DCRNN解读(论文+代码)
一、引言
作者首先提出:空间结构是非欧几里得且有方向性的,未来的交通速度受下游交通影响大于上游交通。虽然卷积神经网络(CNN)在部分研究中用于建模空间相关性,但其主要适用于欧几里得空间(例如二维图像),而非更为复杂的非欧几里得图结构。此外,现有的图卷积研究大多局限于无向图。
在此背景下,作者将交通传感器之间的空间相关性表示为有向图上的扩散过程,通过扩散卷积操作捕捉空间依赖性,提出了扩散卷积递归神经网络(DCRNN)。
二、方法
1. 空间依赖建模
首先,在空间依赖建模上,使用了扩散模型(Diffusion Mode)。这个模型首先定义了一个马尔卡夫链。这是一个随机过程,用于模拟图上信息从一个节点传播到其他节点的方式,通过随机游走来捕捉节点间的空间依赖性。当马尔科夫过程经过多次迭代或多个时间步(步数达到一定程度)后,它会逐渐达到一个稳态分布。在这个稳态分布下,每个节点与其他节点的连接强度(或称扩散影响力)将变得稳定,不再随时间变化。
关于扩散卷模型的更多知识,CSDN 这位博主讲的非常好:扩散模型 (Diffusion Model) 之最全详解图解-CSDN博客
说回论文。在空间依赖建模上想要用到扩散模型(扩散卷积),其核心思想如下:
- 对于每个节点 i,我们考虑它在不同步数 k 下从其他节点接收到的影响。
- 对每一个步数 k,我们使用正向转移矩阵的 k 次幂和反向转移矩阵的 k 次幂来表示扩散的传播过程。
- 在步数 k 时,通过 θ(k,1) 和 θ(k,2) 来控制正向和反向扩散的权重。
- 最后,将每一步的结果加和,以捕捉多步扩散过程中的节点间依赖关系。
有了这个思想,就不难理解论文中图信号 X 与滤波器 fθ 的扩散卷积操作定义:

式中,X 是一个 N×P 的矩阵,X:,p 就表示第 p 个节点的所有特征值(如速度)。fθ 是扩散卷积的滤波器,其作用是控制和调整扩散卷积的影响范围和特性(类似于图卷积中的卷积核)。W 是图的加权邻接矩阵。Do 是 W 的出度对角矩阵,表示每个节点的出度。那么这两项相乘后的矩阵表示一个随机游走过程,也就是说,矩阵的每个元素表示从节点 i 到节点 j 的条件概率,即在随机游走中,从 i 到达 j 的概率。
那么结合这个公式,作者的扩散卷积代码就很容易理解:
with tf.variable_scope(scope):if self._max_diffusion_step == 0: # 根据 _max_diffusion_step 控制扩散层数,0 表示无扩散passelse:for support in self._supports:# 将 support(稀疏邻接矩阵)与 x0(或更新的 x1)相乘,模拟信息在图上扩散。x1 = tf.sparse_tensor_dense_matmul(support, x0)x = self._concat(x, x1)# 将扩散结果 x1、x2 依次拼接到 x 上for k in range(2, self._max_diffusion_step + 1):x2 = 2 * tf.sparse_tensor_dense_matmul(support, x1) - x0 # 切比雪夫多项式算法x = self._concat(x, x2)x1, x0 = x2, x1# 合并扩散结果:(batch_size * num_nodes, input_size * num_matrices)num_matrices = len(self._supports) * self._max_diffusion_step + 1 # Adds for x itself.x = tf.reshape(x, shape=[num_matrices, self._num_nodes, input_size, batch_size])x = tf.transpose(x, perm=[3, 1, 2, 0]) # (batch_size, num_nodes, input_size, order)x = tf.reshape(x, shape=[batch_size * self._num_nodes, input_size * num_matrices])# 应用权重和偏置,得到卷积输出weights = tf.get_variable('weights', [input_size * num_matrices, output_size], dtype=dtype,initializer=tf.contrib.layers.xavier_initializer())x = tf.matmul(x, weights) # (batch_size * self._num_nodes, output_size)biases = tf.get_variable("biases", [output_size], dtype=dtype,initializer=tf.constant_initializer(bias_start, dtype=dtype))x = tf.nn.bias_add(x, biases)先通过 utils.calculate_random_walk_matrix(adj_mx).T 计算出(Do逆)与 W 的乘积 support (并且转化为了稀疏矩阵以便高效运算)。在上面的代码中,x0、x1 代表着代表着不同时间步的特征,也就是公式中的 X:,p;x2 是切比雪夫多项式的算法(优化拉普拉斯矩阵的高次幂计算);_max_diffusion_step 就是公式中的k,代表扩散步数;最后 weights 也就是公式中的 θk,代表扩散权重。
基于上述卷积操作,可以构建一个扩散卷积层,增强模型的表达能力。将 P-维特征映射到 Q-维输出。那么输出矩阵X(N×P)经过激活函数a,就转化为了输出矩阵H(N×Q)。
![]()
# Reshape res back to 2D: (batch_size, num_node, state_dim) -> (batch_size, num_node * state_dim)
return tf.reshape(x, [batch_size, self._num_nodes * output_size])2. 时间动态建模
在时间依赖建模中,作者使用了递归神经网络(RNN)的变体——门控循环单元(GRU)。并且使用扩散卷积替换了 GRU 中的矩阵乘法。那么定义如下:

