【大数据学习 | kafka】kafka的偏移量管理
1. 偏移量的概念

消费者在消费数据的时候需要将消费的记录存储到一个位置,防止因为消费者程序宕机而引起断点消费数据丢失问题,下一次可以按照相应的位置从kafka中找寻数据,这个消费位置记录称之为偏移量offset。

kafka0.9以前版本将偏移量信息记录到zookeeper中

新版本中偏移量信息记录在__consumer_offsets中,这个topic是系统生成的,不仅仅帮助管理偏移量信息还能分配consumer给哪个coordinator管理,是一个非常重要的topic
它的记录方式和我们知道的记录方式一样 groupid + topic + partition ==> offset
其中存储到__consumer_offsets中的数据格式也是按照k-v进行存储的,其中k是groupid + topic + partition
value值为offset的偏移量信息。
[hexuan@hadoop106 ~]$ kafka-topics.sh --bootstrap-server hadoop106:9092 --list
__consumer_offsets
topic_a
topic_b
topic_c
topic_e
topic_f
topic_g
可以看到系统生成的topic
因为之前我们消费过很多数据,现在可以查看一下记录在这个topic中的偏移量信息
其中存在一个kafka-consumer-groups.sh 命令
# 查看消费者组信息
kafka-consumer-groups.sh --bootstrap-server hadoop106:9092 --list
# 查询具体信息
kafka-consumer-groups.sh --bootstrap-server hadoop106:9092 --describe --group my-group
# 查看活跃信息
kafka-consumer-groups.sh --bootstrap-server hadoop106:9092 --describe --group my-group --members查看消费者组信息:
[hexuan@hadoop106 ~]$ kafka-consumer-groups.sh --bootstrap-server hadoop106:9092 --list
hainiu_group
hainiu_group2
当前使用组信息:
[hexuan@hadoop106 ~]$ kafka-consumer-groups.sh --bootstrap-server hadoop106:9092 --describe --group hainiu_groupGROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
hainiu_group topic_c 0 0 0 0 consumer-hainiu_group-1-41a9ebd6-99a3-4d83-b1d7-88a2a9295054 /192.168.154.1 consumer-hainiu_group-1
hainiu_group topic_b 1 1438 1438 0 - - -
hainiu_group topic_b 0 1440 1440 0 - - -
hainiu_group topic_b 3 1417 1417 0 - - -
hainiu_group topic_b 4 1473 1473 0 - - -
hainiu_group topic_b 5 1440 1440 0 - - -
hainiu_group topic_b 2 1407 1407 0 - - -
hainiu_group topic_b 6 1391 1391 0 - 当前组消费偏移量信息:
GROUP:组名
TOPIC:topic信息
PARTITION:分区
CURRENT-OFFSET:当前消费偏移量
LOG-END-OFFSET:这个分区总共存在多少数据
LAG:还差多少没消费
CONSUMER-ID:随机消费者id
HOST:主机名
CLIENT-ID:客户端id同时我们也可以查询__consumer_offset中的原生数据:
kafka-console-consumer.sh --bootstrap-server hadoop106:9092 \
--topic __consumer_offsets --from-beginning --formatter \
kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter使用元数据格式化方式查看偏移量信息数据
key展示的是groupid,topic,partition , value值展示的是当前的偏移量信息
并且在这个topic中是追加形式一致往里面写入的
2. 偏移量的自动管理
那么我们已经看到了偏移量的存储但是偏移量究竟是怎么提交的呢?
首先我们没有设置任何的偏移量提交的代码,这个是默认开启的,其中存在两个参数
pro.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
//开启自动提交偏移量信息
pro.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
//默认提交间隔5s

官网的设置参数为两个true和5000。
所以我们在没有开启默认提交的时候已经自动提交了
为了演示自动提交的效果我们引入一个参数
auto.offset.reset这个参数用于控制没有偏移量存储的时候,应该从什么位置进行消费数据
(因为偏移量自动提交默认是5秒一次,如果数据在5秒内消费完毕,则会造成偏移量并没有存储的情况)
其中参数值官网中给出三个
[latest, earliest, none]latest:从最新位置消费earliest:最早位置消费数据none:如果不指定消费的偏移量直接报错一定要记得一点,如果有偏移量信息那么以上的设置是无效的.

