开源自托管数据管理工具全面指南
在大数据时代,企业和组织面临着海量的数据挑战。随着应用程序复杂性的提高以及用户需求不断演变,开发团队需要高效地处理大量数据,以便快速做出决策。然而,在众多信息中,如何识别并有效利用那些对决策至关重要的数据呢?
数据管理工具提供了解决方案,帮助开发团队从繁杂的信息中提取价值,优化数据结构,使有效数据得到更好的应用。
在这篇全面指南中,我们将探讨数据管理工具的基本概念、关键步骤、重要性,以及如何选择适合自身需求的数据管理工具。希望能够帮助你的团队高效利用数据管理工具,充分挖掘数据价值,实现数据驱动的成功转型!
什么是数据管理?
数据管理是指对数据进行有效组织和维护的过程,涵盖了数据的提取、清洗、整合和加载(ETL)。这一过程通常发生在数据存储、数据分析和数据可视化的各个环节。数据管理的目的是提升数据的质量和可用性,使其适合于不同的分析需求和应用场景。
数据管理的关键步骤
- 数据提取:从不同的数据源(如数据库、API、文件系统等)提取数据。
- 数据清洗:去除重复数据、填补缺失值、纠正数据格式和处理异常值。
- 数据整合:将来自不同来源的数据合并,以便统一分析。
- 数据转换:将数据格式转换为所需的形式,例如将 CSV 转为 JSON,或将关系型数据转为 NoSQL 格式。
- 数据加载:将转换后的数据加载到目标系统或数据仓库中,以供后续使用。
数据管理的重要性
数据管理对于企业的重要性体现在多个方面:
- 提高数据质量:清洗和整合数据可以提升数据的准确性和一致性。
