【大数据学习 | kafka】kafka的ack和一致性
1. ack级别
上文中我们提到过kafka是存在确认应答机制的,也就是数据在发送到kafka的时候,kafka会回复一个确认信息,这个确认信息是存在等级的。
ack=0 这个等级是最低的,这个级别中数据sender线程复制完毕数据默认kafka已经接收到数据。
ack=1 这个级别中,sender线程复制完毕数据leader分区拿到数据放入到自己的存储并且返回确认信息
ack= -1 这个级别比较重要,sender线程复制完毕数据,主分区接受完毕数据并且从分区都同步完毕数据然后在返回确认信息
那么以上的等级在使用的时候都会出现什么问题呢?
ack = 0 会丢失数据

ack=0时,在异步复制过程中,leader可能会丢失leader分区和follower分区的数据。
ack=1

ack=1的时候leader虽然接收到数据存储到本地,但是没有同步给follower节点,这个时候主节点宕机,从节点重新选举新的主节点,主节点是不含有这个数据的,数据会丢失.
ack = -1

这个模式不会丢失数据,但是如果leader接受完毕数据并且将数据同步给不同的follower,从节点已经接受完毕,但是还没有返回给sender线程ack的时候,这个时候leader节点宕机了,sender没有接收到这个ack,它人为没有发送成功还会重新发送数据过来,会造成数据重复。
一般前两种都适合在数据并不是特别重要的时候使用,而最后一种效率会比较低下,但是适用于可靠性比较高的场景使用
所以一般使用我们都会使用ack = -1 retries = N 联合在一起使用
那么我们如何能够保证数据的一致性呢?
2. 幂等性
在kafka的0.10以后的版本中增加了新的特性,幂等性,主要就是为了解决kafka的ack = -1的时候,数据的重复问题,设计的原理就是在kafka中增加一个事务编号。

数据在发送的时候在单个分区中的seq事物编号是递增的,如果重复的在一个分区中多次插入编号一致的两个信息,那么这个数据会被去重掉
在单个分区中序号递增,也就是我们开启幂等性也只能保证单个分区的数据是可以去重的
整体代码如下:
pro.put(ProducerConfig.RETRIES_CONFIG,3);
pro.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG,true);设定retries = 3 ,enable.idempotence = true
幂等性开启的时候,ack默认设定为-1。
幂等性的工作原理很简单,每条消息都有一个「主键」,这个主键由 <PID, Partition, SeqNumber> 组成,他们分别是:
- PID:ProducerID,每个生产者启动时,Kafka 都会给它分配一个 ID,ProducerID 是生产者的唯一标识,需要注意的是,Kafka 重启也会重新分配 PID
- Partition:消息需要发往的分区号
- SeqNumber:生产者,他会记录自己所发送的消息,给他们分配一个自增的 ID,这个 ID 就是 SeqNumber,是该消息的唯一标识
对于主键相同的数据,Kafka 是不会重复持久化的,它只会接收一条,但由于是原理的限制,幂等性也只能保证单分区、单会话内的数据不重复,如果 Kafka 挂掉,重新给生产者分配了 PID,还是有可能产生重复的数据,这就需要另一个特性来保证了 ——Kafka 事务。
3. kafka的事务
Kafka 事务基于幂等性实现,通过事务机制,Kafka 可以实现对多个 Topic 、多个 Partition 的原子性的写入,即处于同一个事务内的所有消息,最终结果是要么全部写成功,要么全部写失败。
Kafka 事务分为生产者事务和消费者事务,但它们并不是强绑定的关系,消费者主要依赖自身对事务进行控制,因此这里我们主要讨论的是生产者事务。
3.1 如何开启事务
创建一个 Producer,指定一个事务 ID:
Properties properties = new Properties();properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());//设置事务ID,必须
properties.setProperty(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "transactional_id_1");
//创建生产者
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);使用事务发送消息:
// 初始化事务
producer.initTransactions();
// 开启事务
producer.beginTransaction();//发送10条消息往kafka,假如中间有异常,所有消息都会发送失败
try {for (int i = 0; i < 10; i++) {producer.send(new ProducerRecord<>("topic-test", "a message" + i));}
}
// 提交事务
producer.commitTransaction();
} catch (Exception e) {// 终止事务producer.abortTransaction();
} finally {producer.close();
}3.2 事务工作原理