官方文档显示给出的该参数的默认值为lastest,即从最新位置开始消费。
现在我们设置读取位置为最早位置,并且消费数据,看看可不可以记录偏移量,断点续传
思路:
首先修改组id为一个新的组,然后从最早位置消费数据,如果记录了偏移量,那么重新启动消费者会看到,没有任何数据,因为之前记录了消费数据的位置
整体代码如下:
package com.hainiu.kafka;import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.*;public class Consumer1 {public static void main(String[] args) {Properties pro = new Properties();pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");pro.put(ConsumerConfig.GROUP_ID_CONFIG,"new_group");pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());pro.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);pro.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");pro.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(pro);List<String> topics = Arrays.asList("topic_d","topic_e");consumer.subscribe(topics);while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));Iterator<ConsumerRecord<String, String>> it = records.iterator();while(it.hasNext()){ConsumerRecord<String, String> record = it.next();System.out.println(record.topic()+"->"+record.partition()+"->"+ record.offset()+"->"+record.key()+"->"+record.value());}}}
}
运行完毕打印数据
这个时候我们需要在5s之内关闭应用,然后重新启动,因为提交的间隔时间是5s
再次启动

我们发现数据依旧被消费出来了,证明之前的偏移量存储没有任何效果和作用,因为间隔时间是5s
现在我们等待5s后在关闭应用

发现没有任何数据产生,因为偏移量已经提交了
3. 偏移量的手动提交
如上的案例我们发现偏移量的管理如果交给系统自己管理,我们没有办法及时的修改和管理偏移量信息,这个时候我们需要手动来提交给管理偏移量,更加及时和方便
这个时候引入两个方法
consumer.commitAsync();
consumer.commitSync();commitAsync 异步提交方式:只提交一次,不管成功与否不会重试
commitSync 同步提交方式:同步提交方式会一直提交到成功为止
一般我们都会选择异步提交方式,他们的功能都是将拉取到的一整批数据的最大偏移量直接提交到__consumer_offsets中,但是同步方式会很浪费资源,异步方式虽然不能保证稳定性但是我们的偏移量是一直递增存储的,所以偶尔提交不成功一个两个不影响我们的使用
pro.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
//设定自动提交为false
consumer.commitSync();
consumer.commitAsync();
//设定提交方式为手动提交整体代码如下:
package com.hainiu.kafka.consumer;/*** ClassName : consumer_offsets* Package : com.hainiu.kafka.consumer* Description** @Author HeXua* @Create 2024/11/5 21:30* Version 1.0*/import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.*;public class Consumer_CommitSync {public static void main(String[] args) {Properties pro = new Properties();pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop106:9092");pro.put(ConsumerConfig.GROUP_ID_CONFIG,"hainiu_group2");pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());pro.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);pro.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// pro.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(pro);List<String> topics = Arrays.asList("topic_h");consumer.subscribe(topics);while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));Iterator<ConsumerRecord<String, String>> it = records.iterator();while(it.hasNext()){ConsumerRecord<String, String> record = it.next();System.out.println(record.topic()+"->"+record.partition()+"->"+ record.offset()+"->"+record.key()+"->"+record.value());}consumer.commitAsync();
// consumer.commitSync();}}
}现在先在topic中输入部分数据
然后启动消费者,当存在数据打印的时候马上关闭掉应用,在此启动会发现数据不会重新消费