上述式子中,∗G 表示扩散卷积(用扩散卷积去处理 Xt 和 Ht),Θr、Θu、ΘC 是相应的滤波器参数(也就是原始 GRU 中的权重参数)。那么接下来就能像 GRU 那样进行多步预测。
接下来看这部分的代码实现:
with tf.variable_scope(scope or "dcgru_cell"): # 添加变量的作用域(前缀)# 1.计算更新门u和重置门rwith tf.variable_scope("gates"):output_size = 2 * self._num_units# We start with bias of 1.0 to not reset and not update.# 判断使用哪种方法计算更新门和重置门if self._use_gc_for_ru:fn = self._gconvelse:fn = self._fcvalue = tf.nn.sigmoid(fn(inputs, state, output_size, bias_start=1.0))# 拆分并调整重置门和更新门的形状value = tf.reshape(value, (-1, self._num_nodes, output_size))r, u = tf.split(value=value, num_or_size_splits=2, axis=-1)r = tf.reshape(r, (-1, self._num_nodes * self._num_units))u = tf.reshape(u, (-1, self._num_nodes * self._num_units))# 2.计算候选状态 cwith tf.variable_scope("candidate"):c = self._gconv(inputs, r * state, self._num_units)if self._activation is not None:c = self._activation(c)# 3. 计算输出和新状态output = new_state = u * state + (1 - u) * c不管是第1步计算更新门 u 和 重置门 r ,还是第2步计算候选状态,都用到了扩散卷积函数 _gconv(公式中的 *G )。其中,偏置值不设置时默认为0,激活函数不设置时默认为 tanh。
在多步预测中,模型在生成每个步骤的预测时,依赖前一步的输出,但如果某一步的预测错误,会导致后续预测受到影响,从而引发错误逐步积累,最终显著降低预测精度。因此,作者团队为了缓解训练和测试期间输入分布不一致的问题,引入了计划抽样方法(Scheduled Sampling)。在训练过程中,计划抽样不是每次都让模型在每一步中直接使用前一步的真实观测值,而是引入一个采样概率 ϵ,按一定概率从真实观测值中抽样,按另一概率从模型的预测结果中抽样。随着训练的进行,这个采样概率逐渐从依赖真实观测值过渡到依赖预测值,最终在测试阶段模型只依赖于自己的预测。也就是说,采样概率 ϵ 会逐渐从1将为0。
计划抽样的代码如下:
# 控制每一步解码输入是使用模型的预测结果 prev,还是使用真实的标签值 labels[i]
def _loop_function(prev, i):if is_training:# Return either the model's prediction or the previous ground truth in training.if use_curriculum_learning: # 使用课程学习(模仿人类学习的特点,由简单到困难来学习课程)c = tf.random_uniform((), minval=0, maxval=1.)# 基于全局步数 global_step 计算采样阈值 thresholdthreshold = self._compute_sampling_threshold(global_step, cl_decay_steps)# 当随机数 c 小于 threshold 时,选择 labels[i](真实值);否则使用 prev(预测值)result = tf.cond(tf.less(c, threshold), lambda: labels[i], lambda: prev)else:result = labels[i]else:# Return the prediction of the model in testing.result = prevreturn result3. 代码结构