- 增强数据可访问性:将数据格式化为适合分析的形式,使数据更易于访问和使用。
- 支持业务决策:高质量的数据能够支持更深入的分析,从而为决策提供有力依据。
- 满足合规要求:通过数据转换,企业能够确保数据符合行业法规和标准。
数据管理工具的选择标准
在选择合适的数据管理工具时,开发者和团队需考虑多个关键因素,其中开源和自托管的特性尤为重要:
- 开源:开源工具可根据特定需求进行修改和优化,适应独特的业务流程,同时,活跃的开源社区为工具的持续改进和问题解决提供支持。
- 自托管:自托管能力使用户能在自己的服务器上运行工具,增强数据安全性和隐私保护,同时提高控制和灵活性,以符合 IT 基础设施和安全政策。
- 功能:工具是否支持多种数据源和格式,以满足具体的数据转换需求。
- 性能:在处理大规模数据时的效率和稳定性。
- 易用性:用户界面是否友好,学习曲线是否适合团队成员的技术背景。
- 社区和支持:是否拥有活跃的社区和良好的技术支持,方便获取帮助和资源。
- 价格:工具的成本是否符合预算,包括潜在的维护和扩展费用。
推荐的开源自托管数据管理工具
NocoBase
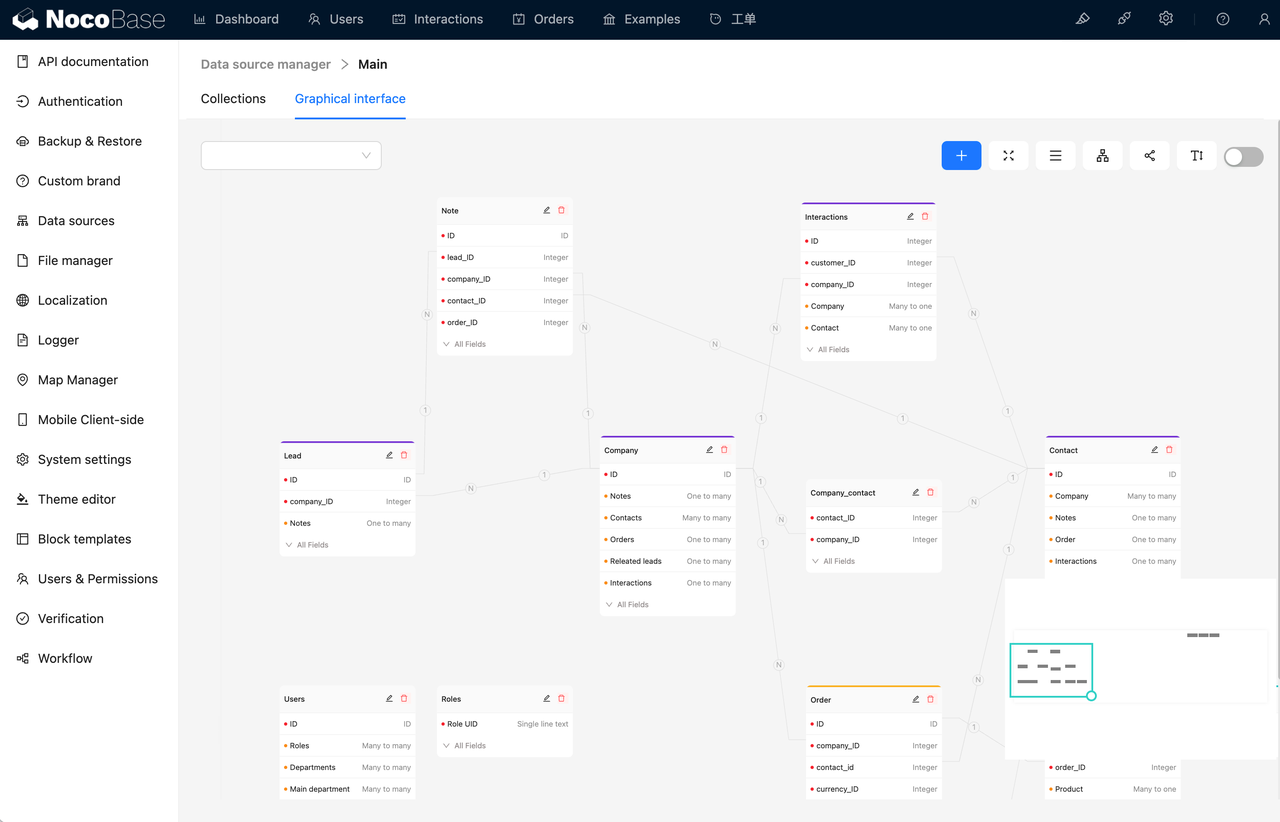
概述
GitHub:https://github.com/nocobase/nocobase
NocoBase 是一个开源无代码/低代码开发平台,通过高效的数据集成能力,能够将分散在不同来源的数据统一整合,同时其自动化数据清洗能力,能够显著降低数据治理成本,帮助用户快速构建定制化解决方案,提升工作效率。