topic_h->5->12->null->1
topic_h->5->13->null->2
topic_h->5->14->null->3
topic_h->5->15->null->4
topic_h->5->16->null->5
topic_h->5->17->null->6偏移量已经提交不会重复消费数据
4. 断点消费数据
在没有偏移量的时候我们可以设定
auto.offset.reset进行数据的消费
可选参数有 latest earliest none等位置
但是如果存在偏移量以上的设定就不在好用了,我们需要根据偏移量的位置进行断点消费数据
但是有的时候我们需要指定位置消费相应的数据
这个时候我们需要使用到
consumer.seek();
//可以指定位置进行数据的检索但是我们不能随意的指定消费者消费数据的位置,因为在启动消费者的时候,一个组中会存在多个消费者,每个人拿到的对应分区是不同的,所以我们需要知道这个消费者能够获取的分区是哪个,然后再指定相应的断点位置
这里我们就需要监控分区的方法展示出来所有订阅的分区信息
consumer.subscribe(topics, new ConsumerRebalanceListener() {@Overridepublic void onPartitionsRevoked(Collection<TopicPartition> partitions) {}@Overridepublic void onPartitionsAssigned(Collection<TopicPartition> partitions) {}});为了演示效果我们使用生产者在topic_d中增加多个消息
package com.hainiu.kafka.consumer;/*** ClassName : Producer2* Package : com.hainiu.kafka.consumer* Description** @Author HeXua* @Create 2024/11/5 23:01* Version 1.0*/
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.Properties;public class Producer2 {public static void main(String[] args) {Properties pro = new Properties();pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop106:9092");pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());KafkaProducer<String, String> producer = new KafkaProducer<String, String>(pro);for (int i = 0; i < 1000; i++) {ProducerRecord<String, String> record = new ProducerRecord<String, String>("topic_d", "" + i, "message"+i);producer.send(record);}producer.close();}
}随机发送数据到不同的节点,使用随机key
然后使用断点消费数据
不设置任何的偏移量提交操作和断点位置
package com.hainiu.kafka.consumer;/*** ClassName : ConsumerWithUDOffset* Package : com.hainiu.kafka.consumer* Description** @Author HeXua* @Create 2024/11/5 23:03* Version 1.0*/
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.*;public class ConsumerWithUDOffset {public static void main(String[] args) {Properties pro = new Properties();pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop106:9092");pro.put(ConsumerConfig.GROUP_ID_CONFIG,"new1");pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());pro.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");pro.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG,6000);pro.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(pro);List<String> topics = Arrays.asList("topic_h");// range roundRobin sticky cooperativeStickyconsumer.subscribe(topics, new ConsumerRebalanceListener() {@Overridepublic void onPartitionsRevoked(Collection<TopicPartition> collection) {}@Overridepublic void onPartitionsAssigned(Collection<TopicPartition> collection) {for (TopicPartition topicPartition : collection) {consumer.seek(topicPartition,195);}}});while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));Iterator<ConsumerRecord<String, String>> it = records.iterator();while(it.hasNext()){ConsumerRecord<String, String> record = it.next();System.out.println(record.topic()+"->"+record.partition()+"->"+ record.offset()+"->"+record.key()+"->"+record.value());}consumer.commitAsync();}}
}