作者在 DCRNN 模型设计上分为了三个代码文件,分别是 dcrnn_cell.py、dcrnn_model.py和dcrnn_supervisor.py。一般而言,cell 文件通常定义的是一个神经网络中的基本计算单元或模块。而 model 文件定义了整个神经网络模型的结构,它将各个 cell 组合起来,实现从输入到输出的完整计算图。supervisor 文件通常负责训练和评估的流程管理,它调用 model 文件中的模型进行训练和推理,设置优化流程,监控训练状态。
dcnn_cell.py 中主要实现了扩散卷积和 GRU 的计算。其核心也就是上面1和2部分的代码。
dcrnn_model.py 的代码主要实现以下几个功能:
- 将 DCGRUCell 聚合为一个多层的 GRU 单元
- 设置训练时的特殊方法(例如上文的计划抽样)
- “编码(encoding)”和“解码(decoding)”
什么是编码和解码呢?它是指在序列到序列(Seq2Seq)模型中,将输入数据转换为潜在表示(编码)并生成输出序列(解码)的过程。在普通的 RNN 中,输入和输出的处理方式是逐时间步的,每个时间步的输入都会产生一个对应的输出。这只适用于固定长度的输入和输出序列,在不同长度的输入输出序列上表现不佳。相反, Seq2Seq 这种结构比普通的 RNN 更适合处理不同长度的输入和输出序列,尤其适合于交通预测等多步预测任务。具体知识点可见这位博主的讲解:Seq2Seq 模型详解_seq2seq模型-CSDN博客。
而在 DCRNNModel 类中,编码器将输入数据处理成隐藏状态(enc_state),这个状态浓缩了输入的特征;解码器以 enc_state 作为起点,逐步生成未来时刻的预测值。这部分的代码在后文实验对比会提到,代码如下所示:
# 创建多层RNN单元
encoding_cells = [cell] * num_rnn_layers # 在编码阶段将使用多个相同的RNN单元
decoding_cells = [cell] * (num_rnn_layers - 1) + [cell_with_projection] # 在解码的最后一层使用具有输出投影的单元,以确保输出维度正确。
encoding_cells = tf.contrib.rnn.MultiRNNCell(encoding_cells, state_is_tuple=True)
decoding_cells = tf.contrib.rnn.MultiRNNCell(decoding_cells, state_is_tuple=True)# 构建编码器和解码器
_, enc_state = tf.contrib.rnn.static_rnn(encoding_cells, inputs, dtype=tf.float32)
outputs, final_state = legacy_seq2seq.rnn_decoder(labels, enc_state, decoding_cells, loop_function=_loop_function)dcrnn_supervisor.py 的代码主要实现以下几个功能:
- 初始化参数配置
- 配置日志系统,便于后续调试和复现。
- 数据准备
- 通过
DCRNNModel初始化训练和测试模型的对象- 初始化学习率变量
- 配置优化器(默认Adam优化器)
- 定义损失函数
- 配置梯度裁剪与优化操作
- 配置模型保存器
其中第4步是这一个python文件的关键代码。
# 4. 构建模型
scaler = self._data['scaler'] # 标准化
with tf.name_scope('Train'): # 训练模式with tf.variable_scope('DCRNN', reuse=False):self._train_model = DCRNNModel(is_training=True, scaler=scaler,batch_size=self._data_kwargs['batch_size'],adj_mx=adj_mx, **self._model_kwargs)with tf.name_scope('Test'): # 测试模式with tf.variable_scope('DCRNN', reuse=True):self._test_model = DCRNNModel(is_training=False, scaler=scaler,batch_size=self._data_kwargs['test_batch_size'],adj_mx=adj_mx, **self._model_kwargs)三、相关工作
作者首先提出了以往研究的一些缺陷:

本文提出的 DCRNN 与上述方法不同:它将传感器网络建模为加权有向图,并利用扩散卷积捕捉空间依赖关系。通过在卷积中结合双向随机游走,DCRNN 能够更灵活地捕捉上游和下游的交通影响。此外,DCRNN 结合序列到序列学习框架及计划抽样技术,以更好地处理长期预测中的误差累积问题。
四、实验
作者使用了两个数据集实验,分别是 METR-LA 数据集和 PEMS-BAY 数据集。其中70% 的数据用于训练,20% 用于测试,剩余 10% 用于验证。
作者分别在后文分别讨论了时间建模和空间建模的效果。
首先在空间依赖建模上,选取了 DCRNN 的变体—— DCRNN-NoConv 和 DCRNN-UniConv。前者忽略空间依赖,后者使用单向游走(欧几里得图结构)。实验对比如下:

如果在空间依赖建模上不适用传播卷积而使用切比雪夫图卷积(GCRNN),那么结果也是显而易见的。

在时间依赖建模上,作者使用了 DCNN 和 DCRNN-SEQ 来做对比。前者是静态输入的卷积神经网络,而后者加入了 Seq2Seq 框架处理。而本文使用的 DCRNN 是在 DCRNN-SEQ 的基础上添加了计划抽样方法。经过实验,DCRNN 的效果表现最好。