💡 推荐阅读:美航通过 NocoBase 节省了 70% 的物流系统升级成本
特点
- 所见即所得界面:通过可视化界面和简单的逻辑,用户可以轻松创建数据转换流程。
- 插件化架构:支持用户根据需求定制和扩展功能,可以通过插件实现个性化数据处理。
- 支持多种数据源:兼容多种数据源,支持数据库、API 等不同格式的数据,满足各种应用场景的需求。
优缺点
- 优点:易于使用,适合不具备深厚技术背景的用户。
- 缺点:功能可能不如一些更复杂的工具丰富。
价格:提供免费的社区版本和更专业的商业版本。
Nifi
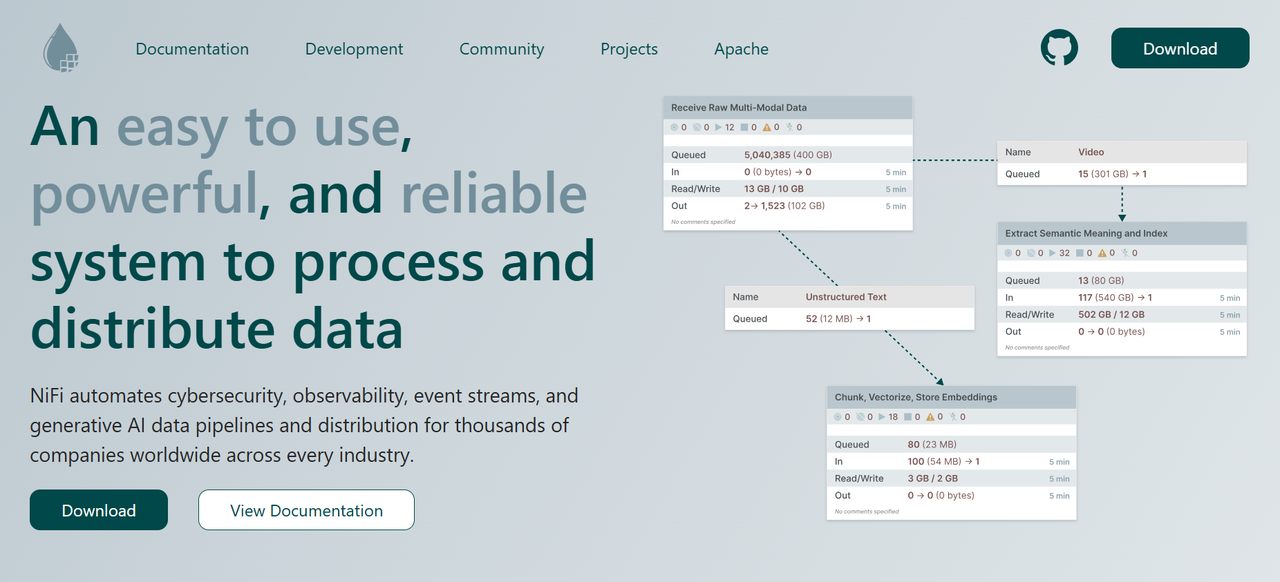
概述
GitHub:https://github.com/apache/nifi
Nifi 是一个强大的数据流管理工具,支持数据的自动化流动和转换。它以可视化界面著称,使用户能够轻松设计数据流。
特点
- 图形化用户界面:通过拖放、连接不同的处理器来构建数据处理流程,无需编写复杂的代码。
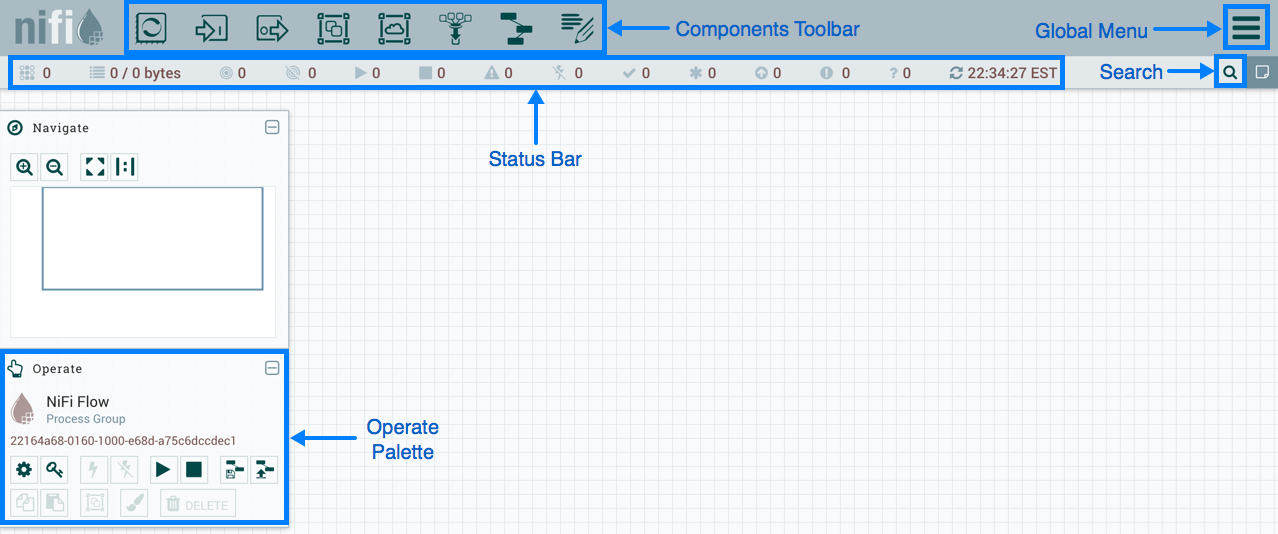
- 安全的数据处理:NiFi 提供了多种安全机制,包括用户认证、授权和数据加密等,以确保数据的安全性和隐私性。
- 丰富的连接器:支持多种数据源和目标,包括数据库、文件和 API。
优缺点
- 优点:灵活性高,适合各种数据处理需求。
- 缺点:对于复杂场景,可能需要较高的学习曲线。
价格:开源,免费使用。
Airflow