5. 时间断点
kafka没有给大家提供直接根据时间找到断点位置的方法,我们需要根据时间找到偏移量,然后根据偏移量进行数据消费
consumer.offsetsForTimes();
//通过这个方法找到对应时间的偏移量位置
consumer.seek();
//然后在通过这个方法根据断点进行消费数据整体代码如下
package com.hainiu.kafka;import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.*;public class Consumer1 {public static void main(String[] args) {Properties pro = new Properties();pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"nn1:9092");pro.put(ConsumerConfig.GROUP_ID_CONFIG,"new_group221");pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());pro.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(pro);List<String> topics = Arrays.asList("topic_e");consumer.subscribe(topics, new ConsumerRebalanceListener() {@Overridepublic void onPartitionsRevoked(Collection<TopicPartition> partitions) {// no op}@Overridepublic void onPartitionsAssigned(Collection<TopicPartition> partitions) {HashMap<TopicPartition, Long> map = new HashMap<>();for (TopicPartition partition : partitions) {map.put(partition,1675076400000L);//将时间和分区绑定在一起,然后合并在一起放入到检索方法中}Map<TopicPartition, OffsetAndTimestamp> offsets = consumer.offsetsForTimes(map);//根据时间获取时间对应的偏移量位置for (Map.Entry<TopicPartition, OffsetAndTimestamp> en : offsets.entrySet()) {System.out.println(en.getKey()+"-->"+en.getValue());if(en.getValue() != null){consumer.seek(en.getKey(),en.getValue().offset());//获取每个分区的偏移量的位置,使用seek进行找寻数据}}}});while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));Iterator<ConsumerRecord<String, String>> it = records.iterator();while(it.hasNext()){ConsumerRecord<String, String> record = it.next();System.out.println(record.topic()+"->"+record.partition()+"->"+ record.offset()+"->"+record.key()+"->"+record.value());}
// consumer.commitAsync();}}
}相关文章:
【大数据学习 | kafka】kafka的偏移量管理
1. 偏移量的概念 消费者在消费数据的时候需要将消费的记录存储到一个位置,防止因为消费者程序宕机而引起断点消费数据丢失问题,下一次可以按照相应的位置从kafka中找寻数据,这个消费位置记录称之为偏移量offset。 kafka0.9以前版本将偏移量信…...
实景三维赋能森林防灭火指挥调度智慧化
森林防灭火工作是保护森林资源和生态环境的重要任务。随着信息技术的发展,实景三维技术在森林防灭火指挥调度中的应用日益广泛,为提升防灭火工作的效率和效果提供了有力支持。 一、森林防灭火面临的挑战 森林火灾具有突发性强、破坏性大、蔓延速度快、…...

【C++课程学习】:string的模拟实现
🎁个人主页:我们的五年 🔍系列专栏:C课程学习 🎉欢迎大家点赞👍评论📝收藏⭐文章 目录 一.string的主体框架: 二.string的分析: 🍔构造函数和析构函数&a…...

Linux(VMware + CentOS )设置固定ip
需求:设置ip为 192.168.88.130 先关闭虚拟机 启动虚拟机 查看当前自动获取的ip 使用 FinalShell 通过 ssh 服务远程登录系统,更换到 root 用户 修改ip配置文件 vim /etc/sysconfig/network-scripts/ifcfg-ens33 重启网卡 systemctl restart network …...

安卓 android studio各版本下载地址(官方)
https://developer.android.google.cn/studio/archive 别用中文,右上角的语言切换成英文...

如何在一个 Docker 容器中运行多个进程 ?
在容器化的世界里,Docker 彻底改变了开发人员构建、发布和运行应用程序的方式。Docker 容器封装了运行应用程序所需的所有依赖项,使其易于跨不同环境一致地部署。然而,在单个 Docker 容器中管理多个进程可能具有挑战性,这就是 Sup…...

poetry 配置多个cuda环境心得
操作系统:ubuntu22.04 LTS python版本:3.12.7 最近学习了用poetry配置python虚拟环境,当为不同的项目配置cuda时,会遇到不同的项目使用的cuda版本不一致的情况。 像torch 这样的库,它们会对cuda-toolkit有依赖&…...

网络编程入门
目录 1.网络编程入门 1.1 网络编程概述【理解】 1.2 网络编程三要素【理解】 1.3 IP地址【理解】 1.4InetAddress【应用】 1.5端口和协议【理解】 2.UDP通信程序 2.1 UDP发送数据【应用】 2.2UDP接收数据【应用】 2.3UDP通信程序练习【应用】 3.TCP通信程序 3.1TCP…...

Linux-socket详解
Linux-socket详解_socket linux-CSDN博客...
)
SQL Server 2022安装要求(硬件、软件、操作系统等)
SQL Server 2022安装要求 1、硬件要求2、软件要求3、操作系统支持4、Server Core 支持5、跨语言支持6、磁盘空间要求 1、硬件要求 以下内存和处理器要求适用于所有版本的 SQL Server: 组件要求存储SQL Server 要求最少 6 GB 的可用硬盘驱动器空间。 磁盘空间要求随…...

