Prim算法与Dijstra算法
注:参考如下文章和视频
不能说毫不相干,简直是一模一样(Prim vs Dijkstra)
普里姆和迪杰斯特拉太像了,他们有什么区别?
Prim算法和Dijkstra算法区别
文章目录
- 总结
- 数组元素的更新
- 两种算法的完整代码
- 普里姆算法
- 算法步骤
- 算法描述
- 迪杰斯特拉算法
- 算法步骤
- 算法描述
- 补档
- Prim算法的C语言实现
- Dijkstra算法的C语言实现
总结
Prim算法解决连通无向有权图中最小生成树问题,而Dijkstra算法解决是源点到其余节点的最短路径问题。
两个算法在添加新结点时,都是选择“距离最短”的结点加入集合,但是Prim算法中,“距离最短”是指未访问的结点到已经访问的所有结点的一个集合的距离最小,将距离最小的结点加入到已访问的集合中;而在Dijkstra算法中,“距离最短”是指所有未访问结点到源点距离最小。
注:集合理解为将所有已访问的结点看成一个结点。
在Prim算法中,数组元素dist[i]表示未访问结点i到已访问结点集合的最短距离。而Dijkstra算法中,数组元素dist[i]表示未访问结点i到源点的最短距离。
数组元素的更新
//Prim算法
for(int i = 0; i < n; i++){ //G表示连通无向有权图,u表示新加入的结点。if(!vist[i] && G[u][i] < dist[i]){dist[i] = G[u][i];}
}//Dijkstra算法
for(int i = 0; i < n; i++){//注意两者在更新最短距离的区别,可以说这是两者唯一的区别if(!vist[i] && G[u][i] + dist[u] < dist[i]){dist[i] = G[u][i] + dist[u];}
}
两种算法的完整代码
void Prim(){fill(vis, 0, maxn);int len = 0;dist[0] = 0;for(int i = 1; i < n; i++){ //初始化数组dis[]dist[i] = G[0][i];}for(int i = 0; i < n; i++){int u = -1, min = INF;for(int j = 0; j < n; j++){if(!vist[j] && dist[j] < min){u = j;min = dist[j];}}if(u == -1) return ;len += min; vist[u] = 1;for(int v = 0; v < n; v++){if(!vist[v] && G[u][v] < dist[v])dist[v] = G[u][v];}}
}
void Dijkstra(){fill(vis, 0, maxn);fill(dis, dis + maxn, inf);dis[0] = 0; //将0设置为源点,同理可设置目标点,只需添加一个if判断即可for(int i = 0; i < n; i++){int u = -1, min = INF;for(int j = 0; j < n; j++){if(!vist[j] && dist[j] < min){u = j;min = dist[j];}}if(u == -1) return ;vis[u] = 1;for(int v = 0; v < n; v++){if(!vist[v] && G[u][v] + dist[u] < dist[v])dist[v] = G[u][v] + dist[u];}}
}
普里姆算法
算法步骤
1)首先将初始顶点u加入 U U U中,对其与的每一个顶点 v j v_j vj,将closedge[j]均初始化为到u的信息。
2)循环n-1次,做如下处理
- 从各组边
closedge中选出最小的边closedgeK[k],输出此边; - 将
k加入 U U U中; - 更新剩余的每组最小边信息
closedge[j],对于 V − U V-U V−U中的边,新增了加了一条从k到j的边,如果新边的权值比closedge[j].lowcost更新为新的边的权值。
算法描述
//辅助数组的定义,用来记录从顶顶点集U到V-U的权值最小的边
struct
{VerTexType adjvex;//最小边在U中的那个顶点ArcType lowcost;//最小边上的权值
}closedge[MVNum];void MiniSpanTree_Prim(AMGraph G,VerTexType U)