概述
GitHub:https://github.com/apache/airflow
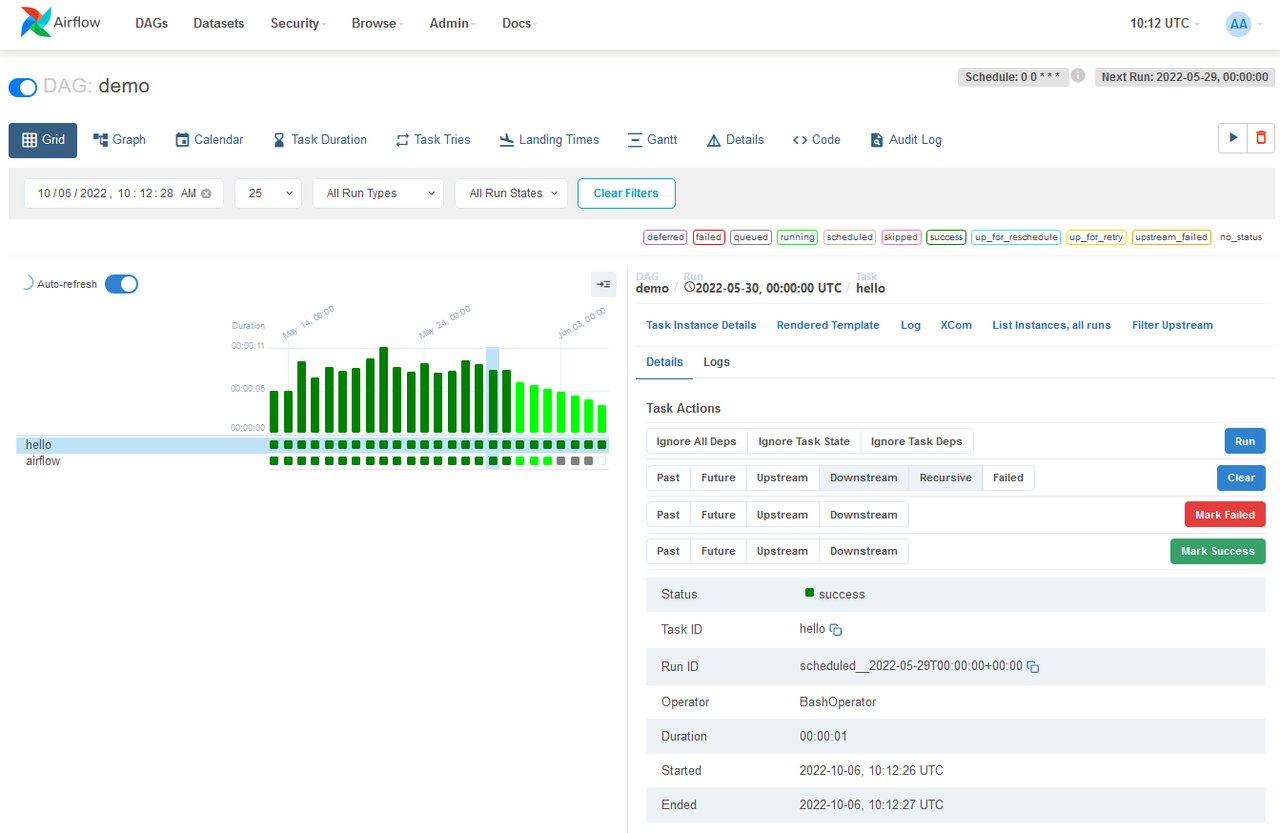
Airflow 是一个开源工作流管理平台,主要用于编排复杂的数据处理和转换任务。
特点
- 灵活的调度:工作流参数化是利用 Jinja 模板引擎构建,能够适应各种复杂的调度需求。
- 可扩展性:可以轻松定义运算符,所有组件都可扩展,能够轻松集成到不同的系统中。
- Python脚本:使用标准 Python 功能创建工作流,包括用于计划的日期时间格式和用于动态生成任务的循环。
优缺点
- 优点:强大的调度和监控功能。
- 缺点:需要一定的开发经验来配置和使用。
价格:开源,免费使用。
Pentaho
概述