五、总结
总结这篇论文的创新点如下:
- 使用传播模型的双向随机游走建立空间模型;
- 使用 GRU 捕捉时间动态;
- 结合了编码器-解码器架构;
- 计划抽样技术。
相关文章:
DCRNN解读(论文+代码)
一、引言 作者首先提出:空间结构是非欧几里得且有方向性的,未来的交通速度受下游交通影响大于上游交通。虽然卷积神经网络(CNN)在部分研究中用于建模空间相关性,但其主要适用于欧几里得空间(例如二维图像&a…...
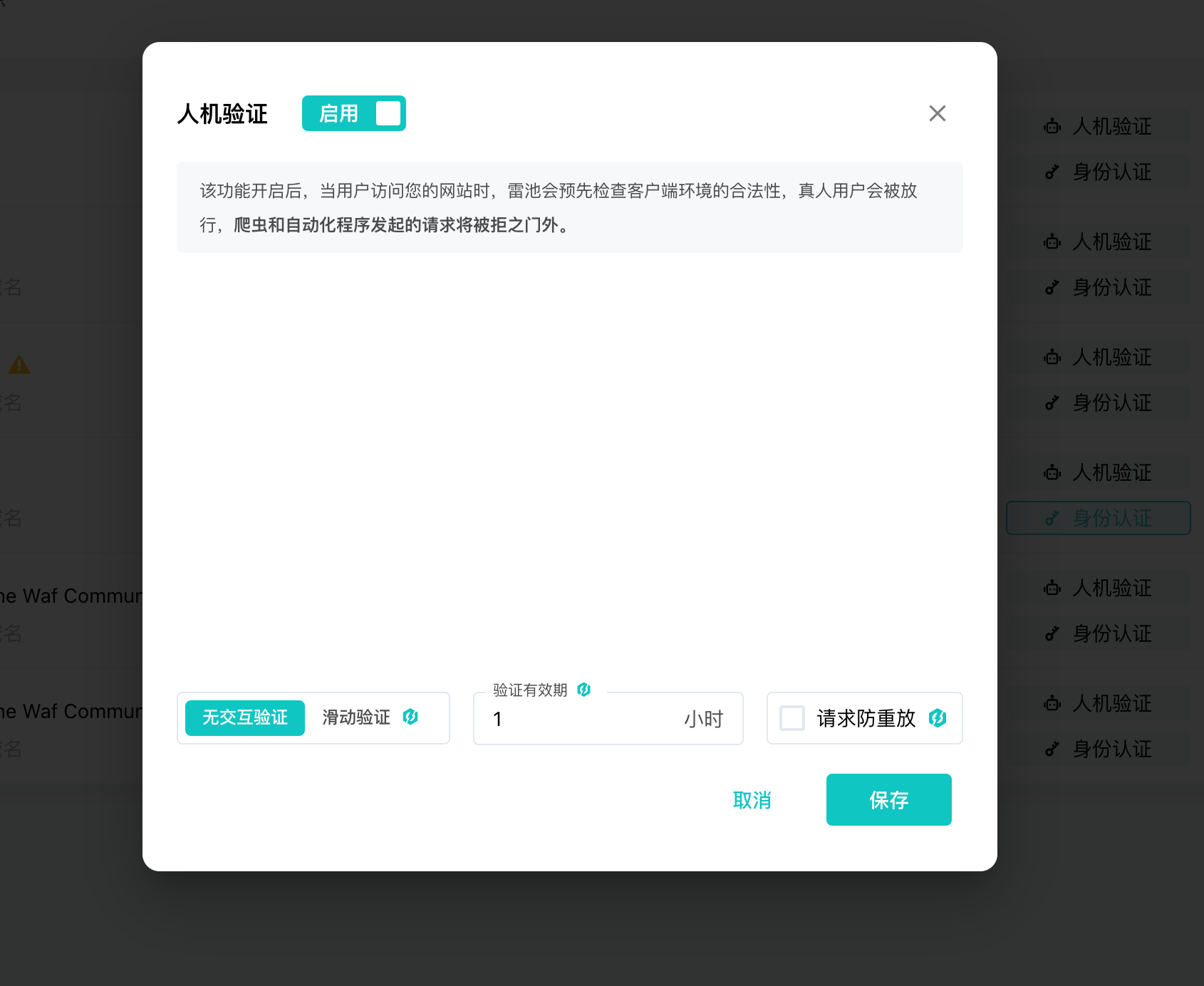
雷池社区版新版本功能防绕过人机验证解析
前两天,2024.10.31,雷池社区版更新7.1版本,其中有一个功能,新增请求防重放 更新记录:hhttps://docs.waf-ce.chaitin.cn/zh/%E7%89%88%E6%9C%AC%E6%9B%B4%E6%96%B0%E8%AE%B0%E5%BD%95 仔细研究了这个需求,…...

一文详解开源ETL工具Kettle!
一、Kettle 是什么 Kettle 是一款开源的 ETL(Extract - Transform - Load)工具,用于数据抽取、转换和加载。它提供了一个可视化的设计环境,允许用户通过简单的拖拽和配置操作来构建复杂的数据处理工作流,能够处理各种数…...

《IMM交互式多模型滤波MATLAB实践》专栏目录,持续更新……
专栏链接:https://blog.csdn.net/callmeup/category_12816762.html 专栏介绍 关于IMM的例程 双模型EKF: 【逐行注释】基于CV/CT模型的IMM|MATLAB程序|源代码复制后即可运行,无需下载三模型EKF: 【matlab代码】3个模型的IMM例程&…...

解决数据集中xml文件类别标签的首字母大小写不一致问题
import os import xml.etree.ElementTree as ET# 指定要处理的 XML 文件夹路径 xml_folder_path rD:\CVproject\ultralytics-main\datatrans\Annotationsdef capitalize_first_letter_in_xml(xml_file):# 解析 XML 文件tree ET.parse(xml_file)root tree.getroot()# 遍历所有…...
手边酒店多商户版V2源码独立部署_博纳软云
新版采用laraveluniapp开发,为更多平台小程序开发提供坚实可靠的底层架构基础。后台UI全部重写,兼容手机端管理。 全新架构、会员卡、钟点房、商城、点餐、商户独立管理...