{//无向网G以邻接矩阵形式存储,从顶点u出发构造G的最小生成树T,输出T的各条边k=LocateVex(G,u);//k为顶点u的下标for(j=0;j<G.vexnum;++j)//对v-U的每一个顶点初始化closedge[j]if(j!=k) closedge[j]={u,G.arcs[k] [j])};//{adjvex,lowcost)closedge[k].lowcost=0;//初始,U={u}for(i=1;i<G.vexnum;++i){//选择其余n-1个顶点,生成n-1条边(n=G.vexnum)k=Min(closedge);//求出T的下一个节点:第k个顶点,closedge[k]中存有当前最小边u0=closedge[k].adjvex;//u0为最小边的一个顶点,u0∈Uv0=G.vexs[k];//v0为最小边的另一个顶点,v0∈V-Ucout<<u0<<v0;//输出当前的最小边(u0,v0)closedge[k].lowcost=0;//第k个顶点并人U集for(j=0;j<G.vexnum;++j)if(G.arcs[k][j]<closedge[j].lowcost)//新顶点并人U后重新选择最小边closedge[j]={G.vexs[k],G.arcs[k] [j]];//for}
}
迪杰斯特拉算法
算法步骤
算法描述
补档
Prim算法的C语言实现
#include <stdio.h>
#include <limits.h>#define MAX_V 100
#define INF INT_MAXint graph[MAX_V][MAX_V]; // 邻接矩阵
int key[MAX_V]; // 存储最小边权
int parent[MAX_V]; // 存储生成树中的边
int inMST[MAX_V]; // 标记顶点是否在最小生成树中void prim(int start, int n) {for (int i = 0; i < n; i++) {key[i] = INF; // 初始化为无穷大inMST[i] = 0; // 初始化为不在生成树中parent[i] = -1; // 初始化父节点}key[start] = 0; // 起始顶点的键值为0for (int count = 0; count < n - 1; count++) {// 查找键值最小的顶点int u = -1;for (int v = 0; v < n; v++) {if (!inMST[v] && (u == -1 || key[v] < key[u])) {u = v;}}inMST[u] = 1; // 将该顶点加入最小生成树// 更新邻居的键值for (int v = 0; v < n; v++) {if (graph[u][v] && !inMST[v] && graph[u][v] < key[v]) {//注意两者区别parent[v] = u;key[v] = graph[u][v];}}}// 打印最小生成树for (int i = 1; i < n; i++) {printf("Edge: %d - %d, Weight: %d\n", parent[i], i, graph[parent[i]][i]);}
}Dijkstra算法的C语言实现
#include <stdio.h>
#include <limits.h>#define MAX_V 100
#define INF INT_MAXint graph[MAX_V][MAX_V]; // 邻接矩阵
int key[MAX_V]; // 存储最短路径权重
int previous[MAX_V]; // 存储前驱节点
int inSPT[MAX_V]; // 标记顶点是否在最短路径树中void dijkstra(int start, int n) {for (int i = 0; i < n; i++) {key[i] = INF; // 初始化为无穷大inSPT[i] = 0; // 初始化为不在最短路径树中previous[i] = -1; // 初始化前驱节点}key[start] = 0; // 起始顶点的键值为0for (int count = 0; count < n - 1; count++) {// 查找键值最小的顶点int u = -1;for (int v = 0; v < n; v++) {if (!inSPT[v] && (u == -1 || key[v] < key[u])) {u = v;}}inSPT[u] = 1; // 将该顶点加入最短路径树// 更新邻居的键值for (int v = 0; v < n; v++) {if (graph[u][v] && !inSPT[v] && key[u] + graph[u][v] < key[v]) {//注意两者区别key[v] = key[u] + graph[u][v];previous[v] = u;}}}// 打印最短路径for (int i = 0; i < n; i++) {printf("Distance from %d to %d is %d\n", start, i, key[i]);}
}相关文章:

Prim算法与Dijstra算法
注:参考如下文章和视频 不能说毫不相干,简直是一模一样(Prim vs Dijkstra) 普里姆和迪杰斯特拉太像了,他们有什么区别? Prim算法和Dijkstra算法区别 文章目录 总结数组元素的更新两种算法的完整代码 普里姆算法算法步骤算法描…...

水经微图IOS版5.6.1发布,新增图源二维码分享并修订徒步模式功能
随时随地,微图一下! 水经微图(以下称“微图”)IOS版5.6.1发布,本次升级主要新增了图源二维码分享功能,以及修订过往足迹的徒步模式功能。 当前版本 当前版本号为:5.6.1 如果你发现该版本中存…...
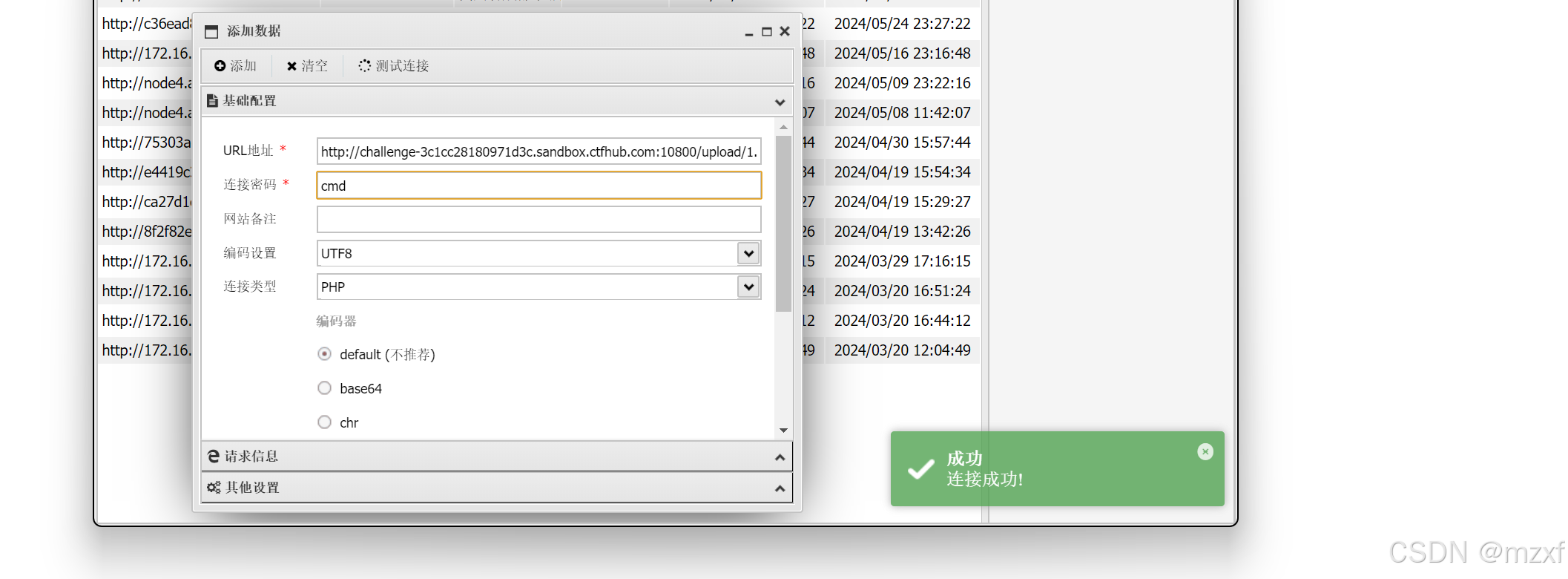
复现第三周
1.eval执行 1)打开题目 简单进行代码审计,而题目又为eval函数说明这里eval() 会执行传入的任意代码,可以通过 cmd 作为参数执行任意 PHP 代码,这里相当于用cmd作为参数来执行url头命令 2)在url头输入命令cmdsystem("ls&quo…...
)
Django---数据库(多表关联)
在Django中操作数据库并实现多表关联,主要是通过定义模型(Models)及其关系,然后利用Django ORM(Object-Relational Mapping)执行数据库操作。 定义模型及其关系 首先,需要在models.py文件中定…...

2024系统架构师---论软件可靠性设计及其应用论文
可靠性 软件可靠性是指软件系统在一定的时间内持续无故障运行的能力。 可靠性通常用平均失效等待时间(MTTF)和平均失效间隔时间(MTBF)来衡量。 影响可靠性的因素 从技术的角度来看,影响软件可靠性的主要因素如下。…...

SpringBoot在线教育系统:云部署策略
6系统测试 6.1概念和意义 测试的定义:程序测试是为了发现错误而执行程序的过程。测试(Testing)的任务与目的可以描述为: 目的:发现程序的错误; 任务:通过在计算机上执行程序,暴露程序中潜在的错误。 另一个…...