GitHub:https://github.com/pentaho/pentaho-kettle
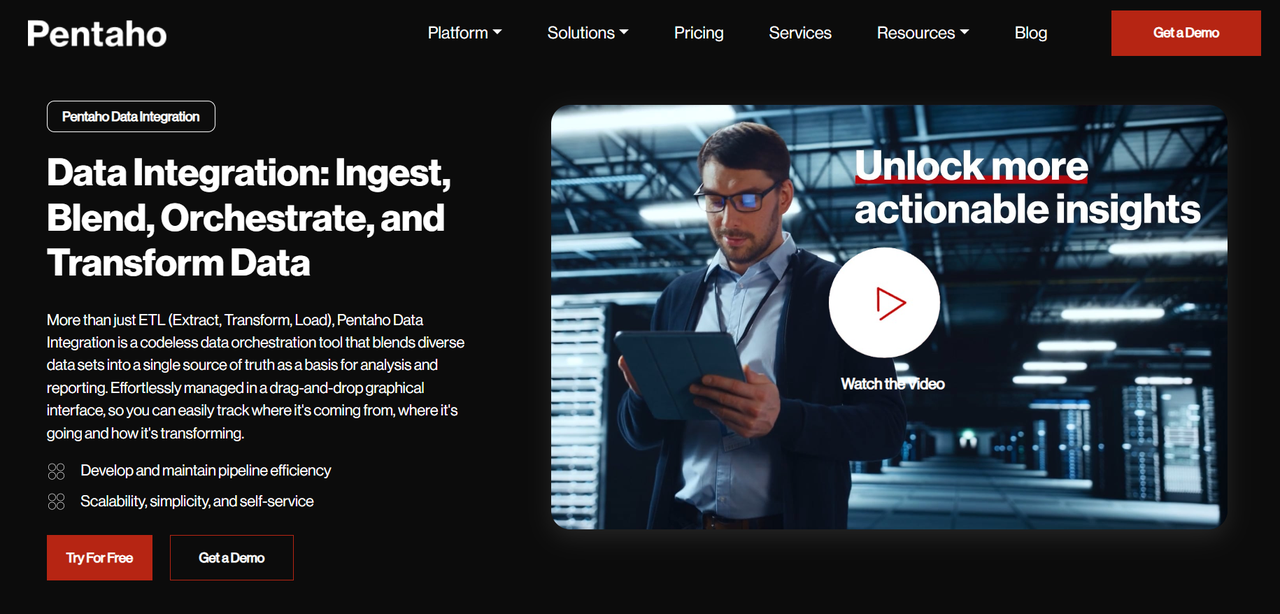
Pentaho 是一款开源的ETL工具,广泛用于数据转换、清洗和加载。
特点
- 拖放式界面:用户可以通过可视化方式设计数据流程,降低了数据集成的难度。
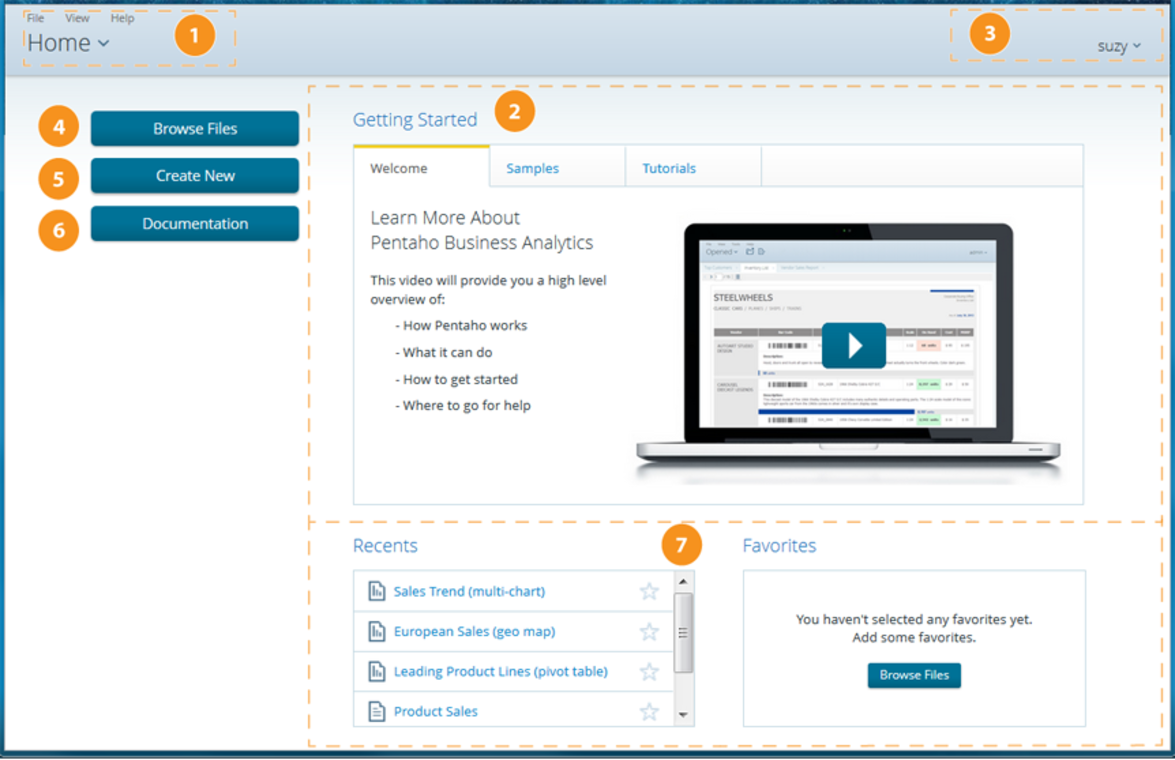
- 支持多种数据源:与关系型数据库、NoSQL 和文件系统兼容。
- 丰富的插件支持:支持插件扩展,用户可以根据自己的需求开发新的插件。
优缺点
- 优点:易于使用且功能全面。
- 缺点:某些高级功能需要额外配置和开发。
价格:提供免费版和付费的商业版。
Singer