1)启动生产者,分配协调器
在使用事务的时候,必须给生产者指定一个事务 ID,生产者启动时,Kafka 会根据事务 ID 来分配一个事务协调器(Transaction Coordinator) 。每个 Broker 都有一个事务协调器,负责分配 PID(Producer ID) 和管理事务。
事务协调器的分配涉及到一个特殊的主题 __transaction_state,该主题默认有 50 个分区,每个分区负责一部分事务;Kafka 根据事务ID的hashcode值%50 计算出该事务属于哪个分区, 该分区 Leader 所在 Broker 的事务协调器就会被分配给该生产者。
分配完事务协调器后,该事务协调器会给生产者分配一个 PID,接下来生产者就可以准备发送消息了。
2)发送消息
生产者分配到 PID 后,要先告诉事务协调器要把消息发往哪些分区,协调器会做一个记录,然后生产者就可以开始发送消息了,这些消息与普通的消息不同,它们带着一个字段标识自己是事务消息。
当生产者事务内的消息发送完毕,会向事务协调器发送 Commit 或 Abort 请求,此时生产者的工作已经做完了,它只需要等待 Kafka 的响应。
3)确认事务
当生产者开始发送消息时,协调器判定事务开始。它会将开始的信息持久化到主题 __transaction_state 中。
当生产者发送完事务内的消息,或者遇到异常发送失败,协调器会收到 Commit 或 Abort 请求,接着事务协调器会跟所有主题通信,告诉它们事务是成功还是失败的。
如果是成功,主题会汇报自己已经收到消息,协调者收到所有主题的回应便确认了事务完成,并持久化这一结果。
如果是失败的,主题会把这个事务内的消息丢弃,并汇报给协调者,协调者收到所有结果后再持久化这一信息,事务结束;整个放弃事务的过程消费者是无感知的,它并不会收到这些数据。
事物不仅可以保证多个数据整体成功失败,还可以保证数据丢失后恢复。
3.3 代码实现
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.Properties;public class ProducerWithTransaction {public static void main(String[] args) {Properties pro = new Properties();pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop106:9092");pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());pro.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"transaciton_test");KafkaProducer<String, String> producer = new KafkaProducer<String, String>(pro);ProducerRecord<String, String> record = new ProducerRecord<>("topic_a", "this is hainiu");producer.initTransactions();producer.beginTransaction();try{for(int i=0;i<5;i++){producer.send(record);}
// int a = 1/0;producer.commitTransaction();}catch (Exception e){producer.abortTransaction();}finally {producer.close();}}
}4. 一致性语义
在大数据场景中存在三种时间语义,分别为
At Least Once 至少一次,数据至少一次,可能会重复
At Most Once 至多一次,数据至多一次,可能会丢失
Exactly Once 精准一次,有且只有一次,准确的消息传输
那么针对于以上我们学习了ack已经幂等性以及事务。
所以我们做以下分析:
如果设定ack = 0 或者是 1 出现的语义就是At Most Once 会丢失数据
如果设定ack = - 1 会出现At Least Once 数据的重复
在ack = -1的基础上开启幂等性会解决掉数据重复问题,但是不能保证一个批次的数据整体一致,所以还要开启事务才可以。
5. 参数调节
| 参数 | 调节 |
|---|---|
| buffer.memory | record accumulator的大小,适当增加可以保证producer的速度,默认32M |
| batch-size | 异步线程拉取的批次大小,适当增加可以提高效率,但是会增加延迟性 |
| linger.ms | 异步线程等待时长一般根据生产效率而定,不建议太大增加延迟效果 |
| acks | 确认应答一般设定为-1,保证数据不丢失 |
| enable.idempotence | 开启幂等性保证数据去重,实现exactly once语义 |
| retries | 增加重试次数,保证数据的稳定性 |
| compression.type | 增加producer端的压缩 |
| max.in.flight.requests.per.connection | sender线程异步复制数据的阻塞次数,当没收到kafka的ack之前可以最多发送五个写入请求,调节这个参数可以保证数据的有序性 |
全部代码:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.Properties;public class ProducerWithMultiConfig {public static void main(String[] args) throws InterruptedException {Properties pro = new Properties();pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop106:9092");pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());pro.put(ProducerConfig.BATCH_SIZE_CONFIG, 16*1024);pro.put(ProducerConfig.LINGER_MS_CONFIG, 100);pro.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 1024*1024*64);pro.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);pro.put(ProducerConfig.RETRIES_CONFIG, 3);pro.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");pro.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, 5);KafkaProducer<String, String> producer = new KafkaProducer<String, String>(pro);ProducerRecord<String, String> record = new ProducerRecord<>("topic_a", "this is hainiu");producer.send(record);producer.close();}
}其中max.in.flight.requests.per.connection参数设定后可以增加producer的阻塞大小
在未开启幂等性的时候,这个值设定为1,可以保证单个批次的数据有序,在分区内部有序
如果开启了幂等性可以设定最大值不超过5,可以保证五个request请求单个分区内有序
因为没有开启幂等性的时候如果第一个请求失败,第二个请求重新发送的时候需要二次排序
要是开启幂等性了会保留原来的顺序性,不需要重新排序
总而言之kafka可以保证单分区有序但是整体是无序的
相关文章:
【大数据学习 | kafka】kafka的ack和一致性
1. ack级别 上文中我们提到过kafka是存在确认应答机制的,也就是数据在发送到kafka的时候,kafka会回复一个确认信息,这个确认信息是存在等级的。 ack0 这个等级是最低的,这个级别中数据sender线程复制完毕数据默认kafka已经接收到…...