Zabbix 6.0 部署
目录 一、序章 二、zabbix概念 2.1 zabbix 是什么? 2.2 zabbix 监控原理: 2.3 Zabbix 6.0 新特性: 2.3.1 Zabbix server高可用防止硬件故障或计划维护期的停机 2.3.2 Zabbix 6.0 LTS新增Kubernetes监控功能,可以在Kubernet…...

用Python遍历输出烟感名称和状态
为了使用Python遍历输出烟感名称和状态,您需要首先从SNMP代理(如网络设备或硬件设备)获取这些值。为此,您可以使用第三方库如pysnmp,它允许您轻松地与SNMP代理通信。 首先,您需要安装pysnmp库,…...

Redis的持久化以及性能管理
目录 一、Redis持久化概述 1.什么是Redis持久化 2.持久化方式 3.RDB持久化 3.1概念 3.2触发条件 3.3执行流程 3.4启动时加载 4. AOF持久化 4.1概念 4.2启动AOF 4.3执行流程 4.4启动时加载 5.RDB和AOF的优缺点 二、Redis性能管理 1.查看Redis内存使用 2…...

Docker部署Meta-Llama-3.1-70B-Instruct API openai格式,vLLM速度对比
下载模型 modelscope环境,国内下载更快: conda create -n modelscope python=3.10 conda activate modelscopepip install modelscope命令行下载: https://modelscope.cn/models/LLM-Research/Meta-Llama-3.1-70B-Instruct modelscope download --model LLM-Research/Met…...

USB协议学习
文章目录 USB发展背景发展变化速度等级通讯接口 四种传输主设备 & 从设备主设备从设备 连接与检测高速设备与主机连接USB总线常见的几种状态 枚举过程特点 控制传输学习资料 USB发展背景 发展变化 USB1.1:规范了USB低全速传输; USB2.0:…...

TDengine 数据订阅 vs. InfluxDB 数据订阅:谁更胜一筹?
在时序数据的应用场景中,数据的实时消费和处理能力成为衡量数据库性能和可用性的重要指标。TDengine 和 InfluxDB 作为时序数据库(Time Series Database)中的佼佼者,在数据订阅方面各有特点。但从架构设计、灵活性和系统负载上看&…...

用户批评 SAP 的人工智能战略
在2024年德语SAP用户组织(DSAG)年会上,SAP用户对公司云优先的AI创新策略表示不满。SAP决定将AI功能仅限于云客户,使使用本地部署(on-premises)系统的用户感到被忽视。这种“云优先”策略引发了SAP用户间的广…...

Jest进阶知识:React组件的单元测试
在现代前端开发中,组件是构建应用程序的基本单元。一个组件不仅拥有完整的功能,还能极大地提高代码的复用性。因此,在进行单元测试时,对重要组件进行测试是必不可少的。 Testing Library Testing Library 是一个专门用于测试 We…...

MATLAB——矩阵操作
内容源于b站清风数学建模 数学建模清风老师《MATLAB教程新手入门篇》https://www.bilibili.com/video/BV1dN4y1Q7Kt/ 目录 1.MATLAB中的向量 1.1向量创建方法 1.2向量元素的引用 1.3向量元素修改和删除 2.MATLAB矩阵操作 2.1矩阵创建方法 2.2矩阵元素的引用 2.3矩阵…...

智能数据驱动的风险管理:正大金融科技的创新实践
在不断变化的金融环境中,风险管理成为投资成功的关键因素。正大公司以数据驱动的智能风控体系为核心,通过深度学习、数据分析等技术创新,帮助投资者在复杂的市场条件下实现稳健操作和风险控制。本文将探讨正大如何利用科技手段提升风险管理效…...

贝尔不等式的验证
在量子计算机上运行一个实验,以演示使用Estimator原型违反CHSH不等式。 import numpy as npfrom qiskit import QuantumCircuit from qiskit.circuit import Parameter from qiskit.quantum_info import SparsePauliOpfrom qiskit_ibm_runtime import QiskitRuntim…...

GR2——在大规模视频数据集上预训练且机器人数据上微调,随后预测动作轨迹和视频(含GR1详解)
前言 上个月的24年10.9日,我在朋友圈看到字节发了个机器人大模型GR2,立马去看了下其论文(当然了,本质是个技术报告) 那天之后,我就一直想解读这个GR2来着 然,意外来了,如此文《OmniH2O——通用灵巧且可全…...