概述
GitHub:https://github.com/singer-io
Singer 是一个开源的标准化数据提取和加载工具,适用于创建可重用的 ETL 管道。
特点
- 模块化设计:使用 “tap” 和 “target” 来定义数据流,便于扩展。

- 灵活性高:支持多种数据源和目标,适合构建定制化的解决方案。
- 基于 JSON:Singer 应用程序与 JSON 相连,易于使用且可以用任何编程语言实现。
优缺点
- 优点:灵活性强,适合构建个性化的数据管道。
- 缺点:需要一定的技术背景来配置和使用。
价格:开源,免费使用。
Spark

概述
GitHub:https://github.com/apache/spark
Spark 是一个统一的分析引擎,适用于大规模数据处理和转换,支持批处理和流处理。
特点
- 批处理/流式处理数据:使用用户的首选语言(Python、SQL、Scala、Java 或 R)以批处理和实时流式处理的方式统一数据处理。
- SQL 分析:执行快速、分布式的 ANSI SQL 查询,用于仪表板和临时报告。
- 丰富的生态系统:与大数据、机器学习等工具兼容。

优缺点
- 优点:强大的性能和灵活性,适合各种数据处理场景。
- 缺点:对新手来说,学习曲线较陡。
价格:开源,免费使用。
总结
- NocoBase:所见即所得的界面和灵活的插件架构简化了数据集成的复杂性。
- Nifi:图形化界面和安全机制确保高效安全的数据流动。
- Airflow:灵活调度和可扩展性提升了复杂任务的编排效率。
- Pentaho:拖放式设计和丰富插件支持降低了学习门槛。
- Singer:模块化设计与灵活性便于构建可重用的 ETL 管道。
- Spark:统一的批处理与流处理能力,满足大规模数据处理需求。
😊 希望这篇指南能帮助你选择合适的数据管理工具,提高数据处理效率,实现数据驱动的业务增长。
相关阅读:
- 如何创建良好的数据模型?
- 如何构建高效的 CRUD 应用程序?
- 构建工作流自动化的 5 个最佳工具
- 6 个最佳核心应用仪表盘构建工具
- BPM(业务流程管理)的最佳开源工具
- 5 个最佳开源无代码项目管理工具
相关文章:
开源自托管数据管理工具全面指南
在大数据时代,企业和组织面临着海量的数据挑战。随着应用程序复杂性的提高以及用户需求不断演变,开发团队需要高效地处理大量数据,以便快速做出决策。然而,在众多信息中,如何识别并有效利用那些对决策至关重要的数据呢…...

护工系统|护工陪护软件|护工系统设计
在现代社会,护工系统的开发成为提升医疗服务质量和效率的重要手段。页面设计作为系统开发的关键环节,必须充分考虑到实用性与用户体验。以下是对护工系统开发页面设计功能的详细阐述: 一、用户登录与权限管理 页面设计首先应设置用户登录模块…...

电商领域软件系统实战:基于TiDB的分布式数据库应用
在电商领域,数据的快速增长和复杂性对数据库系统提出了更高要求。TiDB作为一款开源的分布式数据库,以其兼容MySQL协议、水平扩展能力强、高可用性等特性,在电商系统中得到了广泛应用。本文将围绕TiDB在电商领域的应用,详细介绍其搭…...

鸢尾博客项目开源
1.博客介绍 鸢尾博客是一个基于Spring BootVue3 TypeScript ViteJavaFx的客户端和服务器端的博客系统。项目采用前端与后端分离,支持移动端自适应,配有完备的前台和后台管理功能。后端使用Sa-Token进行权限管理,支持动态菜单权限,服务健康…...

Google封号潮来袭!跨境卖家如何解封?
近期,不少小伙伴在苦苦哀嚎:Google账号又又又又被封啦!对于跨境业务在线的小伙伴来说来说,是一个比较严重的问题。但不必过于担心,以下是一些可能的原因和相应的解决方法,耐心看完,也许对你的账号解封有帮助…...