32位汇编——通用寄存器
通用寄存器 什么是寄存器呢? 计算机在三个地方可以存储数据,第一个是把数据存到CPU中,第二个把数据存到内存中,第三个把数据存到硬盘上。 那这个所谓的寄存器,就是CPU中用来存储数据的地方。那这个寄存器有多大呢&a…...

vue3项目中实现el-table分批渲染表格
开篇 因最近工作中遇到了无分页情景下页面因大数据量卡顿的问题,在分别考虑并尝试了懒加载、虚拟滚动、分批渲染等各个方法后,最后决定使用分批渲染来解决该问题。 代码实现 表格代码 <el-table :data"currTableData"borderstyle"wi…...

开源办公软件 ONLYOFFICE 深入探索
文章目录 引言1. ONLYOFFICE 创建的背景1. 1 ONLYOFFICE 项目启动1. 2 ONLYOFFICE 的发展历程 2. 核心功能介绍2. 1 桌面编辑器2. 1. 1 文档2. 1. 2 表格2. 1. 3 幻灯片 2. 2 协作空间2. 3 文档编辑器 - 本地部署版 3. 技术介绍4. 安装5. 优势与挑战6. 个人体验7. 强大但不止于…...

原生鸿蒙应用市场:开发者的新机遇与深度探索
文章目录 自动化检测前移:提升开发效率与质量的新利器数据服务:数据驱动的精细化运营助手测试服务:保障应用质量的关键环节应用加密:保护应用安全与权益的利器从开发到运营的全方位支持写在最后 2024年10月22日,华为在…...

MATLAB实现蝙蝠算法(BA)
MATLAB实现蝙蝠算法(BA) 1.算法介绍 蝙蝠算法(简称BA)是一种受微型蝙蝠回声定位机制启发的群体智能算法,由Xin-She Yang于2010年提出。这种算法模拟了微型蝙蝠通过向周围环境发出声音并监听回声来识别猎物、避开障碍物以及追踪巢穴的行为。…...

WPF使用Prism框架首页界面
1. 首先确保已经下载了NuGet包MaterialDesignThemes 2.我们通过包的项目URL可以跳转到Github上查看源码 3.找到首页所在的代码位置 4.将代码复制下来,删除掉自己不需要的东西,最终如下 <materialDesign:DialogHostDialogTheme"Inherit"Ide…...

Linux中的软硬链接文件详解
概述 在Linux文件系统中,软连接(Symbolic Link)和硬连接(Hard Link)是两种重要的文件链接方式。它们都可以创建指向相同文件内容的多个“链接”,但在实现方式和特性上有所不同。 1. 硬连接(Ha…...

「Mac畅玩鸿蒙与硬件18」鸿蒙UI组件篇8 - 高级动画效果与缓动控制
高级动画可以显著提升用户体验,为应用界面带来更流畅的视觉效果。本篇将深入介绍鸿蒙框架的高级动画,包括弹性动画、透明度渐变和旋转缩放组合动画等示例。 关键词 高级动画弹性缓动自动动画缓动曲线 一、Animation 组件的高级缓动曲线 缓动曲线&#…...

pgsql数据量大之后可能遇到的问题
当 PostgreSQL 数据量增大时,可能会遇到以下问题: 查询性能下降:随着数据量的增加,查询可能会变得缓慢,尤其是在没有适当索引的情况下。大量的数据意味着更多的行需要被扫描和过滤,这会显著增加查询执行时间…...

Android 解决MTK相机前摄镜像问题
很莫名其妙的,前摄默认镜像,原来是为了前摄拍字体正确显示,比如自拍,前摄拍摄的人像虽左右镜像了,但如果后面有字牌显示,字体会显示正常而不是翻转。但现在需求是满足普遍的前摄原生代码不带镜像修改&#…...

在 Oracle 数据库中,SERVICE_NAME 和 SERVICE_NAMES 有什么区别?
在 Oracle 数据库中,SERVICE_NAME 和 SERVICE_NAMES 是两个相关的但略有不同的概念。它们都用于标识数据库服务,但使用场景和作用有所不同。下面详细解释这两个概念的区别: SERVICE_NAME 1. 定义: SERVICE_NAME 是一个单一的、…...