伦敦金价格是交易所公布的吗?
今年以来,伦敦金价格波动可谓是波澜壮阔,盘中屡次刷新历史新高,目前已经冲上了2700的历史大关。面对高歌猛进的伦敦金价格,投资者除了进行交易之外,还有一点相关方面的知识是想了解的。例如,伦敦金价格是交…...

Oracle SQL Loader概念及用法
Oracle SQLLoader是Oracle数据库提供的一个高效的数据加载工具,它能够将外部数据(如CSV、DAT、Text等文件格式)快速加载到Oracle数据库中。以下是对Oracle SQLLoader的详细介绍: 一、主要功能 数据迁移:SQL*Loader常…...

Unity热更新实战:YooAsset与HybridCLR协同落地指南
1. 这不是“加个插件就能热更”的童话,而是Unity项目里最真实的代码热更新落地现场在Unity游戏开发中,“热更新”三个字背后藏着太多被轻描淡写的代价:策划说“今天上线新活动,明天要热更”,程序却在凌晨三点对着Asset…...

初识递归算法
目录介绍例PythonC原理优缺点分析题目结尾本文由Jzwalliser原创,发布在CSDN平台上,遵循CC 4.0 BY-SA协议。 因此,若需转载/引用本文,请注明作者并附原文链接,且禁止删除/修改本段文字。 违者必究,谢谢配合。…...
)
Win10桌面右键新建菜单丢了记事本?别慌,手把手教你用注册表找回来(附权限设置详解)
Win10右键新建菜单丢失记事本?三步精准修复与权限管理指南刚泡好的咖啡还在冒热气,你像往常一样在桌面右键点击"新建",却发现那个最常用的"文本文档"选项凭空消失了。这不是个例——微软官方社区数据显示,每月…...

告别打包焦虑:UE5 Windows与安卓打包速度优化与稳定性提升全攻略
告别打包焦虑:UE5 Windows与安卓打包速度优化与稳定性提升全攻略在虚幻引擎5(UE5)开发流程中,打包环节往往是开发者体验的分水岭——顺畅的打包过程能保持创作心流,而频繁的报错和漫长等待则会严重消耗开发热情。本文将…...
)
Unity 2020.3.3f1c1 + MySQL:手把手教你搞定餐厅经营游戏的登录注册与房间联机(附完整源码)
Unity餐厅经营游戏开发实战:从登录注册到联机房间的完整架构解析在独立游戏开发领域,餐厅经营类游戏因其轻松愉快的玩法和社交属性,始终保持着稳定的市场需求。本文将深入探讨如何基于Unity 2020.3.3f1c1构建一个完整的餐厅经营游戏框架&…...

ros2_control 代码架构分析
ros2_control 代码架构分析 一、整体框架 1.1 代码框架 ├── ros2_control/ # ★ 框架本体(vendored,jazzy 分支) │ ├── controller_manager/ # 核心运行时:ros2_control_node │ ├── hardware_interface/ # 硬件抽象 +…...

2026最新免费图片去水印保姆级教程!这5种方法一次学会,第三种零门槛秒出图
你是不是也遇到过这种情况?好不容易在小红书、抖音上刷到一张绝美壁纸,保存下来却被水印破坏了整体美感;想把博主分享的干货截图保存,结果那个半透明的Logo刚好挡在关键数据上。别急,今天这篇教程就是为你准备的。 202…...

小学期week2记录
本周完成了发射端电路的pcb原理图绘制,还有很多不足,下周将完善pcb的布线并完成接收端电路的设计...

各个AI公司都在玩的Harness 架构:Harness架构深度解析
Harness 架构深度解析为什么 AI 智能体的未来不是框架,而是「运行壳」TL;DR 三分钟看懂这篇文章•当 Claude Code、Cursor、Codex、Windsurf 四款产品独立演化出几乎相同的内部架构时,一种叫做 Harness(运行壳)的新形态浮出水面。…...
)
股市学习心得-技术指标学习(布林线+MACD)
技术指标学习(布林线MACD)(所提供内容仅用于学习交流,不作为股市交易依据)首先,技术指标除了量比和换手率,都有滞后和造假的可能,因此不能用单一指标判断,也需要通过多个指标辅助决策。布林线MA…...