路径规划 | ROS中多个路径规划算法可视化与性能对比分析
目录 0 专栏介绍1 引言2 禁用局部规划器3 路径规划定性对比实验3.1 加载路径规划器和可视化插件3.2 设置起点和终点3.3 选择规划器规划3.4 不同规划器对比3.5 路径保存和加载 4 路径规划定量对比实验4.1 计算规划耗时4.2 计算规划长度4.3 计算拓展节点数4.4 计算路径曲率4.5 计…...

使用 PyCharm 构建 FastAPI 项目:零基础入门 Web API 开发
使用 PyCharm 构建 FastAPI 项目:零基础入门 Web API 开发 本文提供了一份完整的 FastAPI 入门指南,涵盖从环境搭建、依赖安装到创建并运行一个简单的 FastAPI 应用的各个步骤。通过 FastAPI 和 Uvicorn,开发者可以快速构建现代化的 Web API…...

Prim算法与Dijstra算法
注:参考如下文章和视频 不能说毫不相干,简直是一模一样(Prim vs Dijkstra) 普里姆和迪杰斯特拉太像了,他们有什么区别? Prim算法和Dijkstra算法区别 文章目录 总结数组元素的更新两种算法的完整代码 普里姆算法算法步骤算法描…...

水经微图IOS版5.6.1发布,新增图源二维码分享并修订徒步模式功能
随时随地,微图一下! 水经微图(以下称“微图”)IOS版5.6.1发布,本次升级主要新增了图源二维码分享功能,以及修订过往足迹的徒步模式功能。 当前版本 当前版本号为:5.6.1 如果你发现该版本中存…...
复现第三周
1.eval执行 1)打开题目 简单进行代码审计,而题目又为eval函数说明这里eval() 会执行传入的任意代码,可以通过 cmd 作为参数执行任意 PHP 代码,这里相当于用cmd作为参数来执行url头命令 2)在url头输入命令cmdsystem("ls&quo…...
)
Django---数据库(多表关联)
在Django中操作数据库并实现多表关联,主要是通过定义模型(Models)及其关系,然后利用Django ORM(Object-Relational Mapping)执行数据库操作。 定义模型及其关系 首先,需要在models.py文件中定…...

2024系统架构师---论软件可靠性设计及其应用论文
可靠性 软件可靠性是指软件系统在一定的时间内持续无故障运行的能力。 可靠性通常用平均失效等待时间(MTTF)和平均失效间隔时间(MTBF)来衡量。 影响可靠性的因素 从技术的角度来看,影响软件可靠性的主要因素如下。…...

SpringBoot在线教育系统:云部署策略
6系统测试 6.1概念和意义 测试的定义:程序测试是为了发现错误而执行程序的过程。测试(Testing)的任务与目的可以描述为: 目的:发现程序的错误; 任务:通过在计算机上执行程序,暴露程序中潜在的错误。 另一个…...

Zabbix 6.0 部署
目录 一、序章 二、zabbix概念 2.1 zabbix 是什么? 2.2 zabbix 监控原理: 2.3 Zabbix 6.0 新特性: 2.3.1 Zabbix server高可用防止硬件故障或计划维护期的停机 2.3.2 Zabbix 6.0 LTS新增Kubernetes监控功能,可以在Kubernet…...

用Python遍历输出烟感名称和状态
为了使用Python遍历输出烟感名称和状态,您需要首先从SNMP代理(如网络设备或硬件设备)获取这些值。为此,您可以使用第三方库如pysnmp,它允许您轻松地与SNMP代理通信。 首先,您需要安装pysnmp库,…...

Redis的持久化以及性能管理
目录 一、Redis持久化概述 1.什么是Redis持久化 2.持久化方式 3.RDB持久化 3.1概念 3.2触发条件 3.3执行流程 3.4启动时加载 4. AOF持久化 4.1概念 4.2启动AOF 4.3执行流程 4.4启动时加载 5.RDB和AOF的优缺点 二、Redis性能管理 1.查看Redis内存使用 2…...

Docker部署Meta-Llama-3.1-70B-Instruct API openai格式,vLLM速度对比
下载模型 modelscope环境,国内下载更快: conda create -n modelscope python=3.10 conda activate modelscopepip install modelscope命令行下载: https://modelscope.cn/models/LLM-Research/Meta-Llama-3.1-70B-Instruct modelscope download --model LLM-Research/Met…...