学习虚幻C++开发日志——定时器
官方文档:虚幻引擎中的Gameplay定时器 | 虚幻引擎 5.5 文档 | Epic Developer Community | Epic Developer Community 定时器 安排在经过一定延迟或一段时间结束后要执行的操作。例如,您可能希望玩家在获取某个能力提升道具后变得无懈可击,…...
—— 有了浔川社团官方联合会和社团官方,那么浔川总社部是干什么的呢?)
问政浔川(1)—— 有了浔川社团官方联合会和社团官方,那么浔川总社部是干什么的呢?
问政浔川(1)—— 有了浔川社团官方联合会和社团官方,那么浔川总社部是干什么的呢? 在浔川社团组织的复杂架构中,浔川社团官方联合会和社团官方已广为人知,但对于浔川总社部,很多人仍心存疑惑。这…...
)
区块链技术应用--电子签章(模块三)
区块链技术应用–电子签章(模块三) 背景描述 电子签章可实现与纸质文件盖章操作相似的可视效果,以保障数据来源的真实性、数据完整性以及签名人行为的不可否认性。 传统的电子签章系统是基于中心化的,也就是数据是集中存储在中心数据库中,这就导致传统电子签章使用记录…...

多面体定义+多面体是凸集+多面体的重要性质
文章目录 多面体定义多面体是凸集多面体重要性质1. 有界多面体(Convex Polytope)2. 无界多面体(Unbounded Polyhedron)3. 极点表示(顶点形式)与极点-极射线表示定理 在数学中, 多面体ÿ…...

为什么 Allow 配合 meta noindex 比使用Disallow好?
为什么 Allow 配合 meta noindex 1、Disallow 的问题 当你使用 Disallow: / 时: 爬虫根本不会访问你的页面 因此永远看不到你的 meta noindex 标签 如果有其他网站链接到你的页面,Google 可能还是会将其编入索引(因为它无法确认你是否真的…...

通讯学徒学习日记
本章内容为 长期更新模式,目前入职的第三天,学徒状态。 文章目录 前言开始接水晶头、接光纤水晶头接光纤 PON(GPON 、EPON)AON 和 PON 的详解AONPON 前言 编程虽然是爱好,但确实也想把这份爱好变成工作。但是对于目前刚…...

迪杰斯特拉算法
迪杰斯特拉算法 LeetCode 743. 网络延迟时间 https://blog.csdn.net/xiaoxi_hahaha/article/details/110257368 import sysdef dijkstra(graph, source):"""dijkstra算法:param graph: 邻接矩阵:param source: 出发点,源点:return:""&…...

IPsec传输模式与隧道模式的深度解析及应用实例
随着网络安全威胁的日益严峻,IPsec作为网络层安全协议,其传输模式与隧道模式的选择对确保通信安全至关重要。本文旨在深入探讨这两种模式的差异,并通过实际案例展示其应用。 一、传输模式和隧道模式的详细描述 传输模式: 应用场景…...

实现Vue3/Nuxt3 预览excel文件
安装必要的库 npm install xlsx 创建一个组件来处理文件上传和解析: 在src/components 目录下创建一个名为 ExcelPreview.vue 的文件 <template> <div> <input type"file" change"handleFileUpload" /> <table v-if"…...