“众店模式”:创新驱动下的商业新生态
在数字化浪潮的推动下,传统商业模式正经历着前所未有的转型。“众店模式”作为一种新兴的商业模式,以其独特的商业逻辑和创新的玩法,为商家和消费者构建了一个共赢的商业新生态。 一、“众店模式”的核心构成 “众店模式”的成功࿰…...

54. 螺旋矩阵
https://leetcode.cn/problems/spiral-matrix/description/?envTypestudy-plan-v2&envIdtop-100-liked观察示例中的输出轨迹我们可以想到如下设计: 1.在朝某一方向行进到头后的改变方向是确定的,左->下,下->右,右->…...

剧本杀小程序,市场发展下的新机遇
剧本杀作为休闲娱乐的一种游戏方式,在短时间内进入了大众视野中,受到了广泛关注。近几年,剧本杀行业面临着创新挑战,商家需求寻求新的发展机遇,在市场饱和度下降的趋势下,获得市场份额。 随着科技的不断进…...

【系统架构设计师】论文:论基于 ABSD 的软件开发
更多内容请见: 备考系统架构设计师-专栏介绍和目录 文章目录 摘要正文摘要 2022年5月,我就职的公司承接了xx的智慧党建工作,建设“党建红云” 系统,为xx公司的党组织提供觉务管理、服务功能,促进党员学习和党组织交流。我在该项目中承担架构设计师的职责,主导需求分析和…...

为什么OLED透明屏在同类产品中显示效果最好
说起OLED透明屏,这家伙在同类产品里那真的是“一枝独秀”啊!为啥这么说呢?且听我细细道来。 首先,OLED透明屏的透明度那是杠杠的!它不像传统显示屏那样有个固定的背景,而是可以实现像素级的透明效果。这样一…...

深度学习基础知识-Batch Normalization(BN)超详细解析
一、背景和问题定义 在深层神经网络(Deep Neural Networks, DNNs)中,层与层之间的输入分布会随着参数更新不断发生变化,这种现象被称为内部协变量偏移(Internal Covariate Shift)。具体来说,由…...

基于单片机的燃气报警阀门系统
本设计基于单片机的燃气报警阀门系统,燃气报警阀门系统采用STM32主控制器为核心芯片,外围电路由燃气传感器、OLED液晶显示模块、按键模块、蜂鸣器报警模块、电磁阀以及SIM800模块等模块组成。燃气传感器模块负责采集燃气浓度数据,采集完成由S…...

watch与computed的区别、运用的场景
computed和watch都是响应式数据变化的重要机制,但它们在功能、使用场景和性能表现上有显著的区别。 主要区别 功能和用途 1、computed:计算属性,用于基于其他数据属性进行计算,并返回一个结果。它具有缓存机制,只有当…...
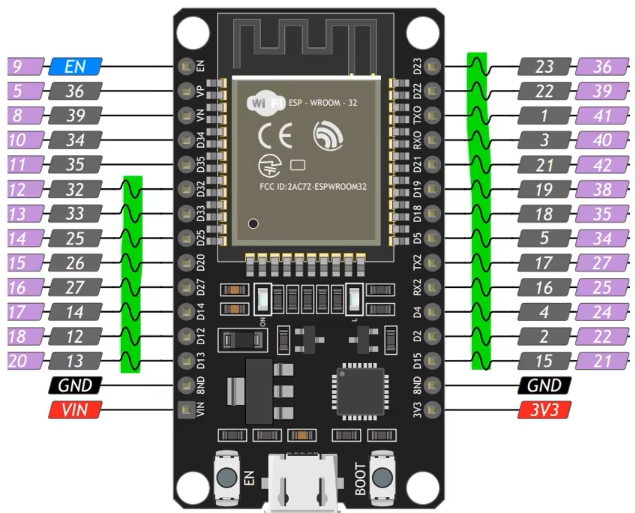
【ESP32+MicroPython】开发环境部署
本教程将指导你如何在Visual Studio Code(VSCode)中设置ESP32的MicroPython开发环境。我们将涵盖从安装Python到烧录MicroPython固件的整个过程,以及如何配置VSCode以便与ESP32进行交互。 准备工作 安装Python 确保你的计算机上安装了Pyth…...

