹配(附常见错误排查)
从PCB走线到天线:手把手教你搞定Sx1262射频前端阻抗匹配(附常见错误排查) 在LoRa终端硬件开发中,射频前端的阻抗匹配往往是决定通信质量的关键因素。许多工程师在完成Sx1262芯片外围电路设计后,常会遇到通信距离不理想…...

重温DIRE:走向通用人工智能生成的图像检测
1.摘要生成模型的快速发展提高了图像质量,并使图像合成广泛可用,引起了对内容可信度的关注。为了解决这个问题,我们提出了一种称为通用重建残差分析(UR2EA)的方法来检测合成图像。我们的研究表明,当通过预训练的扩散模型重建GAN和…...

测水位·报雨情·预洪水:水文监测站
水文监测站采用先进平面阵列雷达微波探测技术,设备悬空架设、非接触式采集河道水体数据。通过高精度雷达天线持续发射微波信号,穿透空气介质触达水面后反射回波,系统精准测算信号传播时长与多普勒频移变化,结合设备自带角度校准功…...

从日偏食图像处理开始:手把手在VS2019里跑通你的第一个OpenCV 4.3程序
从日偏食图像处理开始:手把手在VS2019里跑通你的第一个OpenCV 4.3程序 当那张日偏食照片第一次在屏幕上成功显示时,仿佛打开了计算机视觉的大门。本文将带你从零开始,用VS2019和OpenCV 4.3实现这个充满仪式感的"Hello World"——不…...

Betaflight飞行控制固件:5分钟快速上手指南与完整配置教程
Betaflight飞行控制固件:5分钟快速上手指南与完整配置教程 【免费下载链接】betaflight Open Source Flight Controller Firmware 项目地址: https://gitcode.com/gh_mirrors/be/betaflight 还在为穿越机飞行不稳定而烦恼吗?🤔 想体验…...

如果你的消费观和价值观不一致,就会产生“花钱买后悔“的内耗:你的钱花对了吗?
消费观与价值观 目录 消费观与价值观 一、核心定义与层级关系 1. 价值观:人生的"底层操作系统" 2. 消费观:价值观在金钱领域的"应用程序" 二、底层原理逻辑:从进化到社会 1. 价值观的形成原理:三重塑造 2. 消费观的运行原理:价值兑换模型 3. 为什么会…...

008、RISC-V在TinyML中的崛起与优势
008、RISC-V在TinyML中的崛起与优势 从一块“变砖”的开发板说起 去年冬天,我在调试一个基于Cortex-M4的智能传感器节点。项目要求将唤醒词检测模型塞进32KB的SRAM里,功耗要控制在50μA以下。折腾了两周,模型量化、算子裁剪、甚至手写汇编优化了部分矩阵运算——终于跑通了…...