【AI落地应用实战】HivisionIDPhotos AI证件照制作实践指南
最近在网上发现了一款轻量级的AI证件照制作的项目,名为HivisionIDPhotos。它利用AI模型实现对多种拍照场景的识别、抠图与证件照生成,支持轻量级抠图、多种标准证件照和排版照生成、纯离线或端云推理、美颜等功能。此外,项目还提供了Gradio D…...

php实现sl651水文规约解析
SL651-2014-《水文监测数据通信规约》 1、要素解析说明 39 23 00 00 03 45 0x39查标识符得知为:39H Z 瞬时河道水位、潮位,我们定义为水位 0x23 按照要素标识符的规定,高5bit,低3bit,00100 011 对应的转换为10进制为4与3,也就是水位数据占用4字节,小…...
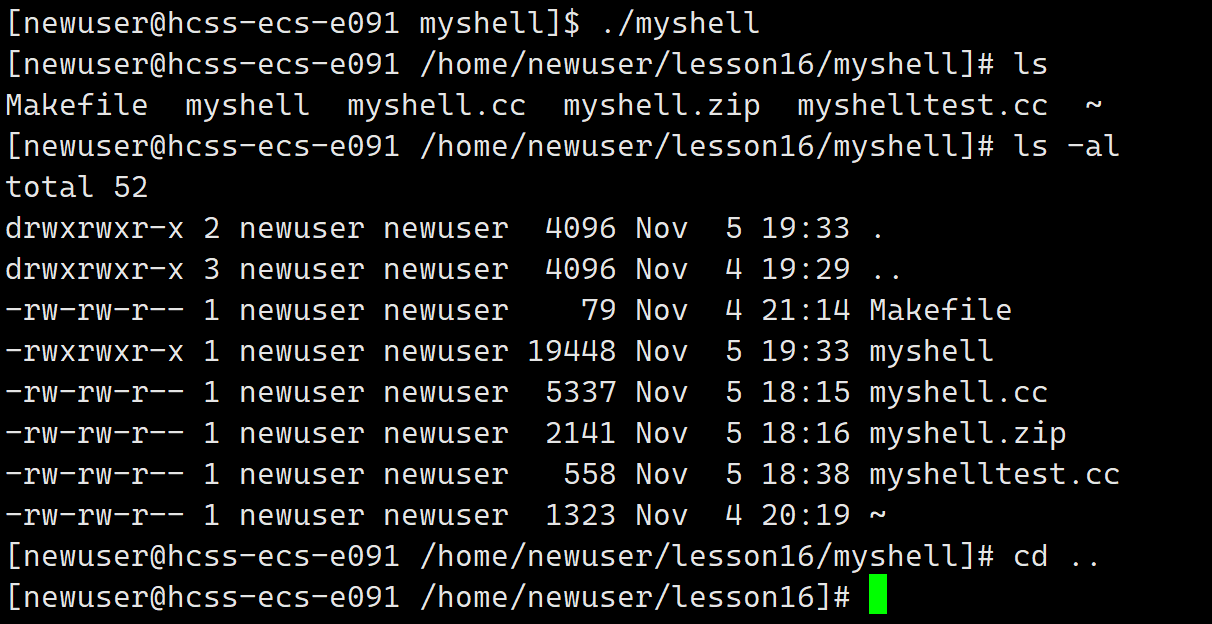
【Linux】简易版shell
文章目录 shell的基本框架PrintCommandLineGetCommandLineParseCommandLineExecuteCommandInitEnvCheckAndExecBuildCommand代码总览运行效果总结 shell的基本框架 要写一个命令行我们首先要写出基本框架。 打印命令行获取用户输入的命令分析命令执行命令 基本框架的代码&am…...

宝塔Linux面板安装PHP扩展失败报wget: unable to resolve host address ‘download.bt.cn’
一、问题: 当使用宝塔面板安装PHP扩展失败出现如下错误时 Resolving download.bt.cn(download.bt.cn)...failed: Connection timed out. wget: unable toresolve host address download.bt.cn’ 二、解决: 第一步:如下命令执行拿到返回的I…...

问:Redis常见性能问题及解法?
Redis 作为一个高性能的键值存储系统,在实际应用中可能会遇到各种性能问题。本文将探讨 Redis 的常见性能问题,并提供相应的解决建议。主要针对五个关键问题进行讨论:Master 节点的持久化工作、Slave 节点的数据备份、主从复制的网络环境、主…...

Imperva 数据库与安全解决方案
Imperva是网络安全解决方案的专业提供商,能够在云端和本地对业务关键数据和应用程序提供保护。公司成立于 2002 年,拥有稳定的发展和成功历史并于 2014 年实现产值1.64亿美元,公司的3700多位客户及300个合作伙伴分布于全球各地的90多个国家。…...
【JavaScript】之文档对象模型(DOM)详解
JavaScript 的强大之处在于它能够与 HTML 和 CSS 交互,动态地修改网页内容和样式。而实现这一功能的核心就是 DOM(文档对象模型)。 一、什么是 DOM? DOM 是文档对象模型(Document Object Model)的缩写。它…...