USB协议学习
文章目录 USB发展背景发展变化速度等级通讯接口 四种传输主设备 & 从设备主设备从设备 连接与检测高速设备与主机连接USB总线常见的几种状态 枚举过程特点 控制传输学习资料 USB发展背景 发展变化 USB1.1:规范了USB低全速传输; USB2.0:…...

TDengine 数据订阅 vs. InfluxDB 数据订阅:谁更胜一筹?
在时序数据的应用场景中,数据的实时消费和处理能力成为衡量数据库性能和可用性的重要指标。TDengine 和 InfluxDB 作为时序数据库(Time Series Database)中的佼佼者,在数据订阅方面各有特点。但从架构设计、灵活性和系统负载上看&…...

用户批评 SAP 的人工智能战略
在2024年德语SAP用户组织(DSAG)年会上,SAP用户对公司云优先的AI创新策略表示不满。SAP决定将AI功能仅限于云客户,使使用本地部署(on-premises)系统的用户感到被忽视。这种“云优先”策略引发了SAP用户间的广…...

解决Keil MDK中RL-ARM许可证错误L9937E的方法
1. 问题现象与背景解析最近在维护一个基于Keil MDK的嵌入式老项目时,遇到了一个棘手的许可证错误。项目需要使用RL-ARM实时库(Real-Time Library),但编译时出现了以下错误提示:Error: L9937E: RL-ARM is not allowed w…...

Landsat8数据EVI计算踩坑实录:从辐射定标到大气校正,你的公式真的写对了吗?
Landsat8数据EVI计算全流程避坑指南:从数据预处理到公式验证第一次用Landsat8数据计算EVI指数时,我盯着屏幕上那些超出[-1,1]范围的数值发愣——这显然不对劲。作为遥感领域最常用的植被指数之一,EVI的正常值范围应该是-1到1之间。经过整整两…...
)
别再乱装驱动了!Win10/Win11频繁蓝屏DPC_WATCHDOG_VIOLATION,用WinDBG揪出真凶(保姆级排查流程)
彻底解决Win10/Win11蓝屏噩梦:DPC_WATCHDOG_VIOLATION实战排查指南每次看到那个蓝色屏幕突然出现,心跳都会漏掉一拍——特别是当重要文件还没来得及保存的时候。DPC_WATCHDOG_VIOLATION(错误代码133)堪称Windows系统最令人头疼的蓝…...
)
esp开发与应用(1602液晶显示屏)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】模块当中,有的是比较简单的,比如说蜂鸣器,尤其是有源蜂鸣器。大家可以把它想象成是一个gpio输出的喇叭ÿ…...
)
Win10升级21H2后远程桌面黑屏?一个组策略设置帮你搞定(附gpedit.msc详细路径)
Windows 10 21H2远程桌面黑屏故障深度解析与精准修复方案当你从Windows 10 1909版本升级到21H2后,是否遇到过这样的场景:远程桌面连接看似成功,却在15秒后突然黑屏断开,只留下"您的远程桌面会话已结束"的模糊提示&#…...
爆火背后的技术解析)
Hermes Agent(爱马仕agent )爆火背后的技术解析
基于对现有技术资料的分析,Hermes Agent 的火爆及其与 OpenClaw 的对比,可以从以下几个核心维度进行解构与推演。 一、 Hermes Agent 项目详细分析与火爆原因 Hermes Agent 是一个由 Nous Research 开发的 AI Agent 框架,其设计哲学偏向于构…...

技术人的职业规划:打造成功的职业生涯
技术人的职业规划:打造成功的职业生涯 引言 作为一名技术人,职业规划是实现职业目标的关键。在快速变化的技术领域,一个清晰的职业规划可以帮助我们明确方向,抓住机会,实现个人价值。 回顾我的职业历程,从一…...

2026必备!AI论文工具测评:最新好用推荐与对比分析
2026年真正好用的AI论文工具,核心看生成的论文质量、低AI味、格式正确、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。一、综…...

Solr CVE-2019-0193漏洞深度解析:DataImportHandler远程代码执行原理与实战修复
1. 这个漏洞不是“能远程执行代码”那么简单,而是Solr管理员自己亲手打开的后门 Apache Solr 是企业级搜索领域绕不开的基础设施,我经手过的金融、电商、政务类项目里,有七成以上都用它做全文检索底座。但2019年爆出的 CVE-2019-0193…...

市场有效的透明化矿场安全防护系统
在矿场作业中,安全问题一直是重中之重。近年来,矿场事故时有发生,给生命和财产带来了巨大损失。据统计,过去十年间,全球矿场事故造成的直接经济损失高达数千亿美元,伤亡人数更是数以万计。因此,…...