Vision - 开源视觉分割算法框架 Grounded SAM2 配置与推理 教程 (1)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/143388189 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 Ground…...

极速净化Windows 11:Win11Debloat一键释放系统潜能
极速净化Windows 11:Win11Debloat一键释放系统潜能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and custo…...

Unity程序化建筑生成系统:性能可控的城市场景管线
1. 这不是“又一个建筑生成插件”,而是我替团队踩了三年坑后重写的底层逻辑在Unity里做城市场景,你肯定经历过:美术手搭一栋楼要两天,程序写个随机生成器跑出来全是穿模、面数爆炸、光照崩坏的“鬼楼”;或者用现成插件…...

ElevenLabs青少年语音TTS效果对比测试:12款竞品横评,仅2家通过COPPA 3.0儿童语音伦理认证
更多请点击: https://kaifayun.com 第一章:ElevenLabs青少年语音TTS的技术定位与伦理边界 ElevenLabs推出的青少年语音合成(Teen Voice TTS)并非简单的声音风格扩展,而是基于多说话人自监督表征学习与音色解耦建模的高…...

安克创新推 Soundcore Liberty 5 Pro 系列耳机:AI 降噪+智能记录,续航与功能的新平衡
Soundcore Liberty 5 Pro 系列:AI 音频芯片带来降噪新体验安克创新推出 Soundcore Liberty Pro 真无线耳机的新版本——Liberty 5 Pro 及 Liberty 5 Pro Max。Liberty 5 Pro 是首款搭载 Thus AI 音频芯片的耳机,该芯片能增强降噪能力,让用户在…...

项目管理专题会议圆满举办丨AI+数据驱动:重塑项目管理全链路
2026 年 5 月 20 日,由深圳市软件行业协会、易趋 、腾讯TAPD主办的第十四期项目管理专题活动 ——AI 如何重塑项目管理全链路主题沙龙在深圳圆满举行。来自IT、制造、金融等领域的PMO、项目管理专家、技术实践者,以及CIO/CTO等高层决策者共同探讨 AI 时代…...

HarmonyOS ArkUI实战:从零构建购物社交应用UI界面
1. 项目概述与核心价值如果你正在学习HarmonyOS应用开发,或者已经从其他移动端框架(如Android、Flutter)转过来,那么构建一个美观、交互流畅的UI界面,往往是上手实践的第一步,也是最直观检验学习成果的一步…...

测试工程师如何与开发人员高效沟通?这5个技巧让你不再背锅
在互联网软件研发流程中,测试工程师和开发工程师是天生的“搭档”也是最容易产生矛盾的组合:测试测出bug,开发说“这不是我的问题”“环境不对”“你操作错了”,最后问题定位下来测试背锅;测试提前同步风险,…...
)
编译和链接(以Windows,VS环境下C语言为例)
编译和链接(以Windows,VS环境下C语言为例)一.什么是翻译环境和运行环境?二.翻译环境2.1预处理(预编译)2.2编译2.2.1词法分析2.2.2语法分析2.2.3语义分析2.3汇编2.4链接三.运行环境提前说明一下,虽然说我们是以Windows操作系统为例,…...

到底什么是 AI 测试?AI 测试与传统测试的区别?
过去两年,AI已经从"加分项"变成了"必选项"。 不只是大厂,二线公司、甚至传统行业的测试团队都在要求:"能熟练使用AI工具提效"。 更关键的是,面试的玩法也变了。现在的技术面试早就跳出了 “考 AI 零…...

OAuthlib错误诊断实战:从invalid_grant到temporarily_unavailable根因定位
1. 为什么OAuthlib的错误信息总让你一头雾水?你刚在Flask或Django项目里集成OAuth2登录,用户点“用GitHub登录”后页面直接报500,控制台只甩出一行红字:oauthlib.oauth2.rfc6749.errors.InvalidGrantError: (invalid_grant) Bad r…...