速盾:cdn域名与ip区别
CDN(内容分发网络)是一种通过在全球多个服务器上缓存和分发静态资源的网络服务,可以提高网站的访问速度和性能。在使用CDN时,域名与IP地址是两个关键的概念。本文将介绍CDN域名与IP地址的区别和作用。 首先,CDN域名是…...

如何优雅的在页面上嵌入AI-Agent人工智能
前言 IDEA启动!大模型的title想必不用我多说了,多少公司想要搭上时代前言技术的快车,感受科技的魅力。现在大模型作为降本增效的强大工具,基本上公司大多人都想要部署开发一把,更多的想要利用到这些模型放到生产中来提…...
如何对LabVIEW软件进行性能评估?
对LabVIEW软件进行性能评估,可以从以下几个方面着手,通过定量与定性分析,全面了解软件在实际应用中的表现。这些评估方法适用于确保LabVIEW程序的运行效率、稳定性和可维护性。 一、响应时间和执行效率 时间戳测量:使用LabVIEW的时…...

建筑项目进度延误率下降37%的秘密:一个轻量化AI Agent工作流,已在12个EPC项目中闭环验证
更多请点击: https://codechina.net 第一章:建筑项目进度延误率下降37%的秘密:一个轻量化AI Agent工作流,已在12个EPC项目中闭环验证 在某头部工程总承包(EPC)企业落地的轻量化AI Agent工作流,…...

别再只跑代码了!用泰坦尼克号数据集,手把手教你从EDA到模型调优的完整数据分析实战
从数据洞察到模型优化:泰坦尼克号生存预测的深度实践指南 如果你已经能够熟练运行数据分析代码,却依然对项目全流程缺乏系统性认知,这篇文章将带你超越基础操作,深入理解数据分析的完整闭环。我们将以经典的泰坦尼克号数据集为例&…...

UE5 BaseDeviceProfiles.ini深度解析:跨平台性能调优核心机制
1. 为什么一个ini文件值得花三天逐行精读——UE5跨平台性能配置的“隐形指挥官”很多人第一次在UE5项目里打开BaseDeviceProfiles.ini,看到满屏的[Android_Samsung_GalaxyS23]、[IOS_iPhone14Pro]、[Windows_NVIDIA_RTX4090]这类Section,下意识觉得&…...

微生物代谢建模与优化:从GEMs构建到工业应用
1. 微生物代谢建模与优化的协同设计方法在工业生物技术领域,微生物代谢建模已成为优化生物转化过程的核心工具。通过构建基因组尺度代谢模型(GEMs),研究人员能够系统分析微生物细胞内数百至数千个酶催化反应的相互作用网络。以丁酸…...
)
仅限首批200家零售企业获取:2024中国零售Agent成熟度评估矩阵V2.1(含137项能力测评项+自动生成差距报告)
更多请点击: https://codechina.net 第一章:AI Agent零售行业应用 AI Agent 正在重塑零售行业的客户体验、供应链效率与决策智能化水平。通过融合自然语言理解、多步推理、工具调用与记忆机制,AI Agent 不再是单点问答机器人,而是…...

3步解锁Windows远程桌面多人连接:RDP Wrapper Library完整指南
3步解锁Windows远程桌面多人连接:RDP Wrapper Library完整指南 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 你是否曾因Windows家庭版无法支持多人远程桌面连接而感到困扰?当团队成员需要…...

去偏机器学习在交通行为因果推断中的应用:从关联分析到因果效应评估
1. 项目概述:当交通研究遇上因果推断在交通工程与城市规划领域,我们常常面临一个核心挑战:如何从海量的观测数据中,剥离出某个特定因素(比如一项新政策、一种交通管控措施)对人们行为的“真实”影响&#x…...

内网渗透之横向移动实战
在红队渗透测试中,当我们通过 Web 渗透拿到边界服务器的权限后,往往不会止步于此 —— 内部网络中还隐藏着更多的核心资产,比如存储着企业所有账号信息的域控制器。而横向移动,就是我们从边界主机出发,一步步渗透到内网…...

深度揭秘:如何在Mac上无痛备份微信聊天记录
深度揭秘:如何在Mac上无痛备份微信聊天记录 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因微信聊天记录丢失而懊恼?那些珍贵的对话、重…...

昇腾CANN runtime Stream 调度引擎:从命令队列到 AI Core 的执行链路
用户看到的是一行 torch.nn.functional.softmax(x),背后 runtime 要做:分配 Stream、入队命令、调度到 AI Core、等待完成、同步结果。如果这一行的延迟是 10μs,runtime 的调度开销必须 < 0.5μs——否则就是 5% 的性能损失。 runtime 的…...