【Maven】——基础入门,插件安装、配置和简单使用,Maven如何设置国内源
阿华代码,不是逆风,就是我疯 你们的点赞收藏是我前进最大的动力!! 希望本文内容能够帮助到你!! 目录 引入: 一:Maven插件的安装 1:环境准备 2:创建项目 二…...

AIGC时代LaTeX排版的应用、技巧与未来展望
文章目录 一、LaTeX简介与基础设置二、常用特殊符号与公式排版三、图片与表格的插入与排版四、自动编号与交叉引用五、自定义命令与样式六、LaTeX在AIGC时代的应用与挑战七、LaTeX的未来展望《LaTeX 入门实战》内容简介作者简介目录前言/序言读者对象本书内容充分利用本书 在AI…...

二叉树的深搜
前言: 本章节更深入学习递归 计算布尔二叉树的值 思路: 1.函数头设计:dfs(root) 2.函数体:需要一个接收left 和 right 的值 并且根据root的值进行比较 3.递归出口:很明显 当为叶子节点的时候…...
:从草稿到发布仅需11分钟)
AI新闻稿写作实战手册(含新华社/财新/36氪真实信源对照表):从草稿到发布仅需11分钟
更多请点击: https://codechina.net 第一章:AI新闻稿写作实战手册(含新华社/财新/36氪真实信源对照表):从草稿到发布仅需11分钟 三步完成合规新闻稿生成 使用本地部署的 Llama-3.1-70B-Instruct 模型配合结构化提示工…...

Node.js 服务端应用无缝接入 TaoToken 多模型 API 的配置详解
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js 服务端应用无缝接入 TaoToken 多模型 API 的配置详解 对于 Node.js 后端开发者而言,为应用快速集成大模型能力…...

如何用WeChatMsg永久保存微信聊天记录:3步轻松备份完整指南
如何用WeChatMsg永久保存微信聊天记录:3步轻松备份完整指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/…...

FigmaCN:3分钟破解设计师的语言障碍,工作效率提升40%的秘密武器
FigmaCN:3分钟破解设计师的语言障碍,工作效率提升40%的秘密武器 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的英文界面而烦恼吗?每次…...

忘记压缩包密码怎么办?3个步骤帮你快速找回加密文件访问权限
忘记压缩包密码怎么办?3个步骤帮你快速找回加密文件访问权限 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经面对一个…...

终极解决方案:如何用qmc-decoder快速解锁QQ音乐加密格式
终极解决方案:如何用qmc-decoder快速解锁QQ音乐加密格式 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾经下载了QQ音乐,却发现那些.qmc3、…...

DCT 变换:揭秘那个让一张图片“瘦身“百倍的数学魔法
一、一个让我"开窍"的乐队演奏故事 我有个学音乐的朋友,他给我讲过一个让我至今难忘的故事。他说有一次他听一支交响乐团演奏贝多芬的《第五交响曲》,指挥家在排练时做了一个特别有趣的"游戏"——他让乐团分别只演奏不同乐器组的声音…...

全域数学公理:32维超球体投影、微观曲率与碳基\-硅基全息共振统一理论
全域数学公理:32维超球体投影、微观曲率与碳基-硅基全息共振统一理论 作者:乖乖数学(大师) 日期:2026年5月28日 学科分类:理论物理;量子宇宙学;高维几何;意识物理&…...

MySQL 分库分表实战
# MySQL 分库分表实战数据量到了千万级,单表扛不住了,就要分库分表。这篇说说怎么做。## 什么时候需要分库分表? 单表数据量: - < 500万:不用分,加索引、优化 SQL - 500万~2000万࿱…...

Java+Selenium等待机制实战:显式等待、FluentWait与SPA适配
1. 为什么“等”这件事,比写代码还难? 在JavaSelenium项目里,我见过太多人把WebDriver写得行云流水,结果一跑自动化脚本就卡在“元素找不到”上——不是代码写错了,是 没等对 。你点一个按钮,页面跳